







1、基础环境
| 三台虚拟机的k8s环境 | 借助Kubesphere部署的v1.21.5 |
| hadoop | 3.3.6 |
| v1.21.5 | v1.21.5 |
| spark-3.4.1-bin-hadoop3 | 3.4.1 |
| hive | 3.1.3 |
| hbase | 2.4.9 |
| flink | 1.17.0 |
| flink-connector-mysql-cdc | 2.4.1 |
| mysql | 8.0.33 |
| hudi | 0.14.1 |
2、模拟数据写入MySQL(doris-mysql)
使用定时任务解析日志文件,封装成特定的格式,netty client发送到server端,server端进行孵化处理,解析,写入MySQL数据
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, DatagramPacket datagramPacket) throws Exception {
try {
ByteBuf byteBuf = datagramPacket.content();
String str = byteBuf.toString(CharsetUtil.UTF_8);
if (StringUtils.isNotBlank(str)) {
Map<String, Object> event = ProcessUtil.parseProcess(str);
LOG.info(JSONUtil.toJsonStr(event));
pushMsgToMysql(event);
}
String resStr = "ok";
byte[] resBytes = resStr.getBytes(StandardCharsets.UTF_8);
DatagramPacket resData = new DatagramPacket(Unpooled.copiedBuffer(resBytes), datagramPacket.sender());
channelHandlerContext.writeAndFlush(resData);
} catch (Exception e) {
LOG.error("channelRead0异常", e);
}
}
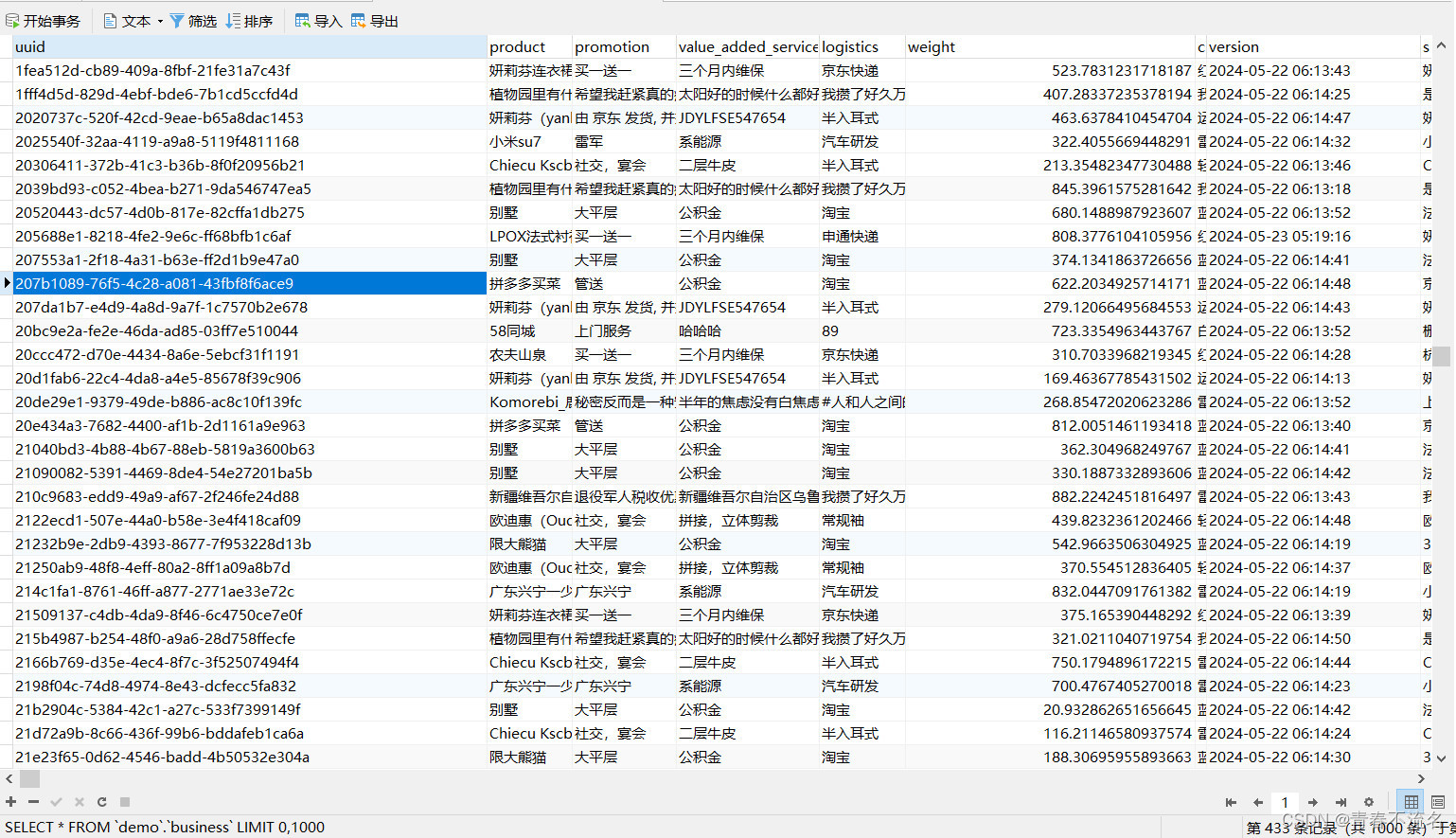
SQL脚本语句:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for business
-- ----------------------------
DROP TABLE IF EXISTS `business`;
CREATE TABLE `business` (
`uuid` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`product` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商品名称',
`promotion` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '促销',
`value_added_service` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '增值服务',
`logistics` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '物流',
`weight` double NULL DEFAULT NULL COMMENT '重量',
`color` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '颜色',
`version` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '版本',
`shop` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '店铺',
`evaluate` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '评价',
`order_num` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '订单编号',
`rider` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '骑手',
`order_time` datetime NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '订单时间',
`create_time` datetime NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
`pay_price` decimal(10, 2) NULL DEFAULT NULL COMMENT '支付价格',
`pay_type` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '支付方式',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '收获地址',
PRIMARY KEY (`uuid`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = DYNAMIC;SET FOREIGN_KEY_CHECKS = 1;
3、flink cdc消费MySQL写入kafka
3.1、程序代码
需要优化,有运行推出的可能
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.kafka.shaded.org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class MysqlFlinkCdcKafkaStream {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",10000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.serverTimeZone("Asia/Shanghai")
.hostname("mysql")
.port(3306)
.username("root")
.password("123456")
.databaseList("demo")
//2.3.0cdc必须前面加上数据库点
.tableList("demo.business")
.startupOptions(StartupOptions.initial())
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
DataStreamSource<String> streamSource = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "mysql-cdc-source");
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("kafka:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("demo")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("demo-")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, "300000")
.build();streamSource.sinkTo(kafkaSink);
try {
env.execute("MySQL-Stream_Flink_CDC_SQL-Kafka");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
3.2、程序maven打包
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.cloud</groupId>
<artifactId>MysqlFlinkCdcKafkaStream</artifactId>
<version>2.4.5</version>
<name>MysqlFlinkCdcKafkaStream</name>
<properties>
<java.version>1.8</java.version>
<flink.version>1.17.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-uber</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>false</filtering>
</resource>
</resources>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<mainClass>com.example.cloud.MysqlFlinkCdcKafkaStream</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<excludeTransitive>false</excludeTransitive>
<stripVersion>false</stripVersion>
<includeScope>runtime</includeScope>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-resources</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}/config
</outputDirectory>
<resources>
<resource>
<directory>src/main/resources/</directory>
</resource>
</resources>
</configuration>
</execution>
<execution>
<id>copy-sh</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}
</outputDirectory>
<resources>
<resource>
<directory>bin/</directory>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.3、k8s flink native 运行部署jar
启动运行命令,
在k8s集群中native flink方式运行
3.3.1、运行命令
flink-1.17.0/bin/flink run-application --target kubernetes-application -Dkubernetes.cluster-id=my-cluster-id -Dkubernetes.namespace=default -Dkubernetes.service-account=default -Dkubernetes.container.image=flink:1.17-scala_2.12-java8 -Dkubernetes.rest-service.exposed.type=NodePort -Dkubernetes.pod-template-file.jobmanager=pod-template.yaml local:///opt/flink/jars/MysqlFlinkCdcKafkaStream-jar-with-dependencies.jar
3.3.2、pod-template.xml
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
namespace: default
spec:
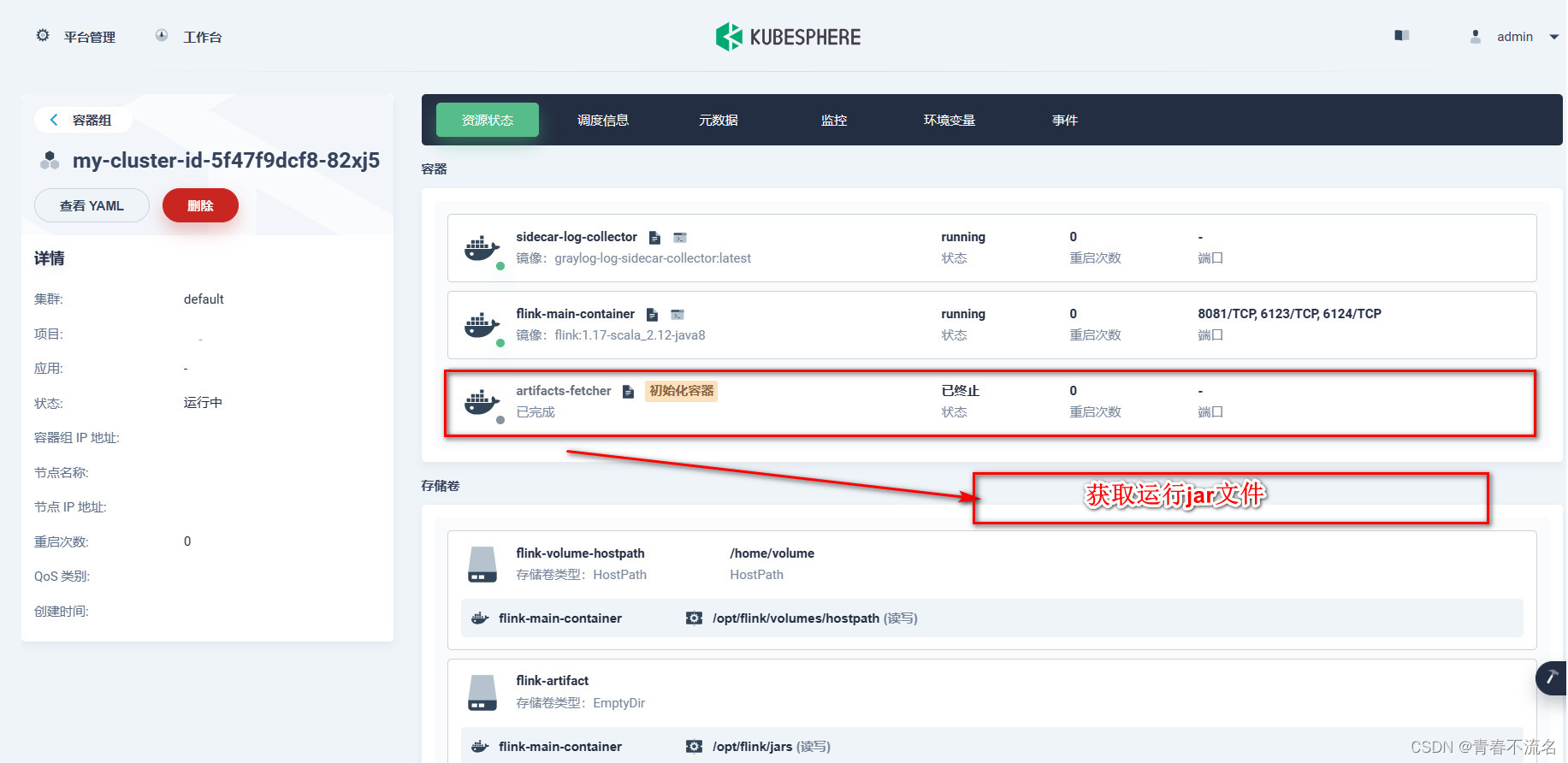
initContainers:
- name: artifacts-fetcher
image: busybox:latest
imagePullPolicy: IfNotPresent
command: [ 'wget', 'http://file-service:8080/file/download/MysqlFlinkCdcKafkaStream-jar-with-dependencies.jar', '-O', '/flink-artifact/MysqlFlinkCdcKafkaStream-jar-with-dependencies.jar' ]
volumeMounts:
- mountPath: /flink-artifact
name: flink-artifact
containers:
- name: flink-main-container
resources:
requests:
ephemeral-storage: 2048Mi
limits:
ephemeral-storage: 2048Mi
volumeMounts:
- name: flink-volume-hostpath
mountPath: /opt/flink/volumes/hostpath
- name: flink-artifact
mountPath: /opt/flink/jars
- name: flink-logs
mountPath: /opt/flink/log
- name: sidecar-log-collector
image: graylog-log-sidecar-collector:latest
imagePullPolicy: IfNotPresent
env:
- name: GS_SERVER_URL
value: "http://graylog2:9000/api/"
- name: GS_NODE_ID
value: "0df87613-0af7-431e-a3c5-48677e66b6a3"
- name: GS_NODE_NAME
value: "file-service-collector-logs"
- name: GS_SERVER_API_TOKEN
value: "16pmeleivc8621t8cp9gtauf8bm3gfm2n4j1773jqoqqf2j2l1m0"
- name: GS_LIST_LOG_FILES
value: "/flink-logs"
volumeMounts:
- name: flink-logs
mountPath: /flink-logs
volumes:
- name: flink-volume-hostpath
hostPath:
path: /home/volume
type: Directory
- name: flink-artifact
emptyDir: { }
- name: flink-logs
emptyDir: { }
3.4、容器启动服务
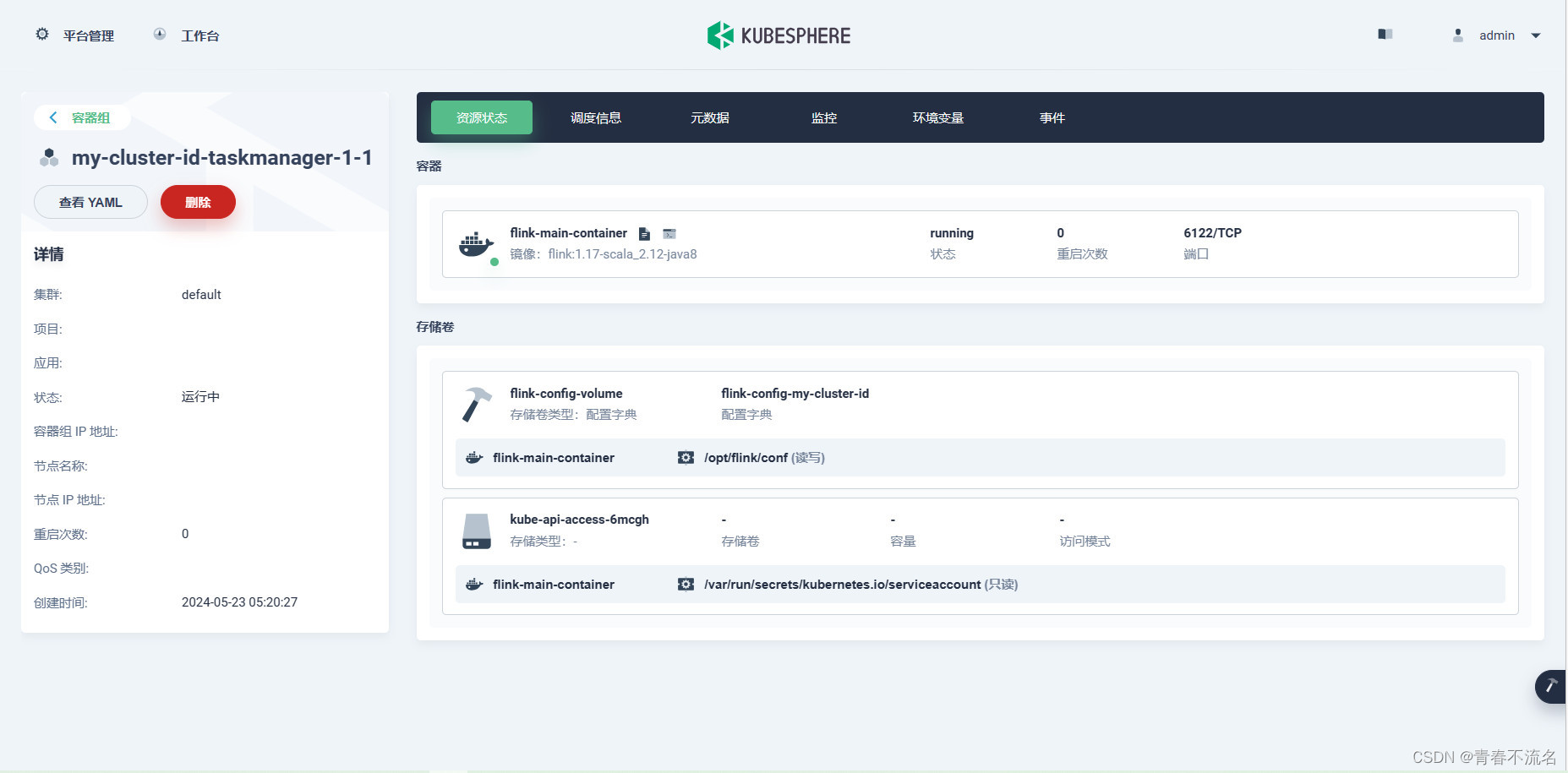
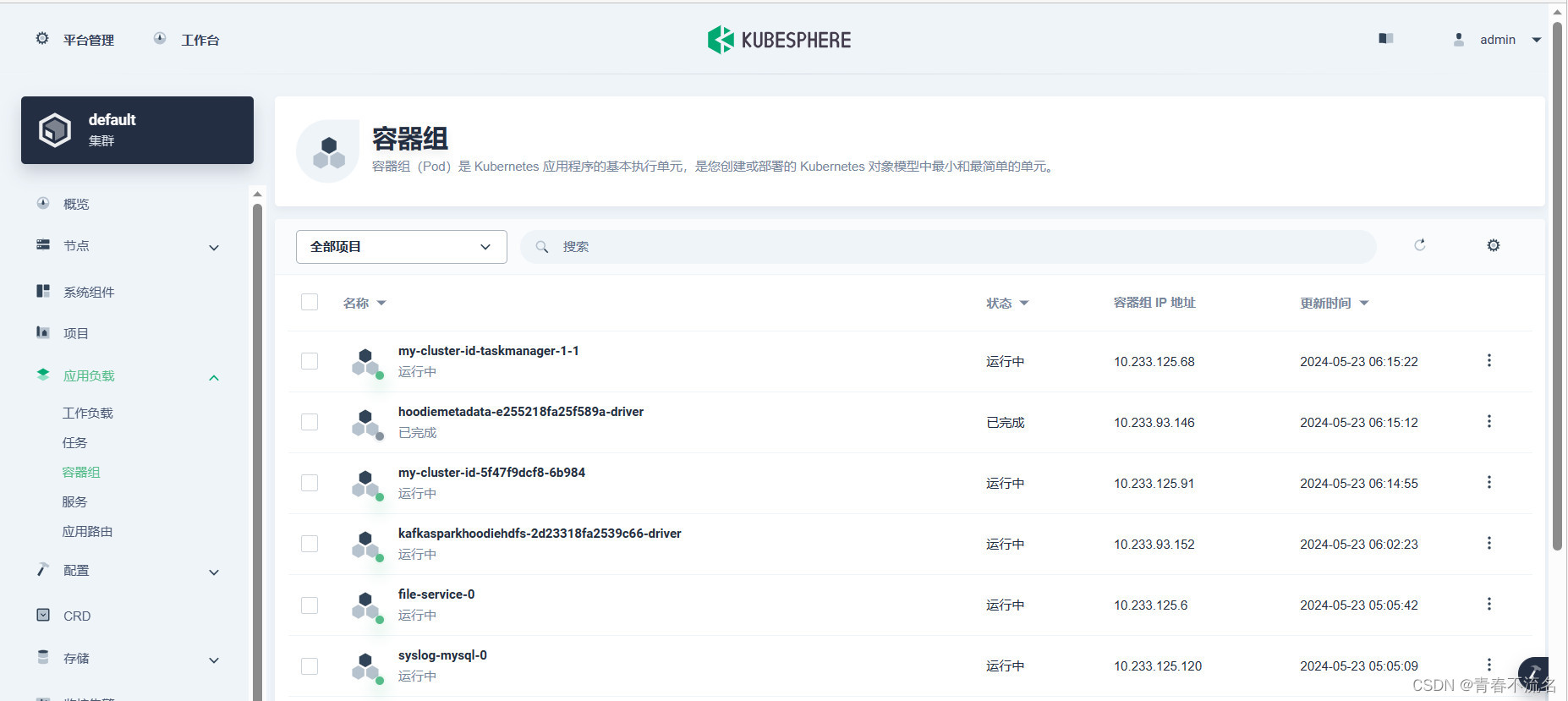
3.5、获取运行jar文件
3.6、写入kafka的效果

4、spark-streaming读取kafka写入hudi
4.1、程序代码
代码需要优化
import org.apache.hudi.DataSourceWriteOptions.{PARTITIONPATH_FIELD, PRECOMBINE_FIELD, RECORDKEY_FIELD}
import org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.spark.sql.streaming.{DataStreamReader, StreamingQuery, Trigger}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.util.concurrent.TimeUnit
object KafkaSparkHoodieHdfs {
def main(args: Array[String]): Unit = {
val kafkaConsumer: String = "你的kafka地址"
val kafkaTopic: String = "你的topic名称"
val startingOffsets: String = "latest"
val endingOffsets: String = "latest"
val kafkaGroupId: String = "kakfa消费组名"
val failOnDataLoss: Boolean = false
val maxOffsetsPerTrigger: Int = 3000
val hoodieTableName: String = "hudi表名"
val lakePath: String = "hdfs路径"
val checkpointLocation: String = "hdfs路径"
val partitionFields: String = Array().mkString(",")
val schema_base = StructType(List(
StructField("before", StringType),
StructField("after", StringType),
StructField("source", MapType(StringType, StringType)),
StructField("op", StringType),
StructField("ts_ms", LongType),
StructField("transaction", StringType)
))
println("create spark session ..........................................................")
val sparkConf = SparkSession.builder().master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.extensions", "org.apache.spark.sql.hudi.HoodieSparkSessionExtension")
val sparkSession: SparkSession = sparkConf.getOrCreate()
println("get spark DataStreamReader start ..........................................................")
val dsr: DataStreamReader = sparkSession
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaConsumer)
.option("subscribe", kafkaTopic)
.option("startingOffsets", startingOffsets)
.option("failOnDataLoss", failOnDataLoss)
.option("maxOffsetsPerTrigger", maxOffsetsPerTrigger)
.option("kafka.group.id", kafkaGroupId)
.option("includeHeaders", "true")
println("get spark DataStreamReader end ..........................................................")
val df: DataFrame = dsr.load()
println("get spark DataFrame end ..........................................................")
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val frame: Dataset[Row] = df.select(from_json('value.cast("string"),schema_base) as "value").select($"value.*")
.alias("data")
.select(
get_json_object($"data.after", "$.uuid").as("uuid"),
get_json_object($"data.after", "$.product").as("product"),
get_json_object($"data.after", "$.promotion").as("promotion"),
get_json_object($"data.after", "$.value_added_service").as("value_added_service"),
get_json_object($"data.after", "$.logistics").as("logistics"),
get_json_object($"data.after", "$.weight").as("weight"),
get_json_object($"data.after", "$.color").as("color"),
get_json_object($"data.after", "$.version").as("version"),
get_json_object($"data.after", "$.shop").as("shop"),
get_json_object($"data.after", "$.evaluate").as("evaluate"),
get_json_object($"data.after", "$.order_num").as("order_num"),
get_json_object($"data.after", "$.rider").as("rider"),
get_json_object($"data.after", "$.order_time").as("order_time"),
get_json_object($"data.after", "$.create_time").as("create_time"),
get_json_object($"data.after", "$.pay_price").as("pay_price"),
get_json_object($"data.after", "$.pay_type").as("pay_type"),
get_json_object($"data.after", "$.address").as("address")
)
println("get spark Dataset end ..........................................................")
val query: StreamingQuery = frame
.writeStream
.format("hudi")
.options(getQuickstartWriteConfigs)
.option("hoodie.metadata.enable", false)
.option(RECORDKEY_FIELD.key, "uuid")
.option(PRECOMBINE_FIELD.key, "product")
.option(PRECOMBINE_FIELD.key, "promotion")
.option(PRECOMBINE_FIELD.key, "value_added_service")
.option(PRECOMBINE_FIELD.key, "logistics")
.option(PRECOMBINE_FIELD.key, "weight")
.option(PRECOMBINE_FIELD.key, "color")
.option(PRECOMBINE_FIELD.key, "order_num")
.option(PRECOMBINE_FIELD.key, "shop")
.option(PRECOMBINE_FIELD.key, "evaluate")
.option(PRECOMBINE_FIELD.key, "order_num")
.option(PRECOMBINE_FIELD.key, "rider")
.option(PRECOMBINE_FIELD.key, "order_time")
.option(PRECOMBINE_FIELD.key, "create_time")
.option(PRECOMBINE_FIELD.key, "pay_price")
.option(PRECOMBINE_FIELD.key, "pay_type")
.option(PRECOMBINE_FIELD.key, "address")
.option(PARTITIONPATH_FIELD.key(), partitionFields)
.option(HoodieWriteConfig.TBL_NAME.key, hoodieTableName)
.outputMode("append")
.option("path", lakePath)
.option("checkpointLocation", checkpointLocation)
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS))
.start()
println("get kafka data end ..........................................................")
query.awaitTermination()
}
}
4.2、maven打包程序
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.cloud</groupId>
<artifactId>KafkaSparkHoodieHdfs</artifactId>
<version>2.4.5</version>
<name>KafkaSparkHoodieHdfs</name>
<properties>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.4.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3.4-bundle_2.12</artifactId>
<version>0.14.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-token-provider-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<!--<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
<targetPath>${project.build.directory}/config</targetPath>-->
</resource>
</resources>
<!--<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<outputDirectory>target</outputDirectory>-->
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.example.cloud.KafkaSparkHoodieHdfs</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<excludeTransitive>false</excludeTransitive>
<stripVersion>false</stripVersion>
<includeScope>runtime</includeScope>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-resources</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}/config
</outputDirectory>
<resources>
<resource>
<directory>src/main/resources/</directory>
</resource>
</resources>
</configuration>
</execution>
<execution>
<id>copy-sh</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}
</outputDirectory>
<resources>
<resource>
<directory>bin/</directory>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
4.3、hudi-spark3.4-bundle_2.12jar本地修改编译
4.4、前置准备,jar上传到hdfs
KafkaSparkHoodieHdfs-jar-with-dependencies.jar
spark-sql-kafka-0-10_2.12-3.4.1.jar
将两个jar文件上传到hdfs
4.5、k8s中提交spark任务
spark-3.4.1-bin-hadoop3/bin/spark-submit \
--name KafkaSparkHoodieHdfs \
--verbose \
--master k8s://https://k8s集群地址 \
--deploy-mode cluster \
--conf spark.network.timeout=3000 \
--conf spark.executor.instances=1 \
--conf spark.driver.cores=2 \
--conf spark.executor.cores=2 \
--conf spark.driver.memory=2048m \
--conf spark.executor.memory=2048m \
--conf spark.kubernetes.namespace=default \
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \
--conf spark.kubernetes.container.image=spark:3.4.1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=default \
--conf spark.kubernetes.authenticate.executor.serviceAccountName=default \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.driver.extraClassPath=/home/d/etc/hadoop \
--jars hdfs://ip:端口/spark-sql-kafka-0-10_2.12-3.4.1.jar \
--class com.example.cloud.KafkaSparkHoodieHdfs \
hdfs://ip:端口/spark/jars/KafkaSparkHoodieHdfs-jar-with-dependencies.jar
4.6、启动效果
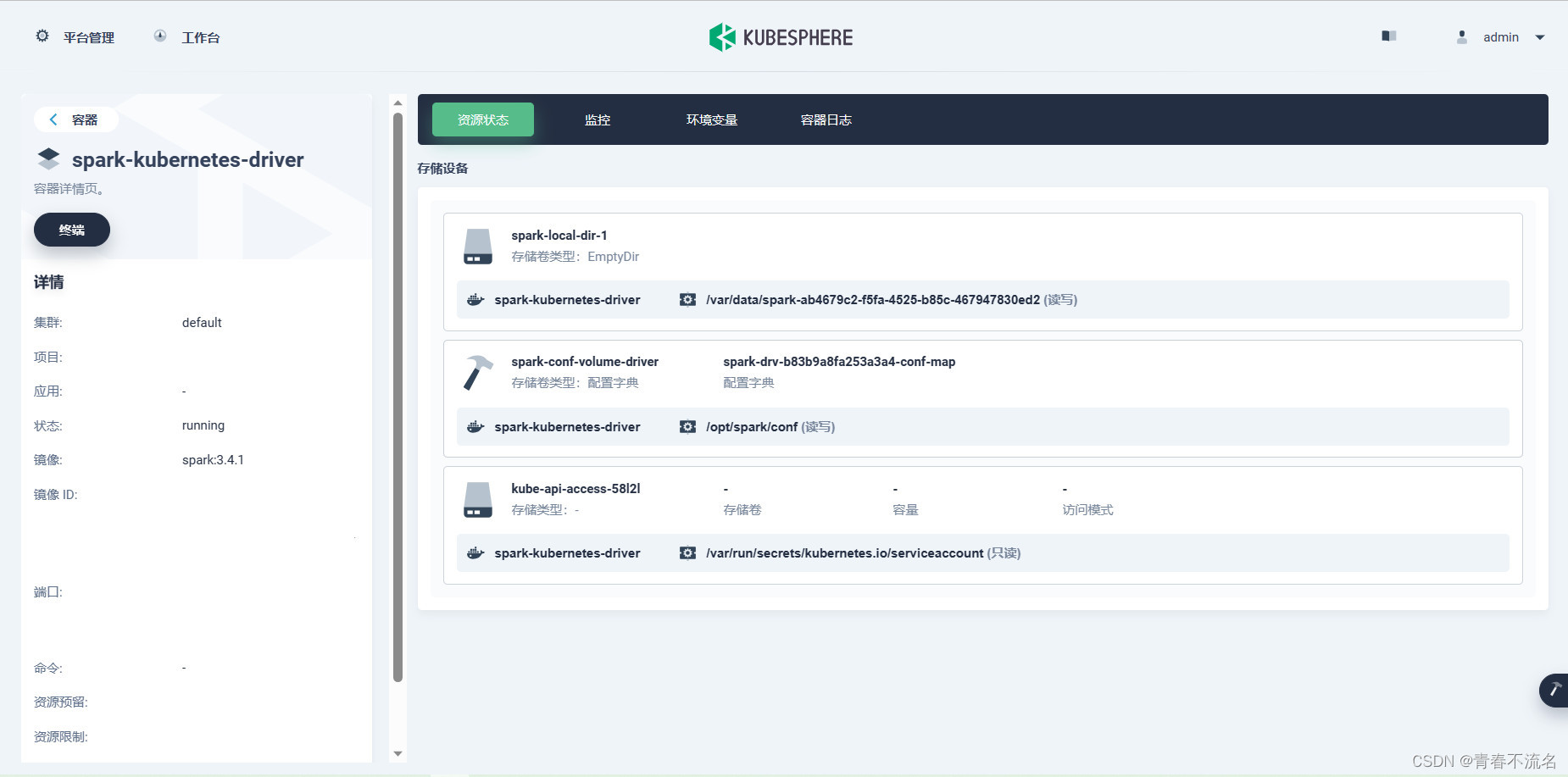
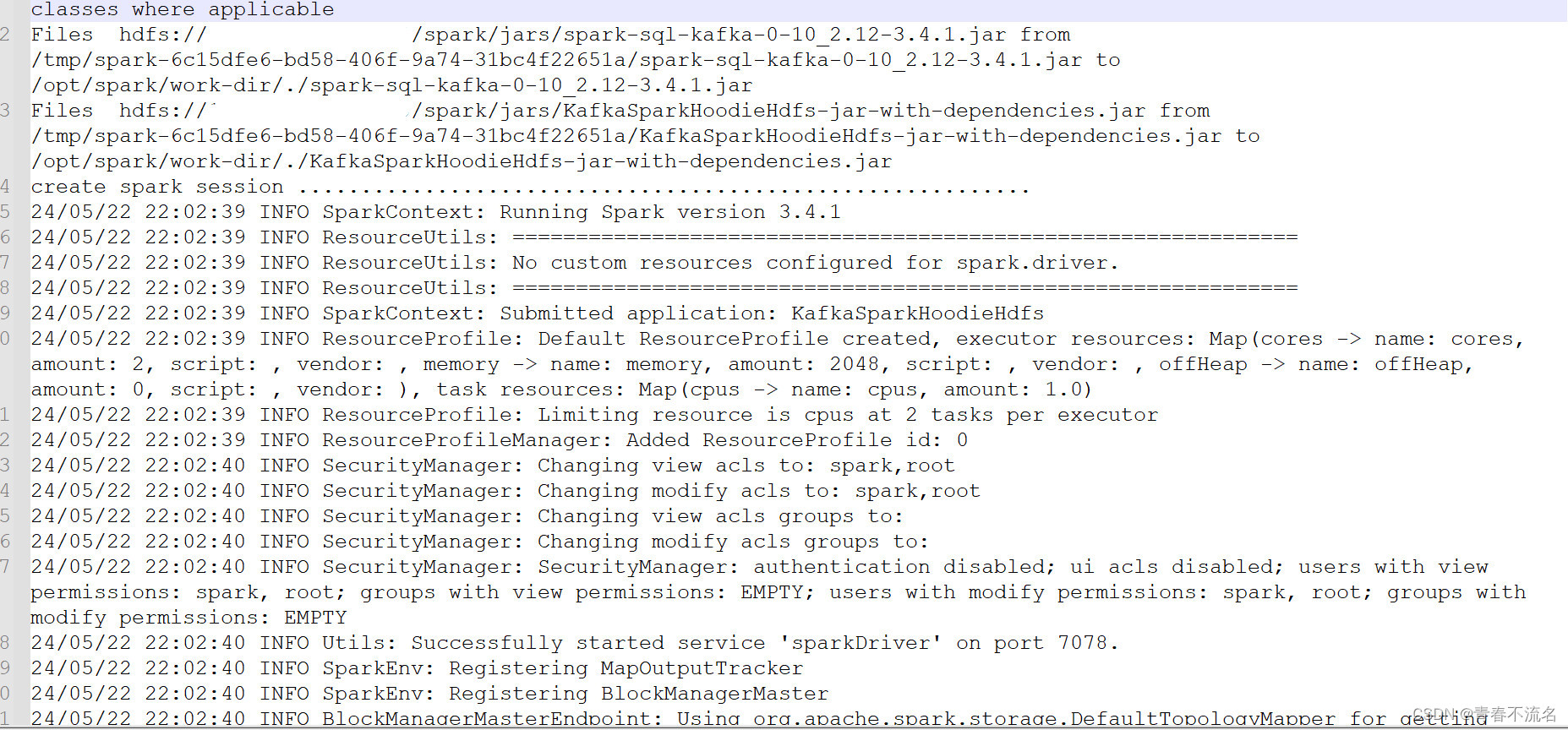
5、读取hudi hdfs结果验证
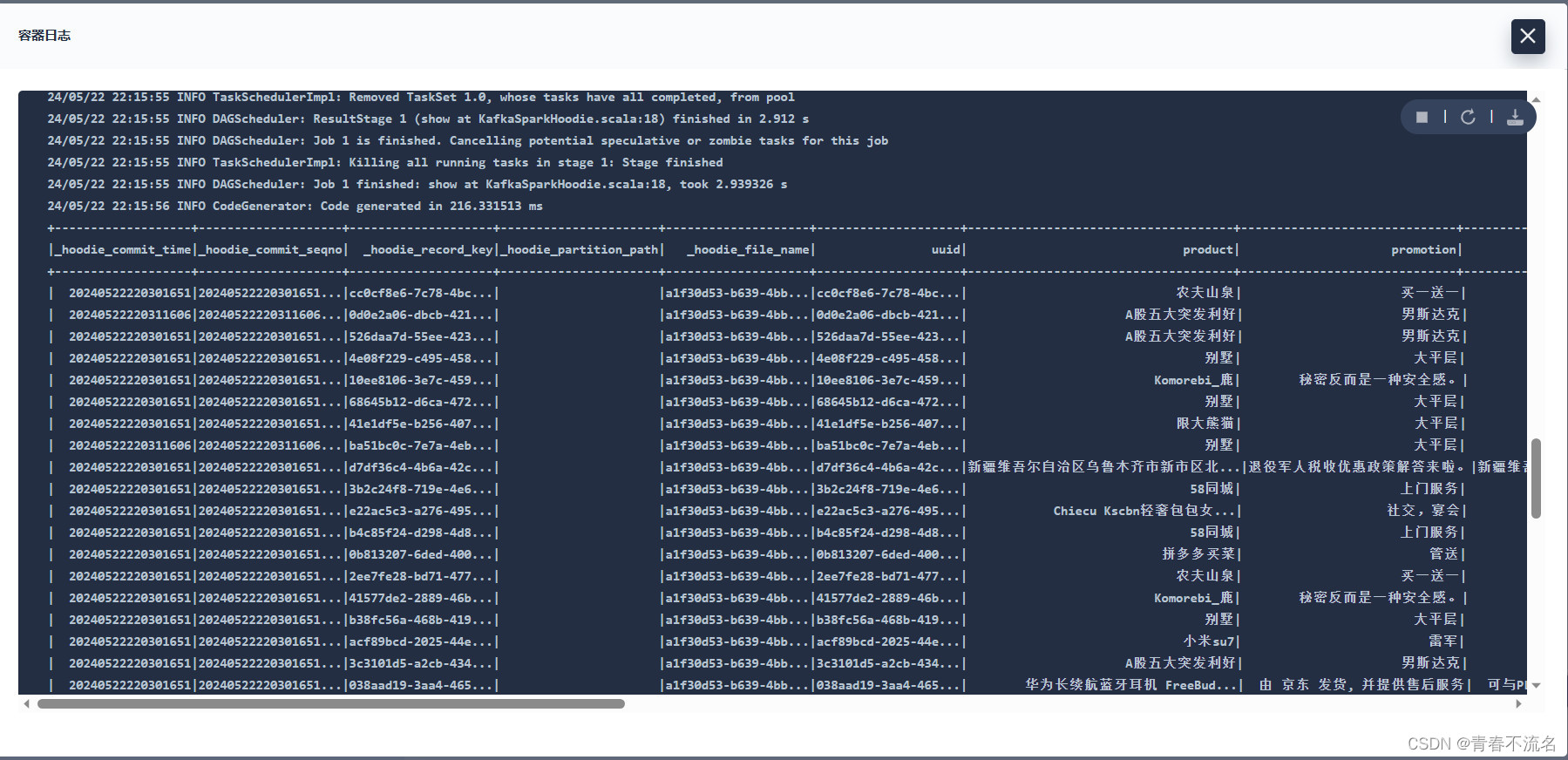
5.1、验证命令
spark-3.4.1-bin-hadoop3/bin/spark-submit \
--name HoodieMetaData \
--verbose \
--master k8s://k8s集群地址 \
--deploy-mode cluster \
--conf spark.network.timeout=3000 \
--conf spark.executor.instances=1 \
--conf spark.driver.cores=2 \
--conf spark.executor.cores=2 \
--conf spark.driver.memory=2048m \
--conf spark.executor.memory=2048m \
--conf spark.kubernetes.namespace=default \
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \
--conf spark.kubernetes.container.image=spark:3.4.1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=default \
--conf spark.kubernetes.authenticate.executor.serviceAccountName=default \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true" \
--conf spark.driver.extraClassPath=/home/d/etc/hadoop \
--jars hdfs://ip:端口/spark/jars/spark-sql-kafka-0-10_2.12-3.4.1.jar \
--class com.example.cloud.HoodieMetaData \
hdfs://ip:端口/spark/jars/HoodieMetaData-jar-with-dependencies.jar
6、问题记录
6.1、 java.io.IOException: Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try.
(Nodes: current=[DatanodeInfoWithStorage[10.7.215.57:9866,DS-93d697c4-d796-47be-8802-d214d95b8234,DISK]],
original=[DatanodeInfoWithStorage[10.7.215.57:9866,DS-93d697c4-d796-47be-8802-d214d95b8234,DISK]]).
The current failed datanode replacement policy is DEFAULT, and a client may configure this via 'dfs.client.block.write.replace-datanode-on-failure.policy' in its configuration.解决方案:
.option("hoodie.metadata.enable", false)或者重新编译代码
6.2、
Caused by: org.apache.hadoop.security.AccessControlException: Permission denied: user=spark, access=WRITE,
inode="/spark-hoodie/data/.hoodie":root:supergroup:drwxr-xr-x解决方案:
core-site.xml增加内容(无法解决,设置export可以解决,仅限--deploy-mode client
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>或者
hadoop fs -setfacl -R -m user:spark:rwx /
hadoop fs -setfacl -R -m user:spark:rwx /spark-hoodie/data/.hoodie
hadoop fs -setfacl -R -m user:spark:rwx /spark-hoodie/data/.hoodie/metadata/.hoodiehadoop fs -getfacl /
hadoop fs -getfacl /spark-hoodie/data/.hoodie
确认Hadoop版本:首先确保你使用的Hadoop版本支持ACL功能。通常,从Hadoop 2.x版本开始,ACL功能就已经包含在其中。
修改Hadoop配置文件:在Hadoop的配置文件中启用ACL功能。主要涉及到 hdfs-site.xml 和 core-site.xml 这两个配置文件。
打开 hdfs-site.xml,确保以下属性被设置为合适的值:
xml
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
在 core-site.xml 中,确认以下属性被设置为合适的值:
xml
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
重启Hadoop服务:修改完配置文件后,需要重启Hadoop集群的相关服务,以使配置生效
6、优化程序、版本编译
hudi
mvn clean package -Dflink1.17.0 -Dscala2.12 -Dspark3.4.1 -DskipTests -Pflink-bundle-shade-hive3 -T 4 -Denforcer.skip
参考地址:
Hudi Spark写入出现NoSuchMethod HdfsDataInputStream.getReadStatistics问题解决 - 简书 (jianshu.com)
mvn clean package -DskipTests -Dspark3.4 -Dflink1.17 -Dscala-2.12 -Dhadoop.version=3.3.6 -Pflink-bundle-shade-hive3 -T 4 -Denforcer.skip
7、代码目录
















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









