







这是做的第一个任务,爬取 http://www.thebigdata.cn/ 中的标题和链接。
红框中为要爬取的部分:
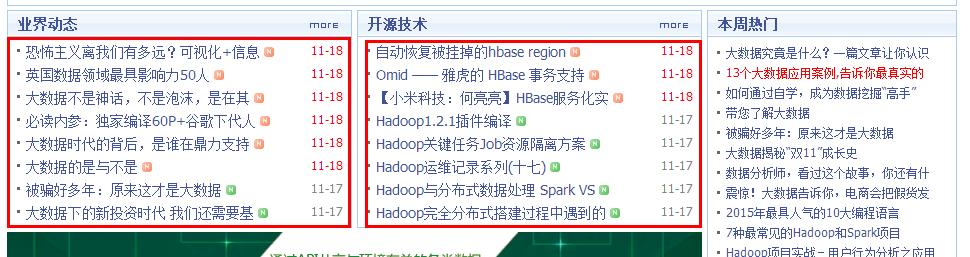
以下为部分源代码:

1、 我一开始是在linux系统下做的,因为是跟着视频学习,然而遇到一些问题,所以改为在PYcharm里,练习的时候是链接和标题分开爬取的,所以将写的代码复制粘贴,运行,然而并没有出现什么,失败。当时是正则的问题。但是在我的电脑上出现了一个问题:
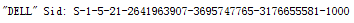
其实这对数据爬取没什么影响,上网查了一下,SID就是为域或本地计算机中创建的每个帐户分配的唯一ID 字符串。因为我的电脑中建立.py文件时会自动生成:
__author__ = 'DELL'2、最开始是将链接和标题分开练习爬取的,爬取链接时发现不止有所需要的链接还有一些网址,类似这样:

发现是正则写的不够全面,观察了一下,发现要爬取的链接开头都是大写英文字母,所以就将正则改为了:
reg=r'href="(.*?)\.html"'
#改为#
reg=r'href="([A-Z].*?)\.html"'
reg=r'</span><a href="((YeJieDongTai|YingYongAnLi|JieJueFangAn|Hadoop|HBase|QiTa|JiShuBoKe)/\d{4,5}\.html)"(.*?)>(.*?)</a>'3、将链接和标题一块爬取的时候,开始写了两个正则的函数,就是想将两个爬虫合一块,然而这样要不出不来,要么链接和标题是分开的,看了她们的代码发现她们用了一个语法:
re.finditer()然后在输出时是这样写的:
fd.write(item.group(1)+'\t'+item.group(3)+'\n')总的来说还是自己掌握的只是不够多。下面是爬取的代码:#conding-utf8 import re import urllib url='http://www.thebigdata.cn/' def getHtml(url): page=urllib.urlopen(url) html=page.read() return html def getDSJ(html): reg=r'</span><a href="([A-Z].*?\.html)"(.*?)>(.*?)</a>' lsre=re.compile(reg) ls=re.finditer(lsre,html) return ls html=getHtml(url) ls=getDSJ(html) fd=open(r'theBigDate2.txt','a+') for item in ls: fd.write(item.group(1)+'\t'+item.group(3)+'\n') fd.close()爬取的部分内容:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









