






前言
这是针对于我之前[博客]的一次整理,因为公司需要一些技术文档的定期整理与分享,我就整理了一下。(https://blog.csdn.net/TT_4419/article/details/141997617?spm=1001.2014.3001.5501)
其实,nginx配置 服务故障转移与自动恢复也是可以的,不过他的技术难度不大,这里可以查看之前的博客。
服务器查看
服务器信息查看
dmesg -T
Linux系统中用于查看内核环缓冲区(kernel ring buffer)内容的命令。这个命令可以显示启动时硬件设备的检测信息、驱动程序的加载信息以及系统运行过程中产生的各种内核级别的消息。dmesg 命令对于系统管理员和开发者来说非常有用,因为它可以帮助他们诊断系统问题或了解系统内部的工作情况。
着重查看 dmesg -T | grep kill 是否有OOM发生
服务器资源查看
free -g
total used free shared buff/cache available
Mem: 15 5 2 0 8 10
Swap: 2 0 2
total:表示系统中总的物理内存(以 GB 为单位)。
used:表示已经被使用的内存(以 GB 为单位)
free:表示完全空闲且未被使用的内存(以 GB 为单位)
shared:表示多个进程共享的内存(以 GB 为单位)。这部分内存通常用于文件系统缓冲区等
buff/cache:表示被用作缓存和缓冲区的内存(以 GB 为单位)。这些内存可以被操作系统快速回收,以供其他应用程序使用。
available:表示可以立即分配给新进程或应用程序的内存(以 GB 为单位)。这个值考虑了 buff/cache 中可以被快速回收的部分。
通常 free很低 但是buffer很高,并不影响程序正常运行和启动,Linux 内核会智能地管理内存,优先保证应用程序的内存需求。
- Swap 分区:Swap 分区是磁盘上的一个区域,用于扩展物理内存。当物理内存不足时,内核会将一些不常用的内存页移动到 Swap 分区,以释放物理内存供其他应用程序使用。
- 优点
- 防止内存溢出:Swap 分区可以防止系统因内存不足而崩溃。
- 提高稳定性:通过将不常用的内存页移到 Swap,可以保持系统稳定运行。
- 缺点
- 性能下降:由于磁盘 I/O 速度远低于内存,频繁使用 Swap 会导致系统性能显著下降。
- 延迟增加:应用程序访问 Swap 中的数据时,响应时间会增加。
df -h
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 7.8G 0 7.8G 0% /dev
tmpfs 1.6G 2.3M 1.6G 1% /run
/dev/sda1 99G 34G 61G 36% /
tmpfs 7.8G 148M 7.7G 2% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/sdb1 232G 123G 100G 54% /mnt/data
查看对应的磁盘资源,之前遇到过 因为nginx的access日志过大,导致磁盘读写受限,进而导致客户整体环境不可用(客户磁盘只有50G)
jstack定位
如果遇到非虚拟机级别的错误,且businessLog无法捕获有效信息的,保留事故现场,进行jstack定位。
进入容器内部(容器下)
docker exec -it container /bin/bash
确定进程id
jsp
或者使用
ps -ef | grep java
之前有发现过线上环境 jsp有两个,ps -ef对应java进程是一个
我们认为是残留进程,这些会对程序干扰
生成堆栈跟踪
jstack 1(pid) > thread_dump.txt
资源拷贝(容器下)
将容器内的资源cp到容器外部
sudo docker cp h3_webapi:/tmp/20240901/stack.log /tmp/20240901/stack.log
stack 日志分析
这一步我推荐 直接丢给AI
然后我这边分析过的,有问题的场景:
1.数据库连接异常
2.大量线程waiting,等待资源锁
3.死锁Deadlock
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007f5b4c005c78 (object 0x000000076b00e0e0, a java.util.HashMap),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x00007f5b4c005b98 (object 0x000000076b00e110, a java.util.HashMap),
which is held by "Thread-1"
一般来说,jstack日志总归能给到点东西,但是注意jstack日志中的时间,指的是你生成出来的时间。
他记录的是你当时线程状态,你看不了过程状态
GC分析
启用 GC 日志记录
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
-XX:+PrintGCDetails:打印详细的 GC 信息。-XX:+PrintGCDateStamps:在每条 GC 日志前加上日期和时间戳。-Xloggc:/path/to/gc.log:指定 GC 日志文件的路径。
启动转轮
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M
-XX:+UseGCLogFileRotation:启用 GC 日志轮转。-XX:NumberOfGCLogFiles=10:设置保留的 GC 日志文件数量。-XX:GCLogFileSize=10M:设置每个 GC 日志文件的最大大小。
GC日志
{Heap before GC invocations=385 (full 2):
garbage-first heap total 27262976K, used 24909326K [0x0000000160800000, 0x0000000160c0d000, 0x00000007e0800000)
region size 4096K, 5121 young (20975616K), 51 survivors (208896K)
Metaspace used 217462K, capacity 254752K, committed 275072K, reserved 1275904K
class space used 24752K, capacity 38227K, committed 47744K, reserved 1048576K
2024-03-13T18:52:10.781+0800: 440420.560: [GC pause (GCLocker Initiated GC) (young)
Desired survivor size 1342177280 bytes, new threshold 5 (max 5)
- age 1: 117000376 bytes, 117000376 total
- age 2: 20296144 bytes, 137296520 total
- age 3: 11908392 bytes, 149204912 total
- age 4: 26488920 bytes, 175693832 total
- age 5: 25737792 bytes, 201431624 total
2024-03-13T18:52:11.040+0800: 440420.818: [SoftReference, 0 refs, 0.0000523 secs]2024-03-13T18:52:11.040+0800: 440420.818: [WeakReference, 199 refs, 0.0000331 secs]2024-03-13T18:52:11.040+0800: 440420.818: [FinalReference, 2295 refs, 0.0030429 secs]2024-03-13T18:52:11.043+0800: 440420.821: [PhantomReference, 0 refs, 0 refs, 0.0000055 secs]2024-03-13T18:52:11.043+0800: 440420.821: [JNI Weak Reference, 0.0007846 secs] (to-space exhausted), 0.7369998 secs]
[Parallel Time: 250.3 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 440420567.7, Avg: 440420567.7, Max: 440420567.8, Diff: 0.1]
[Ext Root Scanning (ms): Min: 1.4, Avg: 4.8, Max: 18.0, Diff: 16.6, Sum: 38.7]
[Update RS (ms): Min: 4.3, Avg: 17.0, Max: 20.6, Diff: 16.3, Sum: 136.3]
[Processed Buffers: Min: 48, Avg: 179.4, Max: 244, Diff: 196, Sum: 1435]
[Scan RS (ms): Min: 1.3, Avg: 1.4, Max: 1.5, Diff: 0.2, Sum: 11.1]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2]
[Object Copy (ms): Min: 226.5, Avg: 226.8, Max: 227.7, Diff: 1.2, Sum: 1814.0]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.3]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
[GC Worker Other (ms): Min: 0.1, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.6]
[GC Worker Total (ms): Min: 250.1, Avg: 250.2, Max: 250.2, Diff: 0.2, Sum: 2001.2]
[GC Worker End (ms): Min: 440420817.9, Avg: 440420817.9, Max: 440420817.9, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 1.8 ms]
[Other: 484.9 ms]
[Evacuation Failure: 463.0 ms]
[Choose CSet: 0.1 ms]
[Ref Proc: 4.0 ms]
[Ref Enq: 0.1 ms]
[Redirty Cards: 0.3 ms]
[Humongous Register: 6.9 ms]
[Humongous Reclaim: 5.5 ms]
[Free CSet: 4.1 ms]
[Eden: 20280.0M(20276.0M)->0.0B(20340.0M) Survivors: 204.0M->140.0M Heap: 24327.5M(26624.0M)->5841.5M(26624.0M)]
Heap after GC invocations=386 (full 2):
garbage-first heap total 27262976K, used 5981738K [0x0000000160800000, 0x0000000160c0d000, 0x00000007e0800000)
region size 4096K, 35 young (143360K), 35 survivors (143360K)
Metaspace used 217462K, capacity 254752K, committed 275072K, reserved 1275904K
class space used 24752K, capacity 38227K, committed 47744K, reserved 1048576K
}
[Times: user=4.17 sys=0.28, real=0.74 secs]
1.本次主要是G1垃圾收集器的Young GC
2.之前发生了两次fullGC,本次是第385次GC
3.total 27262976K, used 24909326K:垃圾回收开始前,整个堆的大小为27262MB,使用了24909MB。region size 4096K:堆的分区(Region)大小为4MB。5121 young (20975616K):年轻代有5121个Region,总共大约占用了20975MB。51 survivors (208896K):Survivor区有51个Region,占用约208MB。
4.[Evacuation Failure: 463.0 ms],意味着Survivor区或者老年代空间不足以存放所有从年轻代复制出来的对象。由于此失败,GC时间显著延长。
5.Heap After GC:total 27262976K, used 5981738K:垃圾回收后,堆的总大小不变(27262MB),但使用量大幅减少,降至5981MB。
6.最后的时间是 [Times: user=4.17 sys=0.28, real=0.74 secs],明显高于一般GC时间
这里需要注意一个我之前一直理解错的点:
GC的时候,容器的总内存使用量不会显著减少,但是内存的碎片化会减少,同时腾出更多的连续内存空间。因为GC本质上是内存优化算法,为了连续的内存。
当然除了Full GC且涉及堆压缩,会减少整体容器的内存,不过生产环境你不会希望有full GC的
参数调整
增加堆内存空间(避免Evacuation Failure)
增加年轻代大小(避免频繁yong gc)
调整晋升到老年代的阈值(-XX:MaxTenuringThreshold 默认16次)
调整xms与xmx(配置合理的初始和最大堆大小,我当时设置了一致的大小)
XMX与XMS配置详情
Xms与-Xmx一致的场景
适用场景
• 生产环境:生产环境通常需要应用运行的稳定性和性能。设置相同的Xms和Xmx可以避免JVM在运行过程中不断调整堆的大小,减少性能波动。
• 长生命周期的应用:如果应用在长时间运行过程中内存需求稳定,并且你预估应用需要使用较大的内存块,那么设置Xms等于Xmx会更合适。
• 避免频繁的堆扩展和收缩:当应用的内存需求变化较少,或是频繁调整堆大小会影响性能时,一致的Xms和Xmx可以避免堆动态扩展/收缩带来的CPU和GC开销。
优点
• 稳定的内存使用,无需JVM在运行时重新分配内存,减少性能波动。
• 避免应用在堆扩展或收缩过程中触发的Full GC。
示例场景
• 高并发服务:如电商、金融系统、在线服务等,需要长时间维持稳定的服务。
• 大数据处理:如批处理、大规模数据集处理系统,其内存需求较为稳定,且需要处理大块数据。
Xms与-Xmx不一致的场景
适用场景
• 开发和测试环境:开发和测试环境下,应用的内存需求可能会有波动,但你不需要为内存分配太多资源。因此,可以设置较小的Xms,以便JVM根据实际需求进行动态扩展。
• 内存需求有明显波动:如果应用的内存需求在不同负载情况下变化明显,如启动时内存占用较少,但在运行过程中占用逐步增加,则可以设置Xms较小,Xmx较大,以应对内存需求的动态变化。
• 节省内存资源:在内存资源有限的环境中(如容器化部署、云环境),将Xms设置较小,以便根据实际负载动态调整内存使用,避免浪费资源。
优点
• 灵活性:能够根据负载动态调整内存分配,特别是在初始阶段内存需求较少的应用中。
• 节省资源:在初始阶段,系统不会分配大量内存,从而节省系统资源。
示例场景
• 微服务:内存使用量随请求量变化较大,或者依赖外部服务的应用,其初始内存使用较少。
• 定时任务:不需要持续占用大量内存的应用,内存使用随着任务进行而增加。
调优结果
JAVA_OPTS=-Xms8g -Xmx16g -Xss1M -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExplicitGC -XX:+PrintGCDetails -XX:+UnlockExperimentalVMOptions -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -Xloggc:/cloudpivot/program/backEnd/webapi/logs/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M -XX:+UseCGroupMemoryLimitForHeap -XX:+HeapDumpOnOutOfMemoryError -XX:NewRatio=1
这里的处理由以下几点:
xms 从20g 到8g 减少内存占用,
xmx从20G到16G 降低webapi对于整体线程的最大占用内存
xms xmx的联合调整,降低了频繁yong gc的频次(GC日志中,yong gc特别频繁)
增加了 Xloggc: -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles -XX:GCLogFileSize 增加了GC日志的转播过程,可以记录服务器之前的gc日志(避免服务器重启后,之前GC日志丢失的情况)
-XX:NewRatio=1 新生代 老年代 比例调整是1:1,通过GC日志发现新生代占用大量空间,老年代则有资源浪费。因此调整成1:1,合理化分配内存资源
Arthas 分析
这个属于对于线上接口的RT排查,使用Arthas,可以直接分析线上的接口耗时。Arthas的优势在于,他的轻量化部署。
下载和启动
# 下载 Arthas
curl -O https://alibaba.github.io/arthas/arthas-boot.jar
# 启动 Arthas
java -jar arthas-boot.jar
链路耗时分析
trace -E 'com.authine.cloudpivot.engine.service.impl.bizrule.FlowRuntimeServiceImpl' 'startBusinessRuleFlow' --skipJDKMethod false '#cost>20000'
可以看到报警日志

SkyWalking分析
skywalking分析整体链路和耗时,在微服务和深链路调用时候,有奇效
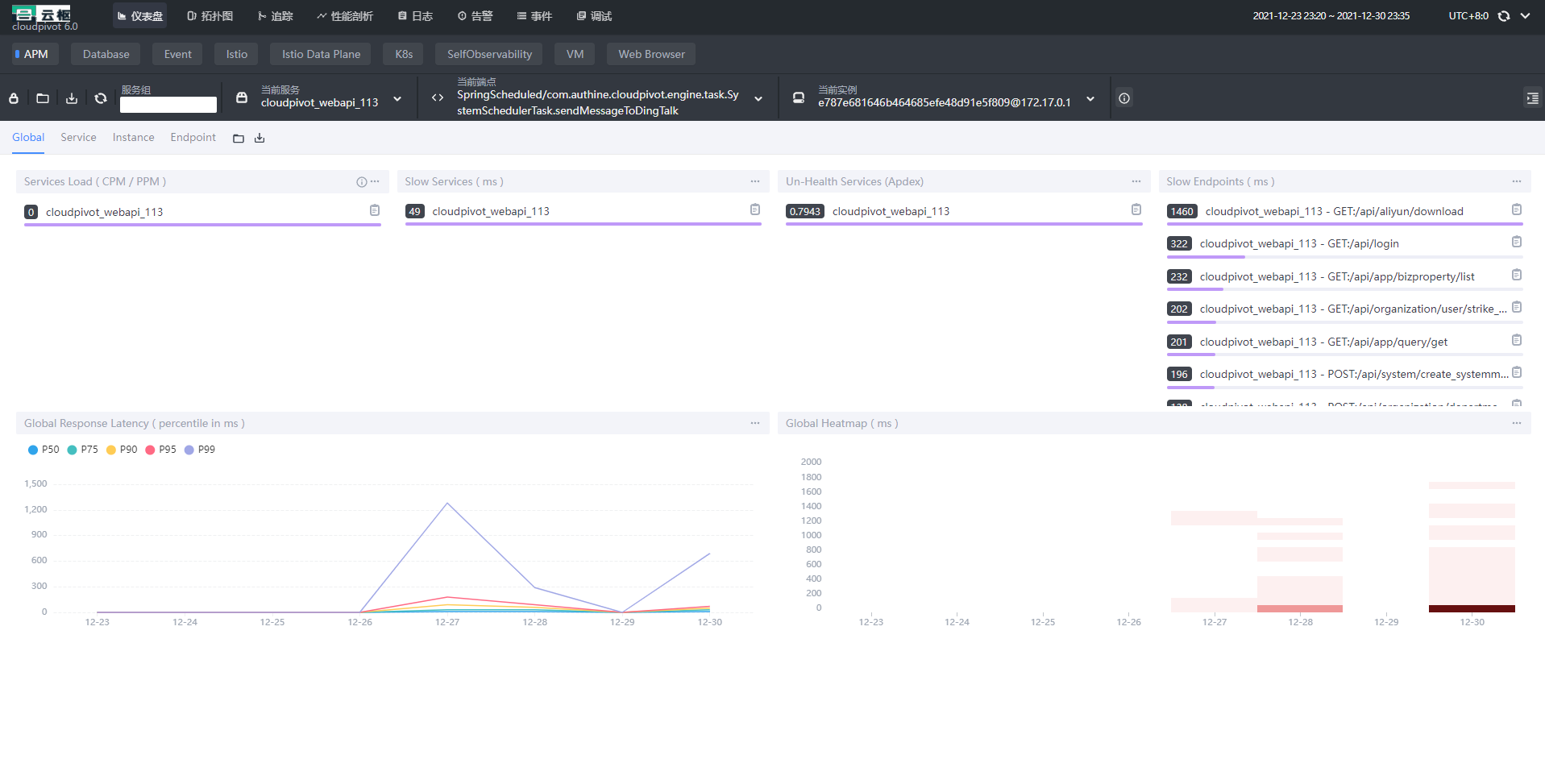
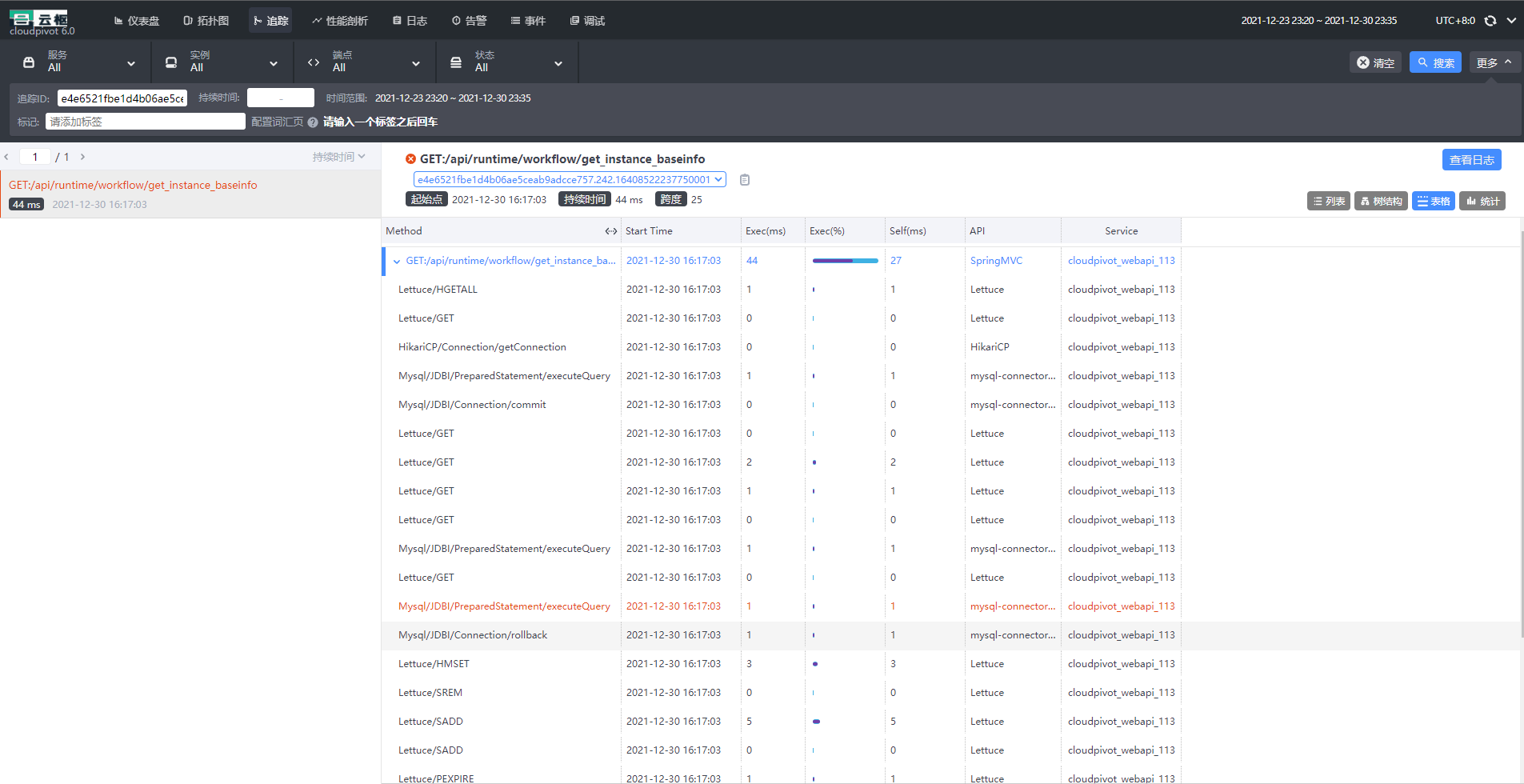
性能分析工具
| 工具名称 | 类型 | 主要特点 | 优点 | 缺点 |
|---|---|---|---|---|
| VisualVM | 免费 | 集成了多个 JDK 工具(如 JConsole、jstat、jinfo、jmap、jstack),提供图形界面 | - 免费且易于使用 - 支持多种监控和分析功能,如内存、CPU、线程、堆栈跟踪等 | - 功能相对有限,不如商业工具强大 - 性能监控可能会影响应用性能 |
| JProfiler | 商业 | 提供全面的性能分析功能,包括 CPU、内存、线程、锁、数据库、网络等 | - 功能强大,支持多种分析视图和报告 - 用户界面友好,易于上手 - 支持远程和本地分析 | - 需要付费 - 可能对应用性能有一定影响 |
| YourKit | 商业 | 提供详细的性能分析和内存分析功能,支持多种 JVM 版本和应用服务器 | - 功能强大,支持多平台 - 用户界面友好,易于使用 - 支持远程分析 | - 需要付费<br- 对应用性能有一定影响 |
| Java Mission Control (JMC) | 免费 | 集成在 JDK 中,提供详细的性能分析和监控功能 | - 免费且功能强大 - 支持详细的性能分析和监控 - 与 JDK 集成,使用方便 | - 可能对应用性能有一定影响 - 学习曲线较陡峭 |
| MAT (Memory Analyzer Tool) | 免费 | 专门用于内存分析,支持堆转储文件分析 | - 免费且功能强大 - 专注于内存分析,能够发现内存泄漏等问题 | - 主要关注内存分析,其他功能较弱 - 学习曲线较陡峭 |
| Dynatrace | 商业 | 提供全面的应用性能管理和监控功能,支持分布式系统 | - 功能强大,支持分布式系统 - 用户界面友好,易于使用 - 提供实时监控和报警 | - 需要付费<br- 对应用性能有一定影响<br- 部署和配置复杂 |
| AppDynamics | 商业 | 提供全面的应用性能管理和监控功能,支持多种技术栈 | - 功能强大,支持多种技术栈 - 用户界面友好,易于使用<br- 提供实时监控和报警 | - 需要付费<br- 对应用性能有一定影响<br- 部署和配置复杂 |
| New Relic | 商业 | 提供全面的应用性能管理和监控功能,支持多种技术栈 | - 功能强大,支持多种技术栈 - 用户界面友好,易于使用<br- 提供实时监控和报警 | - 需要付费<br- 对应用性能有一定影响<br- 部署和配置复杂 |
服务监控工具
| 工具名称 | 类型 | 主要特点 | 优点 | 缺点 |
|---|---|---|---|---|
| Zabbix | 开源 | 提供全面的网络监控功能,支持多种监控方式(如 SNMP、IPMI、JMX) | - 功能强大,支持多种监控方式 - 社区活跃,文档丰富 - 高度可定制,支持插件扩展 | - 配置复杂,学习曲线较陡峭 - 大规模部署时资源消耗较高 |
| Grafana | 开源 | 强大的数据可视化工具,支持多种数据源(如 Prometheus、InfluxDB、Elasticsearch) | - 用户界面友好,图表丰富 - 支持多种数据源,灵活性高 - 社区活跃,插件丰富 | - 主要专注于数据可视化,需要配合其他监控工具使用 - 配置和管理相对复杂 |
| Prometheus | 开源 | 高效的时间序列数据库,主要用于监控和警报 | - 性能优秀,支持高并发 - 生态系统丰富,支持多种数据源和警报规则 - 配置简单,易于上手 | - 主要适合微服务架构 - 数据存储和查询性能在大规模数据下可能受限 |
| Nagios | 开源 | 传统的网络和系统监控工具,支持多种监控插件 | - 功能强大,支持多种监控方式 - 社区活跃,插件丰富 - 高度可定制 | - 配置复杂,学习曲线较陡峭 - 用户界面相对较旧 |
| Datadog | 商业 | 提供全面的监控和分析功能,支持多种技术栈 | - 功能强大,支持多种监控方式 - 用户界面友好,易于使用 - 实时监控和警报功能强大 | - 需要付费<br- 对资源消耗较高<br- 部署和配置复杂 |
| New Relic | 商业 | 提供全面的应用性能管理和监控功能,支持多种技术栈 | - 功能强大,支持多种技术栈 - 用户界面友好,易于使用<br- 提供实时监控和警报 | - 需要付费<br- 对资源消耗较高<br- 部署和配置复杂 |
| SolarWinds | 商业 | 提供全面的网络和系统监控功能,支持多种技术栈 | - 功能强大,支持多种监控方式 - 用户界面友好,易于使用<br- 提供详细的报告和分析 | - 需要付费<br- 对资源消耗较高<br- 部署和配置复杂 |
| PRTG Network Monitor | 商业 | 提供全面的网络监控功能,支持多种监控方式 | - 功能强大,支持多种监控方式 - 用户界面友好,易于使用<br- 提供详细的报告和分析 | - 需要付费<br- 对资源消耗较高<br- 部署和配置复杂 |















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









