






 Redis是一种基于内存的NoSQL数据库,专为解决高并发读写性能瓶颈而设计。它支持多种数据结构、分布式部署和持久化,被广泛用于缓存、计数器、消息队列等领域,以提供低延迟、高并发的处理能力。
Redis是一种基于内存的NoSQL数据库,专为解决高并发读写性能瓶颈而设计。它支持多种数据结构、分布式部署和持久化,被广泛用于缓存、计数器、消息队列等领域,以提供低延迟、高并发的处理能力。
简单介绍
Redis是NoSQL数据库之一,最初由Salvatore Sanfilippo开发,是使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库。
背景
Web应用发展的初期,关系型数据库受到了较为广泛的关注和应用,原因是因为Web站点访问和并发不高、交互也较少。后来,随着访问量的提升,使用关系型数据库的Web站点在性能上都多少出现了一些瓶颈,而瓶颈的源头一般是在磁盘的I/O上。随着互联网技术的进一步发展,各种类型的应用层出不穷,这导致在当今云计算、大数据盛行的时代,对性能有了更多的需求。
需求
- 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度
- 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量
- 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理
- 庞大运营成本的考量:IT部门希望在硬件成本、软件成本和人力成本能够有大幅度地降低
Redis的出现主要是为了解决传统数据库在处理高并发读写时性能瓶颈的问题。Redis利用内存存储数据,并通过持久化机制将数据写入磁盘,从而实现高性能的数据读写操作。
Redis特性
- 基于内存运行,将数据存储在内存中,性能高效,读写速度非常快,适合处理高并发的场景
- 支持分布式,理论上可以无限扩展,支持集群模式,可以部署多个节点,提高系统的可用性和容错性。
- key-value存储系统
- 开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
- 支持主从复制,可以将数据从一个主节点复制到多个从节点,实现读写分离和负载均衡。
- 支持事务操作,可以将多个命令打包成一个事务进行执行,保证操作的原子性。
- 支持发布订阅模式,可以实现消息的发布和订阅,用于实时通信和事件驱动。
- 内置了复制和高可用功能,可以保证数据的可靠性和可用性。
Redis具备的特点
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型,支持多种数据结构,如字符串、列表、集合、哈希表等
- 操作具有原子性
- 提供持久化机制,将数据定期写入磁盘,确保数据不会因服务器重启而丢失。
- 高并发读写
- 使用Lua脚本进行批量操作,提高了操作的灵活性和效率。
使用Redis的公司
- github
- 微博
- Stack Overflow
- 阿里巴巴
- 百度
- 美团
- 搜狐
应用场景
缓存系统(“热点”数据:高频读、低频写)、计数器、消息队列系统、排行榜、社交网络和实时系统。
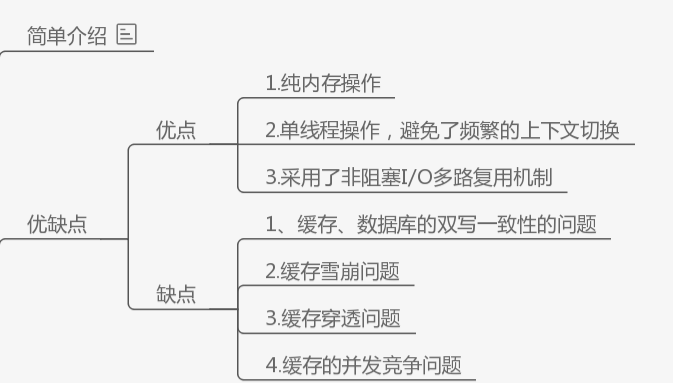
优点
-
纯内存操作:Redis将数据存储在内存中,读取和写入数据的操作都是在内存中完成的,这使得Redis具有极高的读写性能。原因是内存的读写速度远远快于磁盘,Redis能够快速响应客户端请求。
-
单线程操作:Redis采用单线程模型,所有的操作都在一个线程中执行,避免了多线程操作中频繁的上下文切换,减少了系统的开销。虽然单线程模型看起来会导致性能瓶颈,但由于Redis的主要操作都是在内存中进行,单线程反而可以更好地利用CPU的缓存,提高了整体性能。
-
非阻塞I/O多路复用机制:Redis采用了非阻塞I/O和多路复用机制,通过调用操作系统提供的select、poll、epoll等函数,实现在一个线程中同时监听多个文件描述符的I/O事件。这样可以在一个线程中处理多个客户端的请求,提高了系统的并发处理能力。非阻塞I/O也使得Redis能够在等待数据准备就绪的同时继续处理其他请求,避免了线程阻塞,提高了系统的响应速度和并发能力。
缺点
-
缓存、数据库的双写一致性问题:在使用缓存的系统中,通常会存在缓存与数据库之间的数据一致性问题。当数据发生变化时,需要保证缓存和数据库中的数据保持一致。解决方案包括:
- 读写时双写:即在更新数据库数据的同时,也更新缓存中的数据,确保数据一致性。
- 定时失效:设置缓存数据的过期时间,定期刷新缓存数据,防止缓存数据过期导致的一致性问题。
- 使用消息队列:通过消息队列异步更新缓存和数据库,保证数据的最终一致性。
-
缓存雪崩问题:缓存雪崩是指缓存中大量的数据同时失效或者缓存服务器宕机,导致大量请求直接访问数据库,造成数据库压力剧增,甚至引起数据库宕机。预防和解决缓存雪崩问题的方法包括:
- 设置不同的过期时间:避免大量缓存同时失效,可以设置不同的过期时间,分散缓存失效的时间点。
- 使用热点数据预热:提前加载热点数据到缓存中,减少缓存失效时的压力。
- 限流降级:在缓存失效时,通过限流或者降级策略,控制请求的并发量,避免对数据库造成过大压力。
-
缓存穿透问题:缓存穿透是指恶意请求访问缓存中不存在的数据,导致请求直接访问数据库,增加数据库负担。解决方法包括:
- 布隆过滤器:使用布隆过滤器拦截不存在的请求,减少对数据库的访问。
- 空值缓存:缓存空值或者设置短暂的过期时间,防止频繁请求。
- 缓存预热:提前加载热点数据到缓存中,避免缓存穿透。
-
缓存的并发竞争问题:在高并发环境下,多个请求同时访问缓存可能引发并发竞争问题,导致数据不一致或性能下降。解决方法包括:
- 加锁:使用锁机制保证对共享资源的互斥访问,避免并发竞争。
- 缓存更新策略:使用乐观锁或者版本号控制等策略,避免并发更新导致数据不一致。
- 分布式锁:在分布式环境下,使用分布式锁保证数据的一致性和并发安全。
数据类型及主要特性
Redis提供的数据类型主要分为5种自有类型和一种自定义类型,这5种自有类型包括:String类型、哈希类型、列表类型、集合类型和顺序集合类型。
String类型
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。
对每种数据类型,Redis都提供了丰富的操作命令,如:
- GET/MGET
- SET/SETEX/MSET/MSETNX
- INCR/DECR
- GETSET
- DEL
哈希类型
该类型是由field和关联的value组成的map。其中,field和value都是字符串类型的。
Hash的操作命令如下:
- HGET/HMGET/HGETALL
- HSET/HMSET/HSETNX
- HEXISTS/HLEN
- HKEYS/HDEL
- HVALS
列表类型
该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。
List的操作命令如下:
- LPUSH/LPUSHX/LPOP/RPUSH/RPUSHX/RPOP/LINSERT/LSET
- LINDEX/LRANGE
- LLEN/LTRIM
集合类型
Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。
Set类型的底层是通过哈希表实现的,其操作命令为:
- SADD/SPOP/SMOVE/SCARD
- SINTER/SDIFF/SDIFFSTORE/SUNION
Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。
顺序集合类型
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。
ZSet命令:
- ZADD/ZPOP/ZMOVE/ZCARD/ZCOUNT
- ZINTER/ZDIFF/ZDIFFSTORE/ZUNION
数据结构
Redis的数据结构如下图所示:
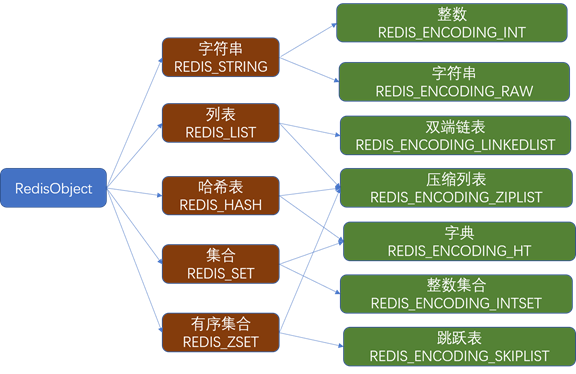
压缩列表
是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现
整数集合
是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现
参考:
Redis是什么?看这一篇就够了 - 葡萄城技术团队 - 博客园 (cnblogs.com)
https://www.cnblogs.com/powertoolsteam/p/redis.html















 5680
5680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









