







by Doug Lea, with help from members of the JMM mailing list.
The JSR-133 Cookbook for Compiler Writers
重排序(Reorderings)
对于编译器编写者而言,JMM主要包括禁止对某些访问字段(其中字段包含数组元素)和monitors (locks)的指令进行重新排序的规则。
Volatiles and Monitors
volatiles和monitors的主要JMM规则可以被视为一个矩阵,其中的单元格告诉你不能对与特定字节码序列相关的指令进行重新排序。该表本身不是JMM规范;他仅仅是为编译器和运行时系统提供查看最终结果的一个表格。
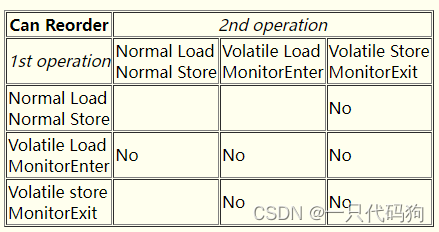
- Normal Load是载入非volatile修饰的普通属性、静态属性和数组。
- Normal Store是存储非volatile修饰的普通属性、静态属性和数组。
- Volatile Load是可以被多个线程载入的用volatile修饰的普通属性、静态属性。
- Volatile Store是可以被多个线程存储的用volatile修饰的普通属性、静态属性。
- MonitorEnter(包括进入同步方法)是可以被多个线程访问的锁对象。
- MonitorExit(包括退出同步方法)是可以被多个线程访问的锁对象。
Normal Load和Normal Store是一样的、Volatile Load和MonitorEnter是一样的、Volatile Store和MonitorExit是一样的,为了方便把他们折叠在一起。
在表中展示的第一个和第二个操作之间可能存在任意数量的其他操作。所以,例如:单元格【Normal Store, Volatile Store】中的‘NO’表示 一个非volatile修饰的存储不能被重排序在任何后续的被volatile修饰的存储之后。
空白的单元格表示允许指令重排。
JMM 规范允许消除可避免的依赖关系的转换,进而允许重新排序。
下面是一个简单的示例,展示多线程调用可以保证x的值一定为42,也就是禁止指令重排的说明。
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42; // Normal store
v = true; // volatile store
// 1st Normal store 2st volatile store,cannot reordering
}
public void reader() {
if (v == true) { // volatile load
//uses x - guaranteed to see 42.
}
}
}
Final Fields
Loads and Stores of final fields act as “normal” accesses with respect to locks and volatiles, but impose two additional reordering rules:(我没有明白这段话,以下是我勉强翻译的,如果觉得有问题可与我联系进行修改。)
Load和Store是载入和存储,final属性得载入和存储就locks和volatile而言是普通访问,但是强制了两个附加的重排序规则:
1.被final修饰的属性执行store操作(在构造函数内部),以及如果该字段是一个引用类型,则任何该final引用可以引用的对象的写入操作,都不能与将持有该字段的对象的引用存储到其他线程可访问的变量中(在构造函数外部)的操作进行重排序。
简单来说就是:构造函数中对final字段的写入操作与随后对这些字段的读取操作之间存在happens-before关系。
class Example {
final int x;
Object y;
public Example() {
x = 1; // final类型的store 也是normal store
y = new Object(); // narmal Store
}
public void publish() {
ExampleHolder.INSTANCE.set(this);
}
}
class ExampleHolder {
static Example INSTANCE;
static void set(Example e) {
INSTANCE = e;
}
}
在这个例子中,如果将 INSTANCE 的写入操作重排序到 x 和 y 的写入操作之前,那么在 publish() 方法被调用之前,其他线程可能会看到 INSTANCE 引用的对象的 x 和 y 字段为默认值,而不是构造函数中设置的值。这可能会导致程序出现不一致的行为。因此,Java 内存模型禁止这种重排序行为。
在构造函数内部,不能将final字段的存储移动到构造函数外部,因为这可能会使对象对其他线程可见。
2.对final属性字段的初始加载(即线程第一次遇到的加载)不能与对包含final属性的对象的引用的初始加载重新排序。
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x;
int j = f.y;
}
}
}
在这个例子中,writer方法创建了一个FinalFieldExample对象,并将其引用赋值给静态字段f。reader方法检查f是否为null,如果不为null,则读取该对象的两个字段。
根据Java内存模型,对final字段的初始加载(即线程第一次遇到的加载)不能与对包含final字段的对象的引用的初始加载重新排序。这意味着,如果一个线程在执行reader方法时看到了对静态字段f的写入,则它也必须看到对final字段x的写入。因此,变量i的值必须为3。
但是,这条规则并不适用于非final字段。因此,变量j的值可能是4,也可能是0(默认值)。
总结:
进一步解释Java内存模型中禁止指令重排序的规则对final字段的影响。它指出,如果Java程序员想要可靠地使用final字段,那么在读取一个对象的共享引用时,这个读取操作本身必须是同步的(synchronized)、具有可见性的(volatile),或者是final字段本身的读取操作,或者是这些操作的衍生操作。这样,才能确保构造函数中的初始化存储和后续在构造函数之外的使用之间的正确顺序。
具体来说,这意味着如果一个final字段是在一个构造函数中初始化的,那么在访问这个final字段之前,需要确保这个对象的引用被正确地发布了,而不是被其他线程在构造函数完成之前就看到了。如果这个引用的读取操作没有被同步、没有可见性,或者不是final字段本身的读取操作,那么就可能会出现初始化存储被重排序的情况,从而导致程序出现错误或异常行为。
因此,为了确保final字段的可靠性,程序员需要遵循一定的规则,如使用同步、volatile或final来保证引用的可见性,或者使用类似于Happens-Before规则的衍生操作来保证初始化存储和后续使用之间的正确顺序。
内存屏障(Memory Barrires)
编译器和处理器这两者必须遵守重排序规则。由于所有的处理器都保证了 “as-if-sequential” 一致性,因此不需要做特别的努力来确保正确的顺序。但是在多处理器上,为了保证指令重排序规则的遵循,通常要求发送屏障指令(barrier instructions)。即便编译器优化了字段的访问(例如:一个被load的值没有被use),仍然需要上次屏障指令,就好像访问仍然存在一样。
“As-if-sequential” 是Java内存模型(JMM)中的一个概念,它描述了Java程序在多线程环境下的执行行为。
在Java程序中,多个线程可能同时访问共享的内存,这种并发访问可能导致一些问题,例如数据竞争(data race)、死锁和活锁等。为了解决这些问题,Java引入了JMM来规范Java程序在多线程环境中的行为。
“As-if-sequential” 是JMM中的一个原则,它指出,Java程序在多线程环境中的执行结果,应该与在单线程环境中的执行结果相同。也就是说,Java程序在多线程环境中的执行行为应该是"as-if-sequential"的,也就是看起来好像程序是单线程执行的一样。
具体来说,这个原则可以被理解为,JMM允许Java编译器和运行时系统对程序进行指令重排、内存重排等优化,只要这些重排不会影响程序在单线程环境下的执行结果。这种优化可以提高程序的性能,但必须保证程序在多线程环境中的正确性。
“As-if-sequential” 是JMM中的一个重要概念,它为Java程序在多线程环境中的正确性和性能提供了保证。
屏障指令是确保多处理器环境下指令重排序规则遵守的一种重要手段。它们控制CPU与其缓存、写缓冲区以及等待加载或者猜测执行指令的缓冲区之间的交互。这些效应可能会导致缓存、主内存和其他处理器之间的进一步交互,因此需要屏障指令来确保正确性。
需要注意的是,内存屏障与内存模型中描述的"acquire" 和 “release” 等高级概念只有间接的关系,而且内存屏障本身并不是 “同步屏障”。此外,内存屏障也与一些垃圾收集器中使用的 “写屏障” 没有关系。内存屏障指令直接控制CPU与其缓存、写缓冲区和等待加载的指令之间的交互,以确保指令重排序规则的遵循。
Java内存模型并不要求在处理器之间进行任何特定形式的通信,只要存储最终在所有处理器上都可见,并且加载在可见时检索到即可。这是因为屏障指令可以确保在多处理器环境下,指令重排序规则得到遵循,从而保证了正确性。
屏障类别
几乎所有的处理器都至少支持粗粒度屏障指令,通常被称为栅栏(Fence),它保证在屏障之前发起的所有stores和loads操作都严格地在屏障之后发起的任何loads和stores操作之前。这通常是任何给定处理器上最耗时的指令之一,其开销通常几乎和原子指令一样大,甚至更大。大多数处理器还支持更细粒度的屏障指令,以便更精细地控制内存访问的顺序。
内存屏障指令有一个需要适应的特性,那就是它们应用在内存访问之间。尽管一些处理器的内存屏障指令可能会有不同的名称,但选择使用的正确/最佳屏障取决于它要分隔的访问类型。以下是一种常见的内存屏障指令类型分类,它与现有处理器上的特定指令(有时是no-ops/空操作)相对应:
-
LoadLoad Barriers
The sequence: Load1; LoadLoad; Load2
在LoadLoad屏障指令的作用下,Load1的数据会先于Load2及其后续的所有加载指令被加载。通常,只有在进行预测加载和/或乱序处理的处理器上才需要使用显式的LoadLoad屏障指令,因为这些处理器上等待的加载指令可能会绕过等待的存储指令。而在保证始终保留加载顺序的处理器上,这些屏障指令实际上是空操作,因为在这些处理器上,加载指令本身就已经保证按顺序执行。
-
StoreStore Barriers
The sequence: Store1; StoreStore; Store2
StoreStore屏障指令确保Store1的数据在Store2及其后续的所有存储指令的数据之前对其他处理器可见(即被刷新到内存中)。通常情况下,只有在处理器不能保证从写缓冲区和/或缓存到其他处理器或主内存的刷新顺序严格一致时,才需要使用StoreStore屏障指令。这些屏障指令的作用是确保存储指令的顺序关系得到正确的维护,从而避免由于存储指令顺序错误而引发的数据不一致问题。
-
LoadStore Barriers
The sequence: Load1; LoadStore; Store2
LoadStore屏障指令确保Load1的数据在Store2及其后续的所有存储指令的数据被刷新之前被加载。通常情况下,只有在具有乱序执行的处理器中,等待的存储指令可以绕过加载指令时,才需要使用LoadStore屏障指令。这些屏障指令的作用是确保存储指令和加载指令之间的顺序关系得到正确的维护,从而避免由于存储指令和加载指令之间的顺序错误而引发的数据不一致问题。
-
StoreLoad Barriers
The sequence: Store1; StoreLoad; Load2
StoreLoad屏障指令确保Store1的数据在Load2及其后续的所有加载指令加载之前被刷新到主内存中,并且可以防止后续的加载指令错误地使用Store1的数据值,而不是由其他处理器执行的最新存储到相同位置的数据值。因此,在下面所讨论的处理器上,StoreLoad屏障指令仅在需要分隔与屏障之前相同位置的存储和后续加载指令时才是必需的。StoreLoad屏障在几乎所有最近的多处理器系统中都是必需的,而且通常是最昂贵的。其中一部分原因是它们必须禁用绕过缓存以满足从写缓冲区中加载的加载指令的机制。这可能需要让缓冲区完全刷新,或者采取其他可能的阻塞措施。
在下面所讨论的所有处理器上,发现执行StoreLoad的指令也会获得其他三个屏障的效果,因此StoreLoad可以作为一种通用的(但通常是昂贵的)屏障指令来使用。(这是一个经验事实,而不是必然的。)但反过来并不成立,通常不能通过发布其他屏障指令的任意组合来实现StoreLoad的效果。
下表展示的就是这些屏障指令对应在JSR-133中的排序规则

还有一个特殊的针对final属性的规则,需要加上StoreStore屏障
x.finalField = v; StoreStore; sharedRef = x;
下面是例子展示:

数据依赖和屏障之间的关系
对于某些处理器,LoadLoad和LoadStore屏障的需求与它们对依赖指令的排序保证相互作用。在某些(大多数)处理器中,一个加载或者存储操作如果依赖于前一个加载操作的值,则处理器会在不需要显示屏障的情况下对它们进行排序。
这种情况通常出现在两种情况下:间接引用(indirection)和控制(control)。
间接引用指的是通过一个对象引用来访问该对象的字段,例如Load x; Load x.field。
控制指的是根据一个加载操作的结果来决定是否执行另一个加载或存储操作,例如Load x; if (predicate(x)) Load or Store y;。
不遵循间接引用排序的处理器需要在通过共享引用获取引用时为final字段访问添加屏障,例如x = sharedRef; … ; LoadLoad; i = x.finalField;。
相反,正如下文所述,遵循数据依赖性的处理器提供了几种优化掉不必要的LoadLoad和LoadStore屏障指令的机会。(但是,依赖性并不能自动消除任何处理器上对StoreLoad屏障的需求。)
原子指令与屏障之间的相互作用
不同处理器上所需的屏障类型与MonitorEnter和MonitorExit的实现进一步相互作用。锁定和/或解锁通常需要使用原子条件更新操作CompareAndSwap(CAS)或LoadLinked/StoreConditional(LL/SC),它们具有执行volatile load后跟随volatile store的语义。虽然CAS或LL/SC最低限度地满足,但某些处理器还支持其他原子指令(例如,无条件交换),有时可以代替或与原子条件更新一起使用。
所有处理器都拥有原子操作指令,用于保护被读取/更新的位置免受先读后写问题的影响。这意味着当多个线程或进程访问相同的内存位置时,原子操作将确保每个线程/进程以不可分割的方式完成其操作,以便其他线程/进程只能在原子操作完成后访问该位置。
然而,处理器在原子指令提供的屏障属性方面存在差异。一些处理器的原子指令还会内部再执行MonitorEnter/Exit所需要的屏障,MonitorEnter/Exit是多线程编程中用于保护共享资源免受同时访问的同步语句。在这些处理器上,原子操作提供了更全面的屏障属性。
而在其他处理器上,一些或所有这些屏障必须明确发出,这意味着程序员需要显示添加额外的同步指令,以确保多线程程序的正确行为。这意味着这些处理器上的原子操作可能具有更有限的屏障属性。
Volatile和Monitor必须分开以解开这些效应,从而得到:
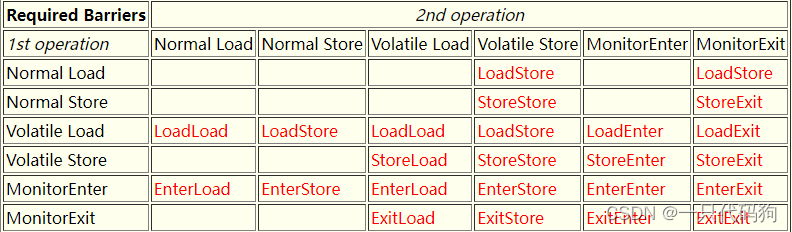
另外,特殊的final字段规则要求在以下情况下使用StoreStore屏障:
x.finalField = v; StoreStore; sharedRef = x;
在实现MonitorEnter和MonitorExit时,通常会使用原子操作,其中"Enter"相当于"Load"(读取操作),“Exit"相当于"Store”(写入操作)。但是,这种使用方式可能会被特定处理器上的原子操作所覆盖或替代。因此,在不同的处理器上实现MonitorEnter和MonitorExit时,可能需要考虑特定处理器的原子操作特性和行为。
-
EnterLoad在进入执行load操作的任何同步块/方法时需要。它与LoadLoad相同,除非在MonitorEnter中使用了原子指令并且本身提供了至少具有LoadLoad属性的屏障,此时它是一个无操作。
-
StoreExit在退出执行store操作的任何同步块/方法时需要。它与StoreStore相同,除非在MonitorExit中使用了原子指令并且本身提供了至少具有StoreStore属性的屏障,此时它是一个无操作。
-
ExitEnter与StoreLoad相同,除非在MonitorExit和/或MonitorEnter中使用了原子指令,并且其中至少一个提供了至少具有StoreLoad属性的屏障,此时它是一个无操作。
下面是一个覆盖基本的屏障类型的例子:

Java SE 5(JDK1.5)中引入了JSR-166,即Java并发工具包,其中包含了一些原子条件更新操作的接口。编译器需要生成与这些接口相关的代码,使用上述表格的一种变体,将MonitorEnter和MonitorExit合并起来,因为在语义上和实践中,这些Java级别的原子更新操作就像是被锁包围的一样。
具体来说,Java并发工具包中提供了一些原子操作类,例如AtomicInteger、AtomicLong、AtomicReference等,这些类提供了一些原子条件更新操作,如compareAndSet、getAndAdd等。这些操作可以用于在多线程环境下更新共享变量,而不需要使用synchronized关键字或volatile关键字。
在实现这些原子操作时,编译器需要生成一些与锁类似的代码,以确保多线程环境下的内存读写操作顺序和可见性符合预期,避免出现数据竞争和线程安全问题。因此,从语义上和实践上看,这些Java级别的原子更新操作就像是被锁包围的一样,即它们具有类似于MonitorEnter和MonitorExit的行为。
屏障移除(Removing Barriers)
通过去除冗余的屏障来优化volatile变量的性能。首先,文章提到了可以通过移除冗余的屏障来优化性能。可以通过下列方式去除冗余的屏障:
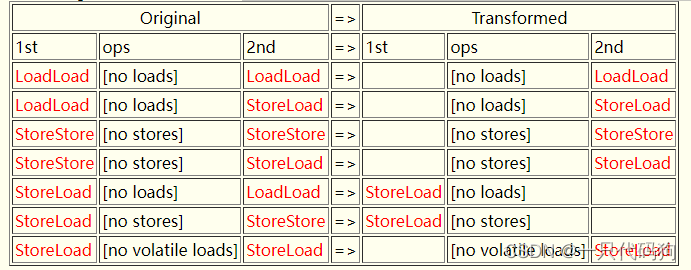
- LoadLoad屏障之后没有加载操作:如果一个LoadLoad屏障之后没有任何加载操作,那么这个屏障可以被删除。因为LoadLoad屏障的作用是保证在该屏障之前的所有加载操作对该屏障之后的所有加载操作可见,如果没有加载操作,那么这个屏障就没有意义了。
- LoadLoad屏障之后只有一个StoreLoad操作:如果一个LoadLoad屏障之后只有一个StoreLoad操作,那么这个屏障可以被删除。因为StoreLoad操作包含了LoadLoad的语义,即它既保证对该屏障之前的所有加载操作可见,又保证对该屏障之后的所有存储操作可见。
- StoreStore屏障之后没有存储操作:如果一个StoreStore屏障之后没有任何存储操作,那么这个屏障可以被删除。因为StoreStore屏障的作用是保证在该屏障之前的所有存储操作对该屏障之后的所有存储操作可见,如果没有存储操作,那么这个屏障就没有意义了。
- StoreStore屏障之后只有一个StoreLoad操作:如果一个StoreStore屏障之后只有一个StoreLoad操作,那么这个屏障可以被删除。因为StoreLoad操作包含了StoreStore的语义,即它既保证对该屏障之前的所有存储操作可见,又保证对该屏障之后的所有加载操作可见。
- StoreLoad屏障之后没有加载操作:如果一个StoreLoad屏障之后没有任何加载操作,那么这个屏障可以被删除。因为StoreLoad屏障的作用是保证对该屏障之前的所有存储操作可见,并且对该屏障之后的所有加载操作可见,如果没有加载操作,那么这个屏障就没有意义了。
- StoreLoad屏障之后没有volatile加载操作:如果一个StoreLoad屏障之后没有任何volatile加载操作,那么这个屏障可以被删除。因为StoreLoad屏障的作用是保证对该屏障之前的所有存储操作可见,并且对该屏障之后的所有volatile加载操作可见,如果没有volatile加载操作,那么这个屏障就没有意义了。
下面是每种情况的代码示例:
- 如果一个LoadLoad屏障之后没有加载操作,则可以删除这个屏障。
int x = 0; // 非volatile变量
volatile int y = 0;
// 冗余的LoadLoad屏障
int a = y; // 加载y,会生成一个LoadLoad屏障,但后面没有加载操作
x++; // 后面是一个非volatile的操作,不需要LoadLoad屏障
// 去除冗余的LoadLoad屏障
x++; // 先执行非volatile操作
int b = y; // 再加载y,不需要LoadLoad屏障
- 如果一个LoadLoad屏障之后只有一个StoreLoad操作,则可以删除这个屏障。
volatile int x = 0;
volatile int y = 0;
// 冗余的LoadLoad屏障
int a = x; // 加载x,会生成一个LoadLoad屏障
y++; // 后面是一个StoreLoad操作,包含了LoadLoad的语义
// 去除冗余的LoadLoad屏障
y++; // 先执行StoreLoad操作,包含了LoadLoad的语义
int b = x; // 再加载x,不需要LoadLoad屏障
- 如果一个StoreStore屏障之后没有存储操作,则可以删除这个屏障。
volatile int x = 0;
// 冗余的StoreStore屏障
x++; // 存储x,会生成一个StoreStore屏障
int a = x; // 加载x,StoreStore屏障后没有存储操作
// 去除冗余的StoreStore屏障
int b = x; // 先加载x,不需要StoreStore屏障
x++; // 再存储x
- 如果一个StoreStore屏障之后只有一个StoreLoad操作,则可以删除这个屏障。
volatile int x = 0;
volatile int y = 0;
// 冗余的StoreStore屏障
x++; // 存储x,会生成一个StoreStore屏障
int a = y; // 加载y,StoreStore屏障后只有一个StoreLoad操作
// 去除冗余的StoreStore屏障
int b = y; // 先加载y,包含了StoreStore的语义
x++; // 再存储x,不需要StoreStore屏障
- 如果一个StoreLoad屏障之后没有加载操作,则可以删除这个屏障。
volatile int x = 0;
// 冗余的StoreLoad屏障
x++; // 存储x,会生成一个StoreLoad屏障
int a = x; // 加载x,StoreLoad屏障后没有加载操作
// 去除冗余的StoreLoad屏障
int b = x; // 先加载x,不需要StoreLoad屏障
x++; // 再存储x
- 如果一个StoreLoad屏障之后没有volatile加载操作,则可以删除这个屏障。
volatile int x = 0;
int y = 0; // 非volatile变量
// 冗余的StoreLoad屏障
x++; // 存储x,会生成一个StoreLoad屏障
int a = y; // 加载y,StoreLoad屏障后没有volatile加载操作
// 去除冗余的StoreLoad屏障
int b = y; // 先加载y,不需要StoreLoad屏障
x++; // 再存储x
此外,也可以通过重新排列代码(在允许的约束条件下)来进一步优化性能,使得不需要LoadLoad和LoadStore屏障的情况更多,因为这些屏障只有当处理器需要它们时才需要。此外,可以移动屏障发出的位置来改善调度,只要它们仍然在需要的时间间隔内发出即可。
另外,可以移除一些不必要的屏障,例如那些只可见于单个线程的volatile变量,或者可以证明一个或多个线程只存储或只加载某些字段的情况。这通常需要进行较为复杂的分析。
总之,就是提供了一些优化volatile变量性能的方法,其中包括去除冗余的屏障、重新排列代码、移动屏障的发出位置等。这些方法需要进行一定的分析和实验,以找到最佳的优化策略。
JSR解决的其他问题
JSR-133还解决了一些其他问题,这些问题在更专业的情况下可能需要屏障:
-
Thread.start() 方法需要屏障来确保启动的线程在调用点看到调用者可见的所有存储。相反,Thread.join() 方法需要屏障来确保调用者看到终止线程的所有存储。这些通常是由这些构造的实现中所涉及的同步机制生成的。
-
静态 final 初始化需要 StoreStore 屏障,这通常包含在遵守 Java 类加载和初始化规则所需的机制中。
-
确保默认的零/空初始化字段值通常需要屏障、同步和/或垃圾收集器内的低级缓存控制。
-
JVM-专用程序可以在构造函数或静态初始化程序之外“神奇地”设置 System.in、System.out 和 System.err,这些程序是 JMM 最终字段规则的特殊遗留例外。
-
类似地,内部 JVM 反序列化代码设置最终字段通常需要一个 StoreStore 屏障。
-
最终化支持可能需要屏障(在垃圾收集器内部)以确保 Object.finalize 代码在对象变为不可引用之前看到所有字段的所有存储。这通常是通过在引用队列中添加和删除引用时使用的同步来确保的。
-
调用和返回 JNI 函数可能需要屏障,尽管这似乎是一个实现质量问题。
-
大多数处理器都有其他同步指令,主要用于与 IO 和操作系统操作一起使用。这些指令不会直接影响 JMM 问题,但可能涉及 IO、类加载和动态代码生成。
或垃圾收集器内的低级缓存控制。 -
JVM-专用程序可以在构造函数或静态初始化程序之外“神奇地”设置 System.in、System.out 和 System.err,这些程序是 JMM 最终字段规则的特殊遗留例外。
-
类似地,内部 JVM 反序列化代码设置最终字段通常需要一个 StoreStore 屏障。
-
最终化支持可能需要屏障(在垃圾收集器内部)以确保 Object.finalize 代码在对象变为不可引用之前看到所有字段的所有存储。这通常是通过在引用队列中添加和删除引用时使用的同步来确保的。
-
调用和返回 JNI 函数可能需要屏障,尽管这似乎是一个实现质量问题。
-
大多数处理器都有其他同步指令,主要用于与 IO 和操作系统操作一起使用。这些指令不会直接影响 JMM 问题,但可能涉及 IO、类加载和动态代码生成。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











