






前言
网上关于ComplexKeysShardingAlgorithm的基本使用很多,但是基本上都是关于基本的使用,以及插入。但是在插入之后,我们应该怎么让查询时让查询落入相应的分库分表之后的数据库和表,不至于全量查询或者未查询到对应的表,这个时候就需要通过配置和相关算法,来实现通过参数落入对应数据库和表。由于ComplexKeysShardingAlgorithm算法支持between and,>,<,=,in 等,我们将in和=可以作为一个方式来处理,in可以看做多个or的=,示例:(id=1 or id=2);其他的可以用范围来判断处理:通过参数来判断参数是否落于配置的区间,如果落于相关区间,则可以获取相关的配置信息。
数据源,表配置信息
在该demo中,我们将数据源和表的配置放置在resource里面,当然也可以写成一个配置项,存在项目配置表或者字典表中
数据源配置:
[
{
"shardingRules": [
{
"range": [
{
"columnName": "company_id",
"lowerBound": 1,
"upperBound": 500
},
{
"columnName": "position_id",
"lowerBound": 1,
"upperBound": 500
}
],
"targetDatasource": "ftdb0",
"order": 30
},
{
"range": [
{
"columnName": "company_id",
"lowerBound": 501,
"upperBound": 2000
},
{
"columnName": "position_id",
"lowerBound": 501,
"upperBound": 2000
}
],
"targetDatasource": "ftdb1",
"order": 30
}
],
"sharingSource": "b_order",
"order": "0"
},
{
"shardingRules": [
{
"range": [
{
"columnName": "delivery_time",
"lowerBound": 20230101,
"upperBound": 20231231
}
],
"targetDatasource": "ftdb0"
},
{
"range": [
{
"columnName": "delivery_time",
"lowerBound": 20240101,
"upperBound": 20241231
}
],
"targetDatasource": "ftdb1"
}
],
"sharingSource": "c_order",
"order": "1"
}
]
在示例中,我们配置了2个表的数据源信息,b_order根据Id配置,c_order根据时间配置在不同的库中
表分片配置:
[
{
"shardingRules": [
{
"range": [
{
"columnName": "company_id",
"lowerBound": 1,
"upperBound": 500
},
{
"columnName": "position_id",
"lowerBound": 1,
"upperBound": 500
}
],
"targetDatasource": "b_order0"
},
{
"range": [
{
"columnName": "company_id",
"lowerBound": 501,
"upperBound": 1000
},
{
"columnName": "position_id",
"lowerBound": 501,
"upperBound": 1000
}
],
"targetDatasource": "b_order1"
},
{
"range": [
{
"columnName": "company_id",
"lowerBound": 1001,
"upperBound": 2000
},
{
"columnName": "position_id",
"lowerBound": 1001,
"upperBound": 2000
}
],
"targetDatasource": "b_order2"
}
],
"sharingSource": "b_order",
"index": "0"
},
{
"shardingRules": [
{
"range": [
{
"columnName": "delivery_time",
"lowerBound": 20230101,
"upperBound": 20231231
}
],
"targetDatasource": "c_order2023"
},
{
"range": [
{
"columnName": "delivery_time",
"lowerBound": 20240101,
"upperBound": 20241231
}
],
"targetDatasource": "c_order2024"
}
],
"sharingSource": "c_order",
"index": "0"
}
]
表配置注意事项:进行分片的分片列(如该demo的columnName)需要与数据库的列名一致
该配置中,也模拟了2个配置,b_order根据Id配置,c_order根据时间配置在不同的表中
配置位置示例:
配置的实体类
import lombok.Data;
import org.jetbrains.annotations.NotNull;
import java.util.List;
/**
* 数据源配置参数
*/
@Data
public class DataRuleConfig implements Comparable<DataRuleConfig>{
private List<ShardingRangeConfig> shardingRules;
private String sharingSource;
private int index;
@Override
public int compareTo(@NotNull DataRuleConfig o) {
return this.index-o.index;
}
}
import lombok.Data;
/**
* 分表查询参数
*/
@Data
public class ShardingParam {
/**
* 表列名
*/
private String columnName;
private ShardingParamValue<? extends Comparable< ? >> shardingParamValue;
/**
* 是否为=查询
*/
private boolean isSingleValue=true;
}
import com.google.common.collect.BoundType;
import lombok.Data;
import java.util.List;
/**
* 分库分表具体信息
*
* @author aaa
*/
@Data
public class ShardingParamValue<T extends Comparable<? super T>> {
private List<T> listValue;
private T singleValue;
private boolean upperBound;
private boolean lowerBound;
private T upperEndPoint;
private T lowerEndPoint;
// 上区间的开闭类型 CLOSE:闭区间 OPEN开区间 比如(1,100]
private BoundType upperBoundType;
// 下区间开闭类型 CLOSE:闭区间 OPEN开区间 比如[1,100)
private BoundType lowerBoundType;
}
import lombok.Data;
/**
* 分片配置信息
*/
@Data
public class ShardingRange {
/**
* 分片列名
*/
private String columnName;
/**
* 下区间
*/
private Long lowerBound;
/**
* 上区间
*/
private Long upperBound;
}
import lombok.Data;
import org.jetbrains.annotations.NotNull;
import java.util.List;
/**
* 区间分片配置
*/
@Data
public class ShardingRangeConfig{
/**
* 区间信息
*/
private List<ShardingRange> range;
/**
* 实际数据源,表,数据库
*/
private String targetDatasource;
}
读取配置信息类
import cn.hutool.core.date.LocalDateTimeUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONUtil;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.DataRuleConfig;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingRangeConfig;
import com.test.ft.common.exception.CommonException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.springframework.util.ResourceUtils;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
import java.util.List;
import java.util.Objects;
import java.util.concurrent.ConcurrentHashMap;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
@SuppressWarnings("all")
@Slf4j
public class ShardingConfigUtil {
private static final String DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
private static final Pattern LONG_TIMESTAMP_PATTERN = Pattern.compile("^[0-9]{10,13}$");
private static final String format = "yyyyMMdd";
private static final ConcurrentHashMap<String, List<ShardingRangeConfig>> MAP = new ConcurrentHashMap<>();
/**
* 定义一个非常小的常量EPSILON,用于比较浮点数是否相等。
* 由于浮点数计算可能存在微小的误差,直接比较两个浮点数是否相等可能会因为这个误差而导致错误的结果。
* 因此,我们引入EPSILON来表示浮点数计算可以接受的误差范围,在比较两个浮点数是否“相等”时,
* 实际上是比较它们的差值是否小于EPSILON。
* 这里的值1e-16是一个经验值,根据实际应用场景的不同,可能需要调整这个值的大小。
* 这个值表示浮点数计算可以接受的误差范围,即两个浮点数之间的差值小于1e-16时,可以认为它们相等。可以满足小数点后10个0的误差范围。
*/
private static final double EPSILON = 1e-16;
private static <T> List<T> getConfigJsonFromFile(Class<T> clazz, String jsonFileName) throws IOException {
File file = ResourceUtils.getFile("classpath:shardingconfig/" + jsonFileName);
JSONArray jsonArray = JSONUtil.readJSONArray(file, StandardCharsets.UTF_8);
List<T> obj = JSONUtil.toList(jsonArray, clazz);
return obj;
}
/**
* 获取分片配置信息。
* 此方法根据表名和标志位(表/数据源)从缓存或配置文件中读取分片范围配置。
* 如果缓存中存在对应配置,则直接返回缓存结果;否则,从配置文件中读取、处理并缓存配置后返回。
*
* @param isTable 表示配置类型,true 表示获取表配置,false 表示获取数据源配置。
* @param tableName 需要获取配置的表名。
* @return 返回一个包含分片范围配置的列表。
*/
public static List<ShardingRangeConfig> getShardingConfig(boolean isTable, String tableName) {
if (tableName == null || tableName.trim().isEmpty()) {
throw new IllegalArgumentException("Table name cannot be null or empty");
}
String key = tableName.trim() + "--" + isTable;
return MAP.computeIfAbsent(key, k -> loadShardingConfig(isTable, tableName));
}
/**
* 加载分片配置。
* 此方法根据传入的布尔值和表名,从对应的配置文件中加载数据规则配置,并筛选出与表名匹配的分片规则配置。
*
* @param isTable 布尔值,指示配置文件是针对表的配置还是数据源的配置。
* @param tableName 表名,用于筛选与之匹配的分片规则。
* @return 返回一个包含匹配分片规则的列表。如果找不到匹配的规则,则返回空列表。
* @throws CommonException 如果读取配置文件发生异常或者读取到的配置为空,则抛出此异常。
*/
private static List<ShardingRangeConfig> loadShardingConfig(boolean isTable, String tableName) {
List<DataRuleConfig> configs;
try {
if (isTable) {
configs = getConfigJsonFromFile(DataRuleConfig.class, "tableConfig.json");
} else {
configs = getConfigJsonFromFile(DataRuleConfig.class, "dataSourceConfig.json");
}
} catch (IOException e) {
log.error("读取配置文件信息异常", e);
throw new CommonException("读取配置文件信息异常", e);
}
if (CollectionUtils.isEmpty(configs)) {
throw new CommonException("读取配置文件信息为空,请检查配置");
}
List<ShardingRangeConfig> result = configs.stream()
.filter(config -> config.getSharingSource().equalsIgnoreCase(tableName))
.flatMap(config -> config.getShardingRules().stream())
.collect(Collectors.toList());
return result;
}
/**
* 将Comparable对象转换为Long类型。主要用于将日期字符串转换为long类型。
*
* @param comparable 待转换的Comparable对象
* @return 转换后的Long类型,如果无法转换或输入为null,则返回null。
*/
public static Long comparableToLong(Comparable<?> comparable) {
if (Objects.isNull(comparable)) {
return null;
}
if (comparable instanceof Long) {
return (Long) comparable;
}
String valueOf = String.valueOf(comparable);
// 检查是否为时间戳格式
if (LONG_TIMESTAMP_PATTERN.matcher(valueOf).matches()) {
return Long.parseLong(valueOf);
}
// 移除小数点后进行日期转换尝试
valueOf = valueOf.substring(0, Math.max(valueOf.lastIndexOf("."), 0));
try {
LocalDate localDate = LocalDateTimeUtil.parseDate(valueOf, DATE_TIME_FORMAT);
String s = LocalDateTimeUtil.format(localDate, format);
return Long.parseLong(s);
} catch (Exception e) {
return null;
}
}
/**
* 检查给定的Number对象是否大于或等于零。
* 此方法支持BigInteger和BigDecimal类型的检查,以确保能够准确处理大数值。
* 对于其他类型的Number对象,将其转换为double值进行比较。
* 如果Number对象为null,则直接返回false。
*
* @param number 要检查的Number对象。
* @return 如果number大于零,则返回true;否则返回false。
*/
public static boolean isGreaterThanZero(Number number) {
// 检查给定的数值是否大于或等于0
if (number==null) {
return false;
}
if (number instanceof BigInteger) {
return ((BigInteger) number).compareTo(BigInteger.ZERO) > 0;
} else if (number instanceof BigDecimal) {
return ((BigDecimal) number).compareTo(BigDecimal.ZERO) > 0;
} else {
double value = number.doubleValue();
// 对于其他类型的Number,转换为double值后进行比较
// 对于整数类型,直接比较
// 对于浮点类型,使用优化后的比较逻辑
return isFloatOrDouble(value) ? isSignificantlyDifferentFromZero(value) : value > 0.0;
}
}
private static boolean isFloatOrDouble(Number number) {
return number instanceof Float || number instanceof Double;
}
/**
* 检查给定的浮点数值是否与零显著不同
* 使用较小的epsilon值来处理浮点数的精度问题
*/
private static boolean isSignificantlyDifferentFromZero(double value) {
return Math.abs(value) > EPSILON;
}
}
复合分库分片算法AbstractComplexSharding类
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingParam;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingParamValue;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingRange;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingRangeConfig;
import com.example.ftserver.sharding.shardingalgrithm.config.ShardingConfigUtil;
import com.google.common.collect.Range;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.collections4.MapUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.*;
@Slf4j
@SuppressWarnings("all")
public abstract class AbstractComplexSharding<T extends Comparable<? super T>> {
/**
* 初始化分库分表参数时处理复合分片键的逻辑。
* 此方法会根据提供的复合分片信息,将分片参数初始化为一个参数列表,每个参数对应一个分片键的值或值范围。
*
* @param shardingValue 包含复合分片键信息的对象,其中包含了按具体列名分组的分片值集合以及按列名分组的范围分片值集合。
* @return 返回一个包含所有初始化好的分片参数的列表。
*/
protected List<ShardingParam> complexKeyInitSharingParams(ComplexKeysShardingValue<Comparable<?>> shardingValue) {
List<ShardingParam> shardingParams = new ArrayList<>();
// 处理显式提供的分片值
Map<String, Collection<Comparable<?>>> valuesMap = shardingValue.getColumnNameAndShardingValuesMap();
String columName;
if (MapUtils.isNotEmpty(valuesMap)) {
for (Map.Entry<String, Collection<Comparable<?>>> entry : valuesMap.entrySet()) {
Collection<Comparable<?>> values = entry.getValue();
columName = entry.getKey();
if (CollectionUtils.isNotEmpty(values)) {
ShardingParam fromCollection = this.initShardingParamsFromCollection(values, columName);
shardingParams.add(fromCollection);
}
}
}
// 处理范围分片值
Map<String, Range<Comparable<?>>> rangeValuesMap = shardingValue.getColumnNameAndRangeValuesMap();
if (MapUtils.isNotEmpty(rangeValuesMap)) {
for (Map.Entry<String, Range<Comparable<?>>> rangeEntry : rangeValuesMap.entrySet()) {
Range<Comparable<?>> range = rangeEntry.getValue();
columName = rangeEntry.getKey();
if (Objects.nonNull(range)) {
ShardingParam param = this.initShardingParamsFromRange(range, columName);
shardingParams.add(param);
}
}
}
return shardingParams;
}
/**
* =,in时分表信息参数组装
*
* @param collection
* @param shardingColumn
* @return
*/
protected ShardingParam initShardingParamsFromCollection(Collection<Comparable<?>> collection, String shardingColumn) {
ShardingParam param = new ShardingParam();
// 有多个参数时,就不是单值
if (collection.size() > 1) {
param.setSingleValue(false);
}
List<Comparable<?>> list = new ArrayList<>();
list.addAll(collection);
param.setColumnName(shardingColumn);
ShardingParamValue paramValue = new ShardingParamValue();
if (list.size() == 1) {
paramValue.setSingleValue(list.get(0));
} else {
paramValue.setListValue(list);
}
param.setShardingParamValue(paramValue);
return param;
}
/**
* 包含>=,<=,>,<,> between and 时分表信息参数组装
*
* @param range
* @param shardingColumn
* @return
*/
protected ShardingParam initShardingParamsFromRange(Range<Comparable<?>> range, String shardingColumn) {
ShardingParam param = new ShardingParam();
// 范围查询,就不是单值
param.setSingleValue(false);
param.setColumnName(shardingColumn);
ShardingParamValue paramValue = new ShardingParamValue();
paramValue.setUpperBound(range.hasUpperBound());
if (range.hasUpperBound()) {
paramValue.setUpperEndPoint(range.upperEndpoint());
paramValue.setUpperBoundType(range.upperBoundType());
}
if (range.hasLowerBound()) {
paramValue.setLowerEndPoint(range.lowerEndpoint());
paramValue.setLowerBoundType(range.lowerBoundType());
}
param.setShardingParamValue(paramValue);
return param;
}
/**
* 获取分片范围配置列表。
* 该方法根据指定的逻辑表名和是否为表级别分片,从ShardingConfigUtil中获取相应的分片范围配置列表。
*
* @param isTable 表示是否为表级别分片。true表示表级别分片,false表示非表级别分片(例如库级别分片)。
* @param logicTableName 指定的逻辑表名。
* @return 返回一个分片范围配置列表,列表中包含了根据条件筛选出的所有分片范围配置。
*/
protected List<ShardingRangeConfig> shardingRangeConfigs(boolean isTable, String logicTableName) {
return ShardingConfigUtil.getShardingConfig(isTable, logicTableName);
}
/**
* 获取实际涉及的数据库和表的集合。
*
* @param sharingParams 分片参数列表,用于指定分片的条件。
* @param rangeConfigs 分片范围配置列表,定义了每个分片的具体范围。
* @return 返回一个集合,包含所有实际涉及的数据库和表的名称。
*/
protected Collection<String> getTargetDataSource(List<ShardingParam> sharingParams, List<ShardingRangeConfig> rangeConfigs) {
Collection<String> dataSource = new HashSet<>();
for (ShardingParam param : sharingParams) {
if (Objects.isNull(param)) {
continue;
}
for (ShardingRangeConfig config : rangeConfigs) {
List<ShardingRange> ranges = config.getRange();
if (CollectionUtils.isEmpty(ranges) || dataSource.contains(config.getTargetDatasource())) {
continue;
}
for (ShardingRange range : ranges) {
if (!StringUtils.equalsIgnoreCase(range.getColumnName(), param.getColumnName())) {
continue;
}
// 命中相关区间时,将此数据源,表加入
if (isInRangeConfig(param, range)) {
dataSource.add(config.getTargetDatasource());
}
}
}
}
return dataSource;
}
private boolean isInRangeConfig(ShardingParam param, ShardingRange range) {
if (param.isSingleValue()) {
return equalsSingleMatch(param, range);
} else {
return rangeMatch(param, range);
}
}
/**
* =时的判断
*
* @param param
* @param range
* @return
*/
private boolean equalsSingleMatch(ShardingParam param, ShardingRange range) {
if (Objects.isNull(param) || Objects.isNull(range)) {
return false;
}
ShardingParamValue<? extends Comparable<?>> value = param.getShardingParamValue();
if (Objects.isNull(value)) {
return false;
}
Long singleValue = ShardingConfigUtil.comparableToLong(value.getSingleValue());
singleValue = Objects.isNull(singleValue) ? 0L : singleValue;
// sql中的 = 的分片值在range中的,则命中该配置的数据源
boolean flag = singleValue >= range.getLowerBound() && singleValue <= range.getUpperBound();
return flag;
}
/**
* 根据分片参数和分片范围进行匹配判断。
*
* @param param 分片参数,包含需要进行分片的参数值信息。它提供了分片所依据的列名和具体的分片值或分片值范围。
* @param range 分片范围,定义了分片的有效区间。包含了分片的下界和上界。
* @return 如果分片参数的值或值范围落在分片范围内,则返回true;否则返回false。
* 这个方法首先检查分片参数的值是否为空,然后根据分片参数的值类型(单个值或值范围)和分片范围进行比较,
* 判断是否匹配。支持处理分片参数为IN列表的情况,并且考虑了分片键值的上界和下界的各种组合情况。
*/
private boolean rangeMatch(ShardingParam param, ShardingRange range) {
ShardingParamValue<? extends Comparable<?>> value = param.getShardingParamValue();
if (Objects.isNull(value)) {
log.info("value is null");
return false;
}
log.info("param clounm:{}", param.getColumnName());
List<? extends Comparable<?>> valueListValue = value.getListValue();
// 为 in的处理,此时会有多个值,只需要判断是否在配置区间内
if (CollectionUtils.isNotEmpty(valueListValue)) {
for (Comparable<?> comparable : valueListValue) {
Long num = ShardingConfigUtil.comparableToLong(comparable) == null ? 0L : ShardingConfigUtil.comparableToLong(comparable);
boolean b = num >= range.getLowerBound() && (Long) comparable <= range.getUpperBound();
if (b) {
return true;
}
}
return false;
}
Long upperBound = ShardingConfigUtil.comparableToLong(value.getUpperEndPoint());
Long lowerBound = ShardingConfigUtil.comparableToLong(value.getLowerEndPoint());
// 判断sql中的分片建范围和配置中的range是否有交集
// sql中的分片键下区间有值,上区间没有值:(1,正无穷)
if (Objects.nonNull(lowerBound) && Objects.isNull(upperBound)) {
return lowerBound <= range.getUpperBound();
}
// sql中的分片键下区间没有值,上区间有值:(负无穷,1)
if (Objects.isNull(lowerBound) && Objects.nonNull(upperBound)) {
return upperBound >= range.getLowerBound();
}
// sql中的分片键上区间和下区间都有值 (50,60),到此行时,lowerBound都已经判断过,无需再次判断
if (Objects.nonNull(upperBound)) {
// 如果分片键区间的最小值小于等于配置区间的最大值且分片建区间的最大值大于等于配置区间的最小值,则说明二者有交集
return lowerBound <= range.getUpperBound() && upperBound >= range.getLowerBound();
}
return false;
}
}
复合分片数据源配置
import com.example.ftserver.sharding.shardingalgrithm.AbstractComplexSharding;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingParam;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingRangeConfig;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.List;
@Component
@Slf4j
public class FtDataBaseComplexShardingAlgorithm extends AbstractComplexSharding<Long> implements ComplexKeysShardingAlgorithm<Comparable<?>> {
/**
* 根据复杂的键进行分片操作。
*
* @param collection 需要进行分片操作的集合。
* @param complexKeysShardingValue 复杂键分片值,包含逻辑表名和分片参数。
* @return 分片后的数据集合。如果无法进行分片或分片结果为空,则返回原始集合。
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Comparable< ? >> complexKeysShardingValue) {
// 获取逻辑表名
String logicTableName = complexKeysShardingValue.getLogicTableName();
// 初始化分片参数
List<ShardingParam> sharingParams = super.complexKeyInitSharingParams(complexKeysShardingValue);
if (CollectionUtils.isEmpty(sharingParams)) {
return collection;
}
List<ShardingRangeConfig> rangeConfigs = super.shardingRangeConfigs(false,logicTableName);
// 根据分片参数和范围配置获取目标数据源
Collection<String> dataSource = super.getTargetDataSource(sharingParams, rangeConfigs);
return CollectionUtils.isEmpty(dataSource) ? collection : dataSource;
}
}
复合分片表配置
import com.example.ftserver.sharding.shardingalgrithm.AbstractComplexSharding;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingParam;
import com.example.ftserver.sharding.shardingalgrithm.complex.sharingvalue.ShardingRangeConfig;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.List;
@Component
@Slf4j
public class FtTableComplexShardingAlgorithm extends AbstractComplexSharding<Long> implements ComplexKeysShardingAlgorithm<Comparable<?>> {
/**
* 根据复杂的键进行分片操作。
*
* @param collection 需要进行分片操作的集合。
* @param complexKeysShardingValue 复杂键分片值,包含逻辑表名和分片键值信息。
* @return 分片后的数据集合。如果无法进行分片或分片结果为空,则返回原始集合。
*/
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Comparable<?>> complexKeysShardingValue) {
List<ShardingParam> sharingParams = super.complexKeyInitSharingParams(complexKeysShardingValue);
if (CollectionUtils.isEmpty(sharingParams)) {
return collection;
}
String logicTableName = complexKeysShardingValue.getLogicTableName();
List<ShardingRangeConfig> rangeConfigs = super.shardingRangeConfigs(true, logicTableName);
// 根据分片参数和范围配置获取目标数据源
Collection<String> dataSource = super.getTargetDataSource(sharingParams, rangeConfigs);
return CollectionUtils.isEmpty(dataSource) ? collection : dataSource;
}
}
yml配置(其他配置见专栏第一篇):
spring:
sharding-sphere:
datasource:
names: ftdb0,ftdb1
ftdb0:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://localhost:3306/ftdb0?useUnicode=true&autoReconnect=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123mysql
ftdb1:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://localhost:3306/ftdb1?useUnicode=true&autoReconnect=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123mysql
sharding:
tables:
# b_order:
# actualDataNodes: ftdb${0..1}.b_order${0..1}
# database-strategy: # 数据库精确精确分库策略
# standard:
# sharding-column: user_id
# precise-algorithm-class-name: com.example.ftserver.sharding.shardingalgrithm.precise.FtDataBasePreciseShardingAlgorithm
# key-generator:
# column: id
# type: SNOWFLAKE
# tableStrategy: #表精确分片策略
# standard:
# shardingColumn: company_id
# preciseAlgorithmClassName: com.example.ftserver.sharding.shardingalgrithm.precise.FtTablePreciseShardingAlgorithm
c_order:
actualDataNodes: ftdb$->{0..1}.c_order$->{2023..2024}
database-strategy:
standard:
sharding-column: delivery_time #数据库范围分库策略,需要配置精确分片策略,不然会报空指针,无法启动
rangeAlgorithmClassName: com.example.ftserver.sharding.shardingalgrithm.range.FtDataBaseRangeShardingAlgorithm
precise-algorithm-class-name: com.example.ftserver.sharding.shardingalgrithm.range.FtDataBaseRangeShardingAlgorithm
tableStrategy:
standard:
sharding-column: delivery_time # 数据库范围分表策略,需要配置精确分片策略,不然会报空指针,无法启动
rangeAlgorithmClassName: com.example.ftserver.sharding.shardingalgrithm.range.FtTableRangeShardingAlgorithm
precise-algorithm-class-name: com.example.ftserver.sharding.shardingalgrithm.range.FtTableRangeShardingAlgorithm
key-generator:
column: id
type: SNOWFLAKE
b_order: #测试自定义复合分片策略
actualDataNodes: ftdb$->{0..1}.b_order$->{0..2}
database-strategy:
complex:
sharding-columns: company_id,position_id
algorithm-class-name: com.example.ftserver.sharding.shardingalgrithm.complex.FtDataBaseComplexShardingAlgorithm
table-strategy:
complex:
sharding-columns: company_id,position_id
algorithm-class-name: com.example.ftserver.sharding.shardingalgrithm.complex.FtTableComplexShardingAlgorithm
key-generator:
column: id
type: MYKEY
测试用例
新增测试代码,仅演示根据Id分库分表:
@Test
public void complexTest() {
BOrderEntity entity = new BOrderEntity();
entity.setIsDel(false);
entity.setCompanyId(RandomUtil.randomLong(1, 500L));
entity.setPositionId(RandomUtil.randomLong(1, 500L));
entity.setUserId(RandomUtil.randomInt(50));
entity.setPublishUserId(2223);
entity.setResumeType(RandomUtil.randomInt(1, 6));
entity.setStatus(RandomUtil.randomString(10));
entity.setWorkYear(String.valueOf(RandomUtil.randomInt(1, 2)));
entity.setName(String.valueOf(RandomUtil.randomChinese()));
entity.setPositionName("运维工程师11");
entity.setResumeId(1);
orderMapper.insert(entity);
entity = new BOrderEntity();
entity.setIsDel(false);
entity.setCompanyId(RandomUtil.randomLong(500, 800L));
entity.setPositionId(RandomUtil.randomLong(500, 800L));
entity.setUserId(RandomUtil.randomInt(100));
entity.setPublishUserId(33369);
entity.setResumeType(RandomUtil.randomInt(6, 9));
entity.setStatus(RandomUtil.randomString(10));
entity.setWorkYear(String.valueOf(RandomUtil.randomInt(1, 2)));
entity.setName(String.valueOf(RandomUtil.randomChinese()));
entity.setPositionName("测试工程师11");
entity.setResumeId(2);
orderMapper.insert(entity);
entity = new BOrderEntity();
entity.setIsDel(false);
entity.setCompanyId(RandomUtil.randomLong(801L, 2000L));
entity.setPositionId(RandomUtil.randomLong(801L, 2000L));
entity.setUserId(RandomUtil.randomInt(300));
entity.setPublishUserId(889);
entity.setResumeType(RandomUtil.randomInt(2, 8));
entity.setStatus(RandomUtil.randomString(10));
entity.setWorkYear(String.valueOf(RandomUtil.randomInt(1, 2)));
entity.setName(String.valueOf(RandomUtil.randomChinese()));
entity.setPositionName("java工程师11");
entity.setResumeId(3);
orderMapper.insert(entity);
}
测试结果:
已经根据分片配置落入了对应的数据库

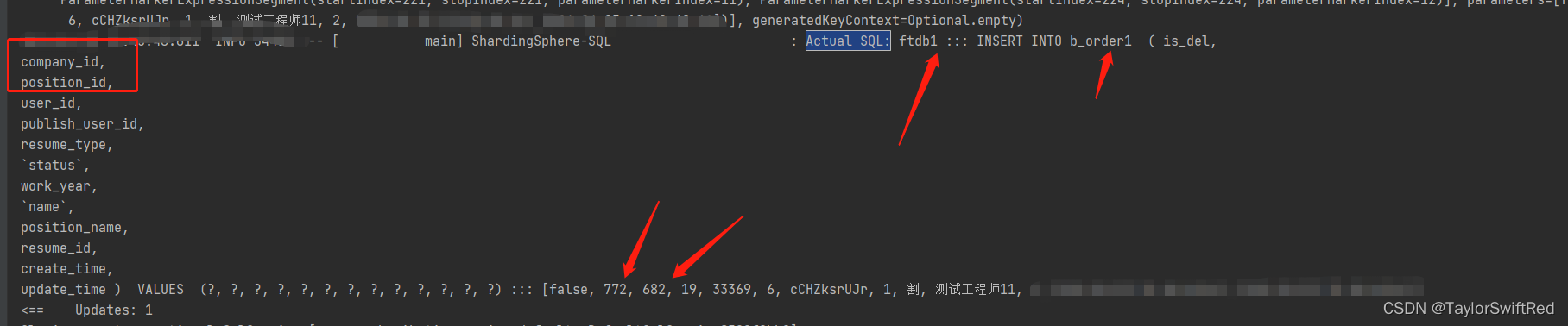
查询测试
使用配置项的列作为查询条件
@Test
public void queryComplex() {
LambdaQueryWrapper<BOrderEntity> queryWrapper = Wrappers.lambdaQuery(BOrderEntity.class).between(BOrderEntity::getCompanyId, 114L, 500L).
le(BOrderEntity::getPositionId, 500L);
List<BOrderEntity> entityList = orderMapper.selectList(queryWrapper);
System.out.println("查询结果:" + JSONUtil.toJsonStr(entityList));
}
查询结果:

可以看到打印的SQL,查询落入了对应的数据库以及表中(该demo配置的b_order在company_id和position_id小于500时,存放于ftdb0和b_order1)
总结
该算法也有不足之处,不足之处为,当插入和查询的时候,某个配置条件超出了配置范围,则会在所有的满足配置项里面新增或者查询数据,如在该demo中:company_id为500,position_id为600时,则新增时会在ftdb0,b_order0和ftdb1的b_order1各新增一条数据,查询时也会走ftdb0,b_order0和ftdb1的b_order1路由。
















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









