










kaleido-BERT原理
论文地址: https://arxiv.org/abs/2103.16110
GitHub地址:https://github.com/mczhuge/Kaleido-BERT/
1. 多模态模型主体类别
阿里的ICBU部门最新的多模态研究工作kaleido-BERT文章中总结了30种近两年多模态预训练模型的,包括模型主要结构,训练数据集,一些核心的idea,使用领域,是否pretrain,fintune方式,还有一些图像和视觉主要用的特征。
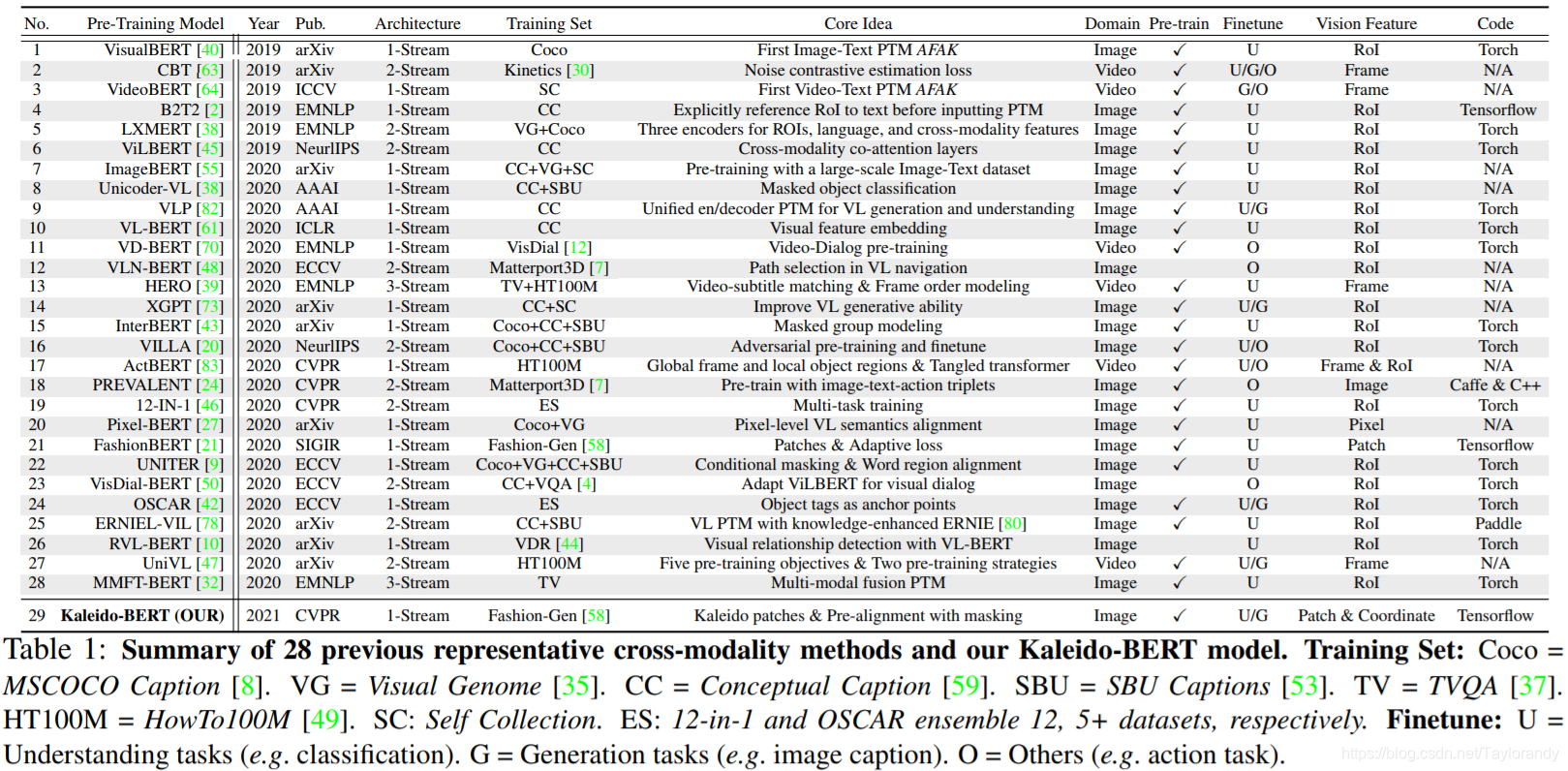
1.1 one stream
目前我们所研究领域的多模态预训练模型主要分为单流,双流和三流的这三种结构。以VL-BERT为例,主要是把图像和text的pair进行预处理,比如图像上提取ROI,文本侧提取token,然后直接放到多模态bert里面去进行交互和学习,去年的话阿里ICBU部门发表的FashionBERT也是类似地单流的结构,不同点是FashionBERT里面图像侧的特征是通过均匀的切片的patch作为图像的token输入到网络去。这是单流的多模态结构。
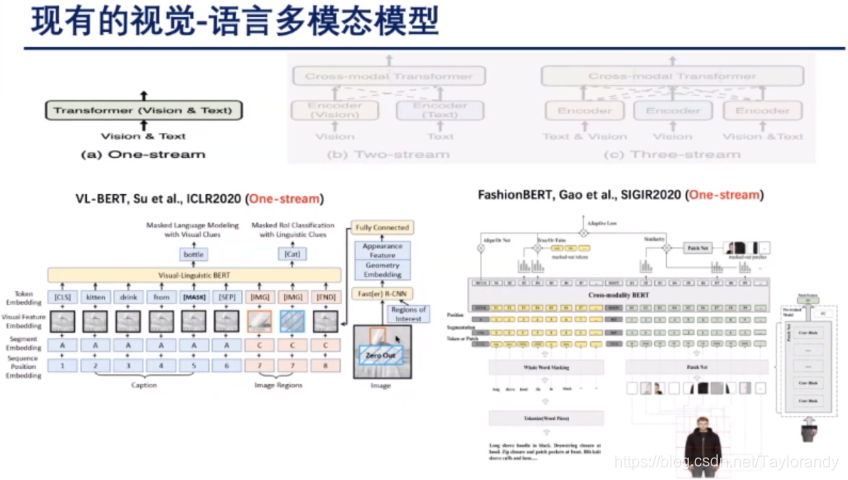
1.2 two stream
还有一种是基于双流的多模态模型。这种模型的主要特点是它会把不同模态的信息先单独进行编码,然后生成它的向量表达,然后再送入transformer或者BERT网络中,让高阶信息进行模态之间的融合。这里举了两个例子一个是LXMERT以及ViLBERT这两篇工作。
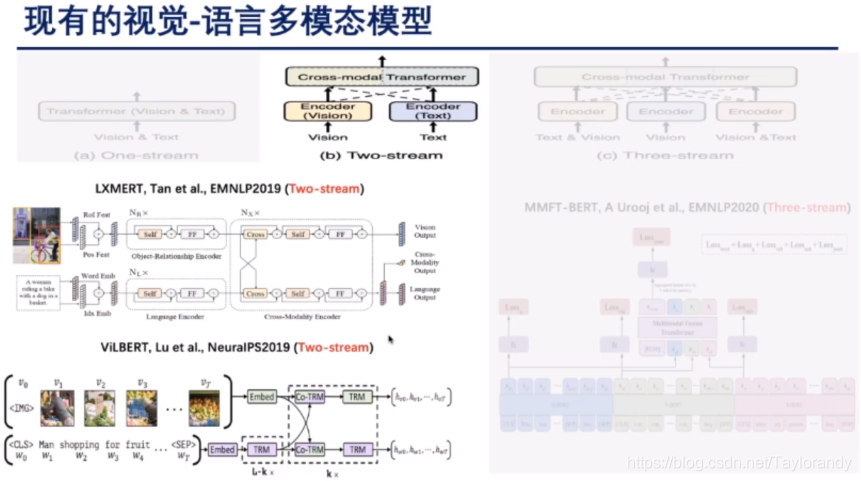
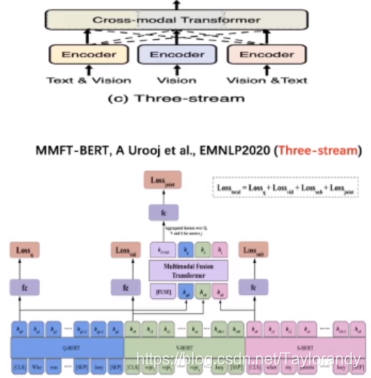
1.3 three stream
这种结构的模型一般是先把多模态形象进行初步的融合或者处理,然后再把多路的表征放到transformer或者BERT中去学习和交互。这种模型一般比较少见,主要是用于特定的一些领域,比如VQA。
2. 存在的问题
2.1 图像特征表达
作者尝试单流和双流的模型,认为单流会讲数据信息更早的融入模型,效果可能会更好。第一个问题是通用领域目标检测器ROI,不适用于电商或者Fashion领域。因为电商或者Fashion领域的商品主体是比较单一的,比如鞋或者包,最多可能也就4-6个ROI就够了。如果你设定一个最小ROI个数比如30或者60(看左下角图),用目标检测会产生很多重复的ROI,其实框定的是一个位置。了解多模态训练的可知,训练过程中有一个mask机制,如果里面含有大量重复的ROI的话会造成信息泄露的问题,导致学习并没有很充分,同时这些重复的ROI中可能还有噪声ROI,你还要训练一个网络去筛选出有用的ROI,这样做成本太高。去年的话,作者所在的组提出了一个Fashion BERT,做法是把图片切片的patch作为图像的特征输入到BERT网络中进行训练。其实这样做也并没有对图像进行充分的利用,有的时候会缺少多层次的图像信息的表达。

2.2 缺少图文信息先验理解
第二个问题在于,目前多模态预训练里面有一个自监督的训练策略,不管是图像侧还是文本侧使用的还是原来BERT的mask language modeling的思想,就是在文本侧mask掉一定的token,然后让模型预测出mask掉的部分,或者是在图像侧mask一定的region,然后回归出图像的region。这里有个问题就是这两个模态是分别独立的mask的,他们的模态之间没有关联起来。如果想学到模态之间的关联信息,比如我知道文本的token和图像的region有一定关联,我们可以设置一些策略,让网络显性的去学习一些语义关系,这样就可以提升多模态的一个能力。

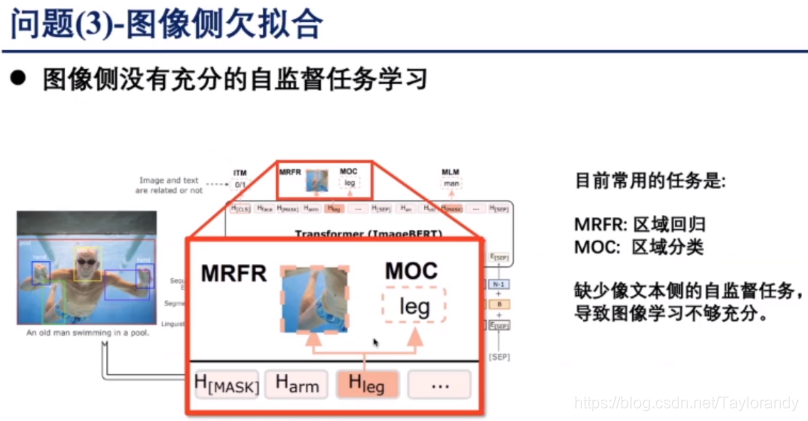
2.3 图像侧欠拟合
大部分的多模态预训练模型图像侧都是使用图像侧的特征进行回归,当然也有少量的工作比如image-BERT,mask图像的这个区块,还要做一个分类,比如mask一个腿,我还要对腿做一个分类。即使这样作者感觉对图像侧的使用还是不够充分的。
3. kaleido-BERT
基于上述的三个问题,作者提出了新的模型。整体分为4个部分,分别解决上述3个问题。下面就主要讲一下这几个模块。
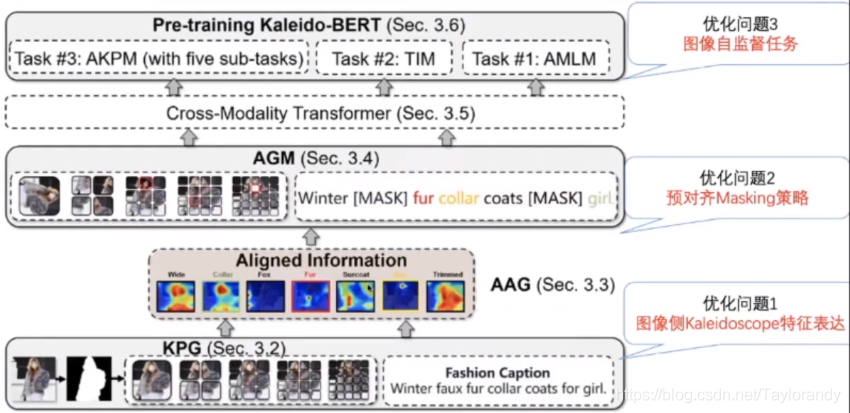
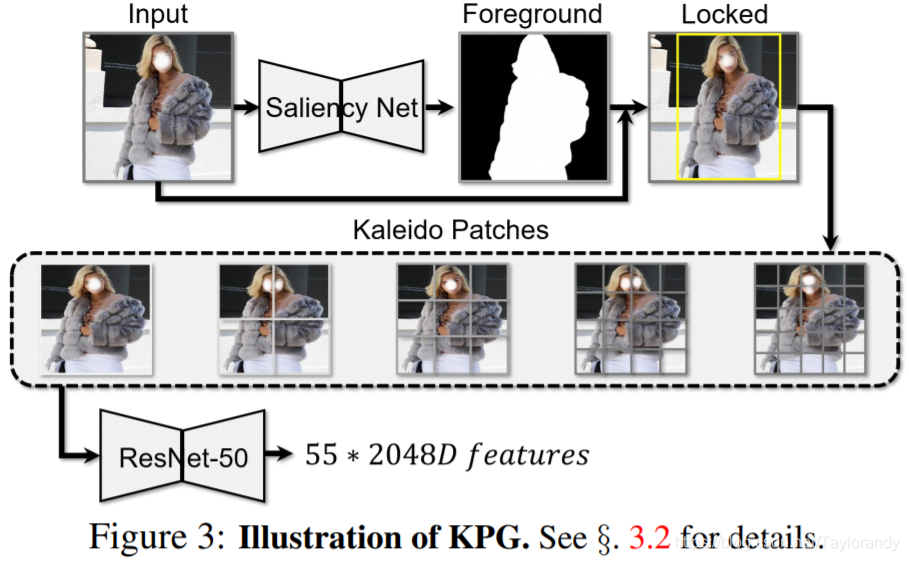
3.1 Kaleido Patch Generation(KPG)
这一部分介绍一下KPG模块,这个模块的主要目的是提供一个更加丰富的图像特征。流程就是对于任意一张电商图片,我们会先经过一个saliency的网络提取出前景和背景锁定出来商品的主要区域,锁定完商品的主要区域之后我们采取一个新的策略叫Kaleido Patches,我们的目的是对图像进行不同尺度的patch切分,比如我切分出1乘1的,3乘3的,然后在不同尺度的特征上去进行特征提取,比如经过ResNet50。那这样的好处是说通过这样多尺度的图像patch其实我能把图像侧的信息极大的丰富化,我既有全局的图像特征我又有细节的图像特征。
3.2 Attention-based Alignment Generation(AAG)
第二个优化点是我们想做一个图文预对齐的Masking。这里有一个前置的工作就是,我们的token和图像的哪一个区域是相关的,这个过程是比较复杂的,总共是分为下面5个部分。
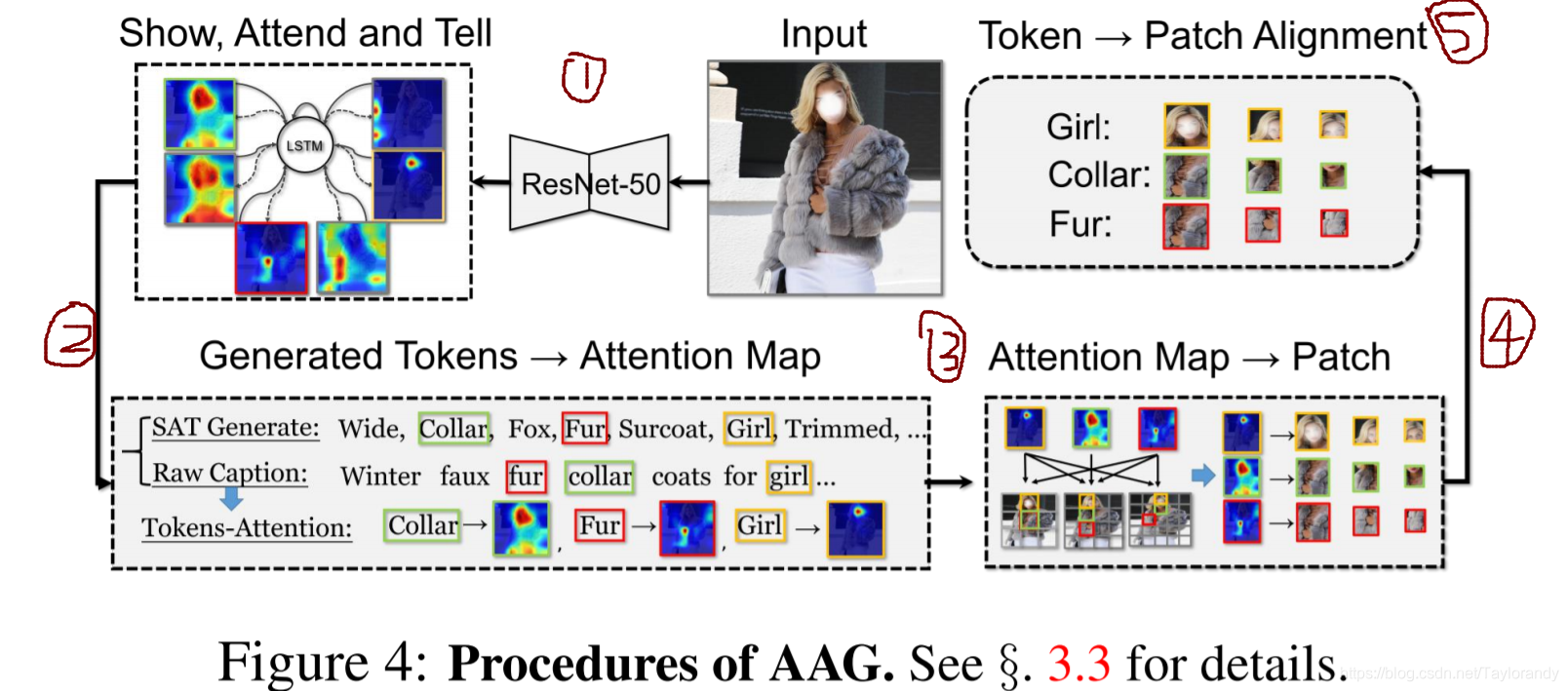
比如第一个流程,我们会针对商品训练一个Show,Attend and Tell(SAT)的一个模型,基于这个模型我们给定一张照片我可以用SAT的模型生成一段文本表达,这段文本表达跟原始的图像的title,我们可以统计出词的贡献的信息。SAT还有一个好处是可以告诉我们图像的token跟图像的Attention的热力图,比方说我们可以从流程2中找到wide或者Fur和图像中的哪一块区域的热力值是比较高的,那根据Attention的热力图和我patch的像素信息,其实我还能得到一个信息是Attention热力图和切割的patch的对应关系,这样最后我可以推导出我贡献的token或者重要的token跟我图像的某一个区域或者某一个patch预对齐的信息,那这个预对齐的信息我们可以理解为我的文本的token跟图像的语义的预对齐信息,那基于这个预对齐信息我们就可以设计我们的masking策略。
3.3 Alignment Guided Making(AGM)
希望mask一部分的信息,mask掉一侧然后我们用另外一个模态的信息去预测这个模态的信息,这样的话可以帮助我们的模型更好的理解多模态模型之间交互的信息。其实ImageBERT或者OSCAR也有一些这样的想法,下面就介绍一下ImageBERT和OSCAR的思想。ImageBERT的做法是我如果有一个图像的ROI的话,他要预测出图像ROI的类别,做一个图像特征的监督。那对于OSCAR来说他会把ROI的label放入到BERT模型的输入里面去作为一个过程输入,但是对比来说KaleidoBERT这个模型相比较ImageBERT/OSCAR来说还是有一定先进性的。
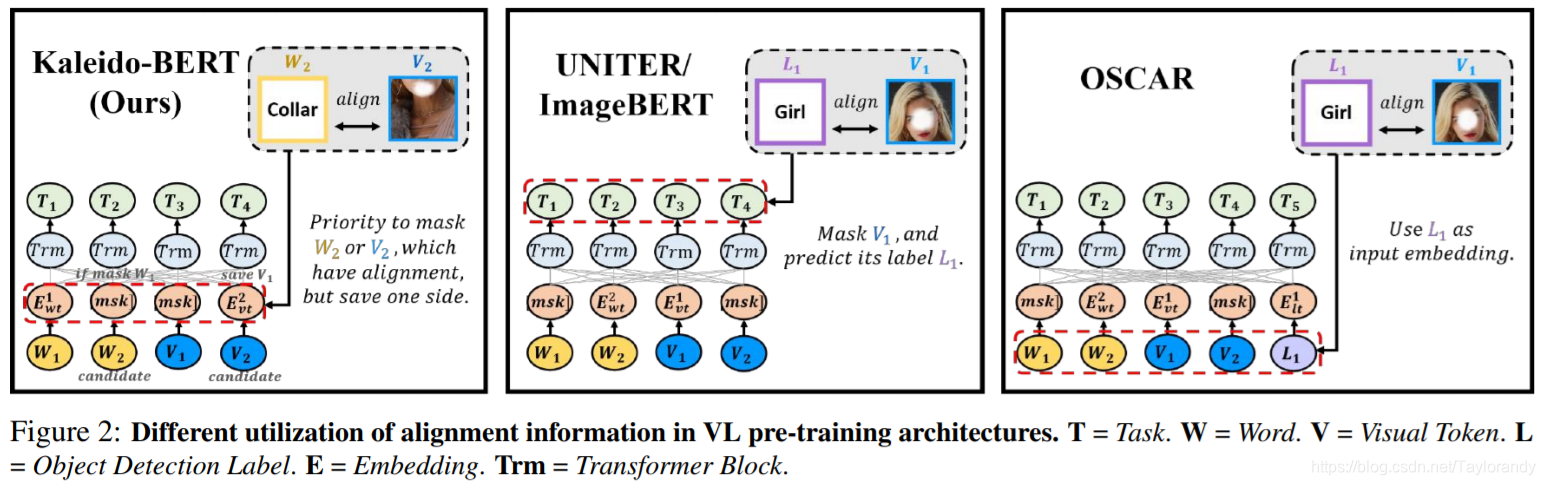
3.4 Aligned Kaleido Patch Modeling(AKPM)
第三个是为了解决图像侧自监督学习不充分的问题。我们引入了5个图像的自监督任务,这里叫做AKPM模块。这五个任务实际上是针对不同的level。第一个预训练任务是图像的旋转角度的预测,第二个任务是类似于一个拼图的预测,相当于告诉我图像的位置是在哪里,第三个任务我们做的是一个隐藏patch的预测,我们会把某一些patch随机的替换掉,让他预测出哪一个patch是被替换的,还有一种是从灰度图重构出彩色图的工作,以及从空白图重构出彩色图的任务。另外的话Image-Text Matching的任务和Alligned Masked Language Modeling的任务都是保留着的。
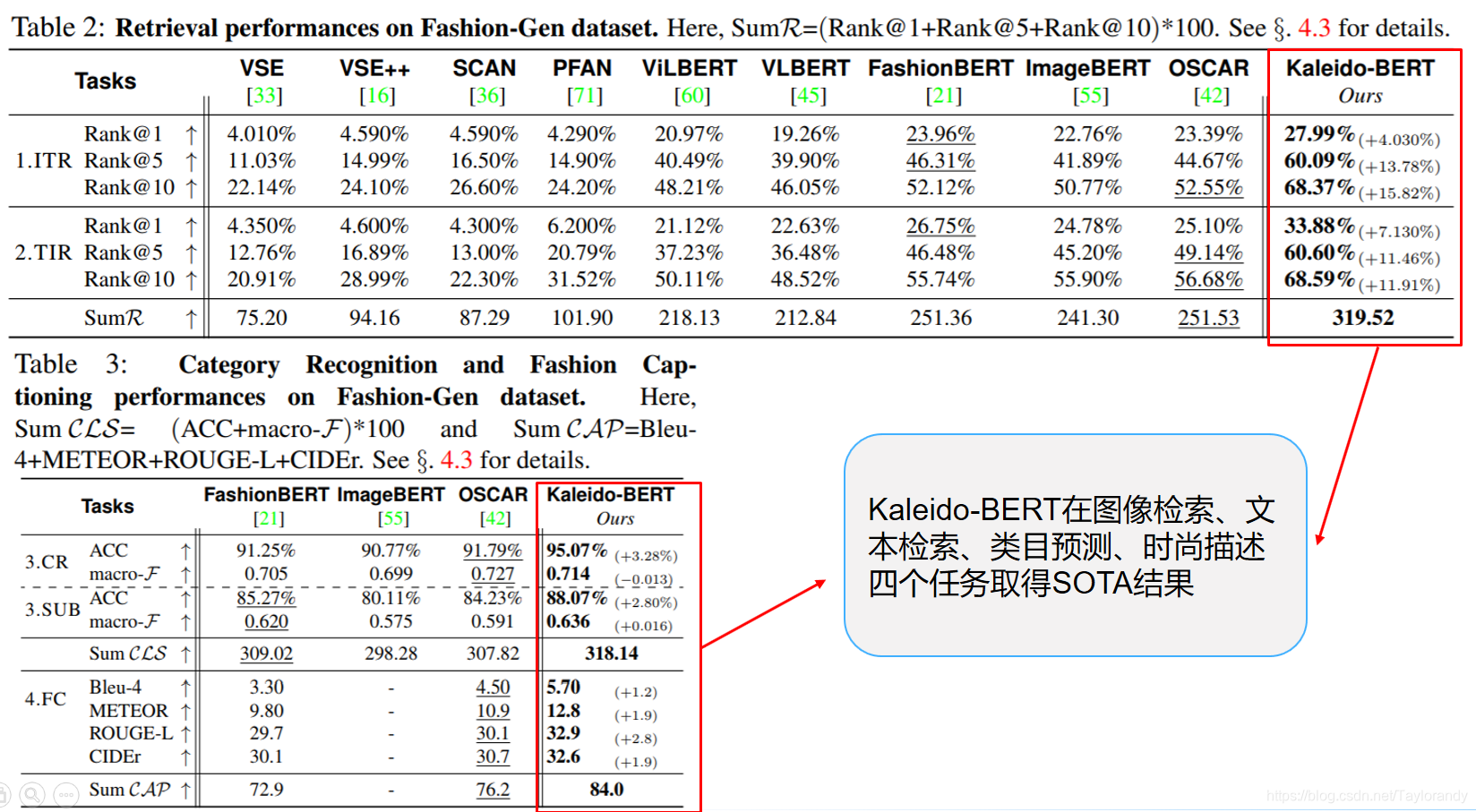
4. 实验
4.1 主实验
实验部分是在图像检索、文本检索、类目预测、时尚描述四个任务取得SOTA结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PUMOokTL-1626102800515)(.\img\13.png)]](https://i-blog.csdnimg.cn/blog_migrate/446d5e2f19fafedca5ae933e08c97620.png)
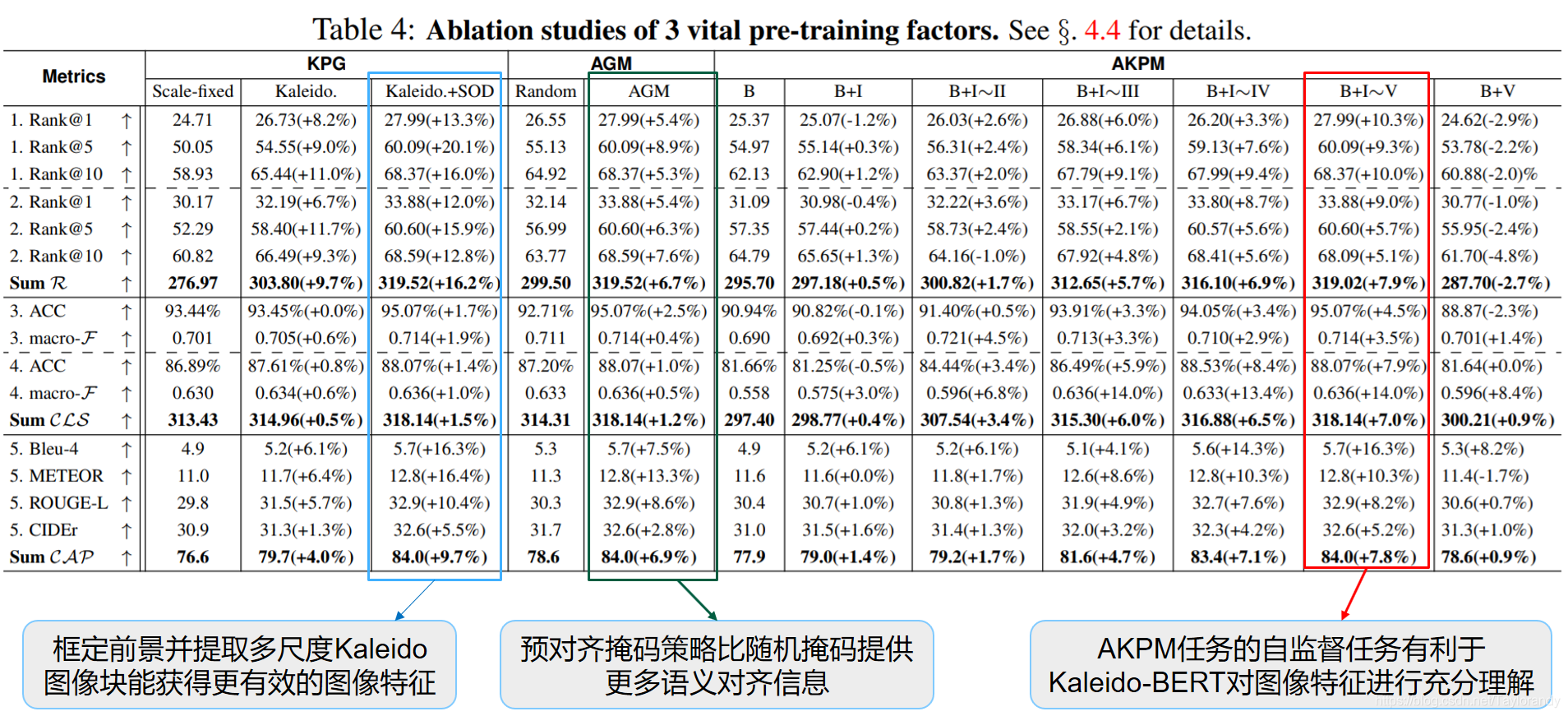
4.2 消融实验
(1)框定前景并提取多尺度Kaleido图像块能获得更有效的图像特征;
(2)预对齐掩码策略比随机掩码提供更多语义对齐信息
(3) AKPM任务的自监督任务有利于Kaleido-BERT对图像特征进行充分理解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









