







以超卖为例✨各种场景下如何防止并发污染数据?
在日常的业务开发中,总是会遇到可能并发操作共享资源的场景
比如:商品库存扣减、用户余额调整、火车票、机票、演唱会入场票的扣减(类似商品库存扣减)等…
以商品库存扣减场景为例,会先从数据库中读出库存,当库存充足时才进行扣减
这是一个先读后写的复合操作,而在这个操作中并没有保证操作的原子性
当大量请求一起读到库存充足再同时扣减就有可能出现超卖的情况,从而污染数据
/**
* 存在并发问题的购买
*
* @param id 商品ID
* @param count 数量
* @return 是否购买成功
*/
public boolean buy(int id, int count) {
boolean res = false;
//根据ID查询商品库存数量 select stock_count from goods where id = ?
int stockCount = selectStockCountByDB(id);
//由于读操作和写操作不是原子性,在此期间可能并发查到 stockCount > 0 导致超卖
if (stockCount > 0) {
//减库存 update goods set stock_count = stock_count - ? where id = ?
cutStock(id, count);
res = true;
}
return res;
}
本篇文章以商品库存扣减为例,来聊聊在各种各样的场景下最适合用什么方式来防止并发导致数据不一致的问题
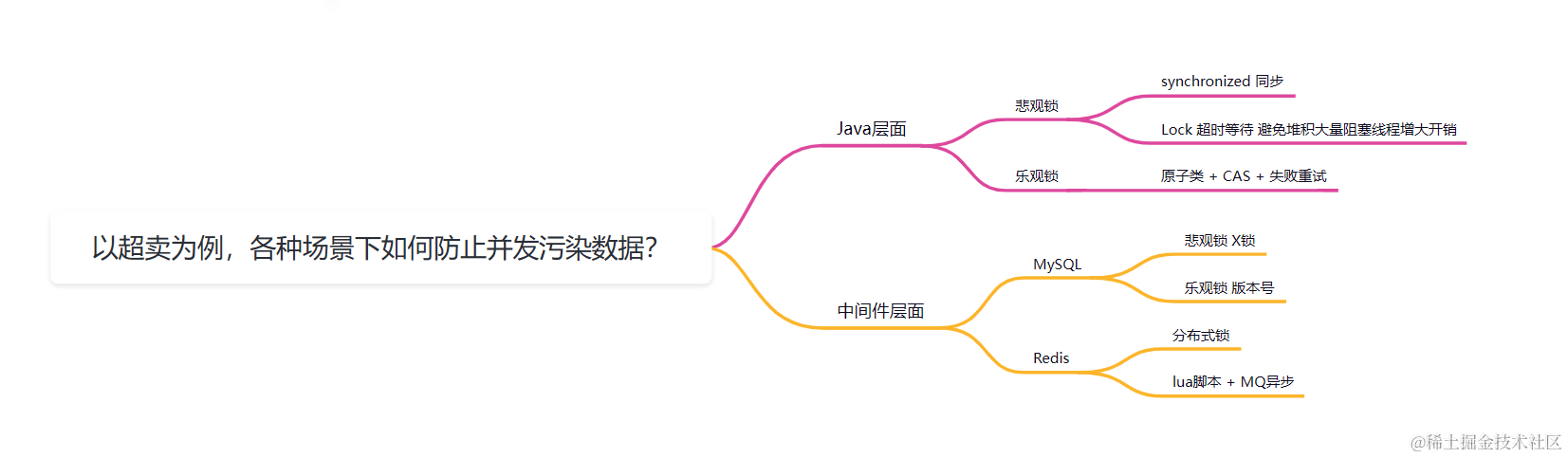
悲观锁和乐观锁
锁能够防止并发同时操作共享资源而导致数据不一致的情况,锁大体上分为悲观锁和乐观锁
悲观锁秉承悲观的思想,遇到要操作共享资源的复合操作时就进行加锁,保证操作共享资源时同步执行
乐观锁秉承乐观的思想,先大胆执行,如果执行失败则使用补偿操作,通常是CAS + 失败重试
Java层面
单机少并发
当我们的服务为单机并且并发较少的情况可以考虑使用Java中的悲观锁synchronized保证原子操作同步
由于商品很多,一个商品对应一个synchronized锁的对象即可
private static final Map<Integer, Object> synchronizedMap = new ConcurrentHashMap<>();
public boolean synchronizedBuy(int id, int count) {
boolean res = false;
//所有商品都用同一把锁粒度太粗,每个商品ID对应一把锁
Object lockObj = synchronizedMap.computeIfAbsent(id, k -> new Object());
//加锁保证原子性
synchronized (lockObj) {
//根据ID查询商品库存数量
int stockCount = selectStockCountByDB(id);
if (stockCount > 0) {
//减库存
cutStock(id, count);
res = true;
}
}
return res;
}
synchronized的好处就是使用简单,并且优化后性能不错(并不是直接挂起线程的)
对synchronized原理感兴趣的同学可以查看这篇文章:彻底搞懂Synchronized
但并发增多时可能会导致大量请求进入等待,线程逐渐增多会导致上下文切换成本高,从而导致吞吐量下降
防止大量阻塞
从另一个思路可以解决这个问题,当等待太久时就主动放弃提示用户稍后再试,避免阻塞的线程过多,导致性能下降
JUC下的Lock一般就携带超时等待的功能
private static final Map<Integer, ReentrantLock> lockMap = new ConcurrentHashMap<>();
public boolean JUCLockBuy(int id, int count) {
boolean res = false;
//所有商品都用同一把锁粒度太粗,每个商品ID对应一把锁
ReentrantLock lock = lockMap.computeIfAbsent(id, k -> new ReentrantLock());
try {
//超过100ms 就返回
if (lock.tryLock(100, TimeUnit.MILLISECONDS)) {
//根据ID查询商品库存数量
int stockCount = selectStockCountByDB(id);
if (stockCount > 0) {
//减库存
cutStock(id, count);
res = true;
}
}
} catch (InterruptedException e) {
//等待被中断 log.error
}finally {
//如果持有锁就释放 (来到这里可能是等待被中断导致的,这种情况不用释放锁)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return res;
}
ReentrantLock是基于AQS实现的,对原理感兴趣的同学可以查看:AQS
ReentrantLock实现与synchronized类似,都是使用等待队列与阻塞队列,功能更多,但需要手动加/解锁
并发增多
上面的加锁期间进行了两次网络IO,第一次是去查询数据库,第二次是去修改数据,这会导致加锁的时间变长,从而导致吞吐量降低
当并发增多时就会导致大量超时的情况,导致对用户体验不好
可以考虑把库存数量提前预热到内存来进行高频率的读写,再使用异步任务将数据同步到数据库中
在内存中使用乐观锁CAS来保证复合操作的原子性
(注意数据最好提前预热到内存,否则懒加载为空时可能会导致大量请求一起查库,导致DB压力大)
private static final Map<Integer, AtomicInteger> casMap = new ConcurrentHashMap<>();
public boolean casBuy(int id, int count) {
boolean res = false;
//提前预热 这里没加锁 只是展示一下
AtomicInteger stockAtomic = casMap.computeIfAbsent(id, k -> {
//内存里没有就查库
//如果不提前预热同时并发查DB,DB压力大,又要加锁
int stock = selectStockCountByDB(id);
return new AtomicInteger(stock);
});
//当前库存数量
int stockCount = stockAtomic.get();
if (stockCount > 0) {
//判断乐观锁是否成功
boolean flag;
//失败重试 自旋
do {
stockCount = stockAtomic.get();
//用库存数量当作比较对象(版本号) 如果增加库存可能会导致ABA问题,可以用携带版本号解决 AtomicStampedReference
flag = stockAtomic.compareAndSet(stockCount, stockCount - count);
} while (!flag);
res = true;
}
return res;
}
需要注意的是使用CAS操作,如果增加库存数量可能带来ABA问题,可以使用携带升序的版本号解决
但是当Java服务宕机时这种方案会导致期间的数据丢失,从而引起数据不一致
并且当并发量更大、写操作太多时,乐观锁会导致持续空转从而降低性能
实际上单机能够承受的并发量是有限的,要扛住更大的并发一般会使用多节点,最终的解决方案留在后面
中间件层面
分布式少并发
当系统是分布式时,可能存在多个节点(多个Java服务),使用本地锁Lock、synchronized就还是会出现超卖的情况
这时可以考虑把加锁的层面从Java代码层放到数据库层面,MySQL数据库层面也是可以加锁的
可以在MySQL数据库层级做乐观锁,用库存数量作为版本号,如果读写之间被其他事务写过,那么库存数量就不对,就会失败重试
public boolean OptimisticLockBuy(int id, int count) {
boolean res = false;
//根据ID查询商品库存数量 select stock_count from goods where id = ?
int stockCount = selectStockCountByDBForUpdate(id);
if (stockCount > 0) {
//修改行数 判断乐观锁是否成功
int row;
//失败重试 自旋
do {
//查询最新数据
stockCount = selectStockCountByDBForUpdate(id);
//用库存数量当作比较对象(版本号) 如果增加库存可能会导致ABA问题,可以用自增版本号解决
//减库存 update goods set stock_count = stock_count - ? where id = ? and stock_count = ?
row = cutStockCompareVersion(id, count, stockCount);
} while (row == 0);
res = true;
}
return res;
}
但如果库存数量被增加时就可能出现ABA问题,这时可以新增一个版本号的字段用于自增就不会出现ABA问题
这种数据库层面做乐观锁的方案往往是少并发下最常用的方案
同时也可以在数据库层面使用悲观锁,MySQL在读数据时默认使用MVCC无锁快照读,直接在读操作时就加X锁(for update),就能够保证同步
public boolean xLockBuy(int id, int count) {
boolean res = false;
//读时加X锁(其他事务读相同商品会被阻塞) select stock_count from goods where id = ? for update
int stockCount = selectStockCountByDBForUpdate(id);
if (stockCount > 0) {
//减库存 update goods set stock_count = stock_count - ? where id = ?
cutStock(id, count);
res = true;
}
return res;
}
但是在数据库层面给读操作加锁的风险很大,可能会导致行锁阻塞,不同事务隔离级别可能会更严重,甚至出现死锁的情况
极端情况下可能导致数据库中请求堆积让连接池被打满,从而影响所有服务,因此不建议使用这种方案
对Innodb加行锁感兴趣的同学可以查看这篇文章:彻底搞懂Innodb行锁加锁规则
分布式锁
另一种解决方案是使用分布式存储的中间件做分布锁
通常是使用数据库做分布式锁,比如MySQL、Redis、zookeeper
最常见的方案是使用Redis做分布锁,Redis中设置一个Key,如果不存在则设置,说明获取锁成功;存在则说明锁已被获取
但Redis当分布式锁自己实现的话还有很多坑:加锁要和设置过期时间保持原子性、释放锁要保证不释放其他线程的锁等…
因此这里API使用Redisson,避免自己重复造轮子
public boolean DistributedLock(int id, int count) {
boolean res = false;
RLock lock = redisson.getLock("stock_lock_" + id);
lock.lock(100, TimeUnit.MILLISECONDS);
try {
//根据ID查询商品库存数量
int stockCount = selectStockCountByDB(id);
if (stockCount > 0) {
//减库存
cutStock(id, count);
res = true;
}
} finally {
lock.unlock();
}
return res;
}
在极端情况下(故障转移,切换节点),还是会导致重复获取锁,但是为了追求性能还是会选择使用
分布式并发增多
当读写并发量极高时,分布式锁会显得力不从心,原因是读写数据也与MySQL进行网络IO通信,并且MySQL操作磁盘太慢了,导致分布式锁粒度大
并且分布式锁的获取与释放与Redis进行网络IO通信也有一定的损耗
在高并发读写时,常常会把数据存放到Redis中,因为Redis基于内存操作、基于哈希表等值查询非常快,让读写操作都基于Redis,后续通过MQ异步将数据同步到MySQL中
那么在Redis中如何保证读写的原子性呢?
Redis是单线程执行的,通常使用lua脚本来保证读写操作原子性,但是lua脚本不能太大,否则可能执行过长造成阻塞
先来解释下这段lua脚本:
local stock = tonumber(redis.call('GET', KEYS[1]))
if stock > 0 then
redis.call('DECRBY', KEYS[1], tonumber(ARGV[1]))
return 1
end
return -1
redis.call('GET', KEYS[1]) 表示执行get命令,KEYS[1]是我们传入参数的第一个Key,也就是某商品库存数量的Key
tonumber 是把查询到的结果转换为数字
local stock = tonumber(redis.call('GET', KEYS[1])) 就是查询库存数量定义变量名为stock
if stock > 0 then 当库存数量充足时执行
redis.call('DECRBY', KEYS[1], tonumber(ARGV[1])) 给KEYS[1]降低数量ARGV[1],也就是写操作降低多少个库存
成功返回1,失败返回-1
通过接收结果能够知道扣减库存是否成功
public boolean lua(int id, int count) {
StringBuilder scriptBuilder = new StringBuilder();
// 如果给定的商品不存在,则返回-1表示失败
scriptBuilder.append("local stock = tonumber(redis.call('GET', KEYS[1])) ");
scriptBuilder.append("if stock > 0 then ");
scriptBuilder.append("redis.call('DECRBY', KEYS[1], tonumber(ARGV[1])) ");
scriptBuilder.append("return 1 ");
scriptBuilder.append("end ");
scriptBuilder.append("return -1 ");
String scriptStr = scriptBuilder.toString();
// 执行Lua脚本
RScript script = redisson.getScript();
Object result = script.eval(RScript.Mode.READ_WRITE,
scriptStr,
RScript.ReturnType.INTEGER,
// 传参 KEYS[]
Collections.singletonList("stock_lua_" + id),
// 传参 ARGV[]
count);
return (Long) result > 0;
}
通过lua脚本保证原子性,结合Redis的优点,能够在大量并发下快速的处理读写请求
总结
本篇文章以防止商品超卖为案例,从Java层面到中间件层面描述各种场景下用不同的方式来解决并发读写可能引起的数据不一致性问题
确保服务一直为单节点时在并发量较少的场景,可以使用本地锁synchronized、Lock,Lock可以超时等待避免大量请求阻塞
如果服务一直为单节点时在并发量较高的场景,可以把库存数据放到内存中操作,再异步同步数据库,宕机可能导致部分数据丢失
服务目前为单节点,以后可能会增加节点的场景,可以使用MySQL新增版本号字段做乐观锁
服务目前为单节点以后一定会增加节点或目前就是分布式并且并发较少的场景,可以使用分布式锁
分布式系统并且读写请求并发大,可以考虑把数据预热到Redis中,直接读写Redis,再MQ异步更新MySQL,并且使用lua脚本保证读写原子性
🌠最后(不要白嫖,一键三连求求拉~)
本篇文章被收入专栏 由点到线,由线到面,深入浅出构建Java并发编程知识体系、复杂场景设计,感兴趣的同学可以持续关注喔
本篇文章笔记以及案例被收入 Gitee-CaiCaiJava、 Github-CaiCaiJava,除此之外还有更多Java进阶相关知识,感兴趣的同学可以starred持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多技术干货,公众号:菜菜的后端私房菜















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









