






 本文探讨了在SYCL中选择工作组大小对kernel性能的影响,强调了work-group大小对资源利用和通信效率的重要性,并给出了调整OpenMPoffload中工作组大小以优化性能的例子。
本文探讨了在SYCL中选择工作组大小对kernel性能的影响,强调了work-group大小对资源利用和通信效率的重要性,并给出了调整OpenMPoffload中工作组大小以优化性能的例子。
本章节翻译by chenshusmail@163.com 原文:Considerations for Selecting Work-Group Size (intel.com)
目录
使用 OpenMP offload 模式调整带有本地和全局 work-group 大小的 kernel
在 SYCL 中,您可以为 nd_range kernel 选择 work-group 大小。 work-group 的大小对计算资源,向量通道和 work-item 之间的通信的利用率具有重要影响。 同一 work-group 中的 work-item 可能具有对 SLM 和硬件同步功能等硬件资源的访问权限, 这将使它们比跨 work-group 的 work-item 运行和通信更高效。因此, 通常应选择加速器支持的最大 work-group 大小。可以通过调用 device::get_info<cl::sycl::info::device::max_work_group_size>() 来查询最大 work-group 大小。
为了说明 work-group 大小选择的影响,请查看以下归约 kernel, 它遍历一个大型向量以添加其中所有元素。 运行 kernel 的函数以 work-group-size 和 sub-group-size 为入参,这使您可以使用不同的值进行实验。 当 kernel 使用不同的 work-group 大小值调用时,可以从报告的时间统计中看到性能差异。
void reduction(sycl::queue &q, std::vector<int> &data, std::vector<int> &flush,
int iter, int work_group_size) {
const size_t data_size = data.size();
const size_t flush_size = flush.size();
int sum = 0;
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
// int vec_size =
// q.get_device().get_info<sycl::info::device::native_vector_width_int>();
int num_work_items = data_size / work_group_size;
sycl::buffer<int> buf(data.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
sycl::buffer<int> sum_buf(&sum, 1, props);
init_data(q, buf, data_size);
double elapsed = 0;
for (int i = 0; i < iter; i++) {
q.submit([&](auto &h) {
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(1, [=](auto index) { sum_acc[index] = 0; });
});
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
// reductionMapToHWVector main begin
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] {
auto v =
sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
sum_acc[0]);
int sum = 0;
int glob_id = item.get_global_id();
int loc_id = item.get_local_id();
for (unsigned int i = glob_id; i < data_size; i += num_work_items)
sum += buf_acc[i];
scratch[loc_id] = sum;
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (loc_id < i)
scratch[loc_id] += scratch[loc_id + i];
}
if (loc_id == 0)
v.fetch_add(scratch[0]);
});
});
q.wait();
elapsed += timer.Elapsed();
sycl::host_accessor h_acc(sum_buf);
sum = h_acc[0];
}
elapsed = elapsed / iter;
std::string msg = "with work-groups=" + std::to_string(work_group_size);
check_result(elapsed, msg, sum);
} // reduction end在下面的代码中,上述 kernel 被调用了两个不同的值: 2*vec-size 和加速器支持的最大可能 work-group 大小。 当 work-group 大小等于 2*vec-size 时,kernel 的性能将低于 work-group 大小为最大可能值时的性能。
int vec_size = 16;
int work_group_size = vec_size;
reduction(q, data, extra, 16, work_group_size);
work_group_size =
q.get_device().get_info<sycl::info::device::max_work_group_size>();
reduction(q, data, extra, 16, work_group_size);在没有使用 barrier 或原子操作的情况下,work-group 大小不会影响性能。为了说明这一点,请参考以下 vec_copy kernel,其中没有使用原子操作或 barrier。
void vec_copy(sycl::queue &q, std::vector<int> &src, std::vector<int> &dst,
std::vector<int> &flush, int iter, int work_group_size) {
const size_t data_size = src.size();
const size_t flush_size = flush.size();
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
int num_work_items = data_size;
double elapsed = 0;
{
sycl::buffer<int> src_buf(src.data(), data_size, props);
sycl::buffer<int> dst_buf(dst.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
for (int i = 0; i < iter; i++) {
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
q.submit([&](auto &h) {
sycl::accessor src_acc(src_buf, h, sycl::read_only);
sycl::accessor dst_acc(dst_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item)
[[intel::reqd_sub_group_size(16)]] {
int glob_id = item.get_global_id();
dst_acc[glob_id] = src_acc[glob_id];
});
});
q.wait();
elapsed += timer.Elapsed();
}
}
elapsed = elapsed / iter;
std::string msg = "with work-group-size=" + std::to_string(work_group_size);
check_result(elapsed, msg, dst);
} // vec_copy end在下面的代码中,上述 kernel 调用了不同的 work-group 大小。 所有上述对 kernel 的调用都将具有类似的运行时间,这表明 work-group 大小对性能没有影响。 原因是当 work-group 中没有 barrier 或 SLM 时, work-group 内创建的线程和来自不同 work-group 的线程在调度和资源分配方面表现相似。
int vec_size = 16;
int work_group_size = vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 2 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 4 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 8 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 16 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);在某些加速器中,由于线程在处理元素之间的调度方式,需要最小的 sub-group 大小才能获得良好的性能。 在这种情况下,当 sub-group 数量小于最小值时,您可能会看到很大的性能差异。 上面第3行对 kernel 的调用只有一个 sub-group,而第5行的调用有两个 sub-group。 在一次执行两个 sub-group 调度的加速器上测试,这两个 kernel 调用的计时将显示出明显的性能差异。
使用 OpenMP offload 模式调整带有本地和全局 work-group 大小的 kernel
上述用于调整 SYCL 中加速器设备上 kernel 性能的方法也适用于通过 OpenMP 在 offload 模式下的实现。 可以使用 OpenMP 指令自定义应用程序 kernel,以使用适当的 work-group 大小。 但是,这可能需要对代码进行大量修改。OpenMP 实现提供了使用环境变量自定义调整 kernel 的可选项。 可以使用两个环境变量 – OMP_THREAD_LIMIT 和 OMP_NUM_TEAMS 来自定义应用程序中 kernel 的本地和全局 work-group 大小,如下所示, 它们有助于设置本地 work-group 大小 (LWS) 和全局 work-group 大小 (GWS):
LWS = OMP_THREAD_LIMIT
GWS = OMP_THREAD_LIMIT * OMP_NUM_TEAMS借助以下归约 kernel 示例,我们展示了在加速器设备上调整 kernel 性能时使用 LWS 和 GWS 的方法。
int N = 2048;
double* A = make_array(N, 0.8);
double* B = make_array(N, 0.65);
double* C = make_array(N*N, 2.5);
if ((A == NULL) || (B == NULL) || (C == NULL))
exit(1);
int i, j;
double val = 0.0;
#pragma omp target map(to:A[0:N],B[0:N],C[0:N*N]) map(tofrom:val)
{
#pragma omp teams distribute parallel for collapse(2) reduction(+ : val)
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
val += C[i * N + j] * A[i] * B[j];
}
}
}
printf("val = %f10.3\n", val);
free(A);
free(B);
free(C);例如,通过配置 OMP_THREAD_LIMIT = 1024 和 OMP_NUM_TEAMS = 120, 分别将 LWS 和 GWS 参数设置为 1024 和 122880。
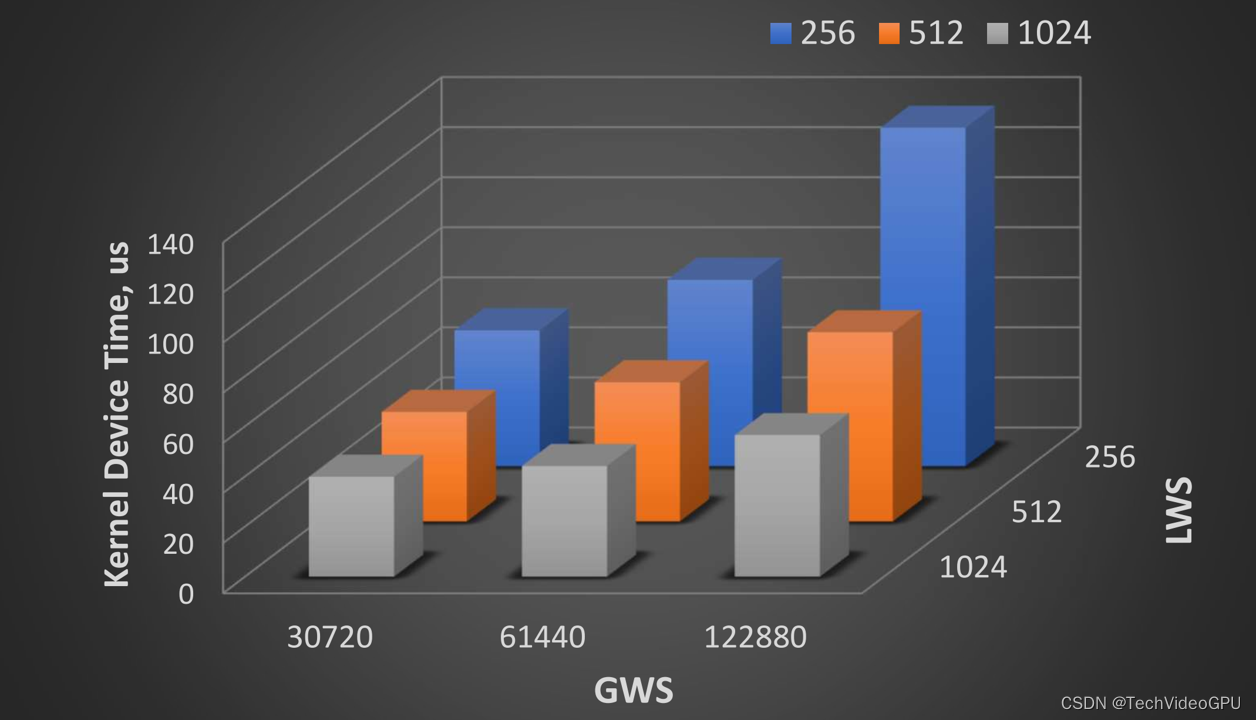
上图显示,此 kernel 的最佳性能来自 LWS = 1024 and GWS = 30720,这对应于 OMP_THREAD_LIMIT = 1024 和 OMP_NUM_TEAMS = 30。这些环境变量将为通过 OpenMP offload 的所有 kernel 将 LWS 和 GWS 值设置为固定数字。但是, 这些环境变量不会影响 OneMKL 等高度调优的库 kernel 使用的 LWS 和 GWS。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









