






本章节翻译by weavingtime@formail.com 原文:Intel® Xe GPU Architecture
目录
Xe-HPC 2-Stack Data Center GPU Max
Xe- Intel® Data Center GPU Flex Series
Terminology and Configuration Summary
Intel® Xe 家族由集成/低功耗(Xe-LP) ,发烧友/高性能游戏(Xe-HPG), 数据中心/AI(Xe-HP) 和高性能计算(Xe-HPC)一系列微架构组成
 Intel® Iris® Xe family
Intel® Iris® Xe family
本章介绍 Xe 的微架构和配置参数。
Xe-LP 执行单元 (EUs)
执行单元(EU)是 Intel® Iris® Xe-LP GPU架构的最小线程级构建块。每个EU同时 具有七个硬件线程(SMT)。主计算单元由一个8宽和一个2宽单指令多 数据(SIMD)算术逻辑单元(ALU)组成。8宽的SIMD ALU可以支持 SIMD8 FP/INT(浮点/整形)操作。2宽SIMD ALU支持SIMD2扩展数学运算。 每个硬件线程具有128个32B宽的通用寄存器(GRF)。
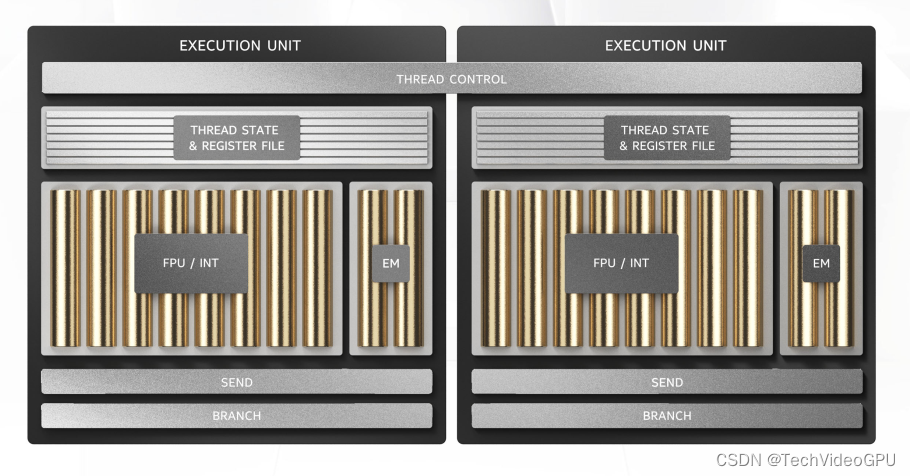 Xe-LP-EU
Xe-LP-EU
Xe-LP EU 支持 AI FP16、INT16 和 INT8的多种数据类型应用程序。
Intel® Iris® Xe-LP GPU Compute Throughput Rates (Ops/clock/EU) 表显示了 Xe-LP GPU 针对各种数据类型的 EU 操作吞吐量.
| FP32 | FP16 | INT32 | INT16 | INT 8 |
|---|---|---|---|---|
| 8 | 16 | 8 | 16 | 32 (DP4A) |
Xe-LP Dual Subslices
每个 Xe-LP DSS(Dual Sub-slice) 包含一个由16个 EU组成的 阵列, 一个指令缓存,一个本地线程调度程序,一个SLM(Shared Local Memory), 以及128B/周期的数据端口。它被称为DSS是因为硬件可以把两个 EU 配对用于 执行SIMD16 操作。
EU可以访问大小为128KB的低延迟高带宽内存SLM。SLM 的一项重要用途是在 work-item之间共享需要原子操作的数据和信号。因此,如果内核的work-group 包含同步操作,work-group的所有work-item必须是在同一个subslice内, 以便它们可以共享访问同一个 128KB SLM。 开发者必须仔细选择work-group的 大小来最大化subslice的利用率。 相反,如果一个kernel不访问SLM, 它的work-item可以跨多个subslice。
下表总结了 Intel® Iris® Xe-LP subslice的计算能力。
| EUs | Threads | Operations |
|---|---|---|
| 16 | 7×16=112 | 112×8=896 |
Xe-LP Slice
每个 Xe-LP Slice由六个DSS组成,总共有 96 个 EU, 最多 16MB 的 L2 缓存,128B/周期的 L2 带宽和 128B/周期 的内存带宽。

Xe-LP slice#
Xe-Core#
Xe-HPG 和 Xe-HPC与使用EU作为计算单元的 Xe-LP以及 前几代 Intel GPU 不同,Xe-HPG 和 Xe-HPC使用类似于 Xe-LP 的DSS Xe-core。
Xe-core 包含矢量和矩阵 ALU,分别称为矢量和矩阵引擎。
Xe-HPC GPU 的 Xe-core 包含 8 个矢量和 8 个矩阵引擎, 以及一个 512KB L1 SLM。 Intel® 数据中心 GPU Max 系列 都使用了这种 Xe-core。每个矢量引擎宽度为 512 比特, 结合FMA可以支持 16 个 FP32 SIMD 操作。 有了 8 个矢量引擎, Xe-core 每周期可提供 512 个 FP16或256 个 FP32 或 256 个 FP64 操作。矩阵引擎的宽度为 4096 比特。有了 8 个矩阵 引擎, Xe-core 每周期可提供 8192 个 int8 和 4096 个 FP16/BF16 操作。 Xe-core 向内存系统提供每周期 1024B 的 加载/存储带宽

Xe-core
Xe-Slice#
一个 Xe-slice 包含 16 个 Xe-core,总共有 8MB 的 L1 缓存,16 个光线追踪单元和 1 个硬件上下文。

Xe-slice#
Xe-Stack
一个 Xe-stack 最多包含 4 个 Xe-slice:64 个 Xe-core,64 个光线追踪单元,4 个硬件上下文, 4 个 HBM2e 控制器,1 个媒体引擎和 8 条高速一致性 织物的 Xe-Link。它还包含一个共享的 L2 缓存。

Xe-stack
Xe-HPC 2-Stack Data Center GPU Max
Xe-HPC 2-stack 数据中心 GPU Max系列之前代号为 Ponte Vecchio 或 PVC,它最多由 2 个stack组成: 8 个slice,128 个 Xe-core,128 个光线追踪单元, 8 个硬件上下文,8 个 HBM2e 控制器和 16 条 Xe-Link。

Xe-HPC 2-Stack#
Xe-HPG GPU
Xe-HPG 是 Xe 架构发烧友和高性能游戏系列的变体。这种微架构专注于图形性能,并支持硬件加速光线追踪。
Xe-HPG GPU 的 Xe-core 包含 16 个矢量引擎和 16 个矩阵引擎。它为 Intel® Arc GPU 提供动力。 每个矢量引擎宽度为 256 比特,结合FMA,可以支持 8 个 FP32 SIMD 操作。有了 16 个矢量引擎,Xe-core 每周期可提供 256 个 FP32 操作。每个矩阵引擎宽度为 1024 比特。 有了 16 个矩阵引擎,Xe-core 每周期可提供4096个 int8 或者2048个 FP16/BF16 操作。Xe-core 向内存系统提供每周期512B的加载/存储带宽。
一个 Xe-HPG GPU 包含8个 Xe-HPG-slice,其中最多包含4个 Xe-HPG-core,总共有4096个 FP32 ALU 单元/着色器(shader)核心
Xe- Intel® Data Center GPU Flex Series
Intel® 数据中心 GPU Flex 系列有两种配置。150W 的配置在 PCIe Gen4 卡上有 32 个 Xe-core。75W 的配置有两个 GPU共 16 个 Xe-core(每个 GPU 8 个 Xe-core)。两种配置都配备了 4 个 Xe media引擎,具有行业首款 AV1 硬件编码器和数据中心加速器,GDDR6 内存,光线追踪单元和内置 的XMX AI 加速。
Intel® 数据中心 GPU Flex 系列是 Xe-HPG GPU 的衍生产品。一个 Intel® 数据中心 GPU Flex 170 包含 8 个 Xe-HPG-slice,总共有 32 个 Xe-core,具有 4096 个 FP32 ALU 单元/shader(着色器)核心。
针对数据中心云游戏、视频流媒体和视频分析应用,Intel® 数据中心 GPU Flex 系列提供硬件加速的 AV1 编码器,在不影响质量的情况下可以节省30%的比特率。每张卡最多支持8路4K视频流或超过30路1080p视频流。利用 Intel® 数据中心 GPU Flex 系列的 Xe-core,应用程序可以在解码之后的视频图像数据上使用AI 模型进行推理。
视频流媒体和传输软件栈依赖于 Intel® oneVPL 来加速所有主流视频格式(包括 AV1)的解码和编码。视频内容分销商可以从两个主流的媒体框架 FFMPEG 或 GStreamer 中选择一个架构来开发应用程序,两者都支持在 Intel CPU 和 GPU 上使用 oneVPL 进行加速。
在oneVPL 加速视频流编解码的同时,oneDNN(oneAPI 深度神经网络库)提供了针对 AI 优化的kernel,能够加速 TensorFlow 或 PyTorch 框架中的推理模型。应用程序也可以选择使用 OpenVINO 模型优化器和推理引擎来进一步加速推理,OpenVINO可以加快客户部署推理业务的速度。
Terminology and Configuration Summary
下面的表格 Architecture Terminology Changes 表将传统 GPU 术语(用于第 9 代至第 12 代 Intel® CoreTM 架构)映射到 Intel® Iris® Xe GPU(第 12.7 代及更高版本)架构范式中的新名称。
| Old Term | New Intel Term | Generic Term | New Abbreviation |
|---|---|---|---|
| Execution Unit (EU) | Xe Vector Engine | Vector Engine | XVE |
| Systolic/”DPAS part of EU” | Xe Matrix eXtension | Matrix Engine | XMX |
| Subslice (SS) or Dual Subslice (DSS) | Xe-core | NA | XC |
| Slice | Render Slice / Compute Slice | Slice | SLC |
| Tile | Stack | Stack | STK |
下面的表格 Xe Configurations 列出了 Xe 系列GPU的硬件特征。
| Architecture | Xe-LP (TGL) | Xe-HPG (Arc A770) | Xe-HPG (Data Center GPU Flex 170) | Xe-HPC (Data Center GPU Max 1550) |
|---|---|---|---|---|
| Slice count | 1 | 8 | 8 | 4 x 2 |
| XC (DSS/SS) count | 6 | 32 | 32 | 64 x 2 |
| XVE (EU) / XC | 16 | 16 | 16 | 8 |
| XVE count | 96 | 512 | 512 | 512 x 2 |
| Threads / XVE | 7 | 8 | 8 | 8 |
| Thread count | 672 | 4096 | 4096 | 4096 x 2 |
| FLOPs / clk - single precision, MAD | 1536 | 8192 | 8192 | 16384 x 2 |
| FLOPs / clk - double precision, MAD | NA | NA | NA | 16384 x 2 |
| FLOPs / clk - FP16 DP4AS | NA | 65536 | 65536 | 262144 x 2 |
| GTI bandwidth bytes / unslice-clk | r:128, w:128 | r:512, w:512 | r:512, w:512 | r:1024, w:1024 |
| LL cache size | 3.84MB | 16MB | 16MB | up to 408MB |
| SLM size | 6×128KB | 32×128KB | 32×128KB | 64×128KB |
| FMAD, SP (ops / XVE / clk) | 8 | 8 | 8 | 16 |
| SQRT, SP (ops / XVE / clk) | 2 | 2 | 2 | 4 |

















 5429
5429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









