







正则表达式必知必会
本文共有2571字,阅读耗费11分钟。本文首发于个人博客:http://tanlehua.top/posts/tech/others/learn-regex/
什么是正则表达式
一(fei)言(hua)蔽(shao)之(shuo),使用单个表达式来描述句法规则,用来匹配出符合这一句法规则的字符串。
使用场景
- 批量提取/替换有规律的字符串
- 用户输入的合法性验证
- 网络爬虫
- 此处省略六点……
善假于物
推荐大家使用RegexBuddy这个强大好用的神器来学习和使用正则表达式,文章底部有下载链接,有能力请支持正版。
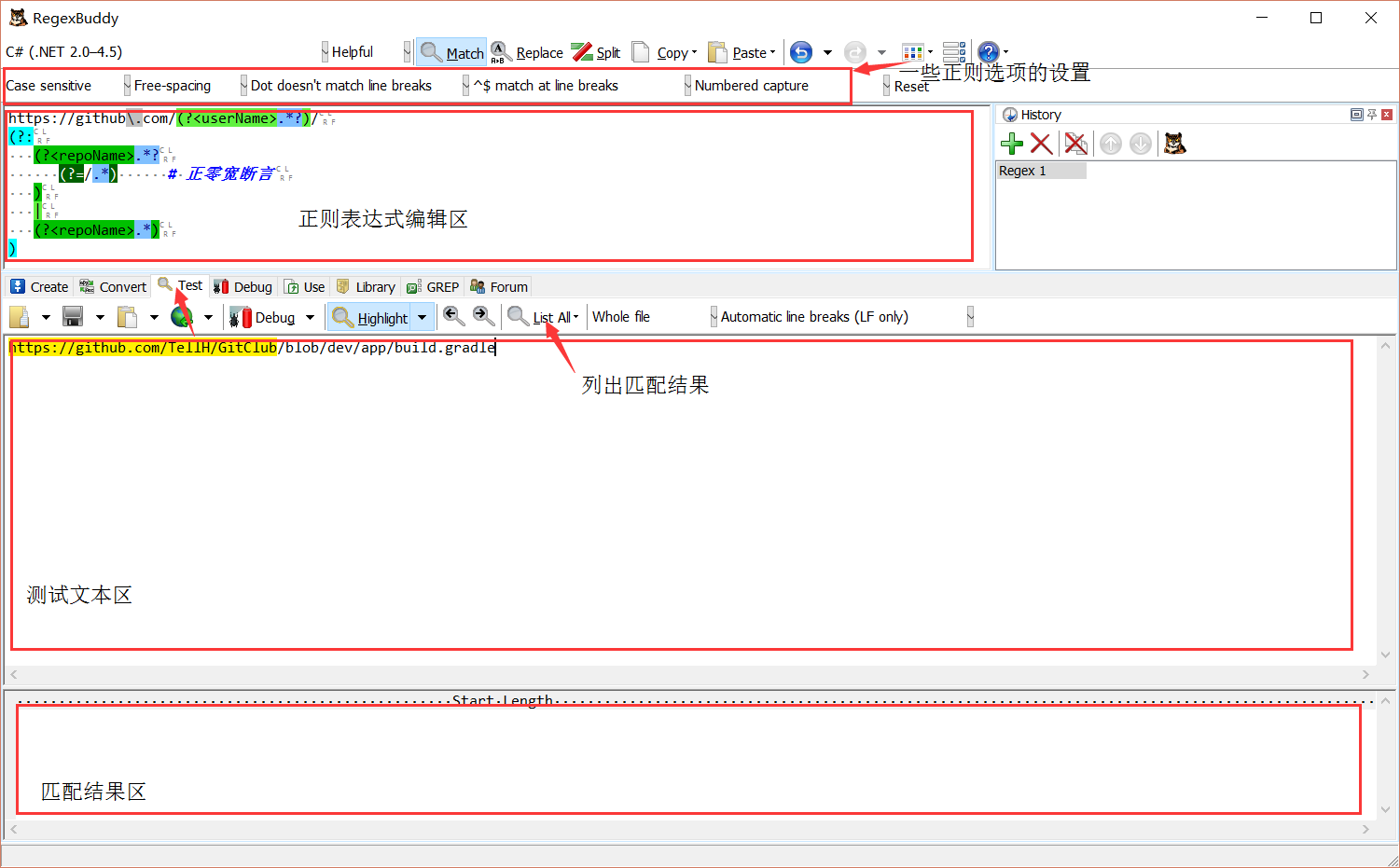
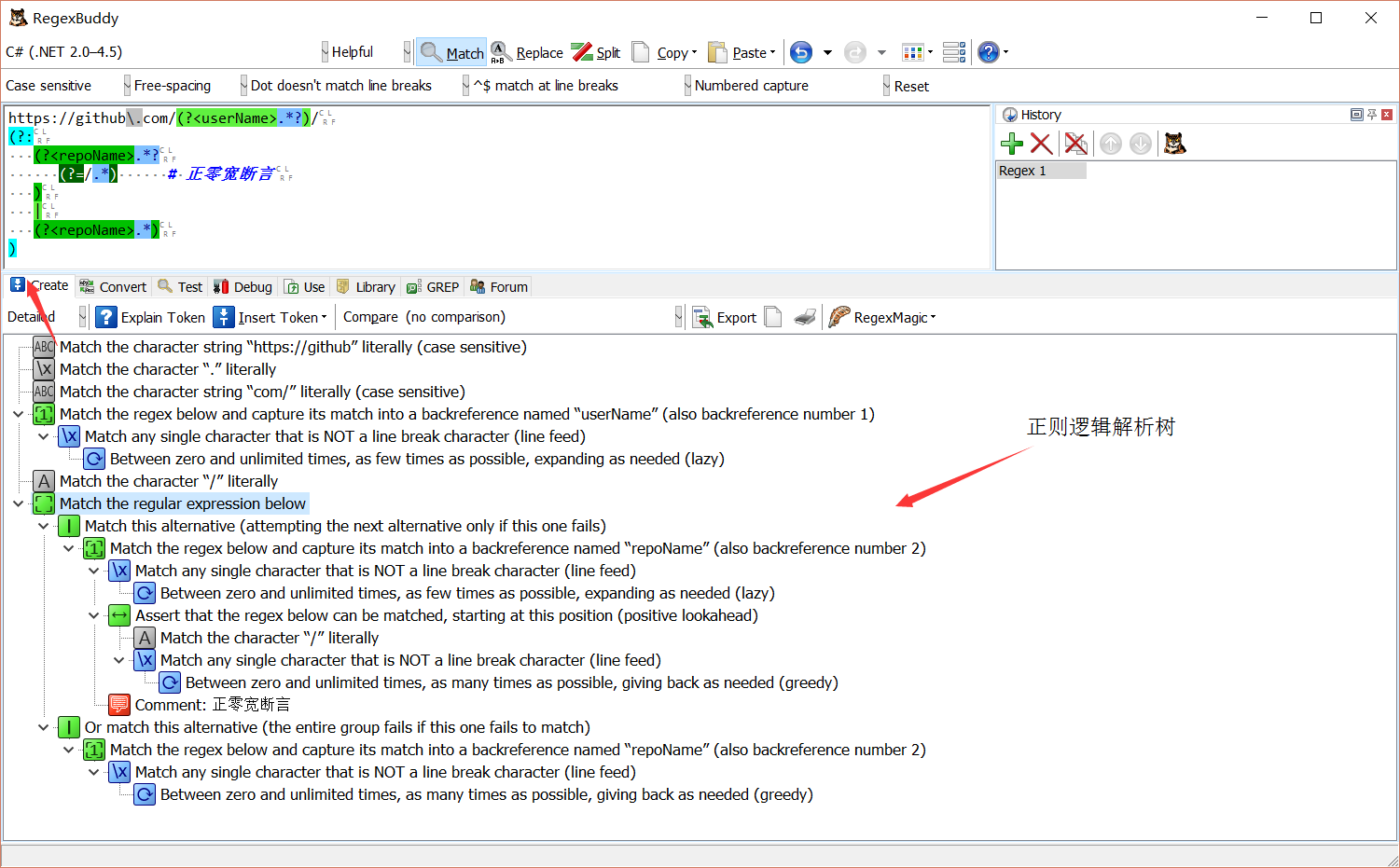
元字符
正则表达式可以理解成一门描述语言,而元字符可以理解成不可再分的关键字(key word)。
测试栗子:
String in Java is very useful. What am I doing? I am building Structure. I am ingenious!
Ring is on.
下文“任意”的意思可以理解为“所有”。
.点号匹配除换行符以外的任意字符\w匹配任意字母/下划线/数字/汉字\s匹配出现的任意空格\d匹配数字\b匹配单词的开始或结束。比如ing/b匹配以ing结尾的单词,而\bing则匹配以ing开头的单词。^匹配字符串的开始$匹配字符串的结束。[abc]匹配abc这几个字符。[0-5]匹配0到5这几个数字。[a-z]匹配所有小写的字母。[a-z0-9A-Z]匹配所有的字母和数字。
说明:
^与$的作用对象是单个字符串。字符串有两种划分方式,一种是把一段测试文本为一个完整的字符串,比如上面的栗子就是一个字符串;另一种是用回车换行符来划分字符串,比如当一段测试文本有2个回车换行符(有3行),那么这段文本就有3个字符串。而单词是用空格来划分的,这样字符串和单词的区别就很明显了吧
那么,若用回车换行符来划分字符串的模式,要想匹配上述的测试栗子的第一行,可以用^S.*!$,表达的意思是被匹配的字符串必须以’S’开头,中间允许有若干个字符,但结尾必须是’!’。
那它们与\b有什么区别呢?\b的作用对象是单个字符,比如我想匹配上述的测试栗子中以ing结尾的的单词,可以用\w*ing\b


反义
\W匹配不是字母/下划线/数字/汉字的字符\S匹配任意的不是空格的字符\D匹配不是数字的字符\B匹配不是单词开头或结束的位置。[^x]匹配除x以外的任意字符[^asS]匹配除asS这几个字母以外的任意字符

重复模式
单靠元字符来做正则表达式匹配是远远无法满足我们对海量字符串中匹配所要字符串的需求的,所以需要学习使用正则表达式的重复模式。下面的一些控制重复的字符需要跟在匹配表达式的后面。
*重复零次或多次。这是汇编原理里面关于星闭包的概念。 比如\w匹配的是字母/下划线/数字/汉字的单个字符,而\w*匹配的是任意长度的单词。+重复一次或多次。?重复零次或一次。比如\b.?ing\b可以匹配上面栗子中Ring这个单词。{n}重复n次。{n,}重复n到正无穷次。{n,m}重复n次到m次。
贪婪与懒惰 Greedy&Lazy
这是两个非常重要的概念。
用默认的重复模式来匹配字符串用的是贪婪模式,它会尽可能多地匹配文本。
而在上述重复符号后面加上?即可启动懒惰模式(如*? +? ?? {n}?等),它会尽可能少地匹配文本。
比如:
a.*b (aababcc) -> aabab 贪婪模式遇到最后一个b时才完成匹配。
a.*?b (aababcc)-> aab 懒惰模式只要遇到b就完成匹配。
分支条件
用|把每个条件分隔开,如(条件一)|(条件二) ,从左到右测试每个条件,如果满足就匹配,不满足则测试下一个条件直到测试完所有条件为止。
分组
Why:
有时我们需要整体匹配后,在其中进行局部的字符串提取,这时就需要用到分组了。比如在一个url字符串中,我需要提取出域名。这需要先匹配出”http://”头部,接着利用分组匹配提取出域名。
How:
使用()括号划分正则式来分组。
More:
- 用
(?<groupname>exp)进行分组命名。默认地,每个括号所划分的组都用数字索引标记,如果括号之间嵌套过多容易造成混乱,所以用自定义分组命名比较方便明了。 - 用
(?:exp)匹配文本但不为此分组编号。因为给分组编号或命名的目的是便于我们提取匹配出来的文本,但很多时候加括号并不是为了要局部把文本提取出来。
比如匹配Url的正则式:
\b(?<protocol>https?|ftp)://(?<domain>[-a-zA-Z0-9.]+)(?<file>/[-a-zA-Z0-9+&@#/%=~_|!:,.;]*)?(?<parameters>\?[a-zA-Z0-9+&@#/%=~_|!:,.;]*)?
其中(?<domain>[-A-Z0-9.]+) 就用到了分组匹配的方式提取域名,表达意思是字母或数字或’-‘或’.’出现一次或n多次的字符串,遇到’/’停止。
高阶玩法
- 向后引用
场景:有时需要将分组提取出来的文本在后面重复多次匹配。如”Good,very Good”需要匹配两次Good。
- 可以用
(Good).*\1来匹配。即\groupNum转义字符加上分组编号即可。 也可以用
(?<txt>Good).*\k<txt>来匹配。即\<groupName>转义字符加上分组名即可。- 零宽断言
断言就是判断真假,只有断言为真时,正则表达式才会往下匹配。通常来说,用一般的正则式匹配出来的文本都是要占一定宽度的。如何理解?
比如,现在有一测试文本”Script JavaScript ShellScript Javac Java”。
要匹配”JavaScript”中的”Script”,若用\bJava这个断言的话,”Java” 就会在匹配出来的文本中占4个宽度。
怎么让”Java”不出现在匹配出的文本当中,又能表达作为匹配文本前缀的断言作用呢?零宽断言就是为此而生。
正向零宽断言:
(?<=\bJava)Script匹配出以”Java”为前缀的”Script”。即”Script Java**Script** ShellScript Javac Java”。Java(?=Script\b)匹配出以”Script” 为后缀的”Java“。即”Script **Java**Script ShellScript Javac Java”。
注意,它们上面两种断言语法的细微差异,当原来的要占位断言表达式在前面,用(?<=exp)包住表达式;当原来的要占位的断言表达式在后面,用(?=exp)包住表达式。下面的负向零宽断言也差不多。
负向零宽断言:
Java(?!c)匹配出后面不跟”c”的”Java”。即”Script Java**Script ShellScript Javac **Java“。(?<!a)Script匹配出前一个字符不是”a”的”Script”。 即”Script JavaScript Shell**Script** Javac Java”
实战
想必大家都用过Github,Github的repository的URL是有规律的:
https://github.com/{userName}/{repoName}/{...}
我们要做的很简单,就是匹配提取出userName和repoName。
测试文本:
- “https://github.com/TellH/GitClub/blob/dev/app/build.gradle”
- https://github.com/TellH/GitClub/
https://github.com/TellH/GitClub
- 先匹配前缀,很自然想到了
https://github.com/,但别忘了对’.’转义,因为点号是元字符,即
- 先匹配前缀,很自然想到了
https://github\.com/
- 先提取userName,要用分组匹配:
https://github\.com/(.*)/
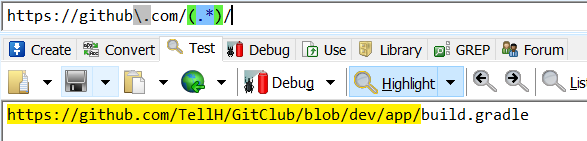
咦,什么鬼,怎么匹配到了最后一个”/”。原来默认匹配模式是贪婪模式,需要改成懒惰模式:
https://github\.com/(.*?)/
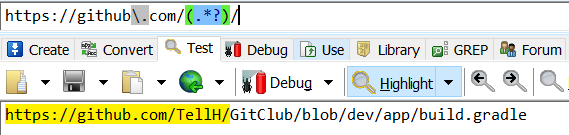
- 接着再分组提取RepoName。
https://github\.com/(.*?)/(.*?)
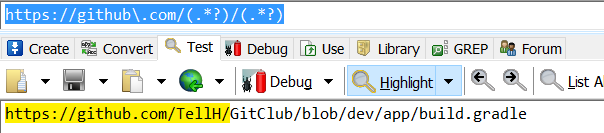
发现,它懒惰过头了,竟然一个字符也不匹配。
我们来分析一下,RepoName后面如果还有内容,那必须后面紧跟着”/”,并且应该用懒惰模式。
而如果RepoName后面没有内容了,比如第三个测试文本,那就应该用贪婪模式,将剩余的全部字符作为RepoName。
因此,我们需要用分支条件:
https://github\.com/(.*?)/
(
(
(.*?)/.* #RepoName后面如果还有内容,那必须后面紧跟着"/",并且应该用懒惰模式
)
|
(.*) #RepoName后面没有内容了,那就应该用贪婪模式,将剩余的全部字符作为RepoName
)因为括号嵌套过多,我们可以用(?<groupname>exp)对感兴趣的分组进行命名,并且用(?:exp)屏蔽其他无用的分组:
https://github\.com/(?<userName>.*?)/
(?:
(?:
(?<repoName>.*?)/.*
)
|
(?<repoName>.*)
)
值得注意的是,Java对分组命名的支持不太好,分组的命名不能有重复。而且各种编程语言对正则表达式的支持可能有所差异。
- 然而就这样结束了吗?还不够好,因为我们在第4行中的
/.*把多余的”/”也匹配进来了,怎么样这些多余部分不占位呢?这时应该想到零宽断言了吧。
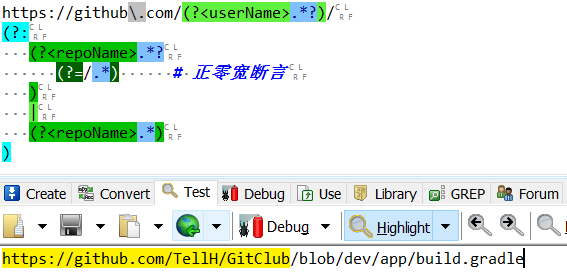
https://github\.com/(?<userName>.*?)/
(?:
(?<repoName>.*?
(?=/.*) # 正零宽断言
)
|
(?<repoName>.*)
)
- 大功告成!然而就这样结束了吗?其实据我了解,Github的UserName和RepoName中是不允许有”/”的,所以正则式只需简单地用:
https://github\.com/([^/]*)/([^/]*)
哈哈,有种被耍的感觉,但通过这个比较简单而全面栗子,我们算是掌握正则表达式的大部分用法了。
干货
RegexBuddy的安装包 ,有能力的请支持正版哈!















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









