








导语:本系列文章一共有三篇,分别是
《实践篇 | 推荐系统之矩阵分解模型》
第一篇用一个具体的例子介绍了MF是如何做推荐的。第二篇讲的是MF的数学原理,包括MF模型的目标函数和求解公式的推导等。第三篇回归现实,讲述MF算法在图文推荐中的应用实践。下文是第三篇——《实践篇 | 推荐系统之矩阵分解模型》,敬请阅读。
本文是MF系列文章中的最后一篇,主要讲的是MF算法在图文推荐中的应用实践。无论是在召回层还是精排层,MF都有发挥作用。在召回层,MF既可以做基于内容的召回,也可以做基于行为的召回,并且相比于其他召回算法,MF有着自身独到的优势。在精排层,MF可以用来对分类变量做embedding,产生具有判别性的低维稠密向量,供排序模型使用,提升排序的效果。
推荐系统通常有两层:召回层和精排层。召回层负责从数以百万的物品中快速地找到跟用户兴趣匹配的数百到数千个物品,而精排层负责对召回的物品打分排序,从而选出用户最感兴趣的top K物品。召回层在为精排层缩小排序范围的同时,也决定了推荐效果的上限。如果召回的内容不够准确,再厉害的排序模型也无法返回一个准确的推荐列表给用户。因此召回层很重要。常用的召回方法可以分为基于内容的召回和基于行为的召回。两种召回方法各有自己的优缺点,相互补充,共同提升召回的质量。
1.1基于内容的召回
基于内容的召回通过计算“用户-文章”或“文章-文章”的内容相似度,把相似度高的文章作为召回结果。内容相似度的计算仅使用内容数据。文章的内容数据有标签、一级分类、二级分类、正文、标题等,用户的内容数据就是用户的画像。通过用向量表示内容数据,计算出内容相似度。对于内容数据中的分类变量,可以对其one/multi-hot向量直接计算余弦相似度,也可以先对其做embedding,然后再计算余弦相似度。
基于内容的召回方法优点是可以召回时新文章。因为无论文章有多新,我们都可以获取到其内容数据,从而能计算内容相似度进行召回。缺点是召回内容可能会走向两个极端,比如用正文或标题的embedding可能会召回内容很相似的文章,从而降低了推荐的多样性。如果用一级分类或二级分类召回,粒度又太粗,可能会召回不太相关的内容,从而降低了推荐的准确性。
1.2基于行为的召回
基于行为的召回就是通过计算“用户-文章”或“文章-文章”的行为相似度,把相似度高的文章作为召回结果。行为相似度的计算仅使用用户行为数据。由于同一个用户在一段时间内的兴趣相对比较固定,点击的文章之间会有一定程度的相关性,所以从用户的行为数据中也能学到文章之间的相似性,即行为相似性。
计算行为相似度的经典方法是使用jaccard相似度公式或者cosine相似度公式。比如,文章A 和文章B 的行为相似度可由如下公式计算:
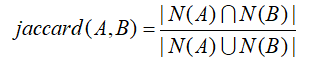
或

其中,N(A )、N(B )分别表示阅读过文章A 和文章B 的用户构成的集合时,|S |表示集合S的元素个数。当越多用户同时读过文章A 和文章B 时,A 和B 的相似性越高。
此外,还可以把行为数据表示为评分矩阵或共现矩阵,通过矩阵分解的方法把用户和文章都向量化,从而计算出“用户-文章”或“文章-文章”的余弦相似度。
基于行为的召回方法优点是能召回内容上不完全相似,但用户又感兴趣的文章,也就是既有相关性,又有多样性。因为用户阅读的文章会在自己的兴趣范围内发散开来,不会一直阅读几乎一样的内容,因此,用这种行为数据计算出来的相似文章既有相关性,又有一定程度的多样性。此外,由于行为相似度反映了大部分用户的行为习惯,更容易切中用户的需求,因此在点击率等指标上往往会比基于内容的召回更高。缺点是不能召回最新的文章,因为行为数据的产生需要时间,计算行为相似度也需要时间,在这些时间里涉及到的新文章是没办法用这种方法召回的。我们只能隔一段时间取最新的行为数据重新计算一次,也就是只能做到准时新召回。此外,基于行为的召回可能会出现假相关,即召回热度高但不相关的文章。
由于两种召回方法各有自己的优缺点,所以在实际应用中一般是采用多路召回的方式,相互补充,取长补短,最后汇总在一起给排序模型做精排。
矩阵分解既可以做基于内容的召回,也可以做基于行为的召回。无论是哪种类型的召回,矩阵分解方法都有着自己的优势。下面将分别介绍基于内容和基于行为的召回是如何应用矩阵分解的,以及它的优势所在。
2.1基于内容的MF召回
在图文推荐场景下,item是文章,文章的内容有标签、一级分类、二级分类、正文、标题等。其中,正文内容最为丰富。我们用文章正文作为语料库,分词后通过word2vec学习出每个词的词向量,对于每篇入库的文章,我们都可以用加权词向量的方法得到它的word2vec向量。在某一时刻,我们的文章库中有M 篇文章,这M 篇文章的向量就构成了一个文章矩阵,记为
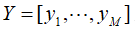
其中yi 为第i 篇文章的向量。记用户u
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1325
1325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









