







1. 通过三种方式抓取字段:
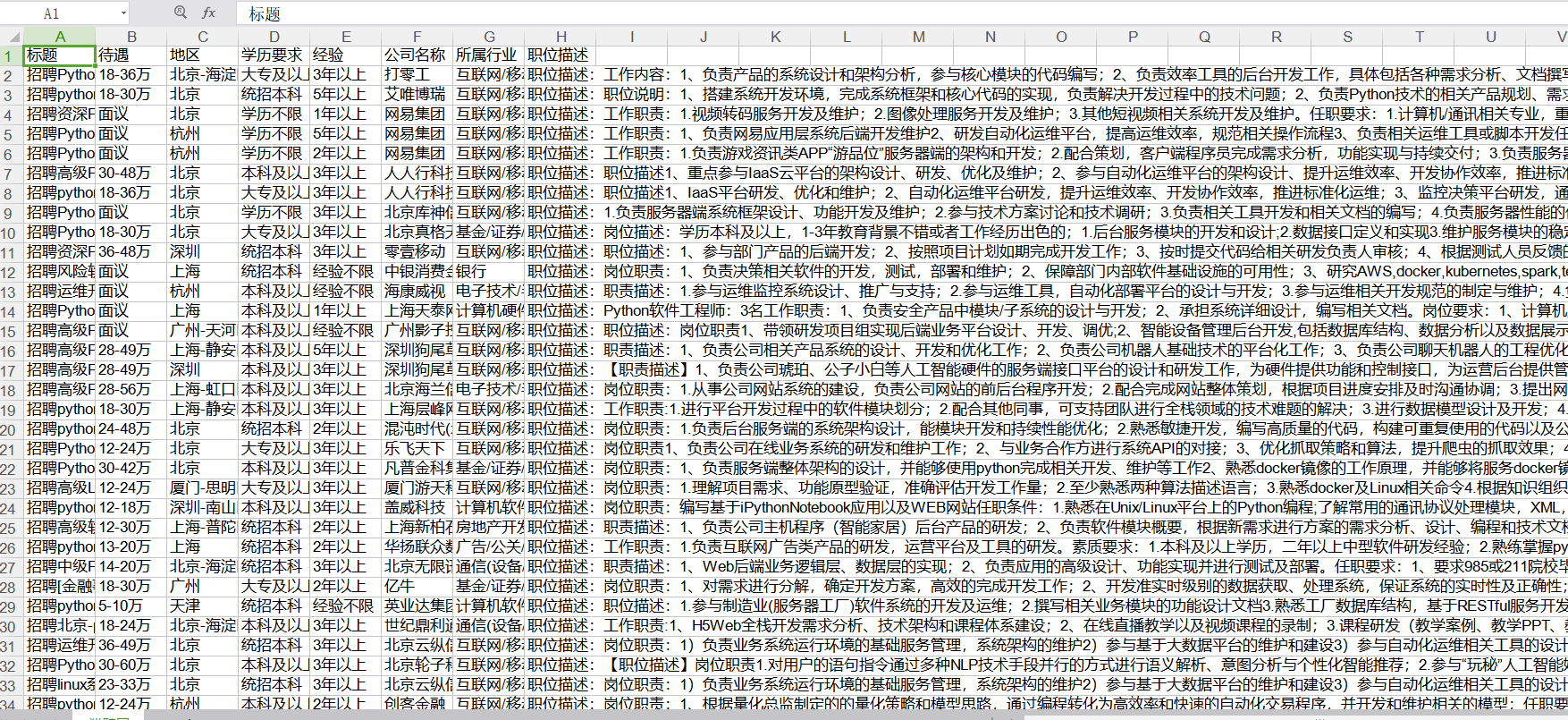
招聘标题 待遇 地区 学历要求 经验 公司名称 公司的行业 职位描述
2. 效果预览

3. 注意事项
* 利用xpath或者其它方式选取节点时,需要注意判断是否为None,如果在后面调用.strip()等方法肯定会报错,所以建议提取出一个共用的判断方法
* url拼接问题,当大部分详情页链接都有schema时,突然返回你一个没有https://等的链接,此时爬取肯定出错,所以建议使用parse.urljoin('https://www.liepin.com',url)方法拼接
* 建议使用bs4爬取时,选取select方法,能提高编程效率和避免一些由于class或其它属性有多个值的情况
4. 上代码
* 首先定义一个Spider类,其主要作用就是作为其它三种方式的父类,提取出共有的行为,学过Java的应该很好理解,它们都有请求数据,解析数据,请求工作详情数据,解析工作详情数据,解析数据的话,得让子类实现,所以此类需要设置为抽象类
* 由于上代码篇幅太长,直接上 代码传送门
* thank you for reading
招聘标题 待遇 地区 学历要求 经验 公司名称 公司的行业 职位描述
2. 效果预览
3. 注意事项
* 利用xpath或者其它方式选取节点时,需要注意判断是否为None,如果在后面调用.strip()等方法肯定会报错,所以建议提取出一个共用的判断方法
* url拼接问题,当大部分详情页链接都有schema时,突然返回你一个没有https://等的链接,此时爬取肯定出错,所以建议使用parse.urljoin('https://www.liepin.com',url)方法拼接
* 建议使用bs4爬取时,选取select方法,能提高编程效率和避免一些由于class或其它属性有多个值的情况
4. 上代码
* 首先定义一个Spider类,其主要作用就是作为其它三种方式的父类,提取出共有的行为,学过Java的应该很好理解,它们都有请求数据,解析数据,请求工作详情数据,解析工作详情数据,解析数据的话,得让子类实现,所以此类需要设置为抽象类
# coding=utf-8
import abc
import time
import requests
from ExeclUtils import ExeclUtils
# abstract class
class Spider():
__metaclass__ = abc.ABCMeta
def __init__(self):
self.row_title = ['标题','待遇','地区','学历要求','经验','公司名称','所属行业','职位描述']
sheet_name = "猎聘网"
self.execl_f, self.sheet_info = ExeclUtils.create_execl(sheet_name,self.row_title)
# add element in one data
self.job_data = []
# the data added start with 1
self.count = 0
def crawler_data(self):
'''
crawler data
'''
for i in range(0,5):
url = 'https://www.liepin.com/zhaopin/?industryType=&jobKind=&sortFlag=15°radeFlag=0&industries=&salary=&compscale=&key=Python&clean_condition=&headckid=4a4adb68b22970bd&d_pageSize=40&siTag=p_XzVCa5J0EfySMbVjghcw~fA9rXquZc5IkJpXC-Ycixw&d_headId=62ac45351cdd7a103ac7d50e1142b2a0&d_ckId=62ac45351cdd7a103ac7d50e1142b2a0&d_sfrom=search_fp&d_curPage=0&curPage={}'.format(i)
self.request_job_list(url)
time.sleep(2)
def request_job_list(self,url):
'''
get the job data by request url
'''
try:
headers = {
'Referer':'https://www.liepin.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
reponse = requests.get(url,headers = headers)
# utf-8
if reponse.status_code != 200:
return
self.parse_job_list(reponse.text)
except Exception as e:
# raise e
print('request_job_list error : {}'.format(e))
@abc.abstractmethod
def parse_job_list(self,text):
'''
parsing the data from the response
'''
pass
def request_job_details(self,url):
'''
request thr job detail's url
'''
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url,headers = headers);
# utf-8
if response.status_code != 200:
return
self.parse_job_details(response.text)
except Exception as e:
# raise e
print('request_job_details error : {}'.format(e))
@abc.abstractmethod
def parse_job_details(self,text):
'''
parsing the job details from text
'''
pass
def append(self,title,salary,region,degree,experience,name,industry):
self.job_data.append(title)
self.job_data.append(salary)
self.job_data.append(region)
self.job_data.append(degree)
self.job_data.append(experience)
self.job_data.append(name)
self.job_data.append(industry)
def data_clear(self):
self.job_data = []
def extract(self, data):
return data[0] if len(data) > 0 else ""* 由于上代码篇幅太长,直接上 代码传送门
* thank you for reading















 2265
2265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









