







从零开始爬的虫
前言
写这篇教程的时候我也是刚入坑,有不对或者是没有提及的部分还请各位见谅。我争取在升华之后来完善这篇教程
一、前情提要
1.基础知识
- http:服务端和客户端进行数据交换的一协议
- https:安全的超文本传输协议(http+s)
- 加密方式:1.对称密钥加密 2. 非对称密钥加密 3.证书密钥加密 - requests模块:python中原生的一款基于网络请求的模块,用于模拟浏览器发送请求
- UA伪装:门户网站的服务器会检测对应请求的载体身份标识,如果检测到的请求载体是浏览器没事,如果检测到不是,就有可能拒绝该次请求
2.html基础
HTML 指的是超文本标记语言: HyperText Markup Language

<!DOCTYPE html> 声明为 HTML5 文档
<html> 元素是 HTML 页面的根元素
<head> 元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8。
<title> 元素描述了文档的标题
<body> 元素包含了可见的页面内容
<h1> 元素定义一个大标题
<p> 元素定义一个段落
HTML 标签是由尖括号包围的关键词,比如 <html>
HTML 标签通常是成对出现的,比如 <b> 和 </b>
标签对中的第一个标签是开始标签,第二个标签是结束标签
开始和结束标签也被称为开放标签和闭合标签

3.网页操作
- 审查元素:
- 网址前面加上’view-source:’(防止反爬)
- 鼠标放到网址上,按下F12
- 直接F12
- 网页右键,检查(常用) - 判断元素是否是动态加载
- 页面element数据,找到对应元素
- 抓包工具,查看页面的response(ALL-当前页-Response),ctrl+f,查找数据
- 如果找得到,可以利用element获取数据
- 如果找不到,数据就是动态加载,去XHR,看请求,找参数,发送请求,获取response,提取对应元素
4.AJAX
一种可以实现页面局部刷新的技术
- 请求的发送:
- 用户从 UI 发送请求,JavaScript 中调用 XMLHttpRequest 对象(可扩展超文本传输请求)。
- HTTP 请求由 XMLHttpRequest 对象发送到服务器。
- 服务器使用 JSP,PHP,Servlet,ASP.net 等与数据库交互。
- 检索数据。
- 服务器将 XML 数据或 JSON 数据发送到 XMLHttpRequest 回调函数。
- HTML 和 CSS 数据显示在浏览器上。 - 工作流程:

5.请求和响应
-
请求:
请求头:

post请求和get请求:
与POST相比,GET 更简单也更快,并且在大部分情况下都能用。
然而,在以下情况中,请使用POST请求:
- 无法使用缓存文件(更新服务器上的文件或数据库)
- 向服务器发送大量数据(POST没有数据量限制)
- 发送包含未知字符的用户输入时,POST比GET更稳定也更可靠一般来说请求的参数较少或者无关紧要用get(id号等)
请求参数较多或比较重要用post(密码等)

这就是get请求携带的参数

-
响应
响应类型有很多种text、content、json、image等
响应头

这里就可以看见响应的具体内容
如果像这种类似于键值对的就是json

这种的就是javascript

这就是image

6.cookie和session
-
cookie:
Cookie 是在HTTP协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web服务器保存 在用户浏览器(客户端)上的小文本文件(内容通常经过加密),它可以包含有关用户的信息。无论何时用户链接到 服务器,Web站点都可以访问Cookie 信息,可以看作是浏览器缓存. -
session:
Session的定义很抽象,在不同的场合中session一词的含义也很不相同.它可以代表服务器与浏览器的一次会话过程,指从一个浏览器窗口打开到关闭的这个期间.也可以用于指一类用来在客户端与服务器之间保持状态的解决方案. -
使用:
cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器.具体内容可以去看我的这篇博客
还是讲的比较详细的
7.线程和进程
并发:一个cpu同时处理多个程序,但是再一个时间点只会处理一个
并行:多个cpu同时处理多个程序
同步:执行io操作时,等待执行完成才得到返回结果
异步:不必等执行三成就能得到返回结果
多线程是在一个cpu上创建多个子任务,当某个子任务休息时其他任务接着执行
多进程是利用多核cpu的优势,同时执行多个任务
协程的实现实在一个线程内实现的(线程切换的消耗大,所以对于并发编程,可以优先使用协程)
8.代理ip
说实话,我到现在还不会弄,没找到可以用的代理ip…
9.超级鹰
使用:
超级鹰官网,注册账号,注册项目,充值,开发文档选python(居然有易语言????)
根据指示来就行了,记得导包
二、通用爬虫
1.案例
案例:药监总局
思路:
1.通过element获取每个企业信息的href元素,通过在抓包工具中查看,搜索不到对应数据(在response中找不到),所以这个地址是动态加载出来的,需要发送请求
2.查看并构造参数,发送ajax请求(post携带参数),接受response(json类型)
3.提取id,再次构造参数和url,发送ajax请求,得到想要数据
import requests
if __name__ == '__main__':
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
id_list = []
for page in range(1, 6):
data = {
"on": "true",
"page": page,
"pageSize": "15",
"productName": "",
"conditionType": "1",
"applyname": "",
"applysn": ""
}
# response为一页的数据
json = requests.post(url=url, data=data, headers=headers).json()
id_list.clear()
# 提取json里面的'list'里面的'ID'
for dic in json['list']:
id_list.append(dic['ID'])
post_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for post_id in id_list:
# url拼接
data = {'id': post_id}
detail = requests.post(url=post_url, headers=headers, data=data).json()
print(detail)
三、聚焦爬虫
1.数据解析
提取html标签中我们想要获得的数据
2.方法
- 正则
- bs4
- xpath(推荐)
3.xpath
- 路径表达式:

- 谓语:
/div/tr[1] :选取属于 bookstore 子元素的第一个 book 元素。
/div/tr[last()] :选取属于 bookstore 子元素的最后一个 book 元素。
/div/tr[last()-1] :选取属于 bookstore 子元素的倒数第二个 book 元素。
//div[@id=‘log_in’] :选取所有div元素,且这些元素拥有值为 log_in 的 class 属性。
/div/tr[price>35.00] :选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
- 选取若干路径:
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
4.案例
古诗文网模拟登录
思路:
1.定位验证码,识别信息
2.在登录成功的页面获取参数信息,并且配置参数,发送请求
3.此时出现了问题:第二次发送后返回的是登录页面
4.原因:http协议特性:无状态。也就是说发送第二次请求时,服务器并不会知道是已经登录的状态
5.需要用cookie记录状态,用到session会话对象携带cookie
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
# 下载lxml模块
from lxml import etree
if __name__ == '__main__':
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400'
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# session会话对象 携带请求产生的cookie
session = requests.Session()
# 验证码识别(这里先蠢一点,不用超级鹰)
img_src = 'https://so.gushiwen.cn' + tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = session.get(url=img_src, headers=headers).content
with open('E:\\python-file/a.jpg', 'wb') as fr:
fr.write(img_data)
code_text = input('人眼识别验证码')
# 登录
login_url = 'https://so.gushiwen.cn/user/login.aspx'
data = {
'__VIEWSTATE': 'J+WuRAV4B/72GItcjC9ob6UNO1i0JoTIczXqRXVoXww8wUlRo3Xi8kLANgsQNCsS2Y8f2D1yNv6UNE98aAu0bJcKBtZUDKQ/4s+0Q//rUORWz/1Xt2sZL7UBi2U=',
'__VIEWSTATEGENERATOR': 'C93BE1AE',
"from": "http://so.gushiwen.cn/user/collect.aspx",
"email": "*********",
"pwd": "*********",
"code": code_text,
"denglu": '登录'
}
login_text = session.post(url=login_url, headers=headers, data=data).text
with open('E:\\python-file/gushiwen.html', 'w', encoding='utf-8') as fr:
fr.write(login_text)
四、增量爬虫
还没学,持续更新
五、异步爬虫
1.方式
- 多进程,多线程(不建议)
- 线程池,进程池
- 协程
2.线程池
先举个栗子,如果使用线程池
from multiprocessing.dummy import Pool
def fn(str):
print('beg' + str)
time.sleep(2)
print('end' + str)
if __name__ == '__main__':
beg = time.time();
li = ['a', 'b', 'c', 'd']
pool = Pool(len(li))
pool.map(fn, li)
end = time.time()
print(end - beg)
梨视频:
思路:
1.查看element里面的链接是不是在response里面,这里不在,也就是发送ajax请求,获取response里的信息
2.拼接得到一个url,查看并不是视频的链接(反爬机制)
3.查看视频正确链接,与得到的url对比,修正url(反反爬,因为正确的链接也是通过代码合成的)
4.将上述得到的url储存进list
5.开线程池进行下载
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
import time
import requests
from lxml import etree
import re
from multiprocessing.dummy import Pool
def get_url(item):
detail_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400',
# 这个referer就是表明是从哪里来的
'Referer': item['detail_url']
}
# 获取视频的url(发送ajax请求,根据返回json(在抓包工具里查看response)获取url)
# 这里我觉得可以用param带id和mrd参数发送get请求
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}'.format(item['id'], random.random())
video_url = requests.get(url=video_url, headers=detail_header).json()["videoInfo"]["videos"]["srcUrl"]
# url修正 (在ajax请求的返回里不是真正的url)
# re.sub(替换)(其中三个必选参数:pattern(要被替换的), repl(被替换成的), string(被处理的))
video_url = re.sub(r'16\d+-', r'cont-{}-'.format(item['id']), video_url)
# 保存视频url
item['video_url'] = video_url
def get_download(item):
# 异步下载
print(item['video_path'] + ' start')
video_text = requests.get(url=item['video_url'], headers=headers).content
with open(item['video_path'], 'wb') as fr:
fr.write(video_text)
print(item['video_path'] + ' over')
if __name__ == '__main__':
# 进程池开4个大小
pool = Pool(4)
# 保存视频的id,detail_url,video_path,video_url
items = []
url = 'https://www.pearvideo.com/category_59'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400'
}
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="categoryList"]/li')
# 处理视频数据
for li in li_list:
# 获取视频保存路径
video_path = 'E:\\python-file/' + ''.join(li.xpath('./div/a/div[2]/text()')[0].split(' ')) + '.mp4'
# 获取详情页url
detail_url = 'https://www.pearvideo.com/' + li.xpath('./div/a/@href')[0]
# 保存id,用于获取视频url
dic = {
'id': detail_url.split('_')[-1],
'detail_url': 'https://www.pearvideo.com/' + li.xpath('./div/a/@href')[0],
'video_path': video_path,
'video_url': ''
}
items.append(dic)
# 开启异步
pool.map(get_url, items)
pool.map(get_download, items)
3.协程
- 实现方法
- greenlet
- yield关键字
- asyncio装饰器
- async,await关键字(推荐)(就是3的关键字改进,代码简洁) - task和future(我也比较迷):
- Future,是对协程的封装,表明一个异步操做的最终结果,其值会在未来被计算出来。当一个Future对象被await的时候,表示当前的协程会持续等待,直到 Future对象所指向的异步操做执行完毕。
- Task(Task是Future子类)是跟事件循环交互的一种主要方式。
- 两种建立Task实例的方式:asyncio.ensure_future 和asyncio.create_task
- 对于绝大多数场景要并发执行的是协程,直接用asyncio.create_task就够。(如果当前线程中没有正在运行 的事件循环,asyncio.create_task将会引起RuntimeError)
- Future有四种状态:Pending, Running, Done, Cancelled
建立Task实例后,Task实例在加入事件循环以前是pending状态。事件循环调用执行的时候固然就是running,调用完毕天然就是done,若是须要中止事件循环,就须要先把task取消。
- coroutine封装为Task后不会立马启动,当某个代码await这个task的时候才会被执行 - 使用:
import asyncio
import aiohttp
async def get_page(url):
print(1)
# async with aiohttp.ClientSession() as session:
# # get()/post()
# async with await session.get(url=url) as response:
# # text():字符串形式
# # read():二进制形式
# # json():json对象
# # 注意:在获取响应数据之前一定要await进行手动挂起
# page_text = await response.text()
await asyncio.sleep(2)
print(2)
async def fn():
urls = ['1', '2', '1']
# 在事件循环中添加任务列表
tasks = [asyncio.ensure_future(get_page(url)) for url in urls]
# await(协程函数内部使用) + 可等待对象(协程对象,future,task)
# await就是等待可等待对象执行完毕再往下走(这段时间可以切换到其他任务)
# 如果是任务列表就要await asyncio.wait(tasks)
# 如果是任务可以直接await task
await asyncio.wait(tasks)
if __name__ == '__main__':
# 运行程序
asyncio.run(fn())
六、selenium
1.什么是selenium
selenium:基于浏览器自动化的一个模块
2.基本使用
- 发起请求:get(url)
- 标签定位:find
- 标签交互:send_keys
- 执行js程序:excute_script
- 前进后退:back,fowards
- 关闭:quit
3.案例
12306:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time
from chaojiying_Python.chaojiying import Chaojiying_Client
import re
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver import ChromeOptions
while True:
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
time.sleep(1)
# # 无头浏览器
# options = ChromeOptions()
# options.add_argument('--headless')
# options.add_argument('--disable-gpu')
# bro = webdriver.Chrome(executable_path='./chromedriver', options=options)
# 规避风险
bro.execute_script('Object.defineProperty(navigator,"webdriver",{get:()=>undefined,});')
bro.find_element_by_link_text('账号登录').click()
time.sleep(1)
# 局部截图
img = bro.find_element_by_class_name('imgCode')
img.screenshot('img.png')
# 使用超级鹰
chaojiying = Chaojiying_Client('1111', '0000', 'First_test')
im = open('img.png', 'rb').read()
all_code = chaojiying.PostPic(im, 9004)['pic_str']
# 点击验证码(正则提取数字,利用索引提取坐标)
code_list = re.findall("[0-9]+", all_code)
for i in range(len(code_list)):
if i % 2 == 0:
ActionChains(bro).move_to_element_with_offset(img, float(code_list[i]),
float(code_list[i + 1])).click().perform()
time.sleep(0.5)
else:
pass
# 填写用户密码
bro.find_element_by_id('J-userName').send_keys('1111')
bro.find_element_by_id('J-password').send_keys('0000')
time.sleep(1)
bro.find_element_by_id('J-login').click()
time.sleep(1)
# 判断滑块是否出来
span = bro.find_element_by_id('nc_1_n1z')
if span.is_displayed():
break
else:
pass
# 拖动滑块
action = ActionChains(bro)
action.click_and_hold(span)
action.move_by_offset(300, 0).perform()
action.release()
# # 判断是否登录成功
# try:
# # 根据登录成功页面个人信息栏的标签
# r = bro.find_element_by_class_name('site-nav-login-info-nick').text
# print('登录成功')
# break
# except NoSuchElementException:
# print('登录失败,再次尝试')
# time.sleep(1)
# 关闭页面
time.sleep(2)
bro.quit()
七、奇奇怪怪的知识点
1.正则快速加引号
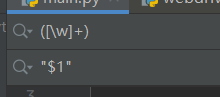
ctrl + r :调取正则页面,上面用()括住,下面用"$1",全部替换即可
2.提取文本乱码
# 方法1:
t = requests.get(url=url, headers=headers)
t.encoding = 'utf-8'
page_text = text.text
# 方法2
page_text = requests.get(url=url, headers=headers).content
# 方法3
name = li.xpath('./a/img/@alt')[0] + '.jpg'
name = name.encode('iso-8859-1').decode('gbk')
3.pip install ***
别pip install 了,直接pycharm-setting

4.找不到标签(iframe)
iframe,在网页里嵌套子页面,如果想找的标签在iframe里面,需要切换浏览器标签定位的作用域
bro.switch_to.frame(‘标签名称’)
div = bro.find_element_by_id(‘标签名称’)















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









