







笔记整理:杜苗增,东南大学硕士,研究方向为多模态知识图谱
链接:https://arxiv.org/pdf/2311.01326.pdf
1. 动机
知识图谱中的实体既可以是现实世界中对象,也可以是抽象的概念,实体间的关系也提供了大量的知识。然而现实世界的知识图谱存在不完备性,意味着知识图谱中存在着未涵盖或未完整表示现实世界知识的情况,即使已经包含了大量的信息和关系,仍然存在一些未被收录或未被充分描述的实体、关系或属性。近来,学者们开始将语言模型(LMs)应用于知识图谱补全(KGC)任务。目前基于LMs的方法仅依赖于从LMs参数中提取的信息,忽略了知识图谱本身拥有的领域实体的一些信息,而知识图谱中的结构和语义信息对于预测缺失的节点是有帮助的。且通常需要对所有可能的候选节点排序,是计算开销大的过程。
为此本文提出了一种生成式图补全方法,该方法结合了语言模型和图邻域信息,以提高知识图谱中缺失链接的预测能力。与传统的知识图谱补全方法不同,不需要计算密集的知识图谱嵌入,而是直接利用语言模型参数和图邻域信息。这种方法不仅避免了对所有可能的候选节点进行排序的计算开销,而且能够更好地捕捉知识图谱中的结构和语义信息。还提出了一种新的邻域选择策略,可以根据节点的重要性和相关性动态地选择邻域,更好地表示图节点。
2. 贡献
(1)提出了一种有效集成语言模型与图邻域信息的生成式图补全方法
(2)证明了将图信息纳入多个生成性语言模型可显著提高链接预测的性能
(3)分析和评估了添加邻域信息对模型性能的影响
3. 方法
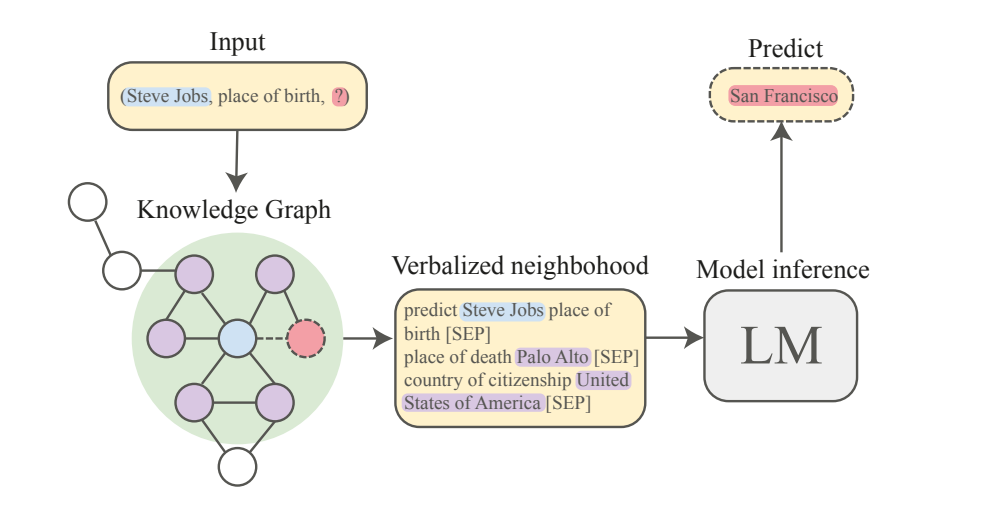
3.1 三元组转化为文本序列
对于给定的知识图谱G,通过一个简单的模板转换将其三元组(头实体,关系,尾实体)转化为文本序列,目的是将结构化的知识图谱数据转化为自然语言文本,以便于后续的语言模型处理。例如将三元组(Steve Jobs,place of birth,?)转化为“predict Steve Jobs place of birth”。
3.2 提取邻域集合
其次对每个三元组通过遍历知识图谱中与头实体直接相连的边,从G中提取与头实体相邻的一跳邻居,形成一个邻域集合,获取头实体的上下文信息,以便于后续的预测。
3.3 排序邻域集合
根据邻居三元组中的关系与查询三元组中的关系的语义相似度,通过计算关系向量之间的余弦相似度,对邻域集合进行排序,选择最相关的邻居作为输入的上下文信息。目的是选择与查询最相关的上下文信息,以提高预测的准确性。
3.4 生成尾实体的文本序列
使用基于T5的Transformer模型,将查询三元组和邻域集合作为输入,直接生成尾实体的文本序列作为输出。目的是生成尾实体的文本序列,以便于后续的实体链接。
3.5 寻找对应的实体
通过一个实体链接模块,根据输出序列在知识图谱中寻找对应的实体,作为补全的结果。如果是归纳性的知识图谱,可能需要生成之前未见过的实体。这一步是来完成的,目的是将生成的文本序列链接到知识图谱中的实体。
4. 实验
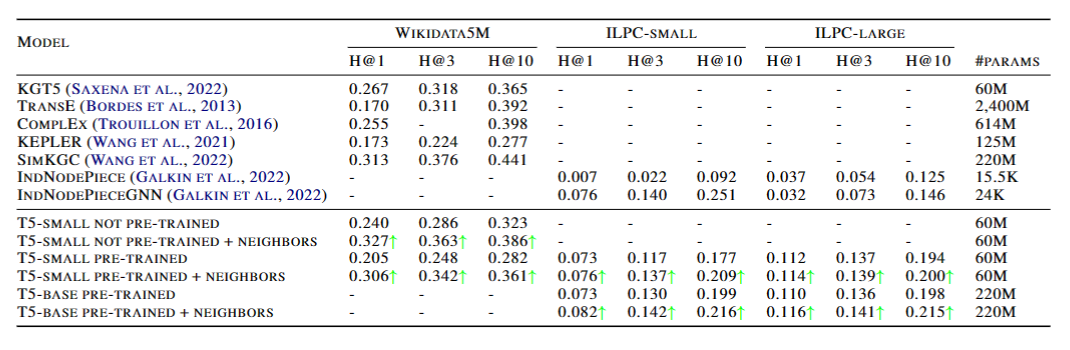
作者方法背后的假设是,在提供给语言模型的上下文中包含的邻域信息应该增强生成LM的链接预测。因此作者使用了两种类型的KG数据集进行了实验,一种是Wikidata5M,另一种是ILPC。作者使用了T5-small模型作为基础模型,并对其进行了不同的配置,包括是否使用预训练的权重,是否加入邻居信息,以及使用不同的推理策略。作者还使用了OpenAI的gpt-3.5-turbo模型进行了零样本的链接预测,并评估了邻居信息的影响。在性能评价方面,则使用Hits@k指标来衡量模型的性能,即预测的候选实体中有多少比例是正确的。下图为实验结果:
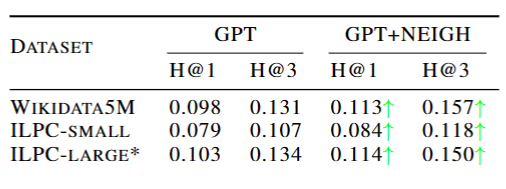
同时使用gpt-3.5-turbo-0613改进邻居信息的零击链接预测,测试集为从ILPC中随机抽取5000的样本,结果如下图,获得了较大的结果。
5. 总结
实验结果表明,加入邻居信息可以显著提升链接预测的质量。方法在ILPC数据集上达到了最优的性能,而在Wikidata5M上也与其他基于图或语言模型的方法有可比的性能,但参数数量更少。作者还发现预训练的语言模型可以加速收敛,但会降低模型的质量。此外作者还证明了邻居信息对于不同的生成模型都有益处,包括开源的T5和专有的GPT。作者还分析了邻居信息的影响,发现模型可以利用邻居中的线索来做出更好的预测,而且邻居的重要性和排序也会影响模型的性能。
这里对论文只进行了核心思想的概要介绍,对本文有兴趣的读者欢迎阅读原文了解更多细节。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









