







笔记整理:习泽坤,浙江大学硕士,研究方向为知识图谱
链接:https://arxiv.org/html/2405.19686v1
摘要
大语言模型(LLM)在一系列自然语言处理任务中表现出色。然而在实际部署时,LLM会遇到拥有个性化(事实)知识的用户,这类个性化知识会在用户与LLM的互动中不断反映出来。为了提升用户体验并满足实时模型个性化至关重要,LLM需要具备在人机交互的过程中快速掌握个性化知识的能力。现有的个性化方法大多需要通过反向传播来微调模型参数,这会带来高计算和内存成本,且缺乏可解释性和不具备长期更新能力。
鉴于此,本文提出了知识图谱微调方法(KGT),一种基于符号知识编辑的大模型个性化方法。KGT的核心思想是基于用户的查询和反馈抽取个性化的事实知识三元组,并通过固定LLM参数优化知识图谱中个性化知识的方式实现LLM的实时个性化。本文的方法通过避免反向传播提高了计算和内存效率,并依靠符号知识图谱实现了个性化知识的可解释性。实验表明,KGT可提高LLM个性化性能,同时减少了延迟和GPU内存成本。知识图谱微调提供了一种基于符号知识编辑的高效且可解释的实时LLM个性化解决方案。
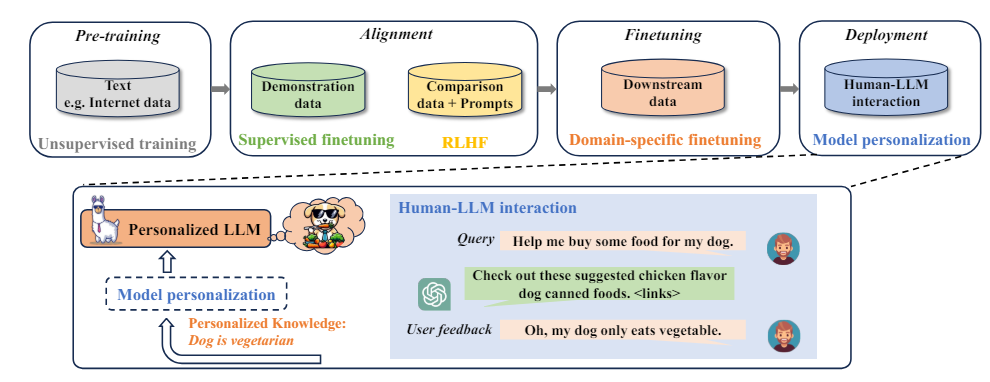
1. 引言
如上图所示,LLM的个性化是实际特定领域部署的重要需求。为提升用户体验,实时模型个性化能力至关重要,其可以让LLM在人机持续交互的过程中掌握个性化知识。目前有多种技术可应用于LLM个性化,包括参数高效微调(PEFT)、(参数)知识编辑(KE)和上下文学习。然而,这些方法大多需要反向传播和参数学习或缺乏可解释性和持续更新能力。
鉴于此,本文提出了一种基于用户反馈调优的符号知识编辑新范式:知识图谱微调(KGT)。该方法从查询和用户反馈中抽取个性化知识三元组,并根据抽取的个性化事实知识优化知识图谱而无需优化LLM参数。
本文基于证据下界(ELBO)制定了优化目标,并得出了实现高个性化知识检索概率和高知识增强推理概率的优化目标,并设计了一种启发式优化算法,通过添加和删除知识三元组来微调知识图谱,大大提高了计算和内存效率。此外,添加和删除的知识三元组对人类是可理解的,确保了方法的可解释性。下面介绍方法细节。
2. 方法
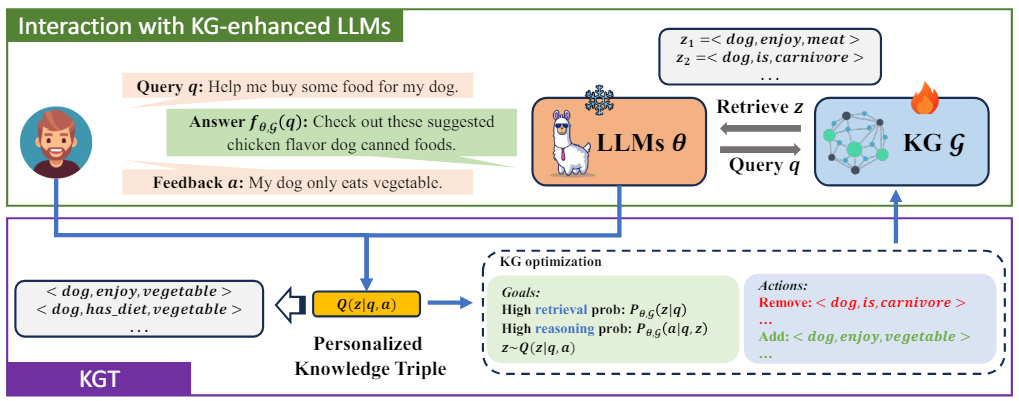
2.1 方法概述
本文提出的方法无需微调模型参数,而通过修改用户的知识图谱将个性化知识注入LLM中。
示例
例如,一个用户希望基于LLM的助手为她的素食狗订购一些食物。用户可以简单地删除知识三元组(狗,喜欢,肉)并添加三元组(狗,喜欢,蔬菜)到知识图谱中。为了生成合适的响应,LLM助手将首先根据用户的查询检索知识三元组(狗,喜欢,蔬菜),然后根据查询和检索到的个性化知识三元组推荐素食狗粮。
优化目标
从上述示例和之前的工作中,本文总结出KG增强的LLM推理包括两个步骤:知识检索和知识增强推理。基于这一洞察,本文通过边缘化知识三元组分布来制定KG增强LLM推理概率。然后,本文将KGT形式化为一个优化问题,旨在最大化从KG增强的LLM推理出答案的概率:
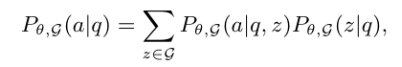
设a表示用户反馈,其中等式右边右半部分是在给定用户查询 q时检索到知识三元组z的概率,代表了知识检索步骤。等式右边左半部分是在给定用户查询和检索到的三元组z时生成答案a的概率,代表了知识增强推理步骤。在KGT中本文不是优化模型参数θ,而是微调知识图谱G。
2.2 知识检索
知识检索项的目标是微调知识图谱(KG),使LLM能够根据用户的反馈检索到个性化的三元组。给定查询q和用户反馈a,本文可以询问用户或利用LLM自身在该查询的上下文中提取出 和 之间的k个关系组成三元组记为H(q,a,K)。在这种情况下,本文假设在个性化三元组子集H(q,a,K) 上是均匀分布的。因此,知识检索损失项可以计算为:
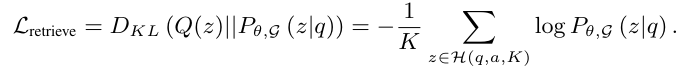
为了收集H(q,a,K),本文设计了指令模板:

为了获得kg的检索概率本文设计了指令模板:
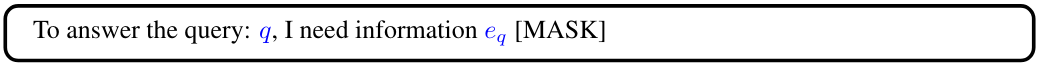
2.3 知识推理增强
知识增强推理项的目标是微调知识图谱,使得检索到的个性化三元组能够最大程度地促进LLM生成正确答案。基于近似后验分布 Q(z),推理损失项可以表示为:
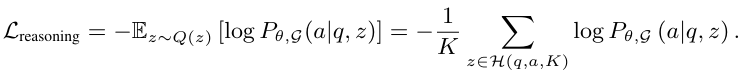
本文设计了一个指令模板,指示模型基于查询q和知识三元组z预测答案。

3. 实验
数据集
为了评估KGT在个性化LLM方面的有效性,本文进行了实验,设置为用户提供与LLM从预训练数据集中学到的常见事实知识相冲突的答案。本文在两个数据集上评估KGT:CounterFact数据集和基于PARALLEL数据集创建的CounterFactExtension数据集。两个数据集都包含涉及与现实冲突的事实知识的查询-答案对。为了在实际中评估实时模型个性化,本文依次将查询-答案对输入模型,确保每对在训练过程中只被访问一次。当数据集中的所有对都被模型处理后,本文评估整个数据集上的个性化有效性。
基线
本文将KGT与以下方法进行比较:微调(FT)、ROME、KE、KN和MEND。对于所有基线,本文测试了多个层的知识编辑规范,并报告每个基线的最佳结果。对于FT,本文按照以前的研究,在单层上执行完全微调。对于KN,本文指定所有层的子集作为知识神经元的候选,以减少大模型的搜索空间。没有编辑知识的基线结果称为“无编辑”。本文在GPT2-xl、Llama2-7B和Llama3-8B上进行实验。本文为每个模型配备了一个知识图谱(KG),ConceptNet,以增强推理能力。在实验中,H(q,a,K)中的K设置为5。
评估指标
本文使用两个指标来评估个性化的性能:(1)有效性评分,直接使用训练查询-答案对衡量个性化的成功率。如果模型生成用户的个性化答案的概率高于调优前的答案概率,则该对被认为成功。(2)释义评分,表示模型准确回忆个性化知识的能力,以释义形式进行。这评估了模型的个性化能力,同时减轻了过拟合到训练数据集中特定上下文的影响。
实验结果
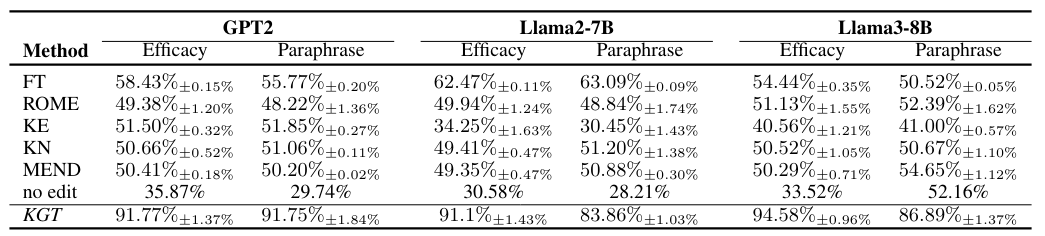
本文评估了用户仅提供答案a作为反馈的设置,模型将提取关系并构建 H(q,a,K)。CounterFact数据集上的结果如下表所示。结果显示,KGT在有效性和释义评分上均显著优于基线方法。具体而言,使用Llama3-8B,KGT在有效性评分上相比FT、KE、KN、MEND和无编辑分别提高了39%、41%、55%、45%、43%和61%。在释义评分上,KGT相比FT、KE、KN、MEND和无编辑分别提高了36%、32%、46%、37%、33%和34%。此外,观察到KGT在Llama3上的结果优于Llama2。本文的分析是Llama3在理解和遵循指令方面更强,这使得从知识图谱(KG)中增强知识更为有效。这种改进表明,当预训练的LLM变得越来越强大时,KGT将实现更好的性能。
CounterFact数据集结果:
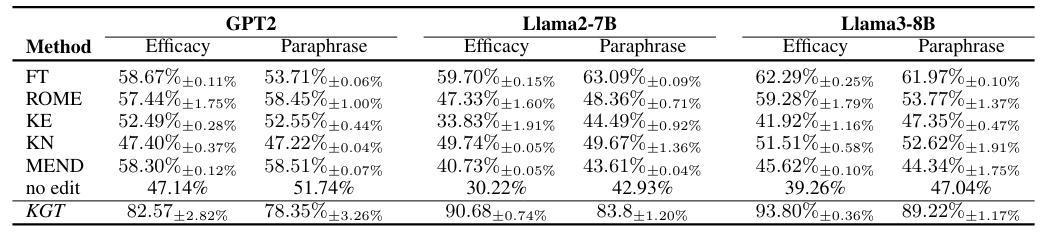
CounterFactExtend数据集结果:
效率分析
除了个性化性能外,本文还评估了KGT在延迟和GPU内存成本方面的效率。在计算资源有限的情况下,为了实现实际中的实时个性化,该方法必须实现低延迟和低GPU内存成本。KGT只需要进行推理,而推理远比反向传播高效,因此可以提高时间和GPU内存成本的效率。
在延迟方面,本文测试了本文的方法和基线方法完成一个查询-答案对的个性化所需的平均时间。CounterFact数据集上的延迟结果如表3所示。结果表明,KGT在大多数情况下实现了最短的延迟。值得注意的是,在几个基线上,Llama3比Llama2和GPT2所需的时间更少,因为本文在损失收敛后停止了训练。
4. 总结
本文提出了知识图谱微调:一种基于符号知识编辑的大模型个性化方法(KGT),通过优化外部知识图谱而非模型参数来个性化模型。本文的方法和实验结果表明,该方法在性能和效率方面具有优势,为基于符号知识编辑实现大语言模型实时个性化提供了新思路。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









