




笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型
论文链接:http://arxiv.org/abs/2407.16127
发表会议:ISWC 2024
1. 动机
传统的知识图谱补全(KGC)模型通过学习嵌入来预测缺失事实。最近的工作尝试使用大型语言模型(LLMs)以文本生成的方式补全KGs。然而,它们需要将LLMs的输出接地到KG实体上,这不可避免地带来了误差。在本文中,我们提出了一个微调框架DIFT,旨在释放LLMs的KGC能力并避免接地错误。给定一个不完整的事实,DIFT使用一个轻量级模型来获得候选实体,并使用判别指令微调LLM,从给定的候选实体中选择正确的实体。为了在减少指令数据的同时提高性能,DIFT使用截断采样方法选择有用的事实进行微调,并将KG嵌入注入到LLM中。
2. 贡献
(1)本文提出了一个新的KGC框架,即DIFT,它利用判别指令来微调生成式LLM。DIFT不需要将LLMs的输出接地到KGs中的实体。
(2)本文提出了一种截断采样方法来选择有用的KG样本用于指令构造,以提高微调效率。我们还将KG嵌入注入到LLMs中,以提高微调效果。
(3)实验表明,DIFT提高了当前最先进的KGC结果,在FB15K-237上达到0.364Hits@1,在WN18RR上达到0.616。
3. 方法
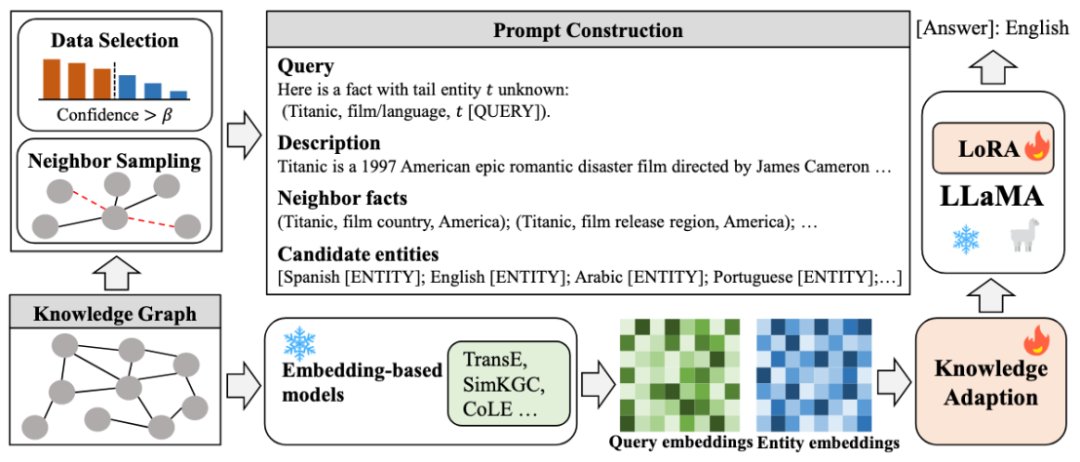
3.1 指令构造
对于一个查询q=(h,r,?),我们通过整合查询Q,描述D,邻居事实N和候选实体C这四条信息来构造提示P: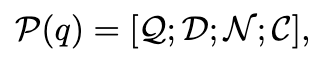 查询Q是指包含不完全事实(h,r,?)的自然语言句子。本文没有设计一个复杂的自然语言问题来提示现成的LLM,而是简单地将实体和关系名称以三元组的形式串联起来,并指出哪个实体缺失。描述D是h的描述性文本,包含了丰富的实体信息。这些额外的信息有助于LLM M更好地理解实体h。近邻事实N是通过抽样与实体h相关的事实得到的。由于可能存在大量与h相关的事实,我们设计了一种简单而有效的采样机制,即关系共现(RC)采样。它根植于关系共现,在精简事实数量的同时保证了相关信息的包含。RC抽样背后的直觉在于观察到与r频繁共现的关系被认为是补全(h、r、?)的关键。候选实体C是由KGE模型排序的top-m个实体的名称。我们保留候选实体的顺序,因为顺序反映了ME中每个实体的置信度。
查询Q是指包含不完全事实(h,r,?)的自然语言句子。本文没有设计一个复杂的自然语言问题来提示现成的LLM,而是简单地将实体和关系名称以三元组的形式串联起来,并指出哪个实体缺失。描述D是h的描述性文本,包含了丰富的实体信息。这些额外的信息有助于LLM M更好地理解实体h。近邻事实N是通过抽样与实体h相关的事实得到的。由于可能存在大量与h相关的事实,我们设计了一种简单而有效的采样机制,即关系共现(RC)采样。它根植于关系共现,在精简事实数量的同时保证了相关信息的包含。RC抽样背后的直觉在于观察到与r频繁共现的关系被认为是补全(h、r、?)的关键。候选实体C是由KGE模型排序的top-m个实体的名称。我们保留候选实体的顺序,因为顺序反映了ME中每个实体的置信度。
3.2 截尾抽样
本文设计了一种抽样方法来选择具有代表性的样本,以减少指令数据。其主要思想是选择KGE模型得到的高置信度样本,从而赋予LLM有效获取KGE内在语义知识的能力。以带有查询( h、r、?)和答案实体t的样本事实( h , r , t)为例,样本事实记为s。本文从全局和局部两个角度评估s的置信度。全局置信度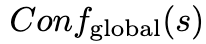 计算方式为
计算方式为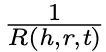 ,其中R(h,r,t)是查询(h,r,?)中t的位次。局部置信度
,其中R(h,r,t)是查询(h,r,?)中t的位次。局部置信度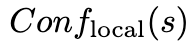 计算方式为
计算方式为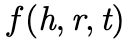 。如果t不在top-m内排序,则赋值为0。最后,我们得到加权的置信度
。如果t不在top-m内排序,则赋值为0。最后,我们得到加权的置信度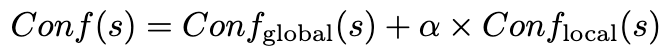 。
。
3.3 知识适配的指令微调
P (q)中提供的事实以文本格式呈现,丢失了KGs的全局结构信息。因此,我们提出将从KG结构中学习到的嵌入注入到M中,以进一步提高其图推理能力。我们将KGE得到的实体嵌入与LLM的语义空间对齐,得到知识表示: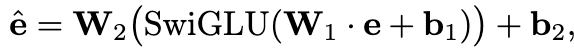 。考虑到KGE模型基于查询q和候选实体t的嵌入对事实进行打分,本文注入q和所有候选实体C的表示。同时,我们添加了两个特殊的占位符'[QUERY]'和'[ENTITY]',表示会有来自KGE的知识表示,如图所示。具体来说,我们在Q中的缺失实体后放置一个'[QUERY]',在C中的每个实体名后放置一个'[ENTITY]'。
。考虑到KGE模型基于查询q和候选实体t的嵌入对事实进行打分,本文注入q和所有候选实体C的表示。同时,我们添加了两个特殊的占位符'[QUERY]'和'[ENTITY]',表示会有来自KGE的知识表示,如图所示。具体来说,我们在Q中的缺失实体后放置一个'[QUERY]',在C中的每个实体名后放置一个'[ENTITY]'。
4. 实验
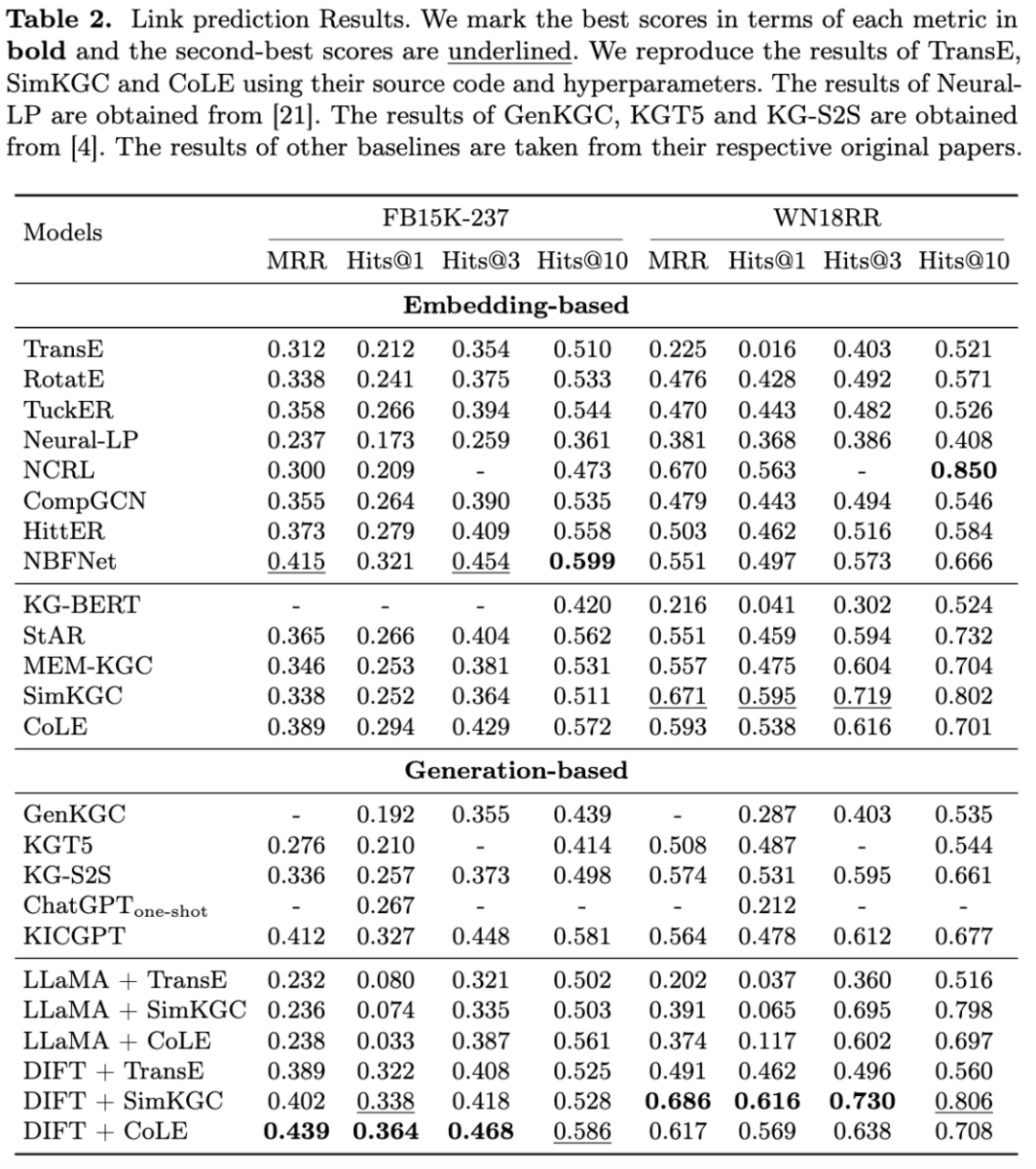
我们提出的框架DIFT在两个数据集的大多数指标上都取得了最好的性能。与基于嵌入的模型TransE、SimKGC和CoLE相比,DIFT在两个数据集上都提高了这些模型的性能,在Hits @1方面有显著提升。在不进行微调的情况下,DIFT的性能急剧下降,说明有必要对LLM进行微调以完成KG任务。
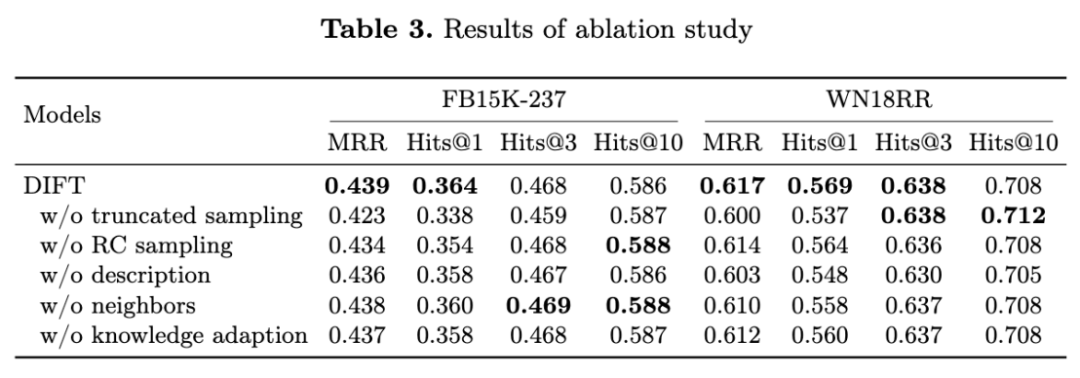
从上表的结果可以看出,所有组分对DIFT都有很大的贡献。在所有这些组成部分中,截断采样对性能的影响最大。在没有截尾抽样的情况下,Hits@1得分至少下降了5.6 %。这表明,该机制能够有效地为LLM选择有用的指令数据,以学习基于嵌入模型的内在语义知识。
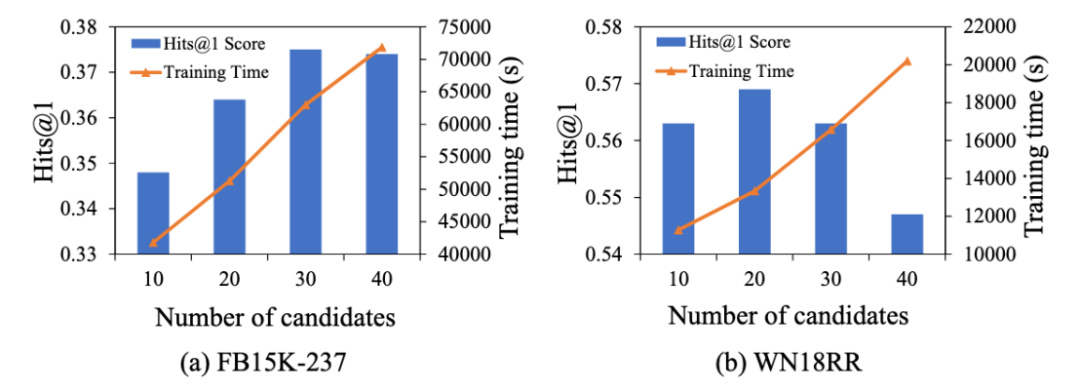
候选实体数量的影响。我们将基于嵌入的模型提供的候选实体数量m设置为20。在这里,我们研究了m对DIFT性能和训练时间的影响。首先,对于训练时间,我们发现它随着m的增加而线性增长。我们可以直观地看到因为m的增加会导致更长的提示。其次,对于DIFT的性能,我们发现在FB15K-237上当m设置为30时性能最好,当m设置为40时性能略有下降。如果我们在20之后继续增加m,在WN18RR上也可以找到相同的观测结果。这表明一味地增加候选实体的数量并不能提高性能。
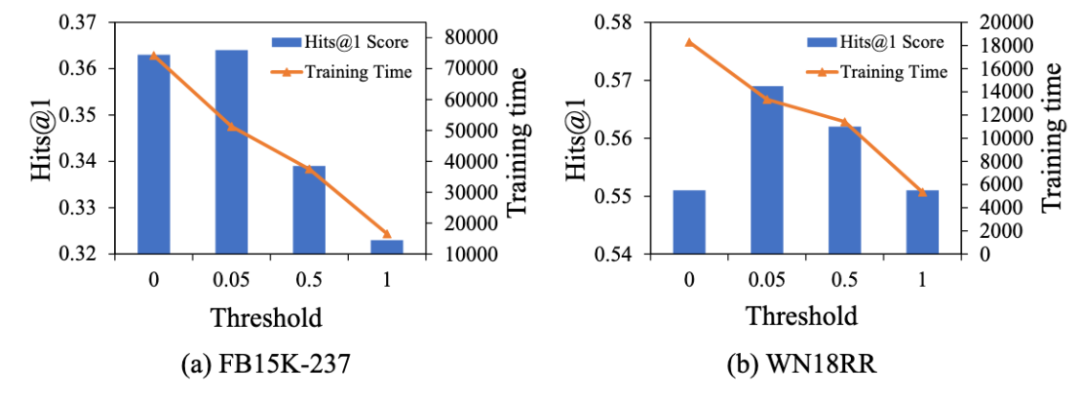
截断采样阈值的影响。我们使用一个阈值β来控制指令数据的数量。随着β的增加,指令数据量减少,因此训练时间也相应减少。其次,当我们在两个数据集上设置β为0时,性能都会下降,这表明增加指令数据的数量并不一定能提高性能,其质量也会影响性能。
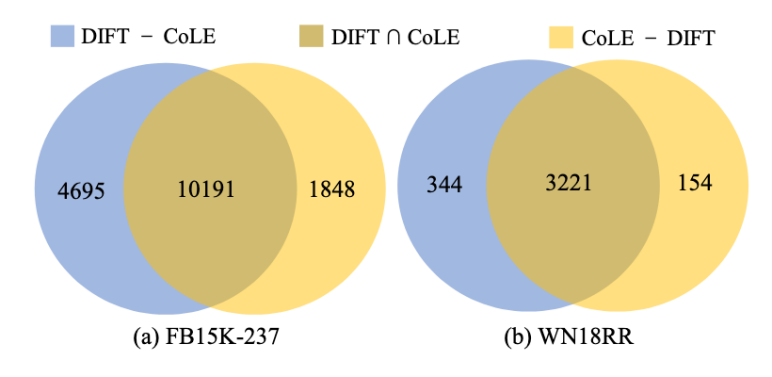
DIFT与基本嵌入模型的比较。我们进一步考察了DIFT的预测结果,并与所选择的基于嵌入的预测结果进行了比较。显而易见,除了共有的正确预测外,DIFT本身也可以得到一些正确的预测。反之,我们观察到CoLE做出DIFT无法复制的正确推断的实例。基于DIFT和CoLE的正确预测之间的差异,我们可以得出结论,LLM并不是盲目地重复CoLE预测的实体,而是基于其在预训练阶段获得的知识来推理缺失的事实。
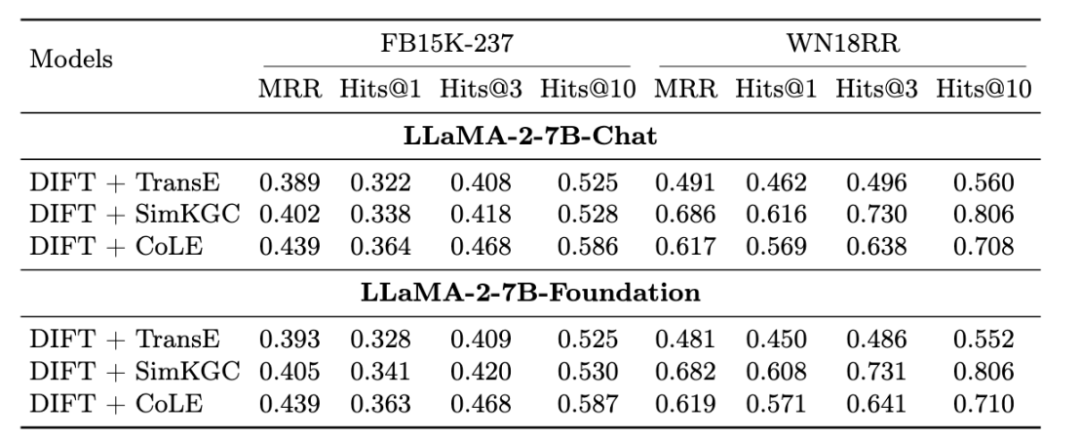
总的来说,不管采用哪种版本的LLM,DIFT都能获得相似的性能。说明了DIFT对不同LLM版本的鲁棒性和泛化性。
5. 总结
本文提出了一个新颖的KG补全框架DIFT。它使用LoRA对带有判别指令的生成式LLM进行微调,不涉及将LLM的输出接地到KG中的实体。为了进一步降低计算成本,提高DIFT的效率,我们提出了一种截断采样方法来选择置信度高的事实进行微调。为了提高微调效果,在LLMs中还加入了KG嵌入。实验表明,DIFT在KG补全上取得了最好的效果。在未来的工作中,我们计划支持其他KG任务,如KGQA和实体对齐。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









