







TOPSIS算法:
TOPSIS是最著名的经典指标方法之一,最初是在1981年由Hwang和Yoon首次提出,在1992年由Chen和Hwang做了进一步的发展。TOPSIS方法引入了两个基本概念:理想解和负理想解。所谓理想解是一设想的最优的解(方案),它的各个属性值都达到各备选方案中的最好的值;而负理想解是一设想的最劣的解(方案),它的各个属性值都达到各备选方案中的最坏的值。方案排序的规则是把各备选方案与理想解和负理想解做比较,若其中有一个方案最接近理想解,而同时又远离负理想解,则该方案是备选方案中最好的方案。TOPSIS通过最接近理想解且最远离负理想解来确定最优选择。这种方法假定了每个属性是单调递增或者递减,TOPSIS利用了欧氏距离测量方案与理想解和负理想解。选择的偏好顺序是通过比较了欧几里得距离,TOPSIS执行过程如下:
(1)标准化决策矩阵:
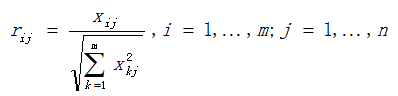
rij表示归一化第i个选择方案的属性值j
(2)计算加权标准化决策矩阵:
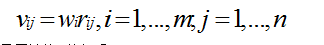
wj是属性值j的权重
(3)确定理想解和负理想解:
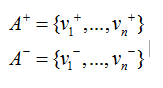
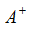
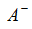
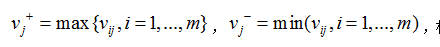
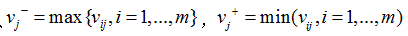
(4)计算每个备选方案到理想解和负理想解的距离:
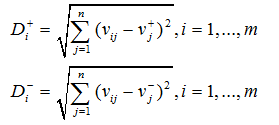
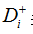
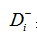
(5)计算最接近理想解的方案
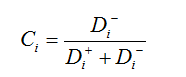
(6)方案排序,按照Ci依次递减的顺序排列。
matlab程序:
function [ output_args ] = TOPSIS(A,W)
%A为决策矩阵,W为权值矩阵,M为正指标所在的列,N为负指标所在的列
[ma,na]=size(A); %ma为A矩阵的行数,na为A矩阵的列数
for i=1:na
B(:,i)=A(:,i)*W(i); %按列循环得到[加权标准化矩阵]
end
V1=zeros(1,na); %初始化正理想解和负理想解
V2=zeros(1,na);
BMAX=max(B); %取加权标准化矩阵每列的最大值和最小值
BMIN=min(B); %
for i=1:na
%if i<=size(M,2) %循环得到理想解和负理想解,注意判断,不然会超个数
V1(i)=BMAX(i);
V2(i)=BMIN(i);
%end
%if i<=size(N,2)
%V1(N(i))=BMIN(N(i));
%V2(N(i))=BMAX(N(i));
%end
end
for i=1:ma %按行循环求各方案的贴近度
C1=B(i,:)-V1;
S1(i)=norm(C1); %S1,S2分别为离正理想点和负理想点的距离,用二阶范数
C2=B(i,:)-V2;
S2(i)=norm(C2);
T(i)=S2(i)/(S1(i)+S2(i)); %T为贴近度
end
output_args=T;小组共同努力的结果~















 7076
7076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









