







最近在工作中,有一段逻辑需要从一张大约70W数据的表中分页查询。
- 最开始写的SQL是:
SELECT * FROM table_name WHERE 1 = 1 ORDER BY time_column DESC LIMIT 600000, 10;
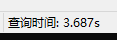
查询时间大概是:3.687s
- 后来优化了一次查询语句如下
SELECT
*
FROM
table_name t1,
( SELECT index_id FROM table_name t0 WHERE 1 = 1 ORDER BY t0.time_column DESC LIMIT 600000, 10 ) t2
WHERE
t1.index_id = t2.index_id;
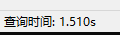
查询时间大概是:1.510s
- 这里是使用的索引字段,经过explain发现,即使使用索引字段,t0表扫描的仍是全表。 此时就考虑使用主键试试,优化如下:
SELECT
*
FROM
table_name t1,
( SELECT id FROM table_name t0 WHERE 1 = 1 ORDER BY t0.time_column DESC LIMIT 600000, 10 ) t2
WHERE
t1.id = t2.id ;
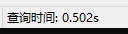
查询时间大概是:0.502s
从第一步到第二步的优化很多人都使用过,为什么从第二步到第三步依然能大幅度提升性能。这就要从主键和索引的区别说起了。
聚集索引
MySQL中,主键使用的聚集索引,也叫聚簇索引。
一张表中只能有一个聚集索引。聚集索引的叶子结点存的整行的数据,可以通过这个聚集索引直接找到某一行。
非聚集索引
一张表中可以有多个非聚集索引,非聚集索引中叶子结点存的是字段的值,通过这个非聚集索引的键值找到对应的聚集索引字段的值,再通过聚集索引键值找到表的某一行。
看到这里想必大家就看出来了,为什么走聚集索引能够提升这么高的性能。这里只记录我遇到的问题和解决方案,如果大家有兴趣了解更多的聚集索引和非聚集索引的区别,可以去搜索大牛们写的文章,我就不再赘述了。















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









