哈希表、映射、集合
哈希表、映射、集合的实现与特性
经常用的数据结构有:
数组
链表
map
set
map和set基本上底层是通过哈希表去实现的,也有部分是通过二叉树去实现
Hash table概述
Hash table(哈希表),也称为散列表
是根据关键码值(key valve)进而直接进行访问的数据结构
其通过把关键码值映射到表中的一个位置来访问记录,进而加快查找的速度
该映射函数称为散列函数(Hash Function),存放记录的数组叫做哈希表(或散列表)
简而言之,有一个哈希函数,通过哈希函数可以把要存储的值能够映射到一个位置(下标),进而存放数据到该索引位置来
Hash table实际应用
缓存 LRU Cache
键值对存储 Redis
Hash table基础
现在我们想要向一个哈希表中传入“lies”
“lies”使用散列函数之后,就会返回一个下标,这里的是9,因此就把“lies”存在9这个位置
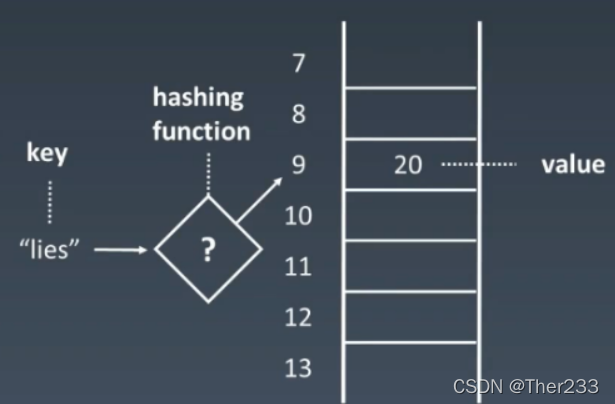
哈希函数有很多种,重载hashCode方法就可以
一个简单的哈希函数:
把每一个字符的ASCII码加在一起,然后再mod上一个数
例如,lies ASCII码 mod 10
但是实际中哈希函数都是比较复杂的,而且哈希函数选的好的话,可以让数据存放的尽量分散,而不会发生碰撞

会存在不同属性值算出来的哈希值却是一样的情况
例如lies和foes
当两个不同的数据的哈希值却是一样的情况,我们称为哈希碰撞

发生哈希碰撞,有以下几种解决办法:
1.依次往下面抢占别人的位置
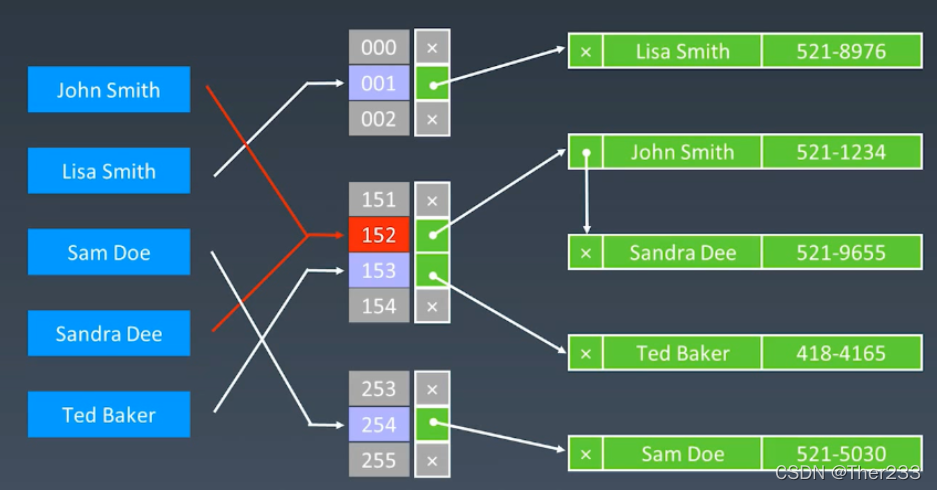
2.再增加一个维度(在该位置不再只是存一个数,而是多个数,链表)
该方法称为 拉链式解决冲突法
如果很多元素都在相同的位置,此时哈希表查询就需要遍历链表,该链表长度很大的时候,效率就会变低,退到O(n),但是如果哈希函数设计的很好的话,哈希函数碰撞的概率很小,平均而言,整个哈希函数的查询是O(1)
Hash table实际中完整的结构
现实中较为完美哈希表为:
大部分位置都只有一个元素,其他少数位置会有一些冲突,有冲突的话就把数据连接起来,串联起来形成一个链表
非常常用:优先队列、红黑树、AVL、哈希表、哈希函数
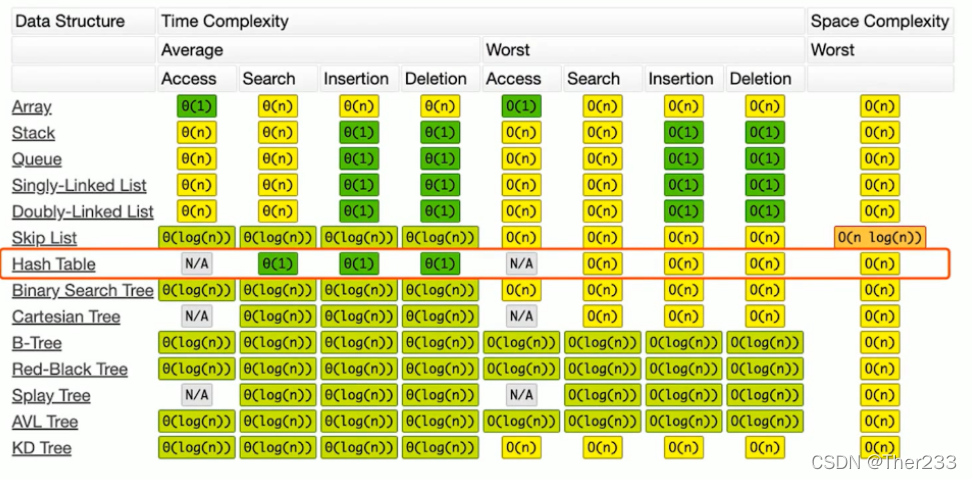
Hash table复杂度分析
增删查大部分都是O(1),最坏的情况:哈希函数选得非常不好或者哈希表的size太小了,经常发生冲突,它就变成了一个链表,复杂度也就退化成了O(n)
但是现在计算机内存越来越大,哈希表就可以开的特别大,哈希函数也在不断优化,因此一般而言,我们认为哈希表在正常情况下查询、删除、添加元素是O(1)
在工程代码中,我们经常使用的不再是哈希表,而是在哈希表基础上抽象出来的map和set
map和set区别:
map的话就是键值对,key是不可重复的,value可以重复
set是不可重复的集合
Java set classes:
TreeSet, HashSet,
ConcurrentSkipListSet, CopyOnWriteArraySet, EnumSet, JobStateReasons, LinkedHashSet
https://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/util/Set.html
Java map classes:
HashMap, Hashtable, ConcurrentHashMap
https://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/util/Map.html

HashSet源码
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
HashMap重要的源码
1.put()
putVal()
2.get()
getNode()


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









