







jvm运行时数据区
总览
java虚拟机在运行时会将它所管理的内存分成若干个区域,这些区域有各自的用途、创建和销毁时间,有的是随着虚拟机进程启动而创建,有的是随着用户线程的启动和结束而创建和销毁,按照虚拟机规范,虚拟机内存被划分为以下区域

程序计数器
定义
Program computer Register 程序计数器,其作用为
-
记住下一条指令地址
-
程序执行过程中,出现分支、循环、跳转、线程恢复需要通过计数器获取下一条指令地址去执行
-
特点
-
线程私有
每个线程都有自己独立的程序计数器,因为多线程是通过线程轮流切换实现,同一时刻永远只有一个线程在cpu或内核上执行,一个线程执行到一半轮到下一个线程执行,需要通过计数器保存指令执行的地址,恢复后就从计数器保存的地址开始继续执行
-
占用内存很小,不存在内存溢出风险
-
案例
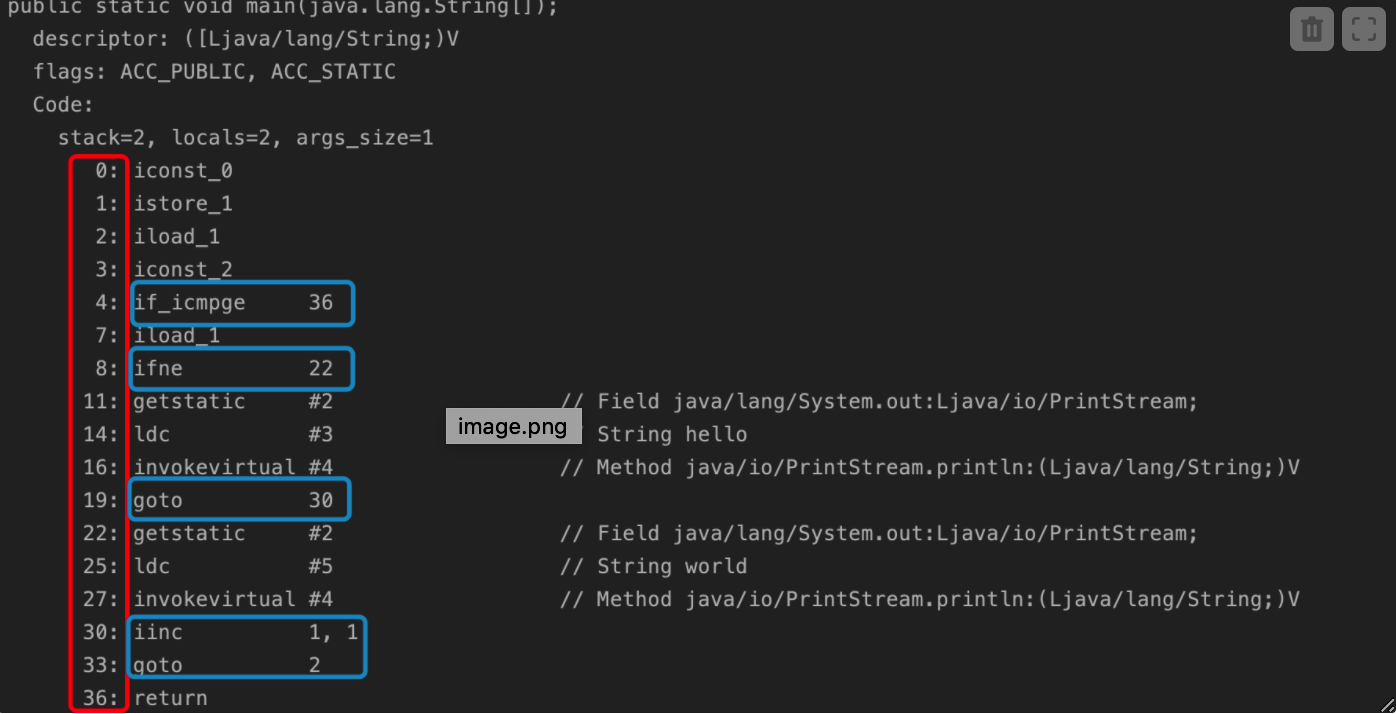
下面通过一个例子看看程序计数器怎么起作用的
public class PCTest {
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
if(i == 0){
System.out.println("hello");
}else {
System.out.println("world");
}
}
}
}
使用javap -v PCTest进行反编译,得到以下片段,左侧红框里面是字节码指令地址,而篮框表示这条字节码指令会跳转到指定地址去执行。PC的作用就是记录这些指令的地址。
虚拟机栈
定义
- 每个线程执行时需要的内存空间被称为栈
- 方法调用时会创建一个栈帧,并将其入栈,方法调用完毕后会将其栈帧出栈
- 栈帧里面包含了局部变量表、操作数栈、动态链接、返回地址等信息
- 每个栈只有一个活动栈帧即位于栈顶的那个栈帧,对应着正在执行的方法
栈帧
局部变量表
一组变量值的存储空间,可以理解为一个数组,数组中每个位置用于存储一个局部变量,或者方法参数、this变量(实例方法才有)。在编译为class文件时,局部变量表的最大长度已经确定,存在code属性的max_locals附加属性中。
变量槽
- 每个变量槽都能存放一个boolean、 byte、char、short、int、float、reference或returnAddress类型的数据
- 如果是double 或long类型的数据,要用连续的两个变量槽
- reference类型有两个作用
- 可以直接或间接查到对象在堆中的地址
- 可以直接或间接查到对象所属数据类型的在方法区中的类型信息
变量槽的分配
- 如果是实例方法,第一个变量槽用this
- 先将参数分布到变量槽,再为局部变量分配变量槽
- 变量槽复用
- 方法体内定义的变量,其作用域不一定是整个方法,一个变量作用域范围以外定义的变量,可以复用其变量槽
操作数栈
- 是一个先入后出的栈
- 最大深度在编译完成后已经确定了,存放在code属性的max_stacks数据项中
- double和long占用两个栈容量,其他数据类型占用一个栈容量
- 可以用来传递参数给调用的方法
- 可以用来进行算术运算
动态链接
-
每个栈帧都包含了一个引用,指向当前方法所属类型在运行时常量池中的地址,用来支持方法代码的动态链接。
-
在class文件中,一个方法通过符号引用来调用其他方法或访问字段。动态链接将这些方法的符号引用转换为方法的直接引用,必要时会加载类信息以解析尚未解析的符号引用,并将变量的访问转换为与这些变量运行时位置相关的存储结构中的适当偏移量。
返回地址
- 方法退出有两种,正常退出和异常退出,正常退出可能有返回值,异常退出一定不会有返回值,但是无论正常或异常退出,都必须返回到方法最初被调用的位置
- 正常退出是通过栈帧中保存的主调方法的PC计数器的值作为返回地址
- 异常退出时返回地址通过异常处理表来确定
- 方法退出的流程可能如下
- 当前栈帧销毁,恢复上一层栈帧的操作数栈和局部变量表,将当前栈帧的返回值压入调用者栈帧的操作数栈,调整PC计数器的值指向方法调用后一条指令的位置
线程、栈、栈帧的关系

栈帧演示
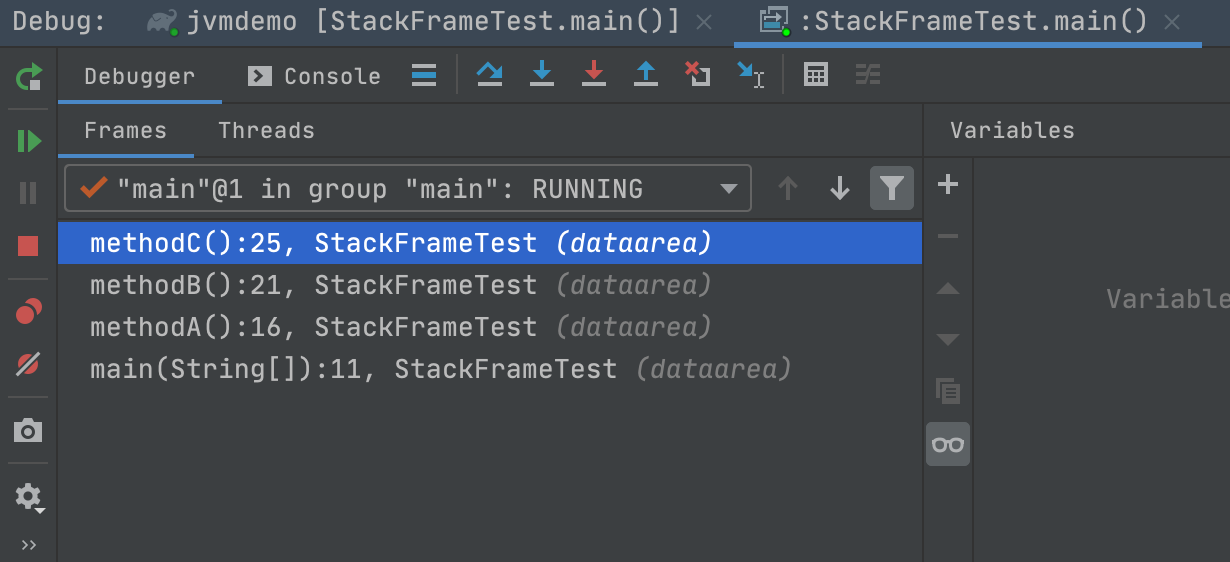
使用idea编写测试类,并在methodC()方法打上断点,然后以debug模式启动程序
public class StackFrameTest {
public static void main(String[] args) {
methodA();
}
private static void methodA() {
System.out.println("A");
methodB();
}
private static void methodB() {
System.out.println("B");
methodC();
}
private static void methodC() {
System.out.println("C");
}
}
当程序运行到methodC()的时候,查看控制台,发现出现了4个栈帧
本地方法栈
- 本地方法栈(Native Method Stacks)和虚拟机栈非常类似,不同的是虚拟机栈是为调用java方法服务,而本地方法栈是为虚拟机调用本地方法服务
- 本地方法栈在栈深度溢出或栈扩展失败是也分别会抛出
StackOverflowError和OutOfMemoryError异常
堆
定义
- 用于存储对象实例的内存区域
特点
- 它是线程共享的,堆中对象需要考虑线程安全问题
- 通过自动内存回收机制管理堆内存
- 堆最小和最大内存分别通过-Xms和-Xmx设置,如
-Xms10m设置最大堆内存为10m
堆内存溢出
通过以下代码可以测试堆内存的溢出, 启动程序前需要先设置虚拟机参数-Xmx10m,将堆内存的最大值设置为10m
package dataarea;
import java.util.ArrayList;
import java.util.List;
/**
* VM Args -Xmx10m
* 堆内存溢出问题
* @author ct
* @date 2021/10/21
*/
public class HeapOOMTest {
static class OOMObject{
byte[] bytes = new byte[1024];
}
public static void main(String[] args) {
List<OOMObject> list = new ArrayList<>();
try{
while (true){
list.add(new OOMObject());
}
}catch(Throwable e){
e.printStackTrace();
}finally {
System.out.println(list.size());
}
}
}
从运行结果可以看出,堆内存发生了溢出,产生OOM异常
8641
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.lang.Throwable.printStackTrace(Throwable.java:649)
at java.lang.Throwable.printStackTrace(Throwable.java:643)
at java.lang.Throwable.printStackTrace(Throwable.java:634)
at dataarea.HeapOOMTest.main(HeapOOMTest.java:24)
方法区
定义
- 方法区是所有线程共享的一个区域
- 主要用于存储类相关的信息,如运行时常量池、字段、方法数据,方法或构造器的代码
- 方法区在虚拟机启动时创建
- 方法区虽然在逻辑上是堆的一部分,但是虚拟机的实现可以选择不进行垃圾回收或整理。
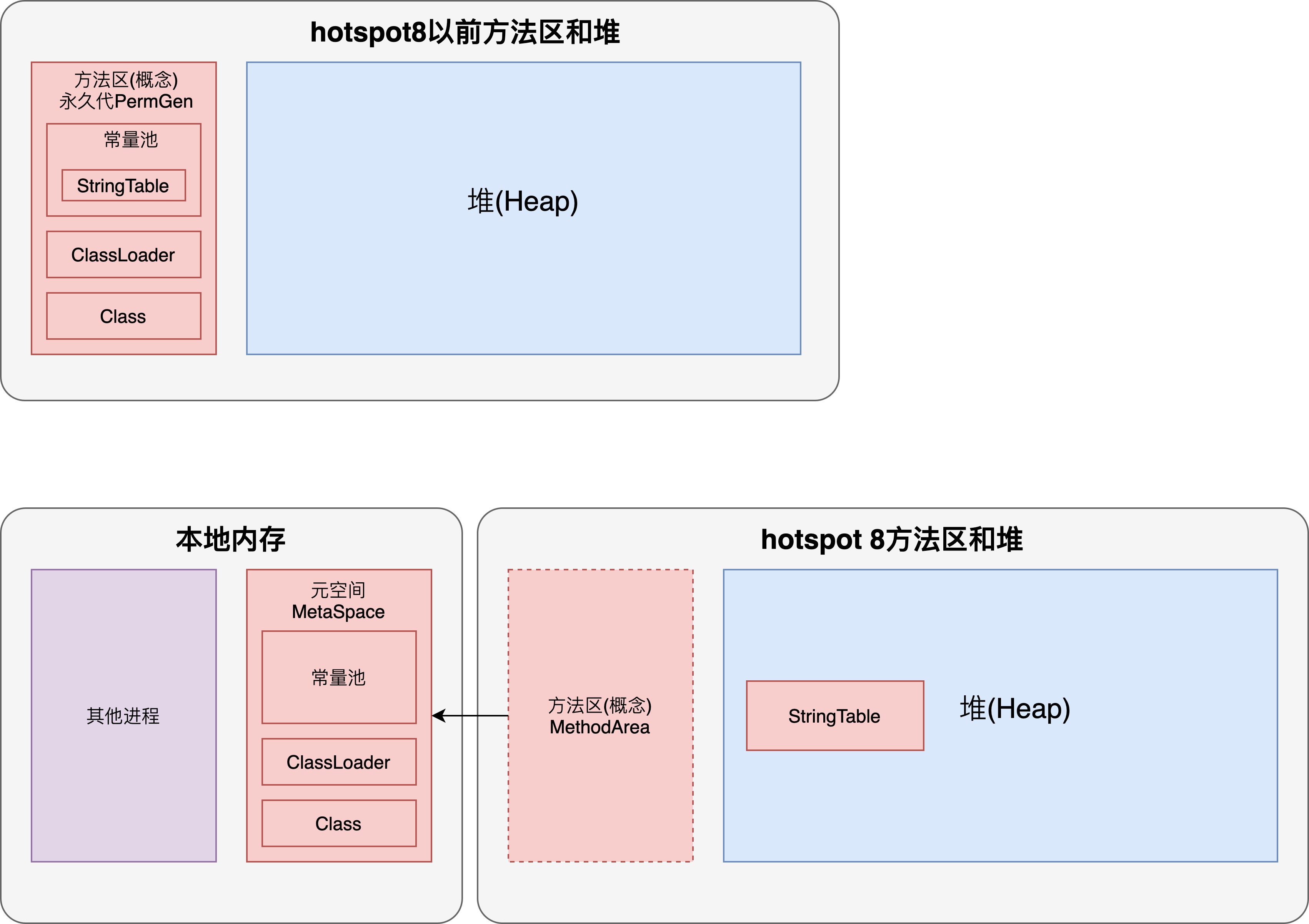
- 方法区是规范,永久代或元空间是其实现,hotspot1.8以前是使用的永久代,1.8以后使用的元空间
- 永久代在堆内存,元空间在本地内存
hotspot8和hotspot8以前的方法区对比
内存溢出
jdk1.8测试元空间的内存溢出。通过动态代理技术创建大量的类,并设置元空间大小为10m:-XX:MaxMetaspaceSize=10m
package com.company;
import jdk.internal.org.objectweb.asm.ClassWriter;
import jdk.internal.org.objectweb.asm.Opcodes;
/**
* 制造元空间的内存溢出,通过
* VM args -XX:MaxMetaspaceSize=10m
*
* @author ct
* @date 2021/10/22
*/
public class MethodAreaOOMTest1 extends ClassLoader{
public static void main(String[] args) {
MethodAreaOOMTest1 test = new MethodAreaOOMTest1();
ClassWriter cw = new ClassWriter(0);
for (int i = 0; i < 10000; i++) {
//jdk版本、修饰符、类名、包名、父类
cw.visit(Opcodes.V1_8,Opcodes.ACC_PUBLIC,"Class"+i, null, "java/lang/Object", null);
byte[] code = cw.toByteArray();
test.defineClass("Class"+i,code,0,code.length);
}
}
}
执行结果如下
 {:height 107, :width 554}
{:height 107, :width 554}
运行时常量池
- 常量池是编译后的字节码文件中的字面量、符号引用信息,当一个类被jvm加载,常量池里面的数据就会被加载到方法区内存中,成为运行时常量池
- 由符号引用翻译过来的直接引用,也会存放到运行时常量池中
字符串池
测试题
(如果知道以下程序输出结果,可以跳过这一讲了)
package stringtable;
/**
* stringtable.StringTableTest
*
* @author ct
* @date 2021/10/23
*/
public class StringTableTest {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a"+"b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
System.out.println(s3 == s4);//
System.out.println(s3 == s5);//
System.out.println(s3 == s6);//
String x1 = new String("c") + new String("d");
String x3 = x1.intern();
String x2 = "cd";
//如果调换22、23行位置,或者在jdk1.6运行呢
System.out.println(x1==x3);//
System.out.println(x2==x3);//
}
}
运行常量池和字符串池的关系
常量池的信息加载到运行时常量池中,字符串池是运行时常量池的一部分
字符串池特性
- 常量池中字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接是通过
StringBuilder - 字符串常量拼接原理是通过编译器优化
- 可以使用
intern()方法,主动将串池中还没有的字符串对象放入串池 - 串池是一个底层使用了
hashTable,可以使用
变量拼接
如下,s1+s2会被转化为new StringBuilder().append("a").append("b").toString()
String s1 = "a";
String s2 = "b";
String s3 = s1 + s2;
通过查看字节码可以验证。
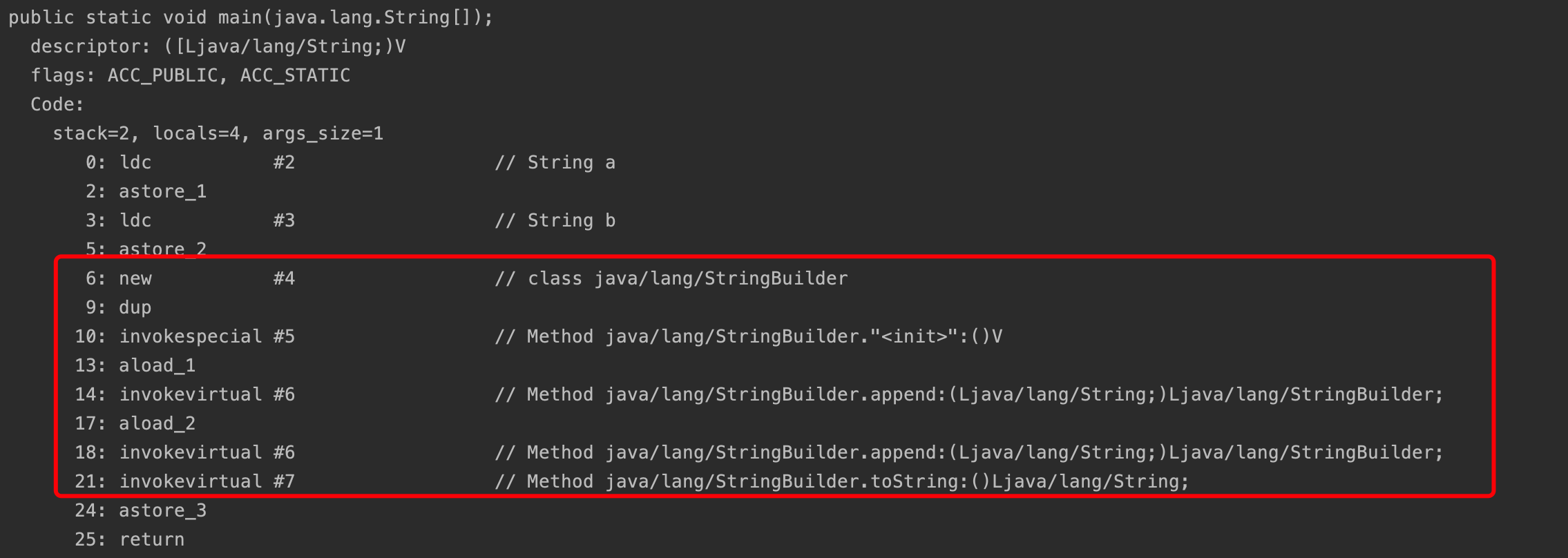
常量拼接
对于两个字符串常量直接相加,可以通过javac在编译期直接优化为一个字符串常量
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
分析字节码指令可以看出,s3直接被编译为了ab
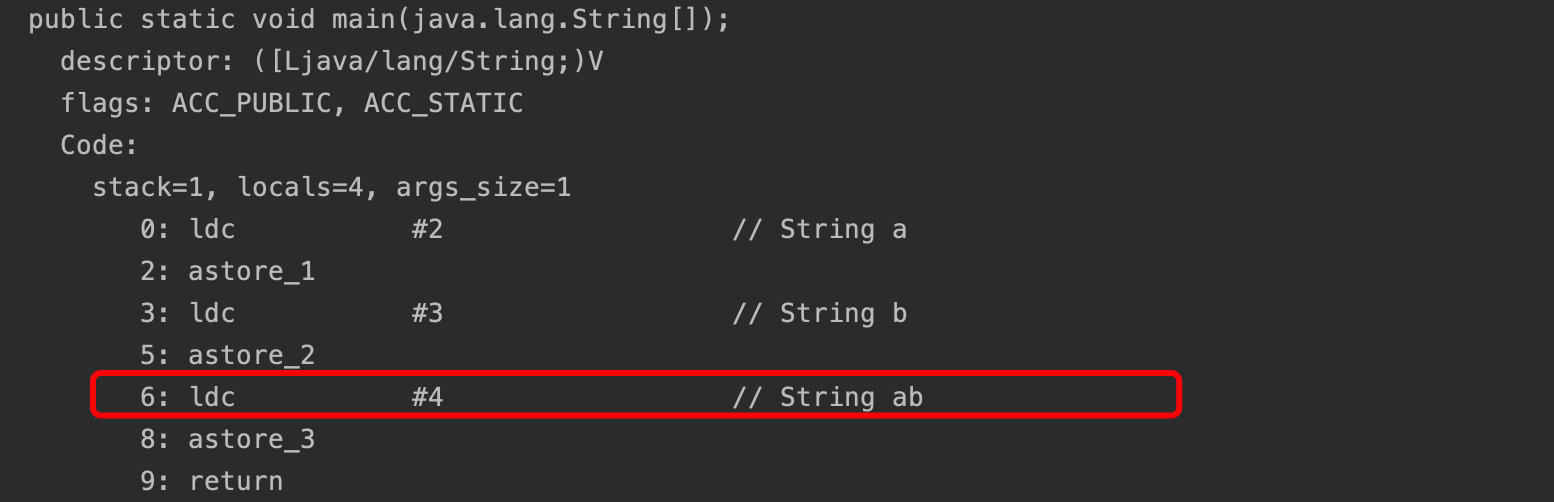
字符串常量延迟加载的验证
通过下面代码以及idea的debug功能,我们来验证一下字符串常量延迟加载的过程
package stringtable;
/**
* stringtable.StringTableTest
*
* @author ct
* @date 2021/10/23
*/
public class StringTableTest2 {
public static void main(String[] args) {
System.out.println();
System.out.println("0");
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println();
System.out.println("0");
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println();
}
}
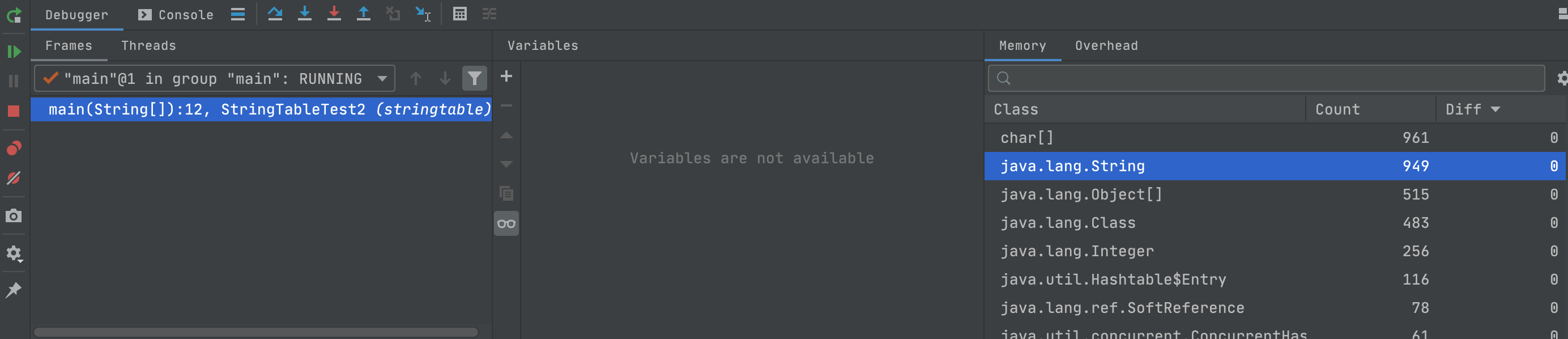
断点打到第12、22、32行,当代码执行到第11行的时候,我们可以看到debug工具界面右侧,string类的实例数量为949个
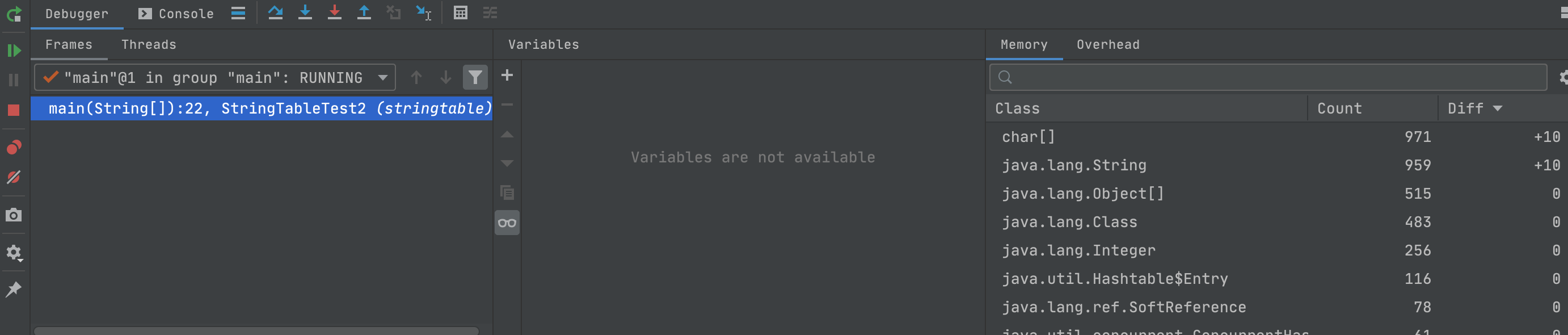
当断点执行到底22行,可以看到实例数量变为959个
可是到底32行的时候,再看实例数量,仍然为959个
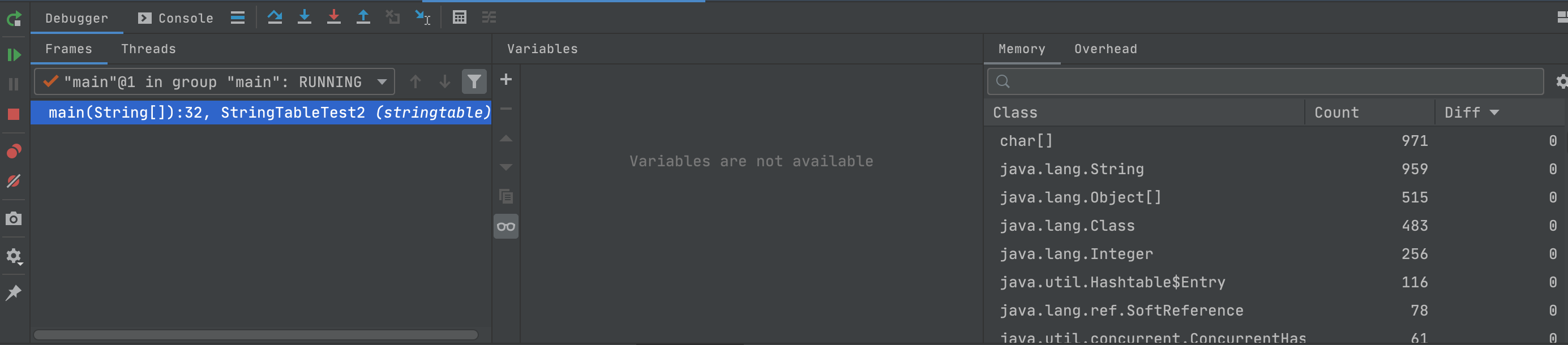
从以上执行结果可以看出,最开始字符串"0",“1”,“2”…"9"本来是在字符串池中不存在的,执行的过程中创建字符串对象,加入串池并返回其引用,随后再执行,因为已经在串池中存在,就不再创建新的对象
intern()方法
intern的字面意思是拘留、软禁,听起来还挺符合这个方法的作用,将一个字符串常量放入字符串池中,在jdk1.8和jdk1.6中,稍有一点区别:
- 1.8尝试将字符串放入串池,如果有则不放入,如果没有则放入串池,并返回一个对象引用
- 1.6尝试将字符串放入串池,如果有则不放入,如果没有则复制一份放入串池,并返回一个对象引用
串池所在位置
-
先说结论
- jdk1.6 存在于方法区的永久代
- jdk1.8 存在于堆中,因为永久代的回收效率不高,而字符串属于使用比较频繁的对象,在1.8虚拟机中开始将串池转移到堆中
-
验证
下列代码不停往字符串常量池中写数据,造成内存溢出
package stringtable; import java.util.ArrayList; import java.util.List; /** * 测试jdk1.8下由于串池过大导致的堆内存溢出,运行前需要修改堆大小为-Xmx=10m * VM args: -Xmx10m * @author ct * @date 2021/10/27 */ public class StringTableOOMTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); for (int i = 0; i < 1000000; i++) { list.add(String.valueOf(i).intern()); } } }执行后发现抛出了异常,但是异常提示为
GC overhead limit exceeded,根据Oracle官方文档,其意思为:默认情况下,如果Java进程花费98%以上的时间执行GC,并且每次只有不到2%的堆被恢复,则JVM抛出此错误。Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded at java.lang.Integer.toString(Integer.java:401) at java.lang.String.valueOf(String.java:3099) at stringtable.StringTableOOMTest.main(StringTableOOMTest.java:16)可以通过
-XX:-UseGCOverheadLimit参数使虚拟机在内存溢出时直接抛出异常。从打印的信息可以看出,抛出了堆内存溢出异常。

串池的垃圾回收
字符串常量池也是会被进行垃圾回收的,通过-XX:+PrintStringTableStatistics参数我们可以在jvm退出的时候打印出串池的详细信息
public class StringTableGCTest {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
String.valueOf(i).intern();
}
}
}
从打印信息可以看出串池中有846个字符串
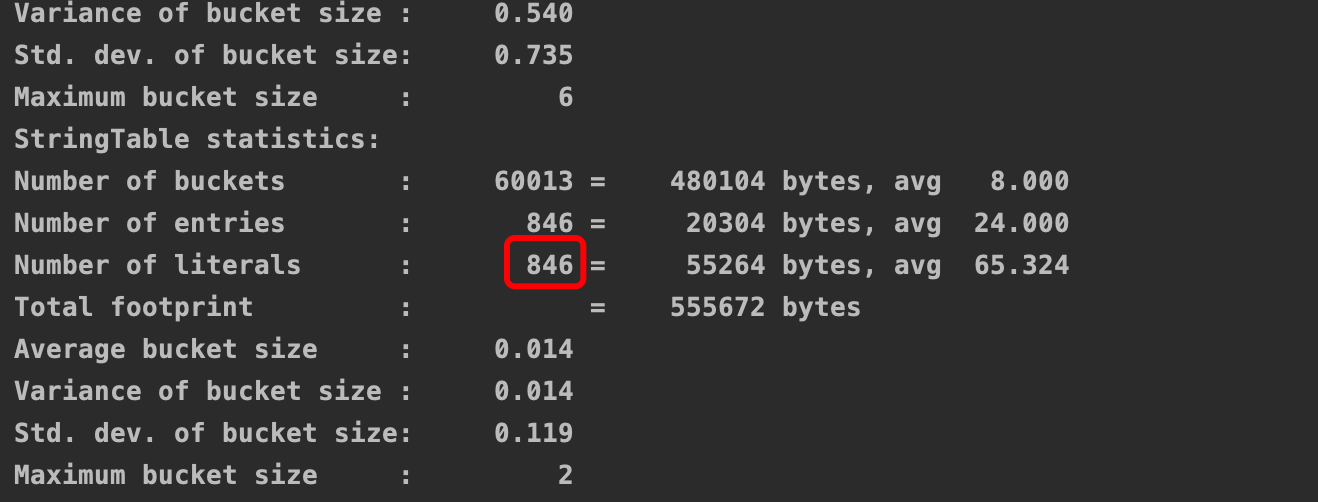
我们把100-199这100个数字的字符串也加到串池,再运行:
public class StringTableGCTest {
public static void main(String[] args) {
for (int i = 0; i < 200; i++) {
String.valueOf(i).intern();
}
}
}
可以看到字符串个数增加到946,此时是没有发生内存溢出的
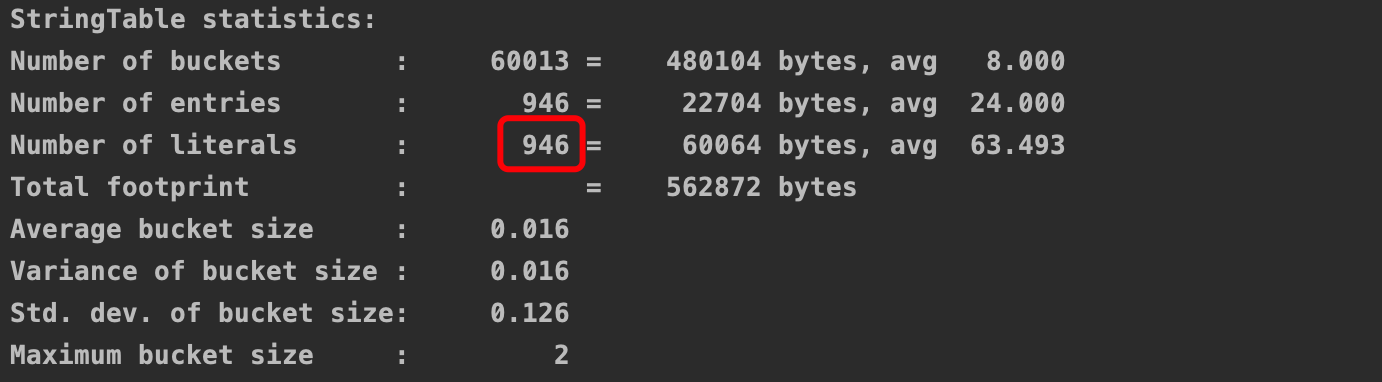
接着我们将字符串个数增大到100000,并且将堆最大内存设置为-Xmx10m,同时加上-XX:+PrintGCDetails参数,用于观看gc日志
public class StringTableGCTest {
public static void main(String[] args) {
for (int i = 0; i < 100000; i++) {
String.valueOf(i).intern();
}
}
}
可以看到结果串池中的字符串个数仅有3万多个
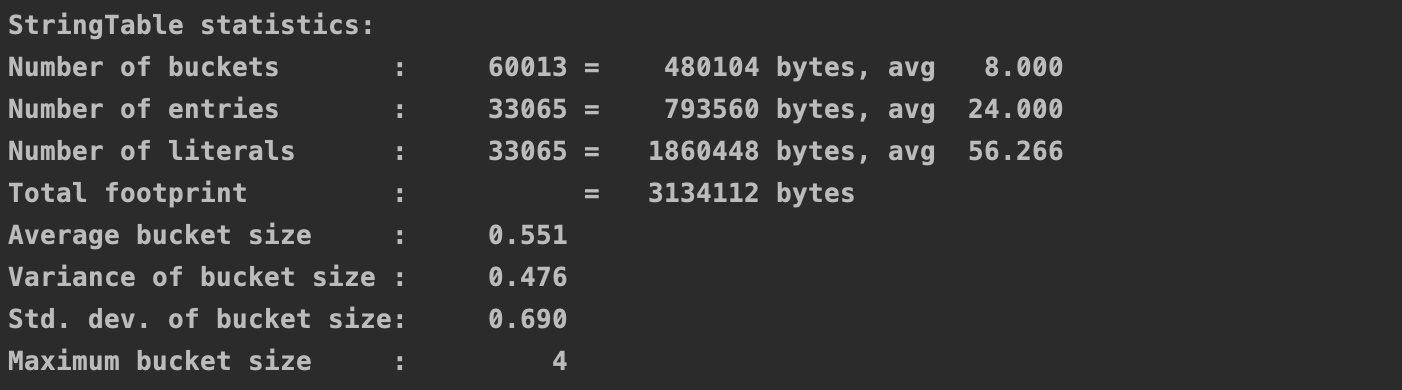
查看日志,可以看出发生了新生代的垃圾回收,这一点从侧面说明串池是存在于堆中的。

性能调优
设置桶大小
由于StringTable是一个hash表,bucket个数越大,越不容易发生hash冲突,效率也越高,我们可以通过jvm参数-XX:StringTableSize来增加桶的个数,看个例子,首先我们不修改StringTableSize(默认为60013),执行下面代码,往串池里面写入字符串:
package stringtable;
import java.util.Random;
/**
* 通过增加StringTable的Bucket个数,提高intern()效率
* VM Args: -XX:StringTableSize=500000 -XX:+PrintStringTableStatistics
* @author ct
* @date 2021/10/23
*/
public class StringTableSizeTest {
public static void main(String[] args) {
Random random = new Random(1);
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
String.valueOf(random.nextInt()).intern();
}
System.out.println("cost "+(System.currentTimeMillis() - start));
}
}
可以看到执行时间为800ms

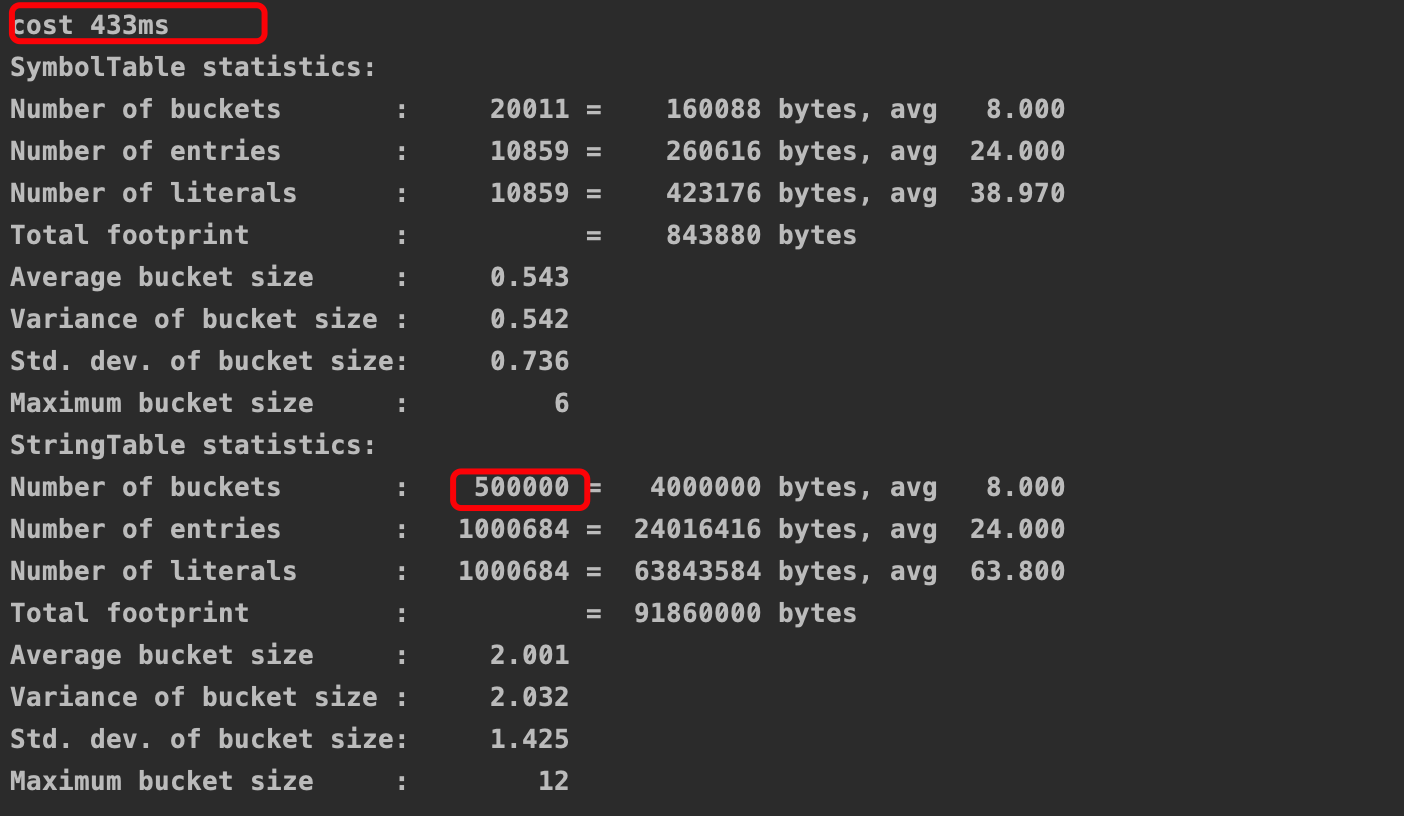
接着将StringTableSize改为500000
可以看到效率有将近一倍的提升















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









