






作者丨hey-hoho
来自神州数码钛合金战队
神州数码钛合金战队是一支致力于为企业提供分布式数据库 TiDB 整体解决方案的专业技术团队。团队成员拥有丰富的数据库从业背景,全部拥有 TiDB 高级资格证书,并活跃于 TiDB 开源社区,是官方认证合作伙伴。目前已为 10+ 客户提供了专业的 TiDB 交付服务,涵盖金融、证券、物流、电力、政府、零售等重点行业。
背景
TiDB 集群的监控面板里面有两个非常重要、且非常常用的指标,相信用了 TiDB 的都见过:
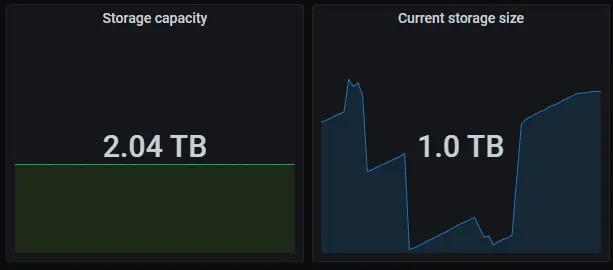
○ Storage capacity:集群的总容量
○ Current storage size:集群当前已经使用的空间大小
当你准备了一堆服务器,经过各种思考设计部署了一个 TiDB 集群,有没有想过这两个指标和服务器磁盘之间到底是啥关系?
反正我们经常被客户问这个问题,以前虽然能说出个大概,总体方向上没错,但是深究一下其实并不严谨,这次翻了源码彻底把这个问题搞清楚。开始之前再卖一个关子,大家可以看看自己手上的集群监控有没有这种情况:
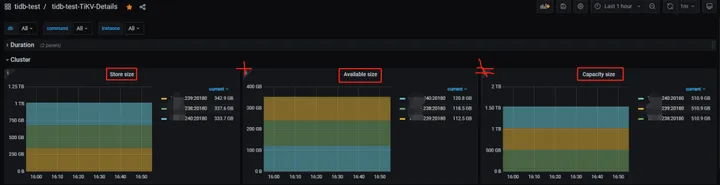
TiKV 实例的已用空间(store size)+ 可用空间(available size) ≠ 总空间(capacity size)
盘越大越明显。
再仔细点看,监控上显示的总容量大小和 TiKV 实例所在盘大小也不匹配。
是不是有“亿点”意外。
结论先行
○ PD 监控下的 Storage capacity 和 Current storage size 来自各个 store 的累加,这里 store 包含了 TiKV 和 TiFlash
○ Current storage size 包含了多个数据副本(TiKV 和 TiFlash 的所有副本数),非真实数据大小
○ TiKV 实例容量统计的是 TiKV 所在磁盘的整体大小与 raftstore.capacity 参数较小的值,同时监控用的 bytes(SI) 标准显示,就是说不是用 1024 做的转换而是 1000,所以和 df -h 输出的盘大小有差距
○ TiKV 实例的已用空间只统计了 data-dir 下的部分目录,非整个 data-dir 或整块盘
○ 基于前两条,可用空间也就不等于总空间减去已用空间了
看到的现象
本文描述的内容基于以下集群:
[tidb@localhost ~]$ tiup cluster display tidb-test
tiup is checking updates for component cluster ...
Starting component `cluster`: /home/tidb/.tiup/components/cluster/v1.13.0/tiup-cluster display tidb-test
Cluster type: tidb
Cluster name: tidb-test
Cluster version: v6.5.5
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://x.236:2379/dashboard
Grafana URL: http://x.242:3000
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
x.242:3000 grafana x.242 3000 linux/x86_64 Up - /data/tidb-deploy/grafana-3000
x.235:2379 pd x.235 2379/2380 linux/x86_64 Up /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
x.236:2379 pd x.236 2379/2380 linux/x86_64 Up|L|UI /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
x.237:2379 pd x.237 2379/2380 linux/x86_64 Up /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
x.242:9090 prometheus x.242 9090/12020 linux/x86_64 Up /data/tidb-data/prometheus-9090 /data/tidb-deploy/prometheus-9090
x.235:4000 tidb x.235 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
x.236:4000 tidb x.236 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
x.237:4000 tidb x.237 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
x.241:9000 tiflash x.241 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /data/tiflash/tidb-data/tiflash-9000 /data/tiflash/tidb-deploy/tiflash-9000
x.238:20160 tikv x.238 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
x.239:20160 tikv x.239 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
x.240:20160 tikv x.240 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160各节点磁盘情况(来自 TiDB Dashboard 统计):
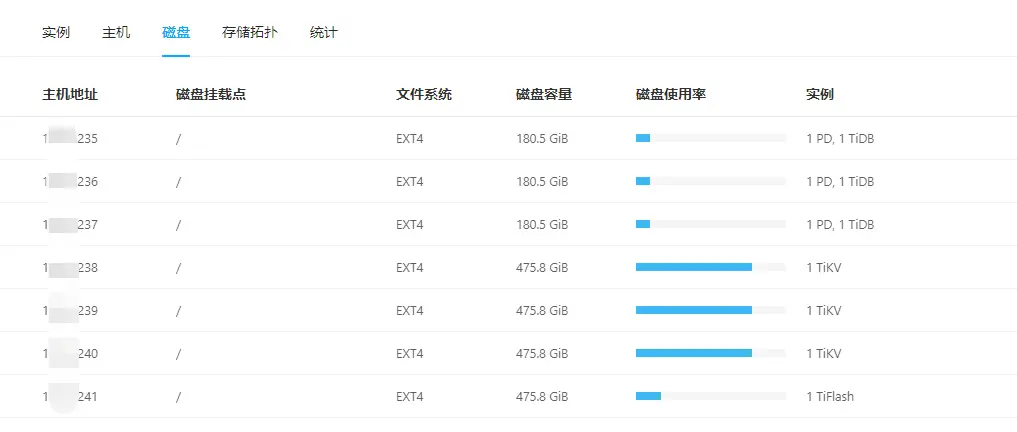
在此之前,我一直以为 PD 监控面板下的集群总空间是 PD 读取了所有 TiKV+TiFlash 实例部署盘的累计大小,所以我尝试把上图的 4 个存储节点的磁盘容量相加发现并不等于集群总容量(文章开头的图片有显示),差了 100 多个 G:
○ Dashboard 上 4 个存储节点磁盘容量均为 475.8G,累计容量 475.8G * 4 = 1903.2G
○ Grafana 显示的单个 TiKV 实例:510.9G,总空间:2.04 T
再和操作系统显示的磁盘容量对比,发现能和 Dashboard 显示的对应上:
[tidb@localhost ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 476G 347G 110G 77% /
devtmpfs 31G 0 31G 0% /dev
tmpfs 31G 4.0K 31G 1% /dev/shm
tmpfs 31G 3.1G 28G 10% /run
tmpfs 31G 0 31G 0% /sys/fs/cgroup
/dev/sda1 477M 138M 310M 31% /boot但仔细看容量单位的区别,发现 Dashboard 显示的是 GiB ,Grafana 显示的是 GB ,两者是有区别的。尝试在系统中用 GB 显示磁盘大小:
[tidb@localhost ~]$ df -H
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 511G 372G 118G 77% /
devtmpfs 34G 0 34G 0% /dev
tmpfs 34G 4.1k 34G 1% /dev/shm
tmpfs 34G 3.3G 30G 10% /run
tmpfs 34G 0 34G 0% /sys/fs/cgroup
/dev/sda1 500M 145M 325M 31% /boot这里输出的 511G 能和 Grafana 监控对应上,同时按 4 个 511G 的存储节点计算也能和总容量对应上。
但是用同样的方法并不能解释 TiKV 已用空间的偏差问题,检查结果如下:
# 输出内容为240节点tikv数据目录大小,但监控显示tikv已用空间333.7GB
[tidb@localhost ~]$ du -sh /data/tidb-data/tikv-20160
329G /data/tidb-data/tikv-20160
[tidb@localhost ~]$ du -sh --si /data/tidb-data/tikv-20160
353G /data/tidb-data/tikv-20160总结一下看到的现象:
○ Dashboard 上显示的 TiKV 盘大小(GiB)是实际部署盘的总大小,Grafana 也是部署盘的总大小但单位是 GB
○ Grafana 集群总容量是所有存储节点部署盘的累计大小(GB)
○ TiKV 实例已用空间大小计算方式未知(要搞清楚只能扒源码了)
不同进制转换带来的影响
这里简单提一下 GB 和 GiB 的区别,帮助大家理解。
○ GB 是按 10 进制来转换,也就是说 1GB=1000MB,市面上厂商宣传的大小都是 10 进制,可理解为商业标准
○ GiB 是按 2 进制来转换,也就是说 1GiB=1024MiB,计算机系统只认这个,可理解为事实标准
那么当你买了一台 128G 存储的手机,实际使用中会发现空间“缩水”了,U 盘、硬盘等也类似。
与这两个进制差异有关的还有两个行业标准,即 byte(SI) 和 byte(IEC) ,感兴趣的可以去查一下历史,这里只需要知道:
○ byte(SI) 对应十进制
○ byte(IEC) 对应二进制
Grafana 里面可以使用编辑监控面板调整显示单位,例如:
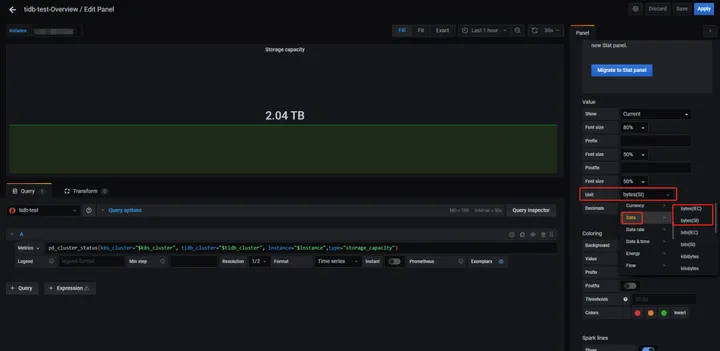
如果把单位统一的话,前 2 个现象就很好解释了。
但需要注意的是,在 Grafana 中并不是所有面板都采用了 byte(SI) ,甚至同一个指标也出现不同面板显示的单位不一样,比如 Overview 下面的 TiDB 分组内存面板使用十进制,System Info 分组内存面板使用二进制,用的时候要小心。
TiKV 的数据文件
要搞清楚 TiKV 的已用空间是怎么计算的,先提一下 TiKV 相关的数据文件。大家都知道 TiKV 底层用的 RocksDB 作为持久层,并且 raft 日志和实际数据分别对应一个 RocksDB 实例,那么看看 TiKV 的数据目录到底放了啥东西,以前面的集群为例:
[tidb@localhost ~]$ cd /data/tidb-data/tikv-20160
[tidb@localhost tikv-20160]$ ll -h
total 14G
drwxr-xr-x 2 tidb tidb 1.1M Dec 22 15:22 db
drwxr-xr-x 4 tidb tidb 132K Dec 21 18:20 import
-rw-r--r-- 1 tidb tidb 20K Nov 15 14:47 last_tikv.toml
-rw-r--r-- 1 tidb tidb 0 Nov 15 14:53 LOCK
-rw-r--r-- 1 tidb tidb 301M Mar 3 2023 raftdb-2023-03-03T17-32-13.506.info
...
-rw-r--r-- 1 tidb tidb 301M Nov 13 21:51 raftdb-2023-11-13T21-51-00.249.info
-rw-r--r-- 1 tidb tidb 31M Nov 15 14:47 raftdb.info
drwxr-xr-x 2 tidb tidb 4.0K Dec 22 00:08 raft-engine
-rw-r--r-- 1 tidb tidb 301M Jan 18 2023 rocksdb-2023-01-18T10-12-55.000.info
...
-rw-r--r-- 1 tidb tidb 301M Dec 7 03:01 rocksdb-2023-12-07T03-01-02.905.info
-rw-r--r-- 1 tidb tidb 197M Dec 22 17:11 rocksdb.info
drwxr-xr-x 2 tidb tidb 4.0K Dec 21 16:27 snap
-rw-r--r-- 1 tidb tidb 4.8G Nov 15 14:53 space_placeholder_file几类文件解读一下:
○ db 目录,这是最终数据的存放目录, db 在源码中写死无法修改
○ rocksdb[-xxx-xxx].info 文件,数据 RocksDB 实例的日志文件,已经按日期归档好的可手动删除
○ raft-engine 目录,这是 raft 日志存放目录,受参数 raft-engine.dir 控制,没有开启 Raft Engine 特性时名称默认为 raft ,受参数 raftstore.raftdb-path 控制
○ raftdb[-xxx-xxx].info 文件,raft 日志 RocksDB 实例的日志文件,已经按日期归档好的可手动删除
○ snap 目录,快照数据存放目录
○ import 目录,看名字是和导入相关,具体什么作用未知
○ space_placeholder_file 文件,预留空间的临时文件(TiKV 磁盘告警救急用,磁盘越大这个文件越大),相关参数 storage.reserve-space
○ last_tikv.toml 和 LOCK 文件,看名字猜测就行
从前面的观察来看,被监控统计到的 TiKV 已用空间比整个数据目录要小,那么可以推测出只统计了数据目录下的部分文件或目录,具体是哪些就要从源码里寻找答案。
Show Me The Code
TiDB 的监控数据分为两类,一类是服务器环境信息(CPU、内存、磁盘、网络等),一类是 TiDB 运行指标(Duration、QPS、Region 数、容量等)。前者通过与 Prometheus 配套的标准探针采集,即 node_exporter 和 black_exporter ,后者通过在源码中类似埋点方式采集数据然后由 Prometheus 来拉取。
import (
...
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/collectors"
...
)
var (
// PanicCounter measures the count of panics.
PanicCounter *prometheus.CounterVec
// MemoryUsage measures the usage gauge of memory.
MemoryUsage *prometheus.GaugeVec
)以集群总容量这个指标入手,看看在源码中它是如何采集的。对应的公式:
pd_cluster_status{k8s_cluster="$k8s_cluster", tidb_cluster="$tidb_cluster", instance="$instance",type="storage_capacity"}用关键字 storage_capacity 去 PD 源码里搜索找到如下代码:
func (s *storeStatistics) Collect() {
placementStatusGauge.Reset()
metrics := make(map[string]float64)
...
metrics["storage_capacity"] = float64(s.StorageCapacity)
for typ, value := range metrics {
clusterStatusGauge.WithLabelValues(typ).Set(value)
}
...
}数据来自 storeStatistics 的 StorageCapacity 字段,根据引用关系继续往上翻:
func (s *storeStatistics) Observe(store *core.StoreInfo) {
...
// Store stats.
s.StorageSize += store.StorageSize()
s.StorageCapacity += store.GetCapacity()
...
}从这里可以看出总容量(Storage capacity)和总已用空间(Current storage size)都是从各个 store 累加得来,并不是 pd 直接从存储节点计算。
继续看 GetCapacity() 是如何实现:
func (ss *storeStats) GetCapacity() uint64 {
ss.mu.RLock()
defer ss.mu.RUnlock()
return ss.rawStats.GetCapacity()
}
func newStoreStats() *storeStats {
return &storeStats{
rawStats: &pdpb.StoreStats{},
avgAvailable: movingaverage.NewHMA(60), // take 10 minutes sample under 10s heartbeat rate
}
}这里 rawStats 是一个 pdpb.StoreStats 类型,引用了另一个仓库: https://github.com/pingcap/kvproto 。最终实现为:
// https://github.com/pingcap/kvproto/blob/master/pkg/pdpb/pdpb.pb.go#L4371C1-L4376C2
func (m *StoreStats) GetCapacity() uint64 {
if m != nil {
return m.Capacity
}
return 0
}从调用关系来看,说明 PD 采集的数据都是来自 TiKV 上报(heartbeat)。继续追踪 TiKV 源码,以 heartbeat 为突破口:
pub fn handle_store_heartbeat(
&mut self,
mut stats: pdpb::StoreStats,
is_fake_hb: bool,
store_report: Option<pdpb::StoreReport>,
) {
...
let (capacity, used_size, available) = self.collect_engine_size().unwrap_or_default();
if available == 0 {
warn!(self.logger, "no available space");
}
stats.set_capacity(capacity);
stats.set_used_size(used_size);
stats.set_available(available);
...
}这里的 stats 正是一个 pdpb::StoreStats 类型,我们想要分析的 3 个指标都在这,继续看他们的出处 collect_engine_size() :
fn collect_engine_size<EK: KvEngine, ER: RaftEngine>(
coprocessor_host: &CoprocessorHost<EK>,
store_info: Option<&StoreInfo<EK, ER>>,
snap_mgr_size: u64,
) -> Option<(u64, u64, u64)> {
if let Some(engine_size) = coprocessor_host.on_compute_engine_size() {
return Some((engine_size.capacity, engine_size.used, engine_size.avail));
}
let store_info = store_info.unwrap();
// 这里跟根据kv engine的目录(${data_dir}/db)获取了所在磁盘的信息
let disk_stats = match fs2::statvfs(store_info.kv_engine.path()) {
Err(e) => {
error!(
"get disk stat for rocksdb failed";
"engine_path" => store_info.kv_engine.path(),
"err" => ?e
);
return None;
}
Ok(stats) => stats,
};
// total_space得到磁盘的总容量,参考API:https://docs.rs/fs2/latest/fs2/fn.total_space.html
let disk_cap = disk_stats.total_space();
// 计算得出tikv实例的容量,用磁盘容量与参数设置的容量(raftstore.capacity)相比
// 如果没有设置raftstore.capacity参数,或者是磁盘容量小于设置的容量,那么取磁盘容量,否则取设置的容量,本质就是取较小的那个
let capacity = if store_info.capacity == 0 || disk_cap < store_info.capacity {
disk_cap
} else {
store_info.capacity
};
// 计算已用大小,快照大小(snap目录) + kv engine大小(db目录) + raft engine大小(raft-engine目录)
let used_size = snap_mgr_size
+ store_info
.kv_engine
.get_engine_used_size()
.expect("kv engine used size")
+ store_info
.raft_engine
.get_engine_size()
.expect("raft engine used size");
// 计算逻辑可用空间,总容量-已用空间
let mut available = capacity.checked_sub(used_size).unwrap_or_default();
// We only care about rocksdb SST file size, so we should check disk available
// here.
// 最终可用空间是取逻辑可用和磁盘可用的较小值
available = cmp::min(available, disk_stats.available_space());
Some((capacity, used_size, available))
}核心逻辑分析都写在注释里,值得认真一看!
以为扒到这里就 happy ending 了,但是偶然又发现了另一个方法让我陷入沉思:
fn init_storage_stats_task(&self, engines: Engines<RocksEngine, ER>) {
...
self.background_worker
.spawn_interval_task(DEFAULT_STORAGE_STATS_INTERVAL, move || {
let disk_stats = match fs2::statvfs(&store_path) {
Err(e) => {
error!(
"get disk stat for kv store failed";
"kv path" => store_path.to_str(),
"err" => ?e
);
return;
}
Ok(stats) => stats,
};
let disk_cap = disk_stats.total_space();
let snap_size = snap_mgr.get_total_snap_size().unwrap();
let kv_size = engines
.kv
.get_engine_used_size()
.expect("get kv engine size");
let raft_size = engines
.raft
.get_engine_size()
.expect("get raft engine size");
...
let placeholer_file_path = PathBuf::from_str(&data_dir)
.unwrap()
.join(Path::new(file_system::SPACE_PLACEHOLDER_FILE));
let placeholder_size: u64 =
file_system::get_file_size(placeholer_file_path).unwrap_or(0);
// 这里的已用空间计算方式与heartbeat有区别,把space_placeholder_file文件算进去了,还加了raft engine单独部署的逻辑
let used_size = if !separated_raft_mount_path {
snap_size + kv_size + raft_size + placeholder_size
} else {
snap_size + kv_size + placeholder_size
};
let capacity = if config_disk_capacity == 0 || disk_cap < config_disk_capacity {
disk_cap
} else {
config_disk_capacity
};
let mut available = capacity.checked_sub(used_size).unwrap_or_default();
available = cmp::min(available, disk_stats.available_space());
...
})
}init_storage_stats_task 在 tikv 启动时被调用,就是说这是几个指标在初始化时的计算方式,整体逻辑与 heartbeat 上报并无区别,但已用空间计算方式有轻微差异:
○ space_placeholder_file 被算进去了
○ 如果 raft engine 使用了单独的部署目录(代码里叫 path_in_diff_mount_point),那么 raft 日志的大小是不算在 tikv 已用空间内的
看起来前后计算不一致,但是由于 heartbeat 是持续更新的,最终是以 heartbeat 上报的为准。
○ PD 源码仓库: https://github.com/tikv/pd
○ TiKV 源码仓库: https://github.com/tikv/tikv
结尾
结论已经在文章开头给出了,希望大家看了本文都能对 TiDB 集群的各种空间计算有了清晰的认识。
本文只讨论的 TiKV 的容量计算细节,TiFlash 的计算方式也类似,我对比了 Ti F lash 的数据目录大小和监控显示已用大小 10 多 G 的差距,应该也是只计算了部分目录,但是总容量还是算的整块盘。不太熟悉 c++,留给其他大佬去探索吧 。
发


















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









