







Java通过HAPI解析HL7消息
HL7(详情)
Health Level Seven组织成立於1987年,由SamSchultz博士在宾夕法尼亚州大学医院主持的一次会议促成了HL7组织和通信标准的诞生。随着许多用户、厂商、顾问组织的加入,HL7队伍在逐渐壮大,于是成立了HL7工作组。(官网)
使用的HAPI(maven)
<dependency>
<groupId>ca.uhn.hapi</groupId>
<artifactId>hapi-base</artifactId>
<version>${hapi.version}</version>
</dependency>
<dependency>
<groupId>ca.uhn.hapi</groupId>
<artifactId>hapi-structures-v24</artifactId>
<version>${hapi.version}</version>
</dependency>
解析
package com.dy.mms.util;
import ca.uhn.hl7v2.HL7Exception;
import ca.uhn.hl7v2.model.Message;
import ca.uhn.hl7v2.model.v24.message.ACK;
import ca.uhn.hl7v2.parser.PipeParser;
/**
* HL7消息解析工具
*/
public class HL7ParseUtil {
/**
* 解析
* @param hl7Str
* @return
* @throws HL7Exception
*/
public static Message parse(String hl7Str) throws HL7Exception {
// 解析器
PipeParser parser = new PipeParser();
// 解析
Message message = parser.parse(hl7Str);
if (message instanceof ACK) {
// 如果确认是ACK消息可以直接返回ACK
return (ACK) message;
}
return message;
}
public static void main(String[] args) throws Exception {
// HL7消息
String hl7Str = "MSH|^~\\&|foo|foo||foo|202103151718||ACK^A01^ACK|1|D|2.4|\rMSA|AA\r";
// 解析为消息
Message message = HL7ParseUtil.parse(hl7Str);
// 输出原消息
System.out.println(message.encode().replaceAll("\r", "\r\n"));
}
}
解读Message
Message

names

表明这个消息中有三个段落,分别是什么。(虽然从原字符串中我们只看到了两个段落,但是由于这条消息是由HL7定义的ACK消息,所以解析完成后显示他有三个段落);
required

表明这三个段落那个是不能为空,这里解析之后我们发现ERR字段可以为空(false);
repeating

表明这三个段落可以有多个吗,这里全都不可以(false);
structures(重点)

structures(Map,kv结构)为这个消息的全部内容,以下我们对重点字段进行分析:
key:段落名
value:段落内容
fields:字段内容

可以看到MSH这个段落有21个字段,每个字段又是一个集合,表明字段里可以有多个值,每个字段(组件)中可能还包括子组件(不多说了,大家自己看);
types:字段类型
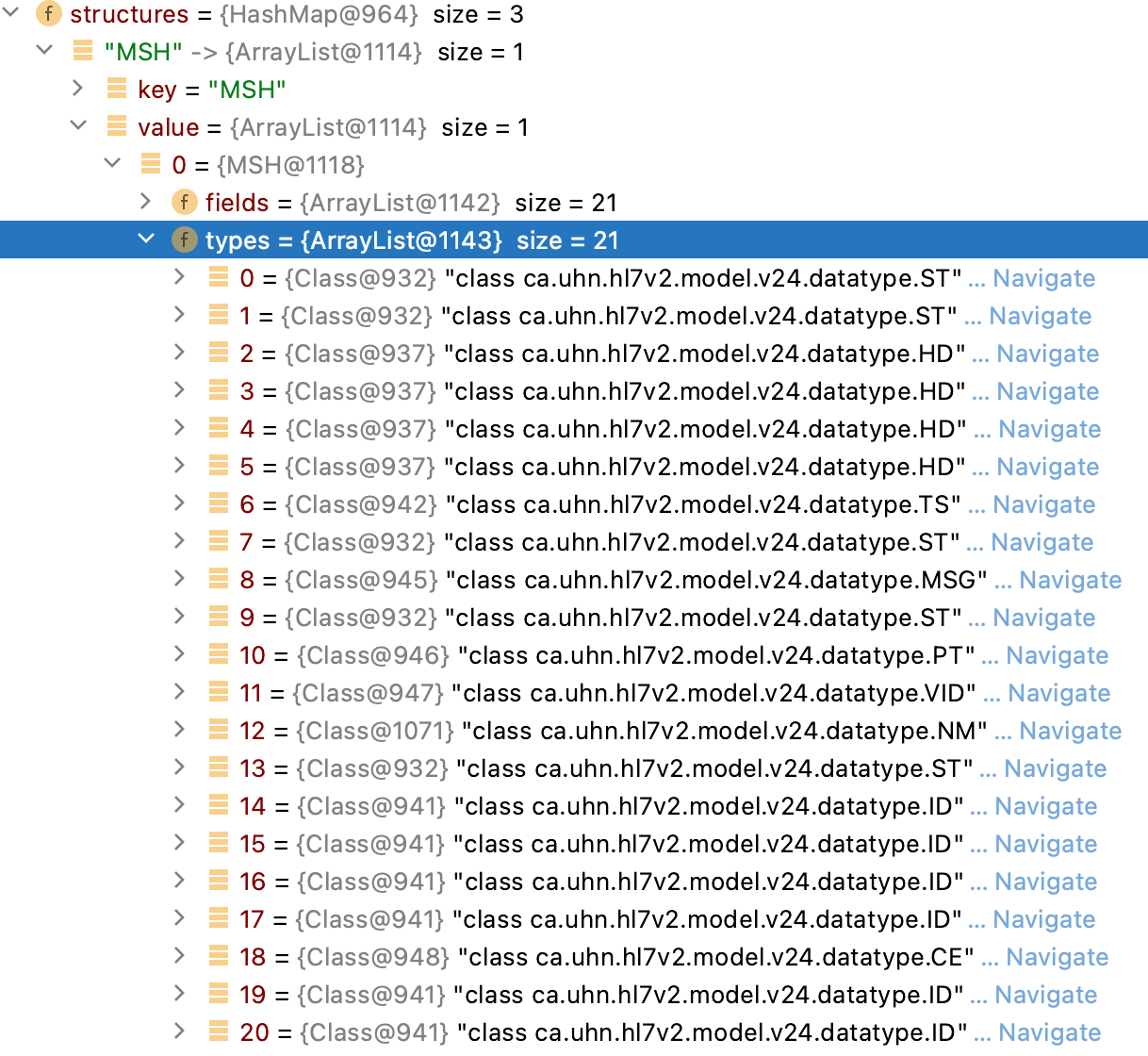
每个字段是什么类型的值;
HL7定义的类型:
| 类型编码 | 类型说明 |
|---|---|
| ST | 字符串 |
| TX | 文本数据 |
| FT | 格式化文本 |
| NM | 数字 |
| SI | 序列ID号 |
| SN | 结构化数据 |
| ID | HL7表的编码值 |
| IS | 用户定义表的编码 |
| EI | 实体标识符 |
| DT | 日期 |
| TM | 时间 |
| CE | 编码要素 |
| CX | 具有校验数位的扩展符合ID |
| XCN | 扩展符合ID号和ID名 |
| XAD | 扩展地址 |
| XPN | 扩展姓名 |
| XTN | 扩展通讯号码 |
names:字段名

每个字段的名称,从字面意思就能够看出每个字段内容的含义;
剩下的字段大家自己消化
以上就是我总结的HL7解析过程,大家可以在解析过程中加入自定义代码以便使用。
原创不宜,请勿抄袭!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











