







- Assumptions:
- built from many commodity machines and able to detect and recover from failures
- Store modest number of large files and thus optimize for it
- Primarily two kinds of read
- large streaming read & small random read
- thus batch and sort small read to advance steadily through the file
- Most write is large & sequential append to files
- Atomicity for cocurrently append to the same file
- High sustained bandwidth more important than low latency
- Normal file system interface
- Snapshot on a file or directory & Record append useful for implementing multi-way merge results and producer-cosumer queues
- Architecture

- Chunkserver stores chunks on local disk as Linux files and each chunk is replicated on mutiple chunkservers(by default 3, each chunk replica is a normal file)
- Master Responsibilty
- Maitain file system metadata
- name space
- access control information
- mapping from files to chunks and chunk's current locations
- control system activities
- chunk lease management
- garbage collection of orphaned chunks
- chunk migratin between chunk servers
- Maitain file system metadata
- No file data cache on chunk server or client
- no cache coherence issue
- client cache meta data(no file data because stream through too large file to be cached)
- chunk server Linux buffer cache will do cache work
- Chunk Size(default 64MB)
- Large chunk size will reduce metadata size, which will enable master keep them in memory, reduce network interaction overhead between master and chunkserver, keep client and chunkserver tcp connection for a long time and reduce the connection setup overhead.
- For small files, large chunk size may cause some chunkservers to be hot spot. One solution is to increase the replication factor
- Metadata
- all kept in master's memory
- easy and efficient for maste to scan through it
- file names stored compactly with prefix compression
- file and chunk namespaces, mapping from file to chunks are also kept persistentby logging mutations tooperation logs stonred on master's local disk and replicated on remote machines
- chunk locations not persistent
- poll chunkservers for the info at its startup and periodically thereafter
- eliminate problem of keeping master and chunkservers in sync
- Operation log
- central to GFS
- master checkpoints its state when log grows beyond a certain size
- when recover, first load latest checkpoints from local disk and then replay log
- two log files which is switched when checkpoint is created
- all kept in master's memory
- Consistency Model
- file namespace mutations are atomic by exculsive lock of master
- file region state after mutations
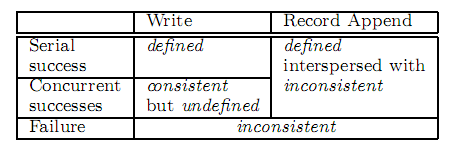
- A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
- A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety.
- A record append causes data (the “record”) to be appended atomically at least once(may dup)even in the presence of concurrent mutations, but at an offset of GFS’s choosing
- file region is guaranteed defined after a sequence of successful mutations and contains last written data
- apply mutations in the same order to all replicas
- using chunk version number to detect stale replicas which will be garbage collected
- client cache may be stale before cache time out
- detect data corruption by checksum and restore from valid replicas
- A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
- Implications for application
- relying on appends rather than overwrites, checkpointing, and writing self-validating, self-identifying records.
- relying on appends rather than overwrites, checkpointing, and writing self-validating, self-identifying records.
- System Interactions
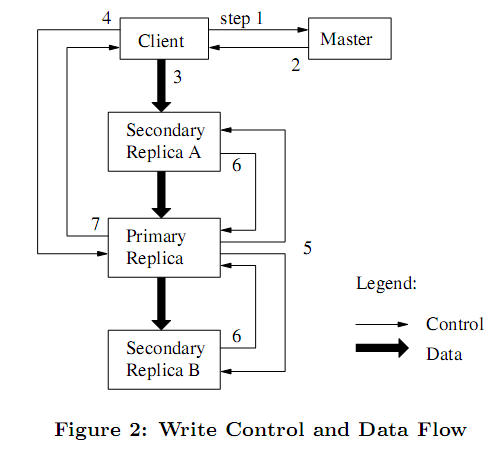
- client asks master for primary chunkserver holding current lease for the chunk and other replicas' location. If no one has a lease, the master grants one to a replica it chooses.
- The master replies with the primary identy and otherreplicas' location which client caches. It needs to contact the master again only when the primary becomes unreachable or replies that it no longer holds a lease.
- The client pushes the data to all the replicas in any proper order which is stored in an internal LRU buffer cache of each chunkserver until it is used or aged out.
- Once all the replicas have acknowledged receiving the data, the client sends a write requestto the primary. The primary assigns consecutive serial numbers to all the mutations it receives and applies the mutation to its own local state in serial number order.
- The primary forwards the write request to all secondary replicas.
- The secondaries all reply to the primary indicating that they have completed the operation.
- The primary replies to the client. Any errors encountered at any of the replicas are reported to the client(??Primary发起重试改进). Client will usually retry in error case.
- Application cross boundary write is breaked down to mutiple mutations by GFS client code
- Data flow is decoupled with control flow and data is pushed linearly along carefully picked chunkserver chain.
- Snapshot
- makes a copy of a file or a directory tree (the “source”) almost instantaneously
- When the master receives a snapshot request, it first revokes any outstanding leases on the chunksin the files it is about to snapshot.
- After the leases have been revoked or have expired, the master logs the operation to disk
- It then applies this log record to its in-memory state by duplicating the metadata for the source file or directory tree. The newly created snapshot files(GFS中没有的namespace只是一个prefix tree,目录中没有像普通文件系统的entry之类需要保护的内容) point to the same chunks as the source files
- The first time a client wants to write to a chunk C after the snapshot operation, it sends a request to the master to find the current lease holder
- The master notices that the reference count for chunkC is greater than one. It defers replying to the client request and instead picks a new chunk handle C’. It then asks each chunkserver that has a current replica of C to create a new chunkcalled C.
- From this point, request handling is no different from that for any chunk: the master grants one of the replicas a lease on the new chunkC’ and replies to the client, which can write the chunk normally.
- makes a copy of a file or a directory tree (the “source”) almost instantaneously
- Master Operations
- Namespace management and locking
- Have no per-directory structures that list all files for that directory; hard/symbol link not supported
- Namespace represented as a prefix tree mapping full path to metadata(如何持久化??)
- Each node has a read-write lock
- File creation does not require write-lock its parent directory, only write-lock the created file name
- For each operation, aquire read-lock on all nodes on the path and read/write lock on the leaf
- lock is ordered by level in namespace tree and lexicographically within the same level
- Replica Management
- two purposes
- maximize data reliability and availability
- maximize networkbandwidth utilization
- Chunk creation, re-replication, ere-balancing
- equalizing diskspace utilization
- limiting active clone operations on any single chunkserver
- spreading replicas across racks
- priority-based
- Garbage collection
- deletion is logged and the file is renamed to a hidden file with deletion timestamp included
- the hidden file's metadata is deleted during master's regular scan of file namespace namespace if it existed for more than 3 days
- orphaned chunks' metadata is erased similarly
- In a HeartBeat message regularly exchanged with the master, each chunkserver reports a subset of the chunks it has, and the master replies with the identity of all chunks that are no longer present in the master’s metadata. The chunkserver is free to delete its replicas of such chunks.
- Stale Replica detection
- chunk version number that is updated each time a lease is granted
- HA
- Fast recovery and chunk/master replications
- Data Integrity
- checksum for 64k blocks stored on each chunkservers seperated from user data
- Performance
- Write: half theoretical limit
- Record Append: 6MB for 16 clients; Performance is limited by the networkbandwidth of the chunkservers that store the last chunkof the file, independent of the num-
ber of clients(??为什么Record append from different client to 1 file不能并发??)














 3053
3053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









