






原文链接: https://blog.csdn.net/kavito/article/details/91403659
RabbitMQ:基于AMQP协议,erlang语言开发
RabbitMQ的工作原理
下图是RabbitMQ的基本结构:
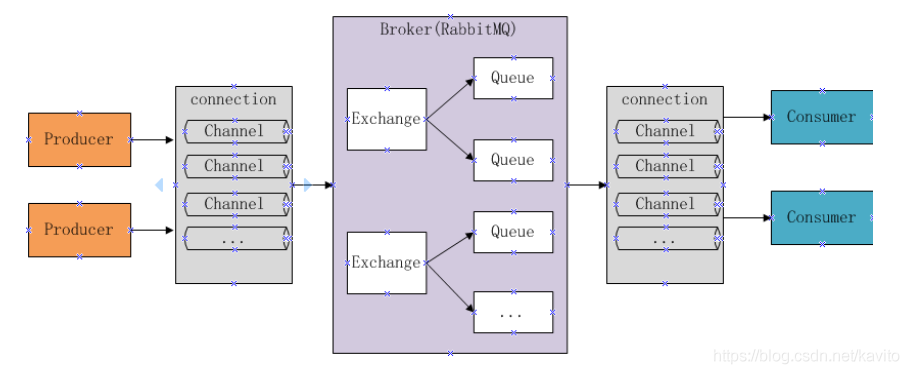
组成部分说明:
Broker:消息队列服务进程,此进程包括两个部分:Exchange和Queue
Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。
Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的
Producer:消息生产者,即生产方客户端,生产方客户端将消息发送
Consumer:消息消费者,即消费方客户端,接收MQ转发的消息。
生产者发送消息流程:
1、生产者和Broker建立TCP连接。
2、生产者和Broker建立通道。
3、生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
4、Exchange将消息转发到指定的Queue(队列)
消费者接收消息流程:
1、消费者和Broker建立TCP连接
2、消费者和Broker建立通道
3、消费者监听指定的Queue(队列)
4、当有消息到达Queue时Broker默认将消息推送给消费者。
5、消费者接收到消息。
6、ack回复
消息确认机制(ACK)
消息一旦被消费者接收,队列中的消息就会被删除,RabbitMQ怎么知道消息被接收了呢?
RabbitMQ有一个ACK机制。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
-
自动ACK:消息一旦被接收,消费者自动发送ACK
-
手动ACK:消息接收后,不会发送ACK,需要手动调用
生产者避免数据丢失:https://www.cnblogs.com/vipstone/p/9350075.html
正常情况下,如果消息经过交换器进入队列就可以完成消息的持久化,但如果消息在没有到达broker之前出现意外,那就造成消息丢失,有没有办法可以解决这个问题?
RabbitMQ有两种方式来解决这个问题:
- 通过AMQP提供的事务机制实现;
- 使用发送者确认模式实现;
六种消息模式
1.基本消息模型

在上图的模型中,有以下概念:
-
P:生产者,也就是要发送消息的程序
-
C:消费者:消息的接受者,会一直等待消息到来。
-
queue:消息队列,图中红色部分。可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
2.work消息模式

work queues与入门程序相比,多了一个消费端,两个消费端共同消费同一个队列中的消息,但是一个消息只能被一个消费者获取。
这个消息模型在Web应用程序中特别有用,可以处理短的HTTP请求窗口中无法处理复杂的任务。
接下来我们来模拟这个流程:
P:生产者:任务的发布者
C1:消费者1:领取任务并且完成任务,假设完成速度较慢(模拟耗时)
C2:消费者2:领取任务并且完成任务,假设完成速度较快
订阅模型分类
1、一个生产者多个消费者
2、每个消费者都有一个自己的队列
3、生产者没有将消息直接发送给队列,而是发送给exchange(交换机、转发器)
4、每个队列都需要绑定到交换机上
5、生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者消费
例子:注册->发邮件、发短信
X(Exchanges):交换机一方面:接收生产者发送的消息。另一方面:知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange类型有以下几种:
Fanout:广播,将消息交给所有绑定到交换机的队列
Direct:定向,把消息交给符合指定routing key 的队列
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Header:header模式与routing不同的地方在于,header模式取消routingkey,使用header中的 key/value(键值对)匹配队列。
Header模式不展开了,感兴趣可以参考这篇文章https://blog.csdn.net/zhu_tianwei/article/details/40923131
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
3.Publish/subscribe(交换机类型:Fanout,也称为广播 )

生产者
和前面两种模式不同:
-
1) 声明Exchange,不再声明Queue
-
2) 发送消息到Exchange,不再发送到Queue
publish/subscribe与work queues有什么区别。
区别:
1)work queues不用定义交换机,而publish/subscribe需要定义交换机。
2)publish/subscribe的生产方是面向交换机发送消息,work queues的生产方是面向队列发送消息(底层使用默认交换机)。
3)publish/subscribe需要设置队列和交换机的绑定,work queues不需要设置,实际上work queues会将队列绑定到默认的交换机 。
相同点:
所以两者实现的发布/订阅的效果是一样的,多个消费端监听同一个队列不会重复消费消息。
2、实际工作用 publish/subscribe还是work queues。
建议使用 publish/subscribe,发布订阅模式比工作队列模式更强大(也可以做到同一队列竞争),并且发布订阅模式可以指定自己专用的交换机。
4.Routing 路由模型(交换机类型:direct)

P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
5.Topics 通配符模式(交换机类型:topics)

每个消费者监听自己的队列,并且设置带统配符的routingkey,生产者将消息发给broker,由交换机根据routingkey来转发消息到指定的队列。
Routingkey一般都是有一个或者多个单词组成,多个单词之间以“.”分割,例如:inform.sms
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
audit.#:能够匹配audit.irs.corporate 或者 audit.irs
audit.*:只能匹配audit.irs
6.RPC

基本概念:
Callback queue 回调队列,客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识,客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
面试题:
避免消息堆积?
1) 采用workqueue,多个消费者监听同一队列。
2)接收到消息以后,而是通过线程池,异步消费。
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
但是,如果在消费者消费之前,MQ就宕机了,消息就没了?
2)可以将消息进行持久化。要将消息持久化,前提是:队列、Exchange都持久化















 5488
5488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









