



参考链接:视频学习连接
文章目录
- 一、Linux系统编程入门
- 二、Linux多进程开发
- 三、Linux 多线程开发
- 四、Linux网络编程
- 五、项目实战与总结
一、Linux系统编程入门
1.1 GCC工作流程



gcc .c文件名 -o 输出文件名
g++ .cpp文件名 -o 输出文件名
生成可执行文件
1.2静态库
提前编写好的,编译的时候需要加到main的编译文件中去
1.2.1命名规则:
linux: libxxx.a
lib: 前缀(固定)
xxx:库的名字(自己取)
.a:后缀(固定)
windows: libxxx.lib
1.2.2静态库制作:
- gcc获得 .o 文件
- 将 .o 文件打包,使用 ar工具(archieve)
ar rcs libxxx.a xxx.o xxx.o
r - 将文件插入备存文件中
c - 建立备存文件
s - 索引
gcc -c 文件名1.c 文件名2.c 文件名3.c //编译、汇编成 .o 文件
1.2.3静态库使用:
库(一些函数等源码 .c 文件 生成 .o 文件然后打包成 .a 库文件) 跟 .h头文件

1.3动态库



直接将制作好的动态库与main.cpp文件一起编译成可执行文件,运行可执行文件会报错
因为动态库在编译的时候没有打包到main.cpp的可执行文件中(静态库会打包到可执行文件中),而是在运行时加载到内存,然后在内存中读取。
可使用环境变量解决
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:(lib的绝对路径)
1.4静态库与动态库的优缺点
a. 静态库在程序的链接阶段被复制到可执行程序中;
优点:
静态库被打包到应用程序,对静态库的加载更快;
发布应用程序时无需提供静态库;方便移植
缺点:
静态库被多个程序使用时,会被复制好几份,浪费空间
更新部署发布麻烦;修改维护库文件都要重新打包到所有应用程序
b. 动态库是程序在运行时由系统动态地加载到内存中供程序使用
优点:
实现进程间资源共享,不需要复制好几份
更新部署发布简单
缺点:
速度相对于静态库更慢
发布时需要提供动态库
共同好处:代码保密,方便部署和分发(库和库所依赖的头文件)
1.4 Makefile
1.4.1命名:
Makefile或者makefile 不然make命令识别不了
1.4.2 规则:
一个Makefile可以有一个或多个规则
目标...:依赖 ...
命令(shell命令)
app: add.c div.c main.c mult.c sub.c
gcc -o app add.c div.c main.c mult.c sub.c
- 目标:最终要生成为文件
- 依赖:生成目标所需要的文件
- 命令:通过执行命令对依赖操作生成目标 注意有tab缩进
vim Makefile
1.4.3 工作原理:
命令执行之前,检查规则中的依赖是否存在。
存在,则执行
不存在,检查下面的规则,看有没有目标是此依赖的规则,若找到,则执行这条规则中的命令。
在执行make时,若目标已存在,会检测更新,通过检查目标和依赖的更新时间:
- 若目标更新时间早于依赖,则会重新执行此命令
- 若目标更新时间晚于依赖,则不会重新执行此命令
app: add.o div.o main.o mult.o sub.o
gcc -o app add.o div.o main.o mult.o sub.o
add.o: add.c
gcc -c add.c -o add.o
div.o: div.c
gcc -c div.c -o div.o
main.o: main.c
gcc -c main.c -o main.o
mult.o: mult.c
gcc -c mult.c -o mult.o
sub.o: sub.c
gcc -c sub.c -o sub.o
// 这种写法检测更新时效率更高,当修改某个单独的文件时,通过检测更新,
只会执行特定的命令,不会执行全部命令
1.4.4 变量:
自定义变量:
变量名=变量值 (var = hello)
获取变量的值
$(变量名) $(var)
预定义变量:
- AR:归档维护程序的名称,默认ar
- CC:C编译器的名称,默认gcc
- CXX:C++编译器的名称,默认g++
- $@: 目标的完整名称
- $^:所有的依赖文件名称
- $<:第一个依赖文件的名称

1.4.5 模式匹配:
%.o: %.c
- % 通配符,匹配一个字符串
- 两个%匹配的是同一个字符串
# 定义变量
src = add.o div.o main.o mult.o sub.o
target = app
$(target): $(src)
$(CC) -o $(target) $(src)
# 模式匹配
%.o: %.c
$(CC) -c -o $@ $<
#常规模式
add.o: add.c
gcc -c add.c -o add.o
div.o: div.c
gcc -c div.c -o div.o
main.o: main.c
gcc -c main.c -o main.o
mult.o: mult.c
gcc -c mult.c -o mult.o
sub.o: sub.c
gcc -c sub.c -o sub.o
1.4.6 函数
makefile中所有的函数必须都有返回值
wildcard
查找指定目录下指定类型的文件,一个参数
src=$(wildcard ./src/*.c)
找到 ./src 目录下所有后缀为 .c 的文件,赋给变量 src
patsubst
匹配替换,从 sec 中找到所有 .c 结尾的文件,并将其替换为 .o
obj=$(patsubst %.c,%.o,%(src))
把 src 变量中所有后缀为 .c 的文件替换成 .o
ob=$(patsubst ./src/%.c,./obj/%.o,%(src))
指定 .o 文件存放的路径 ./obj/%.o
1.4.7 clean
# 定义伪目标,防止有歧义
.PHONY:clean all
# 添加清理功能
clean:
-@rm -f *.o # 加 @表示指令不输出
-@rm -f app.out
1.5 GDB调试工具
vim命令显示行号 :set nu
GDB 主要帮助你完成下面四个方面的功能:
1. 启动程序,可以按照自定义的要求随心所欲的运行程序
2. 可让被调试的程序在所指定的调置的断点处停住(断点可以是条件表达式)
3. 当程序被停住时,可以检查此时程序中所发生的事
4. 可以改变程序,将一个 BUG 产生的影响修正从而测试其他 BUG
◼ 通常,在为调试而编译时,我们会()关掉编译器的优化选项(-O), 并打开调
试选项(**-g**)。另外,-Wall在尽量不影响程序行为的情况下选项打开所有warning,也可以发现许多问题,避免一些不必要的 BUG。
◼ gcc -g -Wall program.c -o program
◼ -g 选项的作用是在可执行文件中加入源代码的信息,比如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证 gdb 能找到源文件。
行的常用命令
◼ 启动和退出
gdb 可执行程序
quit
◼ 给程序设置参数/获取设置参数
set args 10 20
show args
◼ GDB 使用帮助
help
◼ 查看当前文件代码
list/l (从默认位置显示)
list/l 行号 (从指定的行显示)
list/l 函数名(从指定的函数显示)
◼ 查看非当前文件代码
list/l 文件名:行号
list/l 文件名:函数名
◼ 设置显示的行数
show list/listsize
set list/listsize 行数
断点常用命令
◼ 设置断点
b/break 行号
b/break 函数名
b/break 文件名:行号
b/break 文件名:函数
◼ 查看断点
i/info b/break
◼ 删除断点
d/del/delete 断点编号
◼ 设置断点无效
dis/disable 断点编号
◼ 设置断点生效
ena/enable 断点编号
◼** 设置条件断点(一般用在循环的位置)**
b/break 10 if i==5
运行常用命令
◼ 运行GDB程序
start(程序停在第一行)
run(遇到断点才停)
◼ 继续运行,到下一个断点停
c/continue
◼ 向下执行一行代码(不会进入函数体)
n/next
◼ 变量操作
p/print 变量名(打印变量值)
ptype 变量名(打印变量类型)
◼ 向下单步调试(遇到函数进入函数体)
s/step
finish(跳出函数体)
◼ 自动变量操作
display 变量名(自动打印指定变量的值)
i/info display
undisplay 编号
◼ 其它操作
set var 变量名=变量值 (循环中用的较多)
until (跳出循环)
1.6 文件IO
标准c库的IO函数

虚拟地址空间

文件描述符

Linux系统文件IO函数
fd为文件描述符,用来确定文件在内存中的位置
◼ 打开一个存在的文件
int open(const char *pathname, int flags);
参数:
- pathname:要打开的文件路径
- flags:对文件操作权限设置以及其他设置
O_RDONLY(只读), O_WRONLY(只写), O_RDWR(可读可写)
- 返回:返回一个新的文件描述符(用来定位文件位置)如果调用失败返回-1
◼ 创建一个新的文件
int open(const char *pathname, int flags, mode_t mode);
参数:
- pathname:要打开的文件路径
- flags:对文件操作权限设置以及其他设置
必选:O_RDONLY(只读), O_WRONLY(只写), O_RDWR(可读可写)
可选:O_CREAT (没有文件就创建一个新的文件)
必选|可选; 用“|”用“或”运算符 int类型 对应32位标志位,
- mode: 创建文件的读写权限设置,八进制(rwx) 0777, 最后权限为 mode & ~umask
umask用于系统自动矫正文件权限
- 返回:返回一个新的文件描述符(用来定位文件位置);如果调用失败返回-1,并且设置errno
例: int fd = open(“a.txt”, O_RDWR | O_CRERAT, 0777);
◼关闭文件
int close(int fd);
◼文件读取
ssize_t read(int fd, void *buf, size_t count);
参数:
- fd:所操作的文件描述符,open得到
- buf:缓冲数组,需读取数据存放的地方, 数组的地址
- count: 缓冲数组的大小
- 返回值:
- 读取成功:>0 返回读取的字节数, =0文件读取完毕
- 失败: -1;并设置errno
◼文件写入
ssize_t write(int fd, const void *buf, size_t count);
参数:
- fd:所操作的文件描述符,open得到
- buf:缓冲数组,需写入的数据, 数组的地址
- count: 实际写入的数据字节大小
- 返回值:
- 写入取成功:实际写入字节数
- 失败: -1;并设置errno
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include<stdio.h>
int main(){
//1.通过open打开english.txt文件
int src_fd = open("english.txt",O_RDONLY);
if(src_fd==-1){
perror("open");
return -1;
}
//2.通过open创建copy.txt文件
int copy_fd = open("copy.txt",O_RDWR|O_CREAT,0777);
if(copy_fd==-1){
perror("open");
return -1;
}
//3.通过read读取english.txt文件内容
int len =0;
char buf[1024] ={0}; //创建缓冲数组
while((len = read(src_fd,buf,sizeof(buf)))>0){
//进行写入copy.txt文件操作
write(copy_fd,buf,len);
}
//关闭文件
close(copy_fd);
close(src_fd);
return 0;
}
◼ 文件指针操作
off_t lseek(int fd, off_t offset, int whence);
参数:
- fd:所操作的文件描述符,open得到
- offset:偏移量
- whence:
SEEK_SET:设置文件指针的偏移量
SEEK_CUR:当前位置+第二个参数的offset的值
SEEK_END:文件大小+第二个参数的offset的值
返回值:返回文件指针位置
作用:
- 移动文件指针到文件头
lseek(fd, 0 ,SEEK_SET)
- 获取当前文件指针的位置
lseek(fd, 0, SEEK_CUR)
- 获取文件长度
lseek(fd,0 ,SEEL_END)
- 拓展文件长度,当前文件10b,变为110b ,用于提前开辟空间
lseek(fd,100,SEEK_END)
◼ 查看文件信息
int stat(const char *pathname, struct stat *statbuf);
参数:
- pathname:要打开的文件路径
- statbuf: 结构体变量,传出参数,用于保存获取到的文件信息
struct stat {
dev_t st_dev; // 文件的设备编号
ino_t st_ino; // 节点
mode_t st_mode; // 文件的类型和存取的权限
nlink_t st_nlink; // 连到该文件的硬连接数目
uid_t st_uid; // 用户ID
gid_t st_gid; // 组ID
dev_t st_rdev; // 设备文件的设备编号
off_t st_size; // 文件字节数(文件大小)
blksize_t st_blksize; // 块大小
blkcnt_t st_blocks; // 块数
time_t st_atime; // 最后一次访问时间
time_t st_mtime; // 最后一次修改时间
time_t st_ctime; // 最后一次改变时间(指属性)
};
返回值: 成功 返回 0
失败 返回-1
◼获取软连接的信息
int lstat(const char *pathname, struct stat *statbuf);
◼文件属性操作函数
- int access(const char *pathname, int mode);
检查是否对文件有 mode 的权限,是返回 0 ,否 -1
mode:读权限W_OK, 写权限R_OK, 执行权限X_OK, 文件是否存在F_OK
- int chmod(const char *filename, int mode);
修改文件权限为 mode
mode为需要修改的权限值,八进制数
- int chown(const char *path, uid_t owner, gid_t group);
改变文件所有者
- int truncate(const char *path, off_t length);
改变文件的大小为 length
◼目录操作函数
int mkdir(const char *pathname, mode_t mode);
// pathname: 创建目录的路径
// mode: 权限
int rmdir(const char *pathname); // 删除目录
int rename(const char *oldpath, const char *newpath); //重命名目录
int chdir(const char *path); // 修改进程的工作目录为 path
char *getcwd(char *buf, size_t size);
// 返回当前工作目录,参数可为 null ,buf 中也存储返回结果
◼ 目录遍历函数
- DIR *opendir(const char *name);
返回值:DIR* ,理解为目录流;错误返回NULL
- struct dirent *readdir(DIR *dirp);
返回值:读取到文件的信息
如果读取到目录末尾,或者失败了,返回NULL
- int closedir(DIR *dirp);
关闭目录
struct dirent
{
// 此目录进入点的inode
ino_t d_ino;
// 目录文件开头至此目录进入点的位移
off_t d_off;
// d_name 的长度, 不包含NULL字符
unsigned short int d_reclen;
// d_name 所指的文件类型
unsigned char d_type;
// 文件名
char d_name[256];
};
/*
d_type
DT_BLK - 块设备
DT_CHR - 字符设备
DT_DIR - 目录
DT_LNK - 软连接
DT_FIFO - 管道
DT_REG - 普通文件
DT_SOCK - 套接字
DT_UNKNOWN - 未知
*/
◼ 件描述符操作函数
- int dup(int oldfd);
复制文件描述符,复制得到的文件描述符可操作同一个文件
- int dup2(int oldfd, int newfd);
重定向文件描述符,关闭 newfd 指向的文件,然后 newfd 指向 oldfd 指向的文 件,返回 newfd
- int fcntl(int fd, int cmd, … /* arg */ );
fd : 文件描述符
cmd:表示对文件描述符进行如何操作
- F_DUPFD 复制文件描述符,等价于 dup
fcntl(fd, F_DUPFD);
- F_GETFL 获取文件描述符的 flag(就是 open 时指定的 flag)
int flag = fcntl(fd, F_GETFL);
- F_SETFL 设置文件描述符文件状态 flag
- 必选项:O_PDONLY O_WRONLY O_RDWR
- 可选项:O_APPEND追加数据
NONBLOCK 设置成非阻塞
int fd = open("a.txt", O_RDWR);
int flag = fcntl(fd, F_GETFL); //获取文件状态
flag |= O_APPEND; //按位或得到新的flag
fcntl(fd, G_SETFL, flag); // 设置成追加写入
模拟实现 ls -l 命令
#include<stdio.h>
#include<string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <dirent.h>
#include<pwd.h>
#include<grp.h>
#include<time.h>
#include<stdlib.h>
//显示文件信息
//-rw-r--r-- 1 ceyewan ceyewan 2478 6月 19 14:13 a.c
void ShowFileInfo(char *fileName){
//通过stat查看输入的文件信息
struct stat st;
int ret = stat(fileName,&st);
if(ret==-1){
perror("stat");
exit(0);
}
//用字符串保存文件的文件类型以及读写权限,stat中的st_mode变量
//获取文件类型 st_mode&S_IFMT 然后与宏进行匹配
char perms[11];
switch (st.st_mode&__S_IFMT)
{
case __S_IFLNK:
perms[0]='1';
break;
case __S_IFDIR:
perms[0]='d';
break;
case __S_IFREG:
perms[0]='_';
break;
case __S_IFBLK:
perms[0]='b';
break;
case __S_IFCHR:
perms[0]='c';
break;
case __S_IFSOCK:
perms[0]='s';
break;
case __S_IFIFO:
perms[0]='p';
break;
default:
perms[0]='?';
break;
}
//获取读写权限信息,与读写权限宏进行与操作
//文件所有者
perms[1]=(st.st_mode&S_IRUSR)?'r':'-';
perms[2]=(st.st_mode&S_IWUSR)?'w':'-';
perms[3]=(st.st_mode&S_IXUSR)?'x':'-';
//文件所在组
perms[4]=(st.st_mode&S_IRGRP)?'r':'-';
perms[5]=(st.st_mode&S_IWGRP)?'w':'-';
perms[6]=(st.st_mode&S_IXGRP)?'x':'-';
//其他人
perms[7]=(st.st_mode&S_IROTH)?'r':'-';
perms[8]=(st.st_mode&S_IWOTH)?'w':'-';
perms[9]=(st.st_mode&S_IXOTH)?'x':'-';
//硬件链接数
int linkNum = st.st_nlink;
//文件所有者
char *fileUser=getpwuid(st.st_uid)->pw_name;
//文件所在组
char *fileGruop = getgrgid(st.st_gid)->gr_name;
//文件大小
long int fileSize = st.st_size;
//获取修改时间,将秒数转化为时间
char *time = ctime(&st.st_mtime);
time[strlen(time)-1] = '\0';
printf("%s %d %s %s %ld %s %s\n",perms,linkNum,fileUser,
fileGruop,fileSize,time,fileName);
}
//循环遍历目录,打印文件信息以及文件数量
void GetDirInfo(char *DirPath){
//打开目录
DIR * dir = opendir(DirPath);
if(dir==NULL){
perror("opendir");
exit(0);
}
int fileNum=0;
struct dirent * ptr;
while((ptr = readdir(dir))!=NULL){
//过滤掉 ./ ../ 目录文件
char * dname = ptr->d_name;
if(strcmp(dname,".")==0||strcmp(dname,"..")==0)
continue;
char file_path [1024]={0};
sprintf(file_path,"%s/%s", DirPath, dname);
//判断是否是文件还是目录
if(ptr->d_type==DT_DIR){
//生成新的目录路径
// char newpath[1024]={0};
// sprintf(newpath,"%s/%s", DirPath, dname);
GetDirInfo(file_path);
}
//普通文件,输出信息,计入文件数
if(ptr->d_type==DT_REG){
ShowFileInfo(file_path);
fileNum++;
}
}
printf("%s文件数量为:%d\n",DirPath,fileNum);
//关闭目录
closedir(dir);
}
int main(int argc,char *argv[]){
//判断输入参数是否正确
if(argc<2){
printf("%s path\n","argv[0]");
return -1;
}
GetDirInfo(argv[1]);
return 0;
}
二、Linux多进程开发
参考链接:https://blog.csdn.net/qq_53111905/article/details/120402727
1、进程概述
1.1 程序与进程
程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程:
- 二进制格式标识:每个程序文件都包含用于描述可执行文件格式的元信息。内核利用此信息来解 释文件中的其他信息。(ELF可执行连接格式)
- 机器语言指令:对程序算法进行编码。
- 程序入口地址:标识程序开始执行时的起始指令位置。
- 数据:程序文件包含的变量初始值和程序使用的字面量值(比如字符串)。
- 符号表及重定位表:描述程序中函数和变量的位置及名称。这些表格有多重用途,其中包括调试 和运行时的符号解析(动态链接)。
- 共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以 及加载共享库的动态连接器的路径名。
- 其他信息:程序文件还包含许多其他信息,用以描述如何创建进程。
进程是正在运行的程序的实例。是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
- 可以用一个程序来创建多个进程,进程是由内核定义的抽象实体,并为该实体分配用 以执行程序的各项系统资源。从内核的角度看,进程由用户内存空间和一系列内核数据结构**组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。**记录在内核数据结构中的信息包括许多与进程相关的标识号(IDs)、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
1.2 单道、多道程序设计
- 单道程序,即在计算机内存中只允许一个的程序运行。
- 多道程序设计技术是在计算机内存中同时存放几道相互独立的程序,使它们在管理程控制下,相互穿插运行,两个或两个以上程序在计算机系统中同处于开始到结束之间的状态, 这些程序共享计算机系统资源。引入多道程序设计技术的根本目的是为了提高 CPU 的利用率。
- 对于一个单 CPU 系统来说,程序同时处于运行状态只是一种宏观上的概念,他们虽然都已经开始运行,但就微观而言,任意时刻,CPU 上运行的程序只有一个。
- 在多道程序设计模型中,多个进程轮流使用 CPU。而当下常见 CPU 为纳秒级,1秒可以执行大约 10 亿条指令。由于人眼的反应速度是毫秒级,所以看似同时在运行
1.3 时间片
时间片(timeslice)又称为“量子(quantum)”或“处理器片(processor slice)” 是操作系统分配给每个正在运行的进程微观上的一段 CPU 时间。事实上,虽然一台计 算机通常可能有多个 CPU,但是同一个 CPU 永远不可能真正地同时运行多个任务。在 只考虑一个 CPU 的情况下,这些进程“看起来像”同时运行的,实则是轮番穿插地运行, 由于时间片通常很短(在 Linux 上为 5ms-800ms),用户不会感觉到。
时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等 的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的状态时,内核会重新为每个进程计算并分配时间片,如此往复。
1.4并行和并发
- 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
- 并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的 轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的, 只是把时间分成若干段,使多个进程快速交替的执行。

1.5进程控制块(PCB)
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。内核为每个进程分配一个 PCB(Processing Control Block)进程控制块,维护进程相关的信息, Linux 内核的进程控制块是 task_struct 结构体。
在 /usr/src/linux-headers-xxx/include/linux/sched.h 文件中可以查 看 struct task_struct 结构体定义。其内部成员有很多,我们只需要掌握以下 部分即可:
- 进程id:系统中每个进程有唯一的 id,用 pid_t 类型表示,其实就是一个非负整数
- 进程的状态:有就绪、运行、挂起、停止等状态
- 进程切换时需要保存和恢复的一些CPU寄存器
- 描述虚拟地址空间的信息
- 描述控制终端的信息
- 当前工作目录(Current Working Directory)
- umask 掩码
- 文件描述符表,包含很多指向 file 结构体的指针
- 和信号相关的信息
- 用户 id 和组 id
- 会话(Session)和进程组
- 进程可以使用的资源上限(Resource Limit)
ulimit -a
2、进程的状态转换
2.1 进程的状态
进程状态反映进程执行过程的变化。这些状态随着进程的执行和外界条件的变化而转换。在三态模型中,进程状态分为三个基本状态,即就绪态,运行态,阻塞态。
- 运行态:进程占有处理器正在运行
- 就绪态:进程具备运行条件,等待系统分配处理器以便运行。当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列
- 阻塞态:又称为等待(wait)态或睡眠(sleep)态,指进程不具备运行条件,正在等待某个事件的完成
在五态模型中,进程分为新建态、就绪态,运行态,阻塞态,终止态。
2.2进程相关命令
- **查看进程 **ps aux / ajx
a:显示终端上的所有进程,包括其他用户的进程
u:显示进程的详细信息
x:显示没有控制终端的进程
j:列出与作业控制相关的信息
- STAT参数意义:
D 不可中断 Uninterruptible(usually IO)
R 正在运行,或在队列中的进程
S(大写) 处于休眠状态
T 停止或被追踪
Z 僵尸进程
W 进入内存交换(从内核2.6开始无效)
X 死掉的进程
< 高优先级
N 低优先级
s 包含子进程
+位于前台的进程组
- 实时显示进程动态
top 可以在使用 top 命令时加上 -d 来指定显示信息更新的时间间隔,在 top 命令 执行后,可以按以下按键对显示的结果进行排序:
M 根据内存使用量排序
P 根据 CPU 占有率排序
T 根据进程运行时间长短排序
U 根据用户名来筛选进程
K 输入指定的 PID 杀死进程
- 杀死进程
kill [-signal] pid
kill –l 列出所有信号
kill –SIGKILL 进程ID -SIGKILL 9号信号 强制杀死进程
kill -9 进程ID -9 九号信号 强制杀死进程
killall name 根据进程名杀死进程
./a.out && 后台允许 a.out
2.3 进程号和相关函数
每个进程都由进程号来标识,其类型为 pid_t(整型),进程号的范围:0~32767。 进程号总是唯一的,但可以重用。当一个进程终止后,其进程号就可以再次使用。
任何进程(除 init 进程)都是由另一个进程创建,该进程称为被创建进程的父进程, 对应的进程号称为父进程号(PPID)。
进程组是一个或多个进程的集合。他们之间相互关联,进程组可以接收同一终端的各种信号,关联的进程有一个进程组号(PGID)。默认情况下,当前的进程号会当做当前的进程组号。
进程号和进程组相关函数:
- pid_t getpid(void); //获取当前进程的ID
- pid_t getppid(void); //获取当前进程的父ID
- pid_t getpgid(pid_t pid); //获取进程组ID
3、进程创建
3.1 子进程创建
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
#include <unistd.h>
#include <sys/types.h>
pid_t fork(void);返回值:
成功:
- 子进程中返回 0
- 父进程中返回子进程 ID
失败:返回 -1 失败的两个主要原因:
- 当前系统的进程数已经达到了系统规定的上限,这时 errno 的值被设置 为 EAGAIN
- 系统内存不足,这时 errno 的值被设置为 ENOMEM
#include<iostream>
#include <unistd.h>
#include <sys/types.h>
int main(){
//创建子进程
pid_t pid = fork();
if(pid>0){
//如果返回的值大于0,则为父进程
printf("我是父进程,pid:%d\n",getpid());
}else if(pid==0){
//返回值为0,则为子进程
printf("我是子进程,pid:%d,ppid:%d\n",getpid(),getppid());
}
//两个进程将交替执行以下程序
for(int i =0;i<3;i++){
printf("i=%d,pid:%d\n",i,getpid());
sleep(1);
}
return 0;
}
3.2 父子进程的虚拟地址空间
实际上,Linux的 fork()使用是通过写时拷贝(copy- on-write)实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。
内核此时并不复制整个进程的地址空间,而是一开始没有写操作时让父子进程共享同一个地址空间。
只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享
3.3 父子进程之间的区别
区别:
1.fork()函数的返回值不同
父进程中:>0
返回的子进程的ID子进程中:=0
2.pcb中的一些数据
当前的进程的pid ppid
当前的进程的父进程的pid ppid
信号集
共同点:
- 某些状态下:子进程刚被创建出来,还没有执行任何的写数据的操作,共享以下:
-用户区的数据
-文件描述符表
父子进程对变量是不是共享的?
-刚开始的时候,是一样的,共享的。如果修改了数据,不共享了。
-读时共享(子进程被创建,两个进程没有做任何的写的操作),写时拷贝。
3.4 GDB多进程调试
show follow-fork-mode
使用 GDB 调试的时候,GDB 默认只能跟踪一个进程,可以在 fork 函数调用之前,通过指令设置 GDB 调试工具跟踪父进程或者是跟踪子进程,默认跟踪父进程。
设置调试父进程或者子进程:set follow-fork-mode [parent(默认)| child]
设置调试模式:set detach-on-fork [on | off] 默认为** on**,表示调试当前进程的时候,其它的进程继续运行,如果为 off,调试当前进程的时候,其它进程被 GDB 挂起。
查看调试的进程:info inferiors
切换当前调试的进程:inferior id
使进程脱离 GDB 调试:detach inferiors id
4、exec函数族
exec 函数族的作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是在调用进程内部执行一个可执行文件。
替换掉了用户区的内容,内核区的内容不会改变
一般都是 fork + exec
exec 函数族的函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程 ID 等一些表面上的信息仍保持原样(内核信息不变)。只有调用失败了,它们才会返回 -1,从原程序的调用点接着往下执行。
int execl(const char *path, const char arg, …/ (char *) NULL */);
-
第一个参数path:可执行文件的路径
-
第二个参数arg:是可执行文件所需要的参数列表,第一个为执行程序名称,
接着就是所需参数列表,以NULL结束(哨兵)<br />int **execlp**(const char *file, const char *arg, ... /* (char *) NULL */); -
第一个参数file:文件名,不用写路径, 回到环境变量中查找可执行文件,找不到就执行不成功
-
第二个参数同上
int execle(const char *path, const char arg, …/, (char *) NULL, char *const envp[] */);
int execv(const char *path, char *const argv[]); //用的是字符串数组
- char *argv[ ]={“ps”,“aux”,NULL};
- execv(“/bin/ps”,argv);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]); // envp自己指定环境变量数组
int execve(const char *filename, char *const argv[], char *const envp[]);
- l(list) 参数地址列表,以空指针结尾
- v(vector) 存有各参数地址的指针数组的地址
- p(path) 按 PATH 环境变量指定的目录搜索可执行文件
- e(environment) 存有环境变量字符串地址的指针数组的地址
自己指定的环境变量 一连串的目录 按先后顺序区查找
5、进程控制
5.1 进程退出

#include <stdlib.h>
void exit(int status);
#include <unistd.h>
void _exit(int status);
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello\n"); // \n会刷新缓冲区
prinft("world"); //没有刷新缓冲区
// exit(0); //标准C库的 有缓冲区(退出时自动刷新),会输出 world
// _exit(0); //系统调用的 没有缓冲区,不会输出 world
return 0;
}
5.2 孤儿进程
父进程运行结束,但子进程还在运行(未运行结束),这样的子进程就称为孤儿进程 (Orphan Process)。
每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为** init (pid 为 1) **,而 init 进程会循环地 wait() 它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init 进程就会代表党和政府出面处理它的一切善后工作。
因此孤儿进程并不会有什么危害。
5.3僵尸进程
子进程结束后,用户区的数据会被释放掉,而内核区的数据主要是控制块PCB的信息 (包括进程号、退出状态、运行时间等)需要父进程进行释放,否则会占用以上信息,形成僵尸进程
每个进程结束之后, 都会释放自己地址空间中的用户区数据,内核区的 PCB 没有办法 自己释放掉,需要父进程去释放。
进程终止时,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸 (Zombie)进程。
僵尸进程不能被 kill -9 杀死,这样就会导致一个问题,如果父进程不调用 wait() 或 waitpid() 的话,那么保留的那段信息就不会释放,其进程号就会一直被占用, 但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免。
5.4 进程回收
在每个进程退出的时候,内核释放该进程所有的资源、包括打开的文件、占用的内 存等。但是仍然为其保留一定的信息,这些信息主要主要指进程控制块PCB的信息 (包括进程号、退出状态、运行时间等)。
父进程可以通过调用wait或waitpid得到它的退出状态同时彻底清除掉这个进程。
wait() 和 waitpid() 函数的功能一样,区别在于,wait() 函数会阻塞, waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
注意:一次wait或waitpid调用只能清理一个子进程,清理多个子进程应使用循环。
5.4.1 wait函数
调用wait函数的进程会被挂起(阻塞),直到它的一个子进程退出或者收到一个不能被忽略的信号时才被唤醒(相当于继续往下执行)
/*
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *wstatus);
功能:等待任意一个子进程结束,如果任意一个子进程结束了,此函数会回收子进程的资源。
参数:int *wstatus
进程退出时的状态信息,传入的是一个int类型的地址,传出参数。
返回值:
- 成功:返回被回收的子进程的id
- 失败:-1 (所有的子进程都结束,调用函数失败)
调用wait函数的进程会被挂起(阻塞),直到它的一个子进程退出或者收到一个不能被忽略的信号时才被唤醒(相当于继续往下执行)
如果没有子进程了,函数立刻返回,返回-1;如果子进程都已经结束了,也会立即返回,返回-1.
*/
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
// 有一个父进程,创建5个子进程(兄弟)
pid_t pid;
// 创建5个子进程
for(int i = 0; i < 5; i++) {
pid = fork();
if(pid == 0) {
break;
}
}
if(pid > 0) {
// 父进程
while(1) {
printf("parent, pid = %d\n", getpid());
// int ret = wait(NULL);
int st;
int ret = wait(&st);
if(ret == -1) {
break;
}
if(WIFEXITED(st)) {
// 是不是正常退出
printf("退出的状态码:%d\n", WEXITSTATUS(st));
}
if(WIFSIGNALED(st)) {
// 是不是异常终止
printf("被哪个信号干掉了:%d\n", WTERMSIG(st));
}
printf("child die, pid = %d\n", ret);
sleep(1);
}
} else if (pid == 0){
// 子进程
while(1) {
printf("child, pid = %d\n",getpid());
sleep(1);
}
exit(0);
}
return 0; //相当于exit(0)
}
#### 5.4.2 waitpid函数 ```cpp /* #include
int main() {
// 有一个父进程,创建5个子进程(兄弟)
pid_t pid;
// 创建5个子进程
for(int i = 0; i < 5; i++) {
pid = fork();
if(pid == 0) {
break;
}
}
if(pid > 0) {
// 父进程
while(1) {
printf("parent, pid = %d\n", getpid());
sleep(1);
int st;
// int ret = waitpid(-1, &st, 0);
int ret = waitpid(-1, &st, WNOHANG);
if(ret == -1) {
break;
} else if(ret == 0) {
// 说明还有子进程存在
continue;
} else if(ret > 0) {
if(WIFEXITED(st)) {
// 是不是正常退出
printf("退出的状态码:%d\n", WEXITSTATUS(st));
}
if(WIFSIGNALED(st)) {
// 是不是异常终止
printf("被哪个信号干掉了:%d\n", WTERMSIG(st));
}
printf("child die, pid = %d\n", ret);
}
}
} else if (pid == 0){
// 子进程
while(1) {
printf("child, pid = %d\n",getpid());
sleep(1);
}
exit(0);
}
return 0;
}
<a name="fwkQc"></a>
#### 5.4.3 退出信息相关宏函数
WIFEXITED(status) 非0,进程**正常退出**<br />WEXITSTATUS(status) 如果上宏为真,获取进程退出的状态(exit的参数)
WIFSIGNALED(status) 非0,进程**异常终止**<br />WTERMSIG(status) 如果上宏为真,获取使进程终止的信号编号
WIFSTOPPED(status) 非0,进程处于**暂停状态**<br />WSTOPSIG(status) 如果上宏为真,获取使进程暂停的信号的编号
WIFCONTINUED(status) 非0,进程暂停后已经继续运行
<a name="hcoLe"></a>
## 6、进程间通信
<a name="ywDVb"></a>
### 6.1 进程间通讯概念
进程是一个独立的资源分配单元,不同进程(这里所说的进程通常指的是用户进程)之间 的资源是独立的,没有关联,不能在一个进程中直接访问另一个进程的资源。<br />但是,**进程不是孤立的**,不同的进程**需要进行信息的交互和状态的传递**等,因此需要进程间通信( IPC:Inter Processes Communication )。<br />进程间通信的**目的**:
- **数据传输**:一个进程需要将它的数据发送给另一个进程。
- **通知事件**:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种 事件(如进程终止时要通知父进程)。
- **资源共享**:多个进程之间共享同样的资源。为了做到这一点,需要内核提供互斥和同步机制。
- **进程控制**:有些进程希望完全控制另一个进程的执行(如 Debug 进程),此时控制 进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
<a name="ojJfk"></a>
### 6.2 进程间的通信方式
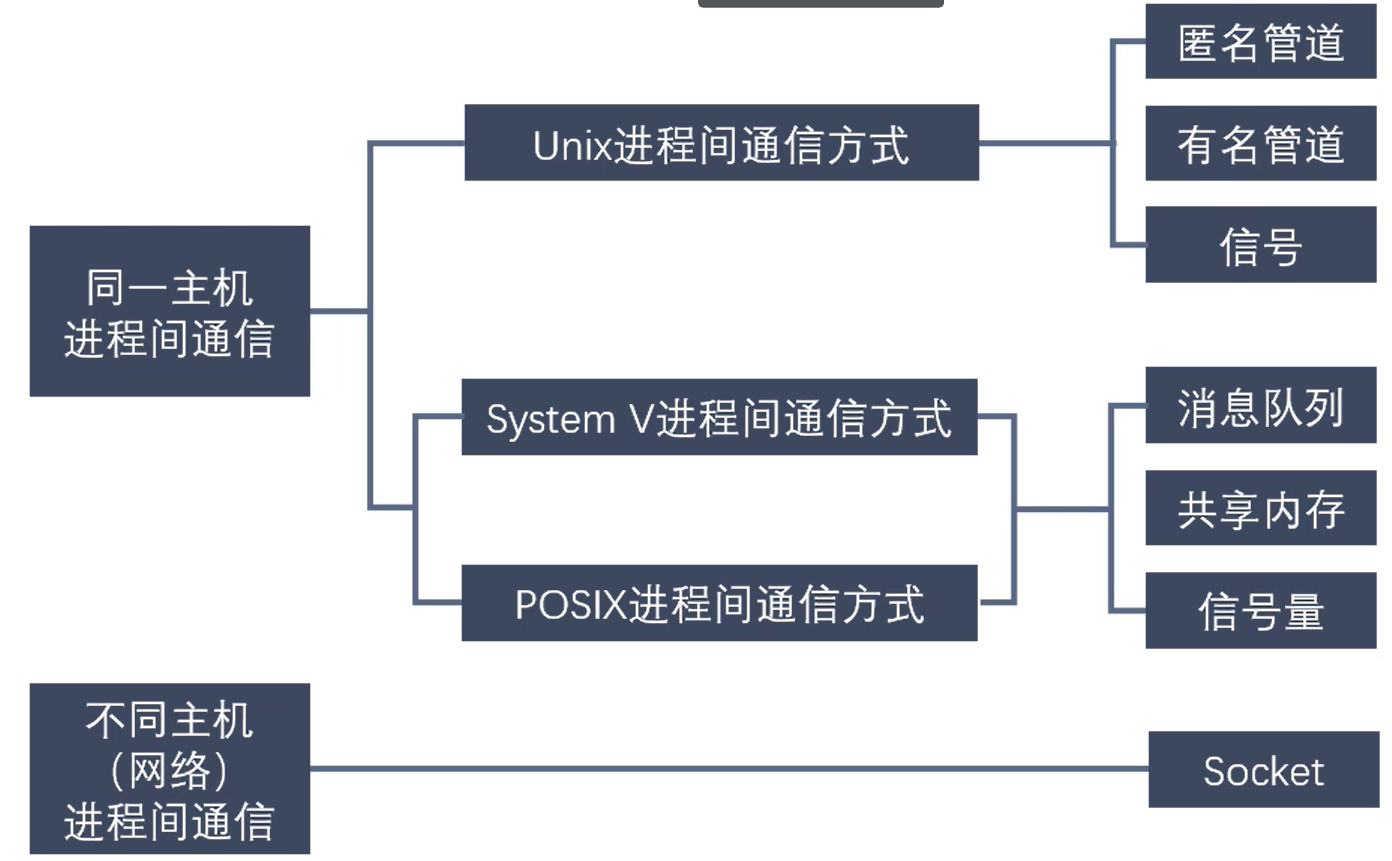
<a name="RunID"></a>
### 6.2 匿名管道
- 管道也叫无名(匿名)管道,它是是 UNIX 系统 IPC(进程间通信)的最古老形式, 所有的 UNIX 系统都支持这种通信机制。
**统计一个目录中文件的数目命令:ls | wc –l,为了执行该命令,shell 创建了两 个进程来分别执行 ls 和 wc。**<br />
<a name="yPeGJ"></a>
#### 6.2.1 管道的特点
管道其实是一个在**内核内存中维护的缓冲器**,这个缓冲器的存储能力是有限的,不同的操作系统大小不一定相同。
- 管道拥有**文件的特质**:读操作、写操作,**匿名管道没有文件实体**,**有名管道有文件实体**, 但不存储数据。但可以**按照操作文件的方式**对管道进行操作。
- **一个管道是一个字节流,使用管道时不存在消息或者消息边界的概念**,从管道读取数据的进程可以读取任意大小的数据块,而不管写入进程写入管道的数据块的大小是多少。
- 通过管道传递的**数据是顺序的**,从管道中读取出来的字节的顺序和它们被写入管道的顺序是完全一样的。
- 在管道中的数据的**传递方向是单向的**,一端用于写入,一端用于读取,管道是半双工的。
- 从管道读数据是一次性操作,**数据一旦被读走,它就从管道中被抛弃**,**释放空间**以便写更多的数据,在管道中无法使用 lseek() 来随机的访问数据。
- **匿名管道只能在具有公共祖先的进**程(父进程与子进程,或者两个兄弟进程,具有**亲缘关系**)之间使用。
<a name="n2vzW"></a>
#### 6.2.2 为什么可以使用管道进行进程间通信
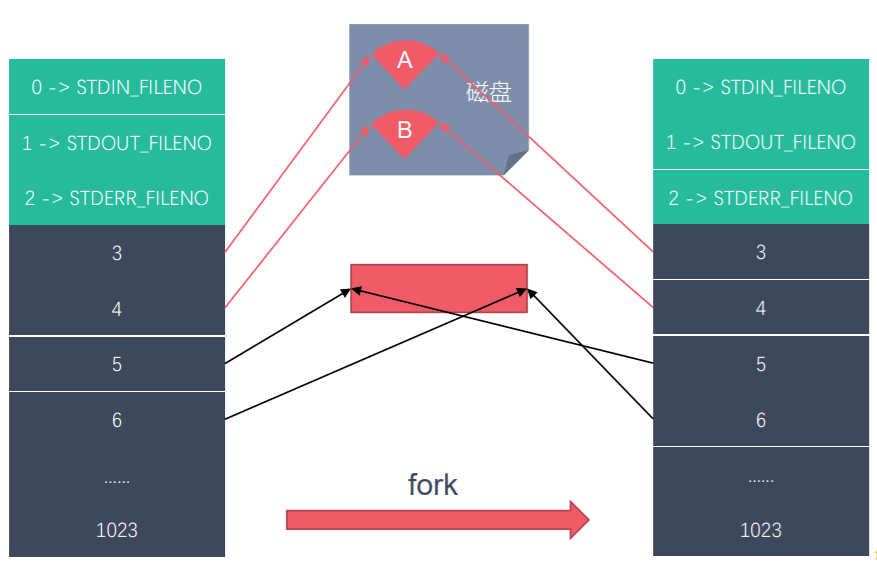<br />管道的数据结构<br />类似循环队列<br />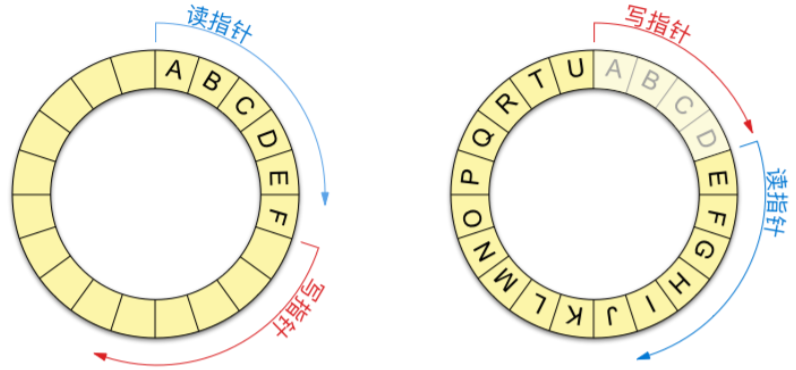
<a name="uFI6Q"></a>
### 6.3匿名管道的使用
- **创建**匿名管道<br />#include <unistd.h><br />int pipe(int pipefd[2]);
- **查看**管道**缓冲大小**命令<br />ulimit –a
- **查看**管道**缓冲大小函数**<br />#include <unistd.h><br />long fpathconf(int fd, int name);
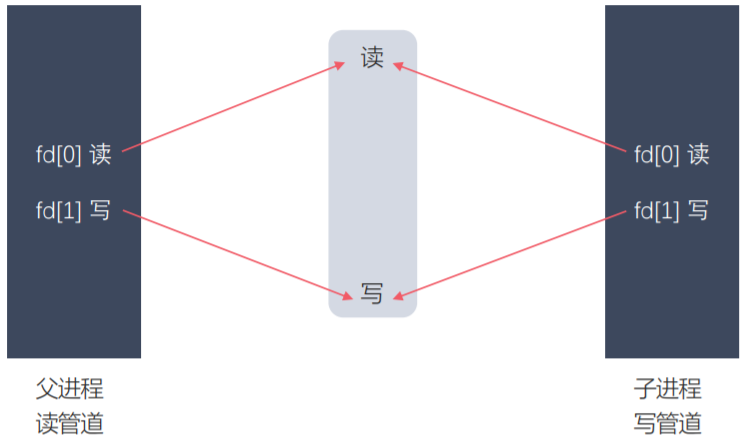<br />#include <unistd.h><br /> int** pipe**(int pipefd[2]);<br /> 功能:创建一个匿名管道,用来进程间通信。<br /> 参数:int pipefd[2] 这个数组是一个传出参数。<br /> pipefd[0] 对应的是管道的**读端**<br /> pipefd[1] 对应的是管道的**写端**<br /> 返回值:<br /> 成功 0<br /> 失败 -1<br /> 管道默认是**阻塞**的:如果管道中**没有数据**,**read阻塞**,如果**管道满了**,**write阻塞**<br /> 注意:匿名管道**只能用于**具有**关系**的**进程之间**的通信(父子进程,兄弟进程)
```cpp
#include <unistd.h>
#include <sys/types.h>
#include<stdlib.h>
#include<string.h>
#include<stdio.h>
int main(){
//父进程创建管道
int pipefd[2];
int ret = pipe(pipefd);
if(ret==-1){
perror("pipe");
exit(0);
}
//创建子进程
pid_t pid =fork();
if(pid>0){
//父进程
printf("i am parent process, pid:%d\n",getpid());
char buff[1024]={0};
while (1)
{ //父进程从管道读数据
int len = read(pipefd[0],buff,sizeof(buff));
printf("parent, recv,%s,pid:%d\n",buff,getpid());
char* str = "hello, i am parent";
write(pipefd[1],str,strlen(str));
sleep(2);
}
}else if(pid==0){
//子进程
printf("i am child process, pid:%d\n",getpid());
char buff[1024]={0};
while (1)
{
char* str = "hello, i am child";
write(pipefd[1],str,strlen(str));
sleep(2);
int len = read(pipefd[0],buff,sizeof(buff));
printf("child, recv,%s, pid:%d\n",buff,getpid());
}
}
return 0;
}
避免双向读写,容易出错
读的就关闭写端,写就关闭读端
close();
/*
实现 ps aux | grep xxx 父子进程间通信
子进程: ps aux, 子进程结束后,将数据发送给父进程
父进程:获取到数据,过滤
pipe()
execlp()
子进程将标准输出 stdout_fileno 重定向到管道的写端。 dup2
*/
#include <unistd.h>
#include <sys/types.h>
#include<stdlib.h>
#include<string.h>
#include<stdio.h>
#include<wait.h>
int main(){
//创建管道
int fd[2] = {0};
int ret = pipe(fd);
if(ret==-1){
perror("pipe");
exit(0);
}
//创建进程
pid_t pid = fork();
if(pid>0){
//父进程
//从管道中读取子进程写入的ps aux指令得到的信息
close(fd[1]); //关闭写
char buf[1024] ={0};
int len = -1;
while (len = read(fd[0],buf,sizeof(buf)-1)>0)
{
printf("%s",buf);
memset(buf,0,sizeof(buf));
}
wait(NULL); //回收子进程
}else if(pid==0){
//子进程
close(fd[0]); //关闭读
dup2(fd[1],STDOUT_FILENO);
//execlp函数将ps shell命令给子进程执行
execlp("ps","ps","aux",NULL);
perror("execlp");
exit(0);
}else if(pid==-1){
perror("fork");
exit(0);
}
return 0;
}
匿名管道读写特点:
几种特殊情况(假设都是阻塞的I/O操作)
读管道:
** 管道中有数据,read返回实际读到的字节数。
管道中无数据:
写端被全部关闭,read返回0(相当于读到文件的末尾)
写端没有完全关闭,read阻塞等待,直到管道中有数据可以读**
写管道:
** 管道读端全部被关闭,进程异常终止(进程收到SIGPIPE信号)
管道读端没有全部关闭:
管道已满,write阻塞**
** 管道没有满,write将数据写入,并返回实际写入的字节数**
6.4 有名管道
6.4.1 有名管道概念
- **匿名管道,**由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道(FIFO),也叫命名管道、FIFO文件。
- 有名管道(FIFO)不同于匿名管道之处在于它提供了一个路径名与之关联,以 FIFO 的文件形式存在于文件系统中,并且其打开方式与打开一个普通文件是一样的,这样即使与 FIFO 的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此 通过 FIFO 相互通信,因此,通过 FIFO 不相关的进程也能交换数据。
- 一旦打开了 FIFO,就能在它上面使用与操作匿名管道和其他文件的系统调用一样的 I/O系统调用了(如read()、write()和close())。与管道一样,FIFO 也有一 个写入端和读取端,并且从管道中读取数据的顺序与写入的顺序是一样的。FIFO 的 名称也由此而来:先入先出。
- 有名管道(FIFO)和匿名管道(pipe)有一些特点是相同的,不一样的地方在于:
- FIFO 在文件系统中作为一个特殊文件存在,但 FIFO 中的内容却存放在内存中。
- 当使用 FIFO 的进程退出后,FIFO 文件将继续保存在文件系统中以便以后使用。
- FIFO 有名字,不相关的进程可以通过打开有名管道进行通信。
6.4.2 有名管道的使用
- 通过命令创建有名管道:
mkfifo 名字
- 通过函数创建有名管道
#include<sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
参数:
- pathname: 管道名称的路径
- mode: 文件的权限 和 open 的 mode 是一样的
是一个八进制的数
返回值:成功返回0,失败返回-1,并设置错误号
- 一旦使用 mkfifo 创建了一个 FIFO,就可以使用 open 打开它,常见的文件 I/O 函数都可用于 fifo。如:close、read、write、unlink 等。
- IFO 严格遵循先进先出(First in First out),对管道及 FIFO 的读总是 从开始处返回数据,对它们的写则把数据添加到末尾。它们不支持诸如 lseek() 等文件定位操作。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include <unistd.h>
#include<string.h>
int main(){
//判断文件存不存在
int ret = access("test",F_OK);
if(ret==-1){
printf("管道不存在 创建管道test\n");
ret = mkfifo("test",0664);
if(ret == -1) {
perror("mkfifo");
exit(0);
}
}
//给管道写入数据
int fd = open("test",O_WRONLY);
if(fd==-1){
perror("open");
exit(0);
}
for(int i =0 ;i<100;i++){
char buf[1024]={0};
sprintf(buf,"hello, %d",i);
int len = write(fd,buf,strlen(buf));
if(len==-1){
perror("write");
exit(0);
}
printf("write data %s, len: %d\n",buf,len);
sleep(1);
}
close(fd);
return 0;
}
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include <unistd.h>
int main(){
//读取管道数据
int fd = open("test",O_RDONLY);
if(fd==-1){
perror("open");
exit(0);
}
while(1) {
char buf[1024] = {0};
int len = read(fd, buf, sizeof(buf));
if(len == 0) {
printf("写端断开连接了...\n");
break;
}
printf("recv buf : %s\n", buf);
}
close(fd);
return 0;
}
6.4.3 有名管道的读写特点
有名管道的注意事项:
1.一个为只读而打开一个管道的进程会阻塞,直到另外一个进程为只写打开管道
2.一个为只写而打开一个管道的进程会阻塞,直到另外一个进程为只读打开管道
读管道:
管道中有数据,read返回实际读到的字节数
管道中无数据:
管道写端被全部关闭,read返回0,(相当于读到文件末尾)
写端没有全部被关闭,read阻塞等待
写管道:
管道读端被全部关闭,进行异常终止(收到一个SIGPIPE信号)
管道读端没有全部关闭:
管道已经满了,write会阻塞
管道没有满,write将数据写入,并返回实际写入的字节数。
6.4.4 实现简单聊天功能。通过两个管道分别进行循环读写操作
运用父子进程同时进行读写(读写会阻塞,A有写B才有读,B有写A才有读)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include <unistd.h>
#include<wait.h>
#include<string.h>
#include<iostream>
using namespace std;
int main(){
printf("========与zz正在激情连线========\n");
//判断管道是否存在,不存在就创建
int ret = access("fifo1",F_OK);
if(ret==-1){
printf("管道fifo1不存在,创建fifo1\n");
ret = mkfifo("fifo1",0664);
if(ret==-1){
perror("mififo");
exit(0);
}
}
ret = access("fifo2",F_OK);
if(ret==-1){
printf("管道fifo2不存在,创建fifo2\n");
ret = mkfifo("fifo2",0664);
if(ret==-1){
perror("mififo");
exit(0);
}
}
//fifo1 只写, fifo2只读
int fd1 = open("fifo1",O_WRONLY);
if(fd1==-1){
perror("open");
exit(0);
}
int fd2 = open("fifo2",O_RDONLY);
if(fd2==-1){
perror("open");
exit(0);
}
//创建父子进程分别进行循环读写操作,父进程写,子进程读
pid_t pid = fork();
if(pid>0){
//父进程
char buf[1024] = {0};
while (1)
{ //键盘录入
memset(buf,0,sizeof(buf));
string str;
cin>>str;
strcpy(buf, str.c_str());
int len = write(fd1,buf,sizeof(buf));
if(len==-1){
break;
}
}
printf("CLOSE FD1\n");
close(fd1);
wait(NULL);
}else if(pid==0){
//子进程
//循环读
char buf[1024]={0};
while (1)
{
buf[1024] = {0};
int len = read(fd2,buf,sizeof(buf));
if(len==0){
printf("zz狠心地结束了会话...\n");
printf("请输入'q'并按回车退出\n");
printf("CLOSE FD2\n");
close(fd2);
exit(0);
}
printf("zz说:%s\n",buf);
}
}else if(pid ==-1){ //fork失败
perror("fork");
exit(0);
}
return 0;
}
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdio.h>
#include<stdlib.h>
#include <unistd.h>
#include<wait.h>
#include<string.h>
#include<iostream>
using namespace std;
int main(){
//判断管道是否存在,不存在就创建
printf("========与bsf正在激情连线========\n");
int ret = access("fifo1",F_OK);
if(ret==-1){
printf("管道fifo1不存在,创建fifo1\n");
ret = mkfifo("fifo1",0664);
if(ret==-1){
perror("mififo");
exit(0);
}
}
ret = access("fifo2",F_OK);
if(ret==-1){
printf("管道fifo2不存在,创建fifo2\n");
ret = mkfifo("fifo2",0664);
if(ret==-1){
perror("mififo");
exit(0);
}
}
//fifo1 只读, fifo2只写
int fd1 = open("fifo1",O_RDONLY);
if(fd1==-1){
perror("open");
exit(0);
}
int fd2 = open("fifo2",O_WRONLY);
if(fd2==-1){
perror("open");
exit(0);
}
//创建父子进程分别进行循环读写操作,父进程写,子进程读
pid_t pid = fork();
if(pid>0){
//父进程
char buf[1024] = {0};
while (1)
{ //键盘录入
memset(buf,0,sizeof(buf));
string str;
cin>>str;
strcpy(buf, str.c_str());
int len = write(fd2,buf,sizeof(buf));
if(len==-1){
break;
}
}
printf("CLOSE FD2\n");
close(fd2);
wait(NULL);
}else if(pid==0){
//子进程
//循环读
char buf[1024]={0};
while (1)
{
memset(buf,0,sizeof(buf));
int len = read(fd1,buf,sizeof(buf));
if(len==0){
printf("bsf狠心地结束了会话...\n");
printf("请输入'q'并按回车退出\n");
printf("CLOSE FD1\n");
close(fd1);
exit(0);
}
printf("bsf说:%s\n",buf);
}
}else if(pid ==-1){
perror("fork");
exit(0);
}
return 0;
}
7、内存映射
- 内存映射(Memory-mapped I/o)是将磁盘文件的数据映射到内存,用户通过修改内存就能修改磁盘文件。(系统自动同步)

7.1 内存映射的系统调用
#include <sys / mman.h>
void *mmap(void *addr,size_t length,int prot,int flags,int fd, off_t offset) ;
- 功能:将一个文件或者设备的数据映射到内存中
- 参数:
- void *addr: NULL, 由内核指定,最后会返回开辟的内存首地址
- length : 要映射的数据的长度,这个值不能为0。建议使用文件的长度。
获取文件的长度:stat lseek
- prot : 对申请的内存映射区的操作权限
-PROT_EXEC :可执行的权限
-PROT_READ :读权限
-PROT_WRITE :写权限
-PROT_NONE :没有权限
要操作映射内存,必须要有读的权限。
PROT_READ、PROT_READ|PROT_WRITE (按位或)
- flags :
- MAP_SHARED : 映射区的数据会自动和磁盘文件进行同步,进程间通信,必须要设置这个选项
- MAP_PRIVATE :不同步,内存映射区的数据改变了,对原来的文件不会修改,会重新创建一个新的文件。(copy on write)
- fd: 需要映射的那个文件的文件描述符
- 通过open得到,open的是一个磁盘文件
- 注意:文件的大小不能为0,open指定的权限不能和prot参数有冲突。
prot: PROT_READ open:只读/读写
prot: PROT_READ | PROT_WRITE open:读写
- offset:偏移量,一般不用。必须指定的是4k的整数倍,0表示不偏移。
- 返回值:返回创建的内存的首地址
失败返回MAP_FAILED,(void *) -1
int munmap(void *addr, size_t length);<br /> - 功能:释放内存映射<br /> - 参数:<br /> - addr : 要释放的内存的首地址<br /> - length : 要释放的内存的大小,**要和mmap函数**中的length参数**的值一样**。
7.2 使用内存映射实现进程间通信:
1.**有关系的进程(父子进程)**<br /> - 还没有子进程的时候<br /> - 通过唯一的父进程,先创建内存映射区<br /> - 有了内存映射区以后,创建子进程<br /> - 父子进程**共享**创建的内存映射区<br /> <br /> 2.**没有关系的进程间通信**<br /> - 准备一个大小不是0的磁盘文件<br /> - 进程1 通过磁盘文件创建内存映射区<br /> - 得到一个操作这块内存的指针<br /> - 进程2 通过磁盘文件创建内存映射区<br /> - 得到一个操作这块内存的指针<br /> - 使用内存映射区通信<br /> 注意:内存映射区通信,是**非阻塞**。
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <wait.h>
int main() {
// 1.打开一个文件
int fd = open("test.txt", O_RDWR);
int size = lseek(fd, 0, SEEK_END); // 获取文件的大小
// 2.创建内存映射区
void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if(ptr == MAP_FAILED) {
perror("mmap");
exit(0);
}
// 3.创建子进程
pid_t pid = fork();
if(pid > 0) {
wait(NULL);
// 父进程
char buf[64];
strcpy(buf, (char *)ptr);
printf("read data : %s\n", buf);
}else if(pid == 0){
// 子进程
strcpy((char *)ptr, "nihao a, son!!!");
}
// 关闭内存映射区
munmap(ptr, size);
return 0;
}
- 1.如果对mmap的返回值(ptr)做++操作(ptr++), munmap是否能够成功?
void * ptr = mmap(…);
ptr++;** 可以对其进行++操作**
munmap(ptr, len); // 错误,保存地址,否则释放时报错(没释放完)
- 2.如果open时O_RDONLY, mmap时prot参数指定PROT_READ | PROT_WRITE会怎样?
错误,返回MAP_FAILED
open()函数中的权限建议和prot参数的权限保持一致。
- 3.如果文件偏移量为1000会怎样?
偏移量必须是4K的整数倍,返回MAP_FAILED
- 4.mmap什么情况下会调用失败?
第二个参数:length = 0
第三个参数:prot
- 只指定了写权限(读权限必须要指定)
- prot PROT_READ | PROT_WRITE(与open不匹配)
第5个参数fd 通过open函数时指定的 O_RDONLY / O_WRONLY
-
5.可以open的时候O_CREAT一个新文件来创建映射区吗?
-
可以的,但是创建的文件的大小如果为0的话,肯定不行
- 可以对新的文件进行扩展
- lseek()
- truncate() -
6.mmap后关闭文件描述符,对mmap映射有没有影响?
int fd = open(“XXX”);
mmap(,fd,0);
close(fd);
映射区还存在,创建映射区的fd被关闭,没有任何影响。
- 7.对ptr越界操作会怎样?
void * ptr = mmap(NULL, 100,);
内存分页大小4K
越界操作操作的是非法的内存 -> 段错误
匿名映射:不需要文件实体进程一个内存映射 mmap的参数 fd设置为 -1,且 flags 要 | 上 MAP_ANONYMOUS 用于有关系的进程间通信
8、信号
8.1 信号的概念
信号是 Linux 进程间通信的最古老的方式之一,是事件发生时对进程的通知机制,有时也称之为软件中断,它是在软件层次上对中断机制的一种模拟,是一种异步通信的方式。
信号可以导致一个正在运行的进程被另一个正在运行的异步进程中断,转而处理某一个突发事件。
发往进程的诸多信号,通常都是源于内核。引发内核为进程产生信号的各类事件如下:
- 对于前台进程,用户可以通过输入特殊的终端字符来给它发送信号。比如输入Ctrl+C 通常会给进程发送一个中断信号。
- 硬件发生异常,即硬件检测到一个错误条件并通知内核,随即再由内核发送相应信号给 相关进程。比如执行一条异常的机器语言指令,诸如被 0 除,或者引用了无法访问的 内存区域。
- 系统状态变化,比如 alarm 定时器到期将引起 SIGALRM 信号,进程执行的 CPU 时间超限,或者该进程的某个子进程退出。
- 运行 kill 命令或调用 kill 函数。
使用信号的两个主要目的是:
让进程知道已经发生了一个特定的事情。
强迫进程执行它自己代码中的信号处理程序。
信号的特点:
-
形式内容简单
-
不能携带大量信息
-
满足某个特定条件才发送
-
优先级比较高
-
查看系统定义的信号列表:kill –l
-
前 31 个信号为常规信号,其余为实时信号




- 查看信号的详细信息:man 7 signal
- 信号的 5 中默认处理动作
- Term 终止进程
- Ign 当前进程忽略掉这个信号
- Core 终止进程,并生成一个Core文件
- Stop 暂停当前进程
- Cont 继续执行当前被暂停的进程
- 信号的几种状态:产生、未决、递达
- SIGKILL 和 SIGSTOP 信号不能被捕捉、阻塞或者忽略,只能执行默认动作。
8.2 信号相关的函数
#include <sys/types.h><br /> #include <signal.h>
-
int kill(pid_t pid, int sig);
- 功能:给任何的进程或者进程组pid, 发送任何的信号 sig<br /> - 参数:<br /> - pid :<br /> > 0 : 将信号发送给**指定的进程**<br /> = 0 : 将信号发送给当前的**进程组**<br /> = -1 : 将信号发 <br /> < -1 : 这个pid=某个进程组的ID取反 (-12345)<br /> - sig : 需要发送的信号的编号或者是宏值,0表示不发送任何信号<br /> kill(getppid(), 9); //给当前父进程发送9 信号<br /> kill(getpid(), 9); //给当前进程发送9信号<br /> -
int raise(int sig);
- 功能:给当**前进程发送信号**<br /> - 参数:<br /> - sig : 要发送的信号<br /> - 返回值:<br /> - 成功 0<br /> - 失败 非0<br /> 相当于 kill(getpid(), sig); -
void abort(void);
- 功能: 发送**SIGABRT**信号给**当前的进程**,**杀死当前进程**<br /> 相当于 kill(getpid(), SIGABRT);
unsigned int alarm(unsigned int seconds);
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
- 功能:设置定时器(闹钟)。函数调用,开始倒计时,
当倒计时为0的时候, 函数会给当前的进程发送一个信号:SIGALARM
- 参数:
seconds: 倒计时的时长,单位:秒。如果参数为0,定时器无效(不进行倒计时,不发信号)。
取消一个定时器,通过alarm(0)。
- 返回值:
- 之前没有定时器,返回0
- 之前有定时器,返回之前的定时器剩余的时间
- SIGALARM :默认终止当前的进程,每一个进程都**有且只有唯一的一个定时器**。<br /> alarm(10); -> 返回0<br /> 过了1秒 剩余9秒<br /> alarm(5); 重置为倒计时5秒, 返回之前定时器的剩余时间9秒<br /> 该函数是不阻塞的(非阻塞)
#include <sys/time.h><br />** int setitimer(int which, const struct itimerval *new_value,**<br />** struct itimerval *old_value);**<br /> <br /> - 功能:设置**定时器(闹钟**)。可以替代alarm函数。**精度微秒us**,可以实现**周期性**定时<br /> - 参数:<br /> - which : 定时器以什么时间计时<br /> ITIMER_REAL: **真实时间**,时间到达,发送 SIGALRM ** 常用**!<br /> ITIMER_VIRTUAL: **用户**时间,时间到达,发送 SIGVTALRM<br /> ITIMER_PROF: 以该进程在**用户**态和**内核**态下所消耗的时间来计算,时间到达,发送 SIGPROF
- new_value: 设置定时器的属性<br /> struct itimerval { // 定时器的结构体<br /> struct timeval it_interval; // 每个阶段的时间,间隔时间<br /> struct timeval it_value; // 延迟多长时间执行定时器<br /> };
struct timeval { // 时间的结构体<br /> time_t tv_sec; // 秒数 <br /> suseconds_t tv_usec; // 微秒 <br /> };<br /> 过10秒(延迟it_value)后,每个2秒(间隔it_interval)定时一次<br /> - old_value :记录上一次的定时的时间参数,一般不使用,指定NULL<br /> - 返回值:<br /> 成功 0<br /> 失败 -1 并设置错误号
8.3 信号捕捉函数
#include <signal.h><br /> typedef void (*sighandler_t)(int);<br />// void (*sighandler_t)(int); 函数指针,**int**类型的参数表示捕捉到的**信号的值**。<br /> sighandler_t **signal**(int signum, sighandler_t handler);<br /> - 功能:设置某个信号的捕捉行为<br /> - 参数:<br /> - signum: 要捕捉的信号<br /> - handler: 捕捉到信号要如何处理<br /> - SIG_IGN : **忽略**信号<br /> - SIG_DFL : 使用信号**默认**的行为<br /> - 回调函数 : 这个函数是内核调用,程序员只负责写,捕捉到信号后**如何去处**<br />**理信号**。<br /> 回调函数:<br /> - 需要程序员实现,提前准备好的,函数的类型根据实际需求,看函数指针<br />的定义<br /> - 不是程序员调用,而是当**信号产生**,**由内核调用**<br /> - 函数指针是实现回调的手段,函数实现之后,将函数名放到函数指针的<br />位置就可以了。
- 返回值:<br /> 成功,返回**上一次**注册的**信号处理函数的地址**。第一次调用返回NULL<br /> 失败,返回SIG_ERR,设置错误号<br /> <br /> SIGKILL SIGSTOP**不能被捕捉**,**不能被忽略**。
signal 采用的是美国国家标准 ANSI c signal handling
sigaction 标准为_POSIX_C_SOURCE 兼容性较好
#include <signal.h>
int sigaction(int signum, const struct sigaction act,
struct sigaction oldact);
- 功能:检查或者改变信号的处理。信号捕捉
- 参数:
- signum : 需要捕捉的信号的编号或者宏值(信号的名称)
- act** :捕捉到信号之后的处理动作
- oldact : 上一次对信号捕捉相关的设置,一般不使用,传递NULL
- 返回值:
成功 0
失败 -1
struct sigaction {<br /> // **函数指针**,指向的函数就是信号捕捉到之后的处理函数<br /> void (*sa_handler)(int);<br /> // 不常用 **第二个信号处理函数**<br /> void (*sa_sigaction)(int, siginfo_t *, void *);<br /> // 临时阻塞信号集,在信号捕捉函数执行过程中,临时阻塞某些信号。<br /> sigset_t sa_mask;<br /> // 使用哪一个信号处理函数对捕捉到的信号进行处理<br /> // 这个值可以是0,表示使用sa_handler,也可以是SA_SIGINFO表示使用 sa_sigaction <br /> int sa_flags;
// 被废弃掉了<br /> void (*sa_restorer)(void);<br /> };
8.4 信号集
许多信号相关的系统调用都需要能表示一组不同的信号,多个信号可使用一个称之为信号集的数据结构来表示,其系统数据类型为 sigset_t。
在 PCB 中有两个非常重要的信号集。一个称之为 “阻塞信号集” ,另一个称之为 “未决信号集” 。这两个信号集都是内核使用位图机制(二进制位)来实现的。但操作系统不允许我们直接对这两个信号集进行位操作。而需自定义另外一个集合,借助信号集操作函数来对 PCB 中的这两个信号集进行修改。
信号的 “未决” 是一种状态,指的是从信号的产生到信号被处理前的这一段时间。
信号的 “阻塞” 是一个开关动作,指的是阻止信号被处理,但不是阻止信号产生。
信号的阻塞就是让系统暂时保留信号留待以后发送。由于另外有办法让系统忽略信号, 所以一般情况下信号的阻塞只是暂时的,只是为了防止信号打断敏感的操作。
8.5 阻塞信号集和未决信号集
未决信号集只能标记 一个信号 ,不支持排队
1.用户通过键盘Ctrl + c,产生 2号信号 SIGINT(信号被创建)
2.信号产生但是没有被处理(未决)
-在内核中将所有的没有被处理的信号存储在一个集合中(未决信号集)- SIGINT信号状态被存储在第二个标志位上
-这个标志位的值为0,说明信号不是未决状态-这个标志位的值为1,说明信号处于未决状态
3.这个未决状态的信号,需要被处理,处理之前需要和另一个信号集(阻塞信号集),进行比较
-阻塞信号集默认不阻塞任何的信号
-如果想要阻塞某些信号需要用户调用系统的API
4.在处理的时候和阻塞信号集中的标志位进行查询,看是不是对该信号设置阻塞了-如果没有阻塞,这个信号就被处理
-如果阻塞了,这个信号就继续处于未决状态,直到阻塞解除,这个信号就被处理
8.6 信号集相关的函数
sigset_t set;
sigemptyset(&set); //初始化信号集
int sigemptyset(sigset_t · *set) ;
-功能:清空信号集中的数据,将信号集中的所有的标志位置为0
-参数: set,传出参数,需要操作的信号集
-返回值:成功返回0,失败返回-1
int sigfillset(sigset_t *set);
-功能:将信号集中的所有的标志位置为1
-参数:set,传出参数,需要操作的信号集
-返回值:成功返回0,失败返回-1
int sigaddset(sigset_t *set, int signum);
-功能:设置信号集中的某一个信号对应的标志位为1,表示阻塞这个信号
-参数:set:传出参数,需要操作的信号集 signum:需要设置阻塞的那个信号
-返回值:成功返回0,失败返回-1
int sigdelset(sigset_t *set, int signum);
-功能:设置信号集中的某一个信号对应的标志位为0,表示不阻塞这个信号
-参数:set:传出参数,需要操作的信号集 signum:需要设置不阻塞的那个信号
-返回值:成功返回0,失败返回-1
int sigismember( const sigset_t *set, int signum);
-功能:判断某个信号是否阻塞
-参数:set:需要操作的信号集 signum:需要判断的那个信号
-返回值:
1 :signum被阻塞
0 : signum不阻塞
-1 :失败
sigprocmask 将自己定义的信号集设置到内核当中
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
- 功能:将自定义信号集中的数据设置到内核中(设置阻塞,解除阻塞,替换)
- 参数:
- how : 如何对内核阻塞信号集进行处理
SIG_BLOCK: 将用户设置的阻塞信号集添加到内核中,内核中原来的数据不变
假设内核中默认的阻塞信号集是mask, mask | set 按位取或
SIG_UNBLOCK: 根据用户设置的数据,对内核中的数据进行解除阻塞
mask &= ~set
SIG_SETMASK: 覆盖内核中原来的值
- set :已经初始化好的用户自定义的信号集
- oldset : 保存设置之前的内核中的阻塞信号集的状态,可以是 NULL
- 返回值:
成功:0
失败:-1
设置错误号:EFAULT、EINVAL 不同类型的错误
int sigpending(sigset_t *set);<br /> - 功能:**获取**内核中的**未决信号集**<br /> - 参数:set,**传出参数**,保存的是内核中的未决信号集中的信息。
8.7 内核实现信号捕捉的过程

8.8 SIGCHLD信号
解决僵尸进程的问题
- SIGCHLD信号产生的条件
- 子进程终止时 (主要用)
- 子进程接收到 SIGSTOP 信号停止时
- 子进程处在停止态,接受到SIGCONT后唤醒时
- 以上三种条件都会给父进程发送 SIGCHLD 信号,父进程默认会忽略该信号
wait/waitpid一次只能回收一个进程,需要循环进行回收
捕捉SIGCHLD信号可以多次回收执行完的子进程
#include<sys/stat.h>
#include<sys/types.h>
#include<stdio.h>
#include<unistd.h>
#include<wait.h>
#include<signal.h>
void myFun(int num){
printf("捕捉到了SIGCHLD信号: %d\n", num);
int ret;
while (1)
{
ret = waitpid(-1,NULL,WNOHANG);//WNOHANG设置非阻塞
if(ret>0){
printf("child die pid:%d\n",ret);
}else if(ret==0){
//说明还有子进程
break;
}else if(ret==-1){
//没有子进程
break;
}
}
}
int main(){
//设置SIGCHLD信号阻塞,防止还没有设置信号捕捉,就要子进程结束了
sigset_t set;
sigemptyset(&set);
sigaddset(&set,SIGCHLD);
//设置到内核中
sigprocmask(SIG_BLOCK,&set,NULL);
//创建子进程
pid_t pid;
for (int i = 0; i < 10; i++)
{
pid = fork();
if(pid==0){
break;
}
}
if(pid>0){
//设置信号SIGCHLD捕捉
struct sigaction act;
act.sa_flags = 0;
act.sa_handler = myFun; //传函数名(指针)
sigemptyset(&act.sa_mask);
sigaction(SIGCHLD, &act, NULL);
//创建完SIGCHLD捕捉后,解除阻塞,
sigprocmask(SIG_UNBLOCK,&set,NULL);
while(1){
printf("parent, pid:%d\n",getpid());
sleep(2);
}
}else if(pid==0){
printf("child, pid:%d\n",getpid());
}
return 0;
}
9、共享内存
9.1 共享内存概念
共享内存允许两个或者多个进程共享物理内存的同一块区域(通常被称为段)。==由于一个共享内存段会成为一个进程用户空间的一部分,因此这种 IPC 机制无需内核介入。==所有需要做的就是让一个进程将数据复制进共享内存中,并且这部分数据会对其他所有共享同一个段的进程可用。 (效率更高)
与管道等要求发送进程将数据从用户空间的缓冲区复制进内核内存和接收进程将数据从内核内存复制进用户空间的缓冲区的做法相比,这种 IPC 技术的速度更快。
9.2 共享内存使用步骤
- 调用 shmget() 创建一个新共享内存段或取得一个既有共享内存段的标识符(即由其他进程创建的共享内存段)。这个调用将返回后续调用中需要用到的共享内存标识符。
- 使用 shmat() 来附上共享内存段,即使该段成为调用进程的虚拟内存的一部分。
- 此刻在程序中可以像对待其他可用内存那样对待这个共享内存段。为引用这块共享内存, 程序需要使用由 shmat() 调用返回的 addr 值,它是一个指向进程的虚拟地址空间中该共享内存段的起点的指针。
- 调用 shmdt() 来分离共享内存段。在这个调用之后,进程就无法再引用这块共享内存了。这一步是可选的,并且在进程终止时会自动完成这一步。
- 调用 shmctl() 来标记删除共享内存段。只有当当前所有附加内存段的进程都与之分离之后内存段才会销毁。
只要有一个进程执行这一步,key 就变为0。
9.3 共享内存操作函数
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
- 功能:创建一个新的共享内存段,或者获取一个既有的共享内存段的标识。
新创建的内存段中的数据都会被初始化为0
- 参数:
- key : key_t类型是一个整形,通过这个找到或者创建一个共享内存。
一般使用16进制表示,非0值
- size: 共享内存的大小
- shmflg: 属性
- 访问权限
- 附加属性:创建/判断共享内存是不是存在
- 创建:IPC_CREAT
- 判断共享内存是否存在: IPC_EXCL , 需要和IPC_CREAT一起使用
** IPC_CREAT | IPC_EXCL | 0664**
- 返回值:
失败:-1 并设置错误号
成功:>0 返回共享内存的引用的ID,后面操作共享内存都是通过这个值。
void *shmat(int shmid, const void *shmaddr, int shmflg);
- 功能:和当前的进程进行关联
- 参数:
- shmid : 共享内存的标识(ID),由shmget返回值获取
- shmaddr: 申请的共享内存的起始地址,指定NULL,内核指定
- shmflg : 对共享内存的操作
- 读 : SHM_RDONLY**,必须要有读权限
- 读写: 0
- 返回值:
成功:返回共享内存的首(起始)地址。
失败 (void *) -1
int shmdt(const void *shmaddr);
- 功能:解除当前进程和共享内存的关联**
- 参数:
shmaddr:共享内存的首地址
- 返回值:成功 0, 失败 -1
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
- 功能:对共享内存进行操作。删除共享内存,共享内存要删除才会消失,创建共享内存的进程被销毁了对共享内存是没有任何影响。
- 参数:
- shmid: 共享内存的ID
- cmd : 要做的操作
- IPC_STAT : 获取共享内存的当前的状态
- IPC_SET : 设置共享内存的状态
- IPC_RMID: 标记共享内存被销毁
- buf:需要设置或者获取的共享内存的属性信息
- IPC_STAT : buf存储数据
- IPC_SET : buf中需要初始化数据,设置到内核中
- IPC_RMID : 没有用,NULL
key_t ftok(const char *pathname, int proj_id);
- ==功能:根据指定的路径名,和int值,生成一个共享内存的key**==
- 参数:
- pathname:指定一个存在**的路径
/home/nowcoder/Linux/a.txt
- proj_id: int类型的值,但是这系统调用只会使用其中的1个字节
范围 : 0-255 一般指定一个字符 ‘a’
9.4 共享内存的一些常见问题
问题1:操作系统如何知道一块共享内存被多少个进程关联?
- 共享内存维护了一个结构体struct shmid_ds 这个结构体中有一个成员 shm_nattch
- shm_nattach 记录了关联的进程个数
问题2:可不可以对共享内存进行多次删除 shmctl
- 可以的
- 因为shmctl 标记删除共享内存,不是直接删除
- 什么时候真正删除呢?
当和共享内存关联的进程数为0的时候,就真正被删除
- 当共享内存的key为0的时候,表示共享内存被标记删除了****
如果一个进程和共享内存取消关联,那么这个进程就不能继续操作这个共享内存。也不能进行关联。
共享内存和内存映射的区别
1.共享内存可以直接创建,内存映射需要磁盘文件(匿名映射除外)
2.共享内存效率更高 (无需更磁盘文件同步)
3.内存
所有的进程操作的是同一块共享内存。
内存映射,每个进程在自己的虚拟地址空间中有一个独立的内存。
4.数据安全
- 进程突然退出
共享内存还存在
内存映射区消失
- 运行进程的电脑死机,宕机了
数据存在在共享内存中,没有了
内存映射区的数据 ,由于磁盘文件中的数据还在,所以内存映射区的数据还存在。
5.生命周期
内存映射区:进程退出,内存映射区销毁
共享内存:进程退出,共享内存还在,标记删除(所有的关联的进程数为0),或者关机
如果一个进程退出,会自动和共享内存进行取消关联。
9.5 共享内存操作命令

10、守护进程
10.1 终端、进程组、会话的概念
终端
在 UNIX 系统中,用户通过终端登录系统后得到一个** shell 进程**,这个终端成 为 shell 进程的控制终端(Controlling Terminal),进程中,控制终端是保存在 PCB 中的信息,而 fork() 会复制 PCB 中的信息,因此由 shell 进程启动的其它进程的控制终端也是这个终端。
默认情况下(没有重定向),每个进程的标准输入、标准输出和标准错误输出都指向控制终端,进程从标准输入读也就是读用户的键盘输入,进程往标准输出或标准 错误输出写也就是输出到显示器上。
在控制终端输入一些特殊的控制键可以给前台进程发信号,例如 Ctrl + C 会产 生 SIGINT 信号,Ctrl + \ 会产生 SIGQUIT 信号。
输入 tty 返回控制终端的信息
echo $$ 查看运行的当前进程ID号,返回登录shell的PID
进程组
- 进程组和会话在进程之间形成了一种两级层次关系:进程组是一组相关进程的集合, 会话是一组相关进程组的集合**。**进程组和会话是为支持 shell 作业控制而定义的抽象概念,用户通过 shell 能够交互式地在前台或后台运行命令。
- ==进行组由一个或多个共享同一进程组标识符(PGID)的进程组成。==一个进程组拥有一 个进程组首进程,该进程是创建该组的进程,其进程 ID 为该进程组的 ID,新进程 会继承其父进程所属的进程组 ID。
- 进程组拥有一个生命周期,其开始时间为首进程创建组的时刻,结束时间为最后一个 成员进程退出组的时刻。一个进程可能会因为终止而退出进程组,也可能会因为加入了另外一个进程组而退出进程组。进程组首进程无需是最后一个离开进程组的成员。
会话
会话是一组进程组的集合。会话首进程是创建该新会话的进程,其进程 ID 会成为会话 ID。新进程会继承其父进程的会话 ID。
一个会话中的所有进程共享单个控制终端。控制终端会在会话首进程首次打开一个终端设备时被建立。一个终端最多可能会成为一个会话的控制终端。 单对单
**在任一时刻,会话中的其中一个进程组会成为终端的前台进程组,其他进程组会成为后台进程组。**只有前台进程组中的进程才能从控制终端中读取输入。当用户在控制终 端中输入终端字符生成信号后,该信号会被发送到前台进程组中的所有成员。
当控制终端的连接建立起来之后,会话首进程会成为该终端的控制进程。
进程组、会话操作函数
pid_t getpgrp(void);
pid_t getpgid(pid_t pid);
int setpgid(pid_t pid, pid_t pgid); //设置
pid_t getsid(pid_t pid);
pid_t setsid(void); //设置
9.2 守护进程概念
守护进程(Daemon Process),也就是通常说的 Daemon 进程(精灵进程),是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。一般采用以 d 结尾的名字。
守护进程具备下列特征:
- 生命周期很长,守护进程会在系统启动的时候被创建并一直运行直至系统被关闭。
- 它在后台运行并且不拥有控制终端。没有控制终端确保了内核永远不会为守护进程自动生成任何控制信号以及终端相关的信号(如 SIGINT、SIGQUIT)。
- Linux 的大多数服务器就是用守护进程实现的。比如,Internet 服务器 inetd, Web 服务器 httpd 等。
9.3 守护进程的创建步骤
- 执行一个 fork(),之后父进程退出,子进程继续执行。 (1、进程组的首进程不能作会话组的组长,为了成功调用 setsid() ;2、退出前台进程,让shell显示出$ (不太重要))
- 子进程调用 setsid() 开启一个新会话。 (脱离控制终端) 子进程的ID作为新的组ID和新的会话的ID
- 清除进程的 umask 以确保当守护进程创建文件和目录时拥有所需的权限。 (不是必须的)
- 修改进程的当前工作目录,通常会改为根目录(/)。 (防止文件卸载时,进程停止运作)
- 关闭守护进程从其父进程继承而来的所有打开着的文件描述符。 (不让它操作终端,或一直占用文件)
- 在关闭了文件描述符0、1、2之后,守护进程通常会打开/dev/null (自动丢弃) 并使用dup2() 使所有这些描述符指向这个设备。
- 核心业务逻辑
/*
写一个守护进程,每隔2s获取一下系统时间,将这个时间写入到磁盘文件中。
*/
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/time.h>
#include <signal.h>
#include <time.h>
#include <stdlib.h>
#include <string.h>
void work(int num) {
// 捕捉到信号之后,获取系统时间,写入磁盘文件
time_t tm = time(NULL);
struct tm * loc = localtime(&tm);
// char buf[1024];
// sprintf(buf, "%d-%d-%d %d:%d:%d\n",loc->tm_year,loc->tm_mon
// ,loc->tm_mday, loc->tm_hour, loc->tm_min, loc->tm_sec);
// printf("%s\n", buf);
char * str = asctime(loc);
int fd = open("time.txt", O_RDWR | O_CREAT | O_APPEND, 0664);
write(fd ,str, strlen(str));
close(fd);
}
int main() {
// 1.创建子进程,退出父进程
pid_t pid = fork();
if(pid > 0) {
//结束父进程
exit(0);
}
// 2.将子进程重新创建一个会话
setsid();
// 3.设置掩码
umask(022); //文件默认权限=666-umask值 666-022=644
// 4.更改工作目录
chdir("/home/nowcoder/");
// 5. 关闭、重定向文件描述符
int fd = open("/dev/null", O_RDWR);
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
// 6.业务逻辑
// 捕捉定时信号
struct sigaction act;
act.sa_flags = 0; //使用第一个函数
act.sa_handler = work;
sigemptyset(&act.sa_mask);
sigaction(SIGALRM, &act, NULL);
struct itimerval val;
val.it_value.tv_sec = 2;
val.it_value.tv_usec = 0;
val.it_interval.tv_sec = 2;
val.it_interval.tv_usec = 0;
// 创建定时器
setitimer(ITIMER_REAL, &val, NULL);
// 不让进程结束
while(1) {
sleep(10);
}
return 0;
}
三、Linux 多线程开发
参考链接:https://blog.csdn.net/qq_53111905/article/details/120402739
3.1 线程的概念
3.1.1 线程概述
与进程(process)类似,线程(thread)是允许应用程序并发执行多个任务的一种机制。一个进程可以包含多个线程。同一个程序中的所有线程均会独立执行相同程序,且共享同一份全局内存区域,其中包括初始化数据段、未初始化数据段,以及堆内存段。(传统意义上的 UNIX 进程只是多线程程序的一个特例,该进程只包含一个线程)
进程是 CPU分配资源的最小单位,线程是操作系统调度执行的最小单位。
线程是轻量级的进程(LWP:Light Weight Process),在 Linux 环境下线程的本质仍是进程。
查看指定进程的 LWP 号:ps –Lf pid
3.1.2 线程和进程区别
-
进程间的信息难以共享。由于除去只读代码段外,父子进程并未共享内存,因此必须采用一些进程间通信方式,在进程间进行信息交换。
-
调用 fork() 来创建进程的代价相对较高,即便利用写时复制技术,仍然需要复制诸如 内存页表和文件描述符表之类的多种进程属性**,这意味着 fork() 调用在时间上的开销依然不菲**。
-
线程之间能够方便、快速地共享信息。只需将数据复制到共享(全局或堆)变量中即可。
-
创建线程比创建进程通常要快 10 倍甚至更多。线程间是共享虚拟地址空间的,无需采用写时复制来复制内存,也无需复制页表。
3.1.3 线程之间共享和非共享资源
- 共享资源 (内核里的数据)
- 进程 ID 和父进程 ID
- 进程组 ID 和会话 ID
- 用户 ID 和 用户组 ID
- 文件描述符表
- 信号处置 注册的信号处理
- 文件系统的相关信息:文件权限掩码 (umask)、当前工作目录
- 虚拟地址空间(除栈、.text(代码段))
- 非共享资源
- 线程 ID
- 信号掩码
- 线程特有数据
- error 变量
- 实时调度策略和优先级
- 栈,本地变量和函数的调用链接信息
3.2 线程操作
任何的线程都可以回收其他的线程,通过pthread_join
man pthread
一般情况下,main函数所在的线程我们称之为主线程(main线程),其余创建的线程<br /> 称之为子线程。<br /> 程序中默认只有一个进程,fork()函数调用,2进行<br /> 程序中默认只有一个线程,pthread_create()函数调用,2个线程。
3.2.1 创建子线程
-
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
- 功能:**创建**一个子线程<br /> - 参数:<br /> - thread:传出参数,线程创建成功后,子线程的线程ID被写到该变量中。<br /> - attr : 设置线程的属性,一般使用默认值,NULL<br /> - start_routine : 函数指针,这个函数是**子线程需要处理的逻辑代码**<br /> - arg : 给第三个参数使用,**传参**<br /> - 返回值:<br /> 成功:0<br /> 失败:返回错误号。这个错误号和之前errno不太一样。<br /> 获取错误号的信息: char * strerror(int errnum);
3.2.2 获取子线程ID
- pthread_t pthread_self(void);
功能:获取当前的线程的线程ID
3.2.3 比较两个子线程ID是否相等
- int pthread_equal(pthread_t t1, pthread_t t2);
功能:比较两个线程ID是否相等
不同的操作系统,pthread_t类型的实现不一样,有的是无符号的长整型,有的
是使用结构体去实现的。
3.2.4 终止一个线程
- void pthread_exit(void *retval);
功能:终止一个线程,在哪个线程中调用,就表示终止哪个线程
参数:
retval:需要传递一个指针,作为一个返回值,可以在pthread_join()中获取到。
3.2.5 回收子线程
-
int pthread_join(pthread_t thread, void **retval);
-
功能:和一个已经终止的线程进行连接
回收子线程的资源
这个函数是阻塞函数,调用一次只能回收一个子线程
一般在主线程中使用
- 参数:
- thread:需要回收的子线程的ID
- retval: 接收子线程退出时的返回值
- 返回值:
0 : 成功
非0 : 失败,返回的错误号
3.2.6 分离子线程
-
int pthread_detach(pthread_t thread);
- 功能:分离一个线程。被分离的线程在终止的时候,会自动释放资源返回给系 统。
1.不能多次分离,会产生不可预料的行为。
2.不能去连接一个已经分离的线程,会报错。
- 参数:需要分离的线程的ID
- 返回值:
成功:0
失败:返回错误号
- 功能:分离一个线程。被分离的线程在终止的时候,会自动释放资源返回给系 统。
3.2.7 取消线程(让线程终止)
-
int pthread_cancel(pthread_t thread);
-
功能:取消线程(让线程终止)
取消某个线程,可以终止某个线程的运行,
但是并不是立马终止,而是当子线程执行到一个取消点,线程才会终止。
取消点:系统规定好的一些系统调用,我们可以粗略的理解为从用户区到内核区的切换,这个位置称之为取消点。
3.2.8 线程属性
int pthread_attr_init(pthread_attr_t *attr);<br /> - **初始化**线程属性变量<br /> int pthread_attr_destroy(pthread_attr_t *attr);<br /> - **释放**线程属性的**资源**<br /> int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);<br /> -** 获取**线程分离的状态属性<br /> int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);<br /> - **设置**线程分离的状态属性
3.3 线程同步
- 线程的主要优势在于,能够通过全局变量来共享信息。不过,这种便捷的共享是有代价 的:必须确保多个线程不会同时修改同一变量,或者某一线程不会读取正在由其他线程修改的变量。
- 临界区是指访问某一共享资源的代码片段,并且这段代码的执行应为原子操作,也就是同时访问同一共享资源的其他线程不应中断该片段的执行。
- 线程同步:即当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其他线程才能对该内存地址进行操作,而其他线程则处于等待状态。
3.4 互斥量
3.4.1 互斥量概念
- 为避免线程更新共享变量时出现问题,可以使用互斥量(mutex 是 mutual exclusion 的缩写)来确保同时仅有一个线程可以访问某项共享资源**。可以使用互斥量来保证对任意共享资源的原子访问**。(原子,不可分割,即不应该中断)
- 互斥量有两种状态:已锁定(locked)和未锁定(unlocked)。任何时候,至多只有一个线程可以锁定该互斥量。试图对已经锁定的某一互斥量再次加锁,将可能阻塞线程或者报错失败,具体取决于加锁时使用的方法。
- 一旦线程锁定互斥量,随即成为该互斥量的所有者,只有所有者才能给互斥量解锁。一般情 况下,对每一共享资源(可能由多个相关变量组成)会使用不同的互斥量,每一线程在访问 同一资源时将采用如下协议:
- 1、针对共享资源锁定互斥量
- 2、访问共享资源
- 3、对互斥量解锁
- 如果多个线程试图执行这一块代码(一个临界区),事实上只有一个线程能够持有该互斥量(其他线程将遭到阻塞),即同时只有一个线程能够进入这段代码区域,如下图所示:

3.4.2 互斥量相关函数
互斥量的类型 pthread_mutex_t<br /> int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);<br /> - **初始化**互斥量<br /> - 参数 :<br /> - mutex : 需要初始化的互斥量变量<br /> - attr : 互斥量相关的属性,NULL<br /> - restrict : C语言的修饰符,被修饰的指针,不能由另外的一个指针进行操作。<br /> pthread_mutex_t *restrict mutex = xxx;<br /> pthread_mutex_t *mutex1 = mutex;<br /> int pthread_mutex_destroy(pthread_mutex_t *mutex);<br /> - **释放**互斥量的资源<br /> int pthread_mutex_lock(pthread_mutex_t *mutex);<br /> - **加锁**,阻塞的,如果有一个线程加锁了,那么其他的线程**只能阻塞等待**<br /> int pthread_mutex_trylock(pthread_mutex_t *mutex);<br /> - **尝试加锁**,如果加锁失败,不会阻塞,会直接返回。<br /> int pthread_mutex_unlock(pthread_mutex_t *mutex);<br /> - **解锁**
#include<stdio.h>
#include<pthread.h>
#include<unistd.h>
//全局变量,所有的线程都共享这一份资源。
int tickets = 100;
//创建一个互斥量
pthread_mutex_t mutex;
void * sell(void * arg){
while (1)
{
sleep(1);
//加锁
pthread_mutex_lock(&mutex);
if(tickets>0){
printf("%ld正在卖第%d张票\n",pthread_self(),tickets);
tickets--;
}else {
//解锁
pthread_mutex_unlock(&mutex);
break;
}
//解锁
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main(){
//初始化互斥量
pthread_mutex_init(&mutex,NULL);
//创建三个子线程
pthread_t tid1,tid2,tid3;
pthread_create(&tid1,NULL,sell,NULL);
pthread_create(&tid2,NULL,sell,NULL);
pthread_create(&tid3,NULL,sell,NULL);
//回收子进程资源
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
pthread_join(tid3,NULL);
//退出主线程
pthread_exit(NULL);
//释放互斥量
pthread_mutex_destroy(&mutex);
return 0;
}
3.4.3 死锁
有时,一个线程需要同时访问两个或更多不同的共享资源,而每个资源又都由不同的互 斥量管理。当超过一个线程加锁同一组互斥量时,就有可能发生死锁。
两个或两个以上的进程在执行过程中,因争夺共享资源而造成的一种互相等待的现象, 若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
死锁的几种场景:
- 忘记释放锁
- 重复加锁
- 多线程多锁,抢占锁资源

3.4.4 读写锁
- 当有一个线程已经持有互斥锁时,互斥锁将所有试图进入临界区的线程都阻塞住。但是考虑一种情形,当前持有互斥锁的线程只是要读访问共享资源,而同时有其它几个线程也想读取这个共享资源,但是由于互斥锁的排它性,所有其它线程都无法获取锁,也就无法读访问共享资源了,但是实际上多个线程同时读访问共享资源并不会导致问题。
- 在对数据的读写操作中,更多的是读操作,写操作较少,例如对数据库数据的读写应用。 为了满足当前能够允许多个读出,但只允许一个写入的需求,线程提供了读写锁来实现。
读写锁的特点:
- 如果有其它线程读数据,则允许其它线程执行读操作,但不允许写操作。
- 如果有其它线程写数据,则其它线程都不允许读、写操作。
- 写是独占的,写的优先级高
读写锁的类型 pthread_rwlock_t<br /> int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr); ** 初始化**<br /> int pthread_rwlock_destroy(pthread_rwlock_t *rwlock); ** 释放资源**<br /> int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); ** 加上读锁**<br /> int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); ** 尝试加上读锁**<br /> int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock); **加上写锁**<br /> int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);**尝试加上写锁**<br /> int pthread_rwlock_unlock(pthread_rwlock_t *rwlock); **解锁**
/*
读写锁的类型 pthread_rwlock_t
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
案例:8个线程操作同一个全局变量。
3个线程不定时写这个全局变量,5个线程不定时的读这个全局变量
*/
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
// 创建一个共享数据
int num = 1;
// pthread_mutex_t mutex;
pthread_rwlock_t rwlock;
void * writeNum(void * arg) {
while(1) {
pthread_rwlock_wrlock(&rwlock);
num++;
printf("++write, tid : %ld, num : %d\n", pthread_self(), num);
pthread_rwlock_unlock(&rwlock);
usleep(100);
}
return NULL;
}
void * readNum(void * arg) {
while(1) {
pthread_rwlock_rdlock(&rwlock);
printf("===read, tid : %ld, num : %d\n", pthread_self(), num);
pthread_rwlock_unlock(&rwlock);
usleep(100);
}
return NULL;
}
int main() {
pthread_rwlock_init(&rwlock, NULL);
// 创建3个写线程,5个读线程
pthread_t wtids[3], rtids[5];
for(int i = 0; i < 3; i++) {
pthread_create(&wtids[i], NULL, writeNum, NULL);
}
for(int i = 0; i < 5; i++) {
pthread_create(&rtids[i], NULL, readNum, NULL);
}
// 设置线程分离
for(int i = 0; i < 3; i++) {
pthread_detach(wtids[i]);
}
for(int i = 0; i < 5; i++) {
pthread_detach(rtids[i]);
}
pthread_exit(NULL);
pthread_rwlock_destroy(&rwlock);
return 0;
}
与互斥锁的区别:互斥锁读写操作都是单一的,只能进行读操作或者写操作,
读写锁,在没有写操作时,多个线程可同时进行读操作
3.5 消费者生产者模型

容器满了,生产阻塞,通知消费者消费
容器空了,消费者阻塞,通知生产者生产
3.6 条件变量
作用:某个条件满足以后阻塞或者解除阻塞
条件变量的类型 pthread_cond_t
条件变量的类型 pthread_cond_t
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
- 等待,调用了该函数,线程会阻塞。
当这个函数调用阻塞的时候,会对互斥锁进行解锁,当不阻塞的时候,继续向下执行,会重新加锁。
int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
- 等待多长时间,调用了这个函数,线程会阻塞,直到指定的时间结束。
int pthread_cond_signal(pthread_cond_t *cond);
- 唤醒一个或者多个等待的线程
int pthread_cond_broadcast(pthread_cond_t *cond);
- 唤醒所有的等待的线程
/*
条件变量的类型 pthread_cond_t
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
- 等待,调用了该函数,线程会阻塞。
int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
- 等待多长时间,调用了这个函数,线程会阻塞,直到指定的时间结束。
int pthread_cond_signal(pthread_cond_t *cond);
- 唤醒一个或者多个等待的线程
int pthread_cond_broadcast(pthread_cond_t *cond);
- 唤醒所有的等待的线程
*/
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
// 创建一个互斥量
pthread_mutex_t mutex;
// 创建条件变量
pthread_cond_t cond;
struct Node{
int num;
struct Node *next;
};
// 头结点
struct Node * head = NULL;
void * producer(void * arg) {
// 不断的创建新的节点,添加到链表中
while(1) {
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->next = head;
head = newNode;
newNode->num = rand() % 1000;
printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());
// 只要生产了一个,就通知消费者消费
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
usleep(100);
}
return NULL;
}
void * customer(void * arg) {
while(1) {
pthread_mutex_lock(&mutex);
// 保存头结点的指针
struct Node * tmp = head;
// 判断是否有数据
if(head != NULL) {
// 有数据
head = head->next;
printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());
free(tmp);
pthread_mutex_unlock(&mutex);
usleep(100);
} else {
// 没有数据,需要等待
// 当这个函数调用阻塞的时候,会对互斥锁进行解锁,当不阻塞的,继续向下执行,会重新加锁。
pthread_cond_wait(&cond, &mutex);
pthread_mutex_unlock(&mutex);
}
}
return NULL;
}
int main() {
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
// 创建5个生产者线程,和5个消费者线程
pthread_t ptids[5], ctids[5];
for(int i = 0; i < 5; i++) {
pthread_create(&ptids[i], NULL, producer, NULL);
pthread_create(&ctids[i], NULL, customer, NULL);
}
for(int i = 0; i < 5; i++) {
pthread_detach(ptids[i]);
pthread_detach(ctids[i]);
}
while(1) {
sleep(10);
}
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
pthread_exit(NULL);
return 0;
}
3.7 信号量
信号量的类型 sem_t<br /> int sem_init(sem_t *sem, int pshared, unsigned int value);<br /> - 初始化信号量<br /> - 参数:<br /> - sem : 信号量变量的地址<br /> - pshared :** 0 **用在**线程**间 ,**非0** 用在**进程间**<br /> - value : 信号量中的值
int sem_destroy(sem_t *sem);<br /> - 释放资源
int sem_wait(sem_t *sem);<br /> - 对信号量加锁,调用一次对信号量的值-1,如果值为0,就阻塞
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);<br /> int sem_post(sem_t *sem);<br /> - 对信号量解锁,调用一次对信号量的值+1
int sem_getvalue(sem_t *sem, int *sval);<br /> sem_t psem;<br /> sem_t csem;<br /> init(psem, 0, 8);<br /> init(csem, 0, 0);<br /> producer() {<br /> sem_wait(&psem);<br /> sem_post(&csem)<br /> }<br /> customer() {<br /> sem_wait(&csem);<br /> sem_post(&psem)<br /> }
/*
信号量的类型 sem_t
int sem_init(sem_t *sem, int pshared, unsigned int value);
- 初始化信号量
- 参数:
- sem : 信号量变量的地址
- pshared : 0 用在线程间 ,非0 用在进程间
- value : 信号量中的值
int sem_destroy(sem_t *sem);
- 释放资源
int sem_wait(sem_t *sem);
- 对信号量加锁,调用一次对信号量的值-1,如果值为0,就阻塞
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
int sem_post(sem_t *sem);
- 对信号量解锁,调用一次对信号量的值+1
int sem_getvalue(sem_t *sem, int *sval);
sem_t psem;
sem_t csem;
init(psem, 0, 8);
init(csem, 0, 0);
producer() {
sem_wait(&psem);
sem_post(&csem)
}
customer() {
sem_wait(&csem);
sem_post(&psem)
}
*/
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<semaphore.h>
#include<pthread.h>
//创建互斥量
pthread_mutex_t mutex;
//创建两个信号量
sem_t psem;
sem_t csem;
struct Node
{
int data;
struct Node * next;
};
//初始化头结点
struct Node * head = NULL;
void * producer(void * arg){
while (1)
{
sem_wait(&psem);//判断是否还能生产,累计初始化的8个就阻塞
//加锁
pthread_mutex_lock(&mutex);
//开始添加结点生产
struct Node * newNode = new(struct Node);
newNode->next = head;
head = newNode;
newNode->data = rand()%100;
printf("add node, num : %d, tid : %ld\n", newNode->data, pthread_self());
//解锁
pthread_mutex_unlock(&mutex);
sem_post(&csem);//生产数+1,告诉消费者可以消费了
sleep(1);
}
return NULL;
}
void * customer(void * arg){
while (1)
{
sem_wait(&csem);//判断是否能消费
//加锁
pthread_mutex_lock(&mutex);
//消费,删除节点
struct Node * temp = head;
head = temp->next;
printf("del node, num : %d, tid : %ld\n", temp->data, pthread_self());
delete(temp);
//解锁
pthread_mutex_unlock(&mutex);
sem_post(&psem);//生产数-1
sleep(1);
}
return NULL;
}
int main(){
//初始化互斥量
pthread_mutex_init(&mutex,NULL);
//初始化信号量
sem_init(&psem,0,8);
sem_init(&csem,0,0);
//创建线程,3个生产,5个消费
pthread_t ptids[5], ctids[5];
for(int i =0;i<5;i++){
pthread_create(&ctids[i],NULL,customer,NULL);
pthread_create(&ptids[i],NULL,producer,NULL);
}
//回收线程
for(int i =0;i<5;i++){
pthread_join(ctids[i],NULL);
pthread_join(ptids[i],NULL);
}
//回收锁资源
pthread_mutex_destroy(&mutex);
//回收信号量
sem_destroy(&csem);
sem_destroy(&psem);
//结束main主线程
pthread_exit(NULL);
return 0;
}
四、Linux网络编程
1. 网络基础
1.1 网络结构模式
C/S结构
服务器–客户机,即Client - Server (C/S)结构。CIS结构通常采取两层结构。服务器负责数据的管理,客户机负责完成与用户的交互任务。客户机是因特网上访问别人信息的机器,服务器则是提供信息供人访问的计算机。
客户机通过局域网与服务器相连,接受用户的请求,并通过网络向服务器提出请求,对数据库进行操作。服务器接受客户机的请求,将数据提交给客户机,客户机将数据进行计算并将结果呈现给用户。服务器还要提供完善安全保护及对数据完整性的处理等操作,并允许多个客户机同时访问服务器,这就对服务器的硬件处理数据能力提出了很高的要求。
在C/S结构中,应用程序分为两部分:服务器部分和客户机部分。服务器部分是多个用户共享的信息与功能,执行后台服务,如控制共享数据库的操作等;客户机部分为用户所专有,负责执行前台功能,在出错提示、在线帮助等方面都有强大的功能,并且可以在子程序间自由切换。
优点
- 能充分发挥客户端PC的处理能力,很多工作可以在客户端处理后再提交给服务器,所以C/S结构客户端响应速度快;
- 操作界面漂亮、形式多样,可以充分满足客户自身的个性化要求;
- C/S结构的管理信息系统具有较强的事务处理能力,能实现复杂的业务流程;
- **安全性较高,**C/S一般面向相对固定的用户群,程序更加注重流程,它可以对权限进行多层次校验,提供了更安全的存取模式,对信息安全的控制能力很强,一般高度机密的信息系统采用C/S结构适宜。
缺点
1.客户端需要安装专用的客户端软件。首先涉及到安装的工作量,其次任何一台电脑出问题,如病毒、硬件损坏,都需要进行安装或维护。系统软件升级时,每一台客户机需要重新安装,其维护和升级成本非常高;
2.对客户端的操作系统一般也会有限制,不能够跨平台。
B/S结构
B/S 结构(Browser/Server,浏览器/服务器模式),是 WEB 兴起后的一种网络结构模式,WEB 浏览器是客户端最主要的应用软件。这种模式统一了客户端,将系统功能实现的核心部分集中到服 务器上,简化了系统的开发、维护和使用。客户机上只要安装一个浏览器,如 Firefox 或 Internet Explorer,服务器安装 SQL Server、Oracle、MySQL 等数据库。浏览器通过 Web Server 同数据 库进行数据交互。
优点
B/S 架构最大的优点是总体拥有成本低、维护方便、 分布性强、开发简单,可以不用安装任何专门的软件就能实现在任何地方进行操作,客户端零维护,系统的扩展非常容易,只要有一台能上网的电脑就能使用。
缺点
1.通信开销大、系统和数据的安全性较难保障;
2.个性特点明显降低,无法实现具有个性化的功能要求;
3.协议一般是固定的: http/https
4.客户端服务器端的交互是请求-响应模式,通常动态刷新页面,响应速度明显降低。
1.2 MAC 地址
网卡是一块被设计用来允许计算机在计算机网络上进行通讯的计算机硬件,又称为网络适配器或网络接口卡NIC。其拥有 MAC 地址,属于 OSI 模型的第 2 层,它使得用户可以通过电缆或无线相互连接。每一个网卡都有一个被称为** MAC 地址的独一无二的 48 位串行号**。网卡的主要功能:1.数据的封装与解封装、2.链路管理、3**.数据编码与译码**。
MAC 地址(Media Access Control Address),直译为媒体存取控制位址,也称为局域网地址、 以太网地址、物理地址或硬件地址,**它是一个用来确认网络设备位置的位址,由网络设备制造商生产时烧录在网卡中。**在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 位址 。MAC 地址用于在网络中唯一标识一个网卡,一台设备若有一或多个网卡,则每个网卡都需 要并会有一个唯一的 MAC 地址。
MAC 地址的长度为 48 位(6个字节),通常表示为** 12 个 16 进制数**,如:00-16-EA-AE-3C-40 就 是一个MAC 地址,其中前 3 个字节,16 进制数 00-16-EA 代表网络硬件制造商的编号,它由 IEEE(电气与电子工程师协会)分配,而后 3 个字节,16进制数 AE-3C-40 代表该制造商所制造的某个网络产品(如网卡)的系列号。只要不更改自己的 MAC 地址,MAC 地址在世界是唯一的。 形象地说,MAC 地址就如同身份证上的身份证号码,具有唯一性。
1.3 IP 地址
1.3.1 IP地址概念
IP 协议是为计算机网络相互连接进行通信而设计的协议。在因特网中,它是能使连接到网上的所 有计算机网络实现相互通信的一套规则,规定了计算机在因特网上进行通信时应当遵守的规则。任何厂家生产的计算机系统,只要遵守 IP 协议就可以与因特网互连互通。各个厂家生产的网络系统 和设备,如以太网、分组交换网等,它们相互之间不能互通,不能互通的主要原因是因为它们所传 送数据的基本单元(技术上称之为“帧”)的格式不同。IP 协议实际上是一套由软件程序组成的协议软件,它把各种不同“帧”统一转换成“IP 数据报”格式,这种转换是因特网的一个最重要的特点,使 所有各种计算机都能在因特网上实现互通,即具有“开放性”的特点。正是因为有了 IP 协议,因特 网才得以迅速发展成为世界上最大的、开放的计算机通信网络。因此,IP 协议也可以叫做“因特网 协议”。
IP 地址(Internet Protocol Address)是指互联网协议地址,又译为网际协议地址。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
IP 地址是一个 32 位的二进制数,通常被分割为 4 个“ 8 位二进制数”(也就是 4 个字节)。IP 地址 通常用“点分十进制”表示成(a.b.c.d)的形式,其中,a,b,c,d都是 0~255 之间的十进制整数。 例:点分十进IP地址(100.4.5.6),实际上是 32 位二进制数 (01100100.00000100.00000101.00000110)。
1.3.2 IP 地址编址方式
最初设计互联网络时,为了便于寻址以及层次化构造网络,每个 IP 地址包括两个标识码(ID),即网络 ID 和主机 ID。同一个物理网络上的所有主机都使用同一个网络 ID,网络上的一个主机(包括网络上工 作站,服务器和路由器等)有一个主机 ID 与其对应。Internet 委员会定义了 5 种 IP 地址类型以适合不同容量的网络,即 A 类~ E 类。
其中 A、B、C 3类(如下表格)由 InternetNIC 在全球范围内统一分配,D、E 类为特殊地址。
A类IP地址
一个 A 类 IP 地址是指, 在 IP 地址的四段号码中,第一段号码为网络号码,剩下的三段号码为本地计算 机的号码。如果用二进制表示 IP 地址的话,A 类 IP 地址就由 1 字节的网络地址和 3 字节主机地址组成,网络地址的最高位必须是“0”。A 类 IP 地址中网络的标识长度为 8 位,主机标识的长度为 24 位,A 类网络地址数量较少,有** 126 个网络**,每个网络可以容纳主机数达 1600 多万台。
A 类 IP 地址 地址范围 1.0.0.1 - 126.255.255.254(二进制表示为:00000001 00000000 00000000 00000001 - 01111111 11111111 11111111 11111110)。 最后一个是广播地址 (除了开头,全1) ,第一个是子网地址 (除了开头,全0) 。
A 类 IP 地址的子网掩码为 255.0.0.0,每个网络支持的最大主机数为 256 的 3 次方 - 2 = 16777214 台。
B类IP地址
一个B类IP地址是指,在IP地址的四段号码中,前两段号码为网络号码。如果用二进制表示IP地址的话,B类IP地址就由⒉字节的网络地址和2字节主机地址组成,网络地址的最高位必须是"10"。B类IP地址中网络的标识长度为16位,主机标识的长度为16位,B类网络地址适用于中等规模的网络,有16384个网络,每个网络所能容纳的计算机数为6万多台。
B类IP地址地址范围128.0.0.1-191.255.255.254-(二进制表示为:10000000 000oooo0 0000000000000001 - 10111111 1111111111111111 11111110)。最后一个是广播地址。
B类IP地址的子网掩码为255.255.0.0,每个网络支持的最大主机数为256的2次方-2=65534台。
C类IP地址
一个C类IP地址是指,在IP地址的四段号码中,前三段号码为网络号码,剩下的一段号码为本地计算机的号码。如果用二进制表示IP地址的话,C类IP地址就由3字节的网络地址和1字节主机地址组成,网络地址的最高位必须是"110"。C类IP地址中网络的标识长度为24位,主机标识的长度为8位,C类网络地址数量较多,有209万余个网络。适用于小规模的局域网络,每个网络最多只能包含254台计算机。
C类IP地址范围192.0.0.1-223.255.255.254 (二进制表示为:11000000 000oo000 0000000oo0000001 -11011111 11111111 11111111 11111110)。
C类IP地址的子网掩码为255.255.255.0,每个网络支持的最大主机数为256-2= 254台。
D类IP地址
D 类 IP 地址在历史上被叫做多播地址(multicast address),即组播地址。在以太网中,多播地址命名了一组应该在这个网络中应用接收到一个分组的站点。多播地址的最高位必须是 “1110”,范围从 224.0.0.0 - 239.255.255.255。
特殊的网址
每一个字节都为0的地址(“0.0.0.0”)对应于当前主机;
IP地址中的每一个字节都为1的IP地址(“255.255.255.255”)是当前子网的广播地址;
IP地址中凡是以“11110”开头的E类IP地址都保留用于将来和实验使用。
IP地址中不能以十进制"127”作为开头,该类地址中数字127.0.0.1到127.255.255.255用于回路测试,如:127.0.0.1可以代表本机IP地址。
1.3.3 子网掩码
子网掩码(subnet mask)又叫网络掩码、地址掩码、子网络遮罩,它是一种用来指明一个 IP 地 址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。子网掩码只有一个作用,就是将某个 IP 地址划分成网络地址和 主机地址两部分。
子网掩码是一个 32 位地址,用于屏蔽 IP 地址的一部分以区别网络标识和主机标识,并说明该 IP 地址是在局域网上,还是在广域网上。
子网掩码是在 IPv4 地址资源紧缺的背景下为了解决 lP 地址分配而产生的虚拟 lP 技术,通过子网掩码将 A、B、C 三类地址划分为若干子网,从而显著提高了 IP 地址的分配效率,有效解决了 IP 地址资源紧张 的局面。另一方面,在企业内网中为了更好地管理网络,网管人员也利用子网掩码的作用,人为地将一 个较大的企业内部网络划分为更多个小规模的子网,再利用三层交换机的路由功能实现子网互联,从而有效解决了网络广播风暴和网络病毒等诸多网络管理方面的问题
在大多数的网络教科书中,一般都将子网掩码的作用描述为通过逻辑运算,将 IP 地址划分为网络标识 (Net.ID) 和主机标识(Host.ID),只有网络标识相同的两台主机在无路由的情况下才能相互通信。
根据 RFC950 定义,子网掩码是一个 32 位的 2 进制数, 其对应网络地址的所有位都置为 1,对应于主机地址的所有位置都为 0。子网掩码告知路由器,地址的哪一部分是网络地址,哪一部分是主机地址, 使路由器正确判断任意 IP 地址是否是本网段的,从而正确地进行路由。网络上,数据从一个地方传到另 外一个地方,是依靠 IP 寻址。从逻辑上来讲,是两步的。第一步,从 IP 中找到所属的网络,好比是去找这个人是哪个小区的;第二步,再从 IP 中找到主机在这个网络中的位置,好比是在小区里面找到这个 人。
子网掩码的设定必须遵循一定的规则。与二进制 IP 地址相同,子网掩码由 1 和 0 组成,且 1 和 0 分别 连续。子网掩码的长度也是 32 位,左边是网络位,用二进制数字 “1” 表示,1 的数目等于网络位的长度;右边是主机位,用二进制数字 “0” 表示,0 的数目等于主机位的长度。这样做的目的是为了让掩码 与 IP 地址做按位与运算时用 0 遮住原主机数**,而不改变原网络段数字,而且很容易通过 0 的位数确定子网的主机数( 2 的主机位数次方 - 2,因为主机号全为 1 时表示该网络广播地址,全为 0 时表示该网络的网络号,这是两个特殊地址)。**通过子网掩码,才能表明一台主机所在的子网与其他子网的关系,使网络正常工作。
1.4 端口
“端口” 是英文 port 的意译,可以认为是设备与外界通讯交流的出口。==端口可分为虚拟端口和物理端口,其中虚拟端口指计算机内部或交换机路由器内的端口,不可见,是特指TCP/IP协议中的端口,是逻辑意义上的端口。==例如计算机中的 80 端口、21 端口、23 端口等。物理端口又称为接口,是可见端口,计算机背板的 RJ45 网口,交换机路由器集线器等 RJ45 端口。电话使用 RJ11 插 口也属于物理端口的范畴。
如果把 IP 地址比作一间房子,端口就是出入这间房子的门。真正的房子只有几个门,但是一个 IP 地址的端口可以有 65536(即:2^16)个之多!端口是通过端口号来标记的,端口号只有整数, 范围是从 0 到65535(2^16-1)。
虚拟端口本质上就是一个缓冲区,有读缓冲区、写缓冲区。
端口类型
1.周知端口(Well Known Ports)
周知端口是众所周知的端口号,也叫知名端口、公认端口或者常用端口,范围从 0 到 1023,它们紧密 绑定于一些特定的服务。例如 80 端口分配给 WWW 服务,21 端口分配给 FTP 服务,23 端口分配给 Telnet服务等等。我们在 IE 的地址栏里输入一个网址的时候是不必指定端口号的,因为在默认情况下 WWW 服务的端口是 “80”。网络服务是可以使用其他端口号的,如果不是默认的端口号则应该在地址栏 上指定端口号,方法是在地址后面加上冒号“:”(半角),再加上端口号。比如使用 “8080” 作为 WWW 服务的端口,则需要在地址栏里输入“网址:8080”。但是有些系统协议使用固定的端口号,它是不能被改变的,比如** 139 端口专门用于 NetBIOS 与 TCP/IP 之间的通信,不能手动改变**。
2.注册端口(Registered Ports)
端口号从 1024 到 49151,它们松散地绑定于一些服务,分配给用户进程或应用程序,这些进程主要是 用户选择安装的一些应用程序,而不是已经分配好了公认端口的常用程序。这些端口在没有被服务器资源占用的时候,可以用用户端动态选用为源端口。
3.动态端口 / 私有端口(Dynamic Ports / Private Ports)
动态端口的范围是从 49152 到 65535。之所以称为动态端口,是因为它一般不固定分配某种服务,而是动态分配。
1.5 网络模型
OSI 七层参考模型
七层模型,亦称 OSI(Open System Interconnection)参考模型,即开放式系统互联。参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为 OSI 参考模型或七层模型。
它是一个七层的、抽象的模型体,不仅包括一系列抽象的术语或概念,也包括具体的协议。
- 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后再转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。
- **数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能。**定义了如何让格式化数据以帧为单位进行传输,以及如何让控制对物理介质的访问。将比特组合成字节进而组合成帧,用MAC地址访问介质。
- **网络层:进行逻辑地址寻址,在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。Internet的发展使得从世界各站点访问信息的用户数大大增加,而网络层正是管理这种连接**的层。
- **传输层:定义了一些传输数据的协议和端口号(WwW端口80等),**如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的)。主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。
- **会话层:通过传输层(端口号︰传输端口与接收端口)建立数据传输的通路。**主要在你的系统之间发起会话或者接受会话请求。
- 表示层:数据的表示、安全、压缩。主要是进行对接收的数据进行解释、加密与解密、压缩与解压缩等(也就是把计算机能够识别的东西转换成人能够能识别的东西(如图片、声音等)。
- 应用层:网络服务与最终用户的一个接口。这一层为用户的应用程序(例如电子邮件、文件传输和终端仿真)提供网络服务。
TCP/IP 四层模型
现在 Internet(因特网)使用的主流协议族是 TCP/IP 协议族,它是一个分层、多协议的通信体系。TCP/IP协议族是一个四层协议系统,自底而上分别是数据链路层、网络层、传输层和应用层。每一层完成不同的功能,且通过若干协议来实现,上层协议使用下层协议提供的服务。

四层介绍
应用层:应用层是 TCP/IP 协议的第一层,是直接为应用进程提供服务的。
(1)对不同种类的应用程序它们会根据自己的需要来使用应用层的不同协议,邮件传输应用使用 了 SMTP 协议、万维网应用使用了 HTTP 协议、远程登录服务应用使用了有 TELNET 协议。
(2)应用层还能加密、解密、格式化数据。
(3)应用层可以建立或解除与其他节点的联系,这样可以充分节省网络资源。
传输层:作为 TCP/IP 协议的第二层,传输层在整个 TCP/IP 协议**中起到了中流砥柱的作用。**且在传输层中, TCP 和 UDP 也同样起到了中流砥柱的作用。
网络层:网络层在 TCP/IP 协议中的位于第三层。在 TCP/IP 协议中网络层可以进行网络连接的建立和终止以及 IP 地址的寻找等功能。
网络接口层:在 TCP/IP 协议中,网络接口层位于第四层。由于网络接口层兼并了物理层和数据链路层所以,网络接口层既是传输数据的物理媒介,也可以为网络层提供一条准确无误的线路。
1.6 协议
协议,网络协议的简称,网络协议是通信计算机双方必须共同遵从的一组约定。如怎么样建立连接、怎么样互相识别等。只有遵守这个约定,计算机之间才能相互通信交流。它的三要素是:语法、语义、时序。
为了使数据在网络上从源到达目的,网络通信的参与方必须遵循相同的规则,这套规则称为协议 (protocol),它最终体现为在网络上传输的数据包的格式。
协议往往分成几个层次进行定义,分层定义是为了使某一层协议的改变不影响其他层次的协议。
1.6.1 常见协议
- 应用层常见的协议有:FTP协议(File Transfer Protocol 文件传输协议)、HTTP协议(Hyper Text Transfer Protocol 超文本传输协议)、NFS(Network File System 网络文件系统)。
- 传输层常见协议有:TCP协议(Transmission Control Protocol 传输控制协议)、UDP协议(User Datagram Protocol 用户数据报协议)。
- 网络层常见协议有:IP 协议(Internet Protocol 因特网互联协议)、ICMP 协议(Internet Control Message Protocol 因特网控制报文协议)、IGMP 协议(Internet Group Management Protocol 因特 网组管理协议)。
- 网络接口层 (数据链路层) 常见协议有:ARP协议(Address Resolution Protocol 地址解析协议)、RARP协议 (Reverse Address Resolution Protocol 反向地址解析协议)MAC -> IP地址。
1.6.2 UDP协议

- 源端口号:发送方端口号
- 目的端口号:接收方端口号
- 长度:UDP用户数据报的长度,最小值是8(仅有首部)
- 校验和:检测UDP用户数据报在传输中是否有错,有错就丢弃
1.6.3 TCP协议

- 源端口号:发送方端口号
- 目的端口号:接收方端口号
- 序列号:本报文段的数据的第一个字节的序号
- 确认序号:期望收到对方下一个报文段的第一个数据字节的序号
- 首部长度(数据偏移):TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远,即首部长度。单位:32位,即以 4 字节为计算单位
- 保留:占 6 位,保留为今后使用,目前应置为 0
- 紧急 URG :此位置 1 ,表明紧急指针字段有效,它告诉系统此报文段中有紧急数据,应尽快传送
- 确认 ACK:仅当 ACK=1 时确认号字段才有效,TCP 规定,在连接建立后所有传达的报文段都必须 把 ACK 置1
- 推送 PSH:当两个应用进程进行交互式的通信时,有时在一端的应用进程希望在键入一个命令后立即就能够收到对方的响应。在这种情况下,TCP 就可以使用推送(push)操作,这时,发送方 TCP 把 PSH 置 1,并立即创建一个报文段发送出去,接收方收到 PSH = 1 的报文段,就尽快地 (即“推送”向前)交付给接收应用进程,而不再等到整个缓存都填满后再向上交付
- 复位 RST:用于复位相应的 TCP 连接
- 同步 SYN:仅在三次握手建立 TCP 连接时有效。当 SYN = 1 而 ACK = 0 时,表明这是一个连接请求报文段,对方若同意建立连接,则应在相应的报文段中使用 SYN = 1 和 ACK = 1。因此,SYN 置 1 就表示这是一个连接请求或连接接受报文
- 终止 FIN:用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要 求释放运输连接
- 窗口:指发送本报文段的一方的接收窗口(而不是自己的发送窗口)
- 校验和:校验和字段检验的范围包括首部和数据两部分,在计算校验和时需要加上 12 字节的伪头部
- 紧急指针:仅在 URG = 1 时才有意义,它指出本报文段中的紧急数据的字节数(紧急数据结束后就是普通数据),即指出了紧急数据的末尾在报文中的位置,注意:即使窗口为零时也可发送紧急数据
- 选项:长度可变,最长可达 40 字节,当没有使用选项时,TCP 首部长度是 20 字节
1.6.4 IP协议

- 版本:IP 协议的版本。通信双方使用过的 IP 协议的版本必须一致,目前最广泛使用的 IP 协议版本 号为 4(即IPv4)
- 首部长度:单位是 32 位(4 字节)
- 服务类型:一般不适用,取值为 0
- 总长度:指首部加上数据的总长度,单位为字节
- 标识(identification):IP 软件在存储器中维持一个计数器,每产生一个数据报,计数器就加 1, 并将此值赋给标识字段
- 标志(flag):目前只有两位有意义。 标志字段中的最低位记为 MF。MF = 1 即表示后面“还有分片”的数据报。MF = 0 表示这已是若干数 据报片中的最后一个。 标志字段中间的一位记为 DF,意思是“不能分片”,只有当 DF = 0 时才允许分片
- 片偏移:指出较长的分组在分片后,某片在源分组中的相对位置,也就是说,相对于用户数据段的 起点,该片从何处开始。片偏移以 8 字节为偏移单位。
- 生存时间:TTL,表明是数据报在网络中的寿命,即为“跳数限制”,由发出数据报的源点设置这个 字段。路由器在转发数据之前就把 TTL 值减一,当 TTL 值减为零时,就丢弃这个数据报。
- 协议:指出此数据报携带的数据时使用何种协议,以便使目的主机的 IP 层知道应将数据部分上交给哪个处理过程,常用的 ICMP(1),IGMP(2),TCP(6),UDP(17),IPv6(41)
- 首部校验和:只校验数据报的首部,不包括数据部分。
- 源地址:发送方 IP 地址
- 目的地址:接收方 IP 地址
1.6.5 以太网帧协议 —— mac地址的封装
 类型:0x800表示 IP、0x806表示 ARP、0x835表示 RARP
类型:0x800表示 IP、0x806表示 ARP、0x835表示 RARP
1.6.6 ARP协议 —— 通过ip地址找mac地址

- 硬件类型:1 表示 MAC 地址
- 协议类型:0x800 表示 IP 地址
- 硬件地址长度:6
- 协议地址长度:4
- 操作:1 表示 ARP 请求,2
表示 ARP 应答,3 表示 RARP 请求,4 表示 RARP 应答
1.7 封装
上层协议是如何使用下层协议提供的服务的呢?其实这是通过封装(encapsulation)实现的。应用程序 数据在发送到物理网络上之前,将沿着协议栈从上往下依次传递。每层协议都将在上层数据的基础上加 上自己的头部信息(有时还包括尾部信息),以实现该层的功能,这个过程就称为封装。
1.8 分用
当帧到达目的主机时,将沿着协议栈自底向上依次传递。各层协议依次处理帧中本层负责的头部数据, 以获取所需的信息,并最终将处理后的帧交给目标应用程序。这个过程称为分用(demultiplexing)。 分用是依靠头部信息中的类型字段实现的。

1.9 网络通信的过程

1.10 ARP协议请求封装



2. Socket通信基础
2.1 Socket介绍
Linux 进程间通信
匿名管道、命名管道(FIFO文件)、信号量、共享内存(key)、消息队列 (key)、套接字、内存映射(mmap)
2.1.1 消息队列
消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。我们可以通过发送消息来避免命名管道的同步和阻塞问题**。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
消息队列跟命名管道有不少的相同之处,通过与命名管道一样,消息队列进行通信的进程可以是不相关的进程**,同时它们都是通过发送和接收的方式来传递数据的。在命名管道中,发送数据用write,接收数据用read,则在消息队列中,发送数据用msgsnd,接收数据用msgrcv。而且它们对每个数据都有一个最大长度的限制。
与命名管道相比,消息队列的优势在于,1、消息队列也可以独立于发送和接收进程而存在,从而消除了在同步命名管道的打开和关闭时可能产生的困难。2、同时通过发送消息还可以避免命名管道的同步和阻塞问题,不需要由进程自己来提供同步方法。3、接收程序可以通过消息类型有选择地接收数据,而不是像命名管道中那样,只能默认地接收。
2.1.2 socket 套接字
所谓** socket(套接字),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。 一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程,下联网络协议栈,是应用程序通过网络协议进行通信的接口, 是应用程序与网络协议根进行交互的接口。
socket 可以看成是两个网络应用程序进行通信时,各自通信连接中的端点**,这是一个逻辑上的概 念。它是网络环境中进程间通信的 API,也是可以被命名和寻址的通信端点,使用中的每一个套接字都有其类型和一个与之相连进程。通信时其中一个网络应用程序将要传输的一段信息写入它所在主机的 socket 中,该 socket 通过与网络接口卡(NIC)相连的传输介质将这段信息送到另外一台主机的 socket 中,使对方能够接收到这段信息。socket 是由 IP 地址和端口结合的,提供向应用层进程传送数据包的机制。
socket 本身有“插座”的意思,在 Linux 环境下,用于表示进程间网络通信的特殊文件类型。本质为内核借助缓冲区形成的伪文件。既然是文件,那么理所当然的,我们可以使用文件描述符引用套接字。与管道类似的,Linux 系统将其封装成文件的目的是为了统一接口,使得读写套接字和读写文件的操作一致。区别是管道主要应用于本地进程间通信,而套接字多应用于网络进程间数据的传递。
2.1.3 字节序
现代 CPU 的累加器一次都能装载(至少)4 字节(这里考虑 32 位机),即一个整数。那么这 4 字节在内存中排列的顺序将影响它被累加器装载成的整数的值,这就是字节序问题。在各种计算机 体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问 题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正确的编码/译码从而导致通信失败。
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
字节序分为大端字节序(Big-Endian) 和小端字节序(Little-Endian)。
- 大端字节序是指一个整数的最高位字节(23 ~ 31 bit)存储在内存的低地址处,低位字节(0 ~ 7 bit)存储在内存的高地址处;
- 小端字节序则是指整数的高位字节存储在内存的高地址处,而低位字节则存储在内存的低地址处。
字节序举例
- 小端字节序 (大部分系统使用)
0x 01 02 03 04 - ff = 255
内存的方向 ----->
内存的低位 -----> 内存的高位
04 03 02 01

- 大端字节序
0x 01 02 03 04
内存的方向 ----->
内存的低位 -----> 内存的高位
01 02 03 04
0x 12 34 56 78 11 22 33 44

2.1.4 字节序转换函数
当格式化的数据在两台使用不同字节序的主机之间直接传递时,接收端必然错误的解释之。解决问题的 方法是:发送端总是把要发送的数据转换成大端字节序数据后再发送,而接收端知道对方传送过来的数 据总是采用大端字节序,所以接收端可以根据自身采用的字节序决定是否对接收到的数据进行转换(小端机转换,大端机不转换)。
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释,网络字节顺序采用大端排序方式。
BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数: htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。
h - host 主机,主机字节序
to - 转换成什么
n - network 网络字节序
s - short unsigned short 转端口 —— 16位 2字节
l - long unsigned int 转ip —— 32位 4字节
2.1.5 通用 socket 地址
socket 地址是一个结构体,封装端口号和IP等信息。
客户端需要访问服务器,服务器要提供自己的IP以及端口号;
socket 网络编程接口中表示** socket 地址的是结构体 sockaddr,其定义如下:
#include <bits/socket.h>
struct sockaddr {
sa_family_t sa_family;
char sa_data[14];
};
typedef unsigned short int sa_family_t;
sa_family 成员是地址族类型**(sa_family_t)的变量。地址族类型通常与协议族类型对应。常见的协议族(protocol family,也称 domain)和对应的地址族入下所示:
宏 PF_* 和 AF_* 都定义在 bits/socket.h 头文件中,且后者与前者有完全相同的值,所以二者通常混用。
sa_data 成员用于存放 socket 地址值。但是,不同的协议族的地址值具有不同的含义和长度,如下所示:
由上表可知,14 字节的 sa_data 根本无法容纳多数协议族的地址值。因此,Linux 定义了下面这个新的 通用的 socket 地址结构体,这个结构体不仅提供了足够大的空间用于存放地址值,而且是内存对齐的。
#include <bits/socket.h>
struct** sockaddr_storage**
{
sa_family_t sa_family;
unsigned long int __ss_align;
char __ss_padding[ 128 - sizeof(__ss_align) ];
};
typedef unsigned short int sa_family_t;
2.1.6 专用 socket 地址
很多网络编程函数诞生早于 IPv4 协议,那时候都使用的是 struct sockaddr 结构体,为了向前兼容,现 在sockaddr 退化成了(void )的作用,传递一个地址给函数,至于这个函数是 sockaddr_in 还是 sockaddr_in6,由地址族确定,然后函数内部再强制类型转化为所需的地址类型。
UNIX** 本地域协议族使用如下专用的 socket 地址结构体:
#include <sys/un.h>
struct sockaddr_un
{
sa_family_t sin_family;
char sun_path[108];
};
TCP/IP 协议族有 sockaddr_in** 和** sockaddr_in6** 两个专用的 socket 地址结构体,它们分别用于 IPv4 和** IPv6**:
#include <netinet/in.h>
//IPv4
struct sockaddr_in
{
sa_family_t sin_family; /* __SOCKADDR_COMMON(sin_) 协议族IPV4为PF_INET*/
in_port_t sin_port; /* Port number. 2个字节端口号*/
struct in_addr sin_addr; /* Internet address. 4个字节的ip地址*/
/* Pad to size of `struct sockaddr'. */
unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE -
sizeof (in_port_t) - sizeof (struct in_addr)]; //内存对齐
};
struct in_addr
{
in_addr_t s_addr;
};
//IPv6
struct sockaddr_in6
{
sa_family_t sin6_family;
in_port_t sin6_port; /* Transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* IPv6 scope-id */
};
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef uint16_t in_port_t;
typedef uint32_t in_addr_t;
#define __SOCKADDR_COMMON_SIZE (sizeof (unsigned short int))
所有专用 socket 地址(以及 sockaddr_storage)类型的变量在实际使用时都需要转化为通用 socket 地址类型 sockaddr(强制转化即可),因为所有 socket 编程接口使用的地址参数类型都是 sockaddr。
2.2 IP地址转换(字符串ip-整数 ,主机、网络字节序的转换)
通常,人们习惯用可读性好的字符串来表示 IP 地址,比如用点分十进制字符串表示 IPv4 地址,以及用 十六进制字符串表示 IPv6 地址。但编程中我们需要先把它们转化为整数(二进制数)**方能使用。而记录日志时则相反,我们要把整数表示的 IP 地址转化为可读的字符串。**下面 3 个函数可用于用点分十进制字 符串表示的 IPv4 地址和用网络字节序整数表示的 IPv4 地址之间的转换:
#include <arpa/inet.h>
in_addr_t inet_addr(const char *cp);
int inet_aton(const char *cp, struct in_addr *inp);
char *inet_ntoa(struct in_addr in);
下面这对更新的函数也能完成前面 3 个函数同样的功能,并且它们同时适用 IPv4 地址和 IPv6 地址:
#include <arpa/inet.h>
// p:点分十进制的IP字符串,n:表示network,网络字节序的整数
int inet_pton(int af, const char *src, void *dst); // 字符串ip 到 网络字节序
af:地址族: AF_INET AF_INET6
src:需要转换的点分十进制的IP字符串
dst:转换后的结果保存在这个里面
// 将网络字节序的整数,转换成点分十进制的IP地址字符串<br /> const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);<br /> af:地址族: AF_INET AF_INET6<br /> src: 要转换的ip的整数的地址<br /> dst: 转换成IP地址字符串保存的地方<br /> size:第三个参数的大小(数组的大小)<br /> 返回值:返回转换后的数据的地址(字符串),和 dst 是一样的
#include<stdio.h>
#include<arpa/inet.h>
#include<string.h>
#include<iostream>
using namespace std;
int main(){
//创建点分十进制字符串
char buff[]="196.128.1.4";
unsigned int num = 0;
//点分十进制字符串转为四个字节的二进制数
inet_pton(AF_INET,buff, &num);
unsigned char * p = (unsigned char*)#
printf("%d %d %d %d\n",*p,*(p+1),*(p+2),*(p+3));
char ip[16];
const char* str = inet_ntop(AF_INET, &num, ip, sizeof(ip));
printf("ip = %s\n",ip);
printf("str = %s\n",str);
return 0;
}
3. TCP通信
3.1 TCP通信流程
UDP : 面向数据报
TCP : 面向连接

// TCP 通信的流程
// 服务器端 (被动接受连接的角色)
- 创建一个用于监听的套接字 socket —— 负责监听的文件描述符
- 监听:监听有客户端的连接
- 套接字:这个套接字其实就是一个文件描述符
- 将这个监听文件描述符和本地的IP和端口绑定(IP和端口就是服务器的地址信息)
- 客户端连接服务器的时候使用的就是这个IP和端口
- 设置监听,监听的fd开始工作 listen
- 阻塞等待,当有客户端发起连接,解除阻塞,接受客户端的连接,会得到一个和客户端通信的套接字(fd) accept —— 负责读写的文件描述符(与之前监听的fd不同,会创建新的)
- 通信
- 接收数据
- 发送数据
- 通信结束,断开连接 close
// 客户端
//主动请求连接
- 创建一个用于通信的套接字(fd) socket
- 连接服务器,需要指定连接的服务器的 IP 和 端口 connect
- 连接成功了,客户端可以直接和服务器通信
- 接收数据
- 发送数据
- 通信结束,断开连接
3.2 套接字函数
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h> // 包含了这个头文件,上面两个就可以省略
int socket(int domain, int type, int protocol);
- 功能:创建一个套接字
- 参数:
- domain: 协议族
AF_INET : ipv4
AF_INET6 : ipv6
AF_UNIX, AF_LOCAL : 本地套接字通信(进程间通信)
- type: 通信过程中使用的协议类型
SOCK_STREAM : 流式协议
SOCK_DGRAM : 报式协议
- protocol : 具体的一个协议。一般写0
- SOCK_STREAM : 流式协议默认使用 TCP
- SOCK_DGRAM : 报式协议默认使用 UDP
- 返回值:
- 成功:返回文件描述符,操作的就是内核缓冲区。
- 失败:-1
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); // socket命名
- 功能:绑定,将fd 和本地的IP + 端口进行绑定
- 参数:
- sockfd : 通过socket函数得到的文件描述符
- addr : 需要绑定的socket地址,这个地址封装了ip和端口号的信息
- addrlen : 第二个参数结构体占的内存大小
int listen(int sockfd, int backlog); // /proc/sys/net/core/somaxconn —— 规定的连接最大值
- 功能:监听这个socket上的连接 不关闭则一直监听
- 参数:
- sockfd : 通过socket()函数得到的文件描述符
- backlog : 未连接的和已经连接的和的最大值, 一般指定128,因为accept处理速度非常块
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
- 功能:接收客户端连接,默认是一个阻塞的函数,阻塞等待客户端连接
- 参数:
- sockfd : 用于监听的文件描述符
- addr : 传出参数,记录了连接成功后客户端的地址信息(ip,port)
- addrlen : 指定第二个参数的对应的内存大小
- 返回值:
- 成功 :用于通信的文件描述符
- -1 : 失败
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- 功能: 客户端连接服务器
- 参数:
- sockfd : 用于通信的文件描述符
- addr : 客户端要连接的服务器的地址信息
- addrlen : 第二个参数的内存大小
- 返回值:成功 0, 失败 -1
ssize_t write(int fd, const void *buf, size_t count); // 写数据
ssize_t read(int fd, void *buf, size_t count); // 读数据
3.3 服务器端与客户端实现
我们可以把地址设置成本机的 IP 地址,这相当告诉操作系统内核,仅仅对目标 IP 是本机 IP 地址的 IP 包进行处理。但是这样写的程序在部署时有一个问题,我们编写应用程序时并不清楚自己的应用程序将会被部署到哪台机器上。这个时候,可以利用通配地址的能力帮助我们解决这个问题。通配地址相当于告诉操作系统内核:“Hi,我可不挑活,只要目标地址是咱们的都可以。”比如一台机器有两块网卡,IP 地址分别是 202.61.22.55 和 192.168.1.11,那么向这两个 IP 请求的请求包都会被我们编写的应用程序处理。
那么该如何设置通配地址呢?对于 **IPv4 的地址来说,使用 INADDR_ANY **来完成通配地址的设置;对于 IPv6 的地址来说,使用 IN6ADDR_ANY 来完成通配地址的设置。
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
int main(){
//创建socket(用于监听套接字)
int lfd = socket(AF_INET,SOCK_STREAM,0);//协议族AF_INET 流式协议SOCK_STREAM
if(lfd==-1){
perror("socket");
exit(-1);
}
//绑定ip地址与端口
struct sockaddr_in saddr;
saddr.sin_family = AF_INET; //指定通信协议
saddr.sin_addr.s_addr = INADDR_ANY; //绑定ip,主机任意ip都可
saddr.sin_port = htons(9999); //绑定端口
int ret = bind(lfd,(struct sockaddr *)&saddr,sizeof(saddr));
if(ret==-1){
perror("bind");
exit(-1);
}
//listen 监听
ret = listen(lfd,8);
if(ret==-1){
perror("listen");
exit(-1);
}
printf("========服务器已经启动========\n");
//接收连接
struct sockaddr_in clientaddr;
unsigned int len = sizeof(clientaddr);
int cfd = accept(lfd,(struct sockaddr*)&clientaddr,&len);
if(cfd==-1){
perror("accept");
exit(-1);
}
printf("********连接客户端成功*********\n");
//输出客户端信息ip,端口
char clientIP[16]={0};
inet_ntop(AF_INET,&clientaddr.sin_addr.s_addr,clientIP,sizeof(clientIP));
unsigned short clientPort = ntohs(clientaddr.sin_port);
printf("client ip is %s, port is %d\n",clientIP,clientPort);
//通信
char recvbuf[1024];
while(1){
int len = read(cfd,recvbuf,sizeof(recvbuf));
if(len==-1){
perror("read");
exit(-1);
}else if (len>0)
{
printf("recv client data: %s\n",recvbuf);
}else if(len==0){
printf("客户端断开了连接\n");
break;
}
char * data = "hello i am server";
write(cfd,data,strlen(data));
}
//关闭文件描述符
close(cfd);
close(lfd);
return 0;
}
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
using namespace std;
int main(){
//创建套接字
int fd = socket(AF_INET,SOCK_STREAM,0);
if(fd==-1){
perror("socket");
exit(-1);
}
//根据服务器的IP地址以端口号请求连接
//初始化addr
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
//点分十进制字符串ip转换
inet_pton(AF_INET,"10.16.53.128",&serveraddr.sin_addr.s_addr);
serveraddr.sin_port =htons(9999);
//请求连接服务器
printf("===========请求连接服务器===========\n");
int ret = connect(fd,(struct sockaddr*)&serveraddr,sizeof(serveraddr));
if(ret==-1){
perror("connect");
exit(-1);
}
printf("***********连接服务器成功**********\n");
//通信
char recvBuf[1024]={0};
while (1)
{
char * data =" hello, i am client";
write(fd,data,strlen(data));
int len = read(fd,recvBuf,sizeof(recvBuf));
if(len==-1){
perror("read");
exit(-1);
}else if(len>0){
printf("recv server data: %s\n",recvBuf);
}else if (len==0)
{
printf("服务器断开了连接。。。\n");
break;
}
sleep(1);
}
close(fd);
return 0;
}
3.4 TCP 三次握手
- TCP 是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的“连 接”,其实是客户端和服务器的内存里保存的一份关于对方的信息,如 IP 地址、端口号等。
- TCP 可以看成是一种字节流,它会处理 IP 层或以下的层的丢包、重复以及错误问题。在连接的建立过程中,双方需要交换一些连接的参数。这些参数可以放在 TCP 头部。
- TCP 提供了一种可靠、面向连接、字节流、传输层的服务,采用三次握手建立一个连接。采用四次挥手来关闭一个连接。
三次握手就是保证双方互相之间建立连接

- 16 位端口号(port number):告知主机报文段是来自哪里(源端口)以及传给哪个上层协议或 应用程序(目的端口)的。进行 TCP 通信时,客户端通常使用系统自动选择的临时端口号。
- 32 位序号(sequence number):一次 TCP 通信(从 TCP 连接建立到断开)过程中某一个传输 方向上的字节流的每个字节的编号。假设主机 A 和主机 B 进行 TCP 通信,A 发送给 B 的第一个 TCP 报文段中,序号值被系统初始化为某个随机值 ISN(Initial Sequence Number,初始序号值)。那么在该传输方向上(从 A 到 B),后续的 TCP 报文段中序号值将被系统设置成** ISN 加上** 该报文段所携带数据的第一个字节在整个字节流中的偏移。例如,某个 TCP 报文段传送的数据是字节流中的第 1025 ~ 2048 字节,那么该报文段的序号值就是 ISN + 1025。另外一个传输方向(从 B 到 A)的 TCP 报文段的序号值也具有相同的含义。
- 32 位确认号(acknowledgement number):用作对另一方发送来的 TCP 报文段的响应。其值是收到的 TCP 报文段的序号值 + 标志位长度(SYN,FIN) + 数据长度 。假设主机 A 和主机 B 进行 TCP 通信,那么 A 发送出的 TCP 报文段不仅携带自己的序号,而且包含对 B 发送来的 TCP 报文段的确认号。反之,B 发送出的 TCP 报文段也同样携带自己的序号和对 A 发送来的报文段的确认序 号。
- 4 位头部长度(head length):标识该 TCP 头部有多少个 32 bit(4 字节)。因为 4 位最大能表示 15,所以 TCP 头部最长是60 字节。
- 6 位标志位包含如下几项:
- URG 标志,表示紧急指针(urgent pointer)是否有效。
- ACK 标志,表示确认号是否有效。我们称携带 ACK 标志的 TCP 报文段为确认报文段。
- PSH 标志,提示接收端应用程序应该立即从 TCP 接收缓冲区中读走数据,为接收后续数据腾 出空间(如果应用程序不将接收到的数据读走,它们就会一直停留在 TCP 接收缓冲区中)。
- RST 标志,表示要求对方重新建立连接。我们称携带 RST 标志的 TCP 报文段为复位报文段。
- SYN 标志,表示请求建立一个连接。我们称携带 SYN 标志的 TCP 报文段为同步报文段。
- FIN 标志,表示通知对方本端要关闭连接了。我们称携带 FIN 标志的 TCP 报文段为结束报文 段。
- 16 位窗口大小(window size):是 TCP 流量控制的一个手段。这里说的窗口,指的是接收 通告窗口(Receiver Window,RWND)。它告诉对方本端的 TCP 接收缓冲区还能容纳多少 字节的数据,这样对方就可以控制发送数据的速度。
- 16 位校验和(TCP checksum):由发送端填充,接收端对 TCP 报文段执行 CRC 算法以校验 TCP 报文段在传输过程中是否损坏。注意,这个校验不仅包括 TCP 头部,也包括数据部分。 这也是 TCP 可靠传输的一个重要保障。
- 16 位紧急指针(urgent pointer):是一个正的偏移量。它和序号字段的值相加表示最后一 个紧急数据的下一个字节的序号。因此,确切地说,这个字段是紧急指针相对当前序号的偏 移,不妨称之为紧急偏移。TCP 的紧急指针是发送端向接收端发送紧急数据的方法。
总结:为了确保双方都有发送与接收的能力,第一次客户端给服务端发送请求,服务端知道客户端有发送的能力,于是第二次回信;当客户端收到回信后,知道服务端有接受与发送的能力,且为了让服务器知道自己有接收的能力,于是第三次发送信息,在服务器接收到信息时知道客户端有接收的能力,于是建立好了连接

第一次握手:客户端给服务端发送连接请求SYN = 1,服务端知道客户端有发送的能力
1.客户端将SYN标志位置为1
2.生成一个随机的32位的序号seq=J , 这个序号后边是可以携带数据(数据的大小)
第二次握手:服务器发送确认信号ACK = 1和连接请求SYN = 1,当客户端收到回信时知道服务端有接受与发送的能力
1.服务器端接收客户端的连接: ACK = 1
2.服务器会回发一个确认序号: ack = 客户端的序号 + 数据长度 + SYN/FIN(或者,按一个字节算)
3.服务器端会向客户端发起连接请求: SYN = 1
4.服务器会生成一个随机序号:seq = K
第三次握手:客户端发送确认信号ACK = 1,在服务器接收到信息时知道客户端有接收的能力
1.客户单应答服务器的连接请求:ACK = 1
2.客户端回复收到了服务器端的数据:ack = 服务端的序号 + 数据长度 + SYN/FIN(或者,按一个字节算)
3.5 TCP 滑动窗口 (缓冲区)
滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的 拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包, 谁也发不了数据,所以就有了滑动窗口机制来解决此问题。滑动窗口协议是用来改善吞吐量的一种 技术,即容许发送方在接收任何应答之前传送附加的包。接收方告诉发送方在某一时刻能送多少包 (称窗口尺寸)。
TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报。
滑动窗口是 TCP 中实现诸如 ACK 确认、流量控制、拥塞控制的承载结构
窗口理解为缓冲区的大小
滑动窗口的大小会随着发送数据和接收数据而变化。
通信的双方都有发送缓冲区和接收数据的缓冲区
服务器:
发送缓冲区(发送缓冲区的窗口)
接收缓冲区(接收缓冲区的窗口)
客户端
发送缓冲区(发送缓冲区的窗口)
接收缓冲区(接收缓冲区的窗口) 发送方的缓冲区:
发送方的缓冲区:
白色格子:空闲的空间
灰色格子:数据已经被发送出去了,但是还没有被接收
紫色格子:还没有发送出去的数据
接收方的缓冲区:
白色格子:空闲的空间
紫色格子:已经接收到的数据
# mss: Maximum Segment Size(一条数据的最大的数据量)
# win: 滑动窗口
1. 客户端向服务器发起连接,客户单的滑动窗口是4096,一次发送的最大数据量是1460
2. 服务器接收连接情况,告诉客户端服务器的窗口大小是6144,一次发送的最大数据量是1024
3. 第三次握手
4. 4-9 客户端连续给服务器发送了6k的数据,每次发送1k
5. 第10次,服务器告诉客户端:发送的6k数据以及接收到,存储在缓冲区中,缓冲区数据已经处理了2k,窗口大小是2k
6. 第11次,服务器告诉客户端:发送的6k数据以及接收到,存储在缓冲区中,缓冲区数据已经处理了4k,窗口大小是4k
7. 第12次,客户端给服务器发送了1k的数据
8. 第13次,客户端主动请求和服务器断开连接,并且给服务器发送了1k的数据
9. 第14次,服务器回复ACK 8194, a:同意断开连接的请求 b:告诉客户端已经接受到方才发的2k的数据c:滑动窗口2k
10.第15、16次,通知客户端滑动窗口的大小
11.第17次,第三次挥手,服务器端给客户端发送FIN,请求断开连接
12.第18次,第四次回收,客户端同意了服务器端的断开请求
四次挥手发生在断开连接的时候,在程序中当调用了close()会使用TCP协议进行四次挥手。
客户端和服务器端都可以主动发起断开连接,谁先调用close()谁就是发起。
因为在TCP连接的时候,采用三次握手建立的的连接是双向的,在断开的时候需要双向断开。
TCP 连接终止时,主机 1 先发送 FIN 报文,主机 2 进入 CLOSE_WAIT 状态,并发送一个 ACK 应答,同时,主机 2 通过 read 调用获得 EOF,并将此结果通知应用程序进行主动关闭操作,发送 FIN 报文。主机 1 在接收到 FIN 报文后发送 ACK 应答,此时主机 1 进入 TIME_WAIT 状态。
主机 1 在 TIME_WAIT** 停留持续时间是固定的**,是最长分节生命期 MSL(maximum segment lifetime)的两倍,一般称之为 2MSL。和大多数 BSD 派生的系统一样,Linux 系统里有一个硬编码的字段,名称为TCP_TIMEWAIT_LEN,其值为 60 秒。也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
你一定要记住一点,只有发起连接终止的一方会进入 TIME_WAIT 状态。这一点面试的时候经常会被问到。
防止连接关闭时四次挥手中的最后一次ACK丢失:
服务器没有收到最后的ACK时会重新发送FIN
报文在链路中的最大生存时间为MSL
最后一次ACK传输到服务器的时间 + 服务器重传FIN 的时间,即为 2MSL。
防止新连接收到旧链接的TCP报文:
在关闭“前一个连接”之后,马上又重新建立起一个相同的IP和端口之间的“新连接”,“前一个连接”的迷途重复分组在“前一个连接”终止后到达,而被“新连接”收到了。2*MSL 的时间足以保证两个方向上的数据都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定是新连接上产生的。
3.6 TCP 通信并发
要实现TCP通信服务器处理并发的任务,使用多线程或者多进程来解决。
思路:
1. 一个父进程,多个子进程
2.父进程负责等待并接受客户端的连接
3.子进程:完成通信,接受一个客户端连接,就创建一个子进程用于通信。
3.6.1 多进程实现方法:
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
#include<signal.h>
#include<wait.h>
#include <errno.h>
void recyleChild(int arg){
while (1)
{
//利用waitpid回收进程(非阻塞)
int ret = waitpid(-1,NULL,WNOHANG);
if(ret==-1){
//所有进程都被回收了
break;
}else if(ret==0){
//还有活着的子进程
break;
}else if(ret>0){
printf("子进程 %d 被回收了\n", ret);
}
}
}
int main(){
//使用信号捕捉,回收子进程,防止僵尸进程
struct sigaction act;
act.sa_flags = 0;
sigemptyset(&act.sa_mask);
act.sa_handler = recyleChild;
//注册信号捕捉
sigaction(SIGCHLD,&act,NULL);
//创建socket(用于监听套接字)
int lfd = socket(AF_INET,SOCK_STREAM,0);//协议族AF_INET 流式协议SOCK_STREAM
if(lfd==-1){
perror("socket");
exit(-1);
}
//绑定ip地址与端口
struct sockaddr_in saddr;
saddr.sin_family = AF_INET; //指定通信协议
saddr.sin_addr.s_addr = INADDR_ANY; //绑定ip,主机任意ip都可
saddr.sin_port = htons(9999); //绑定端口
int ret = bind(lfd,(struct sockaddr *)&saddr,sizeof(saddr));
if(ret==-1){
perror("bind");
exit(-1);
}
//listen 监听
ret = listen(lfd,8);
if(ret==-1){
perror("listen");
exit(-1);
}
printf("========服务器已经启动========\n");
int i = 0;
//循环接收连接
while (1)
{
struct sockaddr_in clientaddr;
unsigned int len = sizeof(clientaddr);
int cfd = accept(lfd,(struct sockaddr*)&clientaddr,&len);
/* 子进程退出会发生以下错误
accept: Interrupted system call
信号捕捉到子进程退出信号SIGCHLD执行软中断,处理完子进程回收,会跳过accept阻塞
cfd就会出现错误
改进:出现软中断,errno = EINTR , 进行 跳过
*/
if(cfd==-1){
if(errno ==EINTR){
continue;
}
perror("accept");
exit(-1);
}
printf("********连接客户端%d成功*********\n",++i);
//创建子进程进行并发通信
pid_t pid = fork();
if(pid==-1){
perror("fock");
exit(-1);
}else if(pid==0){
//子进程
//输出客户端信息ip,端口
char clientIP[16]={0};
inet_ntop(AF_INET,&clientaddr.sin_addr.s_addr,clientIP,sizeof(clientIP));
unsigned short clientPort = ntohs(clientaddr.sin_port);
printf("client ip is %s, port is %d\n",clientIP,clientPort);
//通信
char recvbuf[1024];
while(1){
int len = read(cfd,recvbuf,sizeof(recvbuf));
if(len==-1){
perror("read");
exit(-1);
}else if (len>0)
{
printf("recv client data: %s\n",recvbuf);
}else if(len==0){
printf("客户端断开了连接...\n");
break;
}
char * data = "hello i am server";
write(cfd,data,strlen(data)+1);
}
//关闭文件描述符
close(cfd);
exit(0);
}
}
close(lfd);
return 0;
}
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
using namespace std;
int main(){
//创建套接字
int fd = socket(AF_INET,SOCK_STREAM,0);
if(fd==-1){
perror("socket");
exit(-1);
}
//根据服务器的IP地址以端口号请求连接
//初始化addr
struct sockaddr_in serveraddr;
serveraddr.sin_family = AF_INET;
//点分十进制字符串ip转换
inet_pton(AF_INET,"10.16.53.128",&serveraddr.sin_addr.s_addr);
serveraddr.sin_port =htons(9999);
//请求连接服务器
printf("===========请求连接服务器===========\n");
int ret = connect(fd,(struct sockaddr*)&serveraddr,sizeof(serveraddr));
if(ret==-1){
perror("connect");
exit(-1);
}
printf("***********连接服务器成功**********\n");
//通信
char recvBuf[1024]={0};
int i = 0;
while (1)
{
sprintf(recvBuf, "client send %d\n", i++);
write(fd,recvBuf,strlen(recvBuf)+1);
int len = read(fd,recvBuf,sizeof(recvBuf));
if(len==-1){
perror("read");
exit(-1);
}else if(len>0){
printf("recv server data: %s\n",recvBuf);
}else if (len==0)
{
printf("服务器断开了连接...\n");
break;
}
sleep(1);
}
close(fd);
return 0;
}
3.6.2 多线程实现方法:
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
#include<pthread.h>
struct clientInfo {
int cfd;
struct sockaddr_in caddr;
pthread_t tid;
};
struct clientInfo sockinfos[2];
void * working(void * arg){
//需要获取到的客户端的一些信息,fd,客户端ip地址,线程号
//用结合构体传递参数
printf("********连接客户端成功*********\n");
//获取客户端一些信息
struct clientInfo* cinfo = (struct clientInfo*) arg;
//将ip转换为点分十进制
char ipBuf[16];
inet_ntop(AF_INET,&cinfo->caddr.sin_addr.s_addr,ipBuf,sizeof(ipBuf));
unsigned short cport = ntohs(cinfo->caddr.sin_port);
printf("client ip is %s, port is %d\n",ipBuf,cport);
//开始通信
//接收客户端的信息
char buf[1024]={0};
while (1)
{
int len = read(cinfo->cfd,buf,sizeof(buf));
if(len==-1){
perror("read");
exit(-1);
}else if (len>0)
{
printf("recv client data: %s\n",buf);
}else if(len==0){
printf("客户端断开了连接...\n");
break;
}
char * data = "hello i am server";
write(cinfo->cfd, data, strlen(data)+1);
}
close(cinfo->cfd);
cinfo->cfd = -1;
cinfo->tid = -1;
return NULL;
}
int main(){
//创建套接字
int lfd = socket(PF_INET,SOCK_STREAM,0);
if(lfd==-1){
perror("socket");
exit(-1);
}
//绑定ip端口号
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = INADDR_ANY;
saddr.sin_port = htons(9999);
int ret = bind(lfd,(struct sockaddr *)&saddr,sizeof(saddr));
if(ret==-1){
perror("bind");
exit(-1);
}
//监听
ret = listen(lfd,128);
if(ret==-1){
perror("listen");
exit(-1);
}
// 初始化数据
int max = sizeof(sockinfos) / sizeof(sockinfos[0]);
for(int i = 0; i < max; i++) {
bzero(&sockinfos[i], sizeof(sockinfos[i]));
sockinfos[i].cfd = -1;
sockinfos[i].tid = -1;
}
printf("========服务器已经启动========\n");
//循环监听,有客户端连接就创建子线程
while (1)
{
struct sockaddr_in clientaddr;
unsigned int len = sizeof(clientaddr);
int cfd = accept(lfd,(struct sockaddr *)&clientaddr,&len);
if(cfd==-1){
perror("accept");
exit(-1);
}
struct clientInfo * cinfo;
for(int i = 0; i < max; i++) {
// 从这个数组中找到一个可以用的sockInfo元素
if(sockinfos[i].cfd == -1) {
cinfo = &sockinfos[i];
break;
}
if(i == max - 1) {
i=-1;
}
}
//创建子线程
cinfo->cfd = cfd;
memcpy(&cinfo->caddr,&clientaddr,len);
pthread_create(&cinfo->tid, NULL,working, cinfo);
//设置线程分离,自动回收
pthread_detach(cinfo->tid);
}
close(lfd);
return 0;
}
3.7 TCP 状态转换 (要能默)


2MSL(Maximum Segment Lifetime) ———— 为了确保对方收到最后一个ACK,不再发送FIN,防止影响下一次通信
- 首先,这样做是为了确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
- 第二个理由和连接“化身”和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失。
MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
主动断开连接的一方, 最后进入一个 TIME_WAIT状态, 这个状态会持续: 2msl
- msl: 官方建议: 2分钟, 实际是30s
当 TCP 连接主动关闭方接收到被动关闭方发送的 FIN 和最终的 ACK 后,连接的主动关闭方
必须处于TIME_WAIT 状态并持续 2MSL 时间。
这样就能够让 TCP 连接的主动关闭方在它发送的 ACK 丢失的情况下重新发送最终的 ACK。
主动关闭方重新发送的最终 ACK 并不是因为被动关闭方重传了 ACK(它们并不消耗序列号,
被动关闭方也不会重传),而是因为被动关闭方重传了它的 FIN。事实上,被动关闭方总是
重传 FIN 直到它收到一个最终的 ACK。
3.8 半关闭,端口复用
3.8.1 半关闭
当 TCP 链接中 A 向 B 发送 FIN 请求关闭,另一端 B 回应 ACK 之后**(A 端进入 FIN_WAIT_2 状态),并没有立即发送 FIN 给 A,A 方处于半连接状态(半开关),此时 A 可以接收 B 发 送的数据,但是 A 已经不能再向 B 发送数据。**
使用 API 来控制实现半连接状态:
#include <sys/socket.h>
int shutdown(int sockfd, int how);
sockfd: 需要关闭的socket的描述符
how: 允许为shutdown操作选择以下几种方式:
- SHUT_RD(0): 关闭sockfd上的读功能,此选项将不允许sockfd进行读操作。
该套接字不再接收数据,任何当前在套接字接受缓冲区的数据将被无声的丢弃掉。
- SHUT_WR(1): 关闭sockfd的写功能,此选项将不允许sockfd进行写操作。进程不能在对此套接字发出写操作。
- SHUT_RDWR(2):关闭sockfd的读写功能。相当于调用shutdown两次:首先是以SHUT_RD,然后以SHUT_WR。 //相当于close
使用 close 中止一个连接,但它只是减少描述符的引用计数,并不直接关闭连接,只有当描述符的引用计数为 0 时才关闭连接。shutdown 不考虑描述符的引用计数,直接关闭描述符。也可选择中止一个方向的连接,只中止读或只中止写。
注意:
如果有多个进程共享一个套接字,close 每被调用一次,计数减 1 ,直到计数为 0 时,也就是所用进程都调用了 close,套接字将被释放。
在多进程中如果一个进程调用了 shutdown(sfd, SHUT_RDWR) 后,其它的进程将无法进行通信。 但如果一个进程 close(sfd) 将不会影响到其它进程。
SHUT_RD(0):关闭连接的“读”这个方向,对该套接字进行读操作直接返回 EOF。从数据角度来看,套接字上接收缓冲区已有的数据将被丢弃,如果再有新的数据流到达,会对数据进行 ACK,然后悄悄地丢弃。也就是说,对端还是会接收到 ACK,在这种情况下根本不知道数据已经被丢弃了。
**SHUT_WR(1):关闭连接的“写”这个方向,这就是常被称为”半关闭“的连接。**此时,不管套接字引用计数的值是多少,都会直接关闭连接的写方向。套接字上发送缓冲区已有的数据将被立即发送出去,并发送一个 FIN 报文给对端。应用程序如果对该套接字进行写操作会报错。
SHUT_RDWR(2):相当于 SHUT_RD 和 SHUT_WR 操作各一次,关闭套接字的读和写两个方向。
3.8.2 端口复用

端口复用最常用的用途是:
- 防止服务器重启时之前绑定的端口还未释放(进程处于TIME_WAIT状态占用端口号)
- 程序突然退出而系统没有释放端口
#include <sys/types.h>
#include <sys/socket.h>
// 设置套接字的属性(不仅仅能设置端口复用)
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
参数:
- sockfd : 要操作的文件描述符
- level : 级别 - SOL_SOCKET (端口复用的级别)
- optname : 选项的名称
- SO_REUSEADDR // 允许重用本地地址 Unix网络编程 151
- SO_REUSEPORT // 允许重用本地端口
- optval : 端口复用的值(整形)
- 1 : 可以复用
- 0 : 不可以复用
- optlen : optval参数的大小
端口复用,设置的时机是在服务器绑定端口之前。
先 setsockopt();
后 bind();
常看网络相关信息的命令
netstat
参数:
-a 所有的socket
-p 显示正在使用socket的程序的名称
-n 直接使用IP地址,而不通过域名服务器
3.9 IO多路复用
I/O 多路复用使得程序能同时监听多个文件描述符,能够提高程序的性能,Linux 下实现 I/O 多路复用的 系统调用主要有 select、poll 和 epoll。
阻塞等待 read/writ 阻塞,只能进行一个通信
好处:不占用CPU宝贵的时间片
缺点:同一时刻只能处理一个操作, 效率低
3.9.1 BIO模型
多线程或者多进程解决 用多线程或者多进程实现并发
来一个连接就创建一个线程处理
缺点:
- 线程或者进程会消耗资源
- 线程或进程调度消耗CPU资源

3.9.2 NIO模型
非阻塞, 忙轮询
优点: 提高了程序的执行效率
缺点: 需要占用更多的CPU和系统资源 (多次循环询问判断)
使用IO多路转接技术select/poll/epoll
3.9.4 select/poll I/O多路转接

select代收员比较懒,她只会告诉你有几个快递到了,但是哪个快递,你需要挨个遍历一遍。
select主旨思想:
- 首先要构造一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
- 调用一个系统函数,监听该列表中的文件描述符,直到这些描述符中的一个或者多个进行I/O 操作时,该函数才返回。
a.这个函数是阻塞
b.函数对文件描述符的检测的操作是由内核完成的
- 在返回时,它会告诉进程有多少(哪些)描述符要进行I/O操作。
// sizeof(fd_set) = 128字节 1024个标准位
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/select.h>
int select(int nfds, fd_set readfds, fd_set writefds, fd_set exceptfds, struct timeval timeout);
- 参数:
- nfds : 委托内核检测的最大文件描述符的值 + 1(索引从0开始,数量是对应的索引+1)
- readfds : 要检测的文件描述符的读的集合,委托内核检测哪些文件描述符
的读的属性
- 一般检测读操作
- 对应的是对方发送过来的数据,因为读是被动的接收数据,检测
的就是读缓冲区
- 是一个传入传出参数
- writefds : 要检测的文件描述符的写的集合,委托内核检测哪些文件描述符
的写的属性
- 委托内核检测写缓冲区是不是还可以写数据(不满的就可以写)
- exceptfds : 检测发生异常的文件描述符的集合
- timeout : 设置的超时时间
struct timeval {
long tv_sec; / seconds /
long tv_usec; / microseconds /
};
- NULL : 永久阻塞,直到检测到了文件描述符有变化
- tv_sec = 0 tv_usec = 0, 不阻塞
- tv_sec > 0 tv_usec > 0, 阻塞对应的时间
- 返回值 :
- -1 : 失败
- >0 (n) : 检测的集合中有n个文件描述符发生了变化 **
// 将参数文件描述符fd对应的标志位设置为0 ** 删除监听
void FD_CLR(int fd, fd_set *set);
// 判断fd对应的标志位是0还是1, 返回值 : fd对应的标志位的值,0,返回0, 1,返回1
int FD_ISSET(int fd, fd_set *set);
// 将参数文件描述符fd 对应的标志位,设置为1 添加监听
void FD_SET(int fd, fd_set *set);
// fd_set一共有1024 bit, 全部初始化为0
void FD_ZERO(fd_set *set);


select()的缺点
缺点:
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- **select支持的文件描述符数量太小了,默认是1024 ** fd_set只有128字节,1024位标志位
- fds集合不能重用,每次都需要重置, 需要定义临时tem fd_set
poll
用一个结构体去解决select中fds集合不能复用的问题(有events和revents),并且可以创建一个pollfd数组去维护多个文件描述符的监听,可自定义数量。

#include <poll.h>
struct pollfd {
int fd; /* 委托内核检测的文件描述符 /
short events; / 委托内核检测文件描述符的什么事件 /
short revents; / 文件描述符实际发生的事件 */
};
struct pollfd myfd;
myfd.fd = 5;
myfd.events = POLLIN | POLLOUT; // 检测读数据和写事件
int poll(struct pollfd *fds, nfds_t nfds, int timeout); // pollfd能够重用,传入和修改的变量不是同一个
- 参数:
- fds : 是一个struct pollfd 结构体数组,这是一个需要检测的文件描述符的集合
- nfds : 这个是第一个参数数组中最后一个有效元素的下标 + 1
- timeout : 阻塞时长
0 : 不阻塞
-1 : 阻塞,当检测到需要检测的文件描述符有变化,解除阻塞
>0 : 阻塞的时长
- 返回值:
-1 : 失败
>0(n) : 成功,n表示检测到集合中有n个文件描述符发生变化
#include <stdio.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <poll.h>
int main() {
// 创建socket
int lfd = socket(PF_INET, SOCK_STREAM, 0);
struct sockaddr_in saddr;
saddr.sin_port = htons(9999);
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = INADDR_ANY;
// 绑定
bind(lfd, (struct sockaddr *)&saddr, sizeof(saddr));
// 监听
listen(lfd, 8);
// 初始化检测的文件描述符数组
struct pollfd fds[1024];
for(int i = 0; i < 1024; i++) {
fds[i].fd = -1;
fds[i].events = POLLIN; // 检测读事件
}
fds[0].fd = lfd;
int nfds = 0;
while(1) {
// 调用poll系统函数,让内核帮检测哪些文件描述符有数据
int ret = poll(fds, nfds + 1, -1);
if(ret == -1) {
perror("poll");
exit(-1);
} else if(ret == 0) {
continue;
} else if(ret > 0) {
// 说明检测到了有文件描述符的对应的缓冲区的数据发生了改变
if(fds[0].revents & POLLIN) {
// 表示有新的客户端连接进来了
struct sockaddr_in cliaddr;
int len = sizeof(cliaddr);
int cfd = accept(lfd, (struct sockaddr *)&cliaddr, &len);
// 将新的文件描述符加入到集合中
for(int i = 1; i < 1024; i++) {
if(fds[i].fd == -1) { //第一个可用的
fds[i].fd = cfd;
fds[i].events = POLLIN; // 检测读事件
// 更新最大的文件描述符的索引
nfds = nfds > i ? nfds : i;
break;
}
}
}
for(int i = 1; i <= nfds; i++) { //i 是数组的索引
if(fds[i].revents & POLLIN) {
// 说明这个文件描述符对应的客户端发来了数据
char buf[1024] = {0};
int len = read(fds[i].fd, buf, sizeof(buf));
if(len == -1) {
perror("read");
exit(-1);
} else if(len == 0) {
printf("client closed...\n");
close(fds[i].fd);
fds[i].fd = -1;
} else if(len > 0) {
printf("read buf = %s\n", buf);
write(fds[i].fd, buf, strlen(buf) + 1);
}
}
}
}
}
close(lfd);
return 0;
}
3.9.5 epoll I/O多路转接

epoll代收快递员很勤快,她不仅会告诉你有几个快递到了,还会告诉你是哪个快递公司的快递
#include <sys/epoll.h>
// 创建一个新的epoll实例。在内核中创建了一个数据,这个数据中有两个比较重要的数据,一个是需要检测的文件描述符的信息(红黑树),还有一个是就绪列表,存放检测到数据发生改变的文件描述符信息(双向链表)。
int epoll_create(int size);
- 参数:
size : 目前没有意义了。随便写一个数,必须大于0
- 返回值:
-1 : 失败
> 0 : 文件描述符,操作epoll实例的
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {<br /> uint32_t events; /* Epoll events */<br /> epoll_data_t data; /* User data variable */<br /> };<br /> 常见的Epoll检测事件:<br /> - EPOLLIN<br /> - EPOLLOUT<br /> - EPOLLERR<br /> - EPOLLET<br />// 对epoll实例进行管理:**添加**文件描述符信息,**删除**信息,**修改**信息<br />int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);<br /> - 参数:<br /> - epfd : epoll实例对应的文件描述符 **epoll_create的返回值**<br /> - op : 要进行什么操作<br /> EPOLL_CTL_ADD: 添加<br /> EPOLL_CTL_MOD: 修改<br /> EPOLL_CTL_DEL: 删除<br /> - fd : 要检测的文件描述符<br /> - event : 检测文件描述符什么事情 读还是写 <br />// 检测函数<br />int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);<br /> - 参数:<br /> - epfd : epoll实例对应的文件描述符<br /> - events : **传出参数**,保存了发送了变化的文件描述符的信息<br /> - maxevents : 第二个参数结构体**数组的大小**<br /> - timeout : 阻塞时间<br /> - 0 : 不阻塞<br /> - -1 : 阻塞,直到检测到fd数据发生变化,解除阻塞<br /> - > 0 : 阻塞的时长(毫秒)<br /> - 返回值:<br /> - 成功,返回发生变化的文件描述符的个数 > 0<br /> - 失败 -1
#include <sys/epoll.h>
#include<stdio.h>
#include<stdlib.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<string.h>
int main(){
//创建套接字
int lfd = socket(AF_INET,SOCK_STREAM,NULL);
//绑定ip端口
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_port = htons(9999);
saddr.sin_addr.s_addr = INADDR_ANY;
bind(lfd,(struct sockaddr*) &saddr,sizeof(saddr));
listen(lfd,8);
//创建epoll实例
int epfd = epoll_create(100);
struct epoll_event epev;
epev.data.fd = lfd;
epev.events = EPOLLIN;
epoll_ctl(epfd,EPOLL_CTL_ADD,lfd,&epev);
//events结构体存放监听到的文件描述符
struct epoll_event epevs[1024];
printf("========服务器已经启动========\n");
while (1)
{
int ret = epoll_wait(epfd,epevs,1024,-1);
if(ret==-1){
perror("epoll_wait");
exit(-1);
}
for (int i = 0; i < ret; i++)
{
int curfd = epevs[i].data.fd;
if(curfd==lfd){
//有客户接进来accept
printf("********连接客户端成功*********\n");
struct sockaddr_in caddr;
unsigned int len = sizeof(caddr);
int cfd = accept(lfd,(struct sockaddr *)&caddr,&len);
//获取客户端一些信息
//将ip转换为点分十进制
char ipBuf[16];
inet_ntop(AF_INET,&caddr.sin_addr.s_addr,ipBuf,sizeof(ipBuf));
unsigned short cport = ntohs(caddr.sin_port);
printf("client ip is %s, port is %d\n",ipBuf,cport);
//添加epoll监听
epev.data.fd = cfd;
epev.events = EPOLLIN;
epoll_ctl(epfd,EPOLL_CTL_ADD,cfd,&epev);
}else{
//客户有信息发送过来,进行通信
char buf[1024]= {0};
int len = read(curfd,buf,sizeof(buf));
if(len==-1){
perror("read");
exit(-1);
}else if(len==0){
printf("客户端断开连接了... \n");
epoll_ctl(epfd,EPOLL_CTL_DEL,curfd,NULL);
close(curfd);
}else if(len>0){
printf("recv client data: %s\n",buf);
char * data = "hello i am server";
write(curfd, data, strlen(data)+1);
}
}
}
}
close(epfd);
close(lfd);
return 0;
}
3.9.6 Epoll 的工作模式:
LT 模式 (水平触发)
假设委托内核检测读事件 -> 检测fd的读缓冲区
读缓冲区有数据 - > epoll检测到了会给用户通知
a.用户不读数据,数据一直在缓冲区,epoll 会一直通知
b.用户只读了一部分数据,epoll会通知
c.缓冲区的数据读完了,不通知
LT(level - triggered)是缺省的工作方式,并且同时支持 block 和 no-block socket。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的 fd 进行 IO 操 作。如果你不作任何操作,内核还是会继续通知你的。
ET 模式(边沿触发)
假设委托内核检测读事件 -> 检测fd的读缓冲区
** 读缓冲区有数据 - > epoll检测到了会给用户通知**
** a.用户不读数据,数据一致在缓冲区中,epoll下次检测的时候就不通知了**
** b.用户只读了一部分数据,epoll不通知**
** c.缓冲区的数据读完了,不通知**
ET(edge - triggered)是高速工作方式,只支持 no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪, 并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了。但是请注意,如果一直不对这个 fd 作 IO 操作(从而导致它再次变成 未就绪),内核不会发送更多的通知(only once)。
ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。epoll 工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写 操作把处理多个文件描述符的任务饿死。
只通知一次
epev.events = EPOLLIN | EPOLLET
4. UDP 通信
4.1 udp API

#include <sys/types.h>
#include <sys/socket.h>
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen);
- 参数:
- sockfd : 通信的fd
- buf : 要发送的数据
- len : 发送数据的长度
- flags : 0
- dest_addr : 通信的另外一端的地址信息 **
- addrlen : 地址的内存大小
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
- 参数:
- sockfd : 通信的fd
- buf : 接收数据的数组
- len : 数组的大小
- flags : 0
- src_addr : 用来保存另外一端**的地址信息,不需要可以指定为NULL
- a
- ddrlen : 地址的内存大小
#include<arpa/inet.h>
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
int main(){
//创建一个udp通信的socket
int fd = socket(PF_INET,SOCK_DGRAM,0);
//绑定
struct sockaddr_in addr;
addr.sin_family = PF_INET;
addr.sin_addr.s_addr = INADDR_ANY;
addr.sin_port = htons(9999);
bind(fd,(struct sockaddr *)&addr,sizeof(addr));
char buf[128]={0};
char ipbuf [16];
printf("========服务器已经启动========\n");
while (1)
{
//接收客户端数据
struct sockaddr_in caddr;
unsigned int len = sizeof(caddr);
recvfrom(fd,buf,sizeof(buf),0,(struct sockaddr*)&caddr,&len);
printf("client IP %s, port %d\n",
inet_ntop(AF_INET, &caddr.sin_addr.s_addr, ipbuf, sizeof(ipbuf)),
ntohs(caddr.sin_port));
printf("client say: %s\n",buf);
char * data = "i am server";
//发送数据
sendto(fd,data,strlen(data)+1,0,(struct sockaddr*) &caddr,sizeof(caddr));
}
close(fd);
return 0;
}
#include<arpa/inet.h>
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
int main(){
//创建套接字
int fd = socket(AF_INET,SOCK_DGRAM,0);
if(fd==-1){
perror("socket");
exit(-1);
}
//定义请求的服务器地址端口
struct sockaddr_in saddr;
saddr.sin_family = AF_INET;
saddr.sin_port = htons(9999);
inet_pton(AF_INET,"127.0.0.1",&saddr.sin_addr.s_addr);
unsigned int len = sizeof(saddr);
int num = 0;
char buf[128] = {0};
char rbuf[128]={0};
while (1)
{
sprintf(buf,"hello i am client: %d\n",num++);
int ret = sendto(fd,buf,strlen(buf)+1,0,(struct sockaddr *)&saddr,sizeof(saddr));
if(ret==-1){
perror("sendto");
exit(-1);
}
printf("%d",ret);
recvfrom(fd,rbuf,sizeof(rbuf),0,NULL,NULL);
printf("server say: %s\n",rbuf);
sleep(1);
}
close(fd);
return 0;
}
4.2 广播
向子网中多台计算机发送消息,并且子网中所有的计算机都可以接收到发送方发送的消息,每个广 播消息都包含一个特殊的IP地址,这个IP中子网内主机标志部分的二进制全部为1。
a.只能在局域网中使用。
b.客户端需要绑定服务器广播使用的端口,才可以接收到广播消息。
// 设置广播属性的函数
int setsockopt(int sockfd, int level, int optname,const void *optval, socklen_t
optlen);
- sockfd : 文件描述符
- level : SOL_SOCKET
- optname : SO_BROADCAST
- optval : int类型的值,为1表示允许广播
- optlen : optval的大小
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main() {
// 1.创建一个通信的socket
int fd = socket(PF_INET, SOCK_DGRAM, 0);
if(fd == -1) {
perror("socket");
exit(-1);
}
// 2.设置广播属性
int op = 1;
setsockopt(fd, SOL_SOCKET, SO_BROADCAST, &op, sizeof(op));
// 服务端是发送数据的无需特定绑定,自动绑定 客户端绑定,负责接收
// 3.创建一个广播的地址
struct sockaddr_in cliaddr;
cliaddr.sin_family = AF_INET;
cliaddr.sin_port = htons(9999);
//IP中子网内主机标志部分的二进制全部为1,即为 192.168.193.255
inet_pton(AF_INET, "192.168.193.255", &cliaddr.sin_addr.s_addr);
// 4.通信
int num = 0;
while(1) {
char sendBuf[128];
sprintf(sendBuf, "hello, client....%d\n", num++);
// 发送数据
sendto(fd, sendBuf, strlen(sendBuf) + 1, 0, (struct sockaddr *)&cliaddr, sizeof(cliaddr));
printf("广播的数据:%s\n", sendBuf);
sleep(1);
}
close(fd);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main() {
// 1.创建一个通信的socket
int fd = socket(PF_INET, SOCK_DGRAM, 0);
if(fd == -1) {
perror("socket");
exit(-1);
}
struct in_addr in;
// 2.客户端绑定本地的IP和端口
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(9999);
addr.sin_addr.s_addr = INADDR_ANY;
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
if(ret == -1) {
perror("bind");
exit(-1);
}
// 3.通信
while(1) {
char buf[128];
// 接收数据
int num = recvfrom(fd, buf, sizeof(buf), 0, NULL, NULL);
printf("server say : %s\n", buf);
}
close(fd);
return 0;
}
4.3 组播(多播)
单播地址标识单个 IP 接口,广播地址标识某个子网的所有 IP 接口,多播地址标识一组 IP 接口。 单播和广播是寻址方案的两个极端(要么单个要么全部),多播则意在两者之间提供一种折中方案。多播数据报只应该由对它感兴趣的接口接收,也就是说由运行相应多播会话应用系统的主机上的接口接收。另外,广播一般局限于局域网内使用,而多播则既可以用于局域网,也可以跨广域网使用。
a.组播既可以用于局域网,也可以用于广域网
b.客户端需要加入多播组,才能接收到多播的数据
IP 多播通信必须依赖于 IP 多播地址,在 IPv4 中它的范围从 224.0.0.0 到 239.255.255.255 , 并被划分为局部链接多播地址、预留多播地址和管理权限多播地址三类:

int setsockopt(int sockfd, int level, int optname,const void optval,socklen_t optlen);
// 服务器设置多播的信息,外出接口 !
- level : IPPROTO_IP
- optname : IP_MULTICAST_IF
- optval : struct in_addr
// 客户端加入到多播组:
- level : IPPROTO_IP
- optname : IP_ADD_MEMBERSHIP
- optval : struct ip_mreq
struct ip_mreq
{
/ IP multicast address of group. /
struct in_addr imr_multiaddr; // 组播的IP地址
/ Local IP address of interface. */
struct in_addr imr_interface; // 本地的IP地址
};
typedef uint32_t in_addr_t;
struct in_addr
{
in_addr_t s_addr;
};
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main() {
// 1.创建一个通信的socket
int fd = socket(PF_INET, SOCK_DGRAM, 0);
if(fd == -1) {
perror("socket");
exit(-1);
}
// 2.设置多播的属性,设置外出接口
struct in_addr imr_multiaddr;
// 初始化多播地址
inet_pton(AF_INET, "239.0.0.10", &imr_multiaddr.s_addr);
setsockopt(fd, IPPROTO_IP, IP_MULTICAST_IF, &imr_multiaddr, sizeof(imr_multiaddr));
// 3.初始化客户端的地址信息
struct sockaddr_in cliaddr;
cliaddr.sin_family = AF_INET;
cliaddr.sin_port = htons(9999);
inet_pton(AF_INET, "239.0.0.10", &cliaddr.sin_addr.s_addr);
// 3.通信
int num = 0;
while(1) {
char sendBuf[128];
sprintf(sendBuf, "hello, client....%d\n", num++);
// 发送数据
sendto(fd, sendBuf, strlen(sendBuf) + 1, 0, (struct sockaddr *)&cliaddr, sizeof(cliaddr));
printf("组播的数据:%s\n", sendBuf);
sleep(1);
}
close(fd);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main() {
// 1.创建一个通信的socket
int fd = socket(PF_INET, SOCK_DGRAM, 0);
if(fd == -1) {
perror("socket");
exit(-1);
}
struct in_addr in;
// 2.客户端绑定本地的IP和端口
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(9999);
addr.sin_addr.s_addr = INADDR_ANY;
int ret = bind(fd, (struct sockaddr *)&addr, sizeof(addr));
if(ret == -1) {
perror("bind");
exit(-1);
}
struct ip_mreq op;
inet_pton(AF_INET, "239.0.0.10", &op.imr_multiaddr.s_addr); // 多播地址
op.imr_interface.s_addr = INADDR_ANY; // 本地地址
// 加入到多播组
setsockopt(fd, IPPROTO_IP, IP_ADD_MEMBERSHIP, &op, sizeof(op));
// 3.通信
while(1) {
char buf[128];
// 接收数据
int num = recvfrom(fd, buf, sizeof(buf), 0, NULL, NULL);
printf("server say : %s\n", buf);
}
close(fd);
return 0;
}
5. 本地套接字
本地套接字的作用:本地的进程间通信
有关系的进程间的通信
没有关系的进程间的通信
本地套接字实现流程和网络套接字类似,一般采用TCP的通信流程。
// 本地套接字通信的流程 - tcp
// 服务器端
1. 创建监听的套接字
int lfd = socket(AF_UNIX/AF_LOCAL, SOCK_STREAM, 0); // TCP 和 本地套接字地址格式
2. 监听的套接字绑定本地的套接字文件 -> server端
struct sockaddr_un addr;
// 绑定成功之后,指定的sun_path中的套接字文件会自动生成。
bind(lfd, addr, len);
3. 监听
listen(lfd, 100);
4. 等待并接受连接请求
struct sockaddr_un cliaddr;
int cfd = accept(lfd, &cliaddr, len);
5. 通信
接收数据:read/recv
发送数据:write/send
6. 关闭连接
close();
// 客户端的流程
1. 创建通信的套接字
int fd = socket(AF_UNIX/AF_LOCAL, SOCK_STREAM, 0);
2. 监听的套接字绑定本地的IP 端口
struct sockaddr_un addr;
// 绑定成功之后,指定的sun_path中的套接字文件会自动生成。
bind(lfd, addr, len);
3. 连接服务器
struct sockaddr_un serveraddr;
connect(fd, &serveraddr, sizeof(serveraddr));
4. 通信
接收数据:read/recv
发送数据:write/send
5. 关闭连接
close();
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/un.h>
int main() {
unlink("server.sock"); // 先删除server.sock文件
// 1.创建监听的套接字
int lfd = socket(AF_LOCAL, SOCK_STREAM, 0);
if(lfd == -1) {
perror("socket");
exit(-1);
}
// 2.绑定本地套接字文件
struct sockaddr_un addr;
addr.sun_family = AF_LOCAL;
strcpy(addr.sun_path, "server.sock");
int ret = bind(lfd, (struct sockaddr *)&addr, sizeof(addr)); //绑定成功就会生成sever.sock
if(ret == -1) {
perror("bind");
exit(-1);
}
// 3.监听
ret = listen(lfd, 100);
if(ret == -1) {
perror("listen");
exit(-1);
}
// 4.等待客户端连接
struct sockaddr_un cliaddr;
int len = sizeof(cliaddr);
int cfd = accept(lfd, (struct sockaddr *)&cliaddr, &len);
if(cfd == -1) {
perror("accept");
exit(-1);
}
printf("client socket filename: %s\n", cliaddr.sun_path);
// 5.通信
while(1) {
char buf[128];
int len = recv(cfd, buf, sizeof(buf), 0);
if(len == -1) {
perror("recv");
exit(-1);
} else if(len == 0) {
printf("client closed....\n");
break;
} else if(len > 0) {
printf("client say : %s\n", buf);
send(cfd, buf, len, 0);
}
}
close(cfd);
close(lfd);
return 0;
}
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/un.h>
int main() {
unlink("client.sock"); // 先删除client.sock文件
// 1.创建套接字
int cfd = socket(AF_LOCAL, SOCK_STREAM, 0);
if(cfd == -1) {
perror("socket");
exit(-1);
}
// 2.绑定本地套接字文件
struct sockaddr_un addr;
addr.sun_family = AF_LOCAL;
strcpy(addr.sun_path, "client.sock"); // 客户端生成的套接字文件
int ret = bind(cfd, (struct sockaddr *)&addr, sizeof(addr));
if(ret == -1) {
perror("bind");
exit(-1);
}
// 3.连接服务器
struct sockaddr_un seraddr;
seraddr.sun_family = AF_LOCAL;
strcpy(seraddr.sun_path, "server.sock");
ret = connect(cfd, (struct sockaddr *)&seraddr, sizeof(seraddr));
if(ret == -1) {
perror("connect");
exit(-1);
}
// 4.通信
int num = 0;
while(1) {
// 发送数据
char buf[128];
sprintf(buf, "hello, i am client %d\n", num++);
send(cfd, buf, strlen(buf) + 1, 0);
printf("client say : %s\n", buf);
// 接收数据
int len = recv(cfd, buf, sizeof(buf), 0);
if(len == -1) {
perror("recv");
exit(-1);
} else if(len == 0) {
printf("server closed....\n");
break;
} else if(len > 0) {
printf("server say : %s\n", buf);
}
sleep(1);
}
close(cfd);
return 0;
}
socket编程中recv()和read()的使用与区别:
recv和read相似,都可用来接收sockfd发送的数据,但recv比read多了一个参数,也就是第四个参数,它可以指定标志来控制如何接收数据。
1、recv()
原型:ssize_t recv(int sockfd, void *buf, size_t nbytes, int flags);
返回值:返回数据的字节长度;
若无可用数据或对等方已经按序结束,返回0;
若出错,返回-1.(APUE说法)
对于SOCK_STREAM套接字来讲,recv接收的数据可以比预期的少,recv的第四个参数可以选MSG_WAITALL标志来阻止这种行为,当flags为MSG_WAITALL时,recv会阻塞直到所指定的长度nbytes字节的数据全部返回,recv才会返回。
正常情况下recv 是会等待直到读取到nbytes长度的数据,但是这里的MSG_WAITALL也只是尽量读全,在有中断的情况下recv 还是可能会被打断,造成没有读完指定的nbytes的长度。使用这个标志recv会在以下三种情况发生时返回:
- 当读到了指定的字节时,函数正常返回.返回值等于nbytes;
- 当读到了文件的结尾时,函数正常返回.返回值小于nbytes(不知道对于SOCK_STREAM字节流是否也是这样);
- 当操作发生错误时,返回-1,且设置错误为相应的错误号(errno)。
recv一次能接收的字节数nbytes应该与socket接收缓冲区的大小有关,当使用的套接字为SOCK_STREAM类型时,不能保证一次recv就能读取sockfd发送的所有数据,因此需要重复调用直到它返回0,可以采用如下方法实现:
while((n = recv(sockfd, buf, nbytes, 0)) > 0) {
write(STDOUT_FILENO, buf, n);
}
对于SOCK_DGRAM和SOCK_SEQPACKET套接字,MSG_WAITALL并不改变什么,因为这些基于报文的套接字类型一次读取就返回整个报文。
如果flags为0,则recv和read一样。
2、ssize_t read(inf fd, void *buf, size_t bnytes);
在阻塞的tcp socket上使用read读取的数据长度和recv一样会发生返回值比指定长度短的情况。引用《UNIX网络编程卷一 套接字联网API》3.9中的说法:
字节流套接口(如tcp套接口)上的read和write函数所表现的行为不同于通常的文件IO。字节流套接口上的读或写、输入或输出的字节数可能比要求的数量少。
但这不是错误状况,原因是内核中套接口的缓冲区可能已达到了极限。此时所需的是调用者再次调用read或write函数,以输入或输出剩余的字节。
可以使用readn函数来实现循环读取以解决这个问题:
ssize_t /* Read "n" bytes from a descriptor. */
readn(int fd, void *vptr, size_t n)
{
size_t nleft;
ssize_t nread;
char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR) {
nread = 0; /* and call read() again */
} else {
return(-1);
}
} else if (nread == 0) {
break; /* EOF */
}
nleft -= nread;
ptr += nread;
}
return(n - nleft); /* return >= 0 */
}
五、项目实战与总结
1.阻塞/非阻塞、同步/异步(网络IO)
一个典型的网络IO接口调用,分为两个阶段,分别是“数据就绪” 和 “数据读写”,数据就绪阶段分为阻塞和非阻塞,表现得结果就是,阻塞当前线程或是直接返回。
同步表示A向B请求调用一个网络IO接口时(或者调用某个业务逻辑API接口时),数据的读写都是由请求方A自己来完成的(不管是阻塞还是非阻塞);异步表示A向B请求调用一个网络IO接口时 (或者调用某个业务逻辑API接口时),向B传入请求的事件以及事件发生时通知的方式,A就可以处理其它逻辑了,当B监听到事件处理完成后,会用事先约定好的通知方式,通知A处理结果。
总结:1、当接受缓存中无数据时:如果用户程序一直等待直到新数据到来,是阻塞。如果程序不等待,继续向下执行,是非阻塞。2、当缓存中有数据时:对该数据的读写操作由用户程序自己来完成,是同步;如果读写操作是别人帮忙完成的,是异步。
2. Unix/Linux上的五种IO模型
a.阻塞 blocking
阻塞、非阻塞 —— 文件描述符的属性
调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作。
b.非阻塞 non-blocking(NIO)
非阻塞等待,每隔一段时间就去检测IO事件是否就绪。**没有就绪就可以做其他事。非阻塞I/O执行系统调 用总是立即返回,不管事件是否已经发生,若事件没有发生,则返回-1,此时可以根据 errno 区分这两种情况,**对于accept,recv 和 send,事件未发生时,errno 通常被设置成 EAGAIN。
无须将所有时间用来等待数据
c.IO复用(IO multiplexing)
一次检测多个客户的事件,依次处理
Linux 用 select/poll/epoll 函数实现 IO 复用模型,这些函数也会使进程阻塞,但是和阻塞IO所不同的是 这些函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检测。直到有数据可读或可写时,才真正调用IO操作函数。
d.信号驱动(signal-driven)
Linux 用套接口进行信号驱动 IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO事件就绪,进 程收到SIGIO 信号,然后处理 IO 事件。
内核在第一个阶段是异步,在第二个阶段是同步;与非阻塞IO的区别在于它提供了消息通知机制,不需要用户进程不断的轮询检查,减少了系统API的调用次数,提高了效率。
e.异步(asynchronous)
Linux中,可以调用 aio_read 函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。
内核提前把数据准备好了,不用再用read读取数据
/* Asynchronous I/O control block. */
struct aiocb
{
int aio_fildes; /* File desriptor. */
int aio_lio_opcode; /* Operation to be performed. */
int aio_reqprio; /* Request priority offset. */
volatile void *aio_buf; /* Location of buffer. */
size_t aio_nbytes; /* Length of transfer. */
struct sigevent aio_sigevent; /* Signal number and value. */
/* Internal members. */
struct aiocb *__next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */
#endif
char __glibc_reserved[32];
};
IO多路复用是内核们监听多个文件描述符,阻塞在监听的函数比如select, 拷贝数据也是阻塞的,多路复用只是防止进程在某个io阻塞后,不能及时处理其他io的事件。信号驱动则是先登记信号处理函数,当数据准备完毕后由内核发送信号给进程,让进程处理。信号驱动不阻塞在数据准备过程,但阻塞在数据拷贝,所以两者都是同步IO,
3.Web Server(网页服务器)
3.1 简介
一个 Web Server 就是一个服务器软件(程序),或者是运行这个服务器软件的硬件(计算机)。其主 要功能是通过** HTTP 协议**与客户端(通常是浏览器(Browser))进行通信,来接收,存储,处理来自客户端的 HTTP 请求,并对其请求做出 HTTP 响应,返回给客户端其请求的内容(文件、网页等)或返回一个 Error 信息。
通常用户使用 Web 浏览器与相应服务器进行通信。在浏览器中键入“域名”或“IP地址:端口号”,浏览器则先将你的域名解析成相应的 IP 地址或者直接根据你的IP地址向对应的 Web 服务器发送一个 HTTP 请求。这一过程首先要通过 TCP 协议的三次握手建立与目标 Web 服务器的连接,然后HTTP协议生成针对目标 Web 服务器的 HTTP 请求报文,通过 TCP、IP 等协议发送到目标 Web 服务器上。
3.2 HTTP协议(应用层的协议)
3.2.1 http协议简介
超文本传输协议(Hypertext Transfer Protocol,HTTP)是一个简单的请求 - 响应协议,它通常运行在 TCP 之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以 ASCII 形式给出;而消息内容则具有一个类似 MIME 的格式。HTTP是万维网的数据通信的基础。
HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万 维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的 RFC 2616,定 义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1。
3.2.2 http协议概述
HTTP 是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览 器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如 HTML 文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管 TCP/IP 协议是互联网上最流行的应用,HTTP 协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP 假定其下层协议提供可靠的传输。因 此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在 TCP/IP 协议族使用 TCP 作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的 TCP 连接。HTTP 服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比 如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
3.2.3 工作原理(流程)
HTTP 协议定义 Web 客户端如何从 Web 服务器请求 Web 页面,以及服务器如何把 Web 页面传送给客 户端。HTTP 协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方 法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版 本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
- 客户端连接到 Web 服务器
一个HTTP客户端,通常是浏览器,与 Web 服务器的 HTTP 端口(默认为 80 )建立一个 TCP 套接 字连接。例如,http://www.baidu.com。(URL)
- 发送 HTTP 请求
通过 TCP 套接字,客户端向 Web 服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据 4 部分组成。
- 服务器接受请求并返回 HTTP 响应
Web 服务器解析请求,定位请求资源。服务器将资源复本写到 TCP 套接字,由客户端读取。一个 响应由状态行、响应头部、空行和响应数据 4 部分组成。
- 释放连接 TCP 连接
若 connection 模式为 close,则服务器主动关闭 TCP连接,客户端被动关闭连接,释放 TCP 连 接;若connection 模式为 keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
- 客户端浏览器解析 HTML 内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的 HTML 文档和文档的字符集。客户端浏览器读取响应数据 HTML,根据 HTML 的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立 TCP 连接;
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立 TCP 连接;
- 释放 TCP 连接;
- 浏览器将该 HTML 文本并显示内容。

3.2.4 HTTP 请求报文格式

GET / HTTP/1.1 —— 请求行
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; ×64; rv:86.0)Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,imagelwebp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie:BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFEO15A8099199557E; PSTM=1614320692;BD_UPN=13314752;BDORZ=FFFB88E999055A3F8A630C64834BD6DO;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782;BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alagOlag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=o
3.2.5 HTTP响应报文格式

HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: Oxf3c9743300024ee4
Cache-Control: private
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Fri, 26 Feb 2021 08:44:35GMT
Expires: Fri, 26 Feb 2021 08:44:35GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=13; path=/
Set-Cookie:BD_HOME=1; path=l
Set-Cookie:H_PS_PSSID=33514_33257_33273_31660_33570_26350; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 1614329075128412289017566699583927635684
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
3.2.6 HTTP请求方法
GET和POST区别:
作用
GET用于获取资源,POST用于传输实体主体
参数位置
GET的参数放在URL中,POST的参数存储在实体主体中,并且GET方法提交的请求的URL中的数据做多是2048字节,POST请求没有大小限制。
安全
GET方法因为参数放在URL中,安全性相对于POST较差一些
幂等性
GET方法是具有幂等性的,而POST方法不具有幂等性。这里幂等性指客户端连续发出多次请求,收到的结果都是一样的.
HTTP/1.1 协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
- GET:向指定的资源发出“显示”请求。使用 GET 方法应该只用在读取数据,而不应当被用于产生“副 作用”的操作中,例如在 Web Application 中。其中一个原因是 GET 可能会被网络蜘蛛等随意访问。
- HEAD:与 GET 方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文 部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该 资源的信息”(元信息或称元数据)。
- POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- OPTIONS:这个方法可使服务器传回该资源所支持的所有 HTTP 请求方法。用’*'来代替资源名称, 向 Web 服务器发送 OPTIONS 请求,可以测试服务器功能是否正常运作。
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服 务器的链接(经由非加密的 HTTP 代理服务器)。
3.2.7 HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态 的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
虽然 RFC 2616 中已经推荐了描述状态的短语,例如"200 OK",“404 Not Found”,但是WEB开发者仍 然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。
更多状态码:https://baike.baidu.com/item/HTTP%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin
3.3 服务器编程基本框架
虽然服务器程序种类繁多,但其基本框架都一样,不同之处在于逻辑处理。
| 模块 | 功能 |
|---|---|
| I/O 处理单元 | 处理客户连接,读写网络数据 |
| 逻辑单元 | 业务进程或线程 |
| 网络存储单元 | 数据库、文件或缓存 |
| 请求队列 | 各单元之间的通信方式 |
I/O 处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但是数据的收发不一定在 I/O 处理单元中执行,也可能在 逻辑单元中执行,具体在何处执行取决于事件处理模式。
一个逻辑单元通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给 I/O 处理单元或者直接发送给客户端(具体使用哪种方式取决于事件处理模式)。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并发处理。
网络存储单元可以是数据库、缓存和文件,但不是必须的。
请求队列是各单元之间的通信方式的抽象。I/O 处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竞态条件。请求队列通常被实现为池的一部分。
3.4 两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor 和 Proactor,同步 I/O 模型通常用于实现 Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
3.4.1 Reactor模式
要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步 I/O(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll 内核事件表中注册该 socket 上的写就绪事件。
- 当主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
Reactor 模式的工作流程:
3.4.2 Proactor模式
一般使用异步I/O模式实现
**Proactor 模式将所有 I/O 操作都交给主线程和内核来处理(进行读、写),工作线程仅仅负责业务逻辑。**使用异步 I/O 模型(以 aio_read 和 aio_write 为例)实现的 Proactor 模式的工作流程是:
- 主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置, 以及读操作完成时如何通知应用程序(这里以信号为例)。
- 主线程继续处理其他逻辑。
- 当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据 已经可用。
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求 后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以 及写操作完成时如何通知应用程序。
- 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据 已经发送完毕。
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
Proactor 模式的工作流程:
3.4.3 模拟 Proactor 模式
使用同步 I/O 方式模拟出 Proactor 模式。原理是:主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一”完成事件“。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
使用同步 I/O 模型(以 epoll_wait为例)模拟出的 Proactor 模式的工作流程如下:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更 多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事 件表中注册 socket 上的写就绪事件。
- 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
同步 I/O 模拟 Proactor 模式的工作流程:
3.5 线程池
线程池是由服务器预先创建的一组子线程,线程池中的线程数量应该和 CPU 数量差不多。线程池中的所有子线程都运行着相同的代码*。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程,选择一个已经存在的子线程的代价显然要小得多。至于主线程选择哪个子线程来为新任务服务,则有多种方式:
- 主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round Robin(轮流选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。
- 主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任 务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的”接管权“,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在 工作队列上。

- 空间换时间,浪费服务器的硬件资源,换取运行效率。
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
- 当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配。
- 当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
线程池中的线程数量最直接的限制因素是中央处理器(CPU)的处理器(processors/cores)的数量 N :如果你的CPU是4-cores的,对于CPU密集型的任务(如视频剪辑等消耗CPU计算资源的任务)来 说,那线程池中的线程数量最好也设置为4(或者+1防止其他因素造成的线程阻塞);对于IO密集型的任务,一般要多于CPU的核数,因为线程间竞争的不是CPU的计算资源而是IO,IO的处理一 般较慢,多于cores数的线程将为CPU争取更多的任务,不至在线程处理IO的过程造成CPU空闲导致资源浪费。
3.6 EPOLLONESHOT事件
即使可以使用 ET 模式,一个socket 上的某个事件还是可能被触发多次。这在并发程序中就会引起一个 问题。比如一个线程在读取完某个 socket 上的数据后开始处理这些数据,而在数据的处理过程中该 socket 上又有新数据可读(EPOLLIN 再次被触发),此时另外一个线程被唤醒来读取这些新的数据。于是就出现了两个线程同时操作一个 socket 的局面。一个socket连接在任一时刻都只被一个线程处理,可以使用 epoll 的 EPOLLONESHOT 事件实现。
对于注册了 EPOLLONESHOT 事件的文件描述符,操作系统最多触发其上注册的一个可读、可写或者异 常事件,且只触发一次,除非我们使用 epoll_ctl 函数重置该文件描述符上注册的 EPOLLONESHOT 事件。这样,当一个线程在处理某个 socket 时,其他线程是不可能有机会操作该 socket 的。但反过来思 考,注册了 EPOLLONESHOT 事件的 socket 一旦被某个线程处理完毕, 该线程就**应该立即重置这个 socket 上的 EPOLLONESHOT 事件,**以确保这个 socket 下一次可读时,其 EPOLLIN 事件能被触发,进而让其他工作线程有机会继续处理这个 socket。
3.7 有限状态机
逻辑单元内部的一种高效编程方法:有限状态机(finite state machine)。
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑。如下是一种状态独立的有限状态机:
STATE_MACHINE( Package _pack )
{
PackageType _type = _pack.GetType();
switch( _type )
{
case type_A:
process_package_A( _pack );
break;
case type_B:
process_package_B( _pack );
break;
}
}
这是一个简单的有限状态机,只不过该状态机的每个状态都是相互独立的,即状态之间没有相互转移。 状态之间的转移是需要状态机内部驱动,如下代码:
STATE_MACHINE()
{
State cur_State = type_A;
while( cur_State != type_C )
{
Package _pack = getNewPackage();
switch( cur_State )
{
case type_A:
process_package_state_A( _pack );
cur_State = type_B;
break;
case type_B:
process_package_state_B( _pack );
cur_State = type_C;
break;
}
}
}
该状态机包含三种状态:type_A、type_B 和 type_C,其中 type_A 是状态机的开始状态,type_C 是状 态机的结束状态。状态机的当前状态记录在 cur_State 变量中。在一趟循环过程中,状态机先通过 getNewPackage 方法获得一个新的数据包,然后根据 cur_State 变量的值判断如何处理该数据包。数据包处理完之后,状态机通过给 cur_State 变量传递目标状态值来实现状态转移。那么当状态机进入下一 趟循环时,它将执行新的状态对应的逻辑。
3.8 压力测试
Webbench 是 Linux 上一款知名的、优秀的 web 性能压力测试工具。它是由Lionbridge公司开发。
- 测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。
- 展示服务器的两项内容:每秒钟响应请求数和每秒钟传输数据量。
基本原理:Webbench 首先 fork 出多个子进程,每个子进程都循环做 web 访问测试。子进程把访问的 结果通过pipe 告诉父进程,父进程做最终的统计结果。
webbench -c 1000 -t 30 http://192.168.110.129:10000/index.html
参数:
-c 表示客户端数
-t 表示时间

















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









