









功能介绍:
只通过歌曲名或者歌手去网络上检索,拿到可以播放的URL。
之前做过一个根据拿到歌手和歌曲名然后组合在一起去网上爬数据,然后再解析拿到播放的URL。但是这个还不是很智能,如果只知道歌手或者只知道歌曲名,是否可以到网上去搜索拿到播放的URL,答案是可行的。
实现思路很简单,因为之前已经做过歌手和歌曲名组合去搜歌,现在只需要根据歌手去网上抓歌曲名,然后再传给原来的接口就可以。那么现在要做的就是找到一个可用的搜歌网址。因为平时百度音乐盒用的比较多,试了一下,搜歌还行。
1.确认网址
利用百度音乐盒去搜歌的时候,网页去跳转去另一个页面,比如我搜索周杰伦的歌,它会跳转到下面的网址(http://music.baidu.com/search?key=XXX)

XXX就是你要传的歌名或者歌手,但是由于版权原因,部分结果不能显示,但是还是能搜索到部分结果。那么接下来我们就利用这个网址去实现我们的功能。
2.爬取网址内容
我这里用的是CURL去抓网站的内容,服务器是ubuntu 14.04,刚开始利用libcurl库写了一个模块去访问上面的地址,但是发现爬下来的网页内容很大(约162 KB),但如果直接用CURL命令去下载网页内容,只有几KB,为什么差距这么大?因为code在ubuntu服务器上发的,服务器上没有装Wireshark,那就用tcpdump这个工具去抓包分析。分别抓取命令行模式和code模式的包,如下命令
tcpdump tcp port 80 -n -s 0 -w /tmp/tcp.cap
抓取的结果,再导入Wiresshark去分析,分析结果如下:(上面的是几KB的,下面是100多KB的)
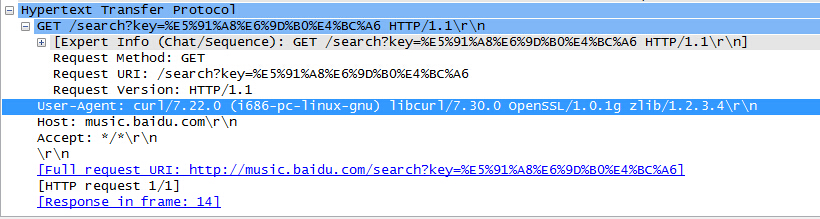
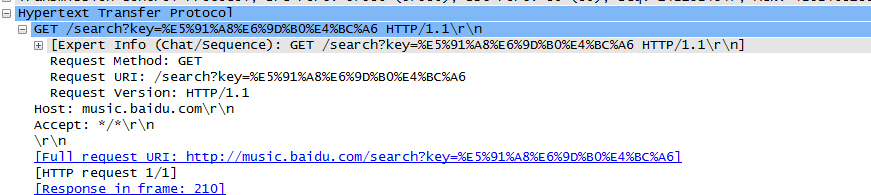
可以很清楚的看出,下载几KB那个,传了一个User-Agent参数,那么找到问题,那就在code中,设置一下libcurl的参数,具体实现如下
int curl_http_get_page(const char* url)
{
CURL *curl;
CURLcode res;
char version[64]={0};
char agent[128]={0};
int lenCurlVersion = 0;
struct curl_slist *chunk = NULL;
res = curl_global_init(CURL_GLOBAL_ALL);
if(CURLE_OK != res)
{
printf("curl_global_init failed \n");
return CURL_RET_FAIL;
}
curl = curl_easy_init();
if(curl)
{
lenCurlVersion = strlen(curl_version());
memcpy(version, curl_version(), lenCurlVersion);
strcpy(agent, "User-Agent: ");
strcat(agent, version);
strcat(agent, "\0");
chunk = curl_slist_append(chunk, agent);
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_HTTPGET, 1);
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, chunk);
curl_easy_setopt( curl, CURLOPT_WRITEFUNCTION, curl_http_write_memory_cb);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void *)&data);
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3);
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L); // display debug msg
curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
return CURL_RET_OK;
}3.解析网页内容
抓下来的网页内容如下
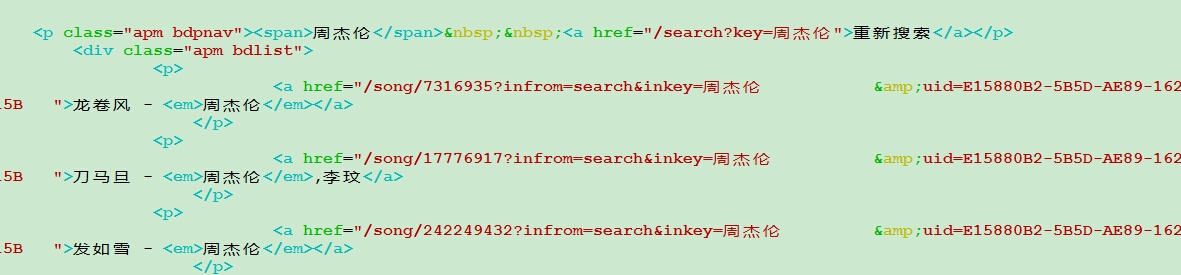
接下来就是解析网页内容,解析方法要么就用开源库,要么就自己暴力破解。刚开始我用libxml2去解析,没有解析出来,后来放弃了,直接暴力破解,抽取我要的内容,然后就可以拿到歌手或者歌曲名。
剩下的就是将歌手和歌曲名字组合起来,利用之前的接口去搜索实现,拿到URL。
具体可以参考下面的地址
[Linux C]百度音乐API实现在线搜歌















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









