







今天遇到了一个问题,使用数据流传输的数据在解析的时候数据错位,想了很久,发现是#pragma pack (n)惹的祸。
首先,解析方使用了编译字节设置,但是在发送方没有使用,于是用同样的结构体解析数据时候,有两个字节被0占用了。后来统一使用,问题解决。
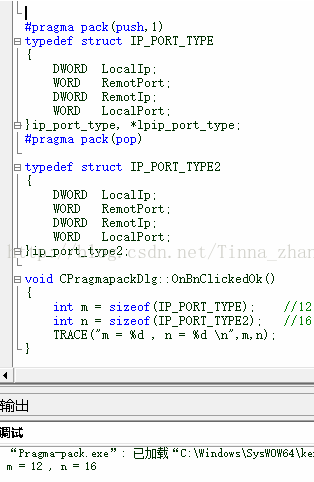
如下图的struct结构体:不使用#pragma pack (1)时候,在解析RemotPort后是没问题的,再解析RemotIp的时候,通过字节转换后,ip地址的前两位是0.0.X.X 原因是WORD不够4字节,编译器自动填了0占位。
这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式。
#pragma pack (n) 作用:C编译器将按照n个字节对齐。
#pragma pack () 作用:取消自定义字节对齐方式。
#pragma pack (push,1) 作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) 作用:恢复对齐状态
因此可见,加入push和pop可以使对齐恢复到原来状态,而不是编译器默认,可以说后者更优,但是很多时候两者差别不大
如:
#pragma pack(push) //保存对齐状态
#pragma pack(4)//设定为4字节对齐
相当于 #pragma pack (push,4)
#pragma pack (1)
作用:调整结构体的边界对齐,让其以一个字节对齐;<使结构体按1字节方式对齐>
首先,解析方使用了编译字节设置,但是在发送方没有使用,于是用同样的结构体解析数据时候,有两个字节被0占用了。后来统一使用,问题解决。
如下图的struct结构体:不使用#pragma pack (1)时候,在解析RemotPort后是没问题的,再解析RemotIp的时候,通过字节转换后,ip地址的前两位是0.0.X.X 原因是WORD不够4字节,编译器自动填了0占位。
这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式。
#pragma pack (n) 作用:C编译器将按照n个字节对齐。
#pragma pack () 作用:取消自定义字节对齐方式。
#pragma pack (push,1) 作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) 作用:恢复对齐状态
因此可见,加入push和pop可以使对齐恢复到原来状态,而不是编译器默认,可以说后者更优,但是很多时候两者差别不大
如:
#pragma pack(push) //保存对齐状态
#pragma pack(4)//设定为4字节对齐
相当于 #pragma pack (push,4)
#pragma pack (1)
作用:调整结构体的边界对齐,让其以一个字节对齐;<使结构体按1字节方式对齐>
但是如果调换一下结构体中DWORD和WORD的顺序,则结果又不同。如下:
















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









