






神奇的序列化
===================================================================
a,什么叫序列化和反序列化
b,为啥要实现这个 Serializable 接口,也就是为啥要序列化
c,serialVersionUID 的作用
1.序列化和反序列化的概念
在Java里面,序列化就是和Serializable接口相关的东西。
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程
简单来说序列化就是一种用来处理对象流的机制。所谓对象流也就是将对象的
内容进行流化(就是I/O)。我们可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间(注:要想将对象传输于网络必须进行流化)!
在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来解决这些问题的!
-----------------------------------------------------------------------------------------小分割线
2.什么情况下需要序列化
( 当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
当你想用套接字在网络上传送对象的时候;
当你想通过RMI(远程方法调用)传输对象的时候; )
如上所述,读写对象会有什么问题呢?比如:我要将对象写入一个磁盘文件而后再将
其读出来会有什么问题吗?别急,其中一个最大的问题就是对象引用!
举个例子来说:假如我有两个类,分别是A和B,B类中含有一个指向A类对象的引用,
现在我们对两个类进行实例化{ A a = new A(); B b = new B(); }。这时在内存中实际上分配
了两个空间,一个存储对象a,一个存储对象b。接下来我们想将它们写入到磁盘的一个文件
中去,就在写入文件时出现了问题!因为对象b包含对对象a的引用,所以系统会自动的将a
的数据复制一份到b中,这样的话当我们从文件中恢复对象时(也就是重新加载到内存中)时,
内存分配了三个空间,而对象a同时在内存中存在两份,想一想后果吧,如果我想修改对象a
的数据的话,那不是还要搜索它的每一份拷贝来达到对象数据的一致性,这不是我们所希望的!
-----------------------------------------------------------------------------------------
以下序列化机制的解决方案:
1.保存到磁盘的所有对象都获得一个序列号(1, 2, 3等等)
2.当要保存一个对象时,先检查该对象是否被保存了
3.如果以前保存过,只需写入"与已经保存的具有序列号x的对象相同"的标记,否则,保存该对象
通过以上的步骤序列化机制解决了对象引用的问题!
-----------------------------------------------------------------------------------------
3.如何实现序列化
将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable
只是为了标注该对象是可被序列化的。然后使用一个输出流(如:FileOutputStream)来构造一个
ObjectOutputStream(对象流)对象。接着,使用ObjectOutputStream对象的writeObject(Object obj)方法
就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
package com.quanma;
import com.quanma.domain.Student;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author maquan
* @date 2022/3/18 15:44
*/
public class PracticeTest {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
// list.add(new Student("zhangsan",14,99));
// list.add(new Student("lisi",17,69));
// list.add(new Student("wangwu",18,50));
// try {
// writeStudents(list);
// } catch (IOException e) {
// e.printStackTrace();
// }
try {
list = readStudents();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
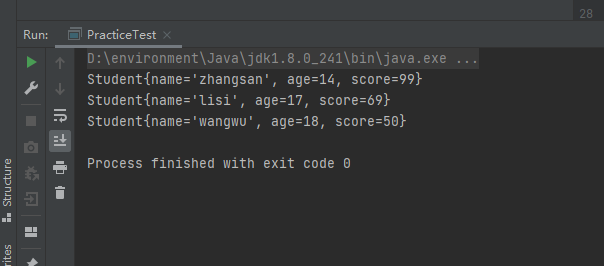
for (Student x:list) {
System.out.println(x);
}
}
public static void writeStudents (List<Student> students) throws IOException {
ObjectOutputStream out = new ObjectOutputStream(
new BufferedOutputStream(new FileOutputStream("students.dat")));
try {
out.writeInt(students.size());
for (Student s : students) {
out.writeObject(s);
}
} finally {
out.close();
}
}
public static List<Student> readStudents() throws IOException,
ClassNotFoundException {
ObjectInputStream in = new ObjectInputStream(new BufferedInputStream(
new FileInputStream("students.dat")));
try {
int size = in.readInt();
List<Student> list = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
list.add((Student) in.readObject());
}
return list;
} finally {
in.close();
}
}
}
===================================================================
在序列化的过程中,有些数据字段我们不想将其序列化,对于此类字段我们只需要在定义
时给它加上transient关键字即可,对于transient字段序列化机制会跳过不会将其写入文件,当然
也不可被恢复。但有时我们想将某一字段序列化,但它在SDK中的定义却是不可序列化的类型,
这样的话我们也必须把他标注为transient,可是不能写入又怎么恢复呢?好在序列化机制为包含
这种特殊问题的类提供了如下的方法定义:
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException;
private void writeObject(ObjectOutputStream out) throws IOException;
(注:这些方法定义时必须是私有的,因为不需要你显示调用,序列化机制会自动调用的)
使用以上方法我们可以手动对那些你又想序列化又不可以被序列化的数据字段进行写出和读入操作。
import java.io.*;
import java.awt.geom.*;
public class TransientTest
{
public static void main(String[] args)
{
LabeledPoint label = new LabeledPoint("Book", 5.00, 5.00);
try {
System.out.println(label); // 写入前
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("Label.txt"));
out.writeObject(label); //通过对象输出流,将label写入流中
out.close();
System.out.println(label);// 写入后
ObjectInputStream in = new ObjectInputStream(new FileInputStream("Label.txt"));
LabeledPoint label1 = (LabeledPoint) in.readObject();
in.close();
System.out.println(label1);// 读出并加1.0后
} catch (Exception e) {
e.printStackTrace();
}
}
}
class LabeledPoint implements Serializable
{
private String label;
transient private Point2D.Double point; //因为不可被序列化,所以需要加transient关键字
public LabeledPoint(String str, double x, double y)//构造方法
{
label = str;
point = new Point2D.Double(x, y); //此类Point2D.Double不可被序列化
}
//因为Point2D.Double不可被序列化,所以需要实现下面两个方法
private void writeObject(ObjectOutputStream out) throws IOException
{
out.defaultWriteObject();
out.writeDouble(point.getX());
out.writeDouble(point.getY());
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException
{
in.defaultReadObject();
double x = in.readDouble() + 1.0;
double y = in.readDouble() + 1.0;
point = new Point2D.Double(x, y);
}
//重写toString方法
public String toString()
{
return getClass().getName()+ "[label = " + label+ ", point.getX() = " + point.getX()+ ", point.getY() = " +
point.getY()+ "]";
}
}4.serialVersionUID的作用
JAVA序列化的机制是通过 判断类的serialVersionUID来验证的版本一致的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID于本地相应实体类的serialVersionUID进行比较。如果相同说明是一致的,可以进行反序列化,否则会出现反序列化版本一致的异常,即是InvalidCastException。
具体序列化的过程是这样的:序列化操作时会把系统当前类的serialVersionUID写入到序列化文件中,当反序列化时系统会自动检测文件中的serialVersionUID,判断它是否与当前类中的serialVersionUID一致。如果一致说明序列化文件的版本与当前类的版本是一样的,可以反序列化成功,否则就失败;
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据包名,类名,继承关系,非私有的方法和属性,以及参数,返回值等诸多因子计算得出的,极度复杂生成的一个64位的哈希字段。基本上计算出来的这个值是唯一的。比如:private static final long serialVersionUID = xxxxL;
注意:显示声明serialVersionUID可以避免对象不一致
现在有一个场景体现serialVersionUID实际的应用
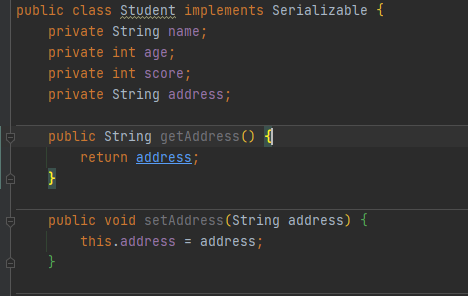
在反序列化前将Student类修改一下添加一个属性address之后再反序列化
反序列化后
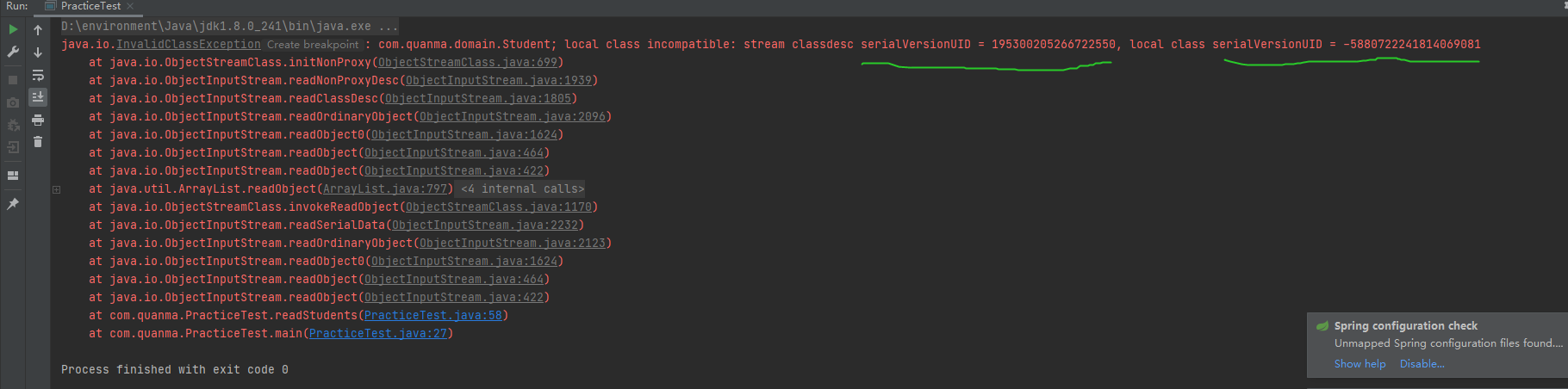
可以明显看到的异常是因为两个serialVersionUID不同,那我们尝试自定义一下serialVersionUID这个值看看
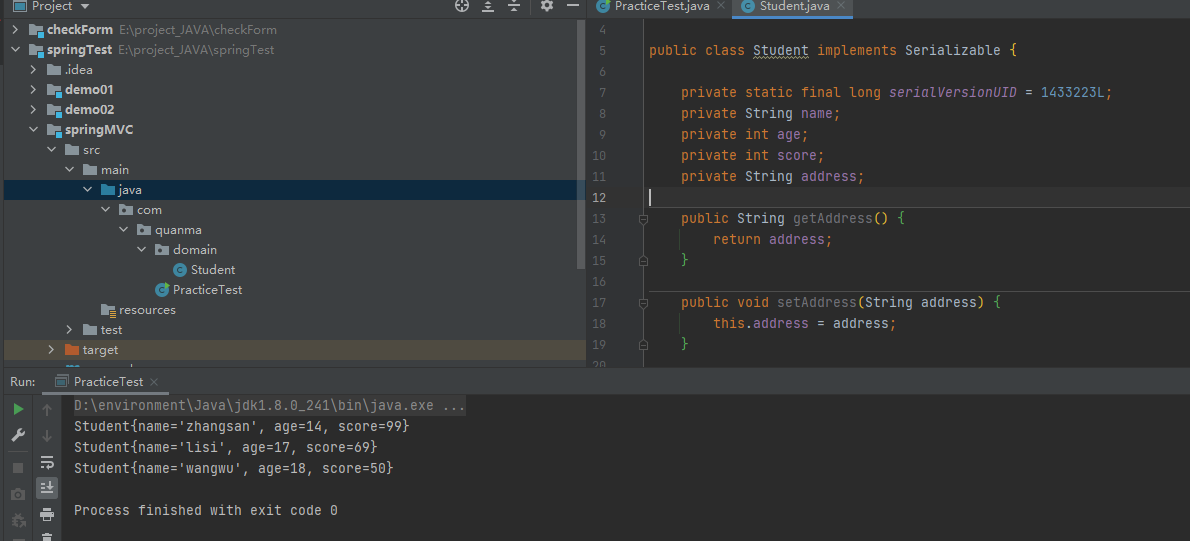
可以看到,再次添加address之后反序列化是可以成功的
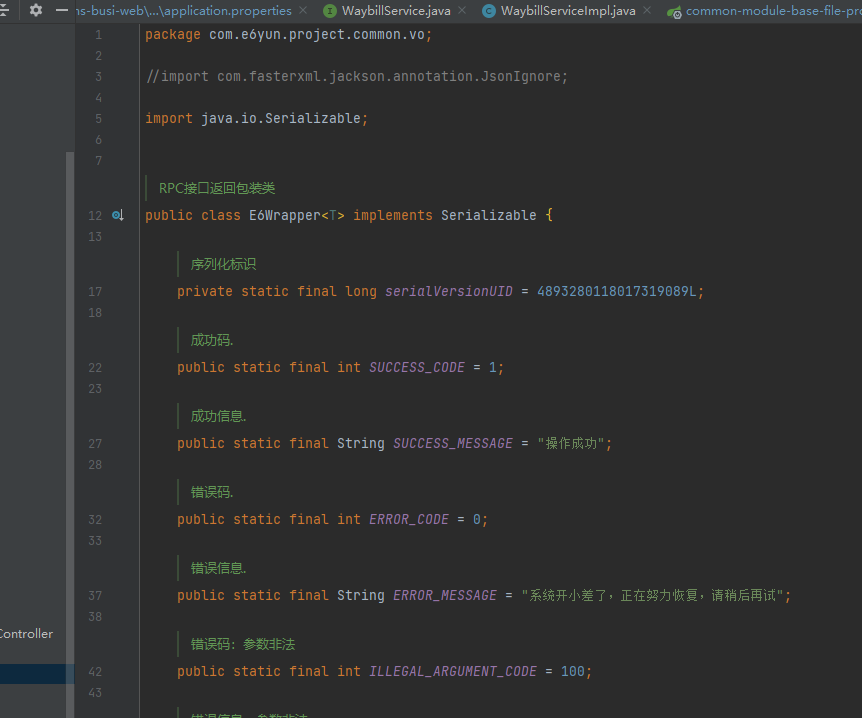
在实际的生产环境中,我们可能会建一系列的中间Object来反序列化我们的pojo,为了解决这个问题,我们就需要在实体类中自定义SerialversionUID
这是我们项目中也用到了自定义SerialversionUID
实用序列化: JSON/XML/MessagePack
===============================================================
XML/JSON都是文本格式,而MessagePack是一种二进制形式的JSON,编码更为精简高效
这是官网给出的简单示例图
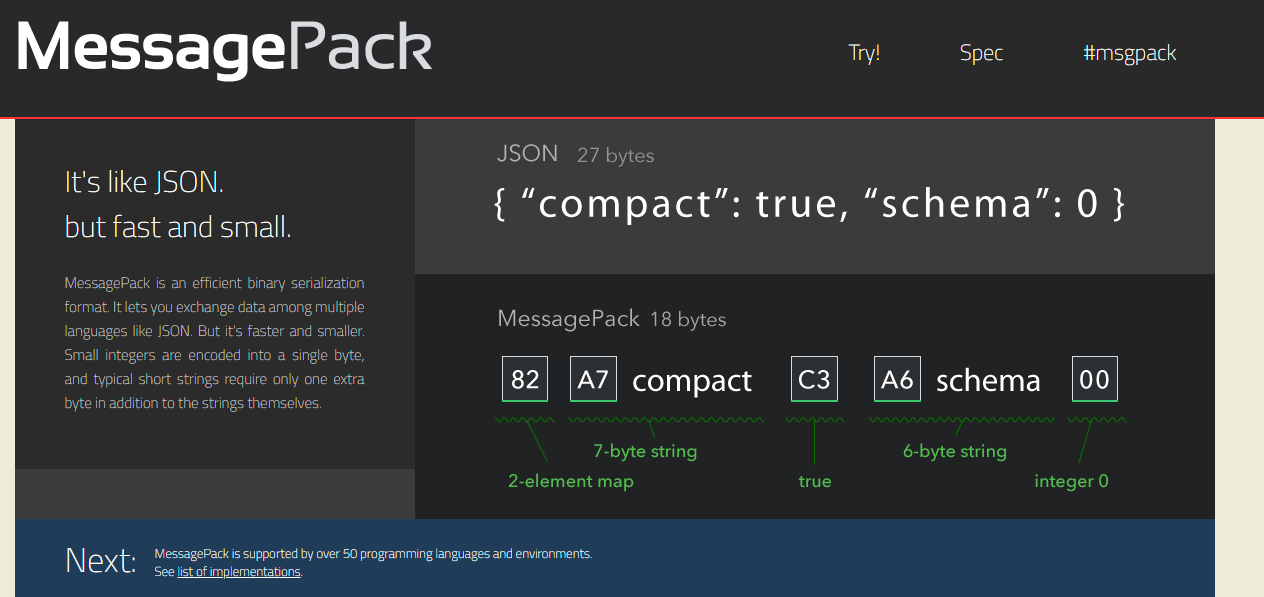
可以看出json27个字节,而MessagePack只用了18个,他是省略了json中那些大括号,引号这些无意义的数据,那他是怎么表示的呢,如A7就是A表示str类型7表示长度这样。具体的压缩原理我们就不讨论了。
java SDK对这些格式的支持有限,所以我们一般用第三方的类库如Jackson,需要添加依赖。
Jackson序列化的主要类是ObjectMapper,它是一个线程安全的类,可以初始化并配置一次,被多个线程共享。
下面我们按顺序来看如何去序列化这些格式
====================================================================
1.JSON
可以先看一下需要的依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>springMVC</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.3.16</version>
<scope>compile</scope>
</dependency>
<!--下面这三个就是Jackson所需要的依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.5</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.5</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
结果就在根目录下输出了该文件

这里有一些ObjectMapper其他的方法,输出字节数组,输出字符串,写出Writer、OutputStream
public byte[] writeValueAsBytes(Object value)
public String writeValueAsString(Object value)
public void writeValue(Writer w, Object value)
public void writeValue(OutputStream out, Object value)接下来将他反序列化,我做的时候遇到了这个问题:
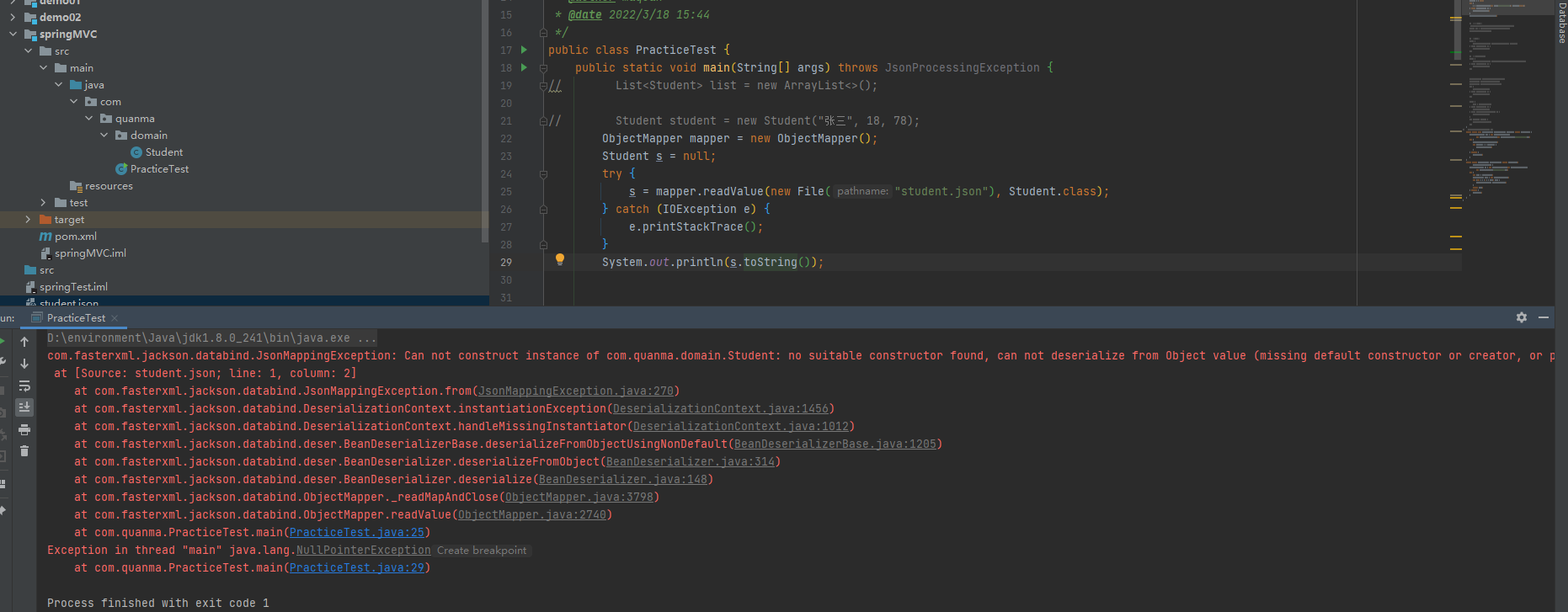
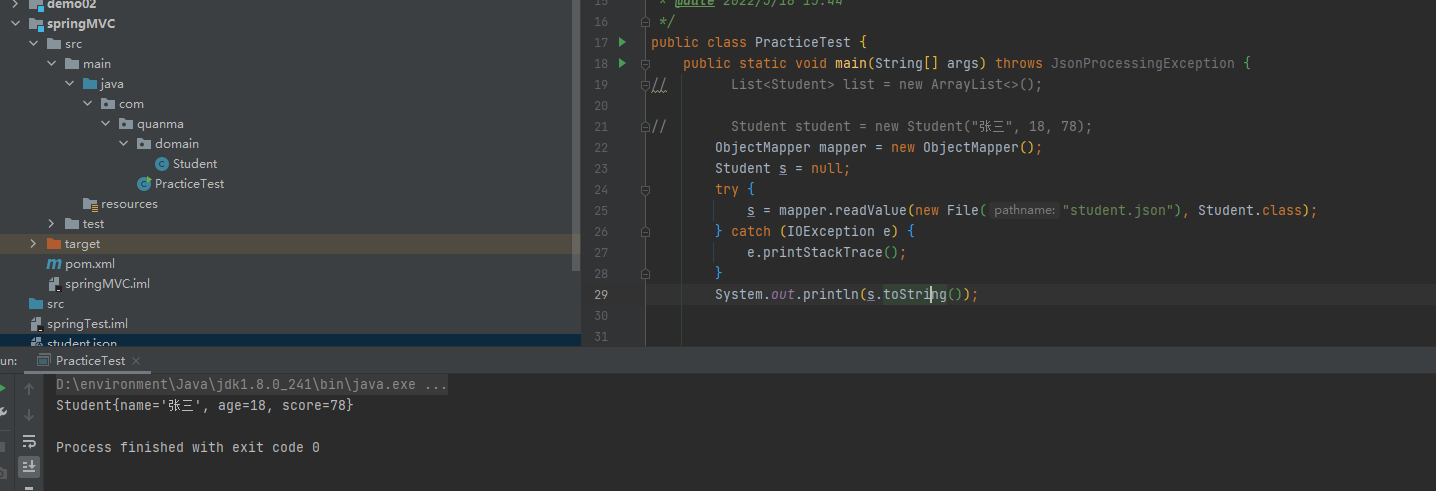
其实很简单,我在Student类中将无参构造方法补上就好了
======================================================================
2.XML
和JSON没什么大的区别,就将ObjectMapper换为XmlMapper,XmlMapper是ObjectMapepr的子类
记得导入依赖
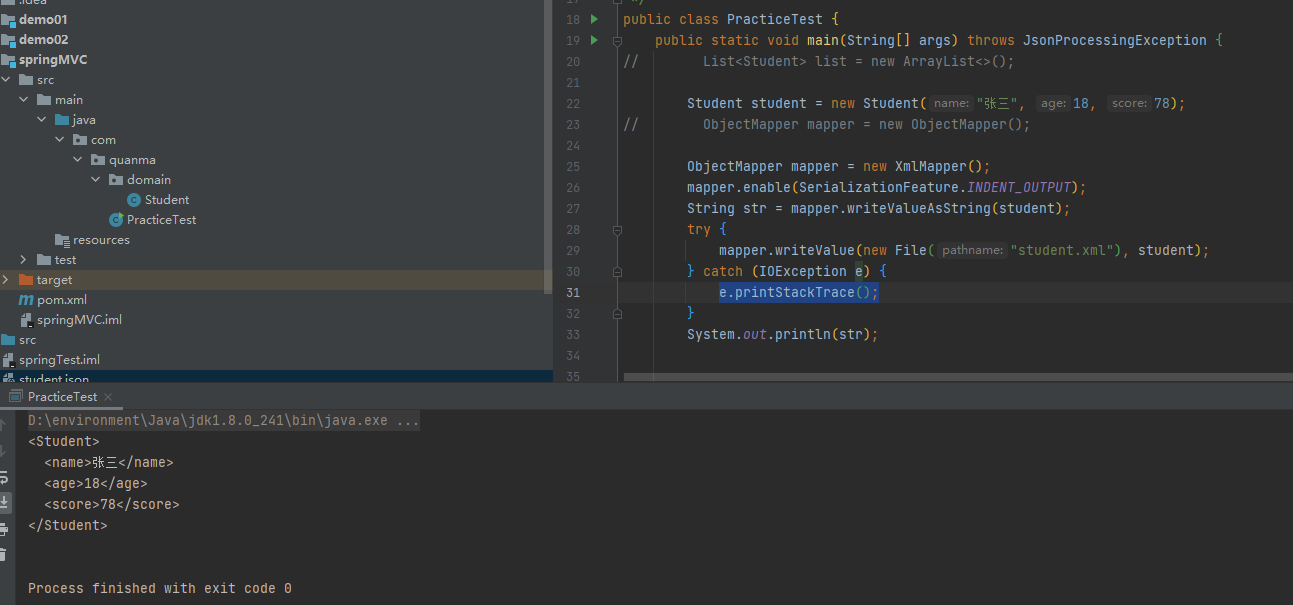
反序列化
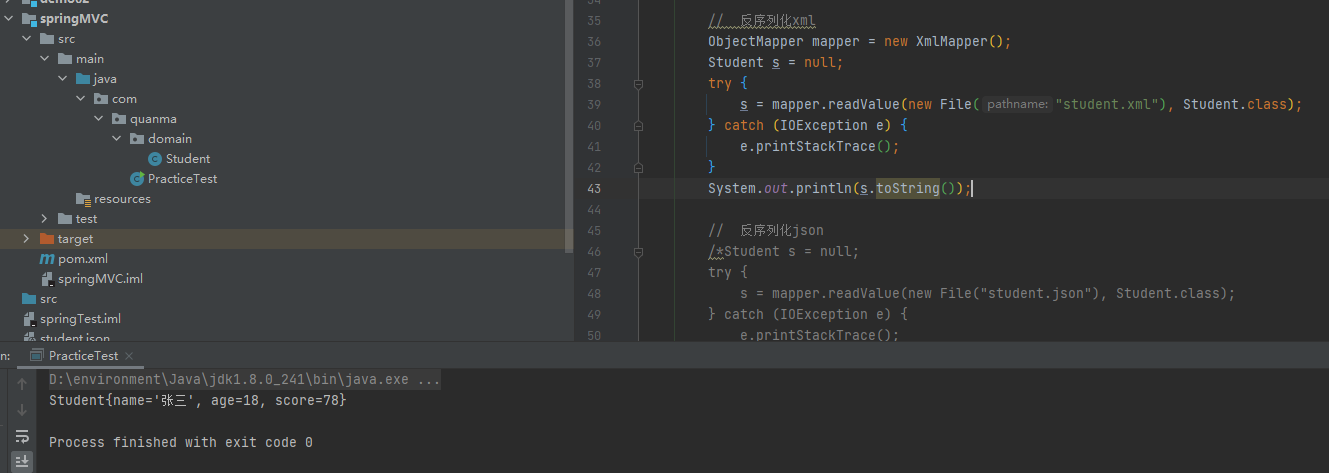
============================================================
3.MessagePack
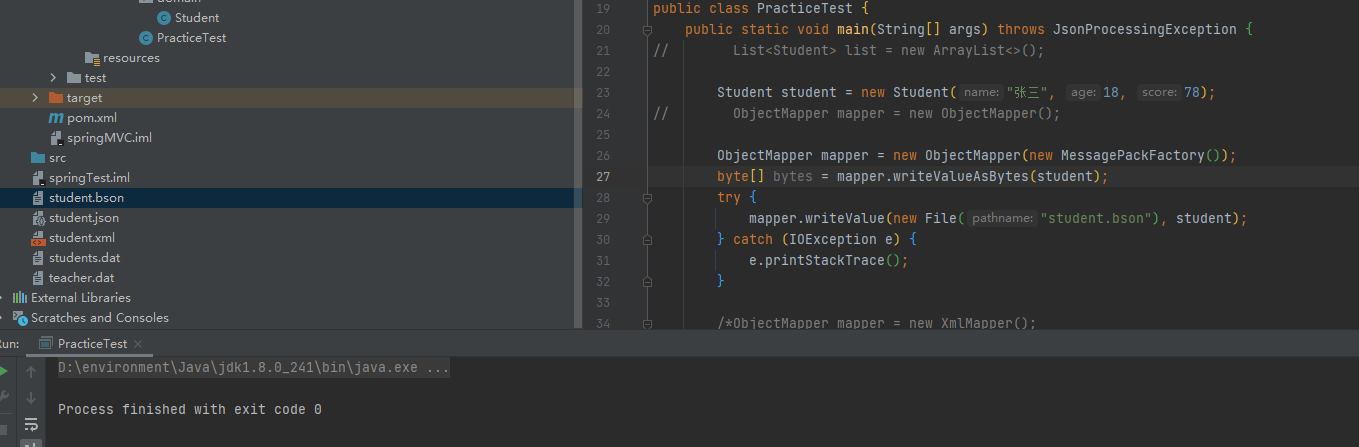
MessagePack也是用ObjectMapper类,但传递一个MessagePackFactory对象
MessagePack是二进制格式,不能写出为String,可以写出为文件、OutpuStream或字节数组
还是先加依赖
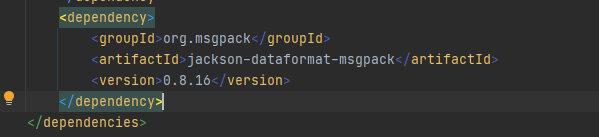
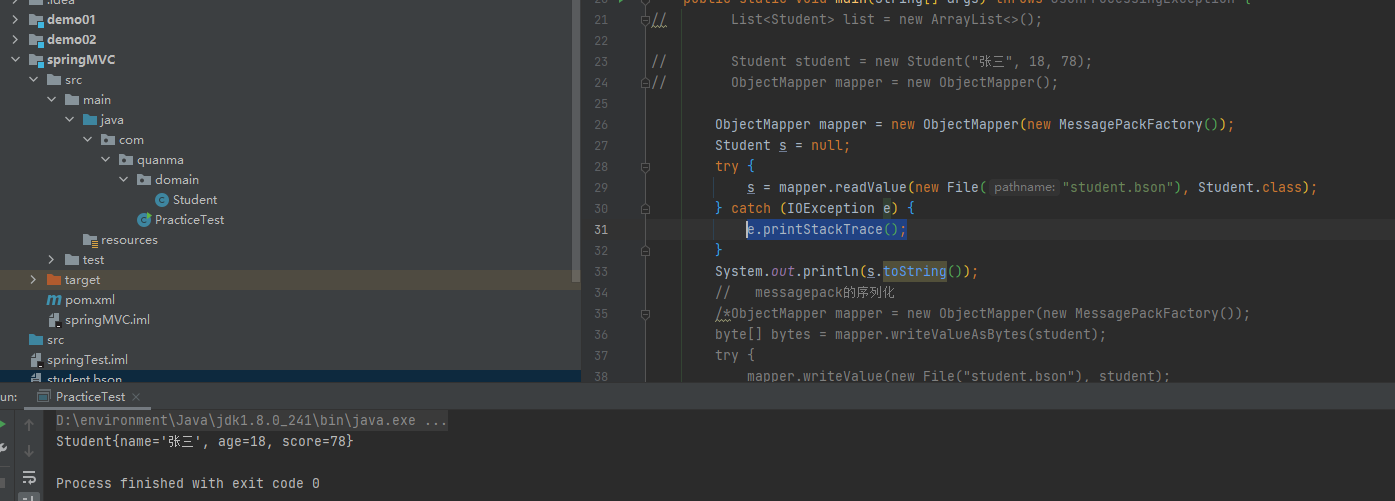
反序列化:
4.容器对象
拿List来说
序列化的过程和前面是一样的
反序列化有一点点区别,要新建一个TypeReference匿名内部类对象来指定类型
ObjectMapper mapper = new ObjectMapper();
List<Student> list = mapper.readValue(new File("students.json"),
new TypeReference<List<Student>>() {});
System.out.println(list.toString());map类似,吧ObjectMapper换为XmlMapper
Map<String, Student> map = new HashMap<String, Student>();
map.put("zhangsan", new Student("张三", 18, 80));
map.put("lisi", new Student("李四", 17, 66));
ObjectMapper mapper = new XmlMapper();
mapper.enable(SerializationFeature.INDENT_OUTPUT);
String str = mapper.writeValueAsString(map);
mapper.writeValue(new File("students_map.xml"), map);
System.out.println(str);
// 反序列化
ObjectMapper mapper = new XmlMapper();
Map<String, Student> map = mapper.readValue(new File("students_map.xml"),
new TypeReference<Map<String, Student>>() {});
System.out.println(map.toString());======================================================
还记得transient吧,是序列化时将他忽略,但在Jackson中即使加上了也会序列化出去
在Jackson中使用注解:
- @JsonIgnore:用于字段, getter或setter方法,任一地方的效果都一样
- @JsonIgnoreProperties:用于类声明,可指定忽略一个或多个字段(括号中指定)
- @JsonIgnoreProperties(ignoreUnknown = true),将这个注解写在类上之后,就会忽略类中不存在的字段。这个注解还可以指定要忽略的字段,例如@JsonIgnoreProperties({ “password”, “secretKey” })
易流云3.0中也遇到了这个问题:

引用同一个对象
/*@JsonIdentityInfo(
generator = ObjectIdGenerators.IntSequenceGenerator.class,
property="id")*/
public class Common {
public String name;
}
public class A {
public Common first;
public Common second;
}
package com.quanma;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.quanma.domain.A;
import com.quanma.domain.Common;
import java.io.IOException;
public class Demo01SameObject {
public static void main(String[] args) {
Common c = new Common();
c.name= "common";
A a = new A();
a.first = a.second = c;
ObjectMapper mapper = new ObjectMapper();
mapper.enable(SerializationFeature.INDENT_OUTPUT); //格式化输出
String str = null;
try {
str = mapper.writeValueAsString(a);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
System.out.println(str);
A a2 = null;
try {
a2 = mapper.readValue(str, A.class);
} catch (IOException e) {
e.printStackTrace();
}
if(a2.first == a2.second){
System.out.println("reference same object");
}else{
System.out.println("reference different objects");
}
}
}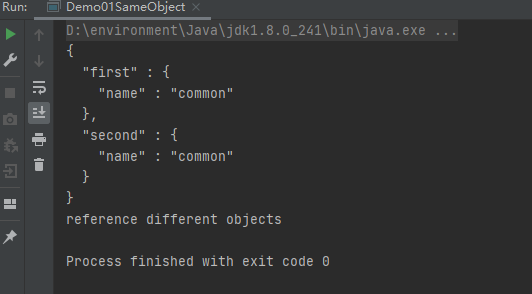
反序列化后所指向的对象不是同一个
加入注解@JsonIdentityInfo,对Common类做注解
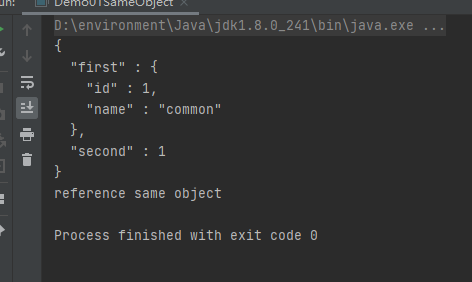
这时候就会指向同一个对象
@JsonIdentityInfo中指定了两个属性,property="id"表示在序列化输出中新增一个属性"id"以表示对象的唯一标示,generator表示对象唯一ID的产生方法,这里是使用整数顺序数产生器IntSequenceGenerator。
=======================================================
常见文件类型处理: 属性文件/CSV/EXCEL/HTML/压缩文件
- 属性文件:属性文件是常见的配置文件,用于在不改变代码的情况下改变程序的行为。
- CSV:CSV是Comma-Separated Values的缩写,表示逗号分割值,是一种非常常见的文件类型,大部分日志文件都是CSV,CSV也经常用于交换表格类型的数据,待会我们会看到,CSV看上去很简单但处理的复杂性经常被低估。
- Excel:Excel大家都知道,在编程中,经常需要将表格类型的数据导出为Excel格式,以方便用户查看,也经常需要接受Excel类型的文件作为输入以批量导入数据。
- HTML:所有网页都是HTML格式,我们经常需要分析HTML网页,以从中提取感兴趣的信息。
- 压缩文件:压缩文件有多种格式,也有很多压缩工具,大部分情况下,我们可以借助工具而不需要自己写程序处理压缩文件,但某些情况,需要自己编程压缩文件或解压缩文件
1.属性文件
处理这种文件用字符流时,主要使用的是Java中java.util.Properties
public synchronized void load(InputStream inStream) //从流中加载属性
public String getProperty(String key) //获取属性值
public String getProperty(String key, String defaultValue) //可以提供默认值
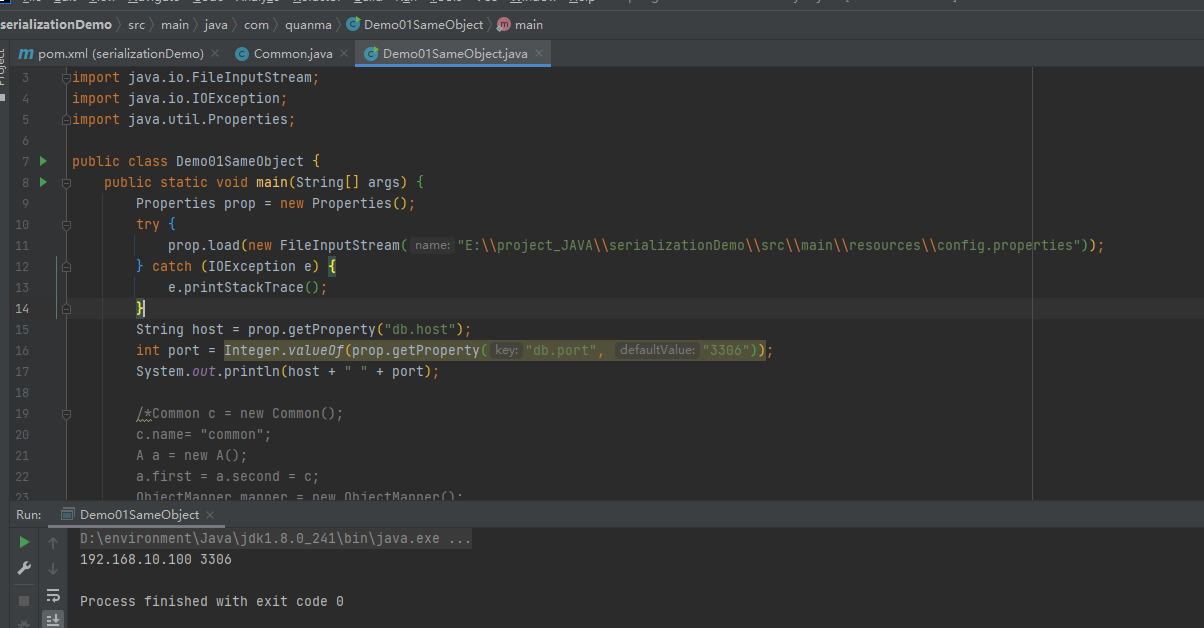
使用类Properties处理属性文件的好处是:
- 可以自动处理空格,我们看到分隔符=前后的空格会被自动忽略
- 可以自动忽略空行
- 可以添加注释,以字符#或!开头的行会被视为注释,进行忽略
2.CSV文件
依赖导入:program-logic/dependencies.xml at master · swiftma/program-logic · GitHub
具体文件格式:
•每条记录占一行
•以逗号为分隔符
•逗号前后的空格会被忽略
•字段中包含有逗号,该字段必须用双引号括起来
•字段中包含有换行符,该字段必须用双引号括起来
•字段前后包含有空格,该字段必须用双引号括起来
•字段中的双引号用两个双引号表示
•字段中如果有双引号,该字段必须用双引号括起来
•第一条记录,可以是字段名
还有一些复杂的问题,如怎么表示null等,用第三方类库Apache Commons CSV,里面有一个重要的类CSVFormat表示CSV格式,下面是定义具体的CSV格式:
//定义分隔符
public CSVFormat withDelimiter(final char delimiter)
//定义引号符
public CSVFormat withQuote(final char quoteChar)
//定义转义符
public CSVFormat withEscape(final char escape)
//定义值为null的对象对应的字符串值
public CSVFormat withNullString(final String nullString)
//定义记录之间的分隔符
public CSVFormat withRecordSeparator(final char recordSeparator)
//定义是否忽略字段之间的空白
public CSVFormat withIgnoreSurroundingSpaces(final boolean ignoreSurroundingSpaces)
CSVFormat有一个方法,可以分析字符流:
public CSVParser parse(final Reader in) throws IOException
返回值类型为CSVParser,它有如下方法获取记录信息:
public Iterator<CSVRecord> iterator()
public List<CSVRecord> getRecords() throws IOException
public long getRecordNumber()
基本代码:
CSVFormat format = CSVFormat.newFormat(';')
.withQuote('"').withNullString("N/A")
.withIgnoreSurroundingSpaces(true);
Reader reader = new FileReader("student.csv");
try{
for(CSVRecord record : format.parse(reader)){
int fieldNum = record.size();
for(int i=0; i<fieldNum; i++){
System.out.print(record.get(i)+" ");
}
System.out.println();
}
}finally{
reader.close();
}
// eg
CSVPrinter out = new CSVPrinter(new FileWriter("student.csv"),
CSVFormat.DEFAULT);
out.printRecord("老马", 18, "看电影,看书,听音乐");
out.printRecord("小马", 16, "乐高;赛车;");
out.close();3.Excel
依赖导入:program-logic/dependencies.xml at master · swiftma/program-logic · GitHub
java处理Excel文件用POI类库
- Workbook: 表示一个Excel文件对象,它是一个接口,有两个主要类HSSFWorkbook和XSSFWorkbook,前者对应.xls格式,后者对应.xlsx格式。
- Sheet: 表示一个工作表
- Row: 表示一行
- Cell: 表示一个单元格
保存学生列表到students.xls代码为:
public static void saveAsExcel(List<Student> list) throws IOException {
Workbook wb = new HSSFWorkbook();
Sheet sheet = wb.createSheet();
for (int i = 0; i < list.size(); i++) {
Student student = list.get(i);
Row row = sheet.createRow(i);
row.createCell(0).setCellValue(student.getName());
row.createCell(1).setCellValue(student.getAge());
row.createCell(2).setCellValue(student.getScore());
}
OutputStream out = new FileOutputStream("student.xls");
wb.write(out);
out.close();
wb.close();
}
//如果要保存为.xlsx格式,只需要替换第一行为:
Workbook wb = new XSSFWorkbook();
//解析Excel文件
public static List<Student> readAsExcel() throws Exception {
Workbook wb = WorkbookFactory.create(new File("student.xls"));
List<Student> list = new ArrayList<Student>();
for(Sheet sheet : wb){
for(Row row : sheet){
String name = row.getCell(0).getStringCellValue();
int age = (int)row.getCell(1).getNumericCellValue();
double score = row.getCell(2).getNumericCellValue();
list.add(new Student(name, age, score));
}
}
wb.close();
return list;
}4.HTML
导入依赖:https://github.com/swiftma/program-logic/blob/master/html_lib/dependencies.xml
有很多HTML分析器,我们简要介绍一种,jsoup,其官网地址为https://jsoup.org/
有这样一个网页

假定我们要抽取网页主题内容中每篇文章的标题和链接,怎么实现呢?jsoup支持使用CSS选择器语法查找元素,如果不了解CSS选择器,可参看http://www.w3school.com.cn/cssref/css_selectors.asp。
定位文章列表的CSS选择器可以是
#cnblogs_post_body p a
我们来看代码(假定文件为articles.html):
Document doc = Jsoup.parse(new File("articles.html"), "UTF-8");
Elements elements = doc.select("#cnblogs_post_body p a");
for(Element e : elements){
String title = e.text();
String href = e.attr("href");
System.out.println(title+", "+href);
}输出为(部分):
计算机程序的思维逻辑 (1) - 数据和变量, http://www.cnblogs.com/swiftma/p/5396551.html
计算机程序的思维逻辑 (2) - 赋值, http://www.cnblogs.com/swiftma/p/5399315.html
jsoup也可以直接连接URL进行分析,比如,上面代码的第一行可以替换为:
String url = "http://www.cnblogs.com/swiftma/p/5631311.html";
Document doc = Jsoup.connect(url).get();5.压缩文件
压缩文件有多种格式,Java SDK支持两种:gzip和zip,gzip只能压缩一个文件,而zip文件中可以包含多个文件。下面我们介绍Java SDK中的基本用法
先来看gzip,有两个主要的类分别是OutputStream和InputStream的子类,都是装饰类,GZIPOutputStream加到已有的流上,就可以实现压缩,而GZIPInputStream加到已有的流上,就可以实现解压缩
java.util.zip.GZIPOutputStream
java.util.zip.GZIPInputStream比如,压缩一个文件的代码可以为:
public static void gzip(String fileName) throws IOException {
InputStream in = null;
String gzipFileName = fileName + ".gz";
OutputStream out = null;
try {
in = new BufferedInputStream(new FileInputStream(fileName));
out = new GZIPOutputStream(new BufferedOutputStream(
new FileOutputStream(gzipFileName)));
copy(in, out);
} finally {
if (out != null) {
out.close();
}
if (in != null) {
in.close();
}
}
}
// 解压缩
public static void gunzip(String gzipFileName, String unzipFileName)
throws IOException {
InputStream in = null;
OutputStream out = null;
try {
in = new GZIPInputStream(new BufferedInputStream(
new FileInputStream(gzipFileName)));
out = new BufferedOutputStream(new FileOutputStream(
unzipFileName));
copy(in, out);
} finally {
if (out != null) {
out.close();
}
if (in != null) {
in.close();
}
}
}zip文件支持一个压缩文件中包含多个文件,Java SDK主要的类是:
java.util.zip.ZipOutputStream
java.util.zip.ZipInputStream分别是OutputStream和InputStream的子类,也都是装饰类但不能像GZIPOutputStream/GZIPInputStream那样简单使用
ZipOutputStream可以写入多个文件,它有一个重要方法:
public void putNextEntry(ZipEntry e) throws IOException
// 构造方法
public ZipEntry(String name)在写入每一个文件前,必须要先调用该方法,表示准备写入一个压缩条目ZipEntry,每个压缩条目有个名称,这个名称是压缩文件的相对路径,如果名称以字符'/'结尾,表示目录,它的构造方法是如上
我们看一段代码,压缩一个文件或一个目录:
public static void zip(File inFile, File zipFile) throws IOException {
ZipOutputStream out = new ZipOutputStream(new BufferedOutputStream(
new FileOutputStream(zipFile)));
try {
if (!inFile.exists()) {
throw new FileNotFoundException(inFile.getAbsolutePath());
}
inFile = inFile.getCanonicalFile();
String rootPath = inFile.getParent();
if (!rootPath.endsWith(File.separator)) {
rootPath += File.separator;
}
addFileToZipOut(inFile, out, rootPath);
} finally {
out.close();
}
}参数inFile表示输入,可以是普通文件或目录,zipFile表示输出,rootPath表示父目录,用于计算每个文件的相对路径,主要调用了addFileToZipOut将文件加入到ZipOutputStream中,代码为:
private static void addFileToZipOut(File file, ZipOutputStream out,
String rootPath) throws IOException {
String relativePath = file.getCanonicalPath().substring(
rootPath.length());
if (file.isFile()) {
out.putNextEntry(new ZipEntry(relativePath));
InputStream in = new BufferedInputStream(new FileInputStream(file));
try {
copy(in, out);
} finally {
in.close();
}
} else {
out.putNextEntry(new ZipEntry(relativePath + File.separator));
for (File f : file.listFiles()) {
addFileToZipOut(f, out, rootPath);
}
}
}它同样调用了copy方法将文件内容写入ZipOutputStream,对于目录,进行递归调用。
=============================================================
ZipInputStream用于解压zip文件,它有一个对应的方法,获取压缩条目:
public ZipEntry getNextEntry() throws IOException如果返回值为null,表示没有条目了。使用ZipInputStream解压文件,可以使用类似如下代码:
public static void unzip(File zipFile, String destDir) throws IOException {
ZipInputStream zin = new ZipInputStream(new BufferedInputStream(
new FileInputStream(zipFile)));
if (!destDir.endsWith(File.separator)) {
destDir += File.separator;
}
try {
ZipEntry entry = zin.getNextEntry();
while (entry != null) {
extractZipEntry(entry, zin, destDir);
entry = zin.getNextEntry();
}
} finally {
zin.close();
}
}调用extractZipEntry处理每个压缩条目,代码为:
private static void extractZipEntry(ZipEntry entry, ZipInputStream zin,
String destDir) throws IOException {
if (!entry.isDirectory()) {
File parent = new File(destDir + entry.getName()).getParentFile();
if (!parent.exists()) {
parent.mkdirs();
}
OutputStream entryOut = new BufferedOutputStream(
new FileOutputStream(destDir + entry.getName()));
try {
copy(zin, entryOut);
} finally {
entryOut.close();
}
} else {
new File(destDir + entry.getName()).mkdirs();
}
}














 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









