







SparkSQL—RDD、DataFrame、DataSet关系与转换
文章目录
1. 关于 SparkSQL
1.1 概念
- Spark SQL 是 Spark 用于
结构化数据(structured data)处理的 Spark 模块 - SparkSQL 的前身是 Shark,给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供快速上手的工具
- 随着 Spark 的发展,SparkSQL在数据兼容、性能优化、组件扩展方面都得到了极大的方便:
(1) 数据兼容方面 SparkSQL不但兼容 Hive,还可以从 RDD、parquet 文件、JSON 文件中获取数据,未来版本甚至支持获取 RDBMS 数据以及 cassandra 等 NOSQL 数据;
(2) 性能优化方面 除了采取 In-Memory Columnar Storage、byte-code generation 等优化技术外、将会引进 Cost Model 对查询进行动态评估、获取最佳物理计划等等;
(3) 组件扩展方面 无论是 SQL 的语法解析器、分析器还是优化器都可以重新定义,进行扩展 - Spark SQL 为了简化 RDD 的开发,提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD:DataFrame,DataSet
1.2 特点
- 易整合:无缝的整合了 SQL 查询和 Spark 编程
- 统一的数据访问:使用相同的方式连接不同的数据源
- 兼容 Hive:在已有的仓库上直接运行 SQL 或者 HiveQL
- 标准数据连接:通过 JDBC 或者 ODBC 来连接
1.3 RDD、DataFrame、DataSet
2、SparkSQL 核心编程
- Spark Core 中,如果想要执行应用程序,需要首先构建上下文环境对象 SparkContext,Spark SQL 其实可以理解为对 Spark Core 的一种封装,不仅仅在模型上进行了封装,上下文环境对象也进行了封装
- SparkSession 是 Spark 最新的 SQL 查询起始点,
SparkSession 内部封装了 SparkContext,所以计算实际上是由 sparkContext 完成的。当我们使用 spark-shell 的时候, spark 框架会自动的创建一个名称叫做 spark SparkSession 对 象, 就像我们以前可以自动获取到一个 sc 来表示 SparkContext 对象一样

2.1 DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。
2.1.1 创建 DataFrame
进入spark的shell终端
(1) 从 Spark 数据源进行创建
scala> spark.read.
由下图可知,可以读取以下类型的数据

读取 json 文件创建 DataFrame
在 spark 的 bin/input 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
{"username":"lisi","age":30}
{"username":"王五","age":40}
代码如下(示例):
scala> val df = spark.read.json("input/user.json")
scala> df.show

2.1.2 SQL语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助
(1) 通过刚刚创建的DataFrame创建一个临时表
scala> val df = spark.read.json("input/user.json")
(2) 通过 SQL 语句实现查询全表
scala> val sqlDF = spark.sql("select * from user")
scala> val sqlDF = spark.sql("select age from user")


普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.user
(1) 对于 DataFrame 创建一个全局表
scala> df.createGlobalTempView("user1")
(2) 通过 SQL 语句实现查询全表(不同session)
scala> spark.sql("select username from global_temp.user1").show()
scala> spark.newSession().sql("select username from global_temp.user1").show()

2.1.3 DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了
(1) 创建一个 DataFrame
scala> val df = spark.read.json("input/user.json")
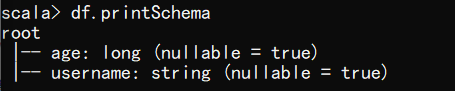
(2) 查看 DataFrame 的 Schema 信息
scala> df.printSchema
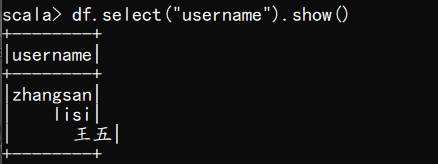
(3) 只查看"username"列数据
scala> df.select("username").show()
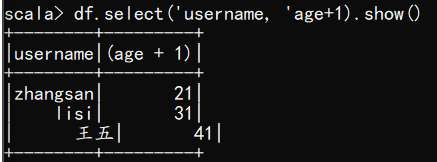
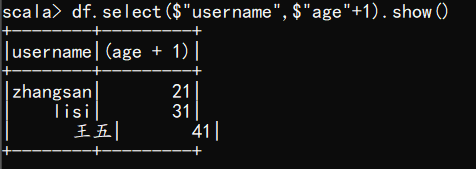
(4) 查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
scala> df.select($"username",$"age"+1).show()
scala> df.select('username, 'age+1).show()
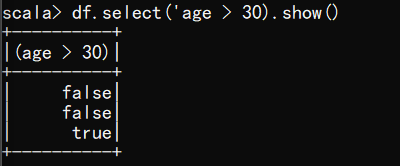
(5) 查看"age"大于"30"的数据
scala> df.select('age > 30).show()
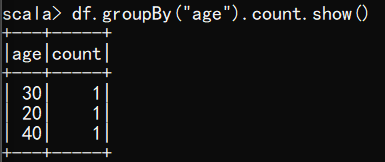
(6) 按照"age"分组,查看数据条数
scala> df.groupBy("age").count.show()
2.2 DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
2.2.1 创建DataSet
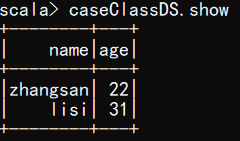
- 使用样例类序列创建 DataSet
scala> val caseClassDS = List(User("zhangsan",22),User("lisi",31)).toDS()
scala> caseClassDS.show

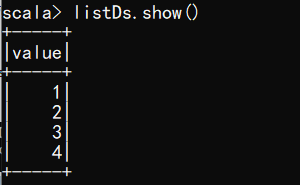
- 使用基本类型的序列创建 DataSet,
序列中数据类型保持一致
scala> val listDs = List(1,2,3,4).toDS
scala> val list2Ds = List("3","4").toDS
scala> listDs.show()



注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
2.3 RDD、DataFrame、DataSet
2.3.1 三者的关系
从版本的产生上来看:
- Spark1.0 => RDD
- Spark1.3 => DataFrame
- Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。在后期的 Spark 版本中,DataSet 有可能会逐步取代 RDD和 DataFrame 成为唯一的 API 接口。
2.3.1 三者的共性
- RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数据提供便利;
- 三者都有
惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到Action 如 foreach 时,三者才会开始遍历运算; - 三者有许多共同的函数,如 filter,排序等;
- 在对 DataFrame 和 Dataset 进行操作许多操作都要包:
importspark.implicits._(在 创建好 SparkSession 对象后尽量直接导入) - 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
- 三者都有 partition 的概念
- DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
2.3.2 三者的区别
- RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作 - DataFrame
➢ 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表头,这样每一列的字段名一目了然(后面专门讲解) - DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
2.3.3 三者的互相转换
RDD更多的是关注数据本身,DataFrame更多的则是由数据的结构,DataSet是数据的类型
// 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sql_trans")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//spark 不是包名,是上下文环境对象名
import spark.implicits._
// RDD => DataFrame
val rdd: RDD[(Int, String, Int)] = spark.sparkContext
.makeRDD(List((1, "zhangsan", 30), (2, "lisi", 26), (3, "wangwu", 29)))
val df: DataFrame = rdd.toDF("id", "username", "age")
df.show()
// DataFrame => DataSet
// 样例类User
val ds: Dataset[User] = df.as[User]
ds.show()
// RDD => DataSet
val ds2: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
ds2.show()
println("--------------------------------------------")
// DataSet => RDD
val rdd2: RDD[User] = ds2.rdd
// DataSet => DataFrame
val df2: DataFrame = ds2.toDF()
df2.show()
//DataFrame => RDD
val rdd3: RDD[Row] = df2.rdd
/**
* RDD 返回的 RDD 类型为 Row,里面提供的 getXXX 方法可以获取字段值
* 类似 jdbc 处理结果集,但是索引从 0 开始
*/
// 对应id : 2 3 1
rdd3.foreach(filed => print(filed.getInt(0) + "\t"))
// 对应name : lisi wangwu zhangsan
rdd3.foreach(filed => print(filed.getString(1) + "\t"))
// 对应age : 26 29 30
rdd3.foreach(filed => print(filed.getInt(2) + "\t"))
// 关闭
spark.close()
}
// 样例类
case class User(id: Int, username: String, age: Int)
结果:
+---+--------+---+
| id|username|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 26|
| 3| wangwu| 29|
+---+--------+---+
+---+--------+---+
| id|username|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 26|
| 3| wangwu| 29|
+---+--------+---+
+---+--------+---+
| id|username|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 26|
| 3| wangwu| 29|
+---+--------+---+
--------------------------------------------
+---+--------+---+
| id|username|age|
+---+--------+---+
| 1|zhangsan| 30|
| 2| lisi| 26|
| 3| wangwu| 29|
+---+--------+---+
2 3 1 lisi wangwu zhangsan 26 29 30
Process finished with exit code 0
总结
文章也是仅作知识点的记录,欢迎大家指出错误,一起探讨~~~















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









