






Redis的使用场景:
MySql等关系型数据库将数据资料保存在硬盘上,如果每次数据都从MySql中读取,一旦查询的并发量大,将严重影响效率,而Redis将数据存储在内存中,读取速度非常快,所以使用Redis。具体的使用场景一般用在数据量不大,读取多而增删改少的业务中。
Redis的安装(Linux):
Redis是C语言编写的,安装前需要准备C语言的环境依赖。
yum install gcc-c++下载Redis
wget <https://download.redis.io/releases/redis-3.0.0.tar.gz>解压编译压缩
tar -zxvf redis-3.0.0.tar.gz
cd /usr/upload/redis-3.0.0
make
make install PREFIX=/usr/local/redis单机版Redis的启动和关闭
在redis的bin目录下
启动:./redis-server redis.conf
关闭: ./redis-cli -h 127.0.0.1 -p 6379 shutdown
启动成功出现如图界面:
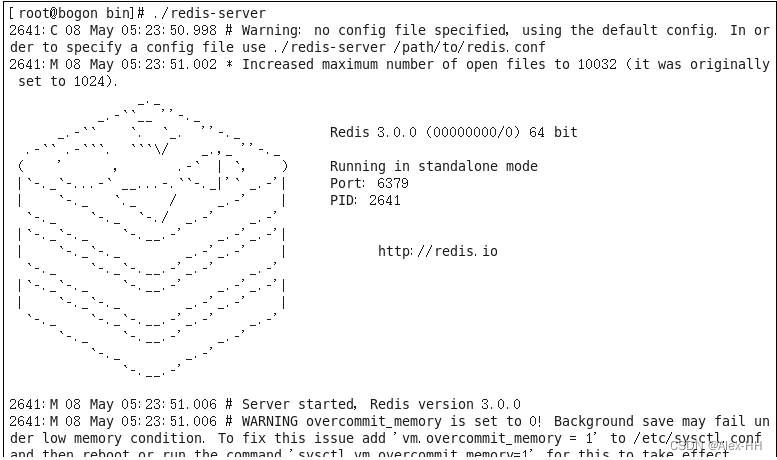
redis默认没有开启后台启动,会一直占用当前的命令窗,需手动开启redis的后台启动
通过vim命令修改redis.conf配置文件
vim /usr/local/redis/bin/redis.conf:将其中的:daemonize 设置为 yes
Redis的数据类型和基本命令
在redis中有五大数据类型,及其对应的数据结构分别是:
1.String Map<String,String>
2.Hash Map<String,Map<String,String>>
3.List Map<String,List<String>>(特别注意,这里的List数据类型,底层是用双向链表实现的,所以在添加删除的时候可以从左添加也可以从右边添加)
4.Set Map<String,Set<String>>
5.ZSet Map<String,SortSet<String>>(和Set的区别是,其是有序的,加入了一个sorted作为每个元素的排序权重)
公用命令:
keys *:查看所有的Key值
expire和ttl:设置key的过期时间和查看Key的过期时间(如果key已过期则返回-2)
exists:判断key值是否存在
incr和decr:自增和自减(可以给定策略因子实现指定范围的自增和自减)
flushdb:清空当前数据库的数据
flushall:清空所有数据库的数据
在redis中默认提供了下标是0-15的16个数据库,不能修改下标,可以通过select切换当前数据库
String类型的常用命令:
赋值: set key value
取值: get key
删除: del key
特点,存储key对应的value值以字符串的形式保存
Hash类型的常用命令:
赋值:hset keyMaster key value
取值:hget keyMaster key
删除:hdel keyMaster key特点:存储key对应的value值以键值对的形式保存,所以指定了存储在Redis中的key之外还需指定key对应键值对的key,通过这个特点,可以用来存储用户信息等(对象),如:
hset user name zhangsan
hset user age 18
hset user gender man假定有一个user对象,设置它的姓名为zhangsan,年龄18,性别男
List类型命令:
赋值:
左赋值-->lpush key value...
右赋值-->rpush key value...
取值(取值的写法为lrange k 开始下标 结束下标,-1表示到最后的元素):
lrange k 0 -1
删除(删除的写法为lrem key 删除元素的个数 value,其中如果删除元素的个数指定的是正数,则从左往右开始计算,如果是负数则从右往左计算):
lrem k -2 vlist类型的特点是一个key对应多个value,并且value是有序的(跟插入的顺序保持一致)
set常用命令:
赋值:
sadd key value...
取值:
smembers key
删除:
srem key valueset类型特点,存储的value是无序不可重复的,同样一个key对应多个value。通过这个特点,可以通过交并差集计算,实现计算共同的喜好,全部的喜好,自己的喜好等功能。
zset常用命令:
赋值(sorted是排序权重,是一个数字):
zadd key sorted value
取值(跟list一样,指定开始与结束下标,-1表示到最后一个元素,不同的是,它可以带上withscores关键字,表示按照权重排序):
zrange key start end withscores
删除:
zrem key value
zset的特点是,有序并且不可重复的,通过这个特点,可以做排行榜应用,取TOP(N)操作,可以用其实现延迟任务等。
Redis的持久化:
redis有两种持久化策略,默认的持久化方式为RDB,这种方式是通过快照来实现的,当符合一定条件时Redis会自动将内存中的数据进行快照并持久化到硬盘中。在redis的配置中默认有以下内容:
save 900 1 #900秒内容如果超过1个key被修改,则发起快照保存
save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
save 60 10000 #表示60秒内如果超过10000个key被修改,则发起快照保存在redis.conf中:
配置dir指定rdb快照文件的位置
配置dbfilename指定快照文件的名称
redis在启动后会读取RDB快照文件,将数据从硬盘读取到内存中。
AOF持久化:
默认情况下redis没有开启AOF(append onlyfile)方式的持久化,可以通过redis.conf配置文件的appendonly参数开启:
appendonly yesAOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof,可以通过appendfilename参数修改:
appendfilename appendonly.aofAOF有三种持久化策略:
#appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
#appendfsync no #从不同步。高效但是数据不会被持久化。Redis的主从复制:
redis的持久化策略保证了即使redis服务重启也会丢失数据,因为redis服务重启后会将硬盘上持久化的数据恢复到内存中,但是当redis服务器损坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障
redis的主从复制模型如下图
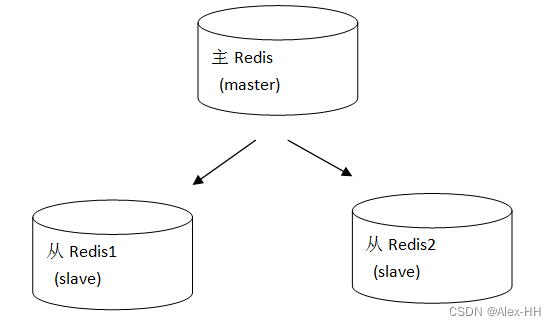
说明:
-
主redis中的数据有两个副本(replication)即从redis1和从redis2,即使一台redis服务器宕机其它两台redis服务也可以继续提供服务。
-
主redis中的数据和从redis上的数据保持实时同步,当主redis写入数据时通过主从复制机制会复制到两个从redis服务上。
-
只有一个主redis,可以有多个从redis。
-
主从复制不会阻塞master,在同步数据时,master可以继续处理client 请求
-
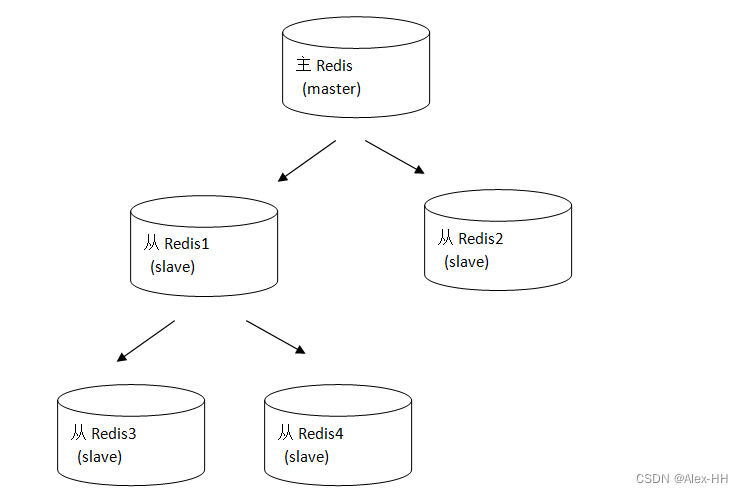
一个redis可以即是主又是从,如下图:
主从复制的相关配置操作:
主redis无需特殊配置
从redis需要修改redis.conf配置文件,添加slaveof主redis ip 及端口
slaveof 192.168.116.40 6379主从复制的过程如下:
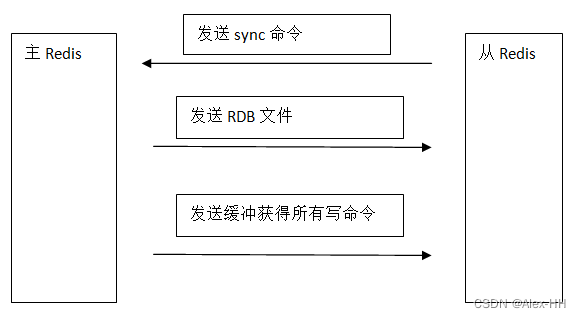
复制过程说明:
1、 slave 服务启动,slave 会建立和master 的连接,发送sync 命令。
2、master启动一个后台进程将数据库快照保存到RDB文件中
3、master 就发送RDB文件给slave
4、slave 将文件保存到磁盘上,然后加载到内存恢复
5、master把缓存的命令转发给slave
注意:主死了,从只能读
在主从配置模式下存在主节点宕机后,从节点只能读取的问题,虽然解决了持久化策略带来的数据不安全问题,安全及稳定性仍能优化。使用redis的集群模式解决。
Redis的集群搭建
redis-cluster架构图
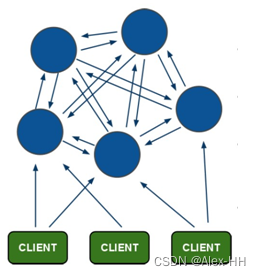
架构有以下特点:
(1)所有的redis节点彼此互联(PING-PONG机制),节点的fail是通过集群中超过半数的节点检测失效时才生效.
(2)存取数据时连接任一节点都可以,但集群中有一个节点fail整个集群都会fail
这是因为:Redis 集群中内置了 16384 个哈希槽,当需要在Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点,如果一个节点fail,则算法算出的结果会导致映射到的哈希槽跟存入的哈希槽不一致,无法正常取出数据。
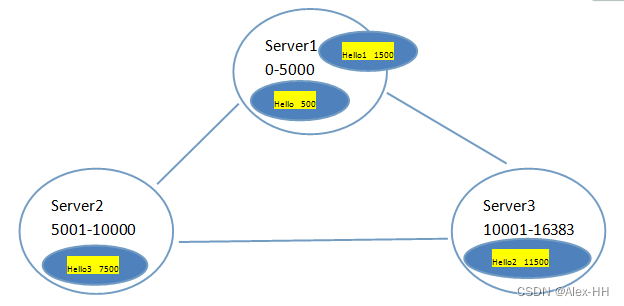
注意:
Redis集群中至少应该有三个节点。要保证集群的高可用,需要每个节点有一个备份机。
Redis集群至少需要6台服务器。
这里示例一下伪集群的搭建(在同一台服务器上开6个redis实现集群)
搭建集群需要使用ruby脚本,首先安装ruby:
[root@upload ~] yum install ruby
[root@upload ~] yum install rubygems
[root@upload ~] gem install redis-3.0.0.gem
第二步,删除快照文件(必须删除dump.rdb和appendonly.aof文件)
第三步,复制六台redis(这里新建了一个redis-cluster文件夹,将复制的redis放入其中)
cp -r /usr/local/redis /usr/local/redis-cluster/redis-7001第四步,修改redis的配置文件
更改端口号并把cluster-enabled yes前的注释去掉
第五步,启动每个redis实例,这里可以创建一个脚本启动(start-all.sh 放在/usr/java/redis-cluster目录下 )
脚本如下:
cd redis-7001
./bin/redis-server bin/redis.conf
cd ..
cd redis-7002
./bin/redis-server bin/redis.conf
cd ..
cd redis-7003
./bin/redis-server bin/redis.conf
cd ..
cd redis-7004
./bin/redis-server bin/redis.conf
cd ..
cd redis-7005
./bin/redis-server bin/redis.conf
cd ..
cd redis-7006
./bin/redis-server bin/redis.conf
cd .. 同时写一个关闭的脚本(shutdown-all.sh,放在/usr/local/redis-cluster目录下 )
cd redis-7001
./bin/redis-cli -p 7001 shutdown
cd ..
cd redis-7002
./bin/redis-cli -p 7002 shutdown
cd ..
cd redis-7003
./bin/redis-cli -p 7003 shutdown
cd ..
cd redis-7004
./bin/redis-cli -p 7004 shutdown
cd ..
cd redis-7005
./bin/redis-cli -p 7005 shutdown
cd ..
cd redis-7006
./bin/redis-cli -p 7006 shutdown
cd .. 写好之后,脚本还不能直接运行,需要配置权限
chmod 777 start-all.sh
chmod 777shutdown-all.sh第六步:使用ruby搭建集群
在redis的src目录下执行(是redis的安装目录的src目录,不是集群的目录)
./redis-trib.rb create --replicas 1 192.168.40.143:7001 192.168.40.143:7002 192.168.40.143:7003 192.168.40.143:7004 192.168.40.143:7005 192.168.40.143:7006执行成功的界面如下:
>>> Creating cluster
Connecting to node 192.168.25.153:7001: OK
Connecting to node 192.168.25.153:7002: OK
Connecting to node 192.168.25.153:7003: OK
Connecting to node 192.168.25.153:7004: OK
Connecting to node 192.168.25.153:7005: OK
Connecting to node 192.168.25.153:7006: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.25.153:7001
192.168.25.153:7002
192.168.25.153:7003
Adding replica 192.168.25.153:7004 to 192.168.25.153:7001
Adding replica 192.168.25.153:7005 to 192.168.25.153:7002
Adding replica 192.168.25.153:7006 to 192.168.25.153:7003
M: 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3 192.168.25.153:7001
slots:0-5460 (5461 slots) master
M: 8cd93a9a943b4ef851af6a03edd699a6061ace01 192.168.25.153:7002
slots:5461-10922 (5462 slots) master
M: 2935007902d83f20b1253d7f43dae32aab9744e6 192.168.25.153:7003
slots:10923-16383 (5461 slots) master
S: 74f9d9706f848471583929fc8bbde3c8e99e211b 192.168.25.153:7004
replicates 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3
S: 42cc9e25ebb19dda92591364c1df4b3a518b795b 192.168.25.153:7005
replicates 8cd93a9a943b4ef851af6a03edd699a6061ace01
S: 8b1b11d509d29659c2831e7a9f6469c060dfcd39 192.168.25.153:7006
replicates 2935007902d83f20b1253d7f43dae32aab9744e6
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.....
>>> Performing Cluster Check (using node 192.168.25.153:7001)
M: 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3 192.168.25.153:7001
slots:0-5460 (5461 slots) master
M: 8cd93a9a943b4ef851af6a03edd699a6061ace01 192.168.25.153:7002
slots:5461-10922 (5462 slots) master
M: 2935007902d83f20b1253d7f43dae32aab9744e6 192.168.25.153:7003
slots:10923-16383 (5461 slots) master
M: 74f9d9706f848471583929fc8bbde3c8e99e211b 192.168.25.153:7004
slots: (0 slots) master
replicates 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3
M: 42cc9e25ebb19dda92591364c1df4b3a518b795b 192.168.25.153:7005
slots: (0 slots) master
replicates 8cd93a9a943b4ef851af6a03edd699a6061ace01
M: 8b1b11d509d29659c2831e7a9f6469c060dfcd39 192.168.25.153:7006
slots: (0 slots) master
replicates 2935007902d83f20b1253d7f43dae32aab9744e6
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.启动时会有个提示:Can I set the above configuration? (type 'yes' to accept): yes
输入yes即可。
搭建完成后启动测试:
启动时使用-c参数来启动集群模式,命令如下:
./redis-cli -c -p 7001redis-cluster模式下的命令:
cluster info #打印集群的信息
cluster nodes #列出集群当前已知的所有节点(node),以及这些节点的相关信息 搭建完毕!















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









