






随着科技的飞速发展,人工智能(AI)技术在各个领域的应用愈发广泛,其中农业领域也不例外。近年来,AI助力农田作物场景下智能激光除草的技术成为了农业领域的一大亮点,它代表着农业智能化、自动化的新趋势。智能激光除草,顾名思义,就是利用激光技术结合AI算法,对农田中的杂草进行精准识别和清除。这种技术不仅高效、环保,而且能够减少对农作物的误伤,提高农田的产量和质量。在智能激光除草系统中,目标检测是至关重要的一环。需要基于大量真实场景的农田作业场景采集到的图像数据进行标注训练,得到高精度高时效性的智能检测模型,能够快速准确的对镜头画面中出现的杂草进行检测识别,之后将位置信息与类型信息发送到硬件端,可以利用高精度激光器和控制系统,根据目标检测模型提供的位置信息,对杂草进行精准施药消除。这种激光除草方式相比传统的机械除草或化学除草具有诸多优势。首先,激光除草无需使用化学药剂,对环境和农作物更加友好;其次,激光除草能够实现对杂草的精准打击,减少对农作物的误伤;最后,激光除草具有高效、快速的特点,能够显著提高农田的管理效率。
在我们前面的系列博文中关于杂草相关的开发实践已经有很多介绍了,感兴趣的话可以自行移步阅读即可:
《助力智能化农田作物除草,基于轻量级YOLOv8n开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《助力智能化农田作物除草,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《助力智能化农田作物除草,基于DETR(DEtection TRansformer)模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《AI助力智慧农业,基于YOLOv6最新版本模型开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统》
《自建田间作物场景杂草检测数据,基于YOLOv5[n/s/m/l/x]全系列参数模型开发构建杂草检测识别分析系统》
《自建数据集,基于YOLOv7开发构建农田场景下杂草检测识别系统》
《激光除草距离我们实际的农业生活还有多远,结合近期所见所感基于yolov8开发构建田间作物杂草检测识别系统》
《助力智能化农田作物除草,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《AI助力农田作物智能化激光除草,基于轻量级YOLOv8n开发构建农田作物场景下常见20种杂草检测识别分析系统》
《AI助力农田作物智能化激光除草,基于YOLO家族最新端到端实时算法YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建农田作物场景下常见20种杂草检测识别分析系统》
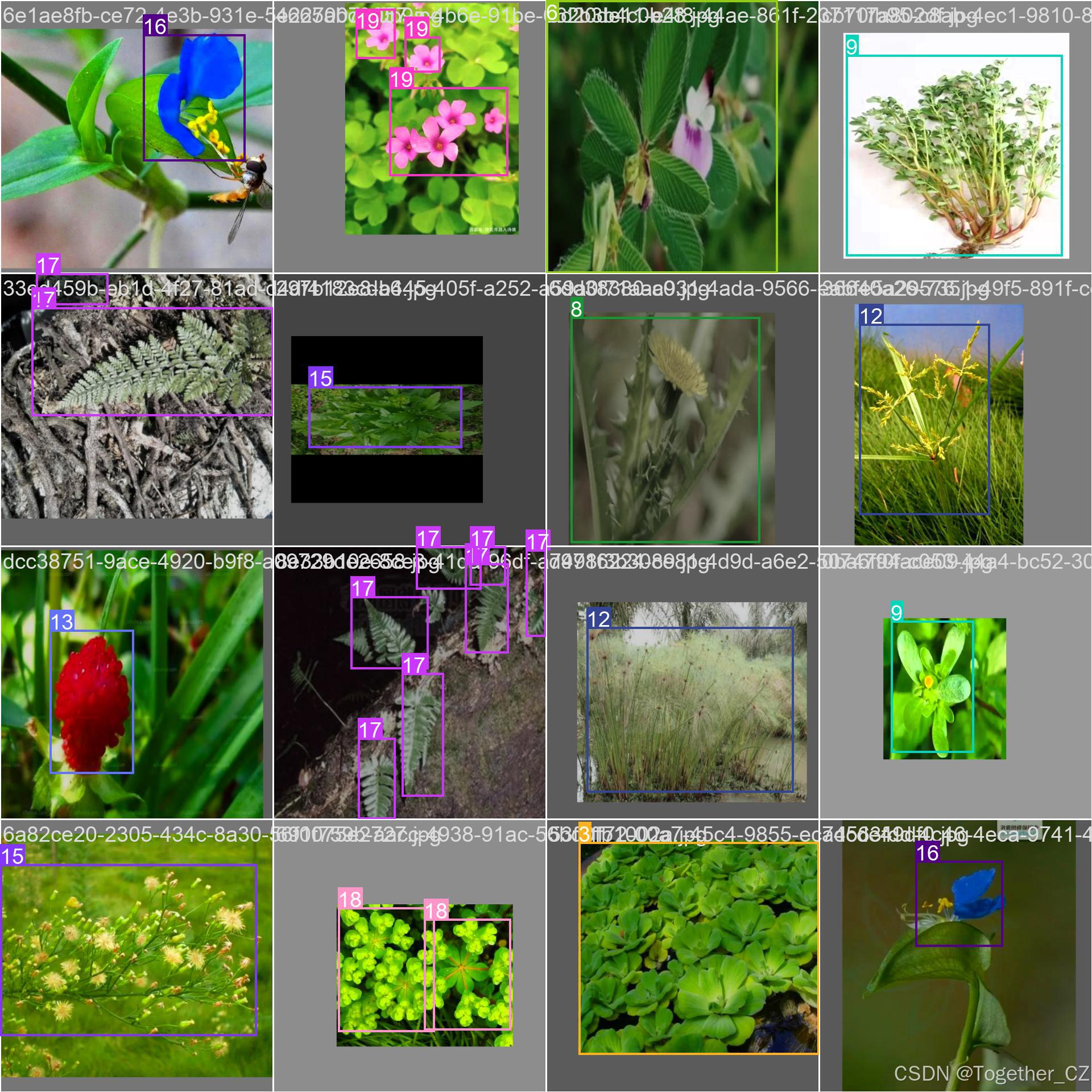
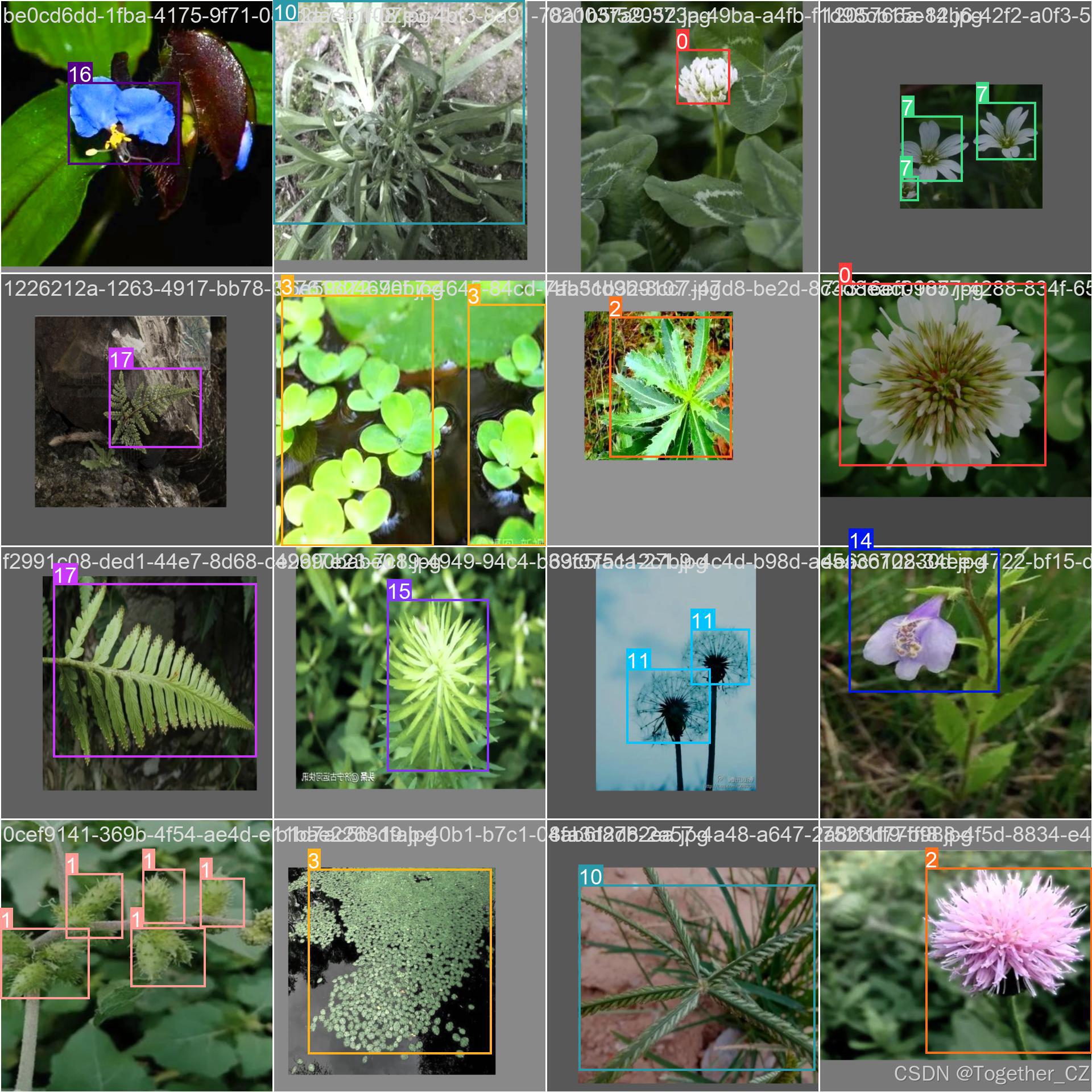
数据实例如下所示:


本文我们自主构建的数据集包含20种常见的杂草数据,类别清单如下所示:
白车轴草
苍耳
刺儿菜
小飞蓬
泽漆
酢浆草
莎草
蛇莓
通泉草
鸭拓草
阴石蕨
马齿苋
浮萍
狗尾巴草
卷耳
苣荬菜
剪刀股
鸡眼草
牛筋草
蒲公英深度神经网络中的计算效率对于目标检测至关重要,尤其是在新模型将速度优先于高效计算(FLOP)的情况下。这种演变在某种程度上已经落后于嵌入式和面向移动的AI对象检测应用程序。这里重点讨论了基于FLOP的高效目标检测计算的神经网络结构的设计选择,并提出了几种优化方法来提高基于YLO的模型的效率。
首先,介绍了一种基于反向瓶颈和信息瓶颈原理的有效主干扩展方法。其次,提出了快速金字塔结构网络(FPAN),旨在促进快速多尺度特征共享,同时减少计算资源。最后提出了一个解耦的网络中网络(DNiN)检测头的设计,以提供快速而轻量级的计算分类和回归任务。
在这些优化的基础上,利用更高效的主干,为对象检测和以YOLO为中心的模型(称为LeYOLO)提供了一种新的缩放范例。在各种资源限制下始终优于现有模型,实现了前所未有的准确性和失败率。值得注意的是,LeYOLO Small在COCO val上仅以4.5次失败(G)获得了38.2%的竞争性mAP分数,与最新最先进的YOLOv9微小模型相比,计算量减少了42%,同时实现了类似的精度。我们的新型模型系列实现了以前未达到的浮点精度比,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOP)的可扩展性,对于0.66、1.47、2.53、4.51、5.8和8.4浮点(G),具有25.2、31.3、35.2、38.2、39.3和41 mAP。
| Models | mAP | Image Size | FLOP (G) |
|---|---|---|---|
| LeYOLONano | 25.2 | 320 | 0.66 |
| LeYOLONano | 31.3 | 480 | 1.47 |
| LeYOLOSmall | 35.2 | 480 | 2.53 |
| LeYOLOSmall | 38.2 | 640 | 4.51 |
| LeYOLOMedium | 39.3 | 640 | 5.80 |
| LeYOLOLarge | 41.0 | 768 | 8.40 |
一共提供了n、s、m和l四款不同参数量级的模型。
这里我们保持完全相同的实验参数设置来进行四款模型的开发训练,等待训练完成之后我们来整体进行各项指标的对比分析。
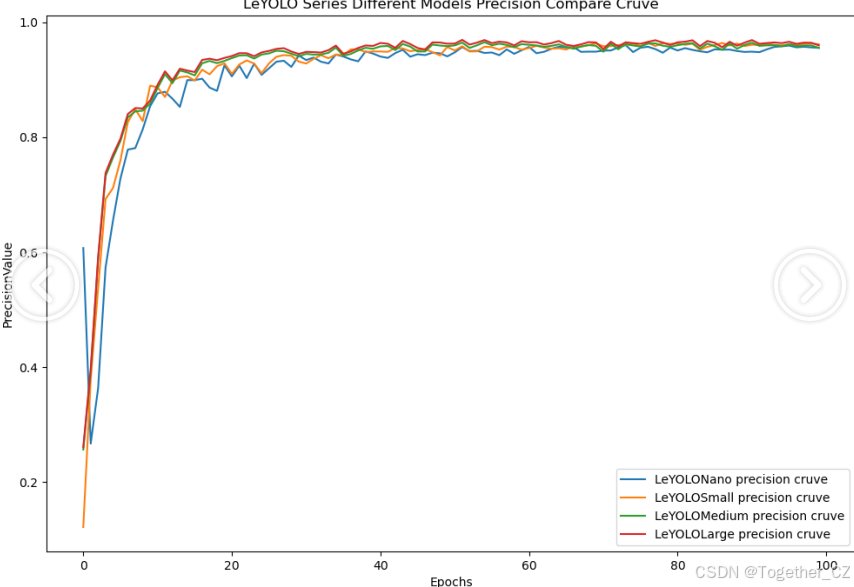
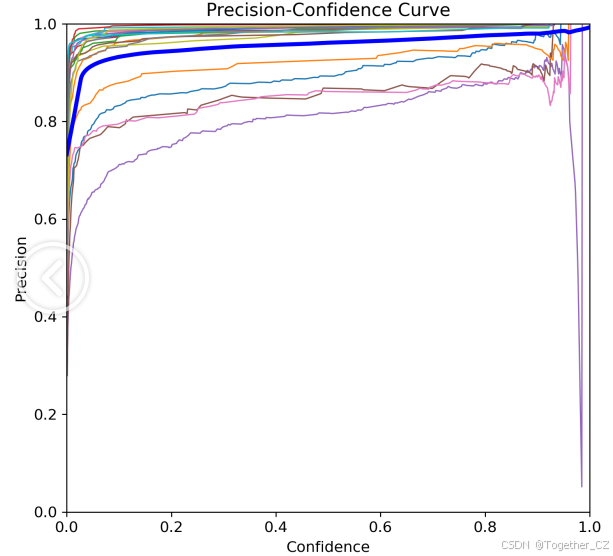
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
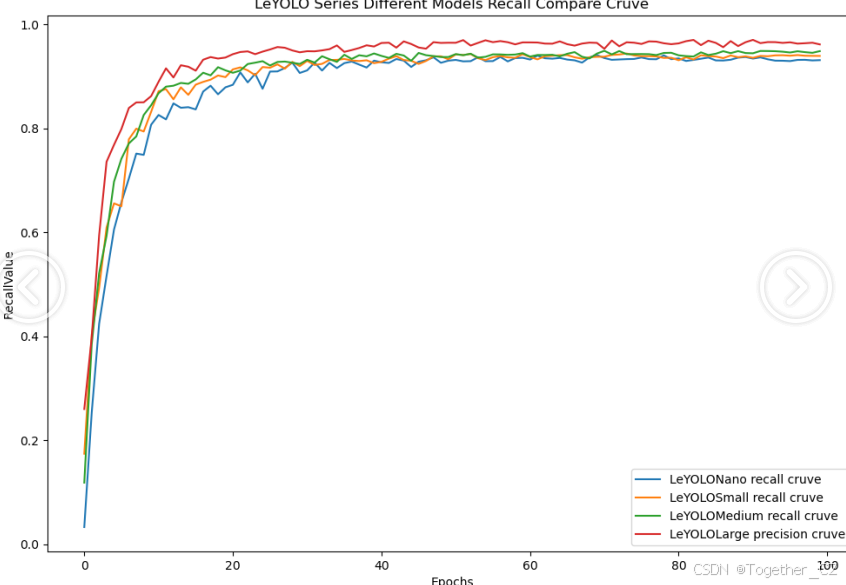
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
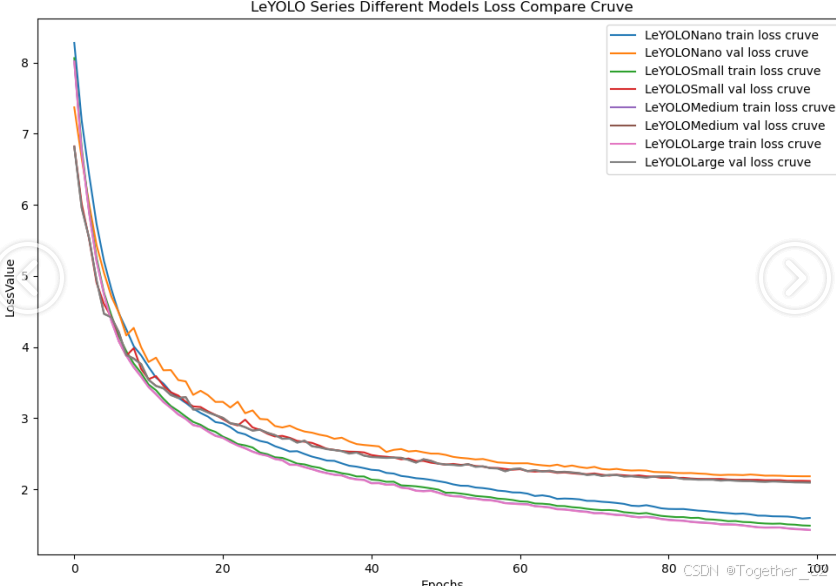
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
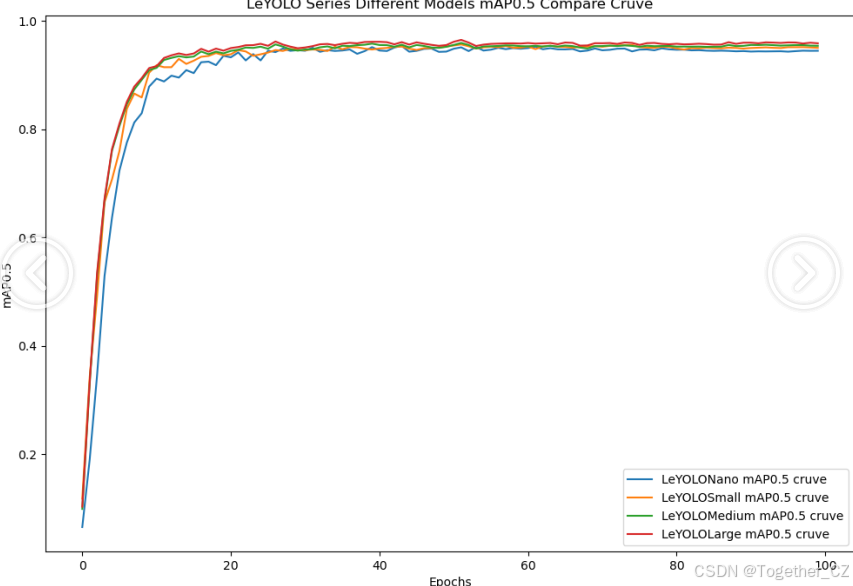
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
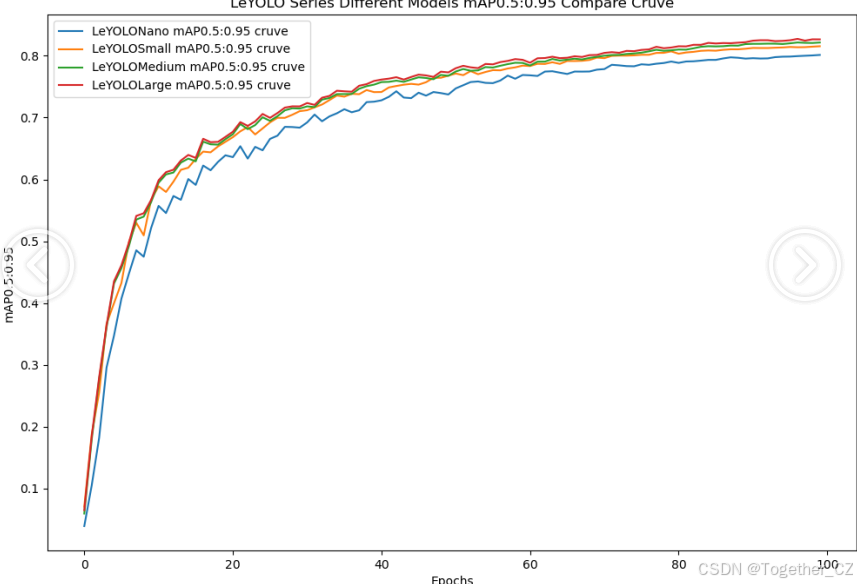
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
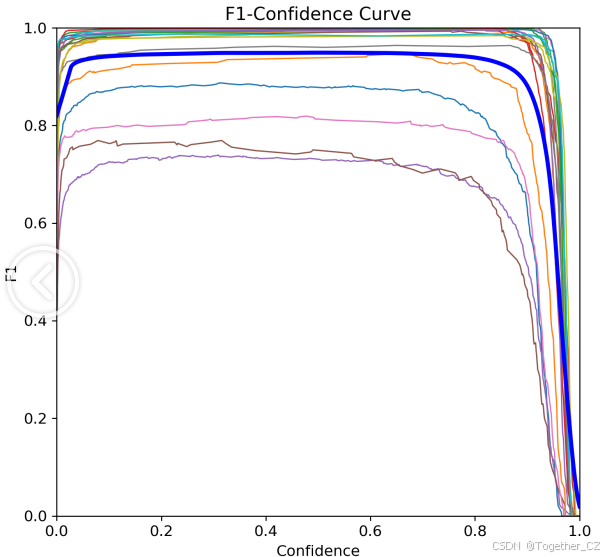
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
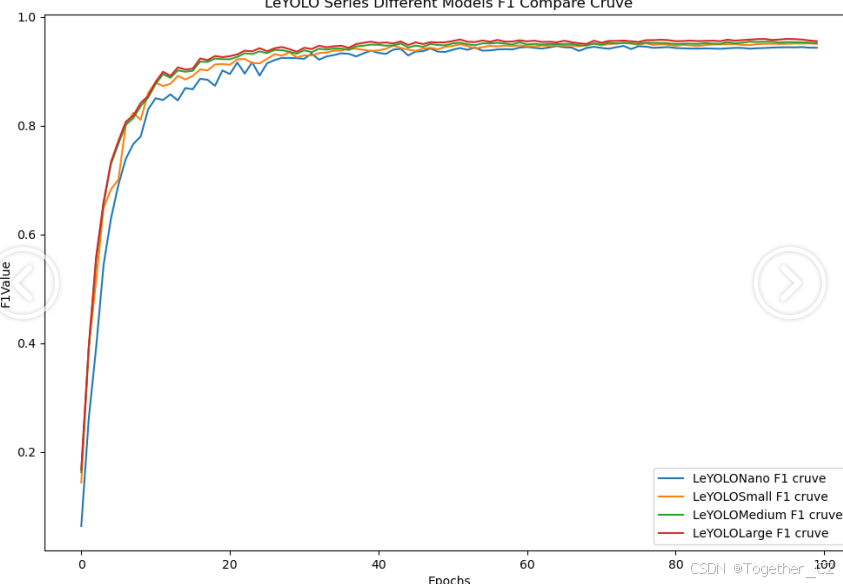
整体对比分析来看:不难发现四款不同参数量级的模型最终达到了较为相似的结果,n系列的模型最终的效果稍微劣一点,其余三款模型效果十分接近这里综合参数量考虑我们最终选定了s系列的模型来作为线上的推理计算模型。
接下来看下s系列模型的详细情况。
【离线推理实例】

【Batch实例】
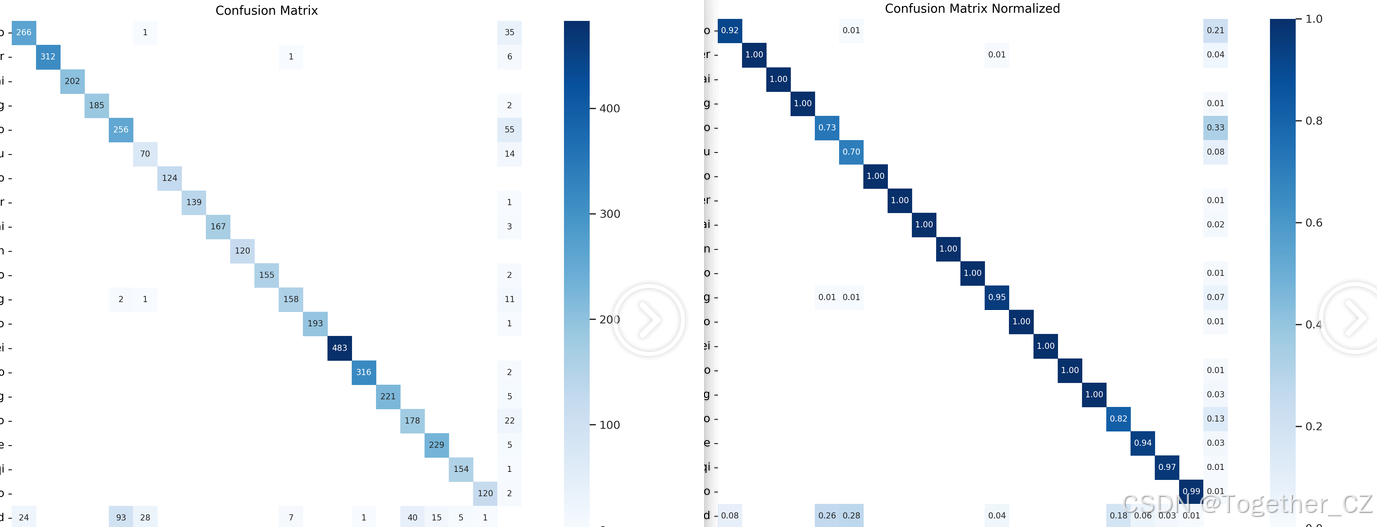
【混淆矩阵】
【F1值曲线】
【Precision曲线】
【PR曲线】
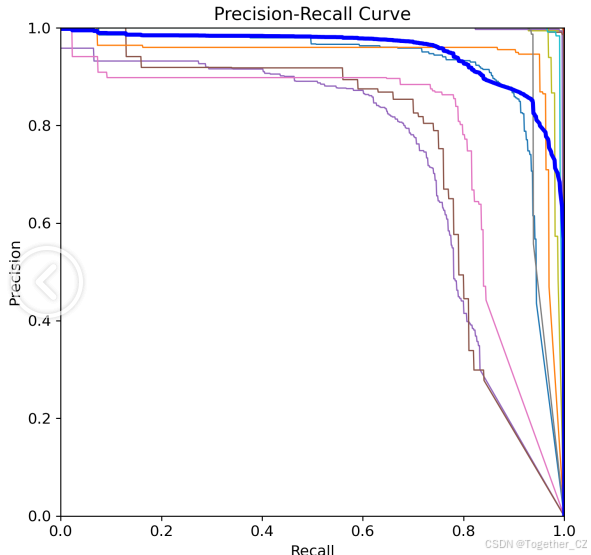
【Recall曲线】
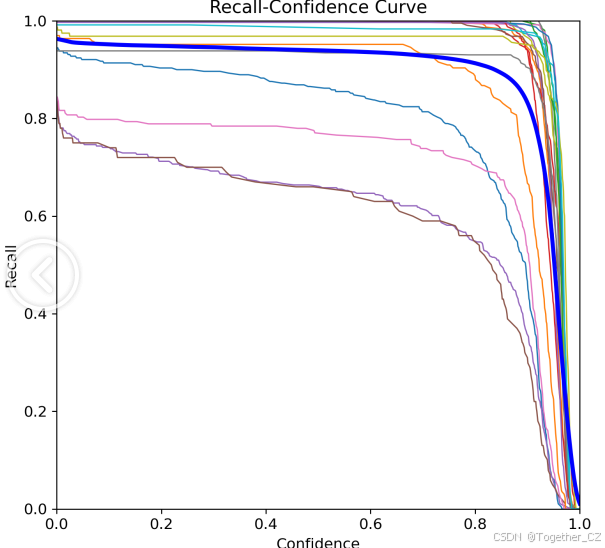
【训练可视化】
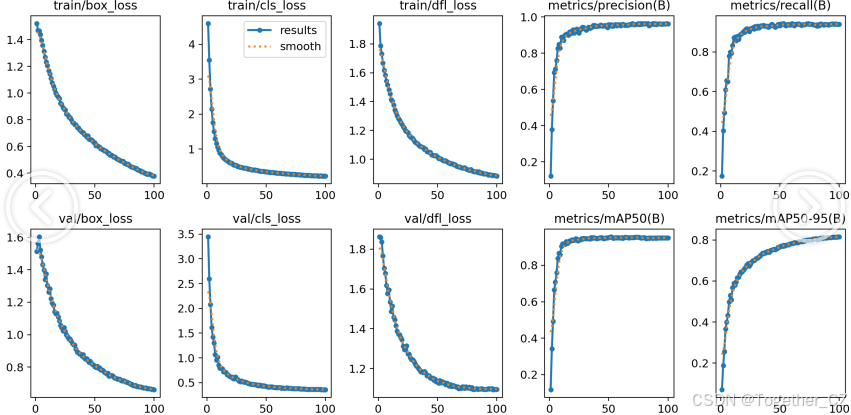
本文仅仅站在软件模型层面从实验的角度探索分析智能模型开发的可行性,希望以此抛砖引玉,期望早日看到真正落地越来越多有助于农业发展的新型科技技术,智能激光除草技术作为农业智能化、自动化的重要组成部分,具有广阔的应用前景。一方面,它可以提高农田的管理效率,降低人力成本;另一方面,它还可以改善农田的生态环境,促进农业的可持续发展。随着技术的不断进步和应用的不断拓展,智能激光除草技术有望在未来成为农业领域的重要支柱之一。我们期待着这种技术能够为农业生产带来更多的便利和效益,推动农业领域的创新发展。
感兴趣的话也可以试试!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











