






晚上闲下来的时候看到一篇比较有意思的文章InfLLM,旨在提高大型语言模型(LLMs)处理极长序列的能力,而无需进行额外的训练。主要工作内容包括:
-
问题背景:现有的LLMs在预训练时序列长度受限,无法处理更长的序列,因为存在领域外和干扰问题。常见的解决方案通常涉及在更长的序列上持续预训练,但这会引入昂贵的计算开销和模型能力不可控的变化。
-
方法介绍:InfLLM采用了一种基于记忆的无训练方法,通过将远距离上下文存储到额外的记忆单元中,并采用高效的机制来查找与令牌相关的单元以进行注意力计算。具体来说,InfLLM结合了滑动窗口注意力和块级上下文记忆机制,确保LLMs在有限的上下文窗口内高效处理长序列,并捕捉长距离依赖关系。
-
实验验证:作者在两个广泛使用的基准测试(∞-Bench和Longbench)上验证了InfLLM的有效性。实验结果表明,InfLLM使预训练在包含几千个令牌的序列上的LLMs能够在没有任何额外训练的情况下取得与在长序列上持续训练的竞争基线相当的表现。此外,InfLLM在处理包含1,024K令牌的极长序列时仍然能够有效捕捉长距离依赖关系。
-
与现有方法的比较:文章还比较了InfLLM与持续训练模型、检索增强生成(RAG)方法的性能和效率。结果显示,InfLLM在无需额外训练的情况下,能够在更少的计算消耗和内存使用下达到与持续训练模型相当甚至更好的表现。
-
未来工作:作者计划进一步探索上下文记忆模块的高效训练,以及将键值缓存压缩方法与InfLLM结合,以进一步减少计算和内存成本。
InfLLM通过引入高效的上下文记忆机制,显著提高了LLMs处理极长序列的能力,展示了在流应用场景中的潜力。这里主要是自己的整体阅读记录,感兴趣的话可以参考一下,如果想要直接阅读原文,可以来这里,如下所示:

摘要
大型语言模型(LLMs)在处理长流输入(如LLM驱动的代理)的实际应用中已成为基石。然而,现有LLMs在预训练时序列长度受限,无法处理更长的序列,因为存在领域外和干扰问题。常见的解决方案通常涉及在更长的序列上持续预训练,这将引入昂贵的计算开销和模型能力不可控的变化。在本文中,我们揭示了LLMs在无需任何微调的情况下理解极长序列的内在能力。为此,我们提出了一种基于记忆的无训练方法,称为InfLLM。具体来说,InfLLM将远距离上下文存储到额外的记忆单元中,并采用一种高效的机制来查找与令牌相关的单元以进行注意力计算。因此,InfLLM允许LLMs在有限的上下文窗口内高效处理长序列,并很好地捕捉长距离依赖关系。无需任何训练,InfLLM使预训练在包含几千个令牌的序列上的LLMs能够与在长序列上持续训练的竞争基线取得相当的表现。即使序列长度扩展到1,024K,InfLLM仍然能够有效捕捉长距离依赖关系。我们的代码可以在这里找到。如下所示:
1 引言
最近,大型语言模型(LLMs)在各种任务中取得了深刻的成就(Brown et al., 2020; Bommasani et al., 2021; Han et al., 2021; Touvron et al., 2023; Meta, 2024)。它们遵循复杂指令的能力为实现人工通用智能带来了希望(OpenAI, 2023; Ouyang et al., 2022)。随着LLM驱动应用的蓬勃发展,如代理构建(Park et al., 2023; Qian et al., 2023; Wang et al., 2024a)和具身机器人(Driess et al., 2023; Liang et al., 2023),增强LLMs处理流长序列的能力变得日益重要。例如,LLM驱动的代理需要根据所有历史记忆处理从外部环境连续接收的信息,这需要强大的处理长流序列的能力。
由于未见过的长输入(Han et al., 2023)和分散注意力的噪声上下文(Liu et al., 2023; Tworkowski et al., 2023)的限制,大多数预训练在仅包含几千个令牌的序列上的LLMs无法处理更长的序列(Press et al., 2022; Zhao et al., 2023)。常见的解决方案通常涉及在更长的序列上持续训练LLMs,但这会导致巨大的成本,并需要大规模的高质量长序列数据集(Xiong et al., 2023; Li et al., 2023)。而在更长序列上的持续训练过程可能会削弱LLMs在短上下文上的表现(Ding et al., 2024)。鉴于此,在不进行进一步训练的情况下提高LLMs的长度泛化性受到了广泛关注,试图使在短序列上训练的LLMs直接适用于长序列。
在本文中,我们提出了一种基于记忆的无训练方法,名为InfLLM,用于以有限的计算成本流式处理极长序列。具体来说,InfLLM将滑动窗口注意力(Xiao et al., 2023; Han et al., 2023)与高效的上下文记忆相结合,每个令牌仅关注局部上下文和记忆中的相关上下文。考虑到注意力分数矩阵的稀疏性,处理每个令牌通常只需要其上下文的一小部分(Zhang et al., 2023b),其余不相关的上下文作为噪声,导致注意力分散问题(Tworkowski et al., 2023)。因此,我们构建了一个包含远距离上下文信息的外部记忆。在每个计算步骤中,仅选择记忆中的相关信息,忽略其他不相关的噪声。由于这一点,LLMs可以使用有限大小的窗口理解整个长序列并避免噪声上下文。
长序列中大量的噪声上下文令牌对有效和高效的记忆查找提出了重大挑战。为了解决这些挑战,我们设计了一种块级上下文记忆机制。具体来说,InfLLM将过去的键值向量组织成块,每个块包含一个连续的令牌序列。在每个块中,选择接收最高注意力分数的语义上最重要的令牌作为后续记忆查找中相关性计算的单元表示。这种设计提供了两个主要好处:(1)有效的查找:每个块的连贯语义可以更有效地满足相关信息检索的要求,相比于单个令牌。单元表示的选择最小化了不重要令牌在相关性计算中的干扰,提高了整体记忆查找的命中率。(2)高效的查找:块级记忆单元消除了每个令牌相关性计算的需求,显著降低了计算成本。此外,块级单元确保了连续的内存访问,从而最小化了内存加载成本并增强了计算效率。此外,考虑到大多数单元的使用频率较低,InfLLM将所有单元卸载到CPU内存,并仅在GPU内存中动态保留经常使用的单元,显著减少了GPU内存使用。值得注意的是,InfLLM中的块级记忆机制不涉及任何额外的训练,可以直接应用于任何LLMs。
为了评估InfLLM的有效性,我们采用Mistral-7B-inst-v0.2(Jiang et al., 2023)和Llama-3-8B-Instruct(Meta, 2024)作为基础模型,这些模型预训练在包含不超过32K和8K令牌的序列上。我们使用两个广泛使用的基准测试,∞∞-Bench(Zhang et al., 2023a)和Longbench(Bai et al., 2023)进行评估。特别是,∞∞-Bench中的平均序列长度超过100K令牌,这对大多数现有LLMs来说具有挑战性。与通常在更长序列上持续训练LLMs的典型方法相比,实验结果表明,InfLLM使预训练在包含几千个令牌的序列上的LLMs能够在没有任何额外训练的情况下取得相当的表现。此外,我们在包含1,024K令牌的序列上检验了InfLLM,InfLLM仍然能够有效捕捉长距离依赖关系,展示了InfLLM在涉及长流输入场景中的潜力。
2 相关工作
使LLMs处理长序列的工作已被广泛研究(Dong et al., 2023; Tay et al., 2023; Huang et al., 2023),通常可以分为两种主要方法:上下文长度外推和高效上下文计算。前者旨在使在短序列上训练的LLMs处理更长的序列。后者专注于增强注意力层的计算效率,允许从零开始高效预训练LLMs以处理更长的序列。尽管本文的重点是上下文长度外推,但我们也会详细介绍高效上下文计算。我们还会介绍基于记忆的模型的相关工作。
上下文长度外推。由于高计算和内存需求,LLMs的训练通常限制在短序列上。直接将LLMs应用于长序列将受到由长且嘈杂的输入引起的领域外和干扰挑战(Han et al., 2023; Tworkowski et al., 2023)。因此,上下文长度外推作为一种在不引入额外训练的情况下提高LLMs序列长度的方法受到了关注。最早的方法涉及在预训练期间设计新的相对位置编码机制(Press et al., 2022; Sun et al., 2023)。随后的研究主要集中在广泛使用的旋转位置嵌入(RoPE)(Su et al., 2021),并提出通过缩放或重用原始位置索引实现长度外推(Chen et al., 2023b; Peng et al., 2023; Chen et al., 2023a; Jin et al., 2024; An et al., 2024)。这些工作可以缓解未见长度带来的领域外问题,但无法缓解嘈杂上下文的干扰挑战。为了解决这个问题,Xiao et al. (2023) 和 Han et al. (2023) 采用了滑动窗口注意力机制,直接丢弃所有远距离上下文以流式读取极长序列。然而,由于这些模型忽略了远距离令牌的信息,它们无法捕捉长文本理解的长距离依赖关系。在本文中,InfLLM利用滑动窗口注意力机制,并额外构建了一个高效的上下文记忆,为LLMs提供相关上下文信息,使LLMs能够有效读取和理解极长序列。
高效上下文计算。注意力层的二次计算复杂性是限制LLMs处理长序列能力的主要因素。因此,许多学者致力于设计高效的注意力机制,包括利用稀疏注意力(Zaheer et al., 2020; Beltagy et al., 2020; Child et al., 2019; Ainslie et al., 2020; Zhao et al., 2019),使用核函数近似注意力计算(Kitaev et al., 2020; Wang et al., 2020; Katharopoulos et al., 2020),以及用线性复杂度的状态空间模型替换注意力层(Gu et al., 2022; Gu & Dao, 2023)。这些方法需要在模型架构上进行修改,需要重新训练模型。同时,许多研究人员通过驱逐无用的键值向量来提高推理效率,以减少计算量(Zhang et al., 2023b; Li et al., 2024; Ge et al., 2023)。这些方法由于未见位置引起的领域外问题,无法在不进行进一步训练的情况下外推LLMs的上下文窗口。
基于记忆的模型。记忆网络已被研究了几十年,被证明在为模型提供额外知识和信息存储能力方面是有效的(Graves et al., 2014; Weston et al., 2015; Sukhbaatar et al., 2015; Miller et al., 2016)。随着预训练模型的成功,记忆层也逐渐应用于递归变换器层的训练过程中,使模型能够递归处理长序列(Dai et al., 2019; Rae et al., 2020; Khandelwal et al., 2020; Wu et al., 2022; Bertsch et al., 2023; Munkhdalai et al., 2024)。这些工作将序列分割成段,分别编码每个段,并使用记忆存储前一段的上下文信息。尽管这些方法在概念上与InfLLM相似,但它们涉及对模型架构的修改,并需要进一步训练整个模型。相比之下,我们旨在探索LLMs的固有特性,并提出了一种用于长文本理解的无训练记忆模块。
3 方法论
如图1所示,InfLLM构建了一个无训练的上下文记忆,以高效地为每个令牌提供高度相关的上下文,赋予滑动窗口注意力机制捕捉长距离依赖关系的能力。
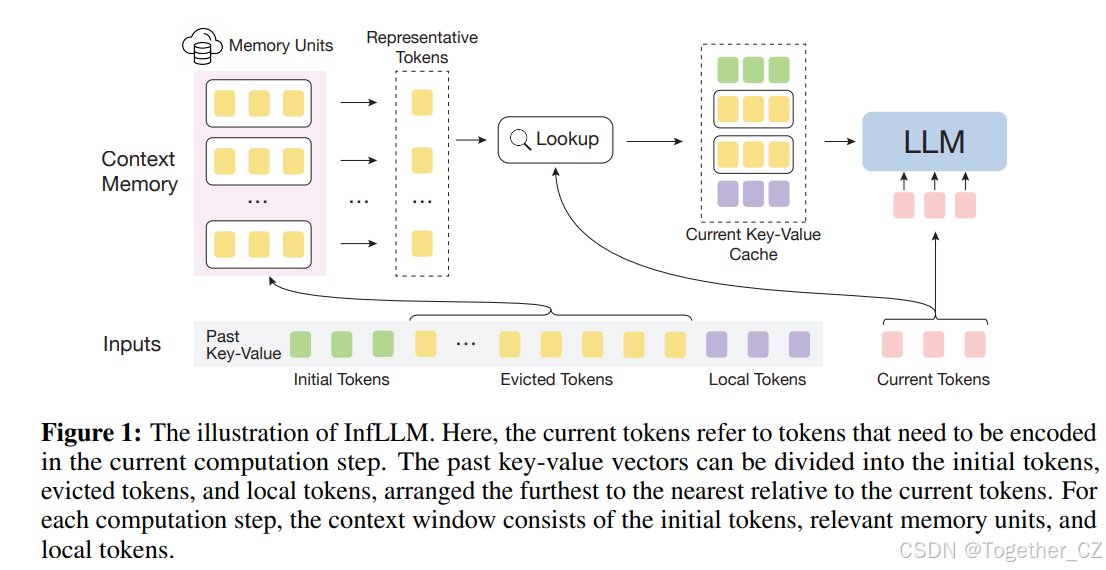
图1:InfLLM的示意图。这里,当前令牌指的是在当前计算步骤中需要编码的令牌。过去的键值向量可以分为初始令牌、驱逐令牌和局部令牌,从最远到最近排列,相对于当前令牌。对于每个计算步骤,上下文窗口由初始令牌、相关记忆单元和局部令牌组成。
总体框架
提高LLMs长度泛化性的主要限制来自于长且嘈杂的上下文引起的领域外和干扰问题。为了解决这些问题,我们采用了滑动窗口注意力机制,每个步骤仅考虑局部令牌(Xiao et al., 2023; Han et al., 2023)。此外,我们构建了一个额外的上下文记忆模块,以提供相关上下文信息来捕捉长距离依赖关系。

上下文记忆
先前的研究发现,LLMs的注意力分数矩阵是稀疏的,我们可以通过仅保留一小部分键值向量来生成相同的输出(Zhang et al., 2023b)。受此启发,我们设计了一个上下文记忆,以高效地从大规模驱逐令牌中查找相关上下文并忽略不相关的上下文以节省计算成本。最直观的方法是为每个过去的键值向量构建一个包含令牌级记忆单元的记忆,每个注意力头分别进行,这将导致大量的记忆单元、不可接受的计算和非连续的内存访问成本。因此,考虑到长序列的局部语义连贯性,我们将过去的键值向量分割成块,每个块作为一个记忆单元,并在块级别进行记忆查找以减少成本同时保持性能。
在本小节中,我们将介绍块级记忆单元的详细信息。然后我们介绍为选定的相关记忆单元分配位置嵌入的方法和上下文记忆的缓存管理。
块级记忆单元。块级记忆单元相比于令牌级单元可以节省计算成本。它也为单元表示带来了新的挑战,单元表示应该包含整个单元的语义以进行有效的相关性分数计算,并且内存高效以实现上下文长度的可扩展性。传统方法通常涉及训练一个额外的编码器将给定单元投影到一个低维向量。受隐藏状态中令牌冗余的启发(Goyal et al., 2020; Dai et al., 2020),我们从包含块中选择几个代表性令牌作为单元表示。对于第mm个令牌,我们定义代表性分数为:

值得注意的是,代表性令牌选择是一种无训练的方法来获得单元表示。这里,我们也可以训练一个额外的编码器来生成更具表现力的单元表示,这留待未来工作。
位置编码。现有的LLM训练通常使用有限数量的位置编码,直接应用于更长的序列处理时会遇到领域外分布挑战(Han et al., 2023)。此外,在InfLLM中,当前的键值缓存由一些不连续的文本块组成,直接为它们分配连续的位置编码也会导致不匹配问题并混淆模型。因此,受先前工作(Raffel et al., 2020; Su, 2023)的启发,我们将局部窗口大小之外的所有令牌分配相同的位置编码。具体来说,上下文记忆单元中的令牌与当前令牌之间的距离设置为![]() 。
。
缓存管理。为了使LLMs在捕捉长上下文中包含的语义相关性的同时处理极长的序列流,我们需要保留所有记忆单元并在每个计算步骤中查找它们。考虑到大多数单元的使用频率较低,我们采用了一种卸载机制,将大多数记忆单元存储在CPU内存中,仅在GPU内存中保留当前步骤所需的记忆单元和代表性令牌。此外,考虑到长序列的语义连贯性,其中相邻令牌通常需要相似的记忆单元,我们在GPU内存中分配了一个缓存空间,使用最近最少使用策略进行管理。这种方法允许使用有限的GPU内存高效编码极长序列。根据观察,我们的卸载机制使InfLLM能够处理包含100K令牌的序列,仅使用26G VRAM。此外,我们的GPU缓存的未命中率相当低,这意味着卸载机制在内存加载时没有引入显著的时间开销,同时节省了GPU内存使用。详细信息可以在附录中找到。
此外,对于极长的序列,每个单元的代表性令牌也可以卸载到CPU内存,构建一个高效的k近邻索引,从而进一步降低计算复杂性。
4 实验
设置
数据集。我们采用广泛使用的长文档基准测试中的代表性任务,∞-Bench(Zhang et al., 2023a)进行评估。我们采用英文数据集进行评估,因为基础模型主要在英文语料库上预训练。∞∞-Bench中的数据集涵盖了问答、摘要、上下文检索和数学计算等多样任务。∞-Bench的平均长度为145.1K,95%分位数的序列长度为214K,远超基础模型的最大长度。这些数据集的详细统计信息和任务描述列在附录中。此外,我们还在LongBench(Bai et al., 2023)上进行了评估。LongBench的结果可以在附录中找到。
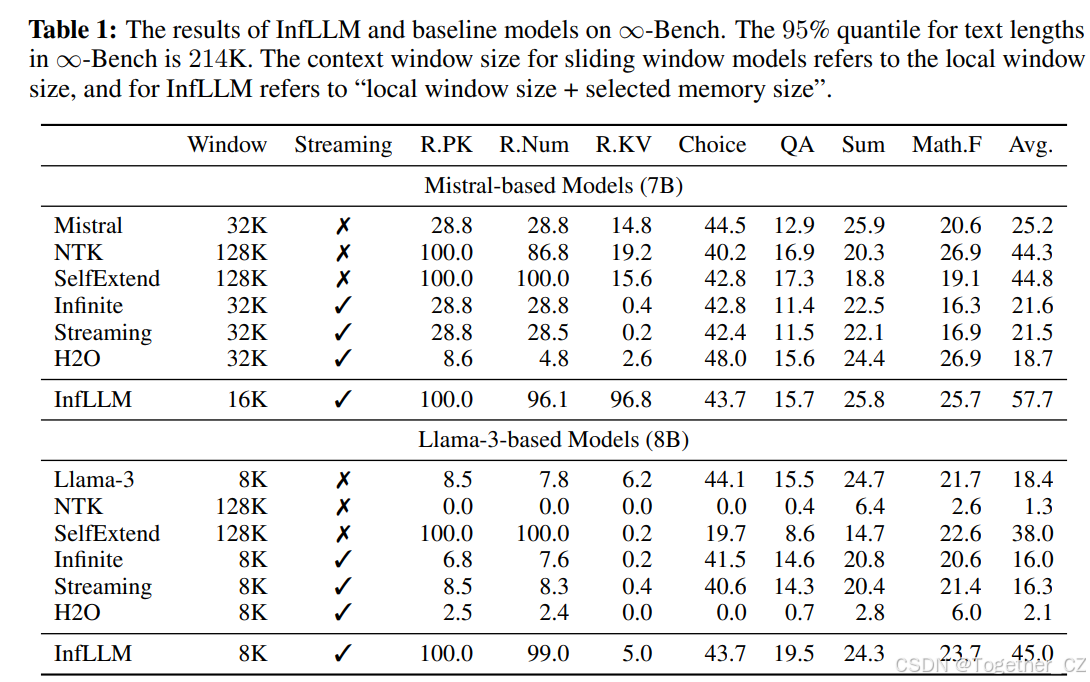
表1:InfLLM和基线模型在∞-Bench上的结果。∞-Bench中文本长度的95%分位数为214K。滑动窗口模型的上下文窗口大小指的是局部窗口大小,而InfLLM的上下文窗口大小指的是“局部窗口大小 + 选定的记忆大小”。
基线模型。为了验证我们提出的方法的有效性,我们将InfLLM与以下竞争基线模型进行比较:(1)原始模型:我们展示了没有上下文长度外推的原始LLMs的性能。(2)位置缩放和重用:NTK-aware scaled RoPE(NTK)(LocalLLaMA, 2023)设计了一种非线性插值方法,基本上改变了RoPE的旋转基。SelfExtend重用相邻令牌的位置ID,使得扩展的相对位置在训练上下文窗口的范围内。(3)滑动窗口:这些方法应用滑动窗口机制丢弃远距离上下文,包括LM-Infinite(Infinite)(Han et al., 2023)和StreamingLLM(Stream)(Xiao et al., 2023)。因此,对于每个注意力计算步骤,输入长度不超过上下文窗口。(5)键值驱逐:键值驱逐方法旨在在长序列处理过程中丢弃无用的键值向量,从而通常用于减少计算复杂性。我们展示了广泛使用的键值驱逐方法H2O(Zhang et al., 2023b)的结果。键值驱逐方法由于未见位置嵌入而无法泛化到更长的序列,预计表现不佳。
在这里,InfLLM和带有滑动窗口机制的模型可以用于处理极长的流输入。对于NTK和SelfExtend,我们将上下文窗口扩展到128K,使LLMs能够处理∞-Bench中的大多数实例。
实现细节
在本文中,我们的目标是使在有限序列长度上训练的LLMs无需进一步训练即可读取和理解极长序列。我们采用Mistral-7B-Instruct-v0.2(Jiang et al., 2023)和Llama-3-8B-Instruct(Meta, 2024)作为我们的基础模型。Mistral-7B-Instruct-v0.2和Llama-3-8B-Instruct的最大长度分别为32K和8K。
对于我们的模型,我们将编码块大小设置为512,过去键值向量的记忆单元大小![]() 设置为128。代表性令牌的数量
设置为128。代表性令牌的数量![]() 设置为4。对于基于Mistral和Llama-3的InfLLM,我们将局部窗口大小设置为4K。对于基于Mistral的InfLLM,我们为每个步骤加载96个相关记忆单元,对于基于Llama-3的InfLLM,我们加载32个相关记忆单元。初始令牌的数量对于LM-Infinite、StreamingLLM和InfLLM设置为128,以覆盖系统提示和任务描述。我们采用FlashAttention(Dao, 2023)加速所有基线模型的实验。更多细节请参阅附录。
设置为4。对于基于Mistral和Llama-3的InfLLM,我们将局部窗口大小设置为4K。对于基于Mistral的InfLLM,我们为每个步骤加载96个相关记忆单元,对于基于Llama-3的InfLLM,我们加载32个相关记忆单元。初始令牌的数量对于LM-Infinite、StreamingLLM和InfLLM设置为128,以覆盖系统提示和任务描述。我们采用FlashAttention(Dao, 2023)加速所有基线模型的实验。更多细节请参阅附录。
主要结果
基于Mistral和Llama-3的模型的结果如表1所示。从结果中,我们可以观察到:(1)与也可以读取极长序列的滑动窗口机制模型相比,我们的方法表现出显著的性能提升。这表明InfLLM中的上下文记忆可以准确地补充LLMs的相关上下文信息,使其能够高效地理解和推理长序列。(2)位置缩放和重用方法,NTK和SelfExtend,在将序列长度扩展到128K时倾向于牺牲模型性能。这是因为这些模型无法解决由嘈杂上下文引起的干扰问题。相比之下,我们的模型可以持续提高极长序列的性能。我们成功地将Llama-3从8K长度扩展到超过其长度的16倍,在∞-Bench上取得了令人称赞的表现。(3)位置缩放和重用方法可以增加LLMs的最大序列长度,但也增加了计算和内存成本,限制了这些方法的应用。相比之下,InfLLM利用块级记忆和卸载机制,在有限资源内实现长序列的高效处理。
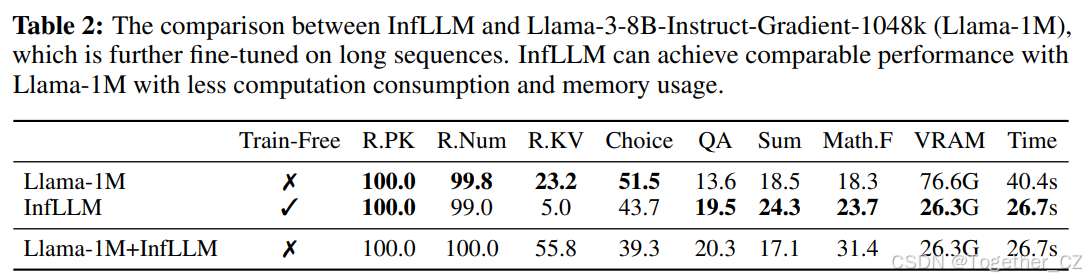
表2:InfLLM与Llama-3-8B-Instruct-Gradient-1048k(Llama-1M)的比较,后者在长序列上进行了进一步微调。InfLLM可以在更少的计算消耗和内存使用下达到与Llama-1M相当的表现。
与持续训练模型的比较
在本文中,我们专注于在不进行额外训练的情况下扩展LLMs的上下文窗口。在本节中,我们将InfLLM与在长序列上进行持续训练的模型在性能和效率方面进行比较。具体来说,我们选择了Llama-3-8B-Instruct-Gradient-1048k(Llama-1M)3,该模型在长文本数据和聊天数据集上进一步微调,将其上下文窗口扩展到1048K。此外,我们还在Llama-1M上应用了InfLLM,将局部窗口设置为4K,选定的记忆大小设置为4K。我们在∞-Bench、GPU内存使用和时间消耗方面展示了结果,如表2所示。从结果中,我们可以观察到:(1)与在长序列上进行持续训练的模型相比,InfLLM可以在没有任何额外训练的情况下取得相当甚至更好的结果。这表明LLMs本身具有识别长序列中的关键信息并有效理解和推理的能力。值得注意的是,Llama-1M需要512个GPU进行持续训练,这对许多研究人员来说是不可承受的。相比之下,InfLLM不需要任何训练,这表明了InfLLM的实用性。(2)在效率方面,InfLLM在时间消耗上减少了34%,GPU内存使用减少了34%,相比于全注意力模型。此外,在256K令牌的更长序列长度下,全注意力基线由于内存不足而失败,而InfLLM可以在单个GPU上高效处理长达1024K令牌的序列。(3)InfLLM也可以直接与持续训练的模型结合,并在仅8K上下文窗口的情况下取得相当甚至更好的结果。这表明InfLLM也可以作为一种提高推理速度的高效方法。
Footnote 3: https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k
与检索增强生成的比较
InfLLM利用LLMs的内在能力构建了一个上下文记忆,用于收集与令牌相关的信息,这一概念类似于检索增强生成(RAG)(Lewis et al., 2020; Nakano et al., 2021)。然而,与使用RAG将历史上下文视为可搜索数据库以进行长序列理解(Xu et al., 2023)相比,InfLLM具有几个优势:(1)无训练:RAG需要额外的检索数据来训练检索模型,而InfLLM是无训练的,适用于任何LLMs。此外,RAG还需要微调LLMs以适应由检索知识增强的输入。(2)更广泛的适用性:RAG模型通常受其检索组件性能的限制。此外,现有的检索模型会遇到分布外问题,难以在任务外表现良好(Lin et al., 2023; Muennighoff et al., 2023)。这种限制会严重影响RAG系统的整体性能。相比之下,InfLLM对任务没有特定要求,可以方便地用于长序列。
表3:InfLLM与RAG的比较。
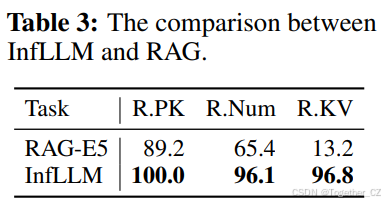
为了验证InfLLM的泛化能力,我们在三个上下文检索任务上将RAG与InfLLM进行了比较。我们使用E5-mistral-TB-instruct(Wang et al., 2024b)作为检索模型。结果如表3所示。我们的研究结果表明,即使没有额外的数据或训练,InfLLM也能持续优于RAG模型,突显了其优越的泛化能力。依赖外部检索模型使得RAG在处理多样任务时不够灵活。
记忆设置的影响
InfLLM依赖上下文记忆来查找相关信息。我们进一步探讨了上下文记忆中核心组件的影响,特别是代表性令牌和记忆单元。结果如图2所示。
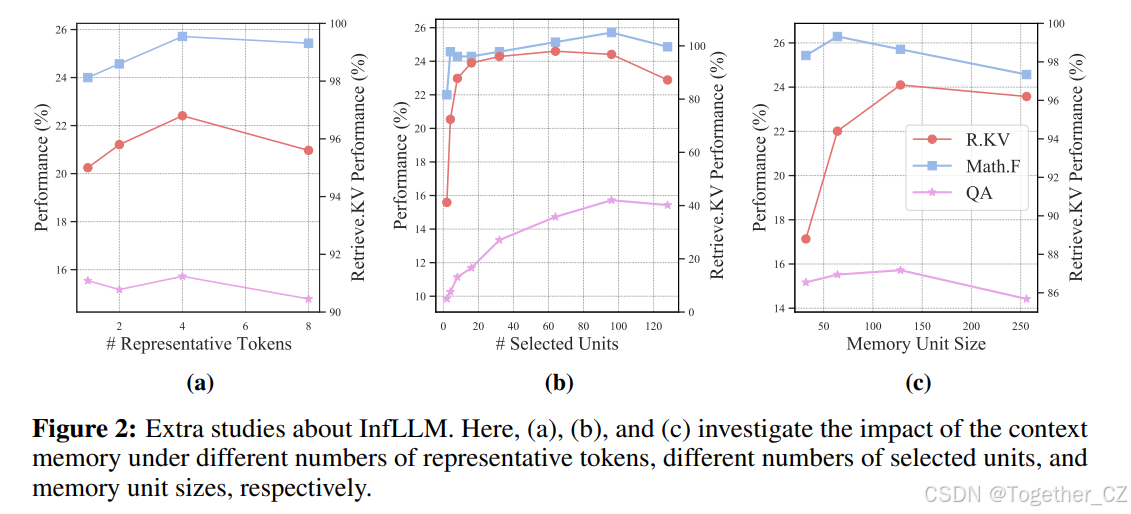
图2:关于InfLLM的额外研究。这里,(a)、(b)和(c)分别研究了在不同数量的代表性令牌、不同数量的选定单元和不同记忆单元大小下上下文记忆的影响。
不同数量的代表性令牌。InfLLM将键值向量分割成记忆单元,并从单元中选择几个代表性令牌作为单元表示。因此,这些代表性令牌在语义上表示整个单元的能力直接影响模型的性能。我们进行了实验,代表性令牌的数量为{1,2,4,8}。结果如图1(a)所示。我们观察到,随着代表性令牌数量的增加,模型性能有改善的趋势,这表明更多的代表性令牌倾向于更好地表示记忆单元的语义内容。然而,值得注意的是,当代表性令牌数量达到8时,性能略有下降。这种下降可以归因于将语义上不相关的令牌作为单元表示。更高效和强大的单元表示将进一步提高未来工作的模型性能。
不同数量的选定单元。选定的单元用于为LLMs提供相关上下文。我们将单元数量设置为{2,4,8,16,32,64,96,128}进行实验。从图1(b)中,我们可以观察到,随着选定单元数量从1增加到32,模型性能显著提高,这是由于更多单元意味着相关内容的召回率更高。更大的单元数量也会增加所需的内存调度时间和注意力计算时间。因此,进一步提高查找准确性仍然是提高InfLLM效率的关键方向。
不同的记忆单元大小。每个记忆单元应该是一个连贯的语义单元。过大的单元大小会阻碍精确查找,而过小的单元大小会增加记忆查找的计算开销。我们评估了单元大小为{32,64,128,256}的InfLLM,并将总上下文长度保持为12K。结果如图1(c)所示。我们可以观察到,由于输入序列的特征不同,不同任务的最佳单元大小不同。例如,在Retrieve.KV中,键值对构成一个语义单元,而在Math.Find中,单个数字代表一个语义单元。使用启发式规则分割上下文很容易导致次优性能。因此,探索如何动态分割上下文是未来研究的重要方向。
消融研究
为了进一步验证动态记忆查找和单元表示的有效性,我们在本节中进行了消融研究。结果如表4所示。
表4:消融研究的结果。
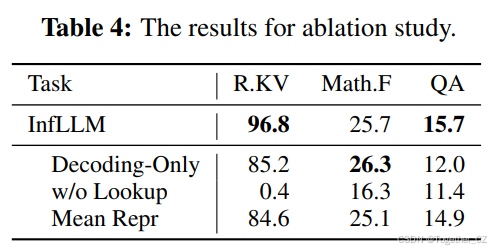
上下文记忆查找。InfLLM在输入编码和输出解码步骤中都采用动态上下文记忆查找,以实现全面的长文本理解。我们展示了仅在输出解码中进行查找(Decoding-Only)和没有任何记忆查找(w/o Lookup)的InfLLM结果。可以观察到,随着记忆查找次数的减少,模型性能显著下降。这表明远距离上下文信息对于长输入编码和答案生成阶段都至关重要。模型需要整合长距离上下文以生成连贯的上下文记忆进行输入理解。LLM应该从大量过去的上下文信息中收集有用信息以生成正确的答案。
单元表示。我们设计了一个块级记忆用于高效的上下文信息查找。我们选择几个代表性令牌作为单元表示进行相关性计算。我们展示了InfLLM使用另一种无训练表示方法(Mean Repr)的结果,该方法通过平均记忆单元中的键向量来计算表示。从结果中,我们可以观察到,使用平均表示的InfLLM也能表现出竞争性能。这表明LLMs中的原始注意力向量在相关性分数计算中是有效的,探索更高效的单元表示是未来工作的重要方向。
扩展到1,024K上下文
为了评估InfLLM在极长序列上的有效性,在本小节中,我们将序列长度扩展到1024K,以评估InfLLM在长序列中捕捉上下文相关性的能力。具体来说,我们采用∞∞-Bench中的Retrieve.PassKey任务进行评估。该任务要求LLMs在长且嘈杂的上下文中找到一个5位序列,这需要LLMs在长序列中有效定位相关信息。我们自动生成包含{32,64,128,256,512,768,1024}千令牌的输入,对于每个长度,我们生成50个实例进行评估。我们采用Mistral作为基础模型。
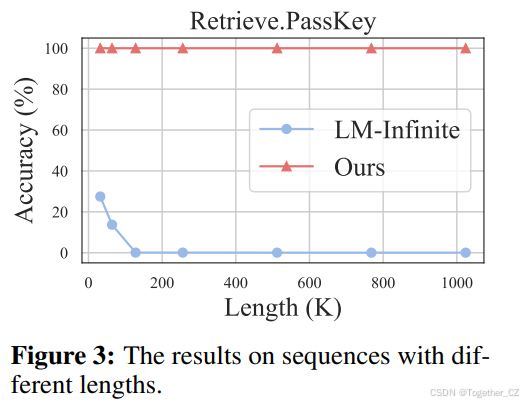
图3:不同长度序列的结果。
结果如图3所示。从结果中,我们可以观察到,InfLLM可以准确地从长度噪声中定位关键信息,即使上下文长度扩展到1024千令牌,也能达到100%的准确率。然而,LM-Infinite只能关注局部窗口内的令牌,随着序列长度的增加,其性能迅速下降。这证明了InfLLM能够准确捕捉长距离依赖关系,实现有效的长序列推理。
5 结论
在本文中,我们提出了一种无训练的方法来提高LLMs的长度泛化性。基于滑动窗口注意力机制,我们构建了一个额外的上下文记忆模块,帮助LLMs从大量上下文中选择相关信息以捕捉长距离依赖关系。在两个广泛使用的长文本基准测试上的实验表明,InfLLM可以有效提高在包含几千个令牌的序列上训练的LLMs处理极长序列的能力。在未来,我们将探索上下文记忆模块的高效训练,以进一步增强模型性能。此外,将键值缓存压缩方法与InfLLM结合可以进一步减少计算和内存成本。我们希望InfLLM能够促进LLMs流应用的发展。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











