






这篇文章介绍了GEMeX,一个大规模、可解释和可解释的医学视觉问答(Med-VQA)基准,专门用于胸部X射线诊断。主要内容如下:
-
背景与挑战:
-
当前的医学VQA数据集存在两个主要问题:缺乏答案的视觉和文本解释,以及问题格式单一,无法反映临床多样化的需求。
-
这些问题限制了Med-VQA系统在患者和初级医生中的理解和应用。
-
-
GEMeX的构建:
-
基于Chest ImaGenome数据集,通过与放射科医生合作,重新定义解剖区域并优化视觉-文本对应关系,生成准确的区域定位报告。
-
使用GPT-4生成多样化的问题,包括开放式、封闭式、单选和多选问题,并为每个问答对提供详细的文本和视觉解释。
-
最终数据集包含151,025张图像和1,605,575个问答对,是目前最大的胸部X射线VQA数据集。
-
-
评估与结果:
-
评估了10个代表性的大型视觉语言模型(LVLMs),发现它们在GEMeX上的表现不佳,突显了数据集的复杂性。
-
通过微调基线模型,显著提升了性能,证明了数据集的有效性。
-
提出了三个评估指标:答案-原因得分(AR-score)、答案得分(A-score)和视觉得分(V-score),全面评估模型的表现。
-
-
贡献与未来工作:
-
GEMeX通过多模态解释性和多样化问题类型,推动了医学VQA的发展。
-
未来工作包括将GEMeX集成到多任务训练中,进一步提升模型的性能。
-
GEMeX通过提供详细的解释和多样化的问题类型,填补了现有医学VQA数据集的空白,为开发更可靠的医学VQA系统提供了重要资源。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

通讯作者。11香港理工大学,香港,22新加坡国立大学,新加坡,33四川大学,中国,44四川大学华西医院,中国55新加坡高性能计算研究所,新加坡
摘要
医学视觉问答(VQA)是一项重要的技术,它将计算机视觉和自然语言处理相结合,自动响应关于医学图像的临床查询。然而,当前的医学VQA数据集存在两个显著的局限性:(1)它们通常缺乏对答案的视觉和文本解释,这阻碍了它们满足患者和初级医生的理解需求;(2)它们通常提供的问题格式范围较窄,无法充分反映临床场景中的多样化需求。这些局限性对开发可靠且用户友好的医学VQA系统提出了重大挑战。为了解决这些挑战,我们引入了一个大规模、可解释和可解释的医学VQA基准,用于胸部X射线诊断(GEMeX),具有几个创新组件:(1)一种多模态解释机制,为每个问答对提供详细的视觉和文本解释,从而增强答案的可理解性;(2)四种不同的问题类型——开放式、封闭式、单选和多选——更好地反映了多样化的临床需求。我们在GEMeX上评估了10个代表性的大型视觉语言模型,发现它们的性能不佳,突显了数据集的复杂性。然而,在使用训练集对基线模型进行微调后,我们观察到显著的性能提升,证明了数据集的有效性。项目网址为www.med-vqa.com/GEMeX。
1 引言
大型视觉语言模型(LVLMs)最近在人工智能领域取得了巨大突破[1, 2, 5, 11, 35, 38, 55, 57],展示了在理解视觉内容的同时生成连贯自然语言响应的卓越能力。这些进展推动了各个领域的创新[13, 15, 47],其中医疗保健成为一个关键应用领域。在这个领域中,医学视觉问答(Med-VQA)脱颖而出,成为一项关键任务,它自动提供可靠且用户友好的答案[29],以回答关于医学图像的问题[24],促进医疗专业人员的诊断、医学教育和临床决策。
为了确保Med-VQA系统的可靠性和用户友好性,必须结合答案解释和多样化的问题格式。尽管现有的Med-VQA系统取得了显著进展[16, 18, 24, 31, 53],但尚未集成答案解释。正如Li等人(2018)所强调的,解释在一般VQA系统中与答案本身同样重要。在医学VQA的背景下,任务的特定领域性质放大了对清晰度的需求[24]。如果Med-VQA工具要协助临床过程,数据集必须设计为包含解释,以增强患者的理解和初级医疗从业者的学习。此外,问题格式的有限范围,如缺乏多选题,限制了医学AI系统的实际应用性,并损害了其整体用户友好性。
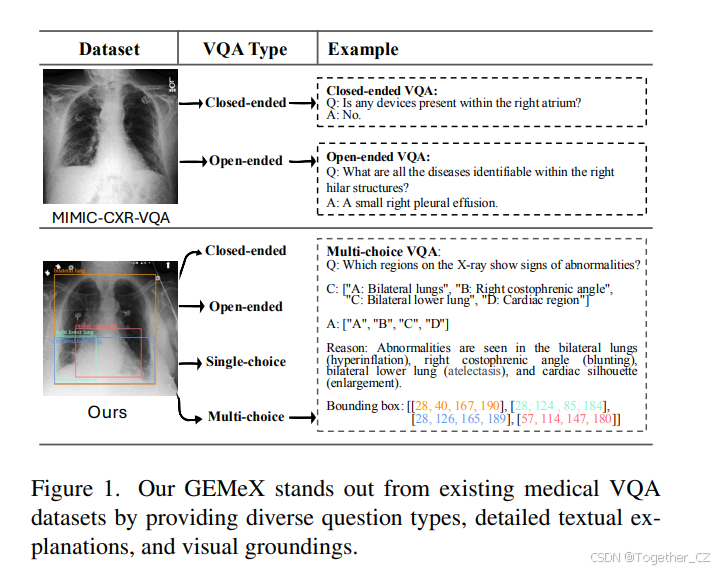
图1. 我们的GEMeX通过提供多样化的问题类型、详细的文本解释和视觉定位,在现有的医学VQA数据集中脱颖而出
为了应对上述挑战,我们开发了一个大规模、可解释和可解释的医学VQA基准,用于胸部X射线诊断(GEMeX)。我们首先对Chest ImaGenome数据集[45]进行了全面的数据优化过程。通过与放射科医生的合作,我们系统地重新定义了解剖区域,并建立了更精确的视觉-文本对应映射,从而为每个X射线图像生成了准确的区域定位报告。随后,我们利用GPT-4o[1]基于这些定位报告生成了一系列多样化的问题,涵盖四种类型:开放式、封闭式、单选和多选问题。每个问答对都通过显式推理和相应的视觉区域注释进行了丰富,如图1所示。最终的数据集包含151,025张放射图像和1,605,575个问题。据我们所知,这是目前最大的胸部X射线VQA数据集,也是第一个同时包含文本和视觉解释的Med-VQA数据集。
我们评估了10个代表性的LVLMs,包括5个来自通用领域(例如,LLaVA-v1[35]、Mini-GPT4-v1[57]、GPT-4o-mini[1])和5个来自医学领域(例如,LLaVA-Med[26]、XrayGPT[40]、RadFM[43])。实验结果突显了我们数据集的挑战性特征。此外,我们提出了一种简单的指令微调策略,以推导出任务特定的LVLM。显著的性能提升突显了我们数据集的有效性。为了评估,我们开发了三个指标来评估模型输出的准确性,包括答案、推理和视觉定位(本地化生成)。值得注意的是,我们应用了语义级别评分和基于语法的指标来评估自然语言生成(例如,BLEU和ROUGE)。结果表明,对于未经过GEMeX微调的模型,语义级别评分更为可靠。然而,在微调后,自然语言生成指标能更好地反映模型对数据集的理解。
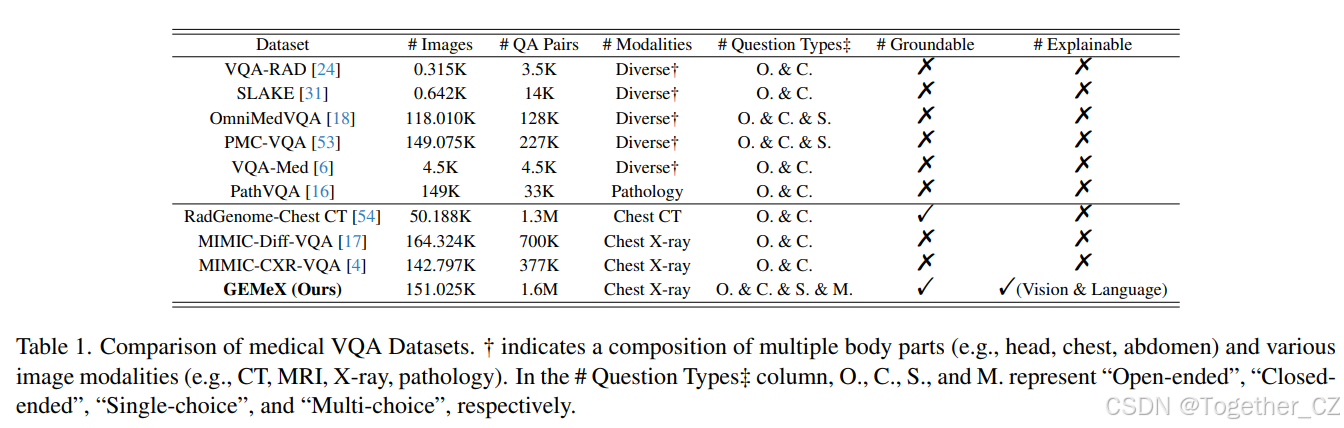
表1. 医学VQA数据集的比较。†表示包含多个身体部位(例如,头部、胸部、腹部)和多种图像模态(例如,CT、MRI、X射线、病理学)。在#问题类型‡列中,O.、C.、S.和M.分别代表“开放式”、“封闭式”、“单选”和“多选”。
本文的贡献可以总结如下:
-
我们引入了GEMeX,一个用于胸部X射线的大规模Med-VQA数据集,旨在支持多样化的问题类型,并为医学VQA系统提供增强的解释性。据我们所知,它是最大的胸部X射线VQA数据集,也是第一个体现多模态解释概念的Med-VQA数据集。
-
我们系统地使用GEMeX基准测试了10个代表性的LVLMs,引入了多个评估指标,全面展示了当前流行的LVLMs在Med-VQA任务中的表现。
-
我们展示了我们提出的精确视觉-文本解释通过微调显著增强了LVLMs的视觉推理能力,解决了各种模型中观察到的一个关键缺陷。我们强调了大规模、可解释和可解释的VQA基准在推动LVLMs在医疗保健领域的发展和部署中的重要性。
2 相关工作
在本节中,我们回顾了与本研究相关的先前工作,主要集中在两个领域:现有的Med-VQA数据集和当前为Med-VQA任务开发的方法。
医学VQA数据集
近年来,为了推动医学VQA研究,创建了各种数据集,每个数据集都在临床领域的特定挑战上取得了进展。详细的比较见表1。具体来说,VQA-RAD[24]是一个开创性数据集,提供了超过3,000个专注于放射图像的问答对。SLAKE[31]是第一个手动创建的数据集,包含超过14,000个跨CT、MRI和X射线图像的QA对,使模型能够通过结合视觉和文本信息处理复杂场景。VQA-Med[6]是Med-VQA竞赛的关键数据集,包含4,500张放射图像和配对的QA集,用于训练、验证和测试。OmniMedVQA[18]提供了更多的数据和更多的成像模态,涵盖了整个身体,以鼓励模型的泛化。PMC-VQA[53]通过提示大型语言模型分解生物医学图表的标题生成VQA数据,从而实现学术知识的提取。PathVQA[16]提供了超过32,000个QA对,用于细粒度的病理分析。尽管这些数据集多样性丰富,但它们共同拥有的X射线相关QA对不到40,000个,这可能限制了它们在LVLM训练中的实用性。
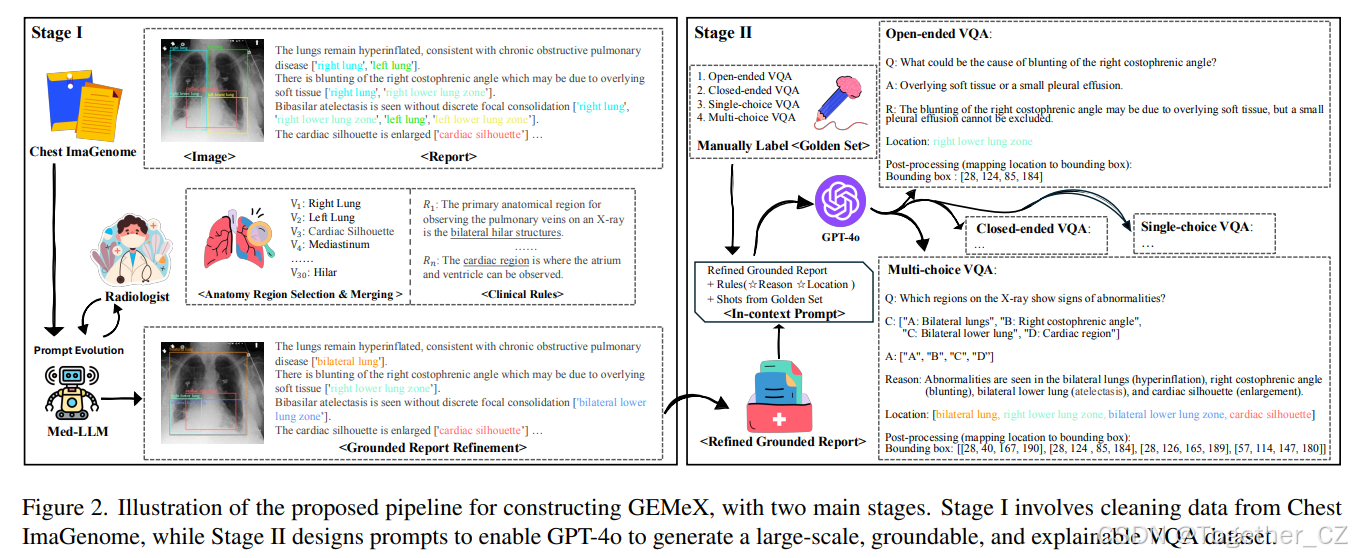
图2. 构建GEMeX的流程示意图,分为两个主要阶段。阶段I涉及对Chest ImaGenome数据的清洗,阶段II设计提示以使GPT-4o生成大规模、可定位且可解释的VQA数据集
对于专门任务,RadGenome-Chest CT[54]支持胸部CT诊断,而MIMIC-Diff-VQA[17]强调两个X射线之间的鉴别诊断推理。MIMIC-CXR-VQA[4]通过多样化的问答模板扩展了MIMIC-CXR[21],生成了胸部的放射QA对,有助于胸部异常检测。然而,所有当前的数据集都缺乏解释性和多样化的问题格式。它们没有为答案提供详细的视觉和文本解释,这限制了它们在患者和初级医生理解中的可用性。此外,有限的问题类型限制了它们模拟实践中遇到的多样化查询的能力。
医学VQA方法
受一般VQA进展的启发,医学VQA作为一个专门的领域获得了显著的关注。然而,由于数据限制,大多数方法[14, 22, 24, 30, 32, 36, 46, 50]直接嵌入视觉和文本信息,以共同捕捉它们之间的关系。随着对比语言-图像预训练(CLIP)[37]的兴起,方法[8, 9, 12, 49, 51]开始专注于将CLIP应用于Med-VQA。一种有前景的方法是通过微调CLIP的联合嵌入,以更好地处理特定的医学领域,增强模型对临床问题和视觉特征的理解[28]。最近,大型视觉语言模型(LVLMs)的爆发进一步推动了医学领域的边界[3, 25, 26, 40, 43, 58]。通常,它们首先在大规模图像-文本数据集(如PMC-OA[28]、PMC-15M[51])上预训练模型,将视觉特征映射到语言模型的嵌入空间,然后进一步使用指令数据进行微调,以进行医学咨询[3, 35]或疾病诊断[7, 40, 42, 56]。这些模型现在被用于Med-VQA任务,以提供更丰富、更具上下文感知的答案,超越简单的文本-图像对齐,结合更广泛的基于知识的推理。
尽管取得了这些进展,当前的方法受限于可用数据集的规模和多样性。此外,这些数据集中缺乏详细的解释也阻碍了构建可解释VQA模型的进展,突显了需要专注于解释性和临床相关性的方法和数据集。
3 GEMeX的构建
我们将详细介绍所提出的GEMeX数据集的构建过程,并附上图2的示意图。本节的结构如下:在第3.1节中,我们介绍了数据集构建的初始步骤,重点是优化解剖区域和定位报告;第3.2节涵盖了四种不同类型的Med-VQA的生成过程,结合了视觉和文本维度的多模态解释性。更多细节见附录。
定位报告优化
如图2的阶段I所示,我们基于Chest ImaGenome[45]构建了我们的数据集,但重点是视觉区域和文本描述实体之间的映射精度。Chest ImaGenome的出现推动了各种多模态任务的进展,包括Med-VQA[17]和定位报告生成[39]。然而,在与放射科医生咨询后,我们发现ImaGenome中的解剖区域描述不精确且缺乏简洁性,甚至引入了临床诊断的歧义。具体来说,在ImaGenome中,一个句子可能包含多个解剖区域,例如句子“右肋膈角变钝,可能是由于覆盖的软组织所致”对应于["右肺", "右下肺区"]。这一缺点在训练模型进行精确视觉定位时提出了挑战。因此,在构建的第一阶段,我们进行了句子-区域优化,生成每句话只对应一个临床精确文本区域实体的对。
3.1.1 解剖区域选择和合并
在原始的Chest ImaGenome中,有29个重要的病理区域。然而,根据放射科医生的实践,我们的数据集重点保留了通过X射线诊断疾病时至关重要的核心临床区域,如“左下肺”和“纵隔”。不太重要或边缘的区域被排除,以简化诊断训练过程并增强临床相关性。例如,我们排除了“carina”等非核心区域,以及仅占总区域频率约2%的“锁骨”。此外,为了增强清晰度,并确保每句话对应一个具有更细粒度的病理区域,语义上相似的区域被合并。例如,“左下肺区”和“右下肺区”被合并为“双侧下肺区”。这种合并与“双侧基底肺不张”等条件一致,如图2的阶段I所示,其中条件描述为“双侧基底肺不张,未见明显局灶性实变”。最终,我们定义了30个解剖区域。从Chest ImaGenome到我们的详细转换见附录。
3.1.2 使用医学LLM进行优化
在定义了解剖区域后,我们利用OpenBioLLM-70B1,该模型在各种医学NLP任务中表现出色,来优化原始的句子-区域对。为了测试提示的有效性,我们首先从Chest ImaGenome测试集中随机选择了100对,其中包含约367个句子。最初,OpenBioLLM-70B模型的表现不佳,主要有两个原因:(1)一些疾病观察区域不够详细,因为OpenBioLLM是一个NLP模型,缺乏临床专业知识;(2)当一个句子涉及多个无法合并的区域时,模型可能会输出多个区域或任意选择一个。
为了解决这些限制,我们采用了一种迭代方法,逐步结合放射科医生的指导(临床规则)和手动标注的案例,以有效分割和重写句子。例如,“心脏纵隔轮廓正常。”可以分割为{"心脏轮廓正常。":"心脏轮廓", "纵隔轮廓正常。":"纵隔"},其中“心脏纵隔”对应于“心脏轮廓”和“纵隔”。这种方法确保输出子句与各自区域一一对应。最终,提示在上述测试集上的准确率约为98.4%。部分临床规则见图2的阶段I,完整的提示见附录。
可解释和可解释的VQA生成
尽管有许多Med-VQA数据集[4, 17]可用,甚至有些是使用MIMIC-CXR或Chest ImaGenome生成的,但它们都有两个弱点,降低了其实用性:(1)这些数据集通常缺乏强大的解释性。当患者提出医学问题时,系统可能只提供简单的文本解释,而没有提供视觉相关的指导。这一限制可能阻碍用户对所呈现的医学信息的理解;(2)这些数据集中包含的问题类型有限,通常仅限于开放式或封闭式格式,没有包含基于选择的问题。这显著限制了数据集在解决更广泛用户查询时的灵活性和全面性。总的来说,这些问题突显了需要更多多功能和可解释的Med-VQA数据集,以增强其在临床环境中的实用性。

如图2的阶段II所示,我们在优化定位报告后准备生成我们的VQA数据集。在这里,我们使用GPT-4o[1]作为生成器,因为它在理解和生成长文本方面表现出色。为了提高生成问题的质量并更好地与我们的目标对齐,我们根据其配对的定位报告手动为30张图像设计了问题(作为黄金集),以作为提示中的示例进行上下文学习。此外,我们还设计了特定规则(如不生成需要通过比较两张图像来回答的问题),以确保生成VQA的质量。对于每个图像-报告样本,我们指示GPT-4o生成总共11个问题:3个开放式VQA、2个封闭式VQA、3个单选题和3个多选题,最终生成了约160万个VQA对。包含少于两个句子的报告将不会用于生成QA。详细的提示见表2。此时,生成的视觉位置仍然是文本格式的解剖区域(例如,“左下肺区”)。为了使进一步的VQA模型能够在图像上定位特定位置,我们需要进行后处理步骤,将区域映射到边界框坐标。图2中展示了一个多模态解释性的示例,更多案例见附录。
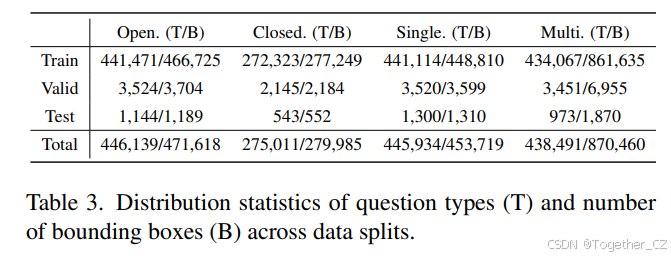
数据集划分。我们的生成VQA根据MIMIC-CXR的分布进行划分。具体来说,我们有149,535张图像和1,588,975个QA对用于训练,1,190张图像和12,640个QA对用于验证,300张图像和3,960个QA对用于测试。值得注意的是,测试集是根据原始数据集中的涉及疾病[19]手动清理的(约2,331张图像),作为评估自动生成VQA质量和基准测试大型视觉语言模型的黄金标准。详细的统计数据,包括问题类型分布和边界框数量,见表3。更多数据,如词云和常见胸部疾病统计,见附录。
4 GEMeX的评估
实验细节
在GEMeX上微调的强基线。为了验证数据集的有效性,特别是自动生成的训练集,我们提出了一种问题类型感知的指令微调策略,以在GEMeX的训练集上微调LLaVA-Med-v1-7B[26],称为LLaVA-Med-GEMeX,作为一个简单的基线。具体来说,对于我们GEMeX中的每个VQA样本,我们在原始系统提示后添加一个类型提示XType和一个问题XQuestion及其答案XAnswer、文本原因XReason和相应的视觉位置XLocation,构建一个单轮对话,如表4所示。通常,XType是“输入一个{Type}问题,助手将输出其答案{Supplement},并提供详细原因和相应的视觉位置。”其中{Type}指的是“开放式/封闭式/单选/多选”,{Supplement}分别替换为“无/(是或否)/(一个选项)/(一些选项)”。我们在附录中展示了一些输入样本。

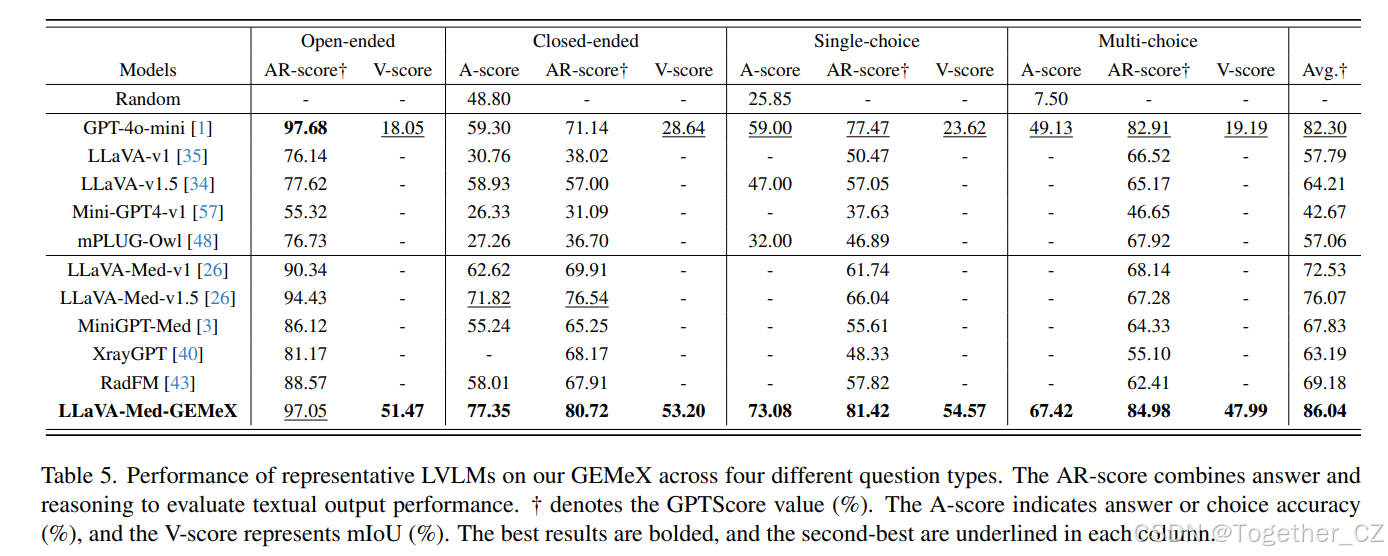
表5. 代表性LVLMs在我们GEMeX上的性能,涵盖四种不同问题类型。AR-score结合答案和推理来评估文本输出性能。†表示GPTScore值(%)。A-score表示答案或选项的准确率(%),V-score表示mIoU(%)。最佳结果以粗体显示,次佳结果在每列中加下划线
训练细节。我们通过计算自回归损失来微调LLaVA-Med-v1的视觉投影层和LLM组件(在阶段II之后),以预测助手的响应和对话终止标记<STOP>。特别地,模型在四个NVIDIA H100 GPU上训练了3个epoch,批量大小为64,耗时约54小时。网络在前0.03个epoch中使用线性学习率从3e-7预热到2e-5,随后按余弦计划衰减。优化器为AdamW。为了加速训练,我们采用了全分片数据并行(FSDP)机制、bf16(Brain Floating Point)数据格式和梯度检查点。
LVLMs基准测试。除了微调任务导向模型外,我们还在GEMeX数据集上对其他10个LVLMs进行了零样本评估,其中5个来自通用领域,另外5个来自医学领域:
-
在通用领域:我们测试了LLaVA-v1[35]、Mini-GPT4-v1[57]、mPLUG-Owl[48]、LLaVA-v1.5[34]和GPT-4o-mini。请注意,我们没有测试GPT-4o,因为其安全保护政策禁止其分析医学图像。
-
在医学领域:我们评估了LLaVA-Med-v1[26]、LLaVA-Med-v1.5[26]、MiniGPT-Med[3]、XrayGPT[40]和RadFM[43]。详细介绍见附录。
评估指标
在GEMeX中,每个问题都有一个对应的答案、文本原因和视觉位置。理想情况下,我们旨在使用设计的指标评估所有这三个方面,如下所示:
-
答案-原因得分(AR-score):实际上,大多数LVLMs在生成格式准确的输出方面表现不佳。这并不一定意味着这些模型缺乏回答问题的知识,而是缺乏正确遵循指令的能力。为了确保公平比较,我们引入了答案-原因得分(AR-score)作为文本输出的评估指标,其中每个测试样本的答案和原因部分合并为参考(真实标签),评估的LVLM的输出作为候选。我们使用GPTScore[26]从语义角度计算AR-Score。具体来说,GPT-4o被用来量化正确性。我们首先将上述参考视为助手#1的文本响应,候选视为助手#2的响应。通过这两个响应、原始问题和X射线报告,GPT-4o评估每个助手的答案的准确性、相关性和帮助性,并提供1到10的总体得分,其中较高的分数表示更好的性能。然后,我们使用GPT-4o的参考分数进行归一化计算相对分数。此外,我们还使用常见的NLG指标(例如,BERTScore[52]、BLEU、ROUGE)来评估AR-score。
-
答案得分(A-score):对于模型可以输出特定答案的响应(例如,封闭式问题的yes/no或单选/多选问题的选项),我们通过与真实标签进行比较来计算准确性。值得注意的是,尽管一些模型不能直接输出答案,我们仍然尝试从其响应中匹配答案。
-
视觉得分(V-score):对于能够进行视觉定位的模型(即输出视觉位置),我们计算平均交并比(mIoU)作为测量标准。对于一个VQA案例,考虑到可能存在多个对应位置(常见于多选问题),我们使用匈牙利算法[23]将预测的边界框与实际的边界框进行匹配。
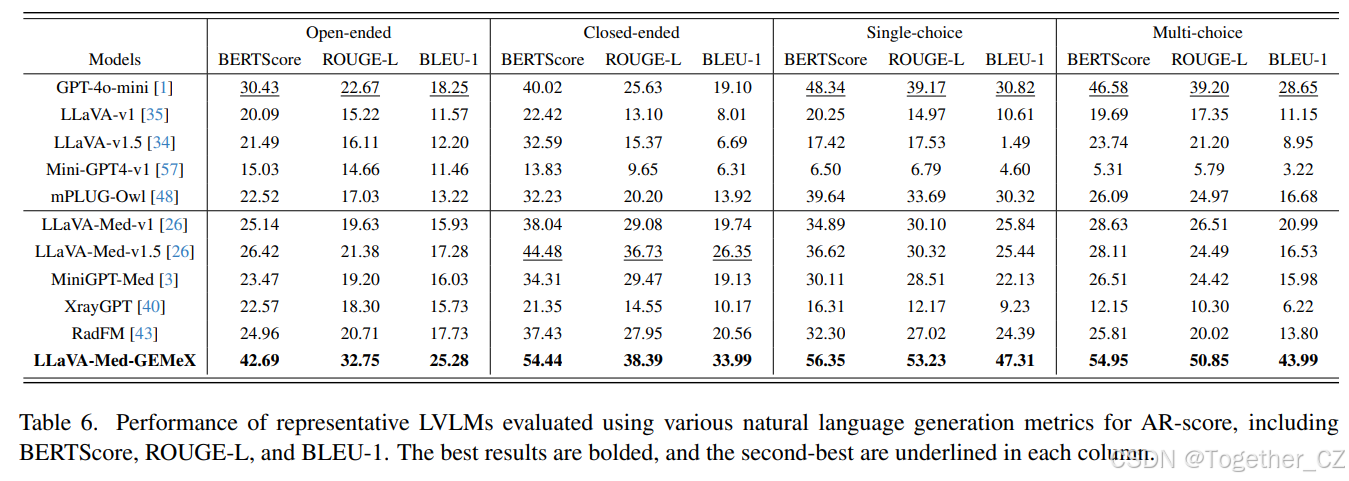
表6. 使用多种自然语言生成指标评估代表性LVLMs的AR-score性能,包括BERTScore、ROUGE-L和BLEU-1。最佳结果以粗体显示,次佳结果在每列中加下划线
结果与分析
总体性能。为了进行公平比较,评估的模型(除GPT-4o-mini和RadFM(使用MedLLaMA-13B[44])外)均基于7B-LLMs。具体来说,LLaVA-v1、LLaVA-Med-v1和MiniGPT4-v1基于Vicuna-v0-7B[10],而LLaVA-v1.5和XrayGPT基于Vicuna-v1-7B;LLaVA-Med-v1.5基于Mistral-7B-Instruct-v0.2[20];mPLUG-Owl使用LLaMA-7B[41]。所有模型的配置均根据其开源代码设置。综合结果见表5。前5行表示通用LVLMs的性能,后6行表示医学LVLMs和我们微调版本的LLaVA-Med-v1(称为LLaVA-Med-GEMeX)的结果。可以发现:
-
大多数可用的LVLMs在GEMeX上测试时表现较弱。唯一的例外是GPT-4o-mini,它在所有任务中的平均AR-score超过80。在考虑特定问题类型时,LLaVA-Med(版本1和1.5)在开放式问题上表现出色,AR-score超过90。然而,所有模型在其他三类任务中表现不佳。
-
面对基于选择的问题时,大多数模型难以输出明确的选项,尽管它们可以分析每个选项。这解释了为什么大多数模型具有相应的AR-score但没有A-score,突显了引入这些类型问题的必要性。
-
强大的LVLMs如GPT-4o-mini通常依赖于捷径推理而不是真正的多模态推理。具体来说,尽管它们有时可以回答问题到一定程度,但它们往往无法准确进行视觉定位。这表明这些模型倾向于使用捷径知识(如从预训练记忆中检索信息)来解决Med-VQA任务,而不是进行真正的多模态推理。然而,多模态推理是Med-VQA系统解释性的核心。
-
通过提出的简单问题类型感知的指令微调,模型实现了显著的性能提升,大约13.5%(即平均AR-score),相比LLaVA-Med-v1。更重要的是,它在大多数指标上超过了GPT-4o-mini,证明了训练集的可靠性。然而,与实际使用仍存在显著差距,突显了所提出的GEMeX的挑战。
限制。我们想强调的是,微调后的模型本质上是任务特定的,这意味着它在其他数据集上的准确性可能会降低,或者失去进行对话的能力。因此,真正的潜力在于将我们的GEMeX集成到多任务训练中(例如LLaVA-Med的第二阶段训练)。这里微调的模型主要用于验证数据集的有效性,同时也建立了一个强大的基线。
更多指标。正如我们在第4.2节中提到的,我们还计算了NLG指标来测量AR-score。详细结果见表6。总体而言,NLG指标通常与GPTScore(表5中的AR-score)趋势相同,但有一些细微差异。(1)具有高NLG分数的模型并不总是表现良好,如mPLUG-Owl与LLaVA-v1.5的比较。本质上,LLaVA-1.5表现出更高的性能,例如在单选任务中实现了比mPLUG-Owl高15%的答案准确率(A-score)。然而,由于LLaVA-v1.5的输出大多只包含答案而没有原因,较短的输出导致NLG分数较低,其BLEU-1比mPLUG-Owl低约28.8%;(2)NLG指标能更好地反映微调后的性能提升。例如,微调后的模型在GPTScore上仅比GPT-4o-mini提高了约3.7%的平均值,但在平均NLG指标上带来了约12.1%的显著提升。这种更显著的提升更好地展示了模型对数据集的学习效果。总体而言,我们认为对于未参与GEMeX训练的模型,使用GPTScore更为合理,因为语义理解可以用来判断模型输出与真实标签之间的差异。对于微调后的模型,NLG指标更受欢迎,因为它们能更好地反映模型与数据集的对齐。
表7. GEMeX中的挑战性问题由GPT-4o-mini和我们的微调LLaVA-Med-GEMeX回答。这些示例突显了GPT-4o-mini等LVLMs在视觉推理方面的局限性,通过使用GEMeX进行微调可以有效改进
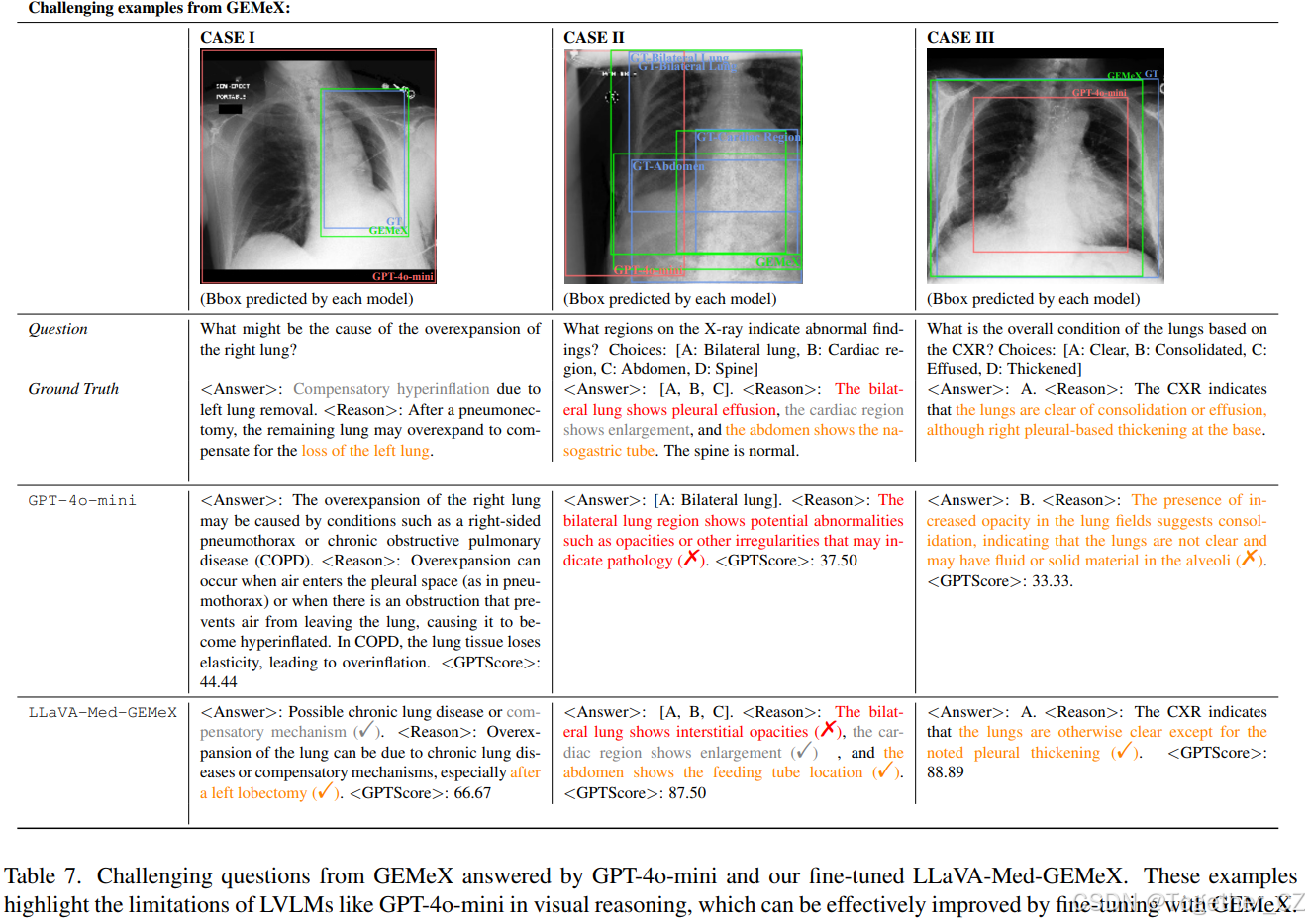
案例研究。在表7中,我们展示了一些问题及其输出,分别来自GPT-4o-mini和我们的微调LLaVA-Med-GEMeX,以进行定性比较。在案例I中,尽管GPT-4o-mini可以生成非常详细的答案,但它没有基于视觉内容提供推理,导致与真实标签存在显著差异。相比之下,LLaVA-Med-GEMeX提供了相对准确的视觉线索,并能够提供部分正确的答案(“代偿机制”),尽管在考虑患者情况时错误地提到了“可能的慢性肺病”。在案例II中,尽管GPT-4o-mini可以分析图像,但其有限的能力导致只选择了一个选项并提供了模糊的原因。相比之下,LLaVA-Med-GEMeX输出了正确的选项,但对一个选项(即答案“A”)给出了错误的原因。在案例III中,GPT-4o-mini无法同时进行视觉推理和正确输出答案,而微调后的模型可以在这两个方面提供更好的输出。从这些例子中,我们可以得出结论,一些LVLMs仍然缺乏对医学图像的足够理解。同时,尽管提出的简单微调方法提高了性能,但仍远未达到完全准确,留下了进一步探索的空间。我们在附录中提供了更多案例研究。
5 结论
在本文中,我们引入了一个基准GEMeX,旨在通过多模态解释性和多样化问题类型推动医学VQA领域的发展。GEMeX不仅为患者和初级医生提供了更易理解的医学解释,还为开发下一代具有增强指令遵循能力的医学LVLMs提供了宝贵的训练资源。我们通过全面测试代表性LVLMs以及任务特定的微调,展示了数据集的有效性和难度,希望GEMeX能够促进医学VQA的发展并改善AI辅助医疗。



















 3822
3822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











