






这篇文章介绍了一个名为GANESH的新框架,旨在从多视角无透镜图像中实现3D场景重建和新视角合成。无透镜成像通过去除传统透镜系统,提供了超紧凑相机的潜力,但由于没有聚焦元件,传感器输出是复杂的多路复用场景表示,而非直接图像。传统方法主要针对2D重建,且在3D重建中表现不佳。
GANESH框架的主要贡献包括:
-
联合细化和渲染:GANESH能够同时从多视角无透镜图像中进行场景细化(去噪)和新视角合成,避免了传统方法中先细化再渲染的两步过程。
-
可推广性:与现有方法需要针对每个场景进行训练不同,GANESH能够在无需重新训练的情况下对新的场景进行即时推理,具有较强的推广能力。
-
数据集:文章提出了第一个多视角无透镜数据集LenslessScenes,包含真实世界的多视角无透镜捕获,用于模型训练和评估。
-
实验结果:通过大量实验,GANESH在重建精度和细化质量上优于现有的方法,特别是在处理复杂场景和噪声数据时表现出色。
文章还详细介绍了GANESH的技术实现,包括使用维纳反卷积进行粗略场景估计、通过合成数据模拟无透镜成像、以及使用感知损失和均方误差损失进行端到端训练。实验结果表明,GANESH不仅在合成数据上表现优异,还能很好地推广到真实世界的无透镜捕获数据。
最后,文章讨论了GANESH的局限性,如训练时间较长和推理速度较慢,并提出了未来可能的研究方向,如将物理光传输模型与数据驱动方法结合,以进一步提高无透镜成像的准确性和效率。
GANESH为无透镜成像领域提供了一种新的、高效的3D重建和新视角合成方法,具有广泛的应用潜力,特别是在医疗成像、增强现实(AR)和虚拟现实(VR)等领域。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目主页地址在这里,如下所示:
摘要
无透镜成像通过去除传统的笨重透镜系统,为开发超紧凑相机提供了重要机会。然而,由于没有聚焦元件,传感器的输出不再是直接的图像,而是复杂的多路复用场景表示。传统方法试图通过可学习的反演和细化模型来解决这一挑战,但这些方法主要设计用于2D重建,并且在3D重建中表现不佳。我们提出了GANESH,这是一个新颖的框架,旨在从多视角无透镜图像中实现同时细化和新视角合成。与现有方法需要针对每个场景进行训练不同,我们的方法支持在无需重新训练的情况下进行即时推理。此外,我们的框架允许我们针对特定场景调整模型,从而提高渲染和细化质量。为了促进该领域的研究,我们还提出了第一个多视角无透镜数据集LenslessScene。大量实验表明,我们的方法在重建精度和细化质量上优于当前的方法。
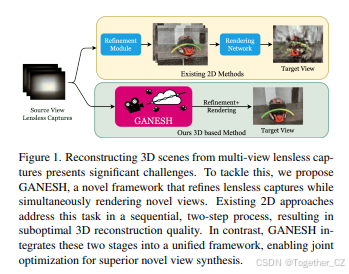
图1. 从多视角无透镜捕获中重建3D场景面临重大挑战。 为了解决这一问题,我们提出了GANESH,这是一个新颖的框架,能够在细化无透镜捕获的同时渲染新视角。现有的2D方法通过顺序的两步过程来处理这一任务,导致3D重建质量不佳。相比之下,GANESH将这两个阶段集成到一个统一的框架中,实现了联合优化,从而生成更高质量的新视角合成。
1 引言
近年来,基于掩模的无透镜成像系统因其能够提供紧凑、轻量且成本效益高的传统相机替代方案而受到广泛关注[18]。这些系统不依赖于标准的光学透镜,而是依靠放置在传感器附近的振幅[2]或相位掩模[1, 6]。这种设计不仅最小化了成像设备的物理尺寸和质量,即更小的外形尺寸,还允许使用非传统的传感器几何形状,如球形、圆柱形甚至柔性配置[28]。在没有传统聚焦元件的情况下,传感器捕获的测量值不再是场景的直观图像,而是由复杂的多路复用数据组成,这些数据以高度压缩和非直观的形式编码场景的光信息。这种图像形成模型需要先进的计算技术来解码和重建原始场景,因为传感器不再生成视觉信息的一对一表示,而是整个视场中光强度的叠加。
许多研究已经探讨了从单张无透镜捕获图像中重建场景的问题[3, 12, 18, 25]。例如,FlatNet[18]采用两步过程来恢复场景。首先,使用可训练的反演模块重建场景的大部分细节;然而,生成的输出仍然包含显著的噪声,随后通过细化网络进行处理。尽管在这一领域的2D场景重建中有许多工作,但从多视角无透镜捕获中重建3D场景的研究却很少。这一进展对于内窥镜手术等应用尤为重要,因为无透镜相机的紧凑尺寸提供了显著优势。从多视角无透镜图像中实现3D重建可以极大地受益于医疗领域和AR/VR应用[13, 17]。
最近,NeRFs因其能够从真实世界的多视角捕获中重建3D场景而备受关注。大多数基于NeRF的方法依赖于RGB图像来建模底层3D场景。在这一领域有许多工作,促使NeRFs使用不同的图像模态,如热成像[33]、事件数据[14]、多光谱捕获[35]、单光子数据[15]。例如,在Thermal NeRF[33]中,他们提出了一种仅从热成像中重建新视角的方法,特别适用于视觉退化的机器人场景。Ev-NeRF[14]从神经形态相机捕获的原始事件数据流中学习重建多视角图像,这有助于在高动态范围场景中更好地重建。尽管有这些有前景的发展,当前NeRF模型的一个显著局限是它们依赖于场景特定的训练。
人们可能会考虑使用已建立的细化技术,如FlatNet[18],然后将其输出馈送到渲染网络,如NeRF或高斯泼溅[16]。虽然这是一个可行的选择,但它也有其缺点。NeRF和高斯泼溅操作的原则是仅将图像用于监督目的,而不是作为直接输入。这样的模型无法在成对的多视角无透镜和RGB图像上进行训练,导致新视角合成质量较差。其次,虽然高斯泼溅在计算效率上优于NeRF,但它可能容易过拟合FlatNet产生的噪声输出,可能导致次优的重建质量。最后,每当呈现一组新图像时,每个模型都必须从头开始重新训练,限制了它们在不同场景中的可扩展性和实际应用。
可推广的辐射场方法最近因其能够在无需特定训练的情况下对新场景进行即时推理而受到关注。许多这些方法[29, 30, 36]利用一组源视图并在它们之间强制执行极线约束以生成新的目标视图。当前最先进的方法GNT[29]采用基于变压器的架构,有效地聚合来自多个视图的极线信息。然后,它沿着每条射线累积这些点特征以计算最终的像素颜色,从而实现准确高效的新视图渲染。然而,如前所述,大多数辐射场方法主要集中在使用RGB图像作为输入,对无透镜捕获等替代模态的探索有限。鉴于无透镜成像的多样化应用,将这种模态纳入辐射场为扩展其在各个领域的实用性提供了重要机会。
在本文中,我们介绍了一种新颖的方法,使我们能够在可推广的设置中从多视角无透镜捕获中重建场景。与需要针对每个新数据集进行场景特定训练的传统方法不同,我们的技术可以推广到各种多视角无透镜输入以渲染新视图。我们提出的方法GANESH可以有效地从无透镜数据中重建3D场景。我们的模型在大量合成的多视角无透镜图像数据上进行训练。尽管仅在合成数据上进行训练,但当应用于真实的多视角无透镜捕获时,该模型可以细化和渲染新视图。实验结果表明,该模型能够有效地推广到合成和真实场景。此外,我们的方法允许通过最少的微调步骤进行场景特定调整,从而提高重建质量。我们还提出了_LenslessScenes_,这是一个包含六个不同场景的真实世界多视角无透镜捕获数据集。这些场景在受控的实验室环境中获取,并附有精确的定量评估的地面真实数据。我们工作的主要贡献如下:
-
我们提出了一个新颖的框架,同时实现了无透镜捕获的细化和渲染。
-
我们的方法是可推广的,即它可以在无需场景特定训练的情况下即时渲染视图。
-
我们提出了_LenslessScenes_,这是第一个多视角无透镜捕获数据集。
-
我们的实验结果表明,所提出的方法优于分别处理细化和新视角合成的现有技术。
2 相关工作
2.1 无透镜成像
无透镜成像是指在不使用传统透镜聚焦入射光的情况下捕获场景图像。历史上,这种技术已广泛应用于X射线和伽马射线成像以用于天文目的[7, 11],但其在可见光谱中的应用直到最近才被探索。在无透镜系统中,场景要么直接由传感器捕获[19],要么在通过掩模元件调制后捕获[27, 1, 2]。我们的研究特别关注基于掩模的无透镜成像,其中用掩模替换透镜导致高度多路复用的传感器捕获,这些捕获并不直接类似于原始场景。因此,需要先进的计算技术来重建图像。FlatNet[18]通过采用可训练的反演模块与U-Net细化架构相结合,从无透镜捕获中恢复场景。FlatNet3D[3]进一步扩展了这一点,通过神经网络从单次无透镜捕获中预测场景的强度和深度。然而,之前的工作尚未探索在无透镜成像中使用多视角图像。我们提出的方法GANESH旨在从多视角无透镜捕获中细化和渲染新视图,从而实现同时细化和新视角合成。
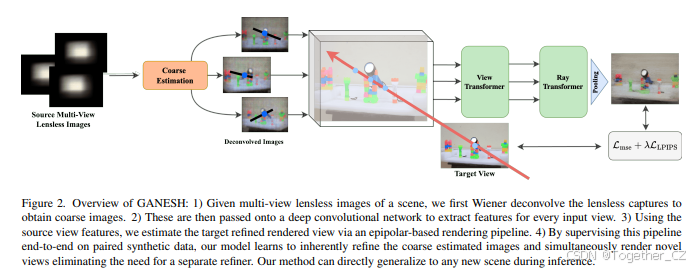
图2. GANESH概述:
-
给定场景的多视角无透镜图像,我们首先通过维纳反卷积处理无透镜捕获,得到粗略图像。
-
然后将这些粗略图像输入到深度卷积网络中,为每个输入视图提取特征。
-
利用源视图的特征,通过基于极线约束的渲染管道估计目标细化后的渲染视图。
-
通过在配对的合成数据上端到端监督这一管道,我们的模型能够隐式地细化粗略估计图像,并同时渲染新视角,从而消除了对单独细化器的需求。我们的方法在推理过程中可以直接推广到任何新场景。
2.2 神经辐射场
NeRF[22]利用多层感知器(MLP)将场景表示为连续的5D函数,结合空间位置和观察方向。该框架通过将3D空间函数和2D方向函数映射到颜色和密度输出来编码场景的几何形状和外观。自其引入以来,许多工作试图增强NeRF的渲染能力[8, 23, 24, 31]。例如,Mip-NeRF[4, 5]通过采用近似锥形追踪方法而不是标准NeRF中使用的射线追踪方法,改进了原始方法。PointNeRF[32]通过引入特征点云作为体积渲染过程中的中间步骤,进一步推进了这一框架,提高了渲染输出的整体质量。
NeRF还被扩展到非RGB输入模态,如Thermal-NeRF[33]和Hyperspectral NeRF[10]等。Thermal-NeRF[33]使用红外(IR)图像作为输入重建3D场景,专注于更准确地保留热特性。同样,Hyperspectral NeRF[10]将NeRF适应于高光谱成像,该成像在广泛的电磁频谱范围内捕获数据。在这项工作中,我们探索了一种相关的方法,通过从无透镜捕获中重建3D场景,利用这种替代成像模态扩展NeRF的能力。
2.3 可推广的辐射场
NeRF的一个显著缺点是缺乏推广性,因为每个模型都是针对单个场景专门训练的,不能轻易转移到新的、未见过的场景。各种方法,如MVSNeRF[9]、IBRNet[30]和Generalizable NeRF Transformer(GNT)[29],通过开发能够推广到不同场景的模型来解决这一限制。MVSNeRF[9]通过结合多视角立体方法提高了新视角合成速度。IBRNet[30]提供了一个可推广的基于图像的渲染框架,从任意输入生成新视图,而无需每个场景的优化。GNT[29]利用基于变压器的架构,通过基于极线约束聚合源视图中的信息来合成新视图。基于这些进展,我们提出了一个专门为从无透镜捕获中合成新视图设计的可推广模型。
3 初步:可推广的NeRF Transformer

我们利用GNT的能力生成目标新视图,并在视觉上增强无透镜捕获的重建,避免了在新视角合成之前需要细化网络。
4 GANESH
概述。我们介绍了GANESH,这是一个新颖的框架,用于从无透镜捕获中执行可推广的新视角合成,如图2所示。任务是从N个校准的多视角无透镜图像中生成细化的新视图,已知相机姿态,同时确保模型推广到未见过的场景。我们的方法建立在现有的GNT架构[29]之上,但基于捕获的多视角无透镜图像对场景表示和渲染过程进行条件化。首先,这些无透镜捕获通过一个简单的维纳反卷积滤波器以获得场景的粗略估计(第4.1节)。然后,该滤波器的反卷积输出被传递到一个可推广的视图合成模型,该模型同时执行细化和渲染。这样的管道可以在合成生成的场景上进行端到端训练(第4.2节),并直接转移到任何真实场景而无需额外优化(第4.3节)。
4.1 粗略场景估计
鉴于无透镜捕获的全局多路复用性,我们不能直接将它们馈送到辐射场模型中以渲染新视图。因此,为了从无透镜捕获中重建RGB图像,需要使用无透镜相机的点扩散函数(PSF)对其进行反卷积以获得粗略的重建图像。为此,我们使用维纳反卷积,它接受无透镜捕获和点扩散函数作为输入,并返回重建图像。对于RGB图像I和PSF核H,观察到的无透镜图像由下式给出:


图3. a) 用于捕获真实世界数据集LenslessScenes的无透镜相机设置。
b) 校准的**点扩散函数(PSF)**用于在我们合成的数据集中模拟无透镜捕获。
4.2 模拟无透镜成像
鉴于缺乏包含多视角无透镜捕获和相应地面真实RGB图像的大规模配对数据集,这对于训练我们的可推广模型至关重要,我们建议使用现有的多视角RGB数据集模拟无透镜数据。具体来说,我们通过将每个地面真实图像与无透镜相机的点扩散函数(PSF)卷积来近似无透镜捕获。然而,在实际应用中,无透镜测量经常被噪声破坏,需要细化步骤来恢复原始场景。我们在卷积的无透镜捕获中人为引入40dB的高斯噪声以模拟这些实际条件。这种噪声的添加确保模型在训练期间暴露于噪声数据,帮助其学习从合成到真实场景的良好转移的鲁棒特征。
我们模拟过程中的一个重要设计选择是使用灰度PSF映射而不是RGB PSF映射进行卷积操作。通过实证研究,我们发现灰度PSF映射更准确地模拟了真实世界的无透镜捕获,由于没有透镜,这些捕获本质上缺乏颜色通道特定信息。因此,灰度PSF映射提供了更接近无透镜成像系统中传感器测量的现实近似,从而在推理期间提高了重建质量,如第5.6节中提出的消融研究所证明的。
4.3 训练和推理
为了端到端优化网络,我们使用2种损失来确保视图一致的渲染和准确的细化。

图4. 在合成NeRF-LLFF数据集上进行的场景特定实验的定性结果。 FlatNet+NeRF基线表现出显著的伪影,并且无法保留关键的场景几何结构。虽然FlatNet+GNT改善了场景几何重建,但它引入了过度的平滑效果,导致高频细节的丢失。相比之下,我们提出的方法能够准确重建场景几何结构并渲染新视角,保留了高频细节,提供了更优的视觉保真度。需要注意的是,所有基线方法和我们模型的输入都是直接的无透镜捕获。在本图及后续所有图的第一列中,我们展示了**维纳反卷积(WD)**的输出,仅用于可视化目的。
均方误差:我们使用MSE来测量地面真实和渲染输出之间的失真,由下式给出:
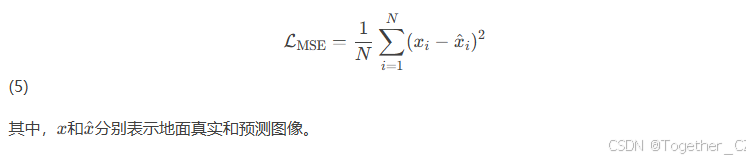
感知损失[34]:除了MSE损失外,我们还采用感知损失来捕捉地面真实和渲染输出之间的高级特征相似性。我们使用预训练的VGG-19网络来实现这一点,从地面真实和预测视图的各个层中提取特征。感知损失公式如下:

通过在合成生成的无透镜场景上进行训练,我们观察到GANESH成功地推广到真实世界数据而无需额外微调。这种推广能力与之前基于2D的方法[18, 3]中观察到的结果一致,将该假设扩展到3D领域,并确认其在无透镜图像重建中的适用性。
5 实验和结果
5.1 数据集
我们利用IBRNet[30]和LLFF[21]数据集创建了一个包含无透镜图像及其对应地面真实RGB图像的合成数据集。这些数据集是新视角合成(NVS)的成熟基准,共包含110个场景。为了在合成场景上进行验证,我们使用了NeRF-LLFF数据集[22]。
5.2 LenslessScenes真实世界数据集
为了补充合成数据并测试我们模型的鲁棒性,我们收集了第一个真实世界多视角无透镜数据集。在实验室环境中收集了7个场景,每个场景平均包含约20帧,每个场景在正面设置下收集。我们复制了FlatNet[18]的设置,使用监视器捕获设置收集真实数据捕获以及地面真实标签。我们使用_BASLER Ace acA4024-29uc_无透镜相机捕获场景,见图3。数据收集涉及多个场景,每个场景都配备了详细的环境设置。使用点光源校准相机的点扩散函数(PSF),这对于准确重建至关重要。此外,使用白色显示屏捕获环境噪声,随后从图像中减去以增强捕获数据的质量。

图5. 在合成NeRF-LLFF数据集上进行的可推广设置的定性结果。 我们观察到,与我们的方法相比,FlatNet+IBRNet和FlatNet+GNT基线在渲染高保真新视角方面表现不足。我们的方法在恢复精细几何结构和纹理方面表现出色。
5.3 实现细节
我们的整个管道使用多视角姿态图像数据集进行端到端训练。为了保持一致性,我们采用了与IBRNet[30]相同的输入视图采样策略,在训练期间选择8到12个源视图,同时在推理期间固定源视图数量为10个。我们没有从头开始训练模型,而是使用GNT[29]的预训练检查点初始化我们的网络,从而利用其推广能力。
我们使用Adam优化器[20]优化模型以渲染干净图像,初始学习率设置为5×10−4,在30万次训练迭代中逐渐衰减。在每次迭代中,投射576条射线,每条射线采样192个点。我们损失函数中的权重λ赋值为0.4,而维纳反卷积过程中的参数K为0.00045。所有实验均在单个NVIDIA RTX 3090 GPU上进行,整个训练过程大约需要24小时完成。由于我们无法直接在无透镜捕获上运行COLMAP[26],我们使用从FlatNet恢复的图像运行COLMAP并提取相机姿态和边界。
5.4 比较
在缺乏专门针对无透镜图像新视角合成的研究的情况下,我们提出了几种基线方法来评估我们的方法。
表1. 在NeRF-LLFF数据集的8个场景上进行的场景特定实验的定量结果(平均值)。 最佳分数和次佳分数分别用各自的颜色高亮显示。
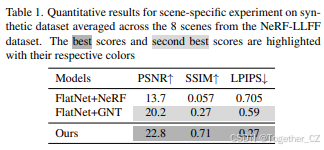
FlatNet+NeRF。这种方法首先应用FlatNet细化无透镜捕获,然后使用NeRF进行渲染。这是使用场景特定方法(如NeRFs)的主要缺点,因为它们依赖于图像的监督,因此无法明确训练以细化无透镜捕获。此外,该基线无法推广到不同场景。
FlatNet+IBRNet。在这里,我们用可推广的IBRNet替换NeRF进行渲染,同时保持FlatNet作为细化模块。
FlatNet+GNT。该基线采用与之前类似的策略,但使用GNT而不是IBRNet进行渲染。FlatNet+IBRNet和FlatNet+GNT都设计为推广到不同场景。
5.5 结果
场景特定微调。我们旨在通过使用相应的地面真实RGB图像监督模型,从多视角无透镜图像中合成细化的新视图。为了评估我们方法的有效性,我们将其与两种基线方法进行比较:FlatNet+NeRF和FlatNet+GNT。我们使用FlatNet输出监督NeRF模型,因为无法使用地面真实标签对其进行监督,因为它接受坐标和观察方向作为输入而不是图像。相比之下,对于FlatNet+GNT基线,FlatNet的输出作为输入提供给GNT,并使用地面真实RGB图像进行监督。评估在合成NeRF-LLFF数据集上进行,结果详见表1。我们提出的方法GANESH在所有三个指标上均优于两种基线模型。这种改进可以归因于联合细化和渲染策略,从而提高了整体重建质量。在我们的多视角设置中,一个视图中丢失的信息可以从另一个视图中恢复,这是我们的方法所利用的特征。相比之下,基线方法顺序执行细化和渲染,错过了联合优化的潜在好处。

图6. 在真实世界LenslessScenes数据集上的定性结果。 我们展示了LenslessScenes数据集中4个场景的结果。尽管我们的模型是在合成数据上训练的,但它能够推广到真实世界的捕获数据,并且在渲染质量上优于两种基线方法。
图4展示了性能的定性差异。FlatNet+NeRF模型存在显著的鬼影伪影,可能是由于FlatNet生成的输出不一致,这些输出用于监督NeRF。虽然FlatNet+GNT通过其更复杂的架构改进了这些问题,但它仍然表现出过度的平滑效果。相比之下,我们的方法实现了卓越的细化和渲染,生成了高质量的新视图。这表明我们在3D上下文中的联合细化和渲染方法显著提高了无透镜成像中新视角合成的准确性。
可推广设置。我们在推广场景中评估我们的方法,其中模型在未见过的场景上进行测试,使用NeRF-LLFF数据集中的八个场景。这些场景的平均结果总结在表2中。我们的方法明显优于FlatNet+IBRNet和FlatNet+GNT基线,在所有三个评估指标上均表现出更高的性能。图5提供了我们方法和基线渲染的新视图的视觉比较。我们的模型成功恢复了复杂的场景细节,如塑料堡垒上的细微凹槽和叶子上的脉络,具有比其它方法显著更高的保真度。这突显了我们的方法在具有挑战性的推广设置中渲染高质量新视图的有效性。
真实世界数据集的定量结果。为了评估我们模型在真实世界数据上的鲁棒性,我们在_LenslessScenes_数据集上评估其性能。我们将其与FlatNet+NeRF和FlatNet+GNT基线进行比较。与之前的实验一样,FlatNet+NeRF基线使用FlatNet的输出监督NeRF,而FlatNet+GNT直接应用于真实场景,无需对真实世界数据进行任何微调。这些比较的定量和定性评估见表3和图6。定性上,我们的模型展示了比基线更好的恢复精细场景细节的能力。例如,图中围绕火炬的玩具的形状和几何形状是可见的,与基线方法的结果形成对比,在基线方法中它们几乎无法辨认。定量结果进一步支持了这一观察,展示了从合成数据转移到真实世界数据时的改进性能。这些发现突显了我们联合细化和渲染方法的有效性,与将细化和渲染视为独立任务的方法相比,显著增强了3D场景重建。
5.6 消融研究
我们进行了以下消融研究以验证我们的无透镜模拟管道,并提供在真实世界数据上评估的定量结果,以测试我们模拟的有效性。
灰度与RGB PSF映射。我们的实验结果表明,使用灰度PSF重建无透镜图像始终优于使用3通道RGB PSF,如表4所示。我们假设这一优势源于灰度PSF更接近实际无透镜相机捕获图像的方式。因此,在模拟过程中使用灰度PSF映射在测试真实世界数据集时产生了更好的结果。
合成噪声。虽然我们的模型对低水平噪声具有弹性,但在训练期间向无透镜图像添加合成噪声对于适应真实世界场景至关重要。在训练合成捕获期间,人为引入高斯噪声作为读取噪声。我们在真实世界数据上测试了这一模型,结果见表5。真实世界捕获中观察到的显著噪声需要这种方法,并且在训练管道中引入噪声增强了模型的鲁棒性和推广到真实世界场景的能力。
6 讨论
局限性和未来工作。虽然GANESH展示了在场景特定和可推广设置中从无透镜捕获中细化和渲染新视图的能力,但它并非没有局限性。它面临的一个主要挑战是,模型在推广到不同场景时需要大量的训练时间,并且其推理速度未针对实时应用进行优化,这对即时渲染任务构成了限制。最后,GANESH是一个完全数据驱动的模型,在广泛的数据集上进行训练以模拟重建任务。将物理光传输模型集成到辐射场中可能是未来改进的一个有前景的方向,结合数据驱动方法和物理原理以实现更准确和高效的无透镜渲染。
结论。在这项工作中,我们提出了GANESH,这是一个新颖的框架,将多视角无透镜捕获的细化和新视图渲染集成到一个可推广的框架中,展示了在真实世界场景中的鲁棒性。虽然现有的方法(如FlatNet用于细化和NeRF或高斯泼溅(GS)用于渲染)可以顺序使用,但它们从根本上受到对图像监督的依赖的限制,使得在广泛的合成数据集上进行训练变得不切实际。相比之下,GANESH实现了联合细化和渲染,解决了这一限制,并在新视角合成中实现了卓越的性能。这种方法对于各种应用至关重要,包括医学成像(如内窥镜检查)、增强和虚拟现实(AR/VR)以及可穿戴技术。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











