






这篇文章提出了一种名为Structure-CLIP的新框架,旨在通过引入场景图知识(Scene Graph Knowledge, SGK)来增强多模态(图像-文本)任务中的结构化表示能力。现有的视觉-语言模型(如CLIP)在处理需要结构化理解的任务(如区分“宇航员骑马”和“马骑宇航员”)时表现不佳,因为它们缺乏对对象、属性和关系的细粒度理解。
主要贡献:
-
语义负采样:通过场景图生成高质量的负样本,确保负样本在保持句子结构不变的情况下改变语义,从而迫使模型学习结构化表示。
-
知识增强编码器(KEE):利用场景图作为输入,显式地建模对象、属性和关系,进一步增强结构化表示。
-
实验验证:在多个数据集(如VG-Relation、VG-Attribution和MSCOCO)上的实验表明,Structure-CLIP在结构化表示任务上达到了最先进的性能,同时在通用表示任务上保持了较强的能力。
实验结果:
-
VG-Relation和VG-Attribution:Structure-CLIP在这两个数据集上分别比现有的多模态SOTA模型(NegCLIP)高出4.1%和12.5%。
-
MSCOCO:在保持通用表示能力的同时,Structure-CLIP在图像-文本检索任务上也表现优异。
Structure-CLIP通过引入场景图知识,显著提升了多模态任务中的结构化表示能力,同时保持了模型的通用表示能力。该方法为多模态理解任务提供了一种新的思路,特别是在需要细粒度语义理解的场景中。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里,如下所示:
摘要:
大规模视觉-语言预训练在多模态理解和生成任务中取得了显著成果。然而,现有方法在需要结构化表示(即对象、属性和关系的表示)的图像-文本匹配任务中表现不佳。如图1(a)所示,模型无法区分“宇航员骑马”和“马骑宇航员”。这是因为它们在学习多模态场景中的表示时未能充分利用结构化知识。本文提出了一个端到端的框架Structure-CLIP,该框架集成了场景图知识(SGK)以增强多模态结构化表示。首先,我们使用场景图来指导语义负例的构建,从而增加对学习结构化表示的重视。此外,我们提出了一个知识增强编码器(KEE),利用SGK作为输入进一步增强结构化表示。为了验证所提出框架的有效性,我们使用上述方法对模型进行预训练,并在下游任务上进行实验。实验结果表明,Structure-CLIP在VG-Attribution和VG-Relation数据集上达到了最先进(SOTA)的性能,分别比多模态SOTA模型领先12.5%和4.1%。同时,MSCOCO上的结果表明,Structure-CLIP在保持通用表示能力的同时,显著增强了结构化表示。
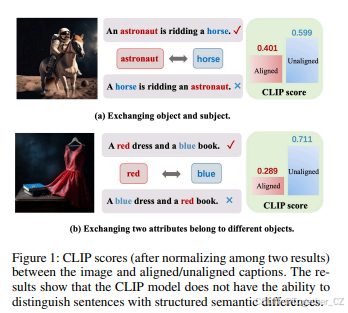
图1:图像与对齐/不对齐标题之间的CLIP分数(在两个结果之间进行归一化)。结果表明,CLIP模型无法区分具有结构化语义差异的句子。
1. 引言
视觉-语言模型(VLMs)在各种多模态理解和生成任务中展示了显著的性能(Radford等,2021;Li等,2022;Singh等,2022;Li等,2019)。尽管多模态模型在各种任务中表现令人印象深刻,但这些模型是否能有效捕捉结构化知识(即理解对象属性及对象间关系的能力)仍然是一个未解决的问题。
例如,如图1(a)所示,图像与正确匹配的标题(“宇航员骑马”)之间的CLIP分数(即语义相似性)低于图像与非匹配标题(“马骑宇航员”)之间的分数。随后,图1(b)展示了在两个对象之间交换属性也会给模型准确区分其语义带来挑战。这些发现表明,CLIP模型生成的通用表示无法区分包含相同单词但在结构化知识上有所不同的文本片段。换句话说,CLIP模型表现出类似于词袋方法的倾向,无法理解句子中的细粒度语义(Lin等,2023)。
Winoground(Thrush等,2022)是第一个关注此问题并进行了广泛研究的工作。他们有意创建了一个包含400个实例的数据集,每个实例由两个单词组成相同但语义不同的句子组成。他们评估了各种表现良好的VLM(如VinVL(Zhang等,2021)、UNITER(Chen等,2020)、ViLBERT(Lu等,2019)和CLIP(Radford等,2021)),旨在评估与对象、属性和关系相关的结构化表示。不幸的是,他们的结果表明,尽管这些模型在其他任务中表现出人类水平的熟练度,但结果与随机选择相当。这些任务的结果表明,通用表示不足以进行语义理解。因此,推断应更加重视结构化表示。
NegCLIP(Yuksekgontil等,2022)通过集成任务特定的负样本来增强结构化表示,这些负样本是通过随机交换句子中的任意两个单词生成的。因此,尽管通用表示在正负样本中保持一致,但结构化表示表现出差异。通过对比学习方法,它迫使模型学习结构化表示而非通用表示。此外,NegCLIP还提供了一个大规模的测试平台来评估VLM在结构化表示方面的能力。然而,NegCLIP在负样本构建过程中缺乏对语义知识的理解和建模,导致负样本质量显著下降。例如,当原始标题“黑白奶牛”中的属性“白色”和“黑色”互换时,句子的潜在语义保持不变。这种低质量的负样本进一步导致性能下降。
在本文中,我们提出了Structure-CLIP,这是一种利用场景图知识(SGK)来增强多模态结构化表示的新方法。首先,与NegCLIP中的随机交换方法不同,我们利用SGK来构建更符合潜在意图的单词交换。其次,我们提出了一个知识增强编码器(KEE),利用SGK提取关键的结构信息。通过在输入层面引入结构化知识,所提出的KEE可以进一步增强结构化表示的能力。在Visual Genome Relation和Visual Genome Attribution上的结果表明,Structure-CLIP达到了最先进(SOTA)的性能及其组件的有效性。此外,我们在MSCOCO上进行了跨模态检索评估,结果表明Structure-CLIP仍然保留了足够的通用表示能力。
总体而言,我们的贡献有三点:
-
据我们所知,Structure-CLIP是第一个通过构建语义负例来增强细粒度结构化表示的方法。
-
Structure-CLIP中引入了知识增强编码器,利用结构化知识作为输入来增强结构化表示。
-
我们进行了全面的实验,证明Structure-CLIP能够在结构化表示的下游任务中实现SOTA性能,并在结构化表示方面取得了显著改进。
2. 相关工作
2.1 视觉语言预训练
视觉-语言模型(VLMs)旨在学习通用的跨模态表示,这有助于在下游多模态任务中实现强大的性能。根据多模态下游任务的不同,开发了不同的模型架构,包括双编码器架构(Radford等,2021;Jia等,2021)、融合编码器架构(Tan和Bansal,2019;Li等,2021)、编码器-解码器架构(Cho等,2021;Wang等,2022;Chen等,2022),以及最近的统一Transformer架构(Li等,2022;Wang等,2022)。
预训练任务对VLM从数据中学到的内容有很大影响。主要有4种类型的任务:
(i) 跨模态掩码语言建模(MLM)(Kim等,2021;Lin等,2020;Li等,2021;Yu等,2022);
(ii) 跨模态掩码区域预测(MRP)(Lu等,2019;Chen等,2020;Huang等,2021);
(iii) 图像-文本匹配(ITM)(Li等,2020;Lu等,2019;Chen等,2020;Huang等,2021);
(iv) 跨模态对比学习(CMCL)(Radford等,2021;Jia等,2021;Li等,2021;Huo等,2021;Li等,2021)。
最近的研究主要集中在CMCL的研究上。以CLIP模型(Radford等,2021)为例,该模型通过将正样本与数据集中的所有其他负样本进行比较,学习了足够的通用表示。
2.2 结构化表示学习
结构化表示指的是能够匹配具有相同单词组成的图像和文本的能力。Winoground(Thrush等,2022)首次提出了一个新颖的任务和数据集,用于评估VLM的能力。该数据集主要由400个手工制作的实例组成,每个实例包括两个单词组成相似但语义不同的句子,以及相应的图像。Winoground的评估结果通过一系列相关任务(即探测任务、图像检索任务)的实验确定了数据集的主要挑战,表明视觉-语言模型的主要挑战可能在于融合视觉和文本表示,而不是组合语言的理解。
由于Winoground测试数据量有限,很难在结构化表示能力上得出可靠的实验结果。最近,NegCLIP(Yuksekgontil等,2022)提供了一个大规模的测试平台来评估VLM的结构化表示。此外,NegCLIP还提出了一种负采样方法来增强结构化表示。
2.3 场景图生成
场景图是一种结构化知识,它通过建模对象、对象属性和对象与主体之间的关系来描述多模态样本的最基本部分。通常,场景图生成(SGG)模型由三个主要模块组成:对象定位(定位对象的边界框)、对象分类(标记检测到的对象)和关系预测(预测成对对象之间的关系)。一些现有工作(Xu等,2017;Yang等,2018;Zellers等,2018)应用RNN和GCN来传播图像上下文,以便更好地利用上下文进行对象和关系预测。VCTree(Tang等,2019)通过利用动态树结构捕捉局部和全局视觉上下文。Gu等(2019)和Chen等(2019)将外部知识集成到SGG模型中,以解决噪声注释的偏差。
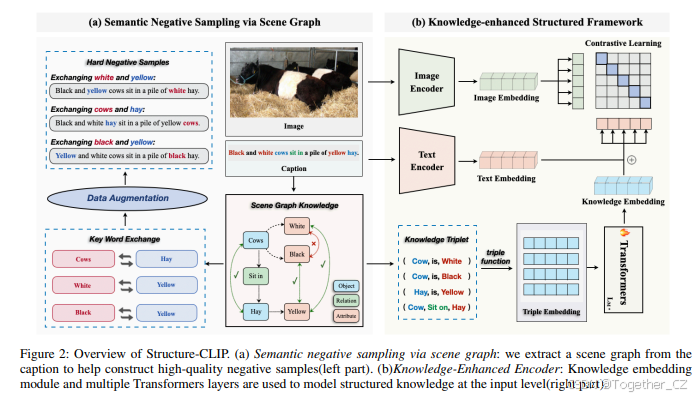
图2:Structure-CLIP的概述。(a) 通过场景图进行语义负采样:我们从标题中提取场景图,以帮助构建高质量的负样本(左部分)。(b) 知识增强编码器:知识嵌入模块和多个Transformer层用于在输入层面建模结构化知识(右部分)。
作为一种描述图像和标题详细语义的有益先验知识,场景图在多个视觉-语言任务中帮助实现了出色的性能,例如图像字幕生成(Yang等,2019)、图像检索(Wu等,2019a)、视觉问答(Zhang等,2019;Wang等,2022b)、多模态情感分类(Huang等,2022)、图像生成(Johnson等,2018)和视觉-语言预训练(Yu等,2021)。
3. 方法论
Structure-CLIP的概述如图2所示。首先,我们的方法利用场景图通过生成具有相同单词组成但不同详细语义的语义负样本来增强细粒度结构化表示(图2的左部分)。其次,我们提出了一个知识增强编码器,利用场景图作为输入,将结构化知识集成到结构化表示中(图2的右部分)。我们将在第3.1节中介绍通过场景图进行语义负采样,并在第3.2节中介绍知识增强编码器。
3.1 通过场景图进行语义负采样
Faghri等(2018)提出了一种负采样方法,通过构建负样本来增强表示,并将其与正样本进行比较。我们的目标是构建具有相似通用表示但不同详细语义的样本,从而鼓励模型专注于学习结构化表示。

如图2所示,我们基于原始标题生成场景图。以图2中的标题“黑白奶牛坐在一堆黄色干草中”为例,在生成的场景图中,对象如“奶牛”和“干草”是基本元素。相关属性如“白色”和“黄色”表征对象的颜色或其他属性。关系如“坐在”表示对象之间的空间连接。
语义负样本的选择。对比学习旨在通过将语义相近的邻居拉近并将非邻居推开,从而学习有效的表示。我们的目标是构建具有相似组成但不同详细语义的语义负样本。因此,负样本的质量在结构化表示学习中起着至关重要的作用。

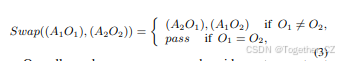
总体而言,我们利用场景图指导构建高质量的语义负样本,而不是随机交换单词位置。我们的语义负样本保持相同的句子组成,同时改变详细语义。因此,我们的模型可以更有效地学习详细语义的结构化表示。

因此,最终的损失结合了hinge损失和InfoNCE损失:
![]()
3.2 知识增强编码器
在本节中,我们提出了一个知识增强编码器,它利用场景图作为文本输入来增强结构化表示。首先,我们使用以下函数对图像Ii和文本Wi进行编码:


知识增强编码器使我们能够从所有输入三元组中提取足够的结构化知识,这些知识可以作为有效的结构化知识来提高结构化表示的性能。
因此,知识增强编码器可用于获取文本知识嵌入。然而,仅依赖结构化知识可能会导致通用语义表示的丢失。因此,我们将文本嵌入和结构化知识嵌入结合起来:

我们的文本表示既包含整个句子携带的单词信息,也包含由句子中的详细语义组成的结构化知识。类似地,我们在训练过程中使用了与公式5相同的损失策略。
4. 实验
4.1 数据集
预训练数据集。高质量的图像-文本对齐数据是训练模型的关键。我们采用了广泛使用的跨模态文本-图像检索数据集MSCOCO(Lin等,2014)。与之前的工作(Li等,2022)一致,我们使用Karpathy(Karpathy和Fei-Fei,2017)划分进行训练和评估。在我们的实验中,预训练通过过滤大约100k涉及多个对象、属性和关系的图像-文本对进行。随后,模型在包含5k图像的测试划分上进行评估。我们报告了图像到文本检索(IR)和文本到图像检索(TR)的Recall@1,以衡量通用表示的能力。
下游数据集。我们使用了两个新颖的数据集(Yuksekgoinil等,2022)来评估不同模型的结构化表示性能,其中每个测试用例由一个图像与匹配的标题和交换的不匹配标题组成。模型的任务是根据相应的图像区分对齐和不对齐的标题。
-
Visual Genome Relation (VG-Relation)。给定一个图像和一个包含关系三元组的标题,我们评估模型选择与图像对齐的标题的能力。具体来说,我们期望模型能够区分“X关系Y”和“Y关系X”与某个图像(例如,图1(a)中的图像“宇航员骑马”与“马骑宇航员”)。
-
Visual Genome Attribution (VG-Attribution)。给定形式“A1 O1和A2 O2”和“A2 O1和A1 O2”,我们评估模型准确归因对象属性的能力。如图1(b)所示,我们期望模型能够根据图像区分标题“红色裙子和蓝色书”与标题“蓝色裙子和红色书”。
4.2 实验设置
我们所有的实验均在单个NVIDIA A100 GPU上使用Pytorch框架进行。我们使用预训练的场景图生成器(Wu等,2019b)提取场景图知识。
结构化知识增强编码器使用6层Transformer架构实现,并使用BERT-base(Devlin等,2019)进行初始化。
在训练阶段,我们使用预训练的CLIP模型初始化模型,并在我们的数据集上训练10个epoch,批量大小为128。我们使用mini-batch AdamW优化器,权重衰减为0.1。学习率初始化为2e-6。知识权重λλ为0.2。
4.3 总体结果
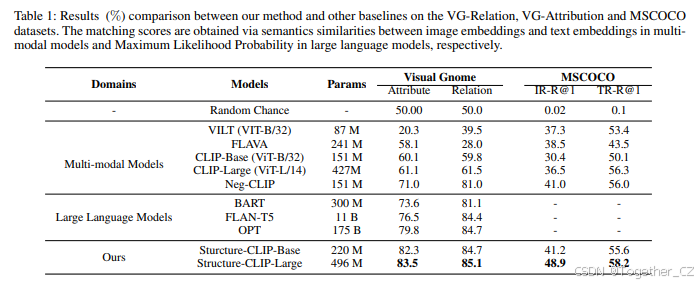
结构化表示任务。我们将我们的方法与8个代表性或SOTA方法进行了比较,包括多模态模型和大型语言模型。如表1所示,我们注意到我们的Structure-CLIP在VG-Relation和VG-Attribute数据集上均达到了SOTA性能。
首先,显然NegCLIP在结构化表示方面优于CLIP模型,这表明上述负样本采样方法可以显著增强结构化表示。此外,通过利用场景图知识指导构建负样本,Structure-CLIP进一步增强了结构化表示。因此,Structure-CLIP在VG-Attribution上比现有的多模态SOTA模型(NegCLIP)领先12.5%,在VG-Relation上领先4.1%。
我们还将Structure-CLIP与现有的使用最大似然概率作为图像和文本匹配分数的大型语言模型(LLMs)进行了比较。我们的结果表明,随着LLMs模型参数的大幅增加,结构化表示也相应提高。然而,尽管Structure-CLIP的参数不到OPT模型的1%,但它仍然比OPT模型分别高出3.7%和0.4%。我们的结果表明,增加模型参数以提高结构化表示是资源密集型的,并且在训练阶段模型主要学习通用表示而不是结构化表示。相比之下,我们提出的Structure-CLIP方法可以显著增强结构化表示,而模型参数仅略有增加,训练量也较小。
通用表示任务。我们评估了Structure-CLIP在通用表示任务上的表现。在基础模型设置下,Structure-CLIP在MSCOCO数据集上实现了与NegCLIP相当的性能。换句话说,在显著提高结构化表示性能的同时,Structure-CLIP保留了通用表示的能力。此外,我们的结果表明,使用Structure-CLIP可以同时获得足够的通用表示和结构化表示,而以前的模型生成的结构化表示不足。在大模型设置下,我们提出的领域微调方法显著增强了结构化表示和通用表示,相比于域外模型。
4.4 消融研究
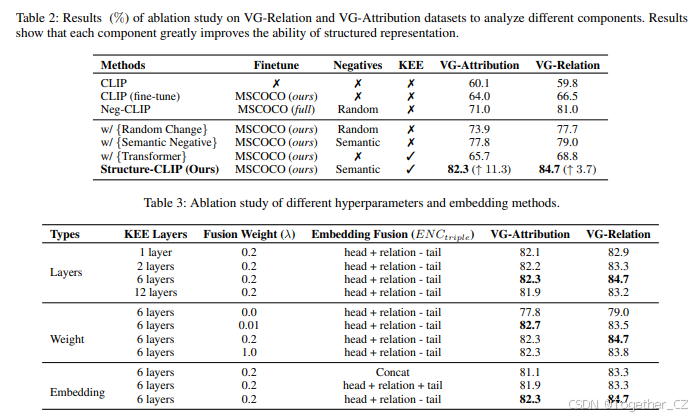
组件分析。我们进行了消融研究,以评估CLIP-base模型的多个增强版本在VG-Relation和VG-Attribution数据集上的表现。每个变体的结果如表2所示。
首先,我们的实验结果表明,应用语义负采样而非随机负采样策略时,性能显著提高(第4行与第5行)。VG-Attribution和VG-Relation数据集上的显著增加分别为3.9%和1.3%,表明所提出的方法生成了更高质量的负样本,从而产生了更优的结构化表示。
通过提出的知识增强编码器将结构化知识作为输入集成,仅带来了轻微的改进(第2行与第6行)。这些发现表明,为了获得足够的结构化表示,负样本采样的引入是必要的。因此,知识增强编码器在与语义负采样结合后实现了显著增强(第5行与第7行)。
超参数分析。基于Structure-CLIP的实验结果(表3),我们可以得出以下结论:
(i) 随着知识Transformer层数的增加,模型表示多模态结构化表示的能力提高。然而,需要注意的是,超过某个阈值后,可用数据可能不足以支持模型增加的能力,导致潜在的过拟合。
(ii) 实验结果表明,如果没有结构化知识集成,模型的性能不理想(第5行)。相反,当集成结构化知识时,不同权重下的性能差异最小,表明我们的方法在增强结构表示方面的有效性和直观性。
三元组嵌入。我们探索了三种不同的三元组嵌入方法来集成三元组。concat方法考虑了输入三元组元素的顺序,但未能考虑头实体、关系实体和尾实体的组合关系。head + relation + tail方法结合了三元组之间的组合关系。然而,它们缺乏区分三元组顺序的能力。例如,两个三元组(奶牛,是,白色)和(白色,是,奶牛)的最终嵌入是相同的,这无法帮助模型进行区分。与这些方法相比,我们的三元组嵌入方法同时考虑了位置和组合信息。通过这种方式,我们的Structure-CLIP模型能够更好地利用句子中的结构化知识来捕捉细粒度语义信息,并增强多模态结构化表示。
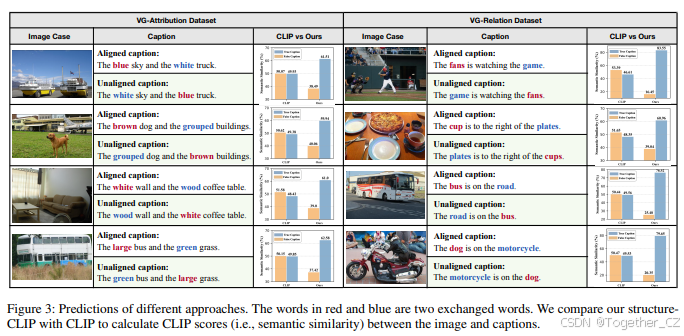
4.5 案例研究
VG-Relation和VG-Attribution中的案例预测结果如图3所示,清楚地表明Structure-CLIP能够成功区分给定图像的对齐和不对齐标题,且差距非常大。然而,CLIP模型在准确确定这些标题与给定图像之间的语义相似性方面遇到了挑战。特别是,当两个属性或对象交换时,CLIP模型表现出近乎一致的语义相似性,表明其缺乏捕捉结构化语义的能力。与CLIP模型相比,Structure-CLIP对细粒度语义的修改表现出敏感性,表明其在表示结构化知识方面的能力。例如,标题“蓝天和白卡车”用于评估Structure-CLIP在两个属性(即蓝色和白色)交换时区分对齐和不对齐标题的能力。结果表明,Structure-CLIP能够以25.16%的差距区分对齐和不对齐的标题,进一步验证了所提出方法在增强多模态结构化表示方面的有效性。
5. 结论
在本文中,我们提出了Structure-CLIP,旨在集成场景图知识以增强多模态结构化表示。首先,我们使用场景图来指导语义负例的构建。此外,我们引入了一个知识增强编码器,利用场景图知识作为输入,从而进一步增强结构化表示。我们提出的Structure-CLIP在预训练任务和下游任务上优于所有最新方法,这表明Structure-CLIP能够有效且稳健地理解多模态场景中的详细语义。
附录
A.1 数据集统计
预训练数据集。高质量的图像-文本对齐数据是训练模型的关键。我们聚焦于标准的跨模态文本-图像检索数据集MSCOCO(Lin等,2014)。根据之前的工作(Li等,2022),我们使用Karpathy(Karpathy和Fei-Fei,2017)划分进行该数据集。鉴于细粒度语义在我们的上下文中的重要性,预训练通过过滤近100k包含属性和关系的图像-文本对进行。随后,模型在包含5k图像的测试划分上进行评估。我们报告了图像到文本检索和文本到图像检索的Recall@1、Recall@5和Recall@10。
下游数据集。我们评估了两个新颖的数据集(Yuksekgonul等,2022)以探测关系和属性理解。每个测试用例由一个图像(例如,宇航员骑马的图像)和一个匹配的标题(例如,“宇航员骑马”)以及交换的不匹配标题(例如,“马骑宇航员”)组成。对于这些数据集中的每个测试用例,我们量化每个模型从两个备选方案中识别正确标题的性能。
A.2 基线补充
我们采用了三种类型的基线。每个基线的详细信息如下:
随机机会。对于这些数据集中的每个测试用例,我们量化每个模型从两个备选方案中识别正确标题的性能,即随机机会水平性能为50%。
多模态模型。
-
VILT(Kim等,2021)大大简化了视觉输入的处理,采用与文本输入相同的无卷积方式。我们报告了VILT的“VITB/32”变体的结果。
-
FLAVA(Singh等,2022)通过在单模态和多模态数据上的联合预训练学习强表示,同时涵盖跨模态“对齐”目标和多模态“融合”目标。我们使用了Huggingface Transformers库中发布的模型。我们遵循作者分享的教程,并使用“FLAVA-full”变体。
-
BLIP(Li等,2022)使用从大规模噪声图像-文本对中引导的数据集预训练多模态编码器-解码器模型,通过注入多样化的合成标题并去除噪声标题。我们报告了BLIP的“Base”变体的结果。
-
CLIP(Radford等,2021)通过对比学习学习文本和图像之间的对齐。我们使用了CLIP的“VITB/32”变体。
-
Neg-CLIP(Yuksekgonul等,2022)提出了一个简单的修复方法:挖掘组合感知的硬负样本。

大型语言模型。
-
BART(Yuan等,2021)是基于生成范式的基线。我们将标题传递给纯LLM以计算仅文本的GPTScore。
-
FLAN-T5(Chung等,2022)具有强大的泛化性能,因此单个模型可以在1800多个NLP任务上表现良好。
-
OPT(Zhang等)是一套仅解码器的预训练Transformer,参数范围从125M到175B,旨在与感兴趣的研究人员充分且负责任地共享。
A.3 语义负样本与硬负样本
在本节中,我们将详细介绍语义负采样和硬负采样方法。此外,概述如图4所示。
NegCLIP中使用的硬负采样方法通过随机单词交换获得负样本。然而,这种方法缺乏语义知识,可能在生成负样本时引入显著错误。如图4所示,通过交换单词“白色”和“黑色”生成的负样本可能会无意中生成正样本。此外,交换单词“in”和“and”会使句子语义模糊且语法不清。
因此,生成的负样本的质量对最终模型的性能有重大影响。因此,我们提出了一种语义负采样方法,在选择要交换的单词时结合了结构知识。具体来说,我们首先从文本句子中提取结构化知识(场景图知识),包括对象、属性和关系,如图4右下角所示。然后我们使用场景图知识指导负样本的构建。例如,单词“白色”和“黄色”与不同的对象相关,因此我们交换这两个单词以获得语义不同的对象-属性对。我们还交换与关系词(“坐在”)相关的对象(“奶牛”)和主体(“干草”)。因此,我们的方法可以生成高质量的语义负样本。
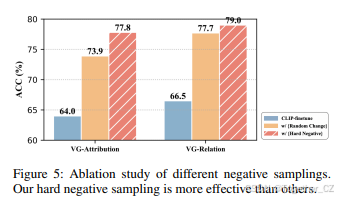
我们使用图5直观地展示了我们采样方法的有效性。我们的结果表明,在不使用任何额外采样方法的情况下进行微调对结构化表示的影响最小。此外,在引入随机交换策略后,结构化表示显著提高(图5中的结果与NegCLIP中获得的结果略有不同,因为我们在构建的数据集中实现了硬负方法,详见第4.1节)。然而,这种方法忽略了句子中的结构化知识,从而无法全面探索对比学习方法的影响。相比之下,我们提出的语义负方法利用高质量负样本增强结构化表示,VG-Attribution提高了3.9%,VG-Relation提高了1.3%。
A.4 实验补充
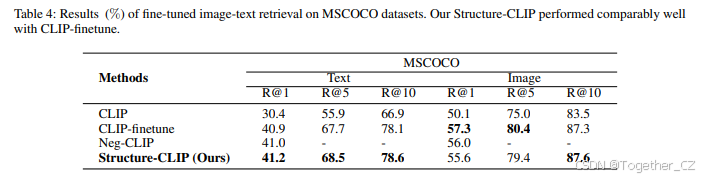
扩展通用表示任务的结果。我们在MSCOCO数据集训练划分的一个子集上对所有模型进行了微调,然后在验证划分上进行了验证。由于我们提出的方法需要基于三元组中的对象或对中的形容词构建负样本,因此在构建负样本时我们还考虑了形容词修饰一个名词的特殊情况。为了解决这些问题,我们使用了MSCOCO数据集训练划分的一个子集作为我们的微调数据语料库。
图像-文本检索包括两个子任务:图像到文本检索和文本到图像检索。我们在微调设置下评估了我们的Structure-CLIP模型在一个检索基准数据集上的表现:MSCOCO。微调图像-文本检索的结果如表4所示。我们的比较包括之前的方法,如CLIP、CLIP-finetune和Neg-CLIP。结果表明,Structure-CLIP在MSCOCO数据集上表现相当好。值得注意的是,它在文本检索的Recall@10和图像检索的Recall@10上分别比CLIP-finetune高出0.5分和0.3分。这些发现表明,Structure-CLIP不仅增强了在下游任务中捕捉详细语义的能力,还提高了多模型预训练的整体性能。
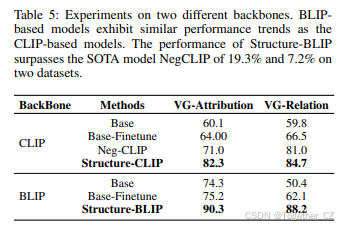
在其他骨干上的扩展方法。我们在CLIP模型骨干上进行了Structure-CLIP实验,并通过在其他骨干上进行实验进一步验证了该方法的可移植性。表5还展示了我们在BLIP骨干上的实验结果。
首先,我们观察到基于BLIP的模型表现出与基于CLIP的模型相似的性能趋势。具体来说,原始BLIP模型在两个结构化表示下游任务上表现不佳,仅略好于随机机会。使用之前的通用表示方法微调模型导致其性能略有提高,而使用我们提出的方法训练则显著增强了结构化表示。这表明我们提出的方法可以有效增强结构化表示,并且可以广泛应用于多模态模型。
此外,通过将我们提出的方法应用于更优的基础模型BLIP,我们在VG-Attribution和VG-Relation上分别实现了90.3%和88.2%的优越结构化表示,超越了SOTA模型NegCLIP的19.3%和7.2%。
A.5 未来工作
知识图谱(KGs)已被实证验证在多个下游应用中提供了实质性好处。它们作为知识补充和数据增强的重要来源,用于各种任务,如问答(Chen等,2021a)、零样本学习(Chen等,2021b;Cheng等,2021)。我们还注意到存在各种KG内任务,如实体对齐(Chen等,2022b;Cheng等,2022c)和链接预测(Zhang等,2023)。
尽管文本中的场景图知识有助于细粒度图像-文本匹配,但知识仍然局限于固定句子本身。因此,我们考虑建立知识图谱与句子中详细语义之间的联系,允许外部知识指导图像和文本匹配,从而使模型能够充分理解句子中的详细信息与图像之间的联系。
此外,我们相信我们提出的方法可以从多模态内容理解领域扩展到文本到图像生成任务。我们计划研究如何将细粒度语义信息融入图像中,并将其作为未来研究的方向。



















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











