






在科技与能源领域日新月异的今天,清洁新能源,尤其是太阳能,正以前所未有的速度改变着我们的能源结构。太阳能光伏板,这一将太阳光转化为电能的神奇装置,已悄然走进千家万户,成为推动绿色能源革命的重要力量。然而,光伏板的运维管理却是一项复杂而艰巨的任务,尤其是积尘、老化、破损、污渍等问题,严重影响了其发电效率,成为制约太阳能产业发展的瓶颈。传统上,光伏板的巡检与维护依赖于经验丰富的工程师定期进行人工检查。然而,面对广阔分布的光伏板阵列,人工巡检不仅耗时费力,而且受限于人力资源和地域气象条件,难以实现高效、全面的监控。尤其是在白天,光伏板正处于高效发电状态,频繁的维修作业会严重干扰其正常运行,降低发电效率。而夜间虽然避开了光伏板的作业时间,但人工视力受限,难以准确发现问题,使得夜间巡检成为一项几乎不可能完成的任务。
然而,随着AI智能化模型的快速发展和无人机技术的广泛应用,这一难题终于迎来了破解之道。AI智能化模型以其强大的数据处理能力和模式识别能力,正在逐步取代传统的人工巡检方式,成为提升光伏板运维效率、降低运维成本的关键手段。而无人机技术,则以其灵活机动、覆盖范围广、作业效率高的特点,为AI模型在光伏板巡检中的应用提供了完美的平台。在光伏板夜间巡检运维场景下,无人机可以搭载红外摄像头进行巡航。红外成像技术能够在夜间或低光照条件下提供清晰的图像,使得无人机能够准确捕捉光伏板上的各种问题,如积尘、老化、破损、污渍等。这些图像数据经过专业的标注处理后,成为开发高精度目标检测模型的基础。目标检测模型是AI智能化模型在光伏板巡检中的核心应用之一。它能够自动识别并定位光伏板上的问题区域,实现对光伏板状态的实时监测。相较于人工巡检,AI模型不仅能够大幅提升巡检效率,还能够发现更多细微的问题,确保运维工作的精准性和及时性。更重要的是,AI模型能够基于历史数据和实时数据,进行智能分析和预测,提前发现潜在的风险点,触发预警机制,为运维团队提供充足的时间进行准备和响应。
在前面的系列博文中,我们以及进行了相关的开发实践,不过是建立在白天场景下采集的数据集开发构建的智能化检测模型,感兴趣的话可以自行移步阅读即可:
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv7全系列【tiny/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv9全系列【yolov9/t/s/m/c/e】参数模开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于YOLOv11全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI智能化模型助力太阳能光伏板自动巡检运维,基于嵌入式端超轻量级模型LeYOLO全系列【n/s/m/l】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
这里我们主要是考虑基于红外夜间无人机航拍的形式来进行探索实践,探索夜间巡检运维的可行性,在前文中我们进行了夜间无人机航拍红外场景下的相关开发实践,感兴趣的话可以自行移步阅读即可:
《AI助力红外场景下光伏板夜间巡检运维,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI助力红外场景下光伏板夜间巡检运维,基于YOLOv7全系列【tiny/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI助力红外场景下光伏板夜间巡检运维,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI助力红外场景下光伏板夜间巡检运维,基于YOLOv9全系列【gelan/t/s/m/c/e—yolov9/t/s/m/c/e】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
《AI助力红外场景下光伏板夜间巡检运维,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建无人机航拍场景下太阳能光伏板污损缺陷智能检测识别系统》
本文主要是想要基于YOLO系列最新的目标检测模型YOLOv11全系列的模型来进行相应的开发实践,首先看下实例效果:
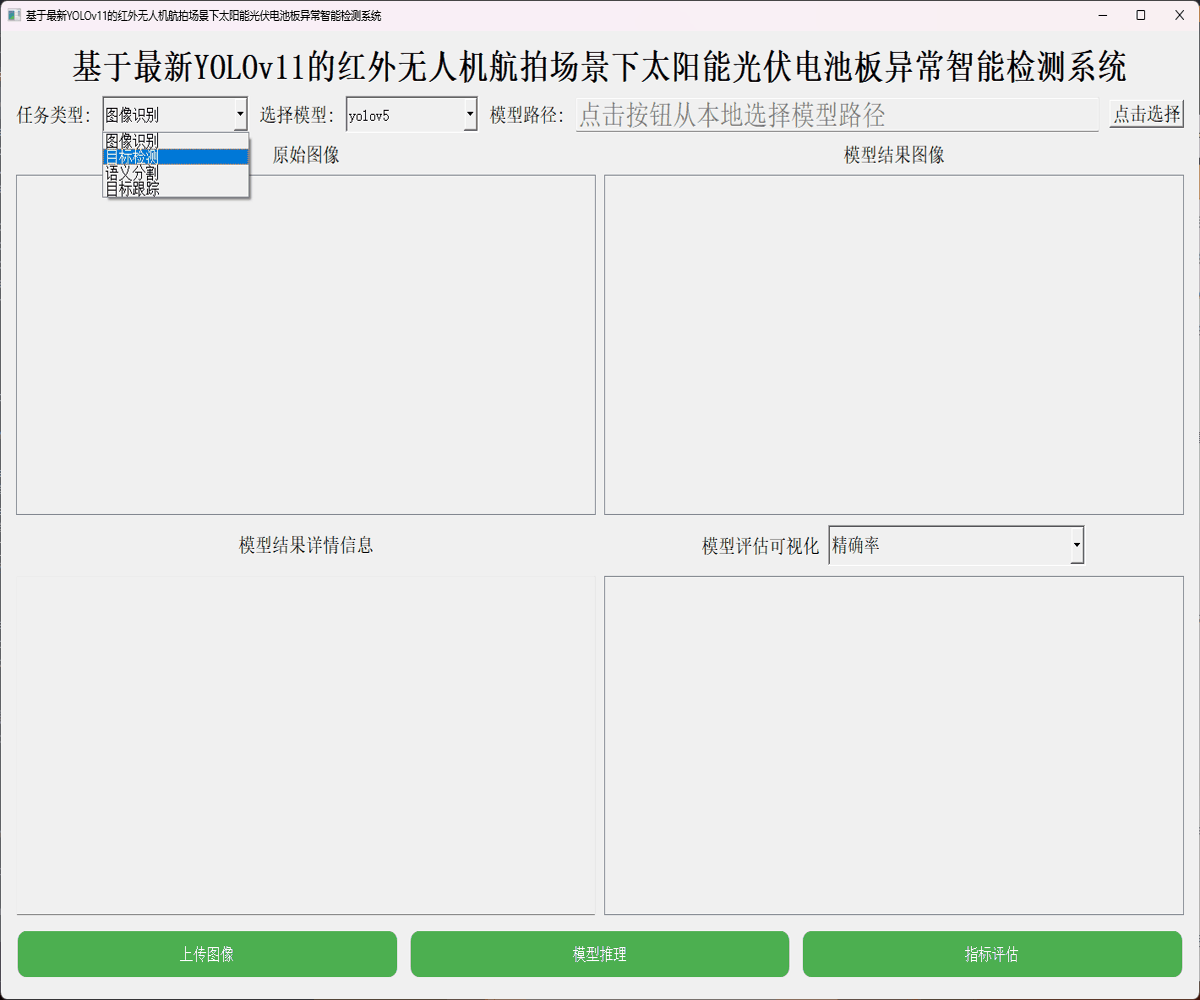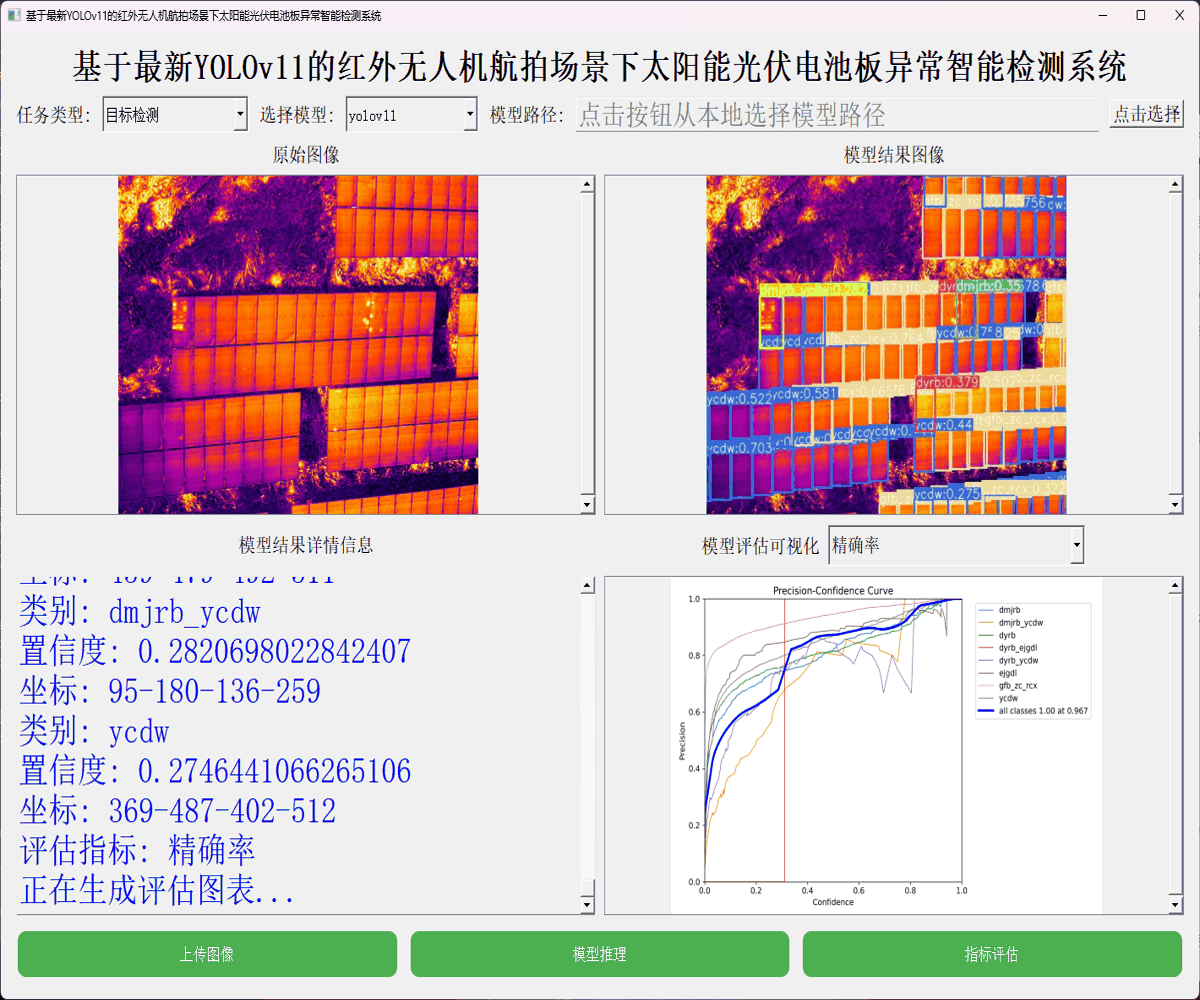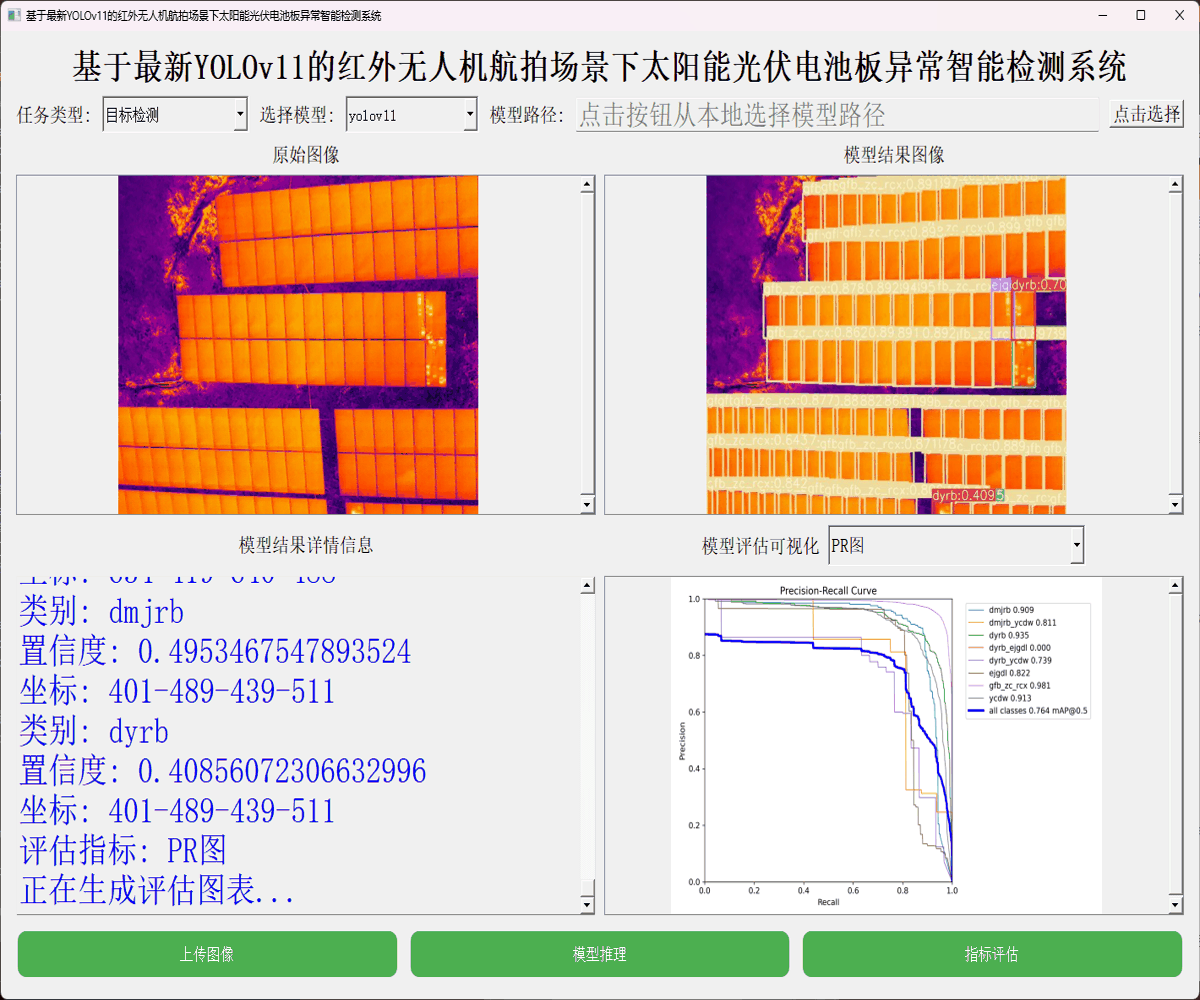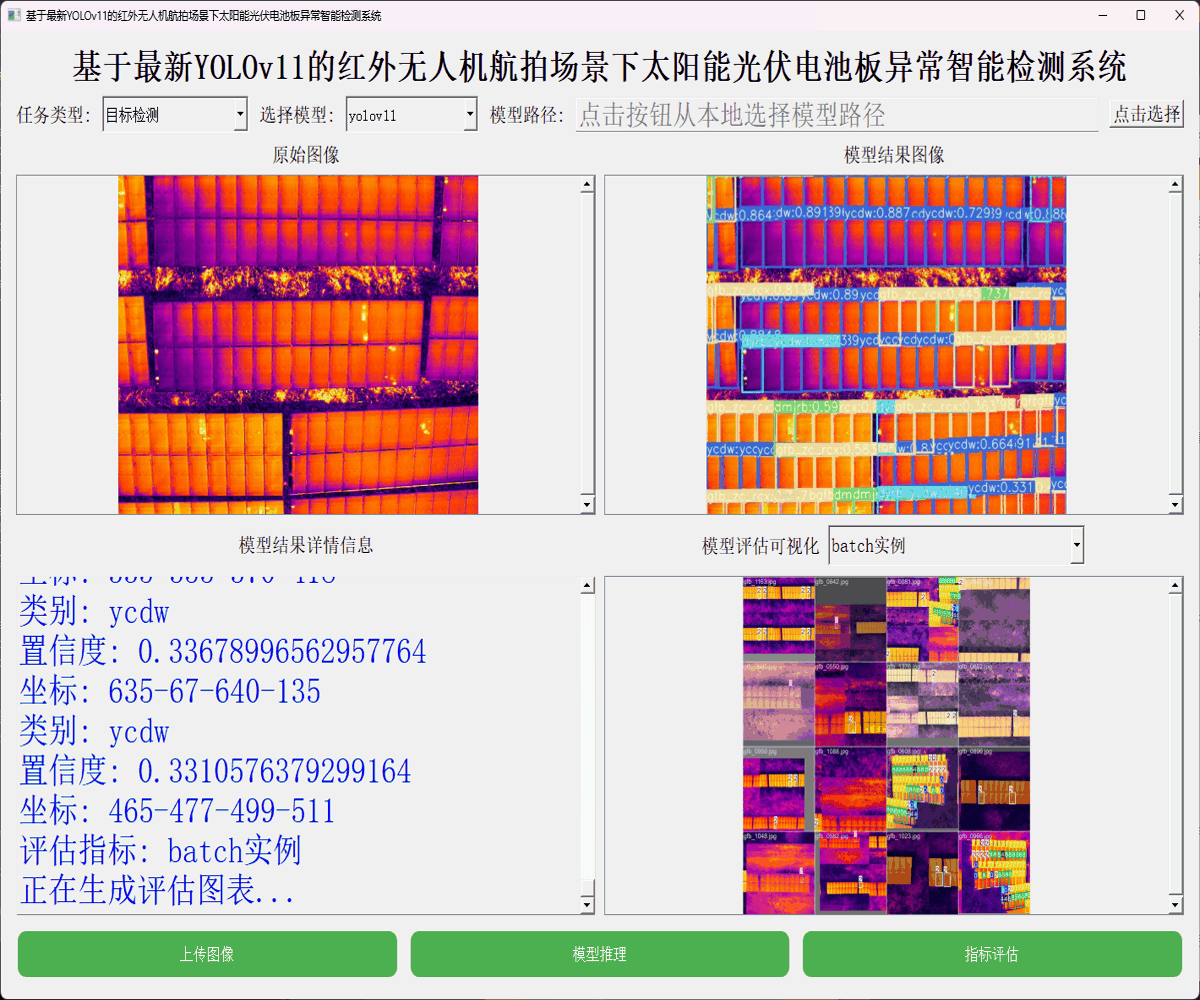
简单看下实例数据:

ultralytics项目自发布以来目前已经逐步迭代至YOLOv11了,不可谓不快速,官方的项目在这里,如下所示:
YOLO11是Ultralytics YOLO系列实时目标检测器的最新版本,以其尖端的准确性、速度和效率重新定义了可能性。基于之前YOLO版本的显著进步,YOLO11在架构和训练方法上引入了重大改进,使其成为广泛计算机视觉任务的多功能选择。
【主要特点】
增强的特征提取:YOLO11采用了改进的骨干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务的性能。
优化的效率和速度:YOLO11引入了精炼的架构设计和优化的训练管道,提供更快的处理速度,并在准确性和性能之间保持最佳平衡。
更少的参数实现更高的准确性:通过模型设计的进步,YOLO11m在COCO数据集上实现了更高的平均精度(mAP),同时比YOLOv8m减少了22%的参数,使其在不影响准确性的情况下计算效率更高。
跨环境的适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台和支持NVIDIA GPU的系统,确保最大的灵活性。
广泛支持的任务:无论是目标检测、实例分割、图像分类、姿态估计还是定向目标检测(OBB),YOLO11都设计用于应对多样化的计算机视觉挑战。
Ultralytics YOLO11在其前身的基础上引入了多项重大进步。关键改进包括:
增强的特征提取:YOLO11采用了改进的骨干和颈部架构,增强了特征提取能力,以实现更精确的目标检测。
优化的效率和速度:精炼的架构设计和优化的训练管道提供了更快的处理速度,同时在准确性和性能之间保持平衡。
更少的参数实现更高的准确性:YOLO11m在COCO数据集上实现了更高的平均精度(mAP),同时比YOLOv8m减少了22%的参数,使其在不影响准确性的情况下计算效率更高。
跨环境的适应性:YOLO11可以部署在各种环境中,包括边缘设备、云平台和支持NVIDIA GPU的系统。
广泛支持的任务:YOLO11支持多样化的计算机视觉任务,如目标检测、实例分割、图像分类、姿态估计和定向目标检测(OBB)。
YOLO11模型具有多功能性,支持广泛的计算机视觉任务,包括:
目标检测:识别和定位图像中的物体。
实例分割:检测物体并描绘其边界。
图像分类:将图像分类为预定义的类别。
姿态估计:检测和跟踪人体上的关键点。
定向目标检测(OBB):检测具有旋转的物体以提高精度。
YOLO11通过模型设计和优化技术的进步,实现了更少的参数实现更高的准确性。改进的架构允许高效的特征提取和处理,从而在COCO等数据集上实现更高的平均精度(mAP),同时比YOLOv8m减少了22%的参数。这使得YOLO11在不影响准确性的情况下计算效率更高,适合部署在资源受限的设备上,YOLO11设计用于适应各种环境,包括边缘设备。其优化的架构和高效的处理能力使其适合部署在边缘设备、云平台和支持NVIDIA GPU的系统上。这种灵活性确保了YOLO11可以在多样化的应用中使用,从移动设备上的实时检测到云环境中的复杂分割任务。
基础实例实现如下:
from ultralytics import YOLO
#n
model = YOLO("weights/yolo11n.pt")
results = model.train(data='data/self.yaml', epochs=100, device=0,batch=32,workers=0,name="yolov11n")
print("results: ", results)
#s
model = YOLO("weights/yolo11s.pt")
results = model.train(data='data/self.yaml', epochs=100, device=0,batch=32,workers=0,name="yolov11s")
print("results: ", results)
#m
model = YOLO("weights/yolo11m.pt")
results = model.train(data='data/self.yaml', epochs=100, device=0,batch=32,workers=0,name="yolov11m")
print("results: ", results)
#l
model = YOLO("weights/yolo11l.pt")
results = model.train(data='data/self.yaml', epochs=100, device=0,batch=32,workers=0,name="yolov11l")
print("results: ", results)
#x
model = YOLO("weights/yolo11x.pt")
results = model.train(data='data/self.yaml', epochs=100, device=0,batch=32,workers=0,name="yolov11x")
print("results: ", results)这里我们依次选择n、s、m、l和x五款不同参数量级的模型来进行开发。
这里给出yolov11的模型文件如下:
# Parameters
nc: 10 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)实验阶段我们保持了相同的参数设置,等待长时期的训练过程结束之后我们来对以上六款不同参数量级的模型进行纵向的对比分析,如下:
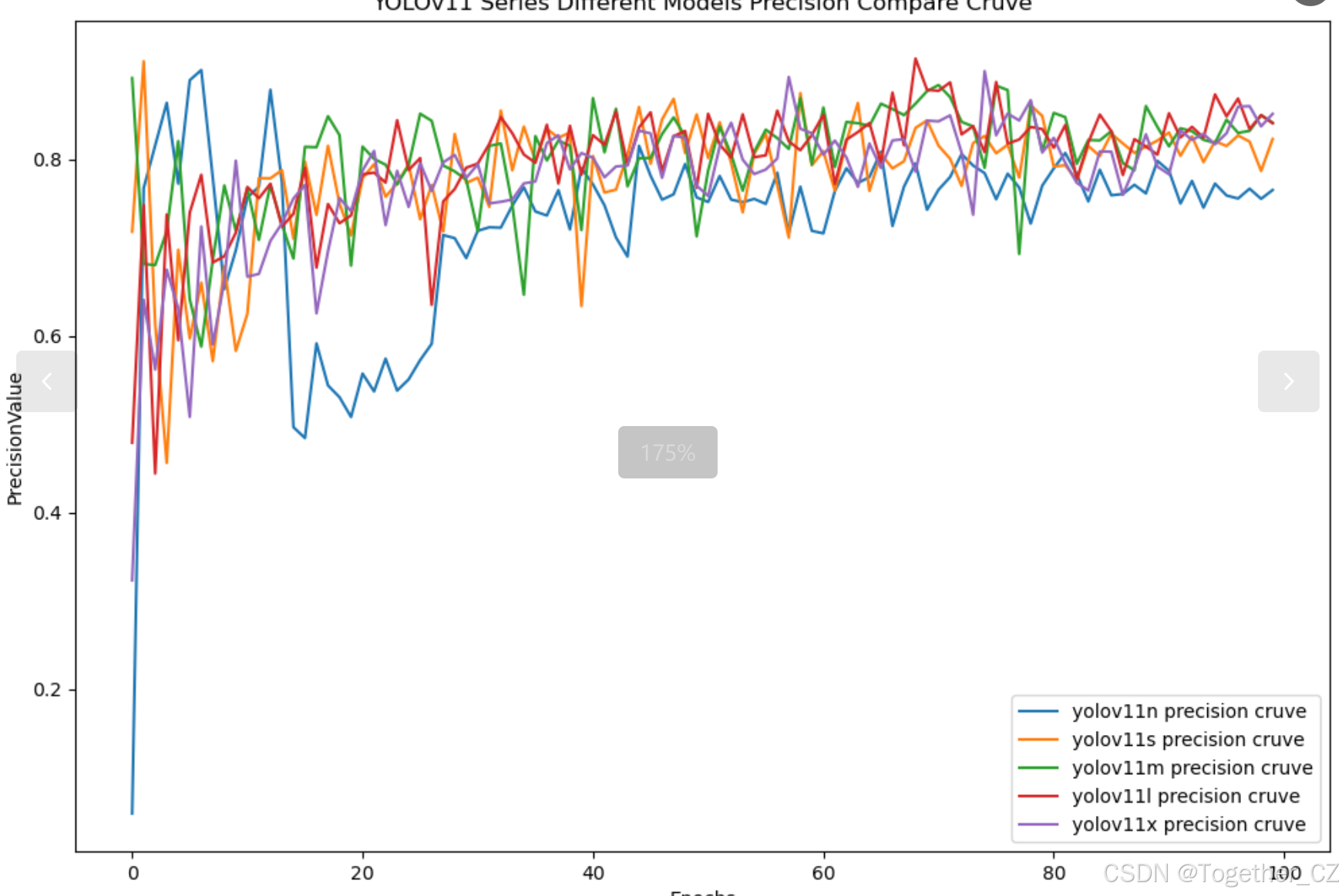
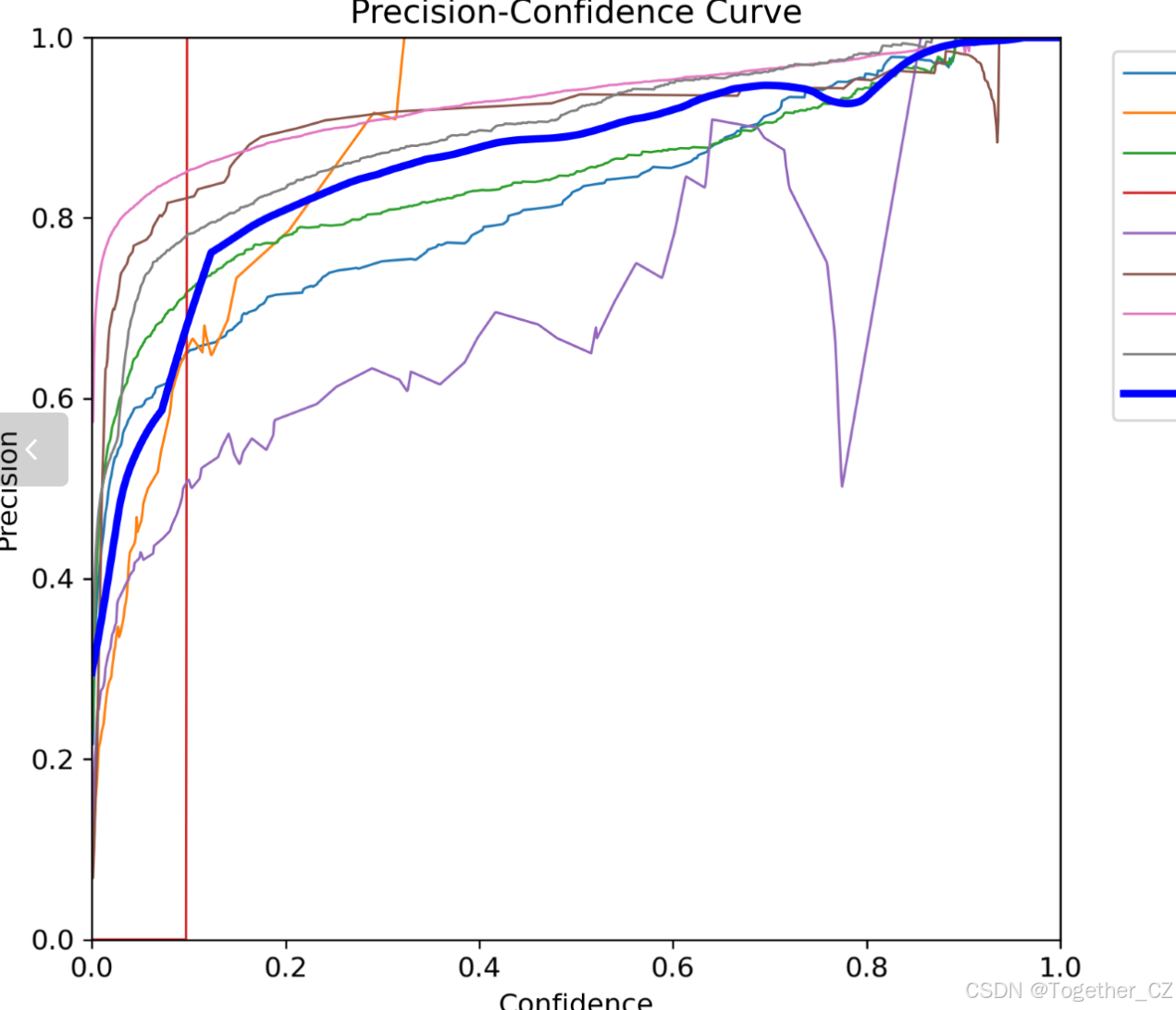
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
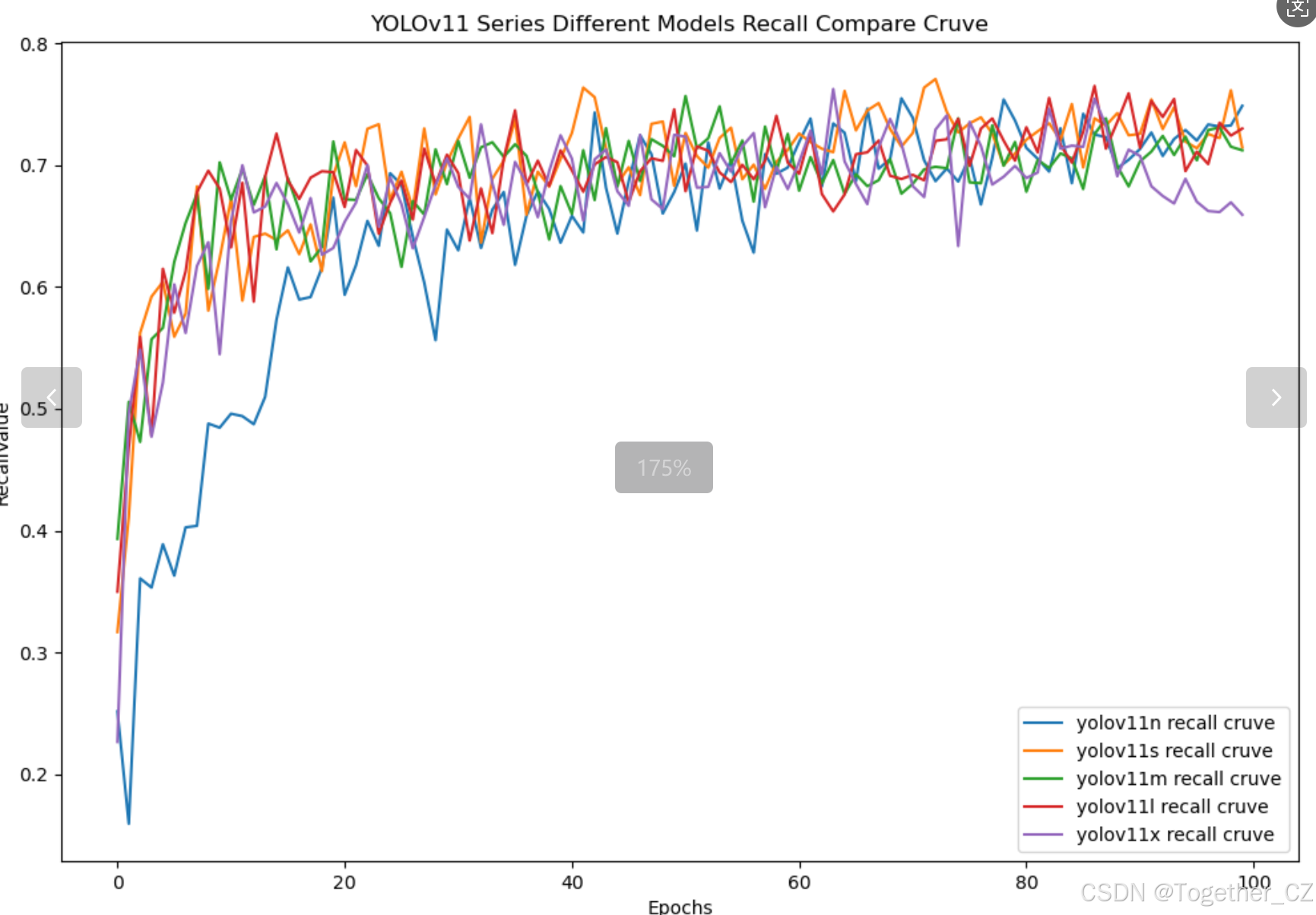
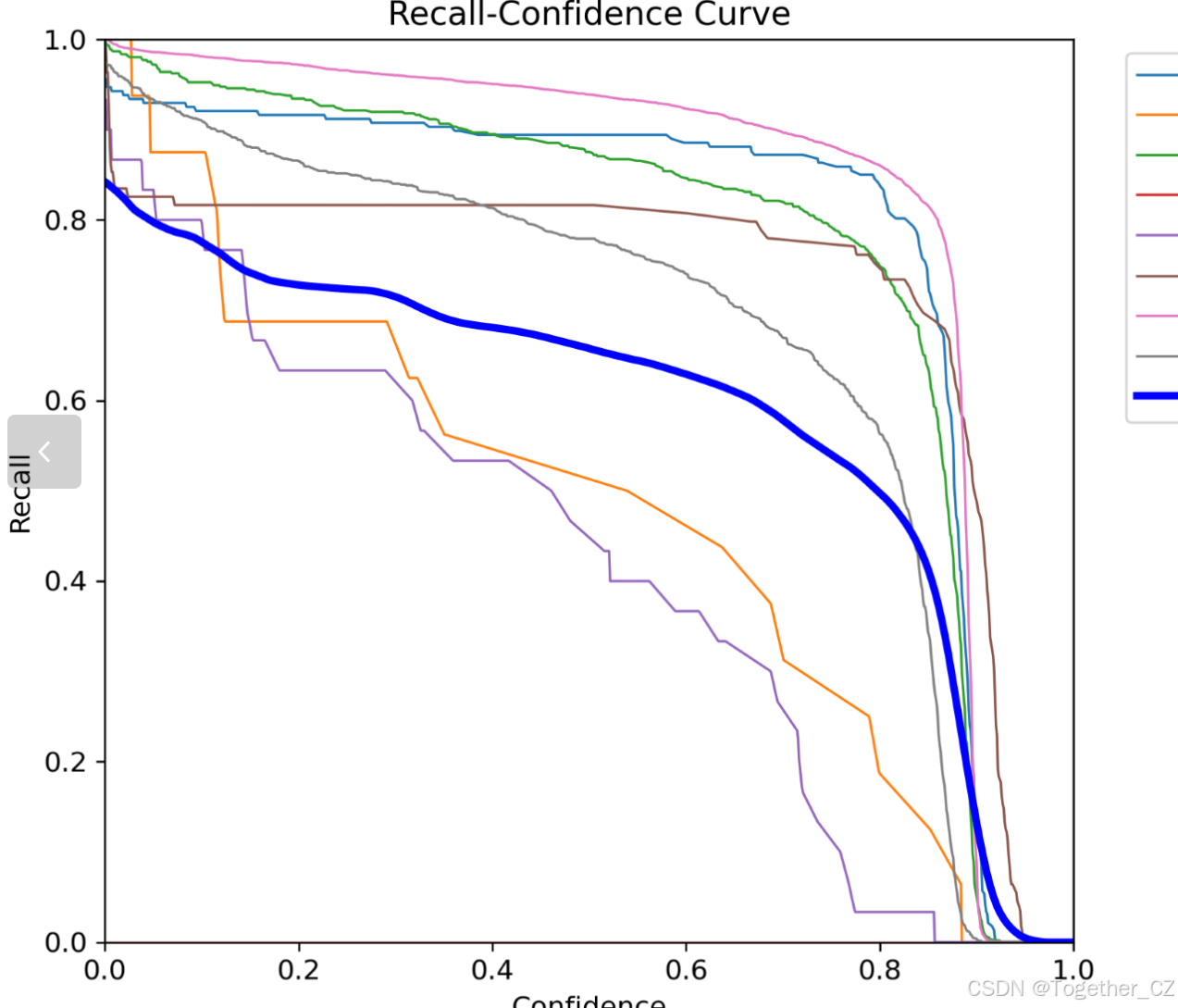
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
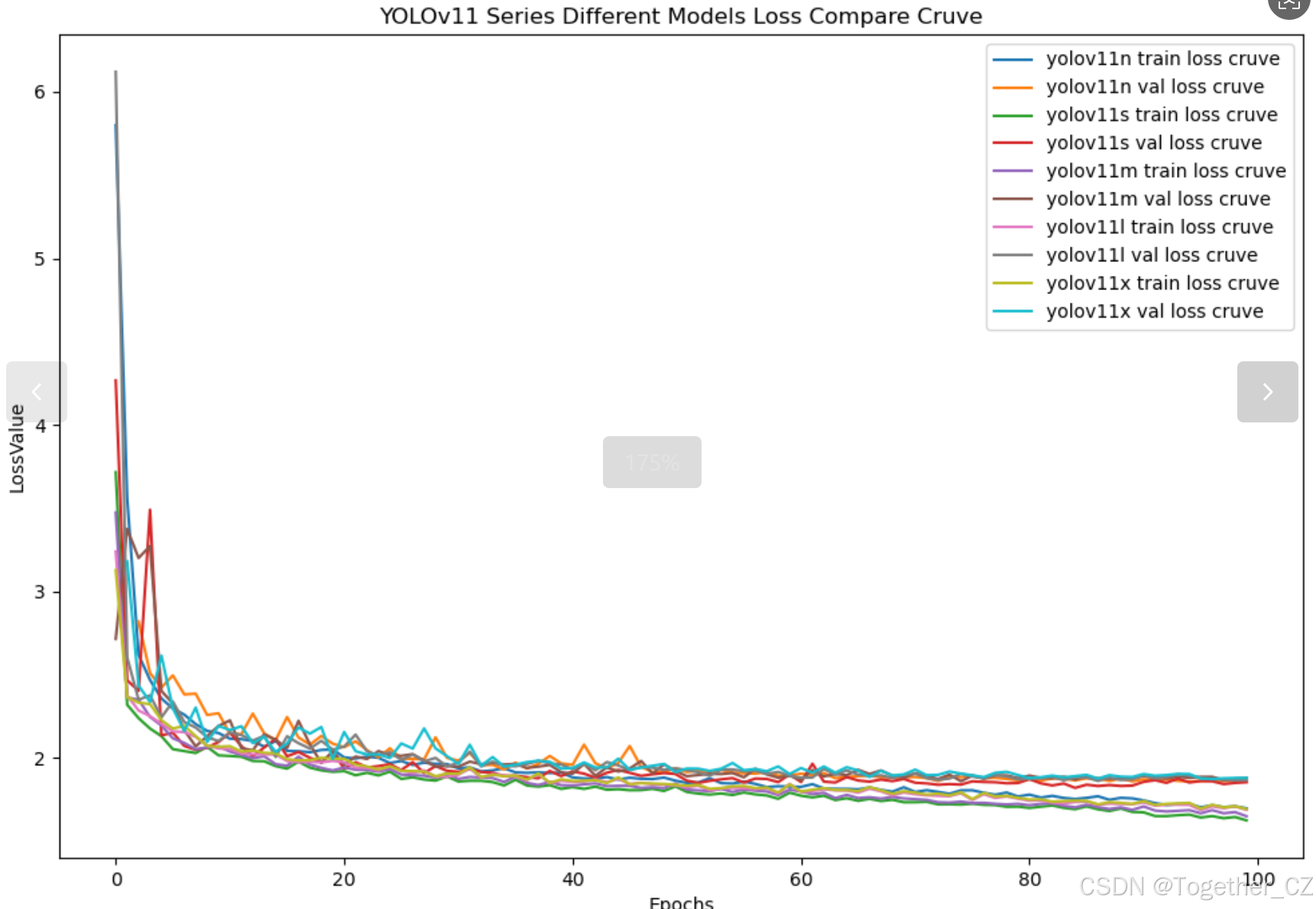
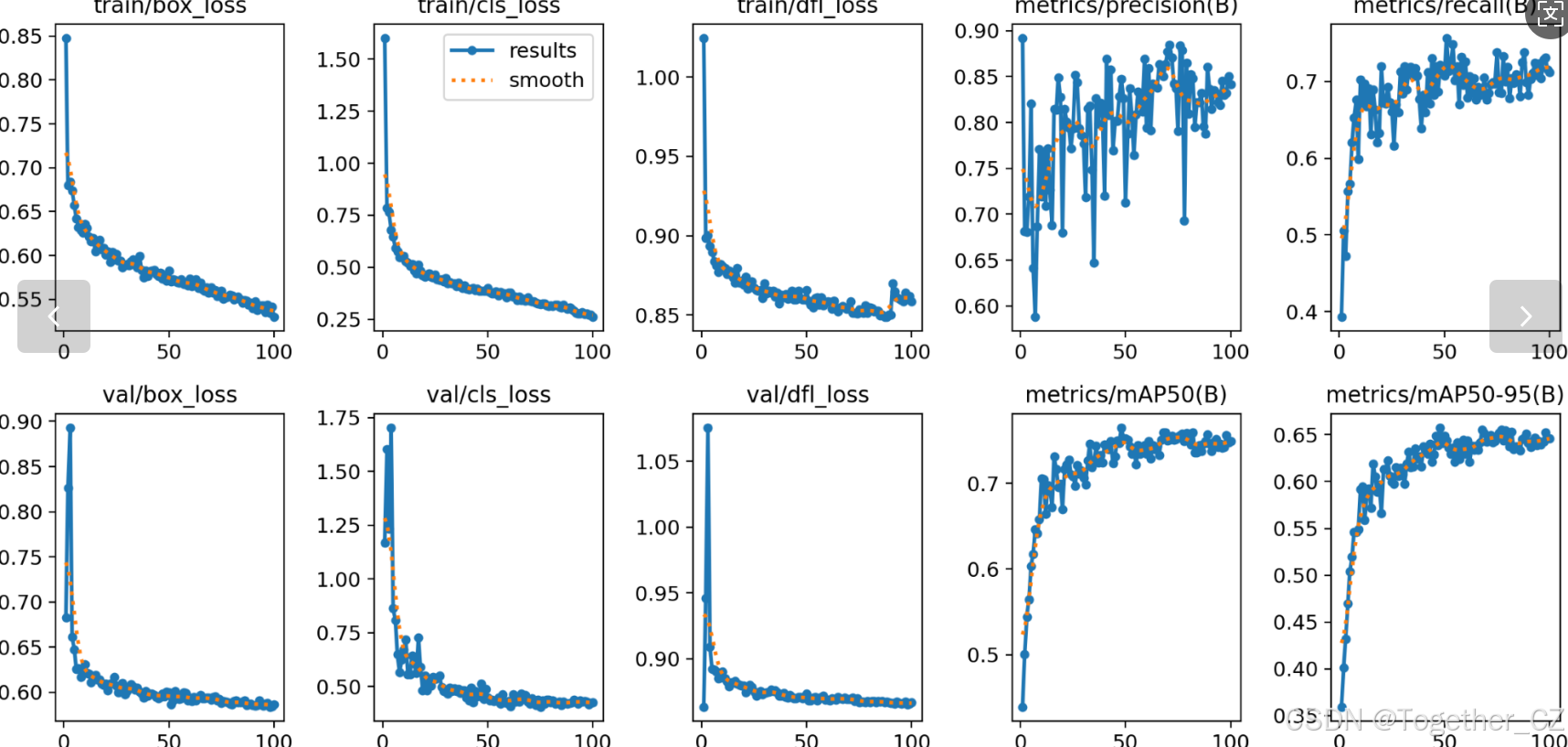
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
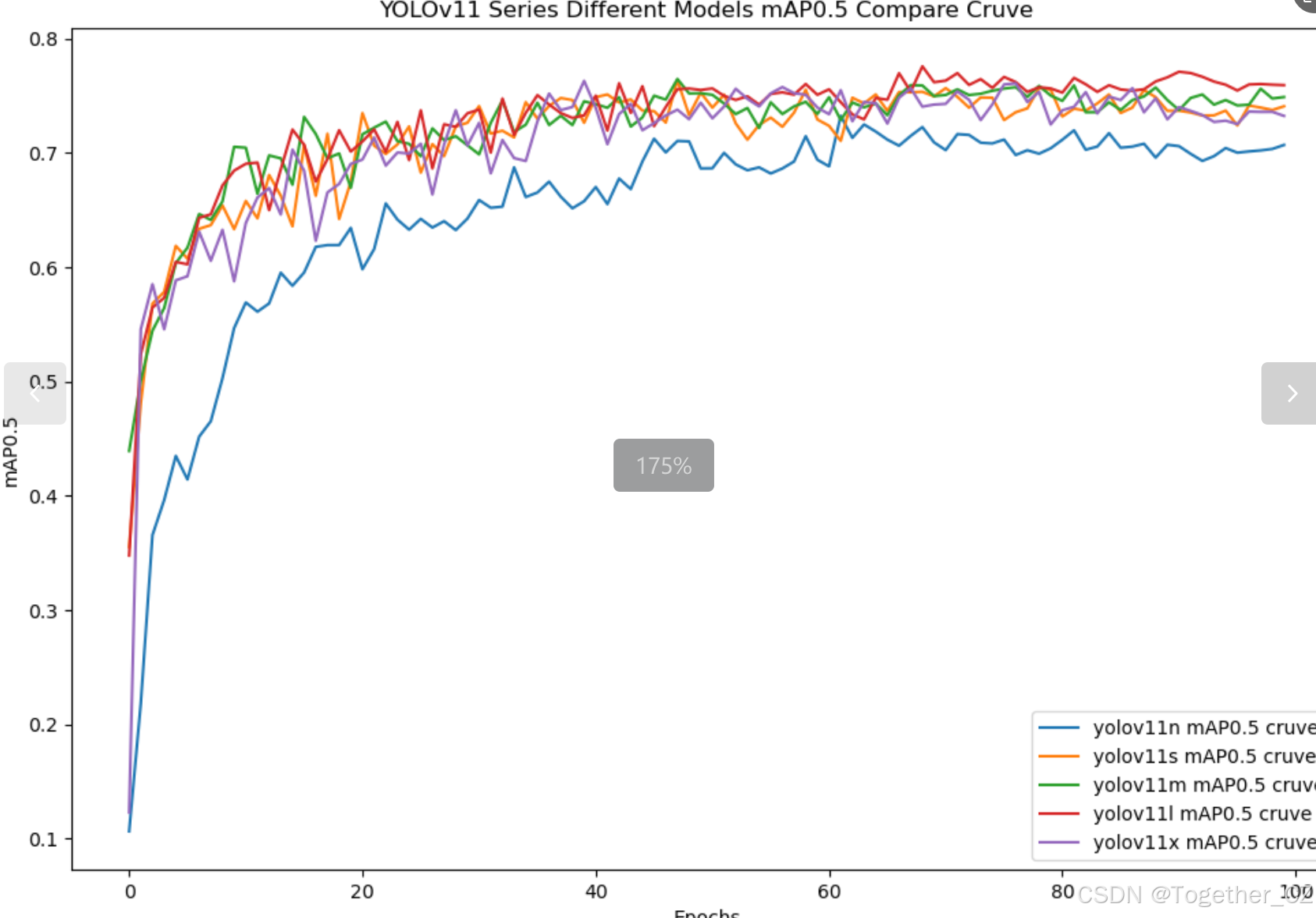
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
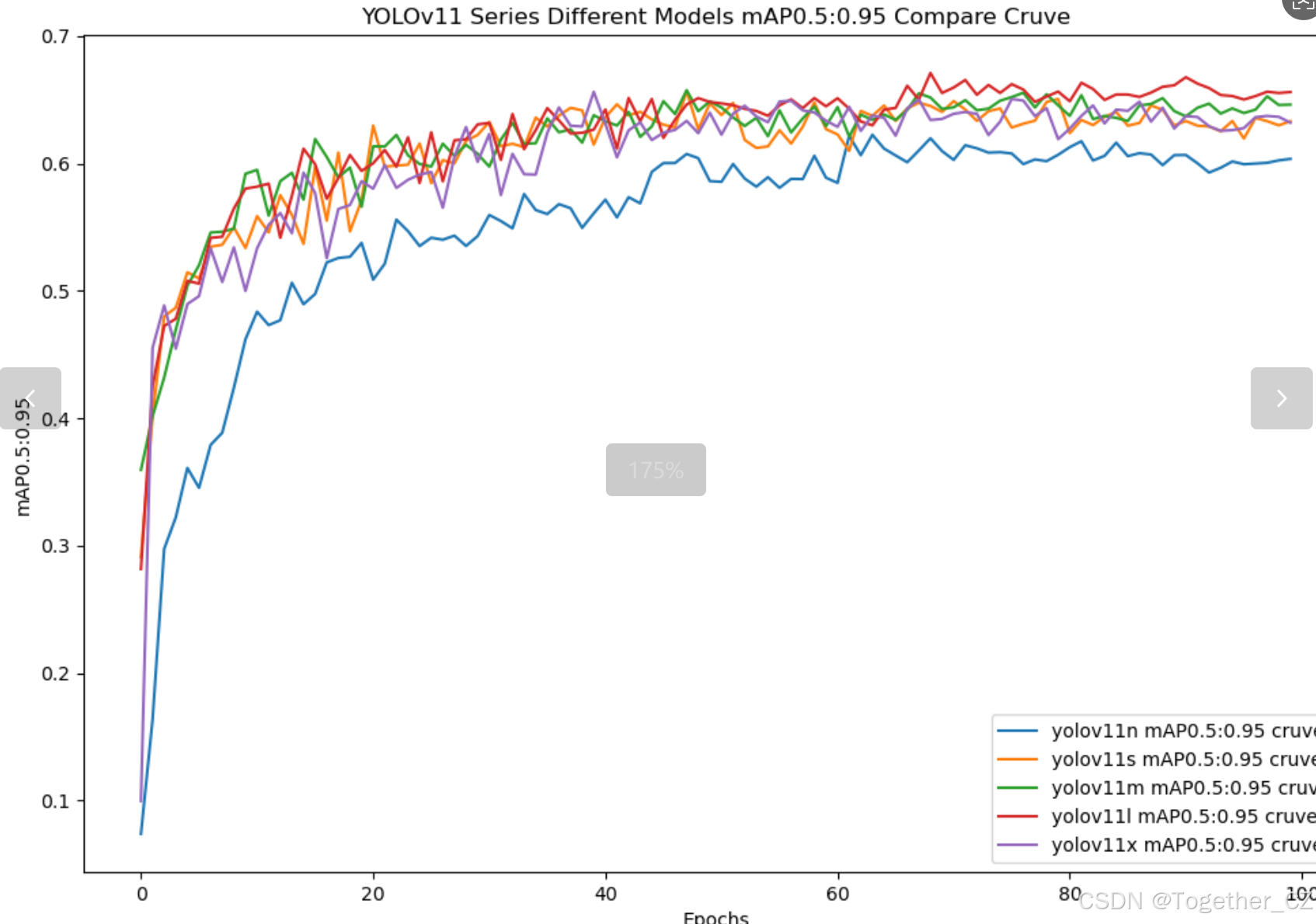
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
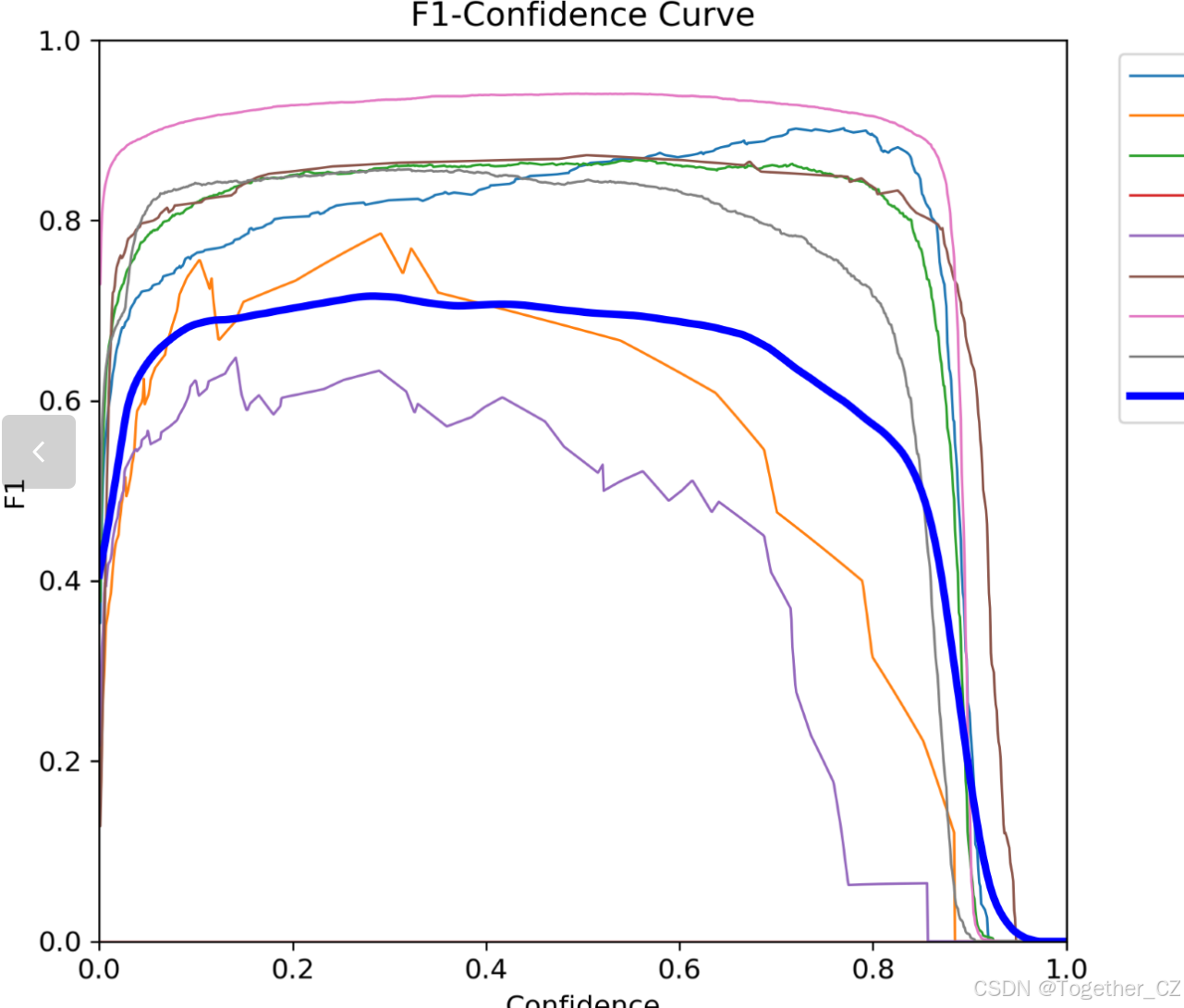
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
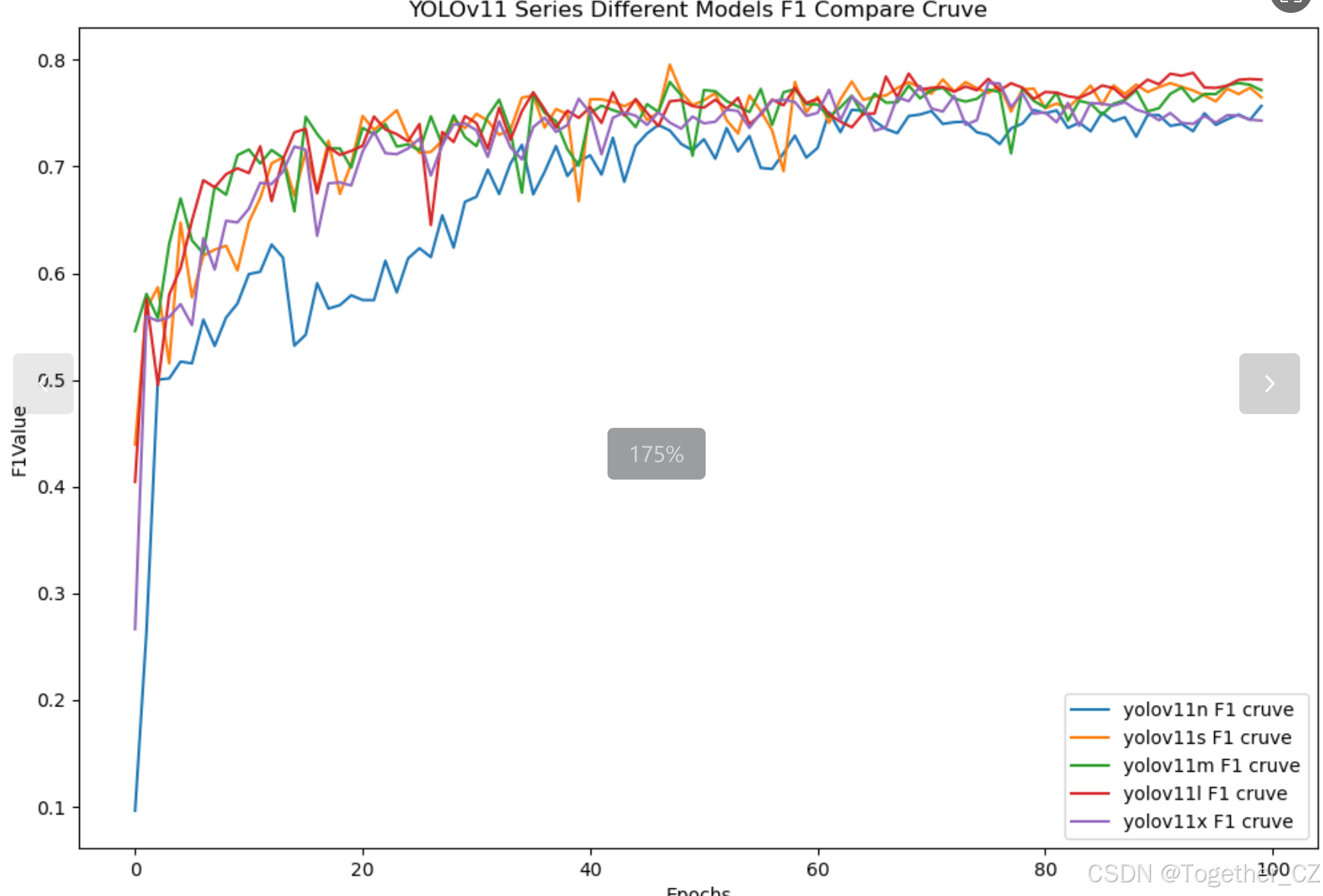
综合五款不同参数量级模型的开发实验对比结果来看:5款模型并没有拉开较为明显的差距,综合对比考虑最终选择使用yolov11s来作为线上推理模型。
接下来看下yolov11s模型的详细情况。
【离线推理实例】

【Batch实例】

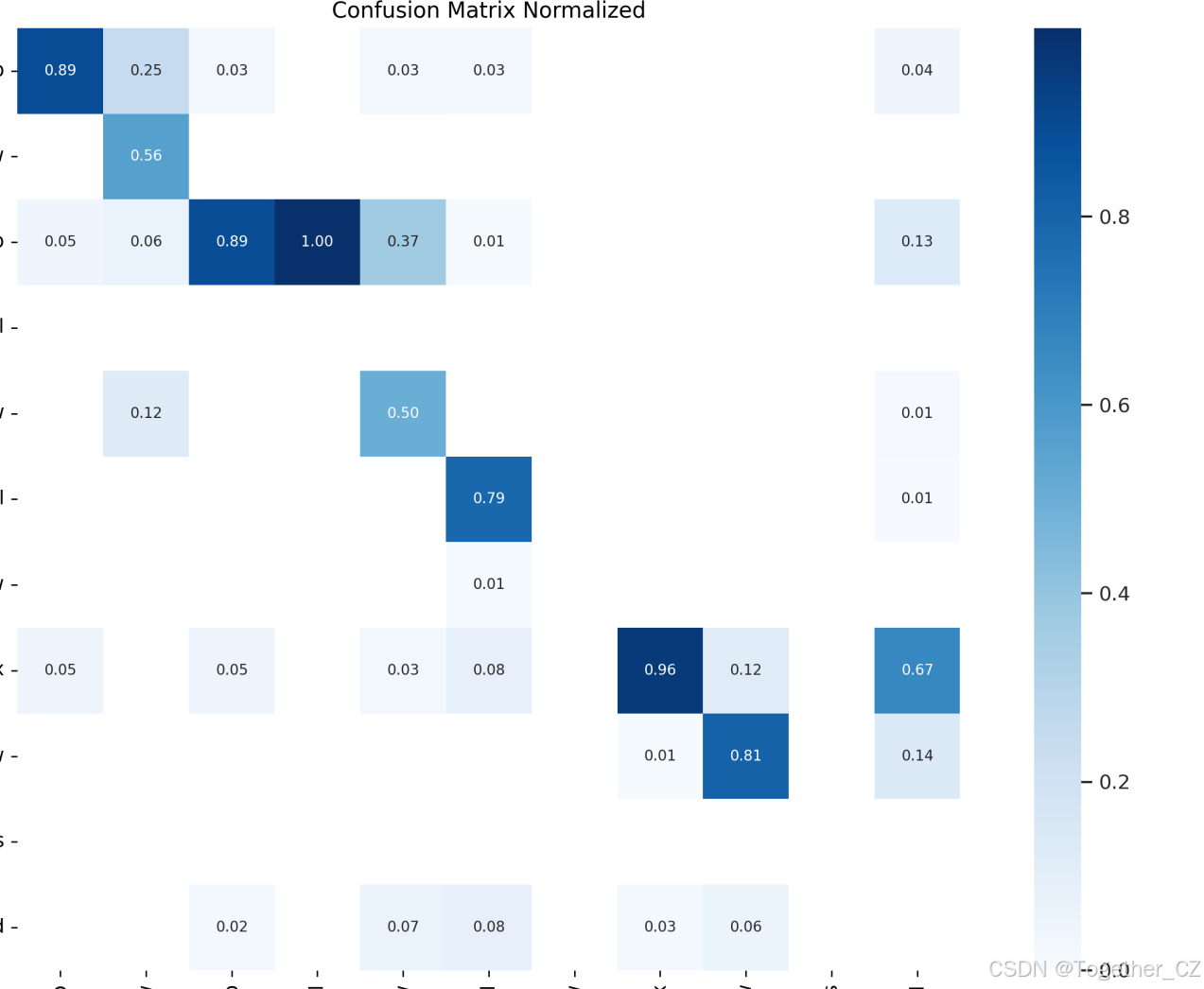
【混淆矩阵】
【F1值曲线】
【Precision曲线】
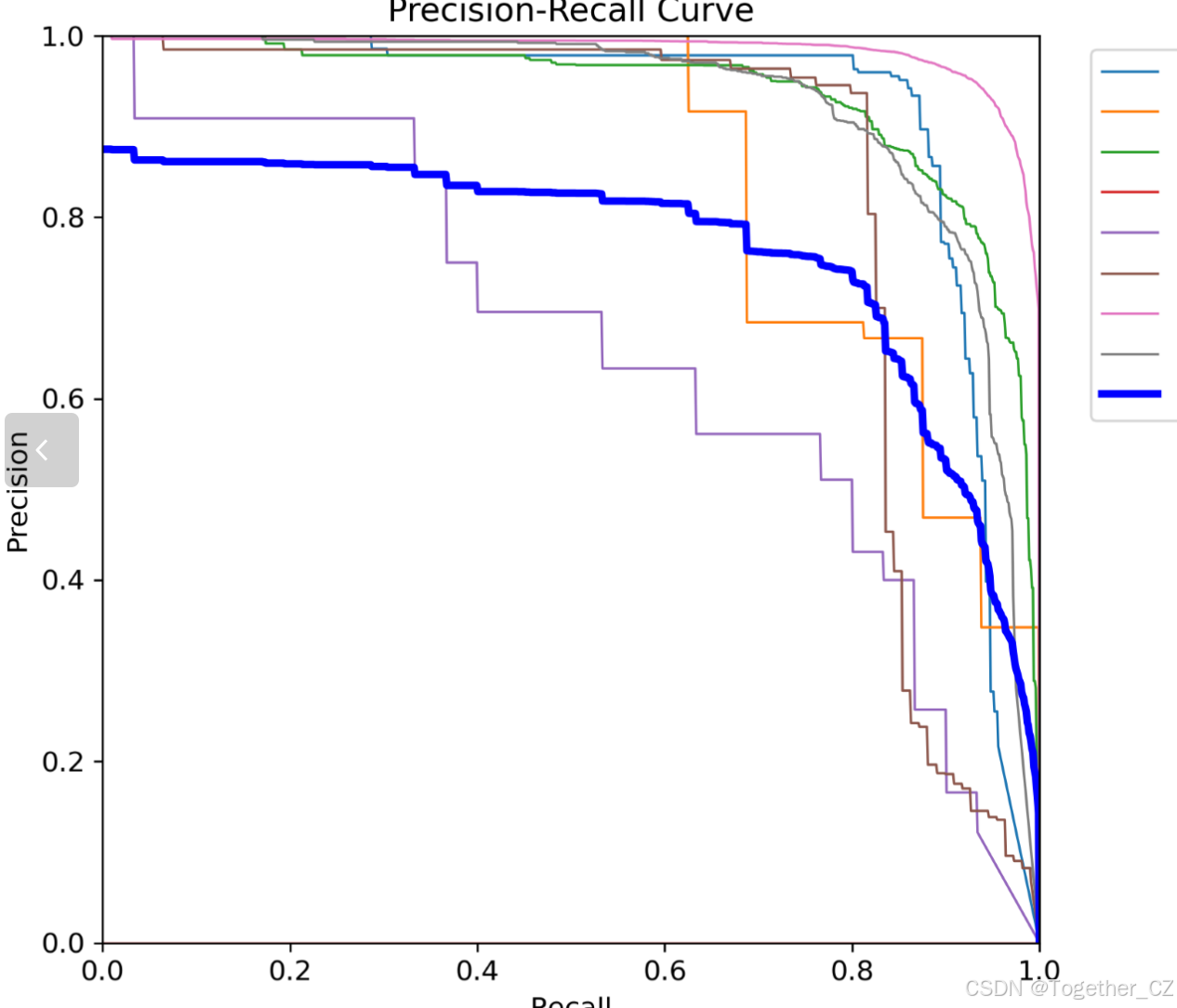
【PR曲线】
【Recall曲线】
【训练可视化】
在AI智能化模型和无人机技术的共同赋能下,光伏板的夜间巡检运维工作有望实现从“不可能”到“可能”的跨越。运维团队可以根据AI模型的预警信息,精准指派专人定点完成维护工作,实现了人力资源的最大化精准化利用。这种智能化的运维模式,不仅提升了运维效率,降低了运维成本,还显著提高了光伏板的运行稳定性和发电效率。AI智能化模型与无人机技术的结合,为光伏板夜间巡检运维带来了革命性的变化。这一创新模式不仅解决了传统巡检方式中存在的诸多难题,还为光伏产业的可持续发展提供了有力支撑。随着技术的不断成熟和应用场景的不断拓展,AI智能化模型和无人机技术将在更多领域展现其独特的价值和潜力,为构建更加高效、绿色、可持续的能源体系贡献力量。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











