






这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
迁移学习对于基础模型适应下游任务非常重要。然而,许多基础模型是专有的,因此用户必须与模型所有者共享数据以微调模型,这既昂贵又引发隐私问题。此外,微调大型基础模型计算密集,对大多数下游用户来说不切实际。本文提出了离站调优(Offsite-Tuning),一种保护隐私且高效的迁移学习框架,可以在不访问完整模型的情况下将数十亿参数的基础模型适应下游数据。在离站调优中,模型所有者向数据所有者发送一个轻量级的适配器和一个有损压缩的模拟器,数据所有者随后在模拟器的帮助下在下游数据上微调适配器。微调后的适配器返回给模型所有者,模型所有者将其插入完整模型中以创建适应后的基础模型。离站调优保护了双方的隐私,并且在计算上比需要访问完整模型权重的现有微调方法更高效。我们在各种大型语言和视觉基础模型上展示了离站调优的有效性。离站调优可以实现与完整模型微调相当的准确性,同时保护隐私并提高效率,实现了6.5倍的加速和5.6倍的内存减少。代码可在此处获取。
关键词: 机器学习, ICML
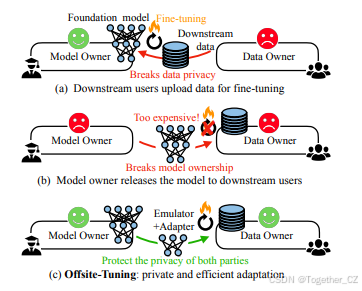
图 1. 比较现有的微调方法(顶部和中部)和 Offsite-Tuning(底部)。
(a) 传统上,用户将标记好的数据发送给模型所有者进行微调,这引发了隐私问题,并且带来了高昂的计算成本。
(b) 模型所有者将完整模型发送给数据所有者是不切实际的,这会威胁到专有模型的所有权,并且由于资源限制,用户无法承担微调庞大基础模型的费用。
(c) Offsite-Tuning 提供了一种隐私保护且高效的替代方案,与传统的微调方法相比,它不需要访问完整的模型权重。
1 引言
大型基础模型在各种任务中表现出色,包括自然语言处理(Devlin et al., 2019; Radford et al., 2019; Brown et al., 2020)、计算机视觉(Radford et al., 2021; Fang et al., 2022)和语音识别(Radford et al., 2022)。通过在大量数据上进行预训练,这些模型可以学习到适用于广泛下游任务的通用表示。尽管一些基础模型能够进行零样本预测或上下文学习(Brown et al., 2020; Fang et al., 2022),迁移学习(即微调)仍然是适应通用基础模型到特定任务的流行且稳健的方法(Wei et al., 2021; Ouyang et al., 2022; Muennighoff et al., 2022; Li and Liang, 2021; Hu et al., 2021)。然而,为下游任务微调基础模型存在两个主要困难(图1)。首先,训练大型基础模型通常需要巨大的计算资源和数据,导致高昂的训练成本(例如,预计训练GPT-3需要超过400万美元)。因此,训练后的权重通常是专有的,不会公开。这意味着下游用户必须与模型所有者共享他们的标注数据以微调模型(例如,OpenAI的微调API),这既昂贵又引发隐私问题,使宝贵的标注数据面临风险。其次,即使下游用户可以访问预训练权重,本地执行微调也相当计算密集且困难。基础模型通常具有大量参数。例如,GPT-3模型(Brown et al., 2020)有1750亿个参数,需要350GB的GPU内存来存储参数并执行推理,更不用说训练了。这种硬件要求使得大多数终端用户无法执行迁移学习。因此,我们需要一种保护隐私且更高效的框架来微调基础模型。
为了解决上述挑战,我们提出了离站调优,一种保护隐私且高效的迁移学习框架,可以在不访问完整模型权重的情况下将基础模型适应下游任务。如图2所示,离站调优涉及模型所有者向数据所有者发送一个适配器和一个模拟器,数据所有者随后在模拟器的帮助下在下游数据上微调适配器。微调后的适配器返回给模型所有者,模型所有者将其插入完整模型中以创建适应后的基础模型供下游用户使用。适配器用于编码任务特定的知识,参数数量较少,而压缩后的模拟器模仿完整模型的其余部分,并为微调适配器提供近似梯度。离站调优保护了数据所有者的隐私,因为他们不需要直接共享训练数据。它还保护了基础模型所有者的财产,因为完整模型权重没有共享,且模拟器经过有损压缩,性能大幅下降。离站调优也比需要访问完整模型权重的现有微调方法更资源高效,因为它通过使用压缩模拟器允许在不访问完整模型的情况下进行微调。
我们在多种语言和视觉基础模型上评估了离站调优的性能,包括GPT-2、OPT、BLOOM、CLIP和EVA。结果表明,离站调优可以在多个下游任务上实现与完整模型微调相当的结果,同时保护隐私并提高资源效率。数据所有者可以通过离站调优更快地适应基础模型,资源消耗更少,与完整微调相比,速度提高了6.6倍,内存减少了5.6倍。此外,离站调优使得在单GPU上微调以前无法实现的模型成为可能,例如OPT-6.7B和BLOOM-7.1B。总体而言,我们认为离站调优是一种实用框架,可以安全高效地将基础模型应用于更广泛的现实世界应用。
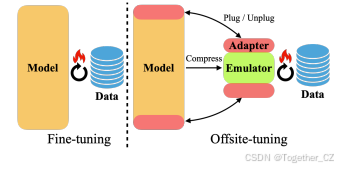
图 2. Offsite-Tuning 概览。
微调(左侧)需要访问完整的模型权重,并且要求模型和数据位于同一位置。在 Offsite-Tuning(右侧)中,模型所有者向数据所有者发送一个适配器(adapter)和一个模拟器(emulator)。数据所有者在下游数据上使用模拟器的辅助对适配器进行微调。微调后的适配器随后被返回并插入到完整模型中,从而创建一个适应后的基础模型。由于双方无需共享完整的模型或数据,并且模拟器是经过压缩的,Offsite-Tuning 既保护了隐私,又提高了效率。
2 相关工作
基础模型(Bommasani et al., 2021),也称为预训练模型,是在用于特定任务之前在大型数据集上训练的大型神经网络。尽管像GPT-3(Brown et al., 2020)、CLIP(Radford et al., 2021)和Painter(Wang et al., 2022)这样的模型可以进行零样本预测或上下文学习,迁移学习仍然是应用模型到新任务的主流方法(Wei et al., 2021; Muennighoff et al., 2022; Liu et al., 2022)。使用基础模型可以节省从头训练模型的时间和资源,但由于其庞大的参数规模,微调和部署它们可能是资源密集型的(Smith et al., 2022; Xiao et al., 2022)。此外,由于许多基础模型是非公开的,用户可能需要与模型所有者共享训练数据以进行微调,这既昂贵又引发隐私问题。
参数高效微调通过仅更新或添加少量参数来适应基础模型到下游任务,而不是更新整个模型。诸如Adapter-tuning(Houlsby et al., 2019)、Prefix-tuning(Li and Liang, 2021)、LoRA(Hu et al., 2021)和BitFit(Ben Zaken et al., 2022)等技术是有用的,因为它们只需要为每个下游任务存储和加载少量参数,而基础模型的大多数参数可以共享。然而,需要注意的是,虽然参数高效微调是有用的,但它需要了解整个模型权重,这可能会损害数据或模型所有者的隐私。此外,微调过程仍然是资源密集型的,因为它至少需要将整个模型的一个副本放置在设备上。
联邦学习(McMahan et al., 2017; Konecny et al., 2016; Kairouz et al., 2021; Augenstein et al., 2020)使用户能够在不与中央服务器共享数据的情况下集体训练或微调模型。相反,每个用户维护整个模型的本地副本,并使用其数据进行更新。更新后的模型随后发送到中央服务器,在那里聚合以创建新的全局模型。然而,需要注意的是,虽然联邦学习可以通过将数据保留在设备上来保护数据隐私,但它不保护模型隐私,因为每个用户都有整个模型的副本。此外,联邦学习假设用户可以在整个模型权重上进行训练,这对于大型基础模型来说几乎是不可能的。
解耦学习将神经网络训练的端到端优化问题分解为较小的子问题。这是通过各种技术实现的,例如使用辅助变量(Askari et al., 2018; Li et al., 2019; Taylor et al., 2016; Zhang & Brand, 2017)、延迟梯度下降(Huo et al., 2018; Xu et al., 2020)和模型组装(Ni et al., 2022)。然而,当前的解耦学习方法主要是为从头训练神经网络而开发的,尚未广泛探索用于微调已经训练好的大型基础模型。
3 问题定义
隐私要求。我们在迁移学习设置中考虑两方的隐私:数据所有者不能与模型所有者共享其标注的训练数据,基础模型所有者不能与数据所有者共享其模型。我们需要找到一种方法,在数据所有者的数据上调整模型,而无需访问完整模型权重。

离站调优的核心概念是下游用户可以在不直接访问完整模型的情况下,在其私有数据上离站微调基础模型。我们通过使用模拟器生成模拟梯度来实现这一点,这些梯度可用于近似更新适配器。因此,我们将我们的方法称为离站调优。
为了证明方法的有效性,我们需要:
-
零样本性能 < 插件性能,表明调优有效地提高了特定下游数据集的性能(否则,调优将没有必要)。
-
模拟器性能 < 插件性能,表明基础模型在任务中仍然具有优势(否则,下游用户将乐于仅使用微调后的模拟器)。
-
插件性能 ≈ 完整微调性能(以便用户不会为了数据隐私而牺牲太多性能)。
4 离站调优

4.1 框架概述

4.2 适配器选择
Transformer架构(Vaswani et al., 2017)已被广泛应用于各种模态的基础模型,如语言和视觉。在本讨论中,我们将重点放在深度Transformer骨干的适配器设计上,这可以轻松扩展到其他模型,如卷积神经网络(CNN)。
我们选择基础模型的一小部分作为适配器,可以在各种下游数据集上进行训练。由于仅更新模型的一部分,适配器必须能够泛化到不同的下游任务。研究表明,从浅层到深层,Transformer的不同层编码了不同层次的特征抽象,选择更新的层会影响迁移学习性能(Lee et al., 2022; Lin et al., 2022)。为了覆盖广泛的任务,我们选择在适配器中同时包含浅层和深层,形成三明治设计,![]() 。我们的实验表明,这种适配器设计在各种下游任务中表现良好,并且优于仅微调最后几层的常见做法(即
。我们的实验表明,这种适配器设计在各种下游任务中表现良好,并且优于仅微调最后几层的常见做法(即![]() ),如图3所示。我们在第5.4.1节中详细讨论了适配器设计。
),如图3所示。我们在第5.4.1节中详细讨论了适配器设计。
4.3 模拟器压缩
使用模拟器的目的是在保持与原始冻结组件![]() 相似的同时,提供粗略的梯度方向来更新适配器。然而,模拟器不能过于精确,否则会泄露原始模型的信息。此外,较小的模拟器尺寸有助于下游用户更高效地进行微调。因此,我们旨在在这三个要求之间找到平衡。
相似的同时,提供粗略的梯度方向来更新适配器。然而,模拟器不能过于精确,否则会泄露原始模型的信息。此外,较小的模拟器尺寸有助于下游用户更高效地进行微调。因此,我们旨在在这三个要求之间找到平衡。
为了实现这一平衡,我们考虑了各种压缩方法,包括剪枝(Han et al., 2016)、量化(Jacob et al., 2018; Xiao et al., 2022)、层丢弃(Sajjad et al., 2023)和知识蒸馏(Hinton et al., 2015; Sanh et al., 2019)。我们的实验表明,基于层丢弃的压缩方法在上述标准之间提供了最佳平衡。具体来说,我们均匀地从冻结组件![]() 中丢弃一部分层,并使用剩余的层作为模拟器
中丢弃一部分层,并使用剩余的层作为模拟器![]() 。我们发现始终将冻结部分的第一层和最后一层包含在模拟器中是有益的(如算法4.1所示)。我们在第5.4.2节中详细比较了不同的压缩方法。
。我们发现始终将冻结部分的第一层和最后一层包含在模拟器中是有益的(如算法4.1所示)。我们在第5.4.2节中详细比较了不同的压缩方法。
此外,为了在保持近似精度的同时实现更高的压缩比,我们在计算资源可用时,对层丢弃的模拟器![]() 进行知识蒸馏,使用原始组件
进行知识蒸馏,使用原始组件![]() 在预训练数据集上进行监督。蒸馏过程使用均方误差(MSE)作为损失函数,如下式所示:
在预训练数据集上进行监督。蒸馏过程使用均方误差(MSE)作为损失函数,如下式所示:

5 实验
5.1 设置
模型和数据集。我们在大型语言模型上评估离站调优,包括GPT-2(Radford et al., 2019)、OPT(Zhang et al., 2022)和BLOOM(Scao et al., 2022),以及视觉模型如CLIP(Radford et al., 2021)和EVA(Fang et al., 2022)。我们在Wikitext语言建模数据集(Merity et al., 2016)和八个问答基准上评估语言模型,包括OpenBookQA(Mihaylov et al., 2018)、PIQA(Bisk et al., 2020)、ARC(Clark et al., 2018)、Hellaswag(Zellers et al., 2019)、SciQ(Johannes Welbl, 2017)、WebQuestions(Berant et al., 2013)和RACE(Lai et al., 2017)。我们在WikiText数据集上报告困惑度,在其他基准上报告准确率。我们在六个细粒度图像分类数据集上评估视觉模型:Flowers(Nilsback & Zisserman, 2008)、Cars(Krause et al., 2013)、Pets(Parkhi et al., 2012)、Food(Bossard et al., 2014)、CIFAR-10(Krizhevsky, 2009)和CIFAR-100(Krizhevsky, 2009)。这些模型的性能以准确率衡量。
实现细节。我们的实验基于Huggingface transformers库。在训练和微调期间,我们使用AdamW(Kingma & Ba, 2015)优化器和余弦学习率调度器。我们在{2e-5, 5e-5, 1e-4, 2e-4, 3e-4}的网格上调整学习率,并报告具有最高模拟器性能的运行。这是因为在现实场景中,用户将返回具有最佳模拟器性能的适配器给模型所有者。我们使用lm-eval-harness进行语言模型评估,并使用NVIDIA A6000 GPU进行所有实验。
5.2 语言模型的结果
中等规模模型。我们首先在参数少于20亿的中等规模语言模型上评估离站调优,包括GPT-2-XL(Radford et al., 2019)和OPT-1.3B(Zhang et al., 2022)。具体来说,GPT-2-XL有48层和16亿参数,OPT-1.3B有24层。在中等规模语言模型(少于20亿参数)上,我们有计算资源来微调完整模型,并使用知识蒸馏来压缩模拟器。我们使用模型的前两层和后两层作为适配器。我们将GPT-2-XL和OPT-1.3B的层数分别减少到16层和8层,作为模拟器蒸馏的初始化。接下来,我们在Pile语料库训练集的前30个块上对模拟器进行单轮蒸馏。结果如表1所示。我们发现离站调优可以有效地适应中等规模语言模型,同时保持较高的性能,因为插件性能与完整模型微调性能相当,而模拟器性能显著较低。
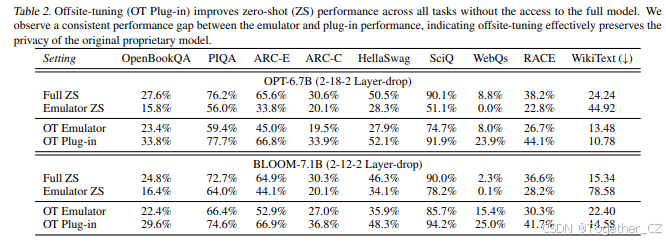
大型模型。然后我们在参数超过60亿的大型语言模型上评估离站调优,包括OPT-6.7B(Zhang et al., 2022)和BLOOM-7.1B(Scao et al., 2022)。由于计算资源有限,我们无法对这些模型进行完整模型微调或模拟器蒸馏(模型所有者应该能够执行蒸馏,其成本与预训练相比只是很小的一部分)。因此,我们将离站调优的性能与零样本性能进行比较,并直接使用层丢弃方法获取模拟器。我们使用模型的前两层和后两层作为适配器。我们将OPT-6.7B和BLOOM-7.1B的中间28层和16层分别丢弃到18层和12层。结果如表2所示。从结果中,我们发现插件性能显著优于零样本性能,而模拟器性能与插件性能之间存在明显差距。这些发现表明,离站调优可以有效地适应大型语言模型,同时保护模型和数据所有者的隐私。
5.3 视觉模型的结果
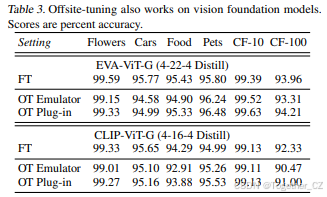
我们进一步在两个最先进的视觉基础模型上评估离站调优:CLIP(Radford et al., 2021)和EVA(Fang et al., 2022)。这两个模型都使用具有10亿参数的ViT-G骨干。我们使用在LAION-2B(Schuhmann et al., 2022)上训练的OpenCLIP(Ilharco et al., 2021)检查点作为CLIP,使用在LAION-400M(Schuhmann et al., 2021)上训练的EVA-CLIP检查点作为EVA。我们使用前四层和后四层以及分类头作为适配器。为了初始化模拟器,我们将CLIP和EVA的层数分别减少到16层和22层。然后我们在ImageNet(Deng et al., 2009)上对模拟器进行单轮蒸馏。如表3所示,我们发现离站调优有效地适应了视觉模型,同时保持了较高的性能。插件性能与完整模型微调性能相当,而模拟器性能略低。这可能是由于在这些数据集上使用大型和小型视觉模型的差异不大,因此模拟器性能并不显著低于插件性能。我们预计离站调优在更具挑战性的视觉任务上会产生更显著的结果。
5.4 消融研究
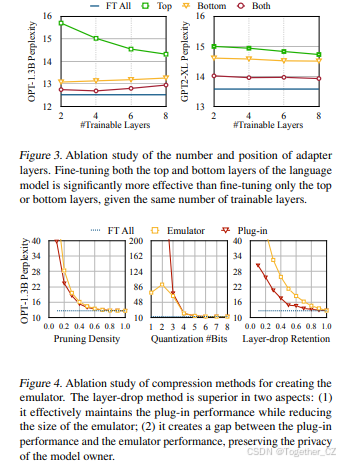
适配器层的位置和数量。在图3中,我们展示了适配器层的位置和数量对微调性能的影响。我们比较了仅微调顶层(靠近输出)、底层(靠近输入)以及均匀微调顶层和底层同时冻结其余层的性能。我们发现,在相同的可训练层预算下,均匀微调顶层和底层显著优于仅微调顶层或底层。此外,当我们增加可训练层数时,部分微调与完整微调之间的性能差距并没有显著缩小。基于这些结果,我们选择在整个实验中使用前两层和后两层作为适配器。
模拟器的压缩方法。除了我们在实验中主要应用的层丢弃和蒸馏方法外,我们还研究了其他压缩技术来创建模拟器,包括基于幅度的剪枝(Han et al., 2016)和量化(Jacob et al., 2018; Xiao et al., 2022)。为了构建模拟器,我们使用前两层和后两层作为适配器,并使用各种压缩方法压缩中间层。我们的结果如图4所示,表明层丢弃方法在插入原始模型时表现最佳。此外,我们观察到在使用层丢弃方法时,插件性能和模拟器性能之间存在明显差距,而在使用其他压缩方法时,这种差距并不显著。这表明基于层丢弃的压缩方法在创建模拟器时可以有效地保护模型的隐私,同时保持较高的插件性能。总体而言,我们的结果表明,基于层丢弃的方法是创建高效且保护隐私的模拟器的有效方法。
模拟器蒸馏的效果。在表4中,我们展示了模拟器蒸馏可以进一步提高插件性能。具体来说,在相同的模拟器层数下,OPT-1.3B模型的插件性能提高了2.47,GPT-2-XL模型的插件性能提高了4.75。尽管有这些改进,我们仍然观察到插件性能和模拟器性能之间存在明显差距,因此完整模型的隐私仍然得到了很好的保护。这表明,如果我们有更多的计算资源来执行额外的蒸馏轮次,模拟器的参数效率还有进一步提高的潜力。
5.5 结合参数高效微调
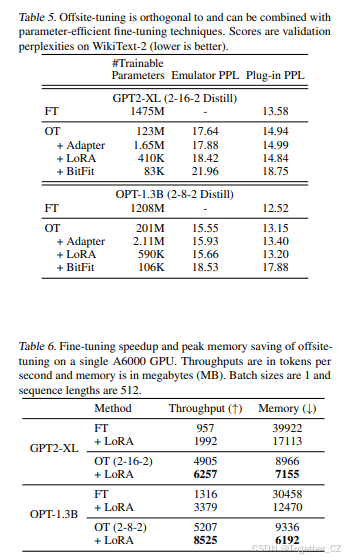
离站调优与现有的参数高效微调方法是正交的,可以无缝结合以进一步减少每个任务的可训练参数数量。为了将离站调优与参数高效微调结合,我们只需要在适配器层上应用该方法。我们使用Adapter-tuning(Houlsby et al., 2019)、LoRA(Hu et al., 2021)和BitFit(Ben Zaken et al., 2022)作为示例来展示这种结合的有效性。我们将适配器大小设置为64用于Adapter-tuning,秩为4用于LoRA。我们在OPT-1.3B和GPT-2-XL模型上在WikiText数据集上进行实验。如表5所示,我们发现Adapter-tuning和LoRA可以显著减少可训练参数数量,同时保持插件性能。然而,我们也观察到BitFit未能适应模型,因为插件性能与完整模型微调性能之间存在显著差距。
5.6 效率
离站调优的关键效率优势在于它不仅减少了可训练参数的数量,还减少了在微调期间需要放置在设备上的总参数数量。这导致微调吞吐量的显著增加和内存占用的减少。为了展示离站调优的有效性,我们进行了实验并在表6中展示了结果。结果表明,当离站调优与LoRA结合时,我们实现了令人印象深刻的6.5倍加速和5.6倍的内存使用减少。这使得离站调优成为在资源受限设备上微调大型基础模型的有吸引力的解决方案。
6 讨论
用例。离站调优是一种在边缘设备上个性化大型语言模型的有效方法,适用于各种应用,如语音助手和聊天机器人。例如,用户可以利用离站调优直接在设备上适应大型语言模型到其个人信息,这更高效且通过消除将数据发送到服务器的需求来保护隐私。适应后的模型随后可用于生成个性化文本,如电子邮件和消息。此外,离站调优可以应用于训练数据极其敏感且无法共享的领域,例如在医院环境中,它可以用于适应大型语言模型到患者记录,而无需与模型所有者共享记录。适应后的模型随后可用于为患者生成个性化医疗报告。在上述两种情况下,该方法还保护了模型所有者的隐私,因为他们不需要与数据所有者共享其完整模型。
推理隐私。在这项工作中,我们专注于解决在适应或微调基础模型过程中的数据隐私和效率问题,而不是解决推理过程中的隐私问题。下游任务的专有训练数据集通常标注良好且包含重要的商业价值,使得隐私成为一个关键考虑因素。然而,推理过程中的隐私问题可以通过其他方法解决,例如(Chou et al., 2018; Li et al., 2022)。
局限性和未来工作。虽然我们的结果表明,使用基础模型的大约三分之一的中间层作为模拟器是可行的,但对于像GPT-3这样的模型来说,它仍然很大。此外,通过计算密集的蒸馏技术压缩模拟器对于更大的模型来说可能是成本高昂的。此外,我们尚未完全证明我们的方法不会无意中导致模型和数据信息泄露。未来的研究应调查从模拟器和适配器重建完整模型和下游数据的可能性。此外,我们方法的理论基础尚不明确,需要进一步研究以提供对模拟器和适配器设计的见解。
7 结论
我们提出了离站调优,一种保护隐私且高效的迁移学习框架,可以在不访问完整模型参数的情况下将基础模型适应下游任务。离站调优在数十亿参数的语言和视觉基础模型上有效。离站调优使用户能够高效地定制基础模型,而无需担心数据隐私和模型隐私。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











