






这篇文章的核心研究内容是关于部分可观测马尔可夫决策过程(POMDPs)的可判定性问题,特别是在具有Omega-正则目标的情况下。文章通过引入“启示机制”(Revelation Mechanism),提出了一类新的POMDPs——弱揭示和强揭示POMDPs,并证明了在这些类别中,某些目标的可判定性问题可以通过分析有限信念支持马尔可夫决策过程(MDP)来解决。以下是文章的主要研究内容和贡献的凝练总结:
1. 研究背景与动机
-
POMDPs是序贯决策中处理不确定性的主要模型之一,但大多数关于POMDPs的决策问题(如是否存在几乎肯定策略)是不可判定的。
-
Omega-正则目标(如Büchi、Co-Büchi和奇偶目标)是POMDPs中常见的目标类别,但即使是简单的Co-Büchi目标,其可判定性问题也是不可判定的。
-
作者引入“启示机制”,通过限制信息损失,使得POMDPs在某些情况下变得可判定。
2. 弱揭示POMDPs
-
定义:弱揭示POMDPs要求智能体几乎肯定地无限频繁地获得当前状态的完整信息。
-
可判定性:对于具有{0, 1, 2}优先级的奇偶目标,弱揭示POMDPs的几乎肯定策略的存在性是可判定的,复杂度为EXPTIME完全。
-
局限性:当优先级扩展到{1, 2, 3}时,问题变得不可判定。
3. 强揭示POMDPs
-
定义:强揭示POMDPs进一步要求每个转移都有一个揭示信号,能够揭示目标状态。
-
可判定性:对于任意奇偶目标,强揭示POMDPs的几乎肯定策略的存在性是可判定的,复杂度为EXPTIME完全。
-
与弱揭示的关系:强揭示POMDPs是弱揭示POMDPs的子类,但强揭示提供了更强的保证。
4. 乐观语义
-
作者提出了“乐观语义”的概念,通过在每个转移中引入小概率的揭示信号,将任何POMDP转换为强揭示POMDP。
-
这种转换不仅保留了原始POMDP的语义,还使得问题变得可判定。
-
乐观语义提供了一种新的视角,用于分析那些原本不可判定的POMDPs。
5. 算法与实验
-
作者提供了一个简单的算法实现,证明了在揭示POMDPs中,基于信念支持的策略是有效的。
-
通过与深度强化学习(DRL)方法的比较,作者展示了精确算法在某些情况下的优势。
6. 相关工作与展望
-
文章讨论了与揭示机制相关的其他研究,如“决定性”属性和“无记忆”策略。
-
作者提出了未来研究的方向,包括更深入地研究POMDPs的结构属性,以及探索更广泛的可判定性问题。
核心贡献
-
揭示机制:通过引入弱揭示和强揭示的概念,为POMDPs的可判定性问题提供了一种新的解决方案。
-
可判定性结果:证明了在弱揭示和强揭示POMDPs中,某些Omega-正则目标的可判定性问题可以通过分析有限信念支持MDP来解决。
-
算法实现:提供了一个基于信念支持的精确算法,并展示了其在揭示POMDPs中的有效性。
-
乐观语义:提出了一种新的语义框架,使得所有POMDPs都可以通过引入揭示信号变得可判定。
文章通过揭示机制,为POMDPs的可判定性问题提供了一种新的视角,并展示了在某些条件下,原本不可判定的问题可以通过限制信息损失变得可判定。这一研究不仅为POMDPs的理论研究提供了新的工具,也为实际应用中的决策问题提供了新的解决方案。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目地址在这里。
摘要
部分可观测马尔可夫决策过程(POMDP)是序贯决策中处理不确定性的主要模型之一。我们感兴趣的是构建具有理论保证的算法,以确定智能体是否有一种策略,能够以概率1确保给定的规范。这一问题在已知的非常简单的Omega-正则目标下已经被证明是不可判定的,因为难以对不确定事件进行推理。我们引入了一种“启示机制”,通过限制信息损失来解决这一问题,要求智能体几乎肯定地最终获得当前状态的完整信息。我们的主要技术成果是为两类POMDP(称为弱揭示和强揭示)构建了精确算法。重要的是,可判定的情况可以简化为对有限信念支持马尔可夫决策过程的分析。这为一大类POMDP提供了一个概念上简单且精确的算法。
1. 引言
部分可观测马尔可夫决策过程(POMDP)是序贯决策中处理不确定性的主要模型之一。它们在20世纪60年代被定义(Åström 1965),并由Kaelbling、Littman和Cassandra(1998)的经典论文引入人工智能领域。我们从模型的角度考虑POMDP,这在规划和形式化方法中很常见。我们的目标是构建精确的(而非近似的)算法,这些算法以POMDP的完整描述为输入,并构建一种确保给定规范的策略。大量研究已经表明,这类问题的大多数表述是不可判定的。例如,即使在智能体没有任何信息,目标是以任意高的概率到达目标状态的极端情况下,也会出现复杂的收敛现象,从而导致强烈的不可判定性结果(Madani、Hanks和Condon 2003;Gimbert和Oualhadj 2010;Fijalkow 2017)。在本工作中,我们感兴趣的是构建几乎肯定的策略,即以概率1确保其规范的策略。我们考虑的Omega-正则目标类别(所有可表示为奇偶目标的形式)是一个强大的类别,包括可以用线性时态逻辑(Pnueli 1977;Giacomo和Vardi 2013)表达的属性。确定是否存在针对Co-Büchi目标子类(要求从某一点开始避免目标)的几乎肯定策略是不可判定的(Chatterjee、Chmelik和Tracol 2016;Bertrand、Genest和Gimbert 2017)。在实际应用中,有大量的工作致力于近似和实用的解决方案,例如使用信念空间中的插值(Lovejoy 1991)、值函数的近似(Hauskrecht 2000),或蒙特卡洛树搜索方法(Silver和Veness 2010)。这与本文的研究方向是正交的,因为我们专注于精确算法。我们的起点是从POMDP构建一个马尔可夫决策过程(MDP),其状态是POMDP信念的支持。换句话说,我们存储关于我们可以处于哪些状态的信息,但忽略概率。信念支持MDP作为POMDP的有限抽象;人们可能会期望,如果POMDP中存在几乎肯定的策略,那么在相应的信念支持MDP中也存在这样的策略。不幸的是,这种抽象既不健全也不完整;我们在图1中给出了一个简单的反例。我们在本文中提出的基本问题是,是否存在自然的充分条件,使信念支持抽象变得正确。从概念上讲,这种抽象的失败是由于信息损失及其随时间积累。我们引入了一种启示机制,通过限制信息损失来解决这一问题,要求几乎肯定地不允许信息损失无限制地积累,从而消除了导致不可判定性的收敛问题。实际上,我们推测启示是一种在部分可观测性中常见的现象;一个典型的例子是具有小概率无限频繁重置的系统,且这种重置是可观察的。我们将留待未来工作进一步研究这一问题。其他限制信息损失的方法已被提出;我们将在相关工作部分(第6节)中进一步讨论。
我们的贡献包括:
-
我们研究了基于启示机制的POMDP的两个属性,称为弱揭示和强揭示。
-
我们为这两类POMDP获得了可判定性(和不可判定性)结果。重要的是,可判定的情况可以简化为对有限信念支持MDP的分析。我们在图2中为POMDP提供了贡献的总结。我们还简要考虑了部分信息的两人博弈类别,以表明我们的揭示机制不足以使这一更大类别的问题变得可判定。
-
我们提供了一个简单的算法实现,作为概念验证。我们还比较了我们的算法与通过观察包装器训练的现成深度强化学习(DRL)。正如我们在本文中将展示的那样,由信念支持诱导的MDP携带了足够的信息来在揭示POMDP中进行游戏;因此,我们使用了一个包装器,该包装器在飞行中实现子集构造,以生成当前信念支持,并专注于适用于MDP的算法。在对奖励工程和超参数调整进行适度努力后,我们未能使用这种DRL方法匹配我们算法的性能(见图3)。这为一大类POMDP提供了一个概念上简单且精确的算法。我们结果的重要性可以通过以下观点来衡量:与其说启示机制是POMDP的一个子类,不如说它是所有POMDP的新语义。从这个意义上说,我们为POMDP的乐观语义获得了可判定性结果,据我们所知,这在以前是没有做过的。我们将在第5.3节中更详细地讨论这一点。
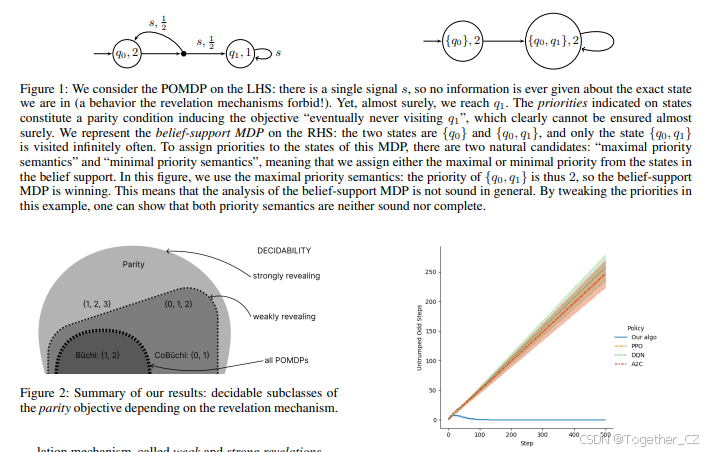
图1: 我们考虑左侧的POMDP:只有一个信号s,因此从未提供关于我们当前处于哪个确切状态的信息(这是启示机制所禁止的行为!)。然而,几乎肯定地,我们会到达q1。状态上的优先级构成了一个奇偶条件,诱导目标“最终永远不访问q1”,这显然无法几乎肯定地实现。我们在右侧表示了信念支持MDP:两个状态是{q0}和{q0, q1},并且只有状态{q0, q1}被无限频繁地访问。为了给这个MDP的状态分配优先级,有两种自然的候选方式:“最大优先级语义”和“最小优先级语义”,意味着我们将信念支持中的状态的最大或最小优先级分配给它。在这个图中,我们使用了最大优先级语义:因此{q0, q1}的优先级是2,所以信念支持MDP是获胜的。这意味着信念支持MDP的分析通常不是健全的。通过调整这个例子中的优先级,可以证明这两种优先级语义既不健全也不完整。
图2: 我们的结果总结:根据启示机制,依赖于奇偶目标的可判定子类。
启示机制。 我们引入的启示机制是一种限制POMDP中信息损失的方法。具体来说,它要求智能体几乎肯定地最终获得当前状态的完整信息。这种机制的核心思想是禁止信息损失无限制地积累,从而避免了导致不可判定性的复杂收敛问题。我们推测,启示机制在实际应用中是一种常见的现象,例如在具有小概率无限频繁重置的系统中,这种重置是可观察的。这种机制不仅为POMDP的子类提供了可判定性,还可以被视为一种新的语义,为所有POMDP提供了一种乐观的语义。
弱揭示和强揭示。 我们定义了两种基于启示机制的POMDP属性:弱揭示和强揭示。弱揭示要求智能体在几乎肯定的情况下,无限频繁地获得当前状态的完整信息;而强揭示则进一步要求,对于任何可能的转移,都存在一种信号能够揭示目标状态。这两种属性都限制了信息损失,但强揭示提供了更强的保证。
可判定性结果。 我们证明了对于弱揭示和强揭示的POMDP,存在几乎肯定策略的问题是可判定的。具体来说,对于弱揭示POMDP,当优先级限制在{0, 1, 2}时,问题可以在EXPTIME复杂度内解决;而对于强揭示POMDP,任何奇偶目标的可判定性也是EXPTIME完全的。这些结果表明,通过引入启示机制,可以在一定程度上克服POMDP的不可判定性。
与深度强化学习的比较。 我们还比较了我们的算法与基于深度强化学习(DRL)的方法。尽管DRL在许多领域表现出色,但在处理揭示POMDP时,我们发现DRL方法难以匹配我们的算法性能。这表明在某些情况下,精确的算法可能比基于学习的方法更为有效。
乐观语义。 我们提出,启示机制不仅可以应用于POMDP的子类,还可以扩展到所有POMDP的乐观语义。具体来说,通过在每个转移中引入小概率的“揭示”信号,可以将任何POMDP转换为强揭示POMDP。这种转换不仅保留了原始POMDP的语义,还使得问题变得可判定。我们称这种语义为“乐观语义”,因为它在一定程度上放宽了对策略的要求。
2 预备知识
一个有限集合X上的离散概率分布是一个函数d: X → [0, 1],满足∑<sub>x∈X</sub> d(x) = 1。所有X上的概率分布的集合记作D(X)。概率分布d的支撑supp(d)是集合{x ∈ X | d(x) > 0}。我们用|X|表示集合X中的元素数量。
2.1 POMDPs
部分可观测马尔可夫决策过程(POMDP)是一个五元组P = (Q, Act, Sig, δ, q₀),其中Q是有限状态集,Act是有限动作集,Sig是有限信号集,δ: Q×Act → D(Sig×Q)是转移函数,q₀ ∈ Q是初始状态。POMDP P = (Q, Act, Sig, δ, q₀)的一个游戏是一个无限序列π = q₀a₁s₁q₁a₂s₂... ∈ (Q·Act·Sig)ω,满足对所有i ≥ 0,有δ(qᵢ, aᵢ₊₁)(sᵢ₊₁, qᵢ₊₁) > 0。POMDP的一个历史h是游戏的一个有限前缀,以状态结尾(它是(Act·Sig)∗·Q的一个元素)。如果h = q₀a₁s₁q₁...aₙsₙqₙ,我们用last(h)表示qₙ。在实践中,状态是不可完全观测的;我们定义一个可观察历史为历史在(Act·Sig)∗上的投影。我们用obs(h)表示从历史h导出的可观察历史,即去掉状态后的相同序列。对于POMDP P = (Q, Act, Sig, δ, q₀)的状态q,我们定义Pq为POMDP (Q, Act, Sig, δ, q),仅将初始状态改为q。我们用βₚ = min{δ(q, a)(s, q′) | q, q′ ∈ Q, a ∈ Act, s ∈ Sig, 且 δ(q, a)(s, q′) > 0}表示P中出现的最小非零概率。
一个马尔可夫决策过程(MDP)是一个四元组M = (Q, Act, δ, q₀),其中δ: Q × Act → D(Q)。形式上,一个MDP M = (Q, Act, δ, q₀)可以看作是一个POMDP P = (Q, Act, Sig, δ, q₀),满足Sig = {sq | q ∈ Q},并且对所有q, q′, q′′ ∈ Q和a ∈ Act,有δ(q, a)(sq′′, q′) > 0当且仅当q′ = q′′。在实践中,这意味着最后一个信号总是唯一确定当前状态。MDP具有“完全观测”,而POMDP具有“部分观测”。对于一个POMDP P = (Q, Act, Sig, δ, q₀),我们定义P的底层MDP为MDP (Q, Act, δ′, q₀),其中δ′(q, a)(q′) = ∑<sub>s∈Sig</sub> δ(q, a)(s, q′)。
备注1. POMDP中的可观测信息是通过转移过程中出现的信号提供的。这与基于状态的观测形成对比,后者将状态空间划分为不同的部分,也是常用于建模POMDP的方式。这两种模型在多项式时间内是等价的:一个具有观测的POMDP可以转换为一个在相同状态空间上具有信号的等价POMDP,而反向转换则需要将状态空间增加一个与|Sig|成线性的大小。两种选择都很方便,但使用信号使强揭示(定义2)的定义更加自然,这也是我们选择这种表示方式的原因。
策略。 设P = (Q, Act, Sig, δ, q₀)是一个POMDP。POMDP中的一个(基于观测的)策略是一个基于当前可观察历史进行决策的函数,即它是函数σ: (Act·Sig)∗ → D(Act)。我们也可以类似地定义MDP中的策略(即假设Sig提供了当前状态的信息),但为了方便起见,我们假设MDP中的策略是一个函数σ: (Act·Q)∗ → D(Act)。一个可观察历史a₁s₁...aₙsₙ与策略σ一致,如果对所有1 ≤ i < n,有σ(a₁s₁...aᵢsᵢ)(aᵢ₊₁) > 0。如果策略σ是纯策略(pure),即对所有可观察历史h ∈ (Act·Sig)∗,σ(h)是一个狄拉克分布(Dirac distribution),换句话说,如果σ是一个函数(Act·Sig)∗ → Act,那么σ就是纯策略。我们用Σ(P)表示POMDP P中的策略集合,用ΣP(P)表示P中的纯策略集合。对于一个MDP M,如果一个策略的决策仅基于当前状态,即如果对所有历史h₁, h₂,满足last(h₁) = last(h₂),则有σ(h₁) = σ(h₂),那么这个策略σ就是无记忆的(memoryless)。我们仅在MDP中定义无记忆的概念。
由策略诱导的概率测度。 设P = (Q, Act, Sig, δ, q₀)是一个POMDP。对于P的一个历史h,我们定义Cyl(h)(h的柱集)为所有以h开始的游戏的集合,即h(Act·Sig·Q)ω。给定一个策略σ,我们可以定义一个在无限游戏上定义的概率测度PPσ[·]。这个函数自然地通过归纳定义在柱集上。我们定义PPσ[Cyl(q₀)] = 1,且对q ∈ Q,q ≠ q₀,有PPσ[Cyl(q)] = 0。对于一个历史h = h′asq,我们定义PPσ[Cyl(h)] = PPσ[Cyl(h′)]·σ(obs(h′))(a)·δ(last(h′), a)(s, q)。根据Ionescu-Tulcea扩展定理(Klenke 2007),这个函数可以唯一地扩展为一个在所有柱集的Borel集上诱导的概率分布PPσ[·]。我们还使用这个概率分布来衡量Qω中的无限序列集合,通过将集合W ⊆ Qω与集合∑<sub>q₀q₁...∈W</sub> q₀ActSigq₁ActSigq₂... ⊆ (Q×Act×Sig)ω关联起来。同样,我们使用这个概率分布来衡量仅基于信号的事件,通过将集合S ⊆ Sigω与集合∑<sub>s₁s₂...∈S</sub> QActs₁QActs₂Q... ⊆ (Q×Act×Sig)ω关联起来。
目标。 设P = (Q, Act, Sig, δ, q₀)是一个POMDP。目标W ⊆ Qω是无限状态序列的一个可测集合。注意,观察一个无限信号序列(而不是状态)可能并不总是足以确定一个游戏是否满足目标。给定一个集合F ⊆ Q,可达目标Reach(F) = {q₀q₁... ∈ Qω | ∃i ≥ 0, qᵢ ∈ F}是访问F中至少一个状态的游戏集合。对于k ∈ N,我们写作Reach≤k(F) = {q₀q₁... ∈ Qω | ∃i, 0 ≤ i ≤ k, qᵢ ∈ F},表示在最多k步内到达F的游戏集合。给定一个集合F ⊆ Q,安全目标Safety(F)是从未访问F中任何状态的游戏集合。给定一个优先级函数p: Q → {0, ..., d}(其中d ∈ N),奇偶目标Parity(p) = {q₀q₁... ∈ Qω | lim supᵢ≥₀ p(qᵢ)是偶数}是无限游戏中最高优先级无限频繁出现的值为偶数的游戏集合。一个Büchi目标是一个奇偶目标Parity(p),其中p: Q → {1, 2},而一个Co-Büchi目标是一个奇偶目标Parity(p),其中p: Q → {0, 1}。对于Q′ ⊆ Q,我们写作Büchi(Q′)表示无限频繁访问Q′的游戏集合;它等于Parity(p),其中优先级函数p满足p(q) = 2如果q ∈ Q′,否则p(q) = 1。我们写作Co-Büchi(Q′)表示有限频繁访问Q′的游戏集合;它等于Parity(p),其中优先级函数p满足p(q) = 1如果q ∈ Q′,否则p(q) = 0。对于一个目标W,如果PPσ[W] = 1,则策略σ是几乎肯定的(almost sure);如果PPσ[W] > 0,则策略σ是正赢得的(positively winning)。如果supσ∈Σ(P) PPσ[W] = 1,则我们说目标W在POMDP P中的值为1。
2.2 信念和信念支持
设P = (Q, Act, Sig, δ, q₀)是一个POMDP。一个信念b ∈ D(Q)是Q上的一个概率分布。一个信念支持b ∈ 2Q\∅(即非空的Q的子集)是信念的支撑。为了简洁,我们写作2Q∅表示2Q{∅}。在每一步中,信念和信念支持可以通过执行一个动作并观察一个信号来更新。我们展示如何对信念支持进行更新:我们定义一个函数B: 2Q∅ × Act × Sig → 2Q∅,用于更新信念支持。对于b ∈ 2Q∅,a ∈ Act,s ∈ Sig,我们定义B(b, a, s) = {q′ ∈ Q | ∃q ∈ b, δ(q, a)(s, q′) > 0}。我们以自然的方式将这个函数扩展为一个函数B∗: 2Q∅ × (Act·Sig)∗ → 2Q∅。目标Reach(B)和Büchi(B)可以自然地扩展到信念支持集合B ⊆ 2Q∅(见附录C)。信念比信念支持包含更多信息,因为它们包含了处于特定状态的确切概率,而信念支持仅包含可能的当前状态的定性信息。注意,当信念支持是一个单例(即b = {q},对于某个q ∈ Q),知道精确的信念并不会比知道信念支持提供更多信息,因为所有概率质量都集中在其中一个状态上。我们将在后面定义的“揭示”限制将利用这一事实。
3 信念支持MDP
对于一个POMDP P = (Q, Act, Sig, δ, q₀),P的信念支持MDP是MDP PB = (2Q∅, Act, δB, {q₀}),其中对于b, b′ ∈ 2Q∅和a ∈ Act,如果存在s ∈ Sig使得B(b, a, s) = b′,则δB(b, a)(b′) > 0。我们假设在具有正概率的后继之间均匀分布。我们可以证明,对于许多简单目标,POMDP及其信念支持MDP的行为是相似的。例如,可以用正概率到达的信念支持集合在POMDP及其信念支持MDP中是相同的(附录C,引理1);如果一个信念支持集合在POMDP中几乎肯定可以到达,那么在信念支持MDP中也是如此(附录C,引理2)。在信念支持MDP中有一个自然的方法将策略提升到POMDP中的策略。我们定义一个符号,用于从信号序列到诱导的信念支持序列的转换。设h = a₁s₁...aₙsₙ ∈ (Act·Sig)∗是P中一个可能的可观察历史。对于1 ≤ i ≤ n,设bᵢ = B∗({q₀}, a₁s₁...aᵢsᵢ)是经过i步后的信念支持。我们定义Bh为PB的历史a₁b₁...aₙbₙ。设σB ∈ Σ(PB)是信念支持MDP的一个策略。我们定义一个从策略σB派生的POMDP P中的策略σ̂B:对于h ∈ (Act·Sig)∗,我们固定σ̂B(h) = σB(Bh)。
4 弱揭示POMDPs
我们在本节中定义了第一个揭示属性,要求几乎肯定地,无限频繁地能够通过查看之前的信号序列来推断出当前状态。形式上,我们写作BPsing = {{q} | q ∈ Q},表示POMDP P = (Q, Act, Sig, δ, q₀)中所有单例信念支持的集合。一个可观察历史h ∈ (Act·Sig)∗,如果满足B∗({q₀}, h) ∈ BPsing,则称为一个启示(revelation)。
定义1(弱揭示)。 如果对于所有策略σ ∈ Σ(P),都有PPσ[Büchi(BPsing)] = 1,即对于所有策略,几乎肯定地会无限频繁地发生启示,则称POMDP P是弱揭示的。特别地,那些“重置”无限频繁发生,并且其重置可以通过专用信号观察到的POMDP是弱揭示的。我们将在图4中使用这样一个例子。对于弱揭示POMDP,可以对启示的发生给出概率界限(见附录D中的引理4,其中F = BPsing):从任何可达的信念出发,在2|Q|−1步内发生启示的概率至少为βP2|Q|−1。这个界限是渐近紧的:存在一个具有n + 2个状态、1个动作和n个信号的弱揭示POMDP,我们需要至少2n−1步才能以正概率观察到启示。更多细节请参见附录E中的示例4。
4.1 信念支持MDP的健全性
在本节中,我们证明对于弱揭示POMDP,信念支持MDP中的几乎肯定策略的存在性意味着POMDP中也存在几乎肯定策略。对于信念支持MDP的优先级函数,我们考虑“最大优先级”语义。形式上,设P = (Q, Act, Sig, δ, q₀)是一个POMDP,PB是其信念支持MDP。设p: Q → {0, ..., n}是P上的优先级函数,诱导目标Parity(p)。我们将这个函数扩展到信念支持MDP:对于b ∈ 2Q∅,我们定义
pB(b) = max{p(q) | q ∈ b}。
在没有任何假设的情况下,信念支持MDP可能不健全,即使是Büchi目标;可能存在信念支持MDP中的几乎肯定策略,但在POMDP中并不存在。图1中给出了一个反例。然而,在没有任何假设的情况下,对于Co-Büchi目标,它是健全的(见附录E中的引理5)。使用“max”(而不是“min”)在我们的设置中是正确的选择。直观上,在正确的揭示假设和策略下,如果一个信念支持被无限频繁地访问,那么它的所有状态也将被无限频繁地访问,因此信念支持的最大优先级是相关的,给定奇偶目标。在弱揭示语义下,信念支持MDP中的几乎肯定策略可以传递到POMDP中,适用于所有奇偶目标。换句话说,信念支持MDP的分析是健全的。我们回顾一下,纯无记忆策略足以在MDP中达到奇偶目标的最优值(Chatterjee和Henzinger 2012)。
命题1. 设P = (Q, Act, Sig, δ, q₀)是一个弱揭示POMDP,具有优先级函数p,PB是其信念支持MDP,具有优先级函数pB。假设在PB中存在一个几乎肯定策略σB用于Parity(pB);根据(Chatterjee和Henzinger 2012),我们可以假设σB是纯的和无记忆的。那么,σ̂B是P中Parity(p)的几乎肯定策略。
完整证明见附录E。
4.2 奇偶目标在优先级为0、1和2时的可判定性
我们证明,对于弱揭示POMDP,如果优先级限制在{0, 1, 2}内,信念支持MDP中的几乎肯定策略的存在性意味着POMDP中也存在几乎肯定策略。这为命题1提供了{0, 1, 2}优先级下的逆命题。我们强调,具有{0, 1, 2}优先级的奇偶目标涵盖了Büchi和Co-Büchi目标。在没有弱揭示假设的情况下,这一结果是错误的;请参见图1中的简单POMDP。该命题的证明见附录E。
命题2. 设P = (Q, Act, Sig, δ, q₀)是一个弱揭示POMDP,其优先级函数p的值在{0, 1, 2}内。设PB是其信念支持MDP,具有优先级函数pB。如果在P中存在一个几乎肯定策略用于Parity(p),那么在PB中也存在一个几乎肯定策略用于Parity(pB)。
从上述内容中,我们可以推导出一个复杂度上界;附录中证明了匹配的下界。
定理1. 在弱揭示POMDP中,具有{0, 1, 2}优先级的奇偶目标的几乎肯定策略的存在性是EXPTIME完全的。
证明:EXPTIME算法是本节结果的直接后果:根据命题1(信念支持MDP的健全性)和命题2(完备性),我们将问题简化为具有{0, 1, 2}优先级的奇偶目标在指数大小的MDP中几乎肯定策略的存在性。在MDP中,奇偶目标的几乎肯定策略的存在性可以在多项式时间内判定(Baier和Katoen 2008,定理10.127)。命题1还构造了POMDP中的几乎肯定策略。EXPTIME难性已在命题4(附录G)中证明,即使是对于Co-Büchi目标(即优先级在{0, 1}内)以及更受限制的强揭示POMDP类别。
备注2. 该算法还给出了弱揭示POMDP中具有{0, 1, 2}优先级的奇偶目标策略大小的上界。由于我们将问题简化为分析一个指数大小的MDP,并且在MDP中奇偶目标的策略是无记忆的,根据命题1,POMDP中的策略大小是指数级的。我们还可以在附录E中的示例4中证明指数级的下界。
4.3 优先级为1、2和3时奇偶目标的不可判定性
上一节表明,对于弱揭示POMDP,分析信念支持MDP是一种健全且完备的方法,适用于具有{0, 1, 2}优先级的奇偶目标。人们可能会问,这种方法是否对任何优先级函数都是完备的,即如果弱揭示POMDP中存在几乎肯定策略,是否意味着其信念支持MDP中也存在几乎肯定策略。遗憾的是,这在一般情况下并不成立,即使对于取值在{1, 2, 3}内的优先级函数也是如此。我们在下面讨论这样一个例子。
示例1. 考虑图4中的POMDP P。这个POMDP是弱揭示的,因为状态q₀在任何策略下都会被无限频繁地访问,并且可以通过信号s₀揭示。这个POMDP中的唯一选择是在状态q₁和q′₁中:是执行动作a并移动到q₀或{q₁, q′₁},还是执行动作c并移动到q₂或q₃。观察到,当游戏从q₀开始时,唯一可达的信念支持是{q₀}、{q₁, q′₁}和{q₂, q₃},它们都具有最大奇数优先级。因此,具有优先级函数pB的信念支持MDP显然没有任何几乎肯定(甚至积极的)获胜策略。然而,我们证明P中存在几乎肯定策略。在这个POMDP中获胜的唯一方法是无限频繁地访问q₂,同时只有限频繁地访问q₃。要做到这一点,观察到,当多次连续执行动作a并且只收到信号s₁时,处于q′₁的概率会变得任意接近1。形式上,如果σa是只执行动作a的策略,那么对于n > 0,有
PPσa[Qₙq′₁ | (s₁)ₙ] = 1 - PPσa[q₀(q₁)ₙ | (s₁)ₙ] = 1 - 1/2ⁿ。
对于n > 0,设σₙ是直到连续看到n次信号s₁时只执行动作a的策略,当这种情况发生时,执行动作c。我们将游戏在POMDP中的一个回合划分为1、2、...;每当我们从访问q₂或q₃后回到q₀时,我们就进入下一个回合。考虑在回合n中执行σₙ的策略。这个策略确保了无限多个回合的发生,因为在每个回合n中,它最终会成功地看到n次连续的s₁。在每个回合n中,动作c最终会以概率1被执行。根据上述等式,q₃被看到的概率为1/2ⁿ,而q₂被看到的概率为1 - 1/2ⁿ。状态q₂显然几乎肯定会被无限频繁地看到,因为每次看到它的概率下界为1/2。然而,q₃在回合n之后再也不会被看到的概率等于∏∞ᵢ₌ₙ(1 - 1/2ⁱ),这个概率是正的,并且随着n的增大而增加。我们推断出q₃被有限频繁看到的概率为1。观察到,没有有限记忆策略可以在这种POMDP中获胜:这样的策略需要无限频繁地执行动作c,但它只能在有界长度的后缀之后执行。因此,每次执行c时,到达q₃的概率都会被下界限制。
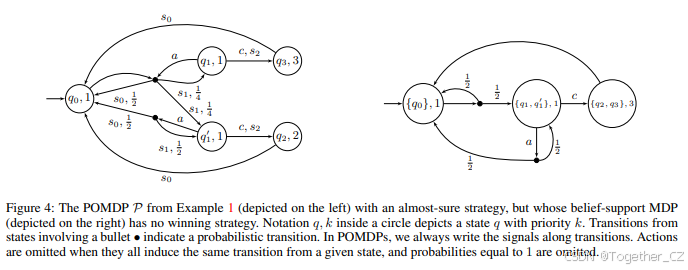
将上述例子推广,我们证明,如果允许p取值在{1, 2, 3}内,那么弱揭示POMDP中几乎肯定策略的存在性是不可判定的。我们在这里提供一个证明草图;完整的证明见附录E。
定理2. 在弱揭示POMDP中,具有{1, 2, 3}优先级的奇偶目标的几乎肯定策略的存在性是不可判定的。对于积极获胜策略的存在性也是如此。
我们的证明使用了从概率自动机的值1问题的归约。概率自动机(Rabin 1963)是一个四元组A = (Q, Act, δ, q₀)。可以通过POMDP定义它们的语义:它们表现得像POMDP,我们假设信号不提供任何信息(Sig是一个单例)。在游戏过程中,信号不提供任何有用的信息(除了已经玩过的步数之外);纯策略因此对应于字母表Act上的单词。直观上,证明扩展了图4中的POMDP,通过用概率自动机A的一个副本替换状态q₁和q′₁:从q₀出发的转移进入A的初始状态,执行动作c会进入q₂,如果当前状态是A的最终状态,则进入q₃,否则进入q₂。我们保持以正概率返回q₀,以使其成为弱揭示的。在例子中连续执行n次动作a的想法被一个可能的单词序列所取代,这些单词到达最终状态的概率任意接近1。可以证明,当且仅当A相对于其最终状态具有值1时,这种POMDP中存在几乎肯定策略。
4.4 弱揭示属性的可判定性
为了结束本节,我们讨论判定一个POMDP是否为弱揭示的复杂性。弱揭示属性是由信念支持上的Büchi条件定义的,这与在POMDP状态上研究的Büchi条件不同。与信念支持相关的目标有时被称为同步目标(Doyen、Massart和Shirmohammadi 2019;Doyen 2023)。然而,据我们所知,它们尚未在POMDP的信念支持上进行研究。一个直接的论证表明,弱揭示属性可以在2-EXPTIME内判定。为了看到这一点,将POMDP扩展为包含当前信念支持的信息:这会创建一个指数大小的POMDP,其状态空间为Q×2Q∅。
这个扩展POMDP对于Co-Büchi(Q×BPsing)没有积极获胜策略,当且仅当它是弱揭示的。由于POMDP中Co-Büchi目标的积极获胜策略的存在性是EXPTIME完全的(Chatterjee、Chmelik和Tracol 2016),这个算法的复杂度是双重指数的。我们证明了一个更好的算法:判定一个POMDP是否为弱揭示的是EXPTIME完全的。EXPTIME难性是通过从POMDP中安全目标的积极策略的存在性问题的归约得到的。EXPTIME成员资格更为复杂:我们研究了在POMDP中存在一个策略,以正概率实现Safety(B)的复杂性,其中B是一个信念支持集合。我们证明这个问题可以通过一个指数大小的确定性可达性游戏来解决,该游戏在EXPTIME内。然后我们证明,判定一个POMDP是否为弱揭示可以归约为多项式多次对该算法的查询。所有细节见附录F;我们得到的结果如下。
定理3. 判定一个POMDP是否为弱揭示是EXPTIME完全的。
5 强揭示POMDPs
在本节中,我们引入强揭示POMDPs,这是一种更强的属性,意味着在POMDP中几乎肯定地无限频繁地发生启示。我们证明,对于具有任意奇偶目标的强揭示POMDPs,存在几乎肯定策略是可判定的。我们定义一种揭示信号的概念:对于POMDP P = (Q, Act, Sig, δ, q₀)中的一个状态q,我们定义Revealing(q) = {s ∈ Sig | ∀r, r′ ∈ Q, r′ = q ⇒ δ(r, a)(s, r′) = 0},即那些表明下一个状态肯定是q的信号集合。为了方便起见,我们定义Succ(q, a) = {q′ ∈ Q | ∃s ∈ Sig, δ(q, a)(s, q′) > 0}和Succ(q, a, s) = {q′ ∈ Q | δ(q, a)(s, q′) > 0}。
定义2. POMDP P = (Q, Act, Sig, δ, q₀)是强揭示的,如果在P的底层MDP中的任何两个状态之间的任何转移,也可以通过一个揭示信号发生。形式上,P是强揭示的,如果对于所有q, q′ ∈ Q和a ∈ Act,如果q′ ∈ Succ(q, a),那么存在s ∈ Revealing(q′),使得q′ ∈ Succ(q, a, s)。
根据这一定义,信念支持集合BPsing从初始状态开始,对于任何给定的策略,都会被无限频繁地访问,因此强揭示POMDP特别是弱揭示的。注意,图4中的弱揭示POMDP不是强揭示的:例如,q′₁ ∈ Succ(q₁, a),但不存在一个揭示信号可以肯定地揭示在q₁之后的q′₁。强揭示属性可以通过简单地分析每个转移来在POMDP的大小的多项式时间内判定。
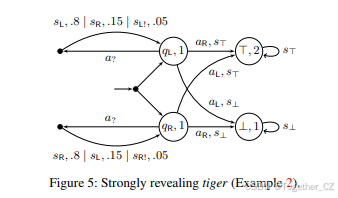
示例2. 我们给出了一个受(Cassandra、Kaelbling和Littman 1994)中的老虎问题启发的强揭示POMDP的例子,如图5所示。这个例子就是图3引言中使用的例子;在附录A中也提供了用我们的工具生成这个例子的代码。在老虎环境中,智能体需要打开左边或右边的门,分别用动作aL或aR表示。其中一扇门后面有一只(致命的)老虎。幸运的是,智能体可以选择等待并倾听(动作a?),以帮助其决策。倾听会产生一个信号,该信号偏向于现实,即信号可以是sL或sR,前者在老虎真的在左边时更有可能,反之亦然。我们提出了老虎环境的一个版本,在这个版本中,倾听保证最终能够分辨出老虎在哪个门后面。这是通过添加新的揭示信号aL!或aR!实现的,重要的是,这些信号只能在老虎在左边或右边时获得。为了保持事情的趣味性,这些信号只能以小概率获得(然而,它们的存在本身已经确保了POMDP是强揭示的)。我们还添加了死亡(s⊥)和胜利(s⊤)的信号,这些信号在原始老虎环境中是缺失的。添加信号sL!和sR!使得目标更容易实现,因此改变了POMDP的语义;事实上,与原始老虎环境相比,可以获得更多关于状态的信息。然而,通过信号s⊤和s⊥揭示死锁状态⊤和⊥是使POMDP成为强揭示的必要条件,但这并没有使目标更容易实现,因为无论如何,没有策略能够离开这些状态。
5.1 强揭示下奇偶目标的可判定性
强揭示POMDPs的信念支持MDP分析的健全性由命题1得出;剩下要证明的是完备性(证明见附录G)。
命题3. 设P = (Q, Act, Sig, δ, q₀)是一个具有奇偶目标的强揭示POMDP,其优先级函数为p,PB是其信念支持MDP,其优先级函数为pB。如果在P中存在一个几乎肯定策略用于Parity(p),那么在PB中也存在一个几乎肯定策略用于Parity(pB)。
我们还证明了一个复杂度下界。该下界适用于强揭示POMDPs中的Co-Büchi目标;由于强揭示POMDPs是弱揭示POMDPs的一个子类,因此对于弱揭示POMDPs也成立。
命题4. 下列问题是EXPTIME难的:给定一个具有Co-Büchi目标的强揭示POMDP,判定是否存在几乎肯定策略。
与之前一样,我们通过将问题简化为信念支持MDP的分析来获得问题的可判定性。证明与定理1的证明类似,只需将命题2替换为命题3。
定理4. 在强揭示POMDPs中,奇偶目标的几乎肯定策略的存在性是EXPTIME完全的。
证明:前面的命题表明,该问题在EXPTIME内:根据命题1(信念支持MDP的健全性)和命题3(完备性),我们可以将问题简化为指数大小的MDP中奇偶目标的几乎肯定策略的存在性。在MDP中,奇偶目标的几乎肯定策略的存在性可以在多项式时间内判定(Baier和Katoen 2008,定理10.127)。EXPTIME难性由命题4得出,即使是对于Co-Büchi目标。
5.2 强揭示下Co-Büchi博弈的不可判定性
在本节中,我们研究揭示语义是否有助于具有部分信息的两人零和博弈。一般来说,这类博弈中的Co-Büchi目标是不可判定的(它们包含POMDPs),而Büchi博弈对于几乎肯定策略是可判定的(Bertrand、Genest和Gimbert 2017)。我们证明了一个负面结果:即使限制在满足强揭示属性的自然扩展的博弈中,具有部分信息的两人Co-Büchi博弈中玩家1的几乎肯定策略的存在性也是不可判定的。
两人零和部分信息博弈是元组G = (Q, Act₁, Act₂, Sig, δ, q₀),其中Q是有限状态集,Act₁和Act₂是两个玩家的动作集,Sig是有限信号集,δ: Q × Act₁ × Act₂ → D(Sig × Q)是转移函数,q₀ ∈ Q是初始状态。在每一轮中,玩家1和玩家2分别从Act₁和Act₂中选择一个动作。历史和游戏的定义与POMDP相同。对于i ∈ {1, 2},玩家i的一个策略是一个函数σᵢ: (Actᵢ × Sig)∗ → D(Actᵢ)。给定玩家1和玩家2的两个策略σ₁和σ₂,我们可以像在POMDP中一样定义在游戏上的概率测度PPσ₁,σ₂[·]。如果玩家1的一个策略σ₁对于玩家2的所有策略σ₂,都有PPσ₁,σ₂[W] = 1,则称策略σ₁对于目标W是几乎肯定的。为了表达Co-Büchi目标,我们像之前一样考虑一个优先级函数p: Q → {0, 1}。如果一个博弈G是强揭示的,对于任何可能的转移,都有一个揭示信号的机会,那么这个博弈的定义与POMDP相同,假设Act = Act₁ × Act₂。
定理5. 在强揭示的两人Co-Büchi博弈中,玩家1的几乎肯定策略的存在性是不可判定的。
5.3 POMDPs的乐观语义
在我们的揭示定义中,我们采用了考虑POMDP子类的观点。这种观点的一个局限性是,我们的结果对于那些既不是强揭示也不是弱揭示的POMDPs没有任何说明。我们认为,从另一个角度来看,我们对结果的表述可能更有成果,即将其应用于所有POMDPs的类,通过定义一种替代的、揭示的语义。考虑一个POMDP P。我们定义一个扩展的POMDP Psr,使得在每个转移中,都有一个很小的概率揭示我们到达了哪个状态,使用额外的信号sq,每个状态q对应一个信号。
定理6. 对于任何POMDP P,Psr是强揭示的。此外,如果在Psr中没有几乎肯定策略来确保一个Omega-正则目标(这是可判定的,根据定理4),那么在P中也没有几乎肯定策略来确保相同的目标。
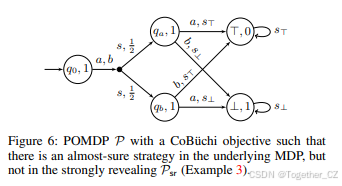
反证法很容易证明:P中的任何几乎肯定策略都可以提升为Psr中的几乎肯定策略。这一属性证明了“乐观语义”这一术语的合理性。注意,逆命题不成立(因为POMDPs的Omega-正则目标是不可判定的)。我们通过比较我们的方法与一个更乐观的语义来说明这一点:在每个转移中揭示确切的状态,这对应于在底层MDP中工作。以下例子表明,研究强揭示语义比研究底层MDP更为精细(即,它证明了对于更多的POMDPs,不存在几乎肯定策略)。
示例3. 考虑图6中的POMDP P,它具有一个Co-Büchi目标。在这个POMDP中,唯一的获胜方式是到达状态⊤;为此,必须从qa执行动作a或从qb执行动作b。然而,这只有在知道确切的状态(qa或qb)之后才可能。因此,在底层MDP中存在一个几乎肯定策略,但在强揭示Psr中并不存在。
我们建议,如果面对一个具有奇偶目标的POMDP,可以尝试以下步骤:
-
首先尝试解决底层MDP(多项式时间可解,根据Baier和Katoen 2008)。
-
如果底层MDP中没有几乎肯定策略,则尝试解决强揭示POMDP(指数时间可解,根据定理4)。
-
如果强揭示Psr中也没有几乎肯定策略,则可以确定原始POMDP中也不存在这样的策略。
这种逐步分析的方法可以有效地利用不同层次的语义来解决问题。
6 相关工作
我们讨论了额外的参考文献,这些文献通过设置限制来使随机系统变得可判定。与我们提出的“启示”机制最接近的想法是(Berwanger和Mathew 2017)中定义的,它描述了一类具有“肯定”(而非仅仅是“几乎肯定”)启示的多人部分信息博弈。在这种博弈中,从任何点开始,肯定会在有限步数内发生“启示”。这是一种比我们的启示机制更强的启示类型,即使在奇偶博弈中也是可判定的。
“决定性”属性(Abdulla、Ben Henda和Mayr 2007;Bertrand等 2020)是另一个有用的属性,用于决定无限随机系统(不涉及决策制定)的可达性属性。决定性意味着存在一个有限吸引子(attractor);在固定有限记忆策略后,弱揭示POMDPs中存在这样的吸引子(如命题1所示)。这一属性的扩展也被考虑用于无限MDP(Bertrand等 2020),用于近似可达性的值,这与我们的目标是正交的。
另一种实现可判定性和强保证的路径是限制策略,例如研究“无记忆”(Vlassis、Littman和Barber 2012)或有限记忆(Chatterjee、Chmelik和Tracol 2016;Andriushchenko等 2022)策略在POMDPs中的应用。在我们的论文中,我们考虑的策略仅使用有限记忆,因为它们是信念支持MDP上的无记忆策略(在我们的案例中,甚至证明了在正确假设下,这些策略是最优的)。信念支持策略在POMDPs中的充分性已知(对于几乎肯定可达性,见Baier、Größer和Bertrand 2012),也被用于设计高效算法(Junges、Jansen和Seshia 2021);这种方法可以加速我们的算法。
Raskin和Sankur(2014)给出了一类具有奇偶目标的可判定POMDPs,称为多环境MDP。这些POMDPs由多个相同的MDP副本组成,只有转移函数不同。唯一的部分观测来自于不知道我们在哪个副本中进行游戏,因此这也是对信息损失的一种限制。这一类POMDPs与我们的揭示POMDPs类是不可比的。
在定量设置中,具有动作成本(时间或能量)以揭示当前状态或减少不确定性的想法在文献中多次出现。这种想法早在2011年就出现了(Bertrand和Genest 2011),用于具有定量可达性目标的POMDPs。最近,在在线规划社区中,也考虑了具有类似机制的主动测量POMDPs(Bellinger等 2021;Krale、Simão和Jansen 2023)。尽管设置不同(在线规划与模型检测),但它与我们的工作有类似的直觉:精确的状态可以被知晓,这有助于找到好的策略。同样,在在线规划中,Liu等(2022)考虑了一类限制信息损失的POMDPs,使强化学习样本效率更高。
7 展望
我们提出了几类POMDP,使得许多自然目标变得可判定,并展示了这些类别与不可判定性边界非常接近(优先级{0, 1, 2}与{1, 2, 3},POMDPs与博弈)。由于POMDPs的内在不可判定性,它们并不常通过精确算法的视角进行研究。我们相信,通过更深入地理解(i)使POMDPs对目标类别可判定的结构属性(例如弱/强揭示),以及(ii)使简单策略(如基于信念支持的策略)足够的条件,可以获得很多收益。我们的文章是朝着这些目标迈出的新一步。
更具体地说,一个有趣的下一步可能是更深入地研究(i),例如通过确定简单目标(涉及信念和信念支持)的策略存在性的精确复杂性,这在定理3的证明中已经有所开始。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











