






在交通强国的战略引领下,中国铁路网如巨龙般纵贯大江南北,将五湖四海紧密相连,极大地促进了人员出行与物流运输的便捷性。然而,随着铁路线路的不断扩展,管理层面的安全问题也日益凸显。历史上,多起与铁路相关的安全事故令人痛心,这些事件不仅夺去了无数鲜活的生命,也为我们敲响了安全管理的警钟。传统的铁道安全巡检工作主要依赖于专业的工程师团队进行定时巡检。然而,这种模式存在诸多局限性。一方面,人力不足可能导致安全隐患无法及时发现;另一方面,非工作人员非法入侵铁轨等意外事故的发生,也给铁路安全带来了严重威胁。此外,天气、气象等客观因素也可能影响巡检工作的正常进行,导致安全空隙的出现。
面对这些挑战,我们迫切需要寻找一种更加高效、智能的巡检方式。随着AI智能化模型的快速发展与普及,越来越多的传统行业开始探索引入这一技术来赋能行业生产作业。对于铁道安全巡检场景而言,无人机+AI智能化模型的新型巡检思路应运而生。无人机作为一种高效、灵活的巡检工具,具有高空作业、视野开阔、覆盖范围广等优势。在指定的作业巡检线路上设定无人机自动巡航,可以实现对铁路线路的全方位、无死角监控。通过高频次的航飞巡检,无人机能够及时发现并捕捉潜在的安全隐患,确保铁路运行的安全稳定。而AI智能化模型则是对无人机捕获的画面进行分析检测的关键。借助先进的算法和模型,AI能够自动识别并判断画面中的异常情况,如人员非法入侵、铁轨损坏等。一旦发现问题,AI会立即发送预警信息到中央平台端,平台端则可以根据预警信息及时安排对应的工作人员进行险情处理。
本文就是建立在这样的思考背景下,想要从实验性质的角度探索分析方案的可行性来开发构建铁路轨道场景下的人员非法侵入检测预警系统,在前文中我们已经进行了相应的开发实践,感兴趣的话可以自行移步阅读即可:
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv7全系列【tiny/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv9全系列【gelan/t/s/m/c/e—yolov9/t/s/m/c/e】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv10全系列【n/s/m/b/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv11全系列【n/s/m/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
《AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv12全系列【n/s/m/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统》
本文正是在这样的思考背景下想要从实验性质的角度出发,尝试应用嵌入式端超轻量级的LeYOLO系列的参数模型来开发构建轻量级的检测识别分析系统,首先看下实例效果:
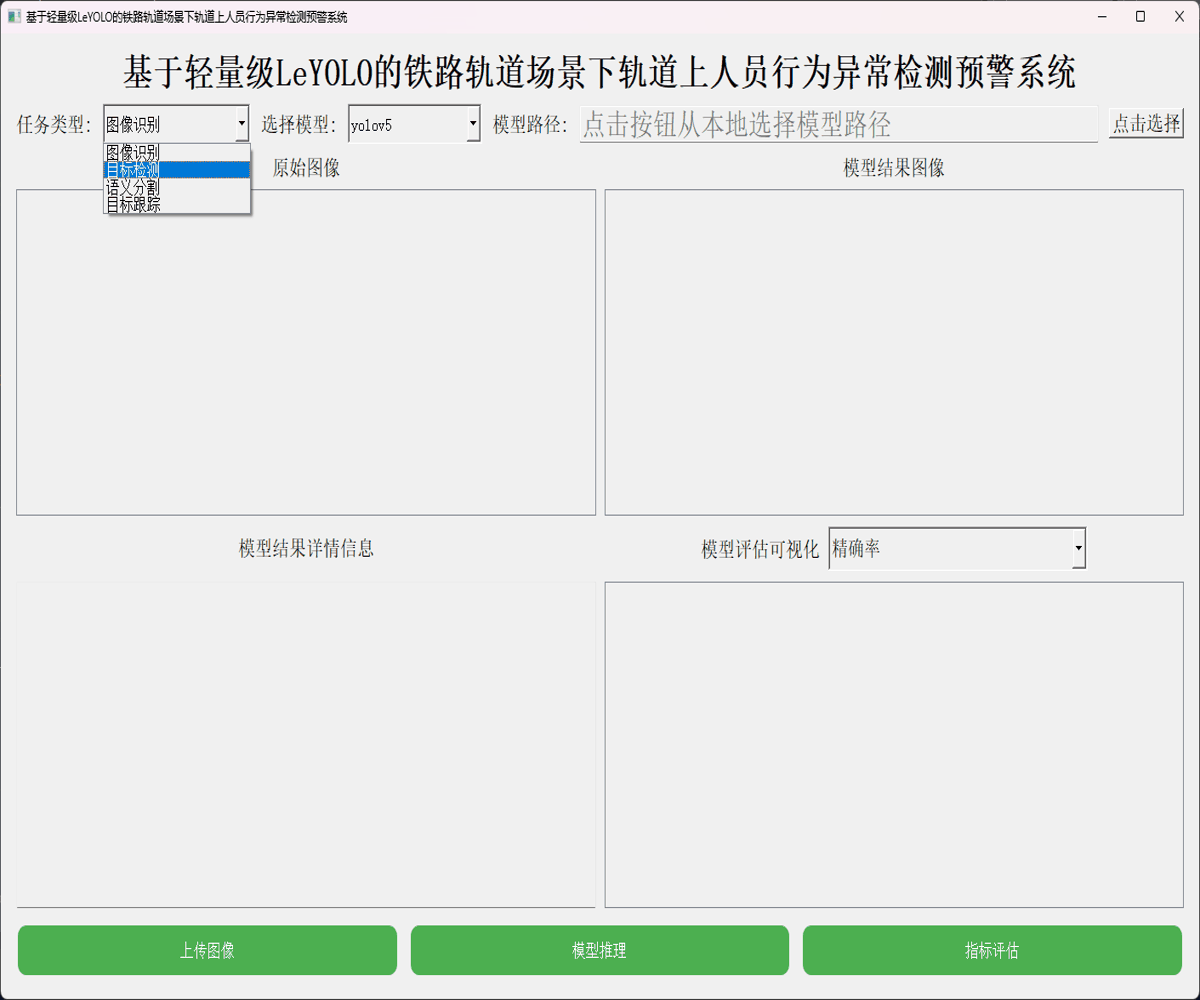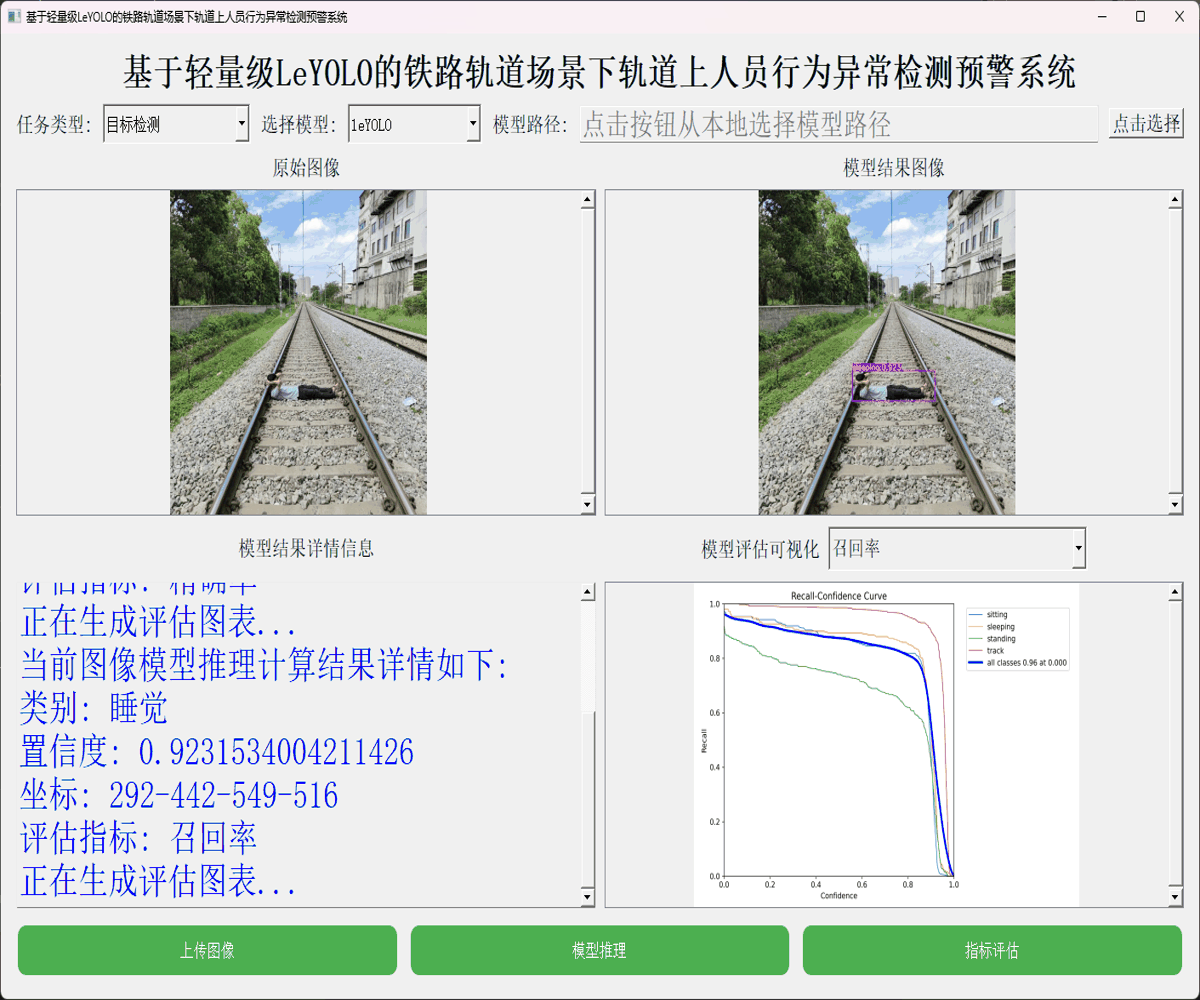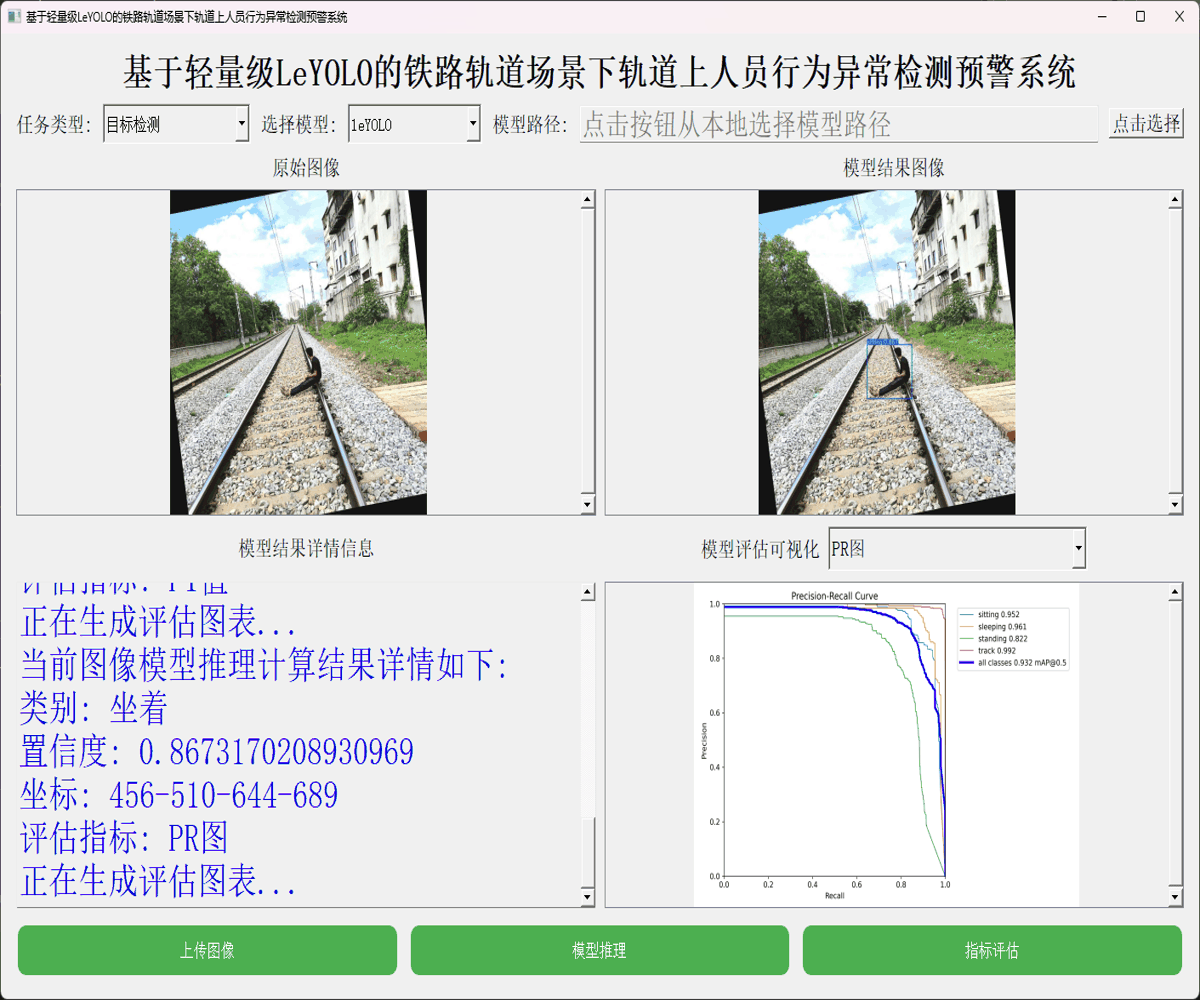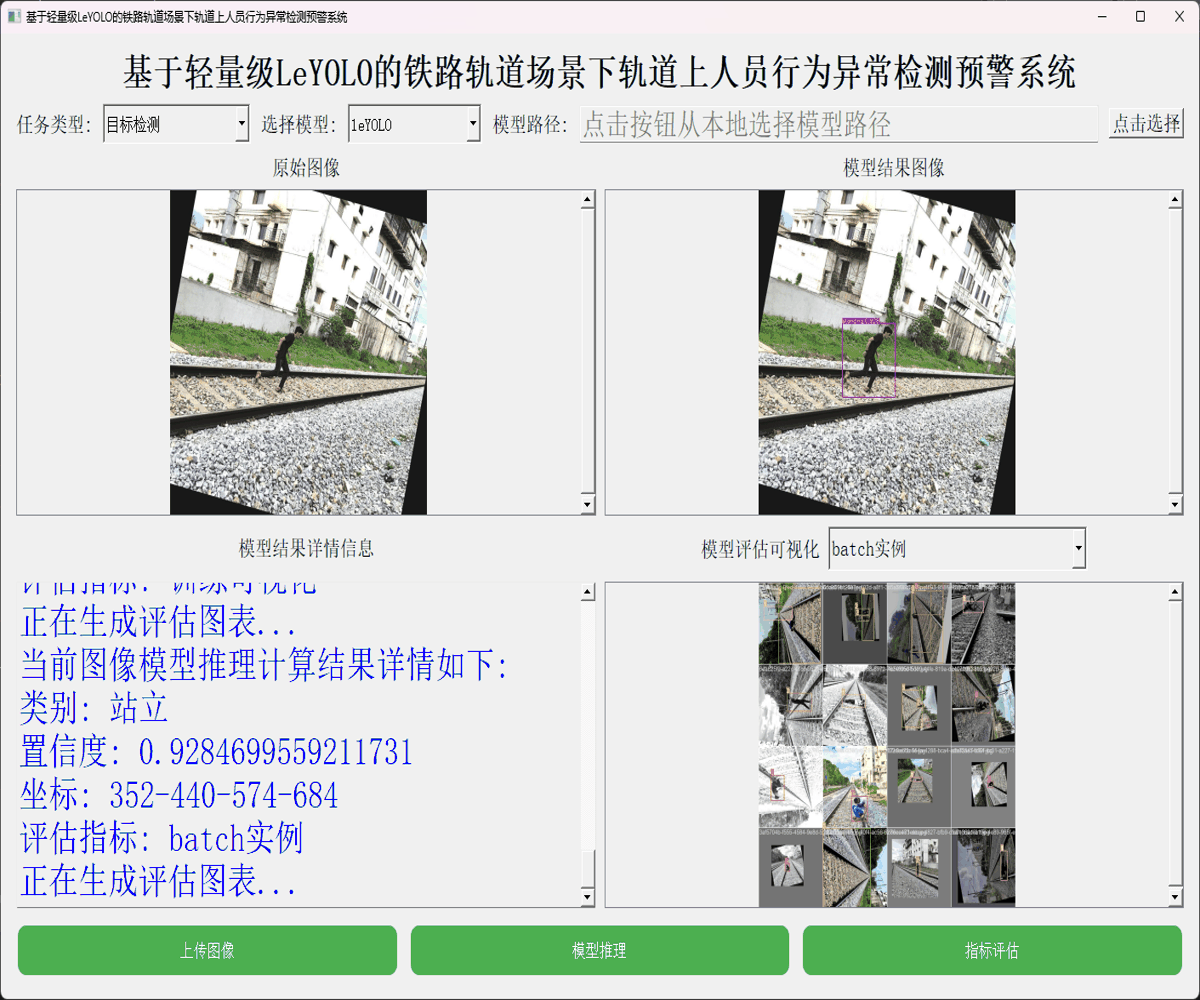
接下来看下实例数据:

深度神经网络中的计算效率对于目标检测至关重要,尤其是在新模型将速度优先于高效计算(FLOP)的情况下。这种演变在某种程度上已经落后于嵌入式和面向移动的AI对象检测应用程序。这里重点讨论了基于FLOP的高效目标检测计算的神经网络结构的设计选择,并提出了几种优化方法来提高基于YLO的模型的效率。
首先,介绍了一种基于反向瓶颈和信息瓶颈原理的有效主干扩展方法。其次,提出了快速金字塔结构网络(FPAN),旨在促进快速多尺度特征共享,同时减少计算资源。最后提出了一个解耦的网络中网络(DNiN)检测头的设计,以提供快速而轻量级的计算分类和回归任务。
在这些优化的基础上,利用更高效的主干,为对象检测和以YOLO为中心的模型(称为LeYOLO)提供了一种新的缩放范例。在各种资源限制下始终优于现有模型,实现了前所未有的准确性和失败率。值得注意的是,LeYOLO Small在COCO val上仅以4.5次失败(G)获得了38.2%的竞争性mAP分数,与最新最先进的YOLOv9微小模型相比,计算量减少了42%,同时实现了类似的精度。我们的新型模型系列实现了以前未达到的浮点精度比,提供了从超低神经网络配置(<1 GFLOP)到高效但要求苛刻的目标检测设置(>4 GFLOP)的可扩展性,对于0.66、1.47、2.53、4.51、5.8和8.4浮点(G),具有25.2、31.3、35.2、38.2、39.3和41 mAP。
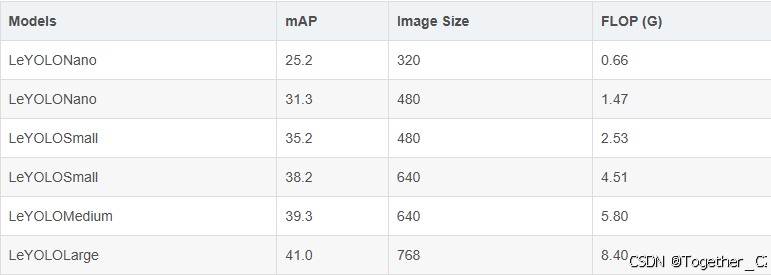
一共提供了n、s、m和l四款不同参数量级的模型。
这里我们保持完全相同的实验参数设置来进行四款模型的开发训练,等待训练完成之后我们来整体进行各项指标的对比分析。
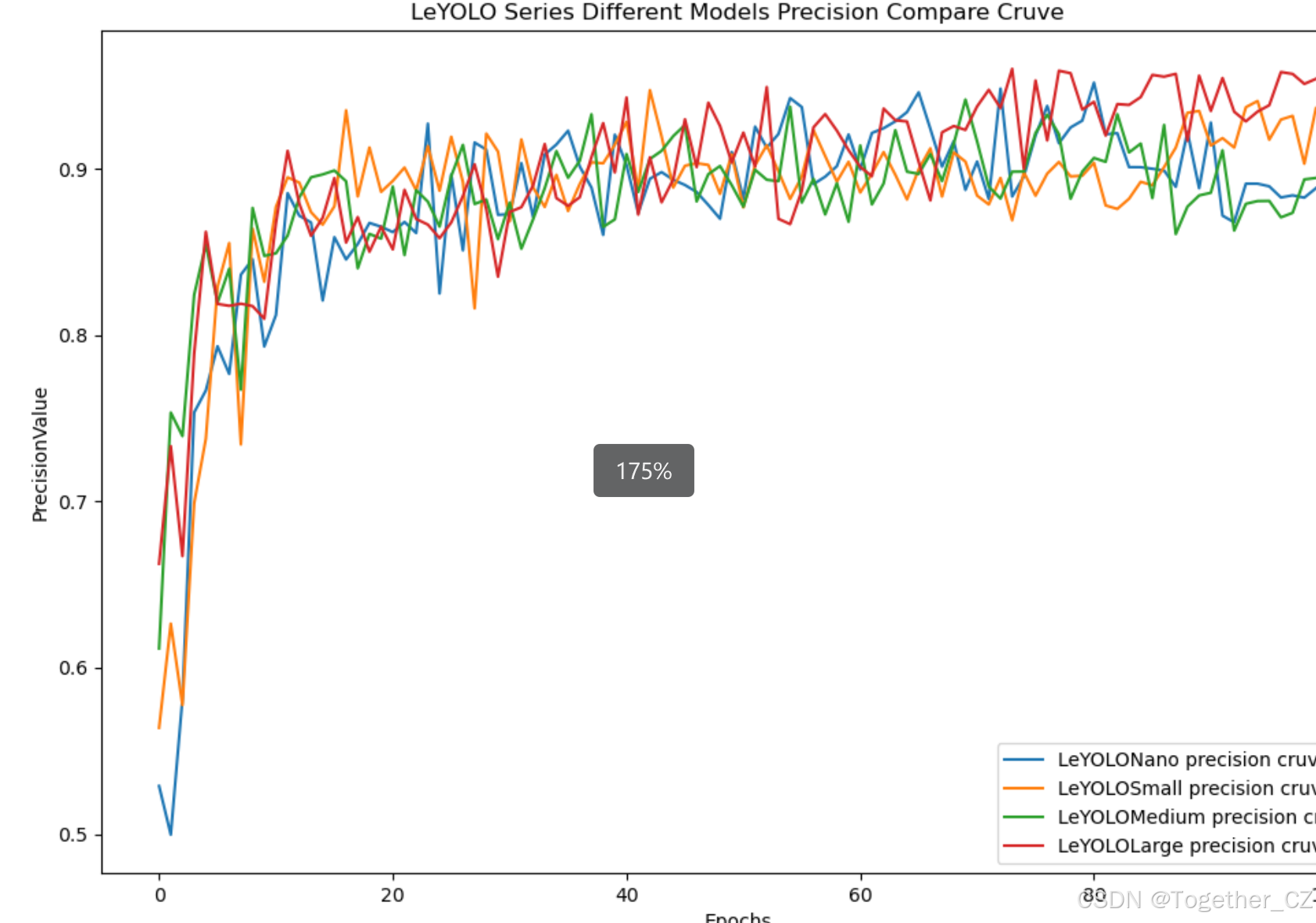
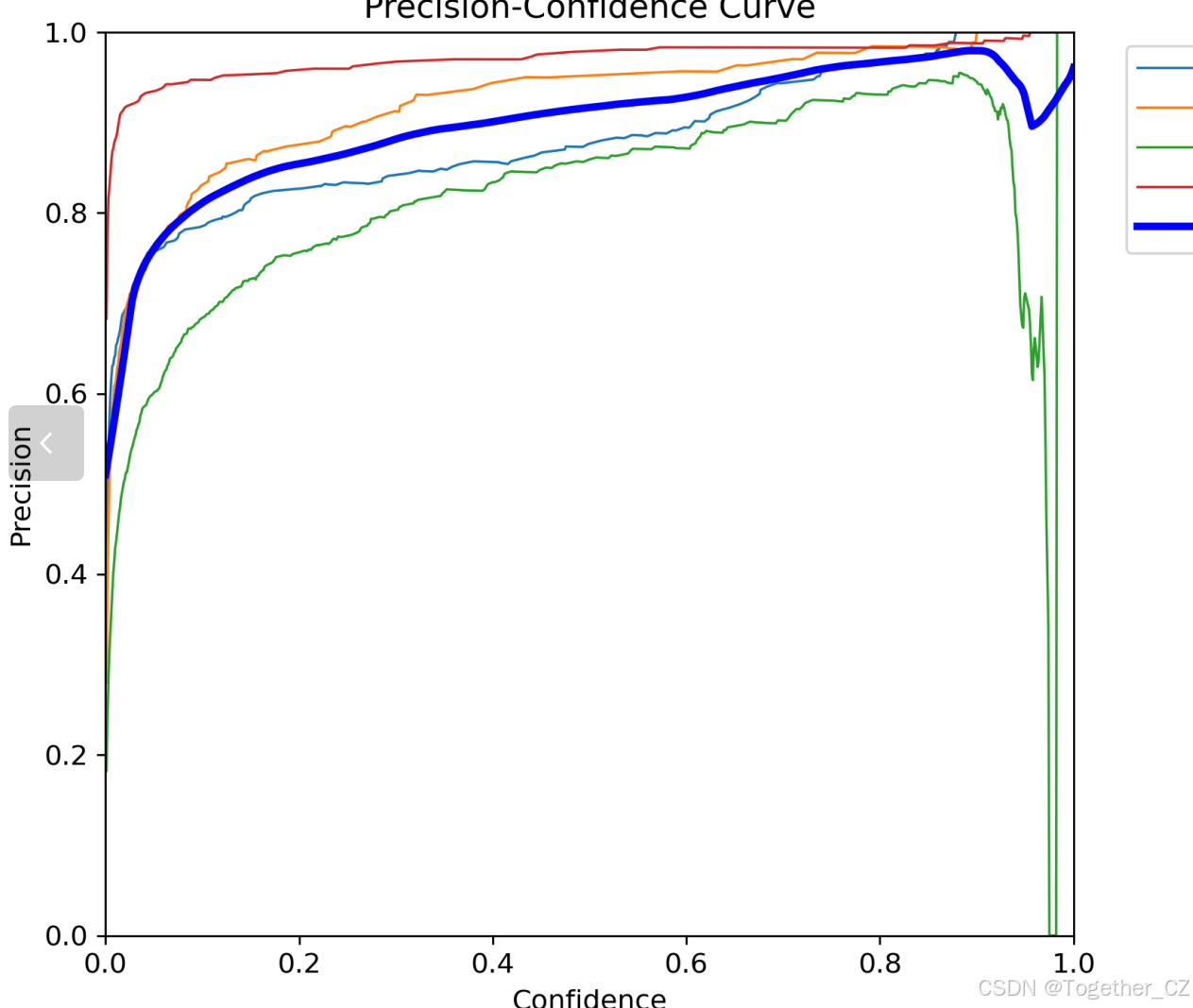
【Precision曲线】
精确率曲线(Precision Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
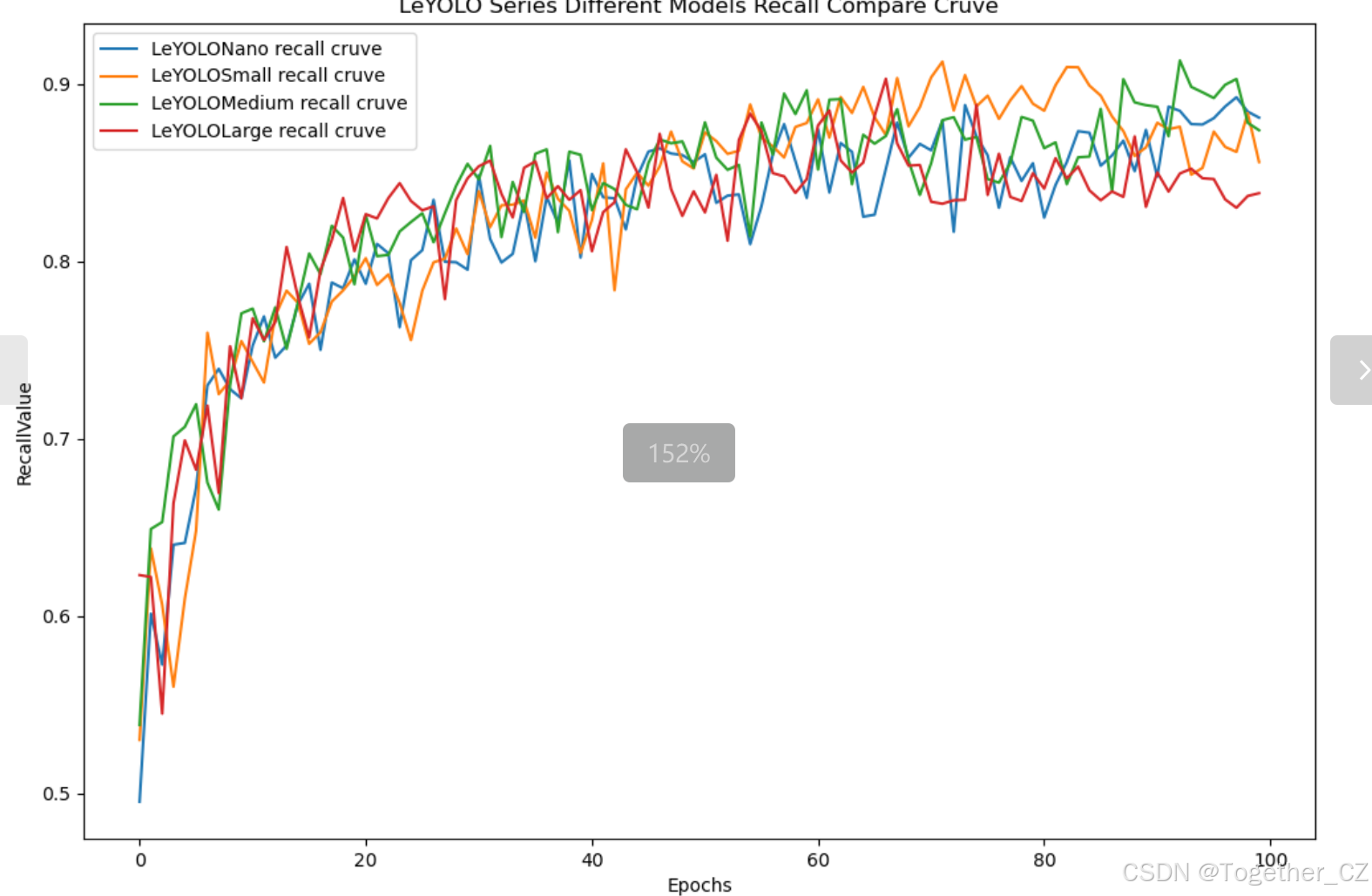
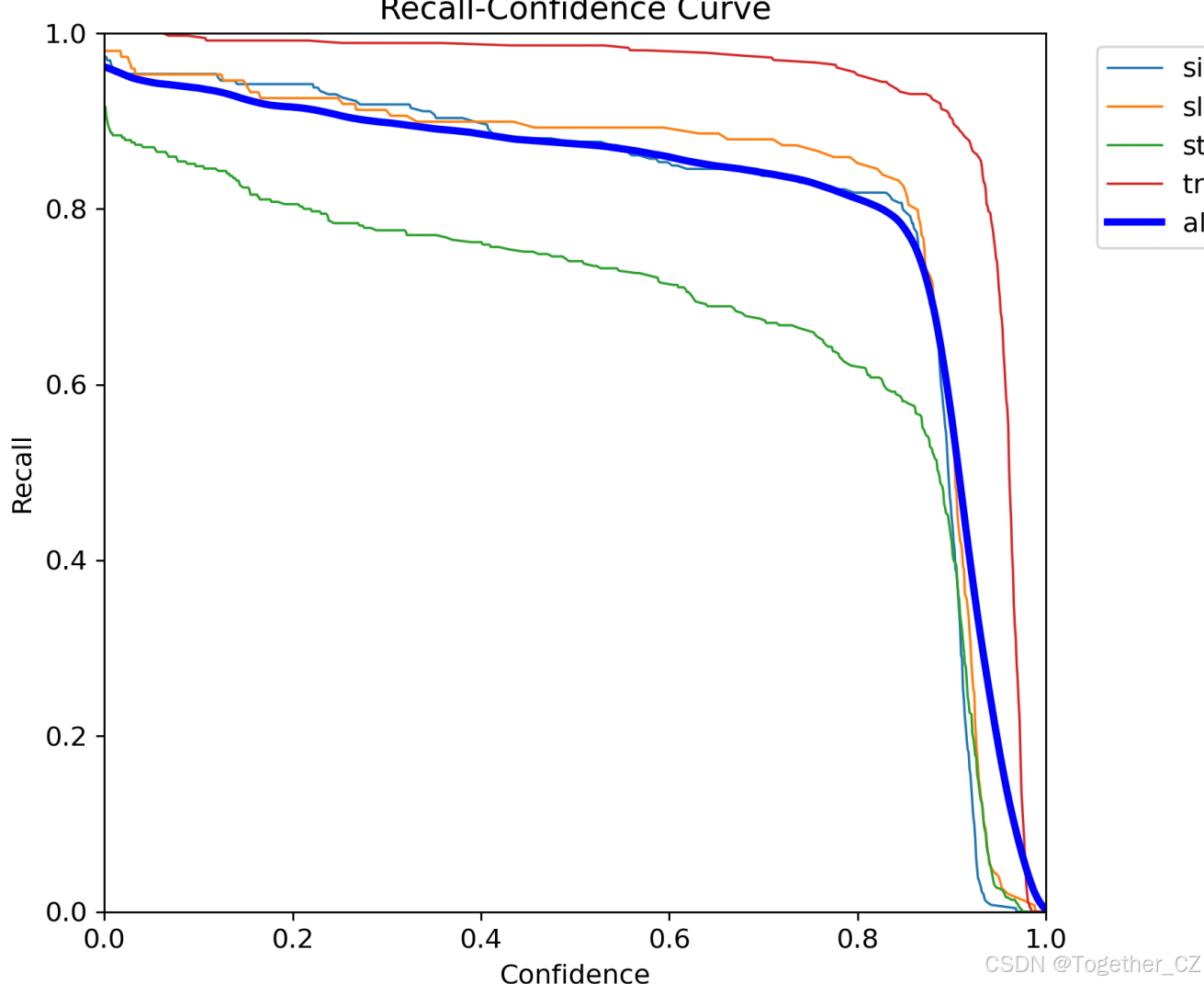
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
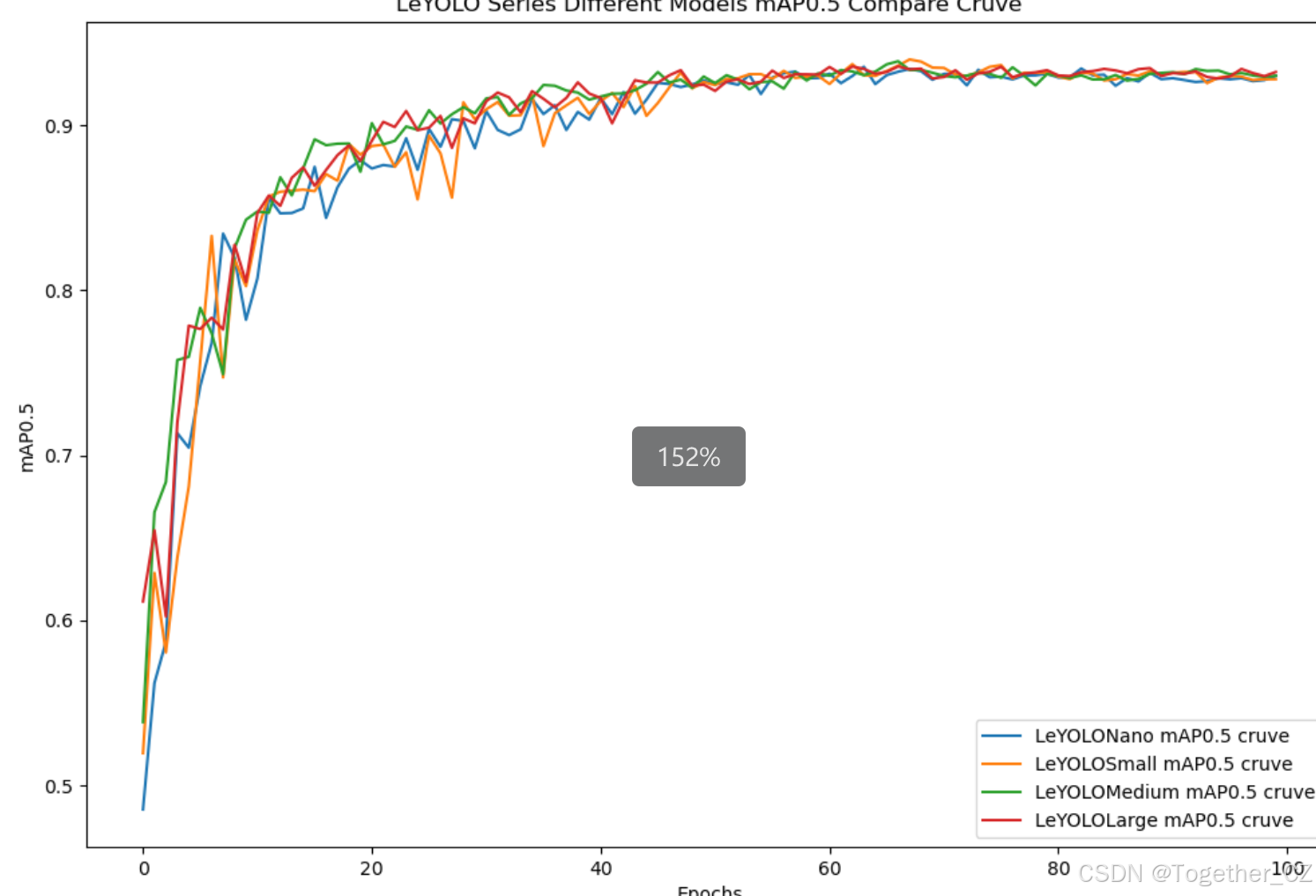
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
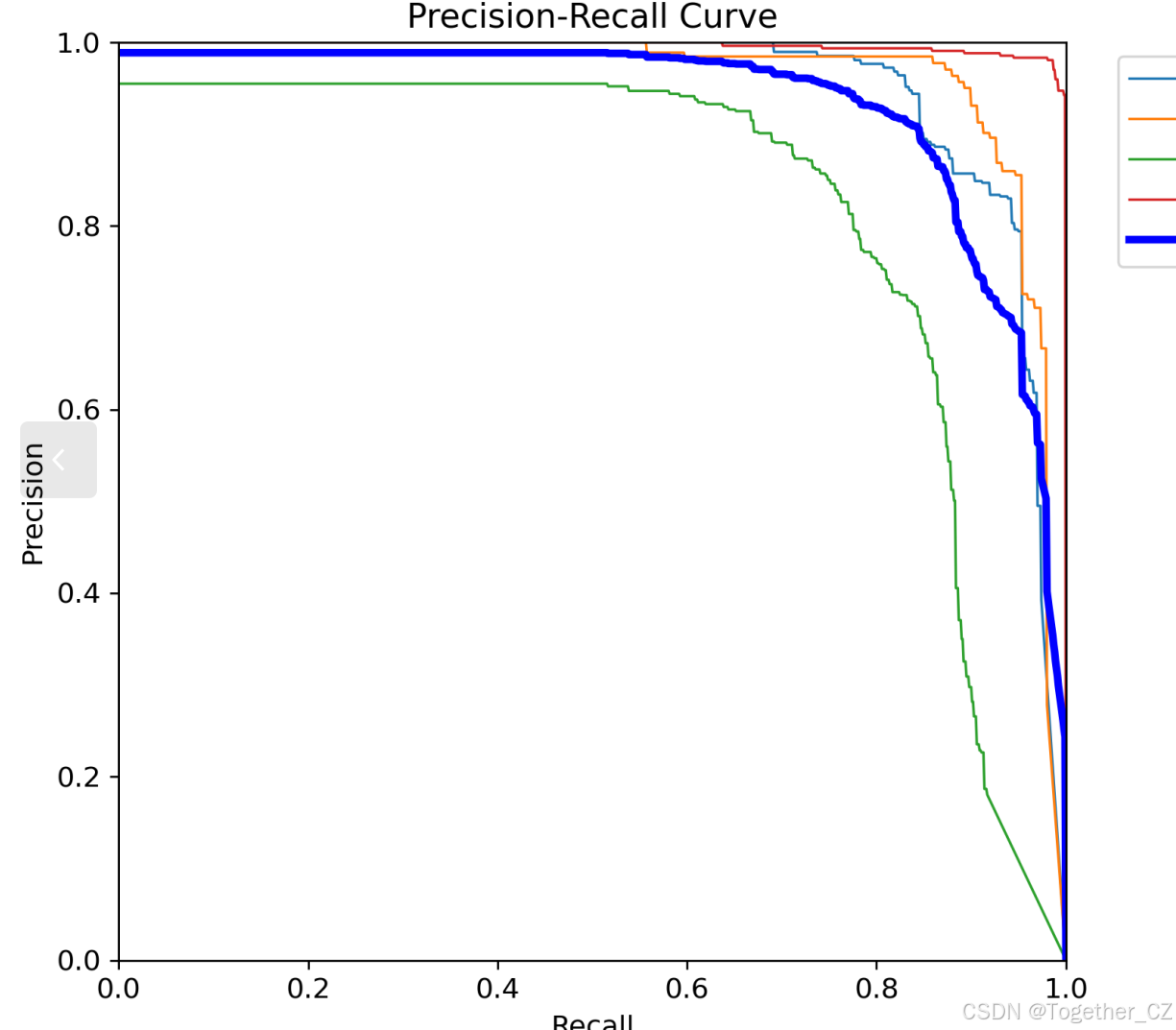
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
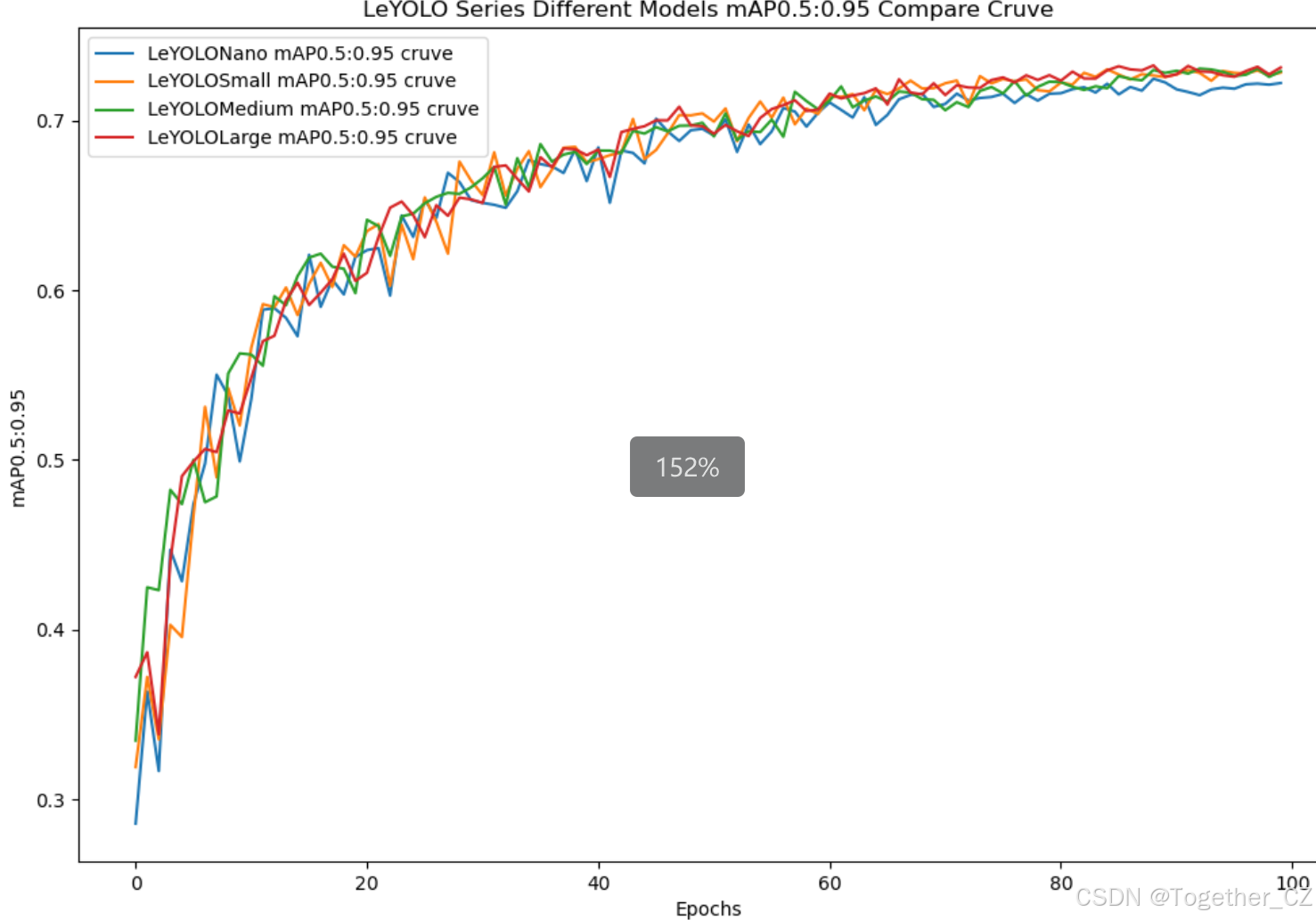
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
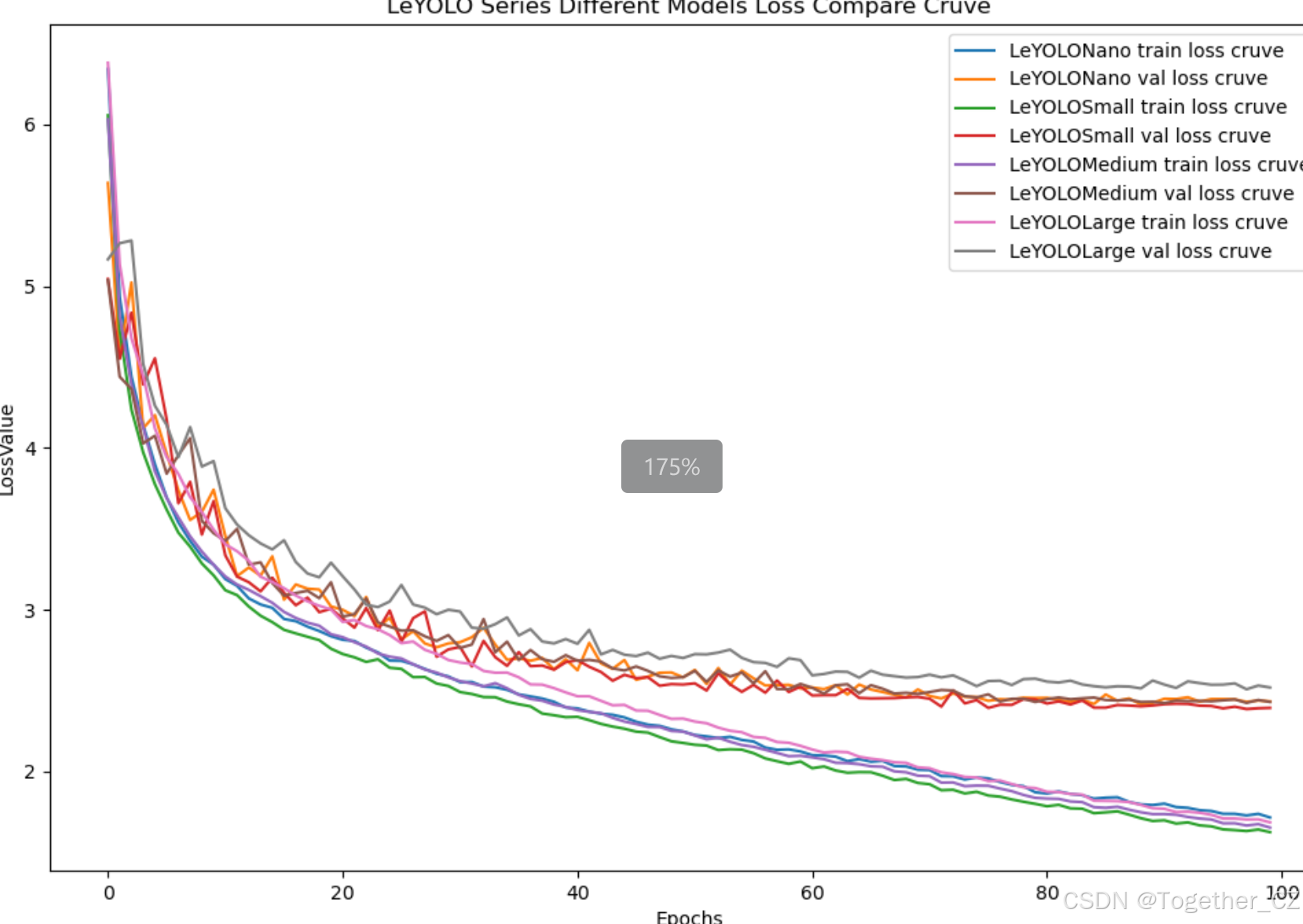
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
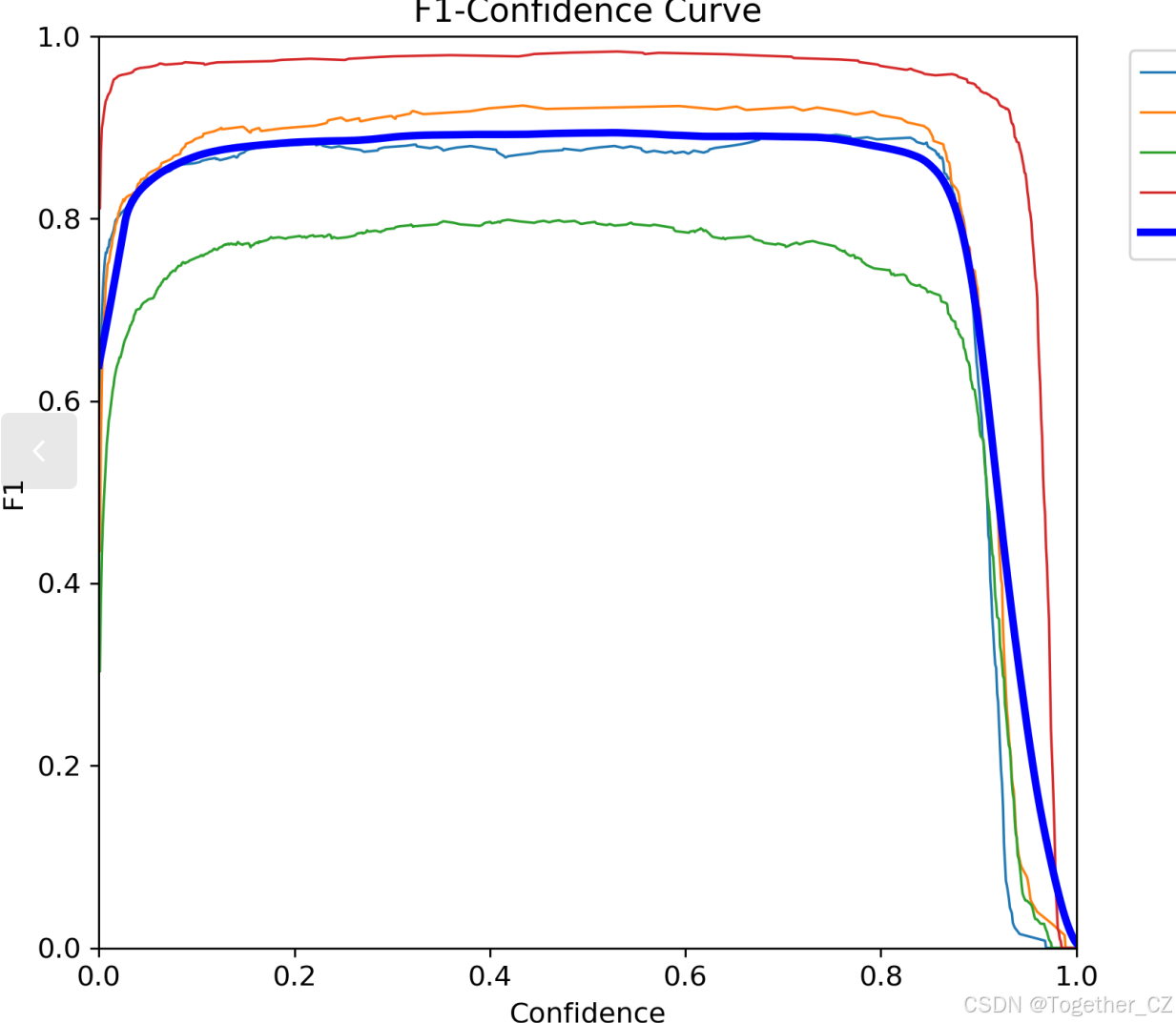
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。

整体对比分析来看:不难发现五款不同参数量级的模型最终达到了较为相似的结果,没有拉开非常大的差距,这里综合参数量考虑我们最终选定了s系列的模型来作为线上的推理计算模型。
接下来看下s系列模型的详细情况。
【离线推理实例】

【Batch实例】

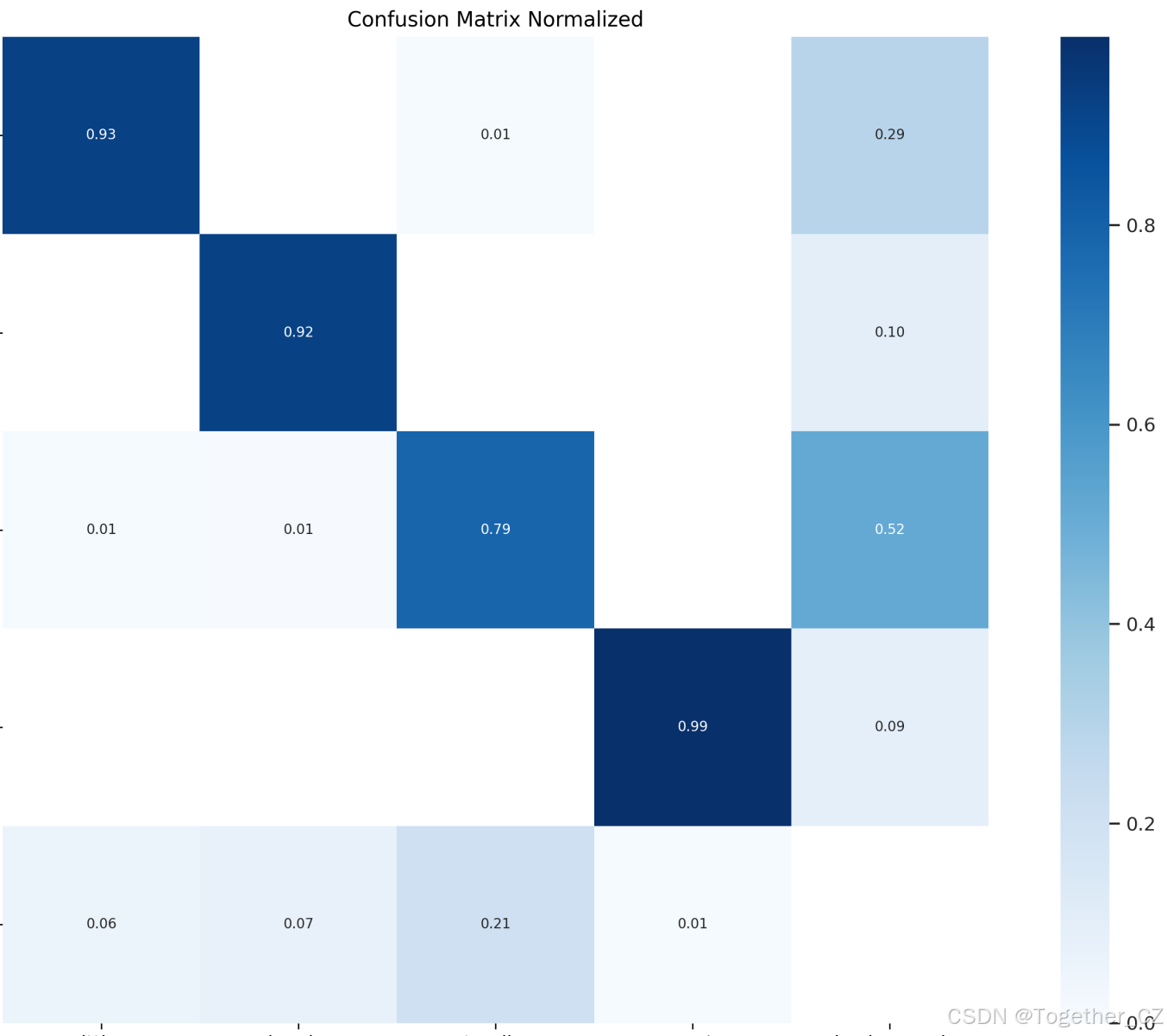
【混淆矩阵】
【F1值曲线】
【Precision曲线】
【PR曲线】
【Recall曲线】
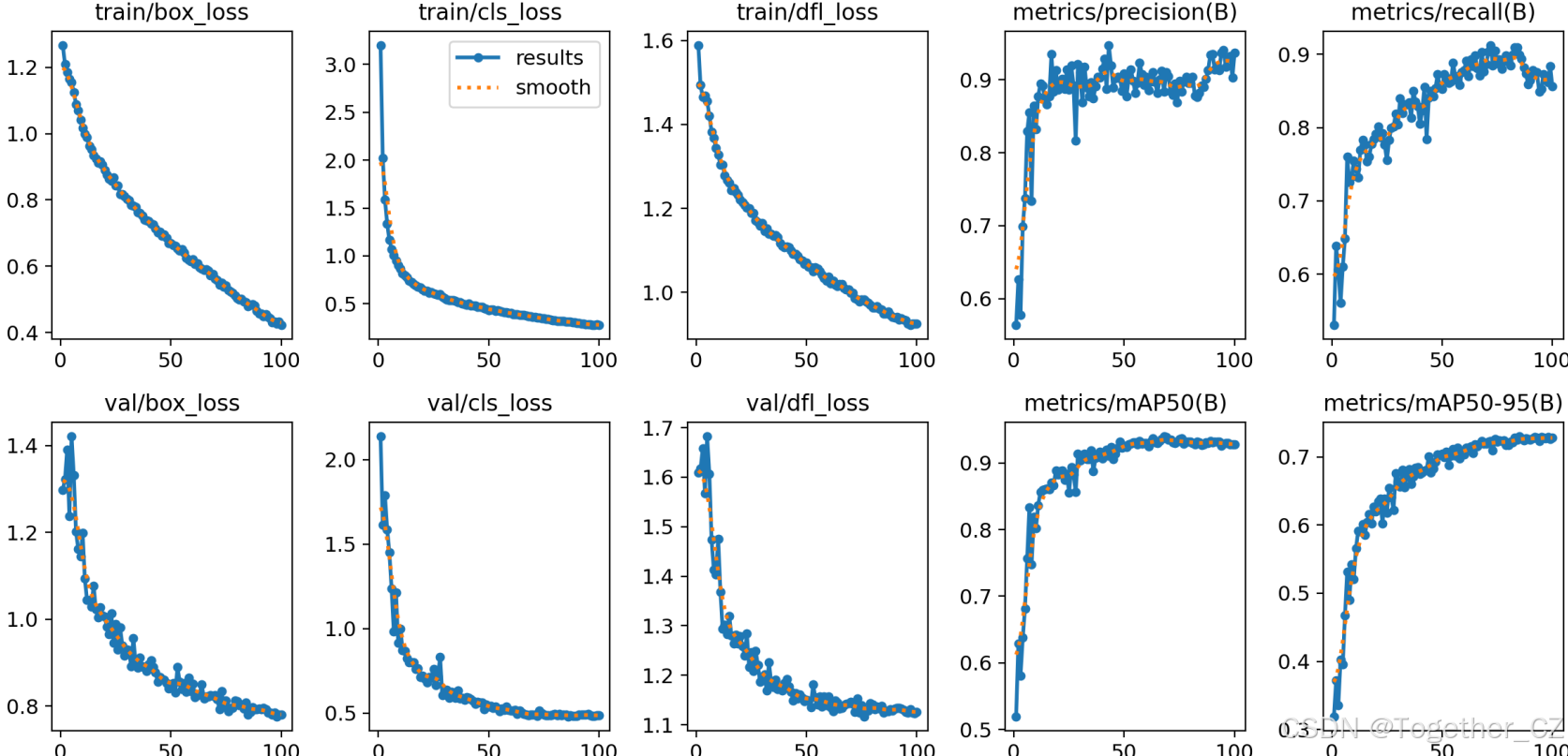
【训练可视化】
这种无人机+AI智能化模型的巡检方式,不仅提高了巡检的效率和准确性,还极大地降低了人力成本和安全风险。它不受天气、气象等客观因素的影响,能够实现全天候、实时的铁道线巡检管理,从而有效填补安全空隙,保障铁路运行的安全稳定。展望未来,随着技术的不断进步和应用的不断深化,无人机+AI智能化模型的巡检方式将在铁道安全巡检领域发挥更加重要的作用。它将成为我们打造交通强国、保障铁路安全的重要支撑和有力保障。让我们携手共进,共同推动这一技术的创新与发展,为中国的铁路事业贡献智慧和力量。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











