






这篇文章介绍了一个名为 BitNet b1.58 2B4T 的大规模语言模型(LLM),它是首个开源的、原生的 1 比特量化模型,参数规模达到 20 亿。该模型在 4 万亿标记的数据集上进行训练,并在多个基准测试中表现出色。以下是文章的主要研究内容总结:
1. 研究背景与动机
-
大规模语言模型(LLM)的挑战:现有的开源 LLM 在部署和推理时需要大量的计算资源,包括较大的内存占用、较高的能耗和显著的推理延迟。这使得它们在边缘设备、资源受限的环境和实时应用中难以使用。
-
1 比特模型的优势:通过将权重和激活量化为 1 比特({-1, 0, +1}),可以显著减少模型的内存占用,并提高计算效率,从而降低部署成本和能耗。
2. BitNet b1.58 2B4T 的架构与训练
-
架构设计:基于标准的 Transformer 模型,但用定制的 BitLinear 层 替换了全精度线性层。这些层通过以下方式实现高效计算:
-
权重量化:将权重量化为 1.58 比特(三元值 {-1, 0, +1})。
-
激活量化:将激活量化为 8 比特整数。
-
归一化:使用 subln 归一化以增强训练稳定性。
-
-
训练方法:BitNet b1.58 2B4T 的训练包括三个阶段:
-
预训练:在大规模数据集上进行预训练,以获得通用的语言能力和知识。
-
监督微调(SFT):使用多样化的指令遵循和对话数据集进行微调,以提高模型在特定任务上的表现。
-
直接偏好优化(DPO):通过偏好数据优化模型,使其生成的回应更符合人类期望。
-
3. 性能评估
-
基准测试:BitNet b1.58 2B4T 在多个基准测试中表现出色,涵盖语言理解、数学推理、编程能力、阅读理解和对话能力。
-
与其他模型的比较:
-
全精度模型:BitNet b1.58 2B4T 在性能上与类似规模的全精度模型相当,但内存占用和能耗显著降低。
-
后训练量化模型:与经过 INT4 量化的全精度模型相比,BitNet b1.58 2B4T 在保持更低内存占用的同时,性能更强。
-
其他 1 比特模型:BitNet b1.58 2B4T 在性能上超越了其他原生 1 比特模型和经过量化的大规模模型。
-
4. 推理实现
-
GPU 推理:开发了自定义的 CUDA 内核,专门用于高效执行 1.58 比特权重和 8 比特激活的矩阵乘法。
-
CPU 推理:开发了
bitnet.cpp库,提供针对 CPU 的优化推理实现,确保在资源受限的设备上也能高效运行。
5. 开源与贡献
-
模型权重:BitNet b1.58 2B4T 的模型权重已通过 Hugging Face 公开发布。
-
推理代码:提供了针对 GPU 和 CPU 的开源推理代码,以促进进一步研究和实际部署。
6. 未来研究方向
-
扩展模型规模:研究更大规模的 1 比特模型(如 70 亿、130 亿参数)的性能。
-
硬件优化:开发针对 1 比特计算的专用硬件加速器。
-
多语言和多模态能力:扩展模型以支持多种语言和多模态输入。
-
理论研究:深入研究 1 比特训练的理论基础,探索其学习动态和表征特性。
BitNet b1.58 2B4T 证明了在大规模语言模型中直接进行极端量化的可行性,并在保持高性能的同时显著降低了计算资源需求。该模型为在资源受限环境中部署强大的语言模型开辟了新的可能性,并为未来的研究和应用提供了坚实的基础。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:
官方项目地址在这里,如下所示:
摘要
我们介绍了 BitNet b1.58 2B4T,这是首个开源的、原生的 1 比特大规模语言模型(LLM),参数规模达到 20 亿。该模型在包含 4 万亿标记的语料库上进行训练,并在涵盖语言理解、数学推理、编程能力和对话能力的基准测试中进行了严格的评估。我们的结果表明,BitNet b1.58 2B4T 的性能与类似规模的领先开源全精度 LLM 相当,同时在计算效率方面具有显著优势,包括大幅降低的内存占用、能耗和解码延迟。为了促进进一步研究和应用,模型权重已通过 Hugging Face 发布,并提供了针对 GPU 和 CPU 架构的开源推理实现。
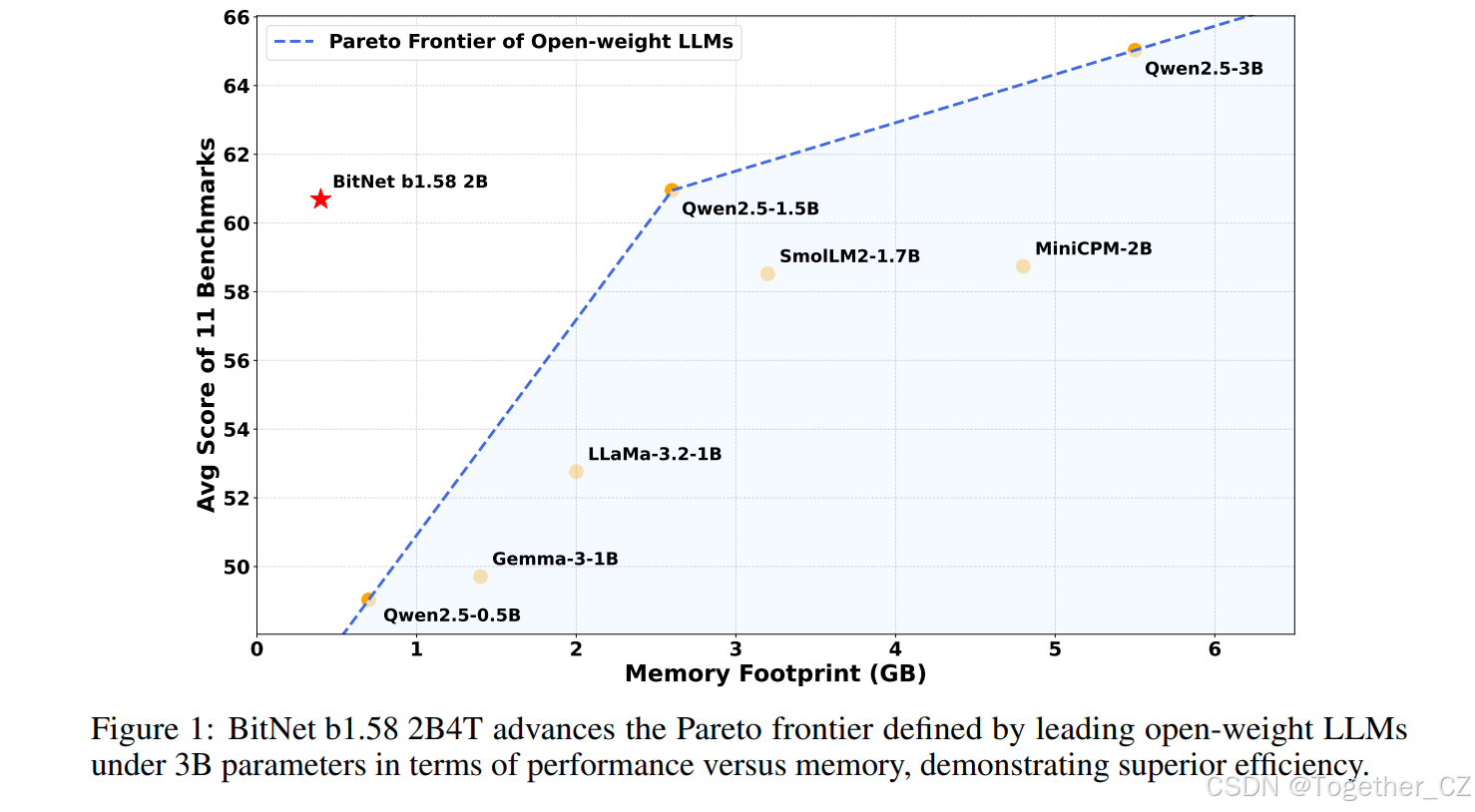
图 1:BitNet b1.58 2B4T 在 30 亿参数以下的开源权重 LLM 的性能与内存的帕累托前沿上取得了进展,展示了卓越的效率。
1 引言
开源的大规模语言模型(LLM)已成为推动先进人工智能能力普及、促进创新以及支持自然语言处理、代码生成和视觉计算等多领域研究的关键因素(Dubey 等人,2024;Yang 等人,2024;Bai 等人,2025)。它们的公开可用性使得广泛的实验和适配成为可能。然而,一个显著的障碍阻碍了它们的广泛应用:部署和推理所需的大量计算资源。现有的开源 LLM 通常需要较大的内存占用,消耗大量能源,并表现出显著的推理延迟,这使得它们在许多边缘设备、资源受限的环境和实时应用中不切实际。
1 比特 LLM 是一种极端但有前景的模型量化形式,其中权重(以及可能的激活)被限制为二进制 {-1, +1} 或三进制 {-1, 0, +1},为解决效率挑战提供了一种有吸引力的解决方案。通过大幅减少存储权重所需的内存,并启用高效的按位计算,它们有可能显著降低部署成本、减少能耗并加速推理速度。尽管此前已有关于 1 比特模型的研究,现有的开源工作通常分为两类:1)应用于预训练全精度模型的后训练量化(PTQ)方法,这可能导致显著的性能下降(Xu 等人,2024b;Team,2024);2)从头开始训练的原生 1 比特模型(例如 OLMo-Bitnet-1B<sup>2</sup>),这些模型的规模相对较小,可能尚未达到更大规模全精度模型的能力。这种性能差距限制了 1 比特 LLM 的实际影响。
为了弥合效率与性能之间的差距,我们推出了 BitNet b1.58 2B4T,这是首个开源的、原生的 1 比特 LLM,其参数规模达到 20 亿。该模型从头开始训练,训练数据集包含 4 万亿标记,并利用针对 1 比特范式的架构和训练创新。本研究的核心贡献在于证明,当在大规模上有效训练时,原生 1 比特 LLM 可以在广泛的任务中实现与类似规模的领先开源权重、全精度模型相当的性能。
本技术报告详细介绍了 BitNet b1.58 2B4T 的开发和评估。我们描述了架构和训练方法,并在标准基准测试中展示了全面的评估结果,这些基准测试评估了语言理解、数学推理、编程能力和多轮对话能力。我们的研究结果证实了其相对于已建立的全精度基线的强劲性能,同时具有显著的效率优势。最后,我们宣布通过 Hugging Face 公开发布 BitNet b1.58 2B4T 模型权重,并提供针对 GPU 和 CPU 执行优化的开源推理代码,旨在促进高效 LLM 的进一步研究和实际部署。
2 架构
BitNet b1.58 2B4T 的架构基于标准的 Transformer 模型(Vaswani 等人,2017),并根据 BitNet 框架(Wang 等人,2023a;Ma 等人,2024)进行了重大修改。该模型完全从头开始训练。
核心架构创新在于用定制的 BitLinear 层替换了标准的全精度线性层(torch.nn.Linear)。这是 BitNet 方法的基础。在这些 BitLinear 层中:
-
权重量化:在正向传播过程中,模型权重被量化为 1.58 比特。这是通过绝对均值(absmean)量化方案实现的,该方案将权重映射到三元值 {-1, 0, +1}。这大幅减少了模型大小,并启用了高效的数学运算。
-
激活量化:通过线性投影的激活被量化为 8 位整数。这采用了按标记应用的绝对最大值(absmax)量化策略。
-
归一化:我们引入了 subln 归一化(Wang 等人,2022),以进一步增强训练稳定性,这在量化训练环境中尤其有益。
除了 BitLinear 层之外,还整合了若干已建立的 LLM 技术,以增强性能和稳定性:
-
激活函数(FFN):在前馈网络(FFN)子层中,BitNet b1.58 2B4T 采用了平方 ReLU(ReLU2),而不是通常使用的 SwiGLU 激活(Shazeer,2020)。这一选择是基于其在 1 比特环境中改善模型稀疏性和计算特性的潜力(Wang 等人,2024b,a)。
-
位置嵌入:使用旋转位置嵌入(RoPE)(Su 等人,2024)注入位置信息,这是现代高性能 LLM 中的标准做法。
-
偏置移除:与 LLaMA 等架构一致,网络中的所有线性层和归一化层都移除了偏置项,减少了参数数量,并可能简化量化。
对于标记化,我们采用了为 LLaMA 3(Dubey 等人,2024)开发的标记器。该标记器实现了字节级的字节对编码(BPE)方案,词汇表大小为 128,256 个标记。这一选择确保了对多样化文本和代码的稳健处理,其广泛采用也便于与现有的开源工具和生态系统无缝集成。
3 训练
BitNet b1.58 2B4T 的训练过程包括三个不同的阶段:大规模预训练,随后是监督微调(SFT)和直接偏好优化(DPO)。尽管先进的技术如近端策略优化(PPO)或分组相对策略优化(GRPO)可以进一步增强数学和推理能力(Schulman 等人,2017;Shao 等人,2024),但当前版本的 BitNet b1.58 2B4T 仅依赖于预训练、SFT 和 DPO。探索强化学习方法是未来工作的方向。
3.1 预训练
预训练阶段旨在赋予模型广泛的通用知识和基础语言能力。我们借鉴了已建立的 LLM 实践中的通用训练策略(Dubey 等人,2024),并针对 1 比特架构进行了特定调整。
3.1.1 学习率调度
采用了两阶段学习率调度。
-
第一阶段(高学习率):初始阶段使用标准的余弦衰减调度,但以相对较高的峰值学习率开始。这一决定是基于观察到 1 比特模型通常比全精度模型具有更高的训练稳定性,允许更激进的初始学习步骤。
-
第二阶段(冷却):在计划的训练标记数量大约过半时,学习率突然衰减,随后通过具有显著较低峰值的余弦调度维持。这一“冷却”阶段允许模型在高质量数据上细化其表示(见第 3.1.3 节)。
3.1.2 权重衰减调度
与学习率调整相辅相成,实施了两阶段权重衰减策略。
-
第一阶段:在第一阶段,权重衰减遵循余弦调度,达到 0.1 的峰值。这种正则化有助于在初始高学习率阶段防止过拟合。
-
第二阶段:在第二阶段,权重衰减被有效禁用(设置为零)。这允许模型参数在较低学习率和策划数据的引导下,进入更精细的最优解。
3.1.3 预训练数据
预训练语料库包括公开可用的文本和代码数据集,包括大型网络爬取数据(如 DCLM(Li 等人,2024b))和教育网页(如 FineWeb-EDU(Penedo 等人,2024))。为了增强数学推理能力,我们还引入了合成生成的数学数据。数据展示策略与两阶段训练相一致:第一阶段处理大部分通用网络数据,而第二阶段冷却阶段则强调高质量策划数据集,与降低的学习率相吻合。
3.2 监督微调(SFT)
预训练完成后,模型接受了监督微调(SFT),以增强其遵循指令的能力,并提高其在对话交互格式中的表现。
3.2.1 SFT 数据
SFT 阶段使用了多种公开可用的遵循指令和对话数据集。这些数据集包括但不限于 WildChat(Zhao 等人,2024)、LMSYS-Chat1M(Zheng 等人,2024)、WizardLM Evol-Instruct(Xu 等人,2024a)和 SlimOrca(Lian 等人,2023)。为了进一步增强特定能力,特别是在推理和复杂指令遵循方面,我们补充了使用 GLAN(Li 等人,2024a)和 MathScale(Tang 等人,2024)等方法生成的合成数据集。
3.2.2 对话模板
在 SFT 和推理期间的对话任务中,采用以下对话模板结构:
<|begin_of_text|>System: {system_message}<|eot_id|> User: {user_message_1}<|eot_id|> Assistant: {assistant_message_1}<|eot_id|> User: {user_message_2}<|eot_id|> Assistant: {assistant_message_2}<|eot_id|>...
3.2.3 优化细节
在 SFT 期间,有几个关键的优化选择:
-
损失聚合:与在批次内对交叉熵损失进行平均(均值归约)不同,我们采用了求和。经验表明,对损失进行求和可以促进更好的收敛,并为该模型带来更好的最终性能。
-
超参数调整:对学习率和训练周期数量进行了仔细调整。与我们的预训练发现一致,1 比特模型在 SFT 期间从相对较高的学习率中受益,这与全精度模型的微调相比有所不同。此外,为了实现最佳收敛,需要将微调时间延长至比类似规模的全精度模型更多的训练周期。
3.3 直接偏好优化(DPO)
为了进一步使模型的行为与人类对有用性和安全性的偏好保持一致,我们在 SFT 阶段之后应用了直接偏好优化(DPO)(Rafailov 等人,2023)。DPO 为传统 RLHF 提供了一种高效的替代方案,通过直接使用偏好数据优化语言模型,从而避免了训练单独的奖励模型。这一 DPO 阶段旨在完善模型的对话能力,并使其在实际用例中与期望的互动模式更加一致。
3.3.1 训练数据
用于 DPO 训练的偏好数据集是通过组合公开资源构建的,这些资源被认为能够捕捉到人类对模型输出的多样化判断。具体来说,我们使用了 UltraFeedback(Cui 等人,2024)和 MagPie(Xu 等人,2024c)。这些数据集的聚合提供了强大且多维度的偏好信号,引导模型生成更符合人类期望的回应。
3.3.2 训练细节
DPO 训练阶段进行了 2 个周期。我们采用了 2×10<sup>−7</sup> 的学习率,并将 DPO 的 beta 参数(控制与参考策略的偏离程度)设置为 0.1。为了提高这一阶段的训练效率,我们整合了来自 Liger Kernel 库(Hsu 等人,2024)的优化内核。从定性观察来看,DPO 过程有效地引导模型朝着首选的回应风格发展,而没有显著降低在预训练和 SFT 阶段建立的核心能力。
4 评估
我们在多种基准测试中衡量性能,这些基准测试分为以下几类:
-
语言理解和推理:ARC-Easy(Yadav 等人,2019)、ARC-Challenge(Yadav 等人,2019)、HellaSwag(Zellers 等人,2019)、WinoGrande(Sakaguchi 等人,2020)、PIQA(Bisk 等人,2019)、OpenbookQA(Mihaylov 等人,2018)和 CommonsenseQA(Talmor 等人,2019)
-
世界知识:TruthfulQA(Lin 等人,2022)和 MMLU(Hendrycks 等人,2021a)
-
阅读理解:TriviaQA(Joshi 等人,2017)和 BoolQ(Clark 等人,2019)
-
数学和代码:GSM8K(Cobbe 等人,2021)、MATH-500(Hendrycks 等人,2021b)和 HumanEval+(Liu 等人,2023)
-
指令遵循和对话:IFEval(Zhou 等人,2023)和 MT-bench(Zheng 等人,2023)
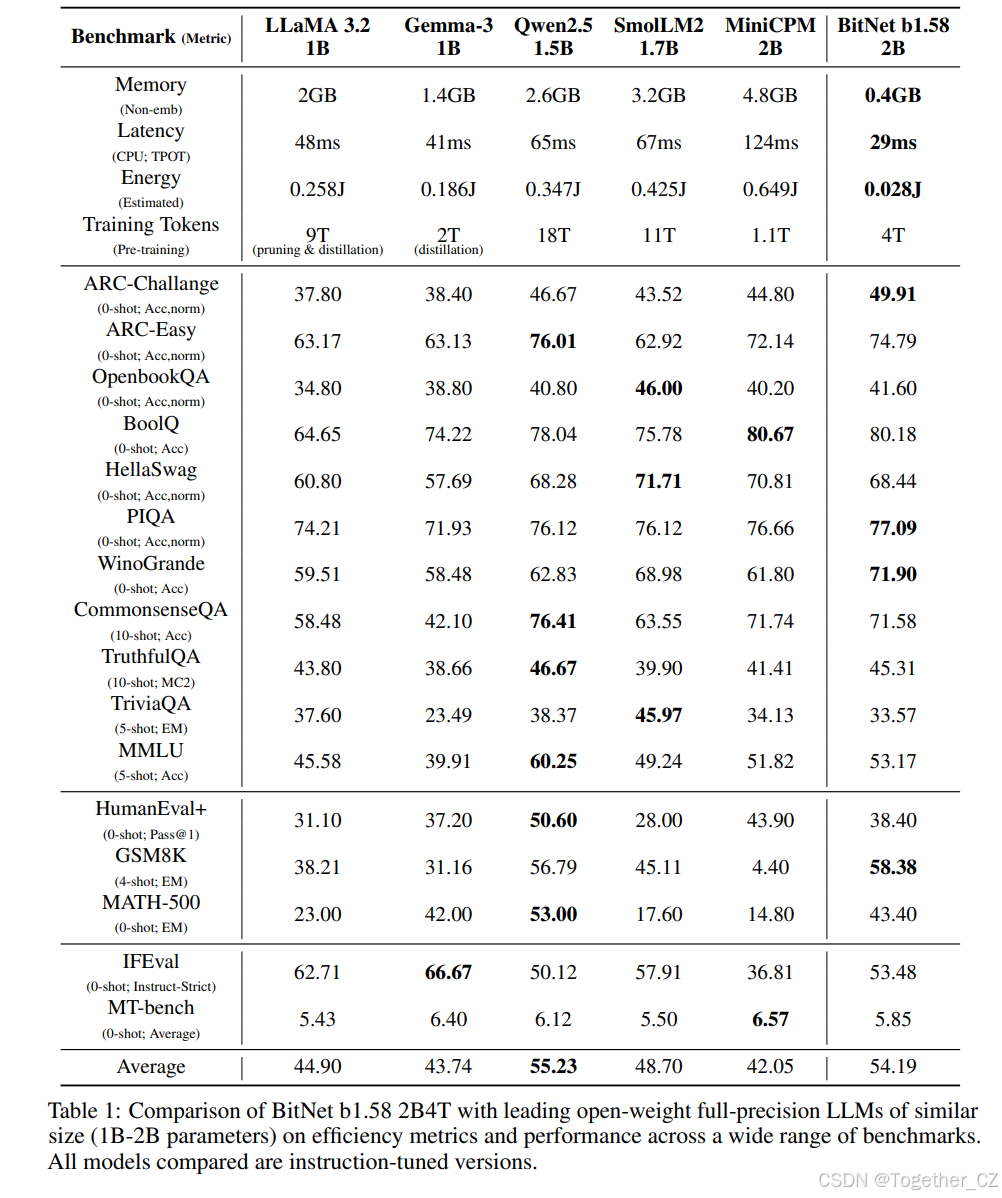
我们将 BitNet b1.58 2B4T 与类似规模的领先开源权重全精度 LLM 进行比较,包括 LLaMA 3.2 1B(Dubey 等人,2024)、Gemma-3 1B(Team 等人,2025)、Qwen2.5 1.5B(Yang 等人,2024)、SmolLM2 1.7B(Allal 等人,2025)和 MiniCPM 2B(Hu 等人,2024)。所有模型均为指令调优版本。我们使用公共评估流程重新运行所有基准测试,以确保公平比较。更多评估细节可在附录中找到。主要结果如表 1 所示。
4.1 主要结果
如表 1 所示,BitNet b1.58 2B4T 在资源效率方面表现出色。其非嵌入式内存占用和解码期间的估算能耗(Horowitz,2014;Zhang 等人,2022)显著低于所有评估的全精度模型,突显了在运营成本和在资源受限设备上部署能力方面的显著优势。
在任务性能方面,BitNet b1.58 2B4T 表现出极强的竞争力。它在涵盖推理、知识和数学能力的多个基准测试中取得了最佳结果。在其他基准测试中,其性能与表现最佳的全精度模型相当接近。尽管某些全精度模型在特定任务或整体平均值上表现出轻微优势,但 BitNet b1.58 2B4T 在各个领域均表现出色。结果表明,BitNet b1.58 2B4T 在实现与类似规模的领先模型相近的能力的同时,提供了显著改进的效率。
4.2 与后训练量化模型的比较
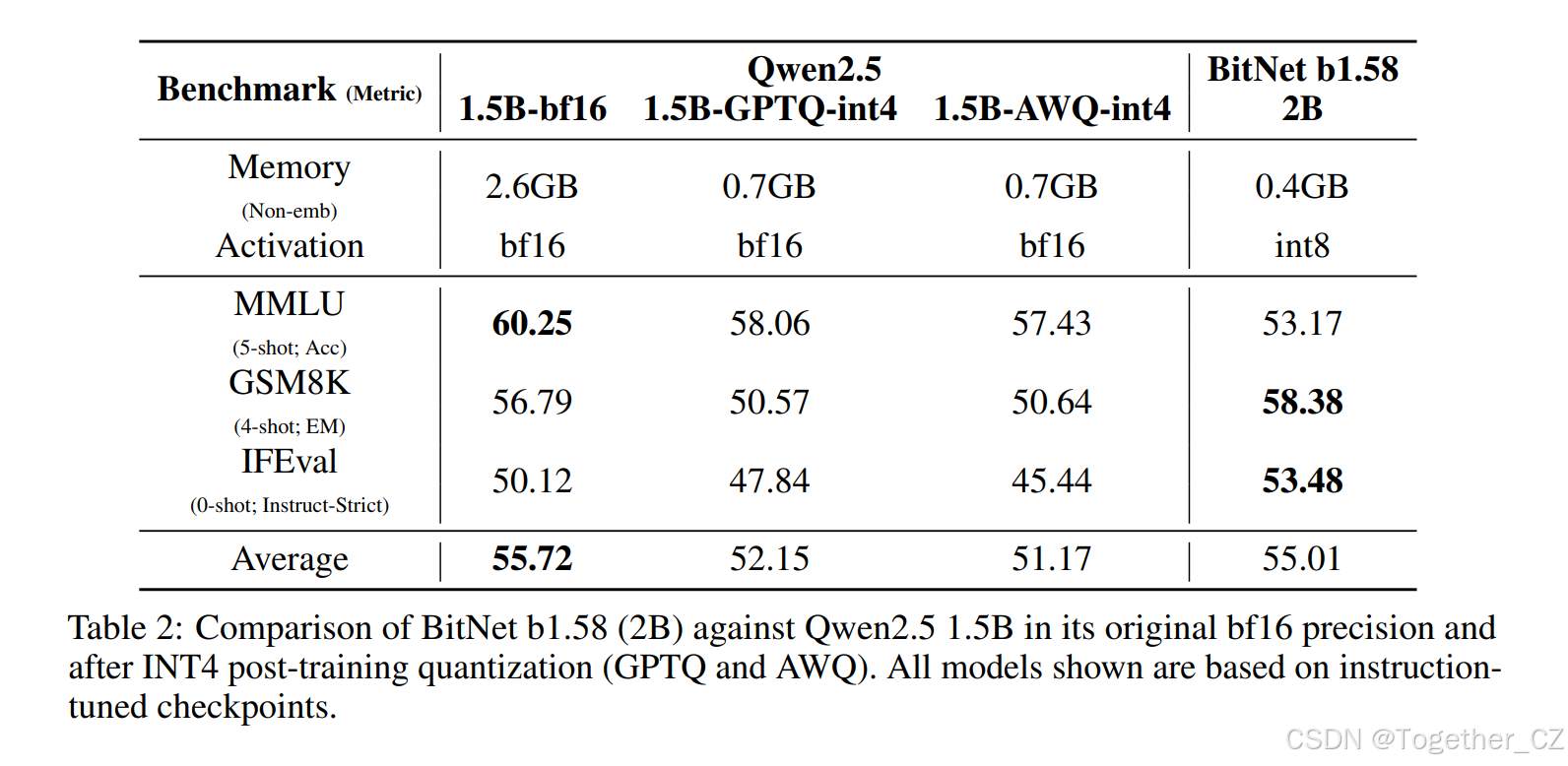
我们进一步通过将 BitNet b1.58 2B4T 与领先竞争对手 Qwen2.5 1.5B 的后训练量化(PTQ)版本进行比较,研究效率与性能之间的权衡,使用标准 INT4 方法(GPTQ 和 AWQ)。结果如表 2 所示。
虽然 INT4 量化成功地减少了全精度模型的内存占用,但由于其原生 1 比特架构,BitNet b1.58 2B4T 实现了更低的内存需求。更重要的是,这种卓越的内存效率并未以牺牲性能为代价。与量化模型相比,标准 PTQ 技术会导致与原始全精度模型相比的显著性能下降。相比之下,BitNet b1.58 2B4T 在评估的基准测试中保持了比 Qwen2.5-1.5B 的 INT4 量化版本更强的整体性能。这一比较表明,BitNet b1.58 2B4T 在效率 - 性能曲线上代表了一个比对现有架构应用传统 INT4 PTQ 更有利的点,提供了更低的资源使用和更好的性能。
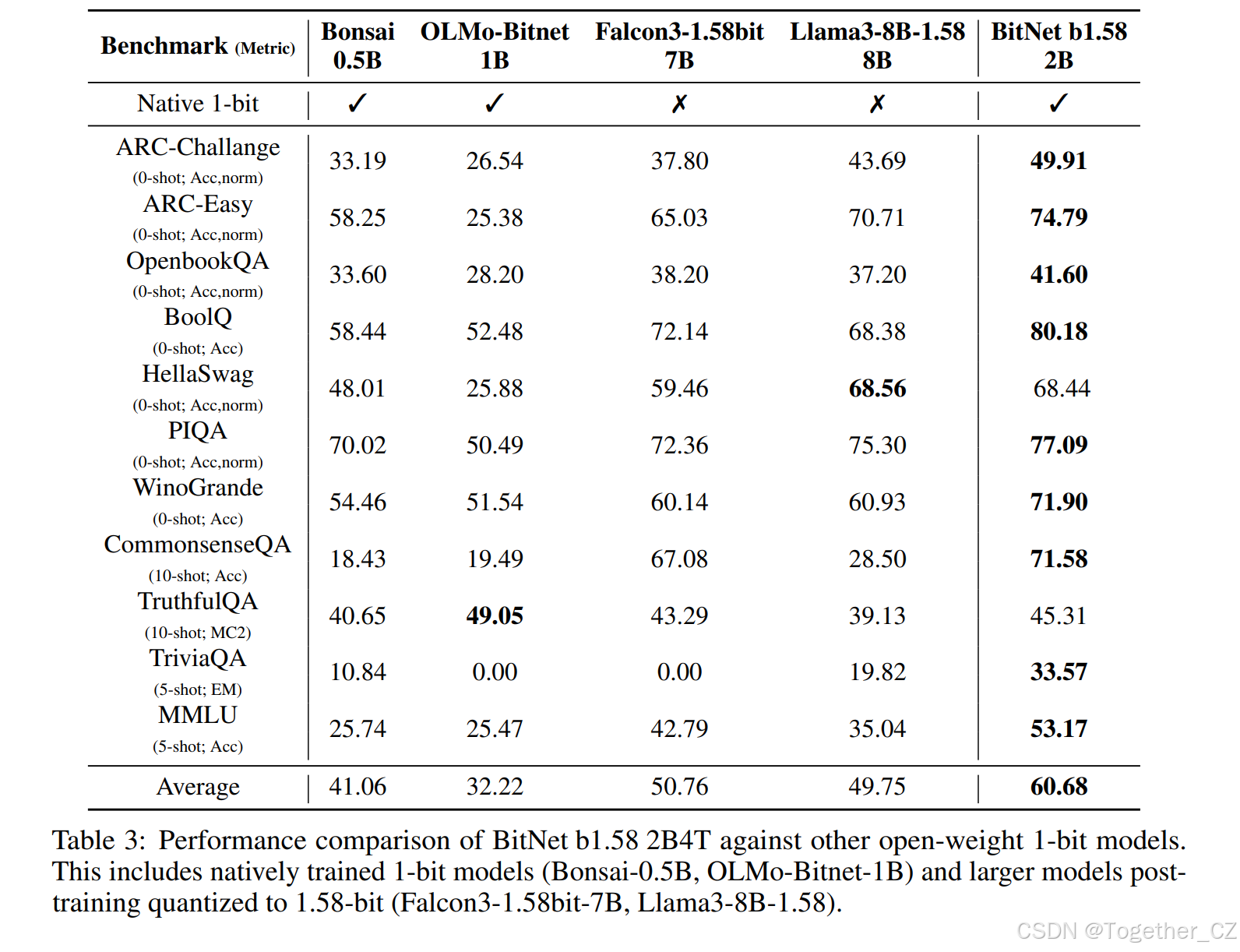
4.3 与开源权重 1 比特模型的比较
最后,我们将 BitNet b1.58 2B4T 置于其他设计用于或量化为接近 1 比特精度的模型的背景下进行比较。我们将其与较小规模的原生训练 1 比特模型以及大幅量化为 1.58 比特精度的更大模型进行了比较。比较结果如表 3 所示。
评估清楚地将 BitNet b1.58 2B4T 定位为这一类别的领先模型。它在大多数基准测试中均取得了最高分数,显著优于所有其他比较的 1 比特模型。值得注意的是,BitNet b1.58 2B4T 不仅大幅超越了其他较小的原生训练 1 比特模型,还超越了参数数量更多的大幅量化为 1 比特的模型。这一结果突显了 BitNet b1.58 2B4T 所采用的原生训练方法的有效性,使其在这一极端量化水平上为模型设定了新的最高性能水平,甚至超过了经过后训练量化的更大模型。
5 推理实现
对于大规模语言模型的部署,尤其是在资源受限的环境中,高效的推理至关重要。BitNet b1.58 2B4T 的独特量化方案,采用 1.58 比特权重和 8 比特激活(W1.58A8),需要专门的实现,因为标准深度学习库通常缺乏针对这种混合精度、低比特格式的优化内核。为了解决这一问题,我们开发并开源了针对 GPU 和 CPU 平台的专用推理库。代码可在 https://aka.ms/bitnet 公开获取。
5.1 GPU 推理
当前的 GPU 架构及其相关软件库(例如 cuBLAS、PyTorch 内核)主要针对标准数据类型(如 FP16、BF16 和 INT8/INT4)的操作进行优化。BitNet b1.58 2B4T 所需的特定 W1.58A8 矩阵乘法的原生高性能支持通常不可用。这一限制可能会阻碍 1 比特模型在现有硬件上实现理论效率提升。
为了实现高效的 GPU 推理,我们开发了一个专门用于 W1.58A8 矩阵乘法的自定义 CUDA 内核。由于三元权重({-1, 0, +1},表示 1.58 比特)无法使用标准数据类型高效存储,我们将多个权重值打包到一个 8 比特整数(“int8”)中,用于在高带宽存储器(HBM)中存储。具体来说,四个三元值被编码到一个“int8”值中。在计算过程中,CUDA 内核将打包的“int8”权重从 HBM 加载到 GPU 更快的片上共享存储器(SRAM)中。然后,它立即将这些值解包回适合高效三元计算的表示形式(例如,重建 -1、0、+1 值),然后与 8 比特激活进行矩阵乘法。这种“打包 - 存储 - 加载 - 解包 - 计算”策略最小化了内存带宽使用,同时利用了自定义计算指令。进一步的实现细节和优化策略在 Ladder 框架(Wang 等人,2023b)中有详细阐述。
尽管我们的自定义内核与简单实现相比显著提高了性能,但我们需要指出,当前的商用 GPU 架构并非为 1 比特模型进行了最优设计。我们相信,未来的硬件创新,可能包括针对低比特操作的专用逻辑,对于完全释放像 BitNet b1.58 这样的模型的性能和能源效率潜力至关重要。
5.2 CPU 推理
为了确保广泛的可访问性,并在缺乏强大 GPU 的设备上实现部署(例如边缘设备、笔记本电脑、标准服务器),我们开发了 bitnet.cpp。这个 C++ 库作为 1 比特 LLM 的官方参考实现,包括 BitNet b1.58,用于 CPU 推理。
bitnet.cpp 提供了针对标准 CPU 架构高效执行的优化内核。这些内核旨在与模型的特定量化方案高效配合,尽可能避免通用量化库或复杂的低级位操作的开销。它以与 BitNet b1.58 训练方法一致的方式处理权重元素,确保数值精度(与训练过程相对无损的推理)。
这种方法直接在 CPU 上快速准确地推理 1.58 比特模型。更多技术细节和使用说明可在 bitnet.cpp 仓库和相关技术报告(Wang 等人,2025)中找到。
6 结论
本技术报告介绍了 BitNet b1.58 2B4T,这是朝着高效且功能强大的大规模语言模型迈出的重要一步。作为首个开源的、原生的 1 比特 LLM,其参数规模达到 20 亿,并在 4 万亿标记的数据集上进行训练,我们的工作证明了在训练过程中直接进行极端量化的可行性。
在涵盖语言理解、推理、数学、编程和对话的基准测试中进行的全面评估表明,BitNet b1.58 2B4T 的性能与类似规模的领先开源权重、全精度模型相当。至关重要的是,这种性能相当性是在显著降低的计算要求下实现的,提供了显著的内存占用、能耗和推理延迟节省。为了促进实际使用和进一步研究,我们开发并发布了针对 GPU(通过自定义 CUDA 内核)和 CPU(通过“bitnet.cpp”库)的优化推理实现,以及可在 Hugging Face 上获取的模型权重。
BitNet b1.58 2B4T 提供了一个引人注目的概念证明,挑战了在大规模 LLM 中实现高性能所需的全精度权重的必要性。它为在以前模型受限的资源受限环境中部署强大的语言模型开辟了道路,可能使先进的人工智能能力更加普及。
7 未来方向
尽管 BitNet b1.58 2B4T 展示了有希望的结果,但仍有许多令人兴奋的研究方向:
-
扩展定律和更大模型:研究原生 1 比特 LLM 的扩展特性至关重要。未来的研究将探索训练更大规模的模型(例如 70 亿、130 亿参数及以上)以及在更大数据集上进行训练,以了解与全精度模型的性能相当性是否仍然成立。
-
硬件协同设计和优化:1 比特模型的全部潜力可能受到当前硬件限制的阻碍。需要继续为现有硬件(GPU、CPU、NPU)开发高度优化的内核。此外,为 1 比特计算和数据移动专门优化的未来硬件加速器的协同设计可能会释放出速度和能源效率的几个数量级的提升。
-
扩展序列长度:扩展 BitNet b1.58 2B4T 能够处理的最大序列长度至关重要。这一增强对于需要长上下文理解的任务至关重要,例如总结长篇文档或进行复杂问题解决,对于提高长链推理任务的表现尤为关键。探索适合低比特模型的长序列长度的高效注意力机制将是关键。
-
多语言能力:当前模型主要在以英语为中心的数据上进行训练。扩展预训练语料库并可能调整架构以有效支持多种语言是实现更广泛应用的关键方向。
-
多模态集成:探索将 1 比特原理集成到多模态架构中是另一个有前途的前沿领域。开发在低比特框架内高效处理和融合来自不同模态(例如文本和图像)信息的方法,可能会开启新的应用领域。
-
理论理解:深入研究 1 比特训练在大规模上的有效性背后的理论基础仍然是一个开放领域。分析这些模型的学习动态、损失景观和表征特性可能会为未来发展提供宝贵的见解。
通过追求这些方向,我们旨在进一步推进 1 比特 LLM 的能力和效率,为更可持续和更易于获取的人工智能铺平道路。BitNet b1.58 2B4T 及其相关工具的开源发布为社区提供了在此基础上进一步努力的基础。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











