







这里写目录标题
groupby()
df.groupby(["字段名1","字段名2"])该方法将会根据括号内字段名进行分组,返回DataFrameGroupBy类型,输出不了,必须进行聚合操作才能变为DataFrame类型。通常我们也是将groupby()和agg()聚合函数一起使用。
data = pd.read_csv('data/ex2data1.txt',names=['exam1','exam2','accept'])
suc = data.groupby(['accept'])
print(type(suc))
>>><class 'pandas.core.groupby.DataFrameGroupBy'>
使用agg()聚合函数之前,我们要明确是对分类后的一列数据进行操作,还是多列数据。
agg()
单列
只对单列数据进行操作时,不用使用agg()函数,直接在该列上进行操作即可,但是返回的数据类型是:<class ‘pandas.core.series.Series’>,而且对于此时的数据不能使用unstack(),因为此时返回的Seriers只有一列行索引>>>accept,不能使用unstack()进行反转。
data = pd.read_csv('data/ex2data1.txt',names=['exam1','exam2','accept'])
#只对exam1字段进行操作
suc = data.groupby(['accept'])['exam1'].sum()
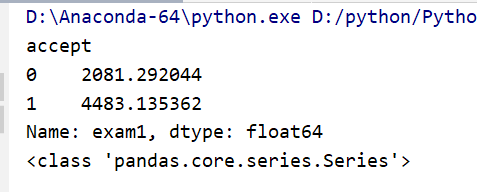
聚合单列,对单列多操作
我们对单列数据的操作往往不止sum(),可能还有其他操作,此时再对单列数据进行直接操作就不行了。这时就要用agg()了。
suc = data.groupby(['accept'])['exam1'].agg([sum,np.average,np.var])
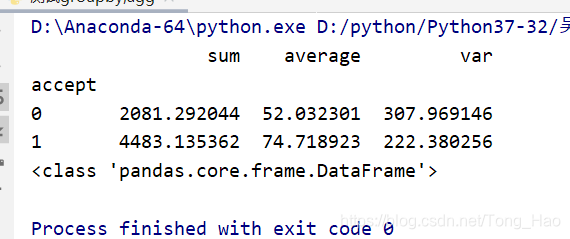
agg([fun1,fun2,fun3])多个方法的索引放在括号里的列表中,并且使用agg后放回数据的类型也是DataFrame。
但一般来说,这样的列名不是我们想要的,我们可以在完成聚合函数后修改列名。
suc.columns = ["总分","平均分","方差"]
聚合单列,对多列操作
要实现的目标是使用groupby()对单列进行聚合分类,同时再对多列进行不同的操作。
suc = data.groupby(['accept']).agg({"exam1":sum,"exam2":sum})
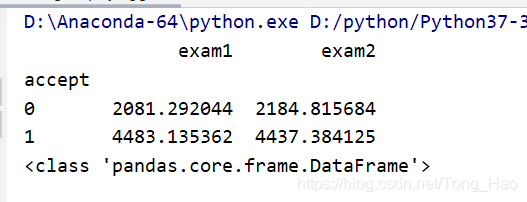
相比于之前对单列的操作,对多列的操作不需要再在聚合分类后选中某列:
| 单列 | 多列 |
|---|---|
| data.groupby([‘accept’])[‘exam1’].agg… | data.groupby([‘accept’]).agg… |
| centered 文本居中 | right-aligned 文本居右 |
使用了agg的另一种表达方式,agg({"字段1":fun1,"字段2":fun2})需要说明的是字段1,2必须真正是数据中的字段名,不能自定义,否则系统不知道你在对那一列进行操作。
dataframe按照某列排序>>sort_values()
对DataFrame数据进行排序,用到了sort_values,by参数可以指定根据哪一列数据进行排序,ascending是设置升序和降序(选择多列或者多行排序要加[ ],把选择的行列转换为列表,排序方式也可以同样的操作)。
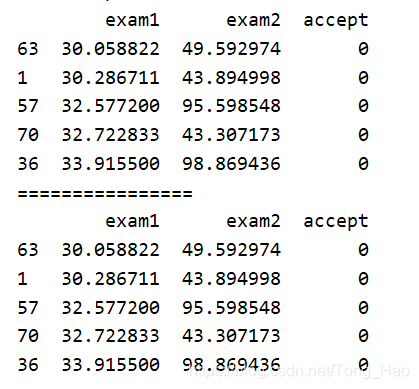
data_sort = data.sort_values('exam1')
data_sort2 = data.sort_values(['exam1','exam2'])
print(data_sort.head(5),"\n================")
print(data_sort2.head(5))
<ndarray>.reshape(\d+,\d+)
数据:第二章逻辑回归_分类问题;第一题;ex2data1.txt
这个方法是在不改变数据内容的情况下,改变一个数组的格式,便于后面的计算
def predit(X,theta,y):
df = sigmoid(np.dot(X, theta))
return [1 if x>=0.5 else 0 for x in df]
y_ = np.array(predit(X,theta_final,y))
print(np.shape(y_))
y_pre = y_.reshape(len(y_),1)
print(np.shape(y_pre ))
>>>(100,)
>>>(100,1)
np.mean()
数据:同上
np.mean()方法的作用有很多,这里的应用场景是,在分类问题的预测部分,预测两个矩阵的值相同率,通常用于最后的预测率计算。
print(np.mean(y_pre == y))
>>>0.89
np.insert()
对DataFrame数据进行列的增加使用df.insert,对行的增加使用df.append() ; df.iloc[len(+1)],而对于一个矩阵,我想要插入一行元素到原矩阵中的某一行或者某一列是完全可以实现的。
numpy.insert(arr, pos, values, axis)
其中
- arr是需要的插入元素的矩阵
- pos插入的位置下标从0开始,序号为0,1,2,3,4,5···
- values是插入的值,可以指定值如[1,2,3,4],或者写values = 0(全为0)
- axis是选择插入的是行还是列。0-行,1-列
newarray = np.insert(arr, pos, values, axis)
需要赋值过去,而不是在原来的数据上直接修改。
np.meshgrid()
在逻辑回归_分类问题中的第二题,该题目线性不可分,最后的决策边界可视化部分用到了这个函数,好像是绘制等高线,但是只绘制高度为0的那条线。
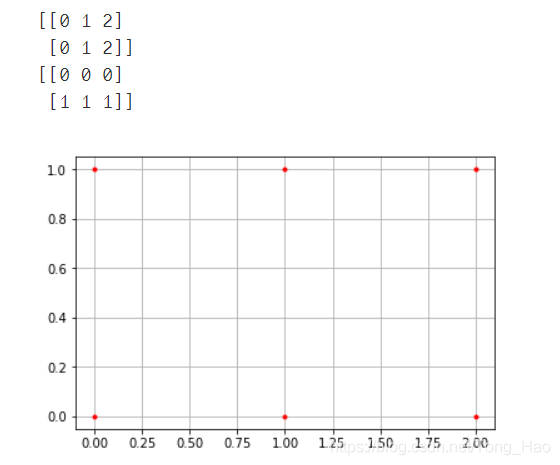
语法:X,Y = numpy.meshgrid(x, y)
输入的x,y,就是网格点的横纵坐标列向量(非矩阵)
输出的X,Y,就是坐标矩阵。
x = np.array([0, 1, 2])
y = np.array([0, 1])
X, Y = np.meshgrid(x, y)
print(X)
print(Y)
plt.plot(X, Y,
color='red', # 全部点设置为红色
marker='.', # 点的形状为圆点
linestyle='') # 线型为空,也即点与点之间不用线连接
plt.grid(True)
plt.show()
np.ravel()
数组扁平化,拉伸数组为向量
https://www.cnblogs.com/mzct123/p/8659193.html
plt.contour
在逻辑回归_分类问题中的第二题,该题目线性不可分,最后的决策边界可视化部分的画图代码,
plt.contour([X, Y,] Z, [levels], ** kwargs)绘制轮廓。
参数:
- X,Y : array-like,可选值Z的坐标。X和Y必须都是2-D,且形状与Z相同(这个地方坑了好长时间,画图之前shape一下看看xx,yy,zz),或者它们必须都是1-d,这样len(X)== M是Z中的列数,len(Y)== N是Z中的行数。
- Z : array-like(N,M)绘制轮廓的高度值。
- levels: 没用过
- kwargs: 盲猜高度,如果是0,则只画出高度为0的那条线
x = np.linspace(-1.2,1.2,200)
xx,yy = np.meshgrid(x,x)
z = features_mapping(xx.ravel(),yy.ravel(),6).values
zz = np.dot(z,theta_final).reshape(xx.shape)
#xx,yy,zz 的形状一定要一样
plt.contour(xx,yy,zz,0)
array.flatten()
flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组。
flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用!。
a.flatten():a是个数组,a.flatten()就是把a降到一维,默认是按行的方向降 。
a = np.array([[1,3],[2,4],[3,5]])
b = a.flatten()
b.shape
>>> (6,)
**注意:**该方法需要复制,不是在原数组上进行修改
np.argmax(array,axis=)
确定数组中的最大元素位置
https://blog.csdn.net/weixin_42755982/article/details/104542538
讲的很棒!
我猜测,当axis为空时,他会将数组一行一行首位合并成一个大数组,然后去确定最大值所在位置。
arr = np.array([[12,33,55],
[22,53,98]])
np.argmax(arr) #结果是5
>>> 5
#他会把arr变成[12,33,55,22,53,98]然后去寻找最大值98所在位置,就是5
将datafrmae或series转换整列转换为list>>df[‘a’].values.tolist()
# 方法1df['a'].values.tolist()
# 方法2df['a'].tolist()
Pandas列表类型饼状图
https://blog.csdn.net/kevinelstri/article/details/52685772
https://blog.csdn.net/guduruyu/article/details/78034676?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-6.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-6.not_use_machine_learn_pai
datafrmae直接饼状图
https://blog.csdn.net/gezigezao/article/details/103654509














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









