







在开始之前先日常介绍一波 Jsoup:
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup的主要功能如下:
1. 从一个URL,文件或字符串中解析HTML;
2. 使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;
jsoup是基于MIT协议发布的,可放心使用于商业项目。
今天演示的只是简单从首页爬取用户的用户名和头像及主要content。
先看下简单的代码:
public class MainActivity extends AppCompatActivity {
private static final String TAG = "MainActivity" ;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView getdata = (TextView) findViewById(R.id.getdata);
getdata.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
new Thread(new Runnable() {
@Override
public void run() {
try {
// Document doc = Jsoup.connect("http://www.qiushibaike.com/8hr/page/1/").get();
Document mozilla = Jsoup.connect("http://www.qiushibaike.com/8hr/page/1/")
.userAgent("Mozilla")
.timeout(3000)
.post();
Elements select1 = mozilla.select("div.author.clearfix");
for (Element element : select1) {
Document parse = Jsoup.parse(element.toString());
Elements select = parse.select("a h2");
Elements select2 = parse.select("a img");
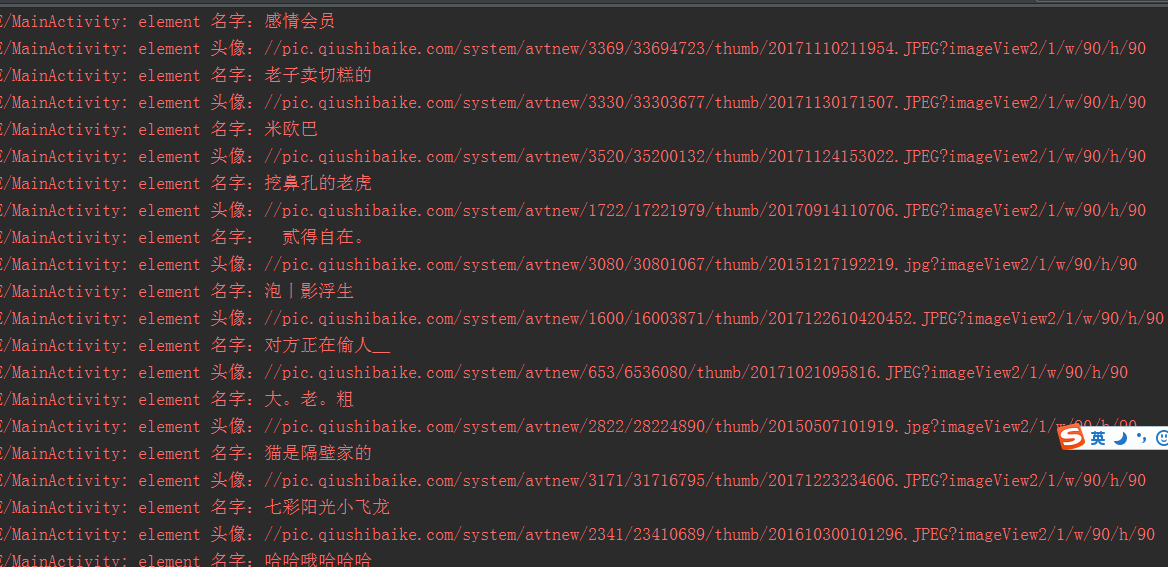
Log.e(TAG,"element 名字:"+select.text());
Log.e(TAG,"element 头像:"+select2.attr("src"));
}
Elements select = mozilla.select("a.contentHerf");
for (Element element : select) {
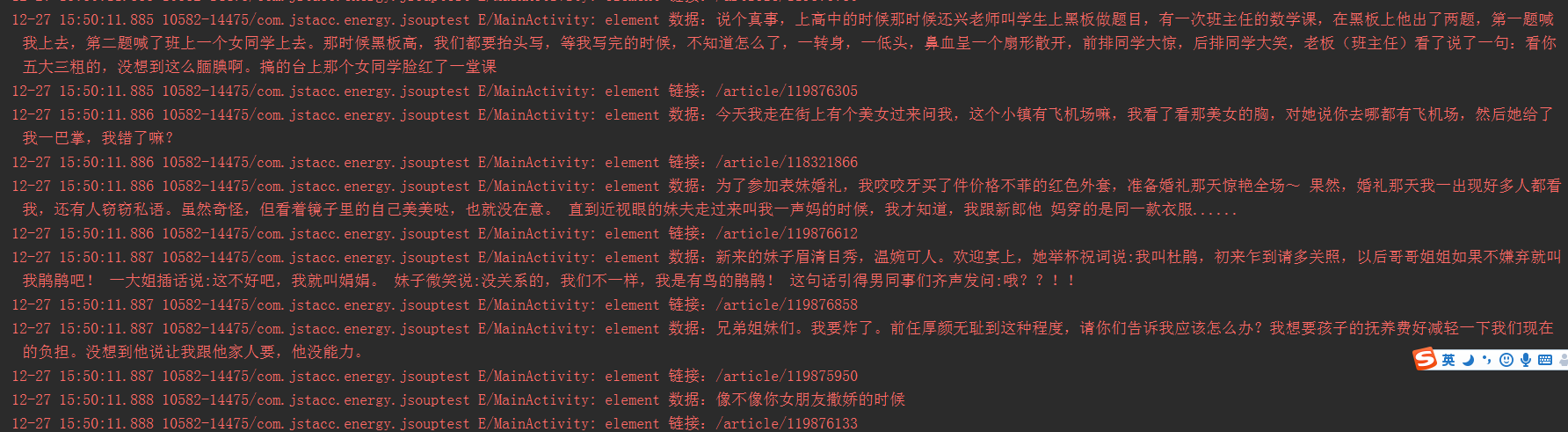
Log.e(TAG,"element 数据:"+element.text());//element.text()得到标签对应的文本内容
Log.e(TAG,"element 链接:"+element.attr("href"));//element.text()得到标签对应的文本内容
}
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
});
}
}
我们看下代码
jsoup 可以从包括字符串、URL地址以及本地文件来加载HTML 文档,并生成Document 对象实例。
jsoup 有两种方式可以生成:get()和post()
get()方法是上面的:
Document doc = Jsoup.connect("http://www.qiushibaike.com/8hr/page/1/").get();
post()是:
Document mozilla = Jsoup.connect("http://www.qiushibaike.com/8hr/page/1/")
.userAgent("Mozilla")
.timeout(3000)
.post();
userAgent("Mozilla");此方法是设置用户代理(请求头的东西,可以判断你是PC还是Mobile端)
timeout(3000);设置超时时间
得到 Document 之后我们就可以开始根据页面的节点进行解析了。我们用浏览器打开上面的url,然后按F12进行html页面源码查看。如图所示:
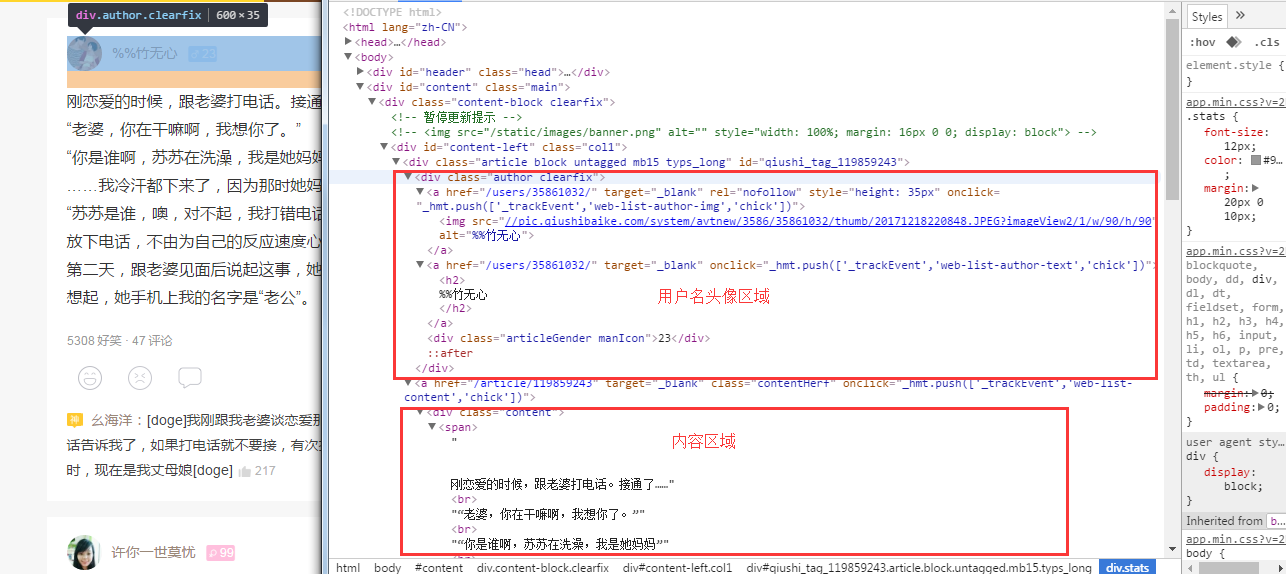
我们今天只是简单讲解抓取用户头像用户名和内容。我们根据上图可以看到,我们所要的用户头像信息在div-class为 author.clearfix里面,这样我们就好办了:
Elements select1 = mozilla.select("div.author.clearfix");
for (Element element : select1) {
Document parse = Jsoup.parse(element.toString());
Elements select = parse.select("a h2");
Elements select2 = parse.select("a img");
Log.e(TAG,"element 名字:"+select.text());
Log.e(TAG,"element 头像:"+select2.attr("src"));
}因为我们在页面源码发现用户名节点下就只有用户名的字符串,所以我们直接调用Element对象的text()方法即可,此方法是指得到该Element下所有字符信息。
接下来就是我们的图片地址,我们已经得到图片地址的Element,但是我们真正需要的地址则在 Img 节点 的 src 参数属性下面,所以我们还需要调用图片Element下的attr("src")方法来得到头像真正的图片地址。
用户头像和用户名读取完毕,我们接下来就只剩下内容的抓取了,我们在上面的图可以发现,内容包含在div-class 为content里面,如果我们只有内容的话我们可以直接Elements select = mozilla.select("div.content");得到每个content下Element集合,然后循环element.text(),这样我们就可以直接得到每一条的内容,但是我们单单内容还不够,我们还需要该条目的详情链接,这样我们就不能直接mozilla.select("div.content")了,而是需要
到上一层:a节点class为contentHerf的这一层,这一层我们可以解析到详情链接和content,我们看下代码:
Elements select = mozilla.select("a.contentHerf");
for (Element element : select) {
Log.e(TAG,"element 数据:"+element.text());//element.text()得到标签对应的文本内容
Log.e(TAG,"element 链接:"+element.attr("href"));
}到这里,我们已经可以得到页面上我们想要的数据了,当然,我们可以抓更多详细的信息。看下log.















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









