






近年来,随着互联网的发展,越来越多的数据以网页的形式存在于各个网站上。对于数据分析师、研究员或者仅仅是对数据感兴趣的人来说,如何高效地提取和分析网页数据成为了一项重要的技能。Python作为一门强大的编程语言,通过其丰富的库和强大的数据处理能力,成为了爬虫的首选工具。在本文中,我将向大家介绍Python爬虫的实战技巧,帮助大家掌握网页数据的提取和分析。
在开始之前,我们先来了解一下Python爬虫的基础知识。Python爬虫是一种自动化的程序,用于从互联网上抓取数据。爬虫可以模拟人的行为,通过发送HTTP请求获取网页的HTML源码,进而解析和提取有用的数据。相比手动复制粘贴,使用爬虫可以极大地提高数据获取的效率。
爬虫的工作流程
爬虫的工作流程可以概括为以下几个步骤:
-
发送HTTP请求:爬虫首先需要构造一个合法的URL,并发送HTTP请求到目标网站。
-
获取HTML源码:目标网站收到请求后,会返回一个HTML文件,爬虫需要将这个文件保存下来。
-
解析HTML文件:爬虫需要从HTML文件中提取有用的信息,比如链接、文本等。
-
存储数据:爬虫需要将提取到的数据存储起来,可以是保存到本地文件或者数据库中。
-
循环操作:爬虫需要对多个网页进行重复的操作,直到完成数据的获取。
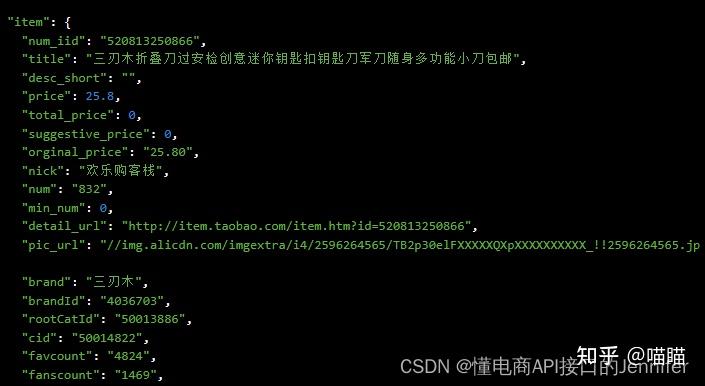
淘宝商品详情爬虫API:item_get 传入商品id获取该商品详情页的数据。

编辑
item_get响应参数
Version: Date:2022-04-04
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| item | item[] | 1 | 宝贝详情数据 | |
| num_iid | Bigint | 1 | 520813250866 | 宝贝ID |
| title | String | 1 | 三刃木折叠刀过安检创意迷你钥匙扣钥匙刀军刀随身多功能小刀包邮 | 宝贝标题 |
| desc_short | String | 0 | 商品简介 | |
| promotion_price | Int | 0 | 优惠价 | |
| price | Float | 1 | 25.8 | 价格 |
| total_price | Float | 0 | 0 | |
| suggestive_price | Float | 0 | 0 | |
| orginal_price | String | 0 | 25.80 | 原价 |
| nick | String | 0 | 欢乐购客栈 | 掌柜昵称 |
| num | Int | 0 | 3836 | 库存(没有精确,是模糊值) |
| min_num | Int | 0 | 0 | 最小购买数 |
| detail_url | String | 0 | http://item.taobao.com/item.htm?id=520813250866 | 宝贝链接 |
| pic_url | String | 1 | //http://gd2.alicdn.com/imgextra/i4/2596264565/TB2p30elFXXXXXQXpXXXXXXXXXX_!!2596264565.jpg | 宝贝图片 |
| brand | String | 0 | 三刃木 | 品牌名称 |
| brandId | Int | 0 | 8879363 | 品牌ID |
| rootCatId | Int | 0 | 50013886 | 顶级分类ID |
| cid | Int | 1 | 50014822 | |
| crumbs | Mix | 0 | [] | 导航菜单 |
| created_time | String | 0 | ||
| modified_time | String | 0 | ||
| delist_time | String | 0 | ||
| desc | String | 0 | 商品详情 | |
| desc_img | Mix | 0 | [] | 商品详情图片 |
| item_imgs | Mix | 0 | item_imgs[] | 商品图片 |
| item_weight | String | 0 | ||
| item_size | String | 0 | ||
| location | String | 0 | 发货地 | |
| express_fee | Float | 0 | 0.00 | 快递费用 |
| ems_fee | Float | 0 | EMS费用 | |
| post_fee | Float | 0 | 物流费用 | |
| shipping_to | String | 0 | 发货至 | |
| has_discount | Boolean | 0 | false | 是否有优惠 |
| video | video[] | 0 | 商品视频 | |
| is_virtual | String | 0 | ||
| is_promotion | Boolean | 0 | false | 是否促销 |
| props_name | String | 0 | 1627207:1347647754:颜色分类:长方形带开瓶器+送工具刀卡+链子;1627207:1347647753:颜色分类:椭圆形带开瓶器+送工具刀卡+链子; | 商品属性名。格式为pid1:vid1:name1:value1;pid1:vid2:name2:value2。 |
| prop_imgs | prop_imgs[] | 0 | 商品属性图片列表 | |
| property_alias | String | 0 | 20509:9974422:36;1627207:28326:红色;20509:9975710:38;1627207:28326:红色;20509:9981357:40;1627207:28326:红色 | 销售属性值别名。格式为pid1:vid1:alias1;pid1:vid2:alia2。 |
| props | Mix | 0 | [{ “name”: “产地”,“value”: “中国” }] | 商品属性 |
| total_sold | Int | 0 | ||
| skus | skus[] | 0 | 商品规格信息列表 | |
| seller_id | Int | 0 | 2844096782 | 卖家ID |
| sales | Int | 0 | 138 | 销量 |
| shop_id | Int | 0 | 151372205 | 店铺ID |
| props_list | Mix | 0 | {20509:9974422: 尺码:36} | 商品属性 |
| seller_info | seller_info[] | 1 | 卖家信息 | |
| tmall | Boolean | 0 | false | 是否天猫 |
| error | String | 0 | 错误信息 | |
| warning | String | 0 | 警告信息 | |
| url_log | Mix | 0 | [] | |
| favcount | Int | 0 | 0 | |
| fanscount | Int | 0 | 0 | |
| method | String | 0 | item_tmall:pget_item | |
| promo_type | String | 0 | ||
| props_img | Mix | 0 | 1627207:28326": "//http://img.alicdn.com/imgextra/i2/2844096782/O1CN01VrjpXt1zyCc9DvERE_!!2844096782.jpg | 属性图片 |
| shop_item | Mix | 0 | [] | |
| relate_items | Mix | 0 | [] |
以上就是“Python爬虫获取淘宝商品详情页数据|实现自动化采集商品信息”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}