







实模式
实模式是什么?实模式是指8086CPU的寻址方式,寄存器大小,指令用法等,是用来反应CPU在该环境下如何工作的概念。
先讲一下CPU 的工作原理:
1,控制单元要取下一条待运行的指令,该指令的地址在程序计数器 PC 中,在 x86CPU 上,程序计数器就是 cs: ip。于是读取 ip 寄存器后,将此地址送上地址总线, CPU 根据此地址便得到了指令,并将其存入到指令寄存器 IR 中。
2,这时候轮到指令译码器上场了,它根据指令格式检查指令寄存器中的指令,先确定操作码是什么,再检查操作数类型,若是在内存中,就将相应操作数从内存中取回放入自己的存储单元,若操作数是在寄存器中就直接用了,免了取操作数这一过程。
3,操作码有了,操作数也齐了,操作控制器给运算单元下令,开工,于是运算单元便真正开始执行指令了。
4,ip 寄存器的值被加上当前指令的大小,于是 ip 又指向了下一条指令的地址。
–》 接着控制单元又要取下一条指令了,流程回到了本段开头。
CPU 便开始了日复一日的循环,由于 CPU 特别不容易坏,所以唯一它停下来的条件就是停电。
通过上面的说明,我们知道CPU执行程序是要知道程序指令的地址的,就像你要去吃饭,你得知道餐厅在哪里一样。CPU通过cs:ip的组合在内存里寻址,只要将转换后的地址提交给地址总线,就能找到该数据,指哪打哪。
参考:平坦模型与分段模型。
实模式有很多不靠谱的地方,实模式被保护模式淘汰的原因,最主要是安全隐患。
(1)实模式下操作系统和用户程序属于同一特权级,这哥俩平起平坐,没有区别对待。
(2)用户程序所引用的地址都是指向真实的物理地址,也就是说逻辑地址等于物理地址,实实在在地
指哪打哪。
(3)用户程序可以自由修改段基址,可以不亦乐乎地访问所有内存,没人拦得住。
以上 3 个原因属于安全缺陷,没有安全可言的 CPU 注定是不可依赖的,这从基因上决定了用户程序乃至操作系统的数据都可以被随意地删改,一旦出事往往都是灾难性的,而且不容易排查。
(4)访问超过 64KB 的内存区域时要切换段基址,转来转去容易晕乎。
(5)一次只能运行一个程序,无法充分利用计算机资源。
(6)共 20 条地址线,最大可用内存为 1MB,这即使在 20 年前也不够用
保护模式
保护模式是相对于实模式而言的,它首次出现是在Intel 80286 CPU中首次出现的,紧跟着8086,为了克服在实模式下的种种问题,处理器厂商开发出保护模式,这样,物理地址不能直接被程序访问,程序内部的地址(虚拟地址)需要被转化成物理地址之后再去访问,程序对此一无所知,它只需要老老实实运行就是。
32 位 CPU 具有保护模式和实模式两种运行模式,可以兼容实模式下的程序(一切以兼容为大,兼容 == money)。兼容实模式,是指能够正确处理好实模式下的程序,并不是说在实模式下运行时就完全变成了纯 16 位的 CPU。就像中学生做小学生的题一样,可以用小学生的知识方法来做,但并不要求自己退化成小学生的知识水平。如果不强调方法,甚至可以用中学知识来解小学生问题。
假设我们使用的是32位的CPU,当开机时,32位的CPU是处于先处于实模式(bios -> mbr -> loader -> kernel -> os,这些寻址过程是要求准确物理地址的),之后再进入保护模式的(其它程序运行)。
在保护模式下每运行一个实模式下的程序,就要为其虚拟一个实模式环境,故称虚拟模式。它是实模式向保护模式过渡时的产物(毕竟要搞兼容占住市场)。
既然保护模式是与实模式相对区分开的,首先,先要能解决实模式下存在的问题。
(1)实模式下的用户程序可以破坏存储代码的内存区域,所以要添加个内存段类型属性来阻止这种行为。
(2)实模式下的用户程序和操作系统是同一级别的, 所以要添加个特权级属性来区分用户程序和操作系统的地位。
其次,是一些访问内存段的必要属性条件。
(1)内存段是一片内存区域,访问内存就要提供段基址,所以要有段基址属性。
(2)为了限制程序访问内存的范围,还要对段大小进行约束,所以要有段界限属性。
这些用来描述内存段的属性,被放到了一个称为段描述符的结构中,顾名思义,该结构专门用来描述一个内存段,该结构是 8 字节大小,结构如下图所示。
段选择子
段寄存器 CS、 DS、 ES、 FS、 GS、 SS,在实模式下时,段中存储的是段基地址,即内存段的起始地址。而在保护模式下时,由于段基址已经存入了段描述符中,所以段寄存器中再存放段基址是没有意义的,在段寄存器中存入的是一个叫作选择子的东西------------selector。
选择子“基本上”是个索引值,这里说的是基本上,。用此索引值在段描述符表中索引相应的段描述符,这样,便在段描述符中得到了内存段的起始地址和段界限值等相关信息。
下面正式介绍下选择子。由于段寄存器是 16 位,所以选择子也是 16 位,在其低 2 位即第 0~1 位,用来存储 RPL,即请求特权级,可以表示 0、 1、 2、 3 四种特权级。此处可以理解为请求者的当前特权级。
选择子的第 2 位是 TI 位,即 Table Indicator,用来指示选择子是在 GDT 中,还是 LDT 中索引描述符。 TI为 0 表示在 GDT 中索引描述符, TI 为 1 表示在 LDT 中索引描述符。选择子的高 13 位,即第 3~15 位是描述符的索引值,用此值在 GDT 中索引描述符。前面说过 GDT 相当于一个描述符数组,所以此选择子中的索引值就是 GDT 中的下标。选择子结构如下图所示:

由于选择子的索引值部分是 13 位,即 2 的 13 次方是 8192,故最多可以索引 8192 个段,这和 GDT中最多定义 8192 个描述符是吻合的。
选择子的作用主要是确定段描述符,确定描述符的目的,一是为了特权级、界限等安全考虑,最主要的还是要确定段的基地址。
段描述符
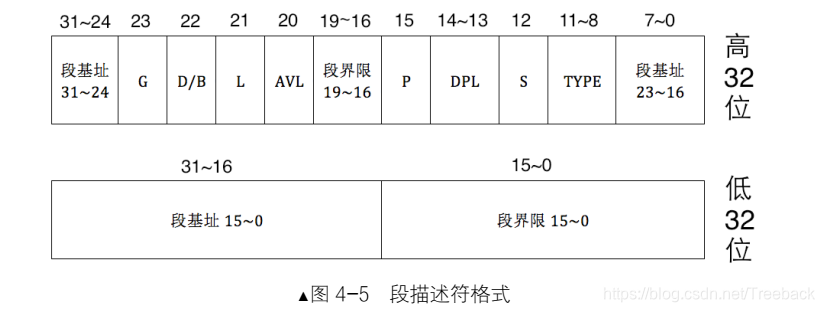
保护模式下地址总线宽度是 32 位,段基址需要用 32 位地址来表示。
段界限表示段边界的扩展最值,即最大扩展到多少或最小扩展到多少。扩展方向只有上下两种。对于数据段和代码段,段的扩展方向是向上,即地址越来越高,此时的段界限用来表示段内偏移的最大值。对于栈段,段的扩展方向是向下,即地址越来越低,此时的段界限用来表示段内偏移的最小值。无论是向上扩展,还是向下扩展,段界限的作用如同其名,表示段的边界、大小、范围。
段界限用 20 个二进制位来表示。只不过此段界限只是个单位量,它的单位要么是字节,要么是 4KB,这是由描述符中的 G 位来指定的。
最终段的边界是此段界限值*单位,故段的大小要么是 2 的 20 次方等于 1MB,要么是 2 的 32 次方(4KB 等于 2 的 12 次方, 12+20=32)等于 4GB。
上面所说的 1MB 和 4GB 只是个范围,并不是具体的边界值。由于段界限只是个偏移量,是从 0 算起的,所以:
实际的段界限边界值=(描述符中段界限+1) *(段界限的粒度大小: 4KB 或者 1) -1。
这个公式很简单,就是表示有多少个 4KB 或 1。由于描述符中的段界限是从 0 起的,所以左边第 1个括号中要加个 1,表示 4KB 或 1 的实际数量。它与第二个括号中的段粒度大小相乘后得到的乘积是以 1为起始的段的实际大小。由于地址是以 0 为起始的,所以公式的最后又减了 1。
如果 G 位为 0,表示段界限粒度大小为 1 字节,根据上面的公式,实际段界限=(描述符中段界限+1)*1 -1=描述符中段界限,段界限实际大小就等于描述符中的段界限值。
如果 G 位为 1,表示段界限粒度大小为 4KB 字节,故实际段界限=(描述符中段界限+1) 4k-1。
举个例子,如果是平坦模型,段界限为 0xFFFFF, G 位为 1,套用上面公式,段界限边界值=0x1000000x1000-1=0xFFFFFFFF。
段描述符的低 32 位分为两部分,前 16 位用来存储段的段界限的前 0~15 位,后 16 位用来存储段基址的 0~15 位。
在段描述符的高 32 位中:
0~7 位是段基址的 16~23, 24~31 位是段基址的 24~31 位, 加上在段描述符低 32 位中的段基址 0~15 位,这下 32 位基地址才算齐全了。
8~11 位是 type 字段,共 4 位,用来指定本描述符的类型。这里要提前说下段描述符的 S 字段了。是这样的,一个段描述符,在 CPU 眼里分为两大类,要么描述的是系统段,要么描述的是数据段,这是由段描述符中的 S 位决定的,用它指示是否是系统段。
段描述符的第 13~14 位是 DPL 字段, Descriptor Privilege Level,即描述符特权级,这是保护模式提供的安全解决方案,将计算机世界按权力划分成不同等级,每一种等级称为一种特权级。(保护模式下权限访问跟它有很大的关系)
全局描述符表
全局描述符表(Global Descriptor Table, GDT)是保护模式下内存段的登记表,这是不同于实模式的显著特征之一。
一个段描述符只用来定义(描述)一个内存段。代码段要占用一个段描述符、数据段和栈段等,多个内存段也要各自占用一个段描述符,这些描述符放在哪里呢?答案是放在全局描述符表,为什么将该表称为“全局”描述符表?全局体现在多个程序都可以在里面定义自己的段描述符,是公用的。全局描述符表位于内存中, 需要用专门的寄存器指向它后, CPU 才知道它在哪里。这个专门的寄存器便是 GDTR,即 GDT Register,专门用来存储 GDT 的内存地址及大小。 如下图所示:

GDT界限表示它能存储的段描述符的多少,由于 GDT 的大小是 16 位二进制,其表示的范围是 2的 16次方等于 65536字节。每个描述符大小是 8字节,故,GDT中最多可容纳的描述符数量是 65536/8=8192个,即 GDT 中可容纳 8192 个段或门。
要寻址到一个描述符可以用起始地址+段选择子内段描述符的index*8字节的方式找到段描述符,从而可以由该方式寻址到要找的物理段,只需要拥有该段描述符的编号。
分页
分页机制其实是建立在分段机制之上的。 这是不是有些让大家意外呢?其实这并不是说分页机制依赖于分段机制, 只是这内存分段机制属于 Intel IA32 架构骨子里的东西, 改是改不掉的, 除非从头再造个 CPU出来,所以分页机制只能在现有分段机制大局已定的情况下诞生。(在内存不足,且内存使用物理不连续时,需要置换部分内存出去,分段之下只能KILL掉一部分进程,但是分页能让他在不被KILL的情况下运行)
CPU 在不打开分页机制的情况下,是按照默认的分段方式进行的,段基址和段内偏移地
址经过段部件处理后所输出的线性地址, CPU 就认为是物理地址。如果打开了分页机制,段部件输出的线性地址就不再等同于物理地址了,我们称之为虚拟地址,它是逻辑上的,是假的,不应该被送上地址总线(因为地址只是个数字,任何数字都可以当作地址,这里说的“不应该”是指应该人为保证送上地址总线上的数字是正确的地址)。 CPU 必须要拿到物理地址才行,此虚拟地址对应的物理地址需要在页表中查找,这项查找工作是由页部件自动完成的。为了要搞清楚页部件的工作原理,必须要搞清楚这两件事。
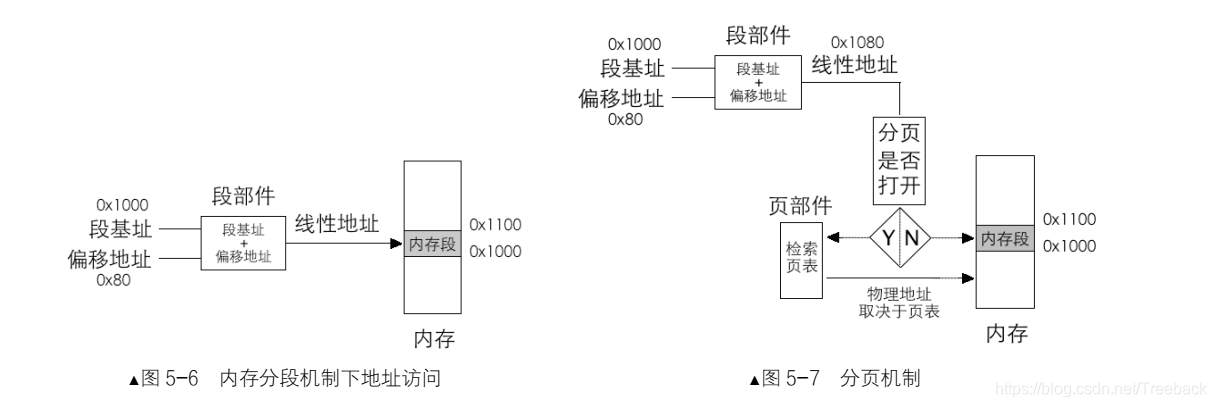
经过段部件处理后,保护模式的寻址空间是 4GB,注意啦,这个寻址空间是指线性地址空间,它在逻辑上是连续的。分页机制的思想是:通过映射,可以使连续的线性地址与任意物理内存地址相关联,逻辑上连续的线性地址其对应的物理地址可以不连续。
分页机制的作用有两方面。
1)将线性地址转换成物理地址。
2)用大小相等的页代替大小不等的段。
即使在分页机制下的进程也要先经过逻辑上的分段才行,每加载一个进程,操作系统按照进程中各段的起始范围,在进程自己的 4GB 虚拟地址空间中寻找可用空间分配内存段,此虚拟地址空间可以是页表,也可以是操作系统维护的某种数据结构,总之此阶段的分
配是逻辑上的,并没有真正写入物理内存。
一级页表
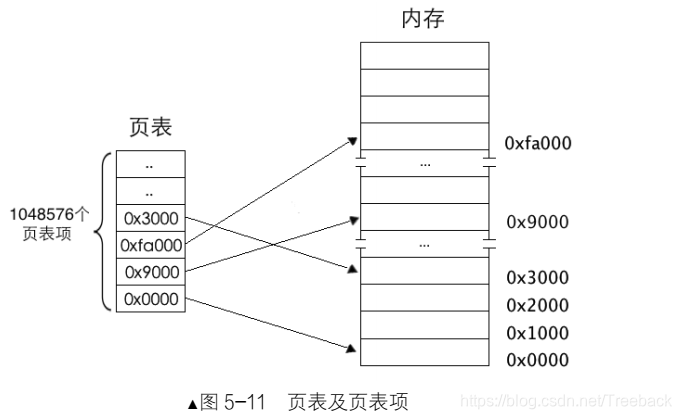
页是地址空间的计量单位,并不是专属物理地址或线性地址,只要是 4KB 的地址空间都可以称为一页,所以线性地址的一页也要对应物理地址的一页。一页大小为 4KB,这样一来, 4GB 地址空间被划分成 4GB/4KB=1M 个页, 也就是 4GB 空间中可以容纳1048576 个页, 页表中自然也要有 1048576 个页表项,这就是我们要说的一级页表。
二级页表
前面讲述了页表的原理,并以一级页表作为原型讲述了地址转换过程。既然有了一级页表,为什么还要搞个二级页表呢?理由如下。
(1)一级页表中最多可容纳 1M(1048576)个页表项,每个页表项是 4 字节,如果页表项全满的话,便是 4MB 大小。
(2)一级页表中所有页表项必须要提前建好,原因是操作系统要占用 4GB 虚拟地址空间的高 1GB,用户进程要占用低 3GB。
(3)每个进程都有自己的页表,进程一多,光是页表占用的空间就很可观了。
二级页表很好地解决了该问题。我们来说下什么是二级页表。
无论是几级页表,标准页的尺寸都是 4KB,这一点是不变的。所以 4GB 线性地址空间最多有 1M 个标准页。一级页表是将这 1M 个标准页放置到一张页表中,二级页表是将这 1M 个标准页平均放置 1K 个页表中。每个页表中包含有 1K 个页表项。页表项是 4 字节大小,页表包含 1K 个页表项,故页表大小为4KB,这恰恰是一个标准页的大小。
拆分出了这么多个页表,如何使用它们呢?为此,专门有个页目录表来存储这些页表。每个页表的物理地址在页目录表中都以页目录项(Page Directory Entry, PDE)的形式存储,页目录项大小同页表项一样,都用来描述一个物理页的物理地址,其大小都是 4 字节,而且最多有 1024 个页表,所以页目录表也是 4KB 大小,同样也是标准页的大小。
页表是用于管理内存的数据结构,其也要占用内存,所以页目录表和页表所占用的物理页,同样混迹于物理内存之中,
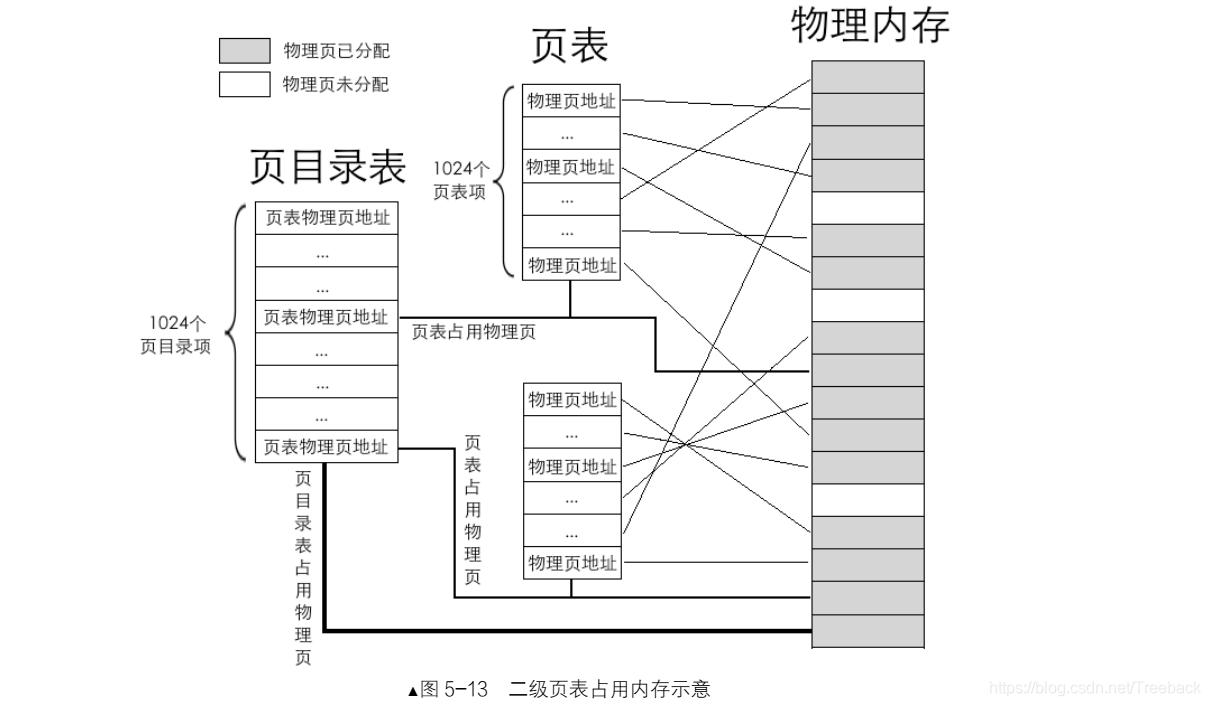
每个页表中可容纳 1024 个物理页,故每个页表可表示的内存容量是 10244KB=4MB。页目录中共有1024 个页表,故所有页表可表示的内存容量是 10244MB=4GB,这已经达到了 32 位地址空间的最大容量。
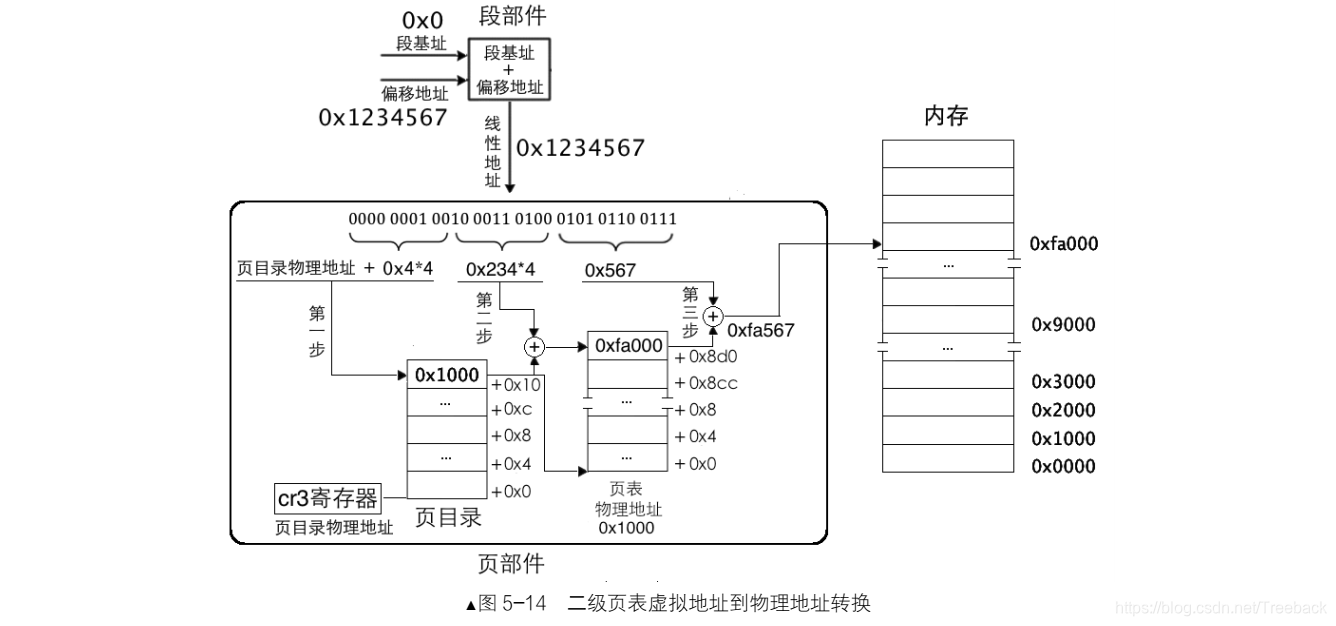
所以说,任意一个 32 位物理地址,它必然在某个页表之内的某个物理页中。我们定位某一个物理页,必然要先找到其所属的页表。页目录中 1024 个页表,只需要 10 位二进制就能够表示了,所以,虚拟地址的高10 位(第 31~22 位)用来在页目录中定位一个页表,也就是这高 10 位用于定位页目录中的页目录项 PDE,PDE 中有页表物理页地址。 找到页表后, 到底是页表中哪一个物理页呢?由于页表中可容纳 1024 个物理页,
故只需要 10 位二进制就能够表示了。所以虚拟地址的中间 10 位(第 21~12 位)用来在页表中定位具体的物理页,也就是在页表中定位一个页表项 PTE, PTE 中有分配的物理页地址。由于标准页都是 4KB, 12 位二进制便可以表达 4KB 之内的任意地址,故线性地址中余下的 12 位(第 11~0 位)用于页内偏移量。
经以上分析,二级页表地址转换原理是将 32 位虚拟地址拆分成高 10 位、中间 10 位、低 12 位三部分,它们的作用是:高 10 位作为页表的索引,用于在页目录表中定位一个页目录项 PDE,页目录项中有页表物理地址,也就是定位到了某个页表。中间 10 位作为物理页的索引,用于在页表内定位到某个页表项 PTE,页表项中有分配的物理页地址,也就是定位到了某个物理页。低 12 位作为页内偏移量用于在已经定位到的物理页内寻址。
同一级页表一样,访问任何页表内的数据都要通过物理地址。由于页目录项 PDE 和页表项 PTE 都是4 字节大小,给出了 PDE 和 PTE 索引后,还需要在背后悄悄乘以 4,再加上页表物理地址,这才是最终要访问的绝对物理地址。转换过程背后的具体步骤如下。
(1)用虚拟地址的高 10 位乘以 4,作为页目录表内的偏移地址,加上页目录表的物理地址,所得的和,便是页目录项的物理地址。读取该页目录项,从中获取到页表的物理地址。
(2)用虚拟地址的中间 10 位乘以 4,作为页表内的偏移地址,加上在第 1 步中得到的页表物理地址,所得的和,便是页表项的物理地址。读取该页表项,从中获取到分配的物理页地址。
(3)虚拟地址的高 10 位和中间 10 位分别是 PDE 和 PTE 的索引值,所以它们需要乘以 4。但低 12 位就不是索引值啦,其表示的范围是 0~0xfff,作为页内偏移最合适,所以虚拟地址的低 12 位加上第 2 步中得到的物理页地址,所得的和便是最终转换的物理地址。
举个例子:比如 mov ax, [0x1234567],其过程如图所示:
实模式和保护模式的比较
1,实模式可以直接访问物理地址;保护模式下不是你想访问哪个物理地址就能访问哪个物理地址,要通过分页,GDT等来进行间接访问。
2,实模式没有特权级的概念,人人都可以占山为王,攻伐不断;保护模式有严格的权限保护(虽然这里没讲)。
3,实模式下不可能用平坦模型(寄存器的锅),而保护模式 可以直接过渡到平坦模型。
这里放的大部分内容来自郑刚大佬的《操作系统真象还原》,膜拜。

















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









