






名字:姚翔,230143042 IP:上海。
他是一名不折不扣的跑单狗,在2024年11月12日中午1点到3点这个时间段,厚颜无耻地找到我,企图让我代替他参加考试,并承诺会给予我一笔不菲的酬劳作为回报。出于对他言辞恳切以及我们之间那点微薄信任的考量,我最终决定冒着风险帮他这个忙,而且出于善意,我并没有事先要求他支付任何定金。然而,世事无常,当我尽心尽力地帮他完成了考试任务之后,这个所谓的“朋友”却瞬间变脸,人间蒸发般地消失得无影无踪。我尝试通过微信联系他,消息如石沉大海,杳无音讯;再到咸鱼平台上寻找他的踪迹,结果同样令人失望,他仿佛从虚拟世界中彻底抹去了自己的存在。这一系列变故,让我深刻体会到了人性的复杂与险恶,以及信任被辜负后的苦涩与无奈。
以下是两个平台页面:
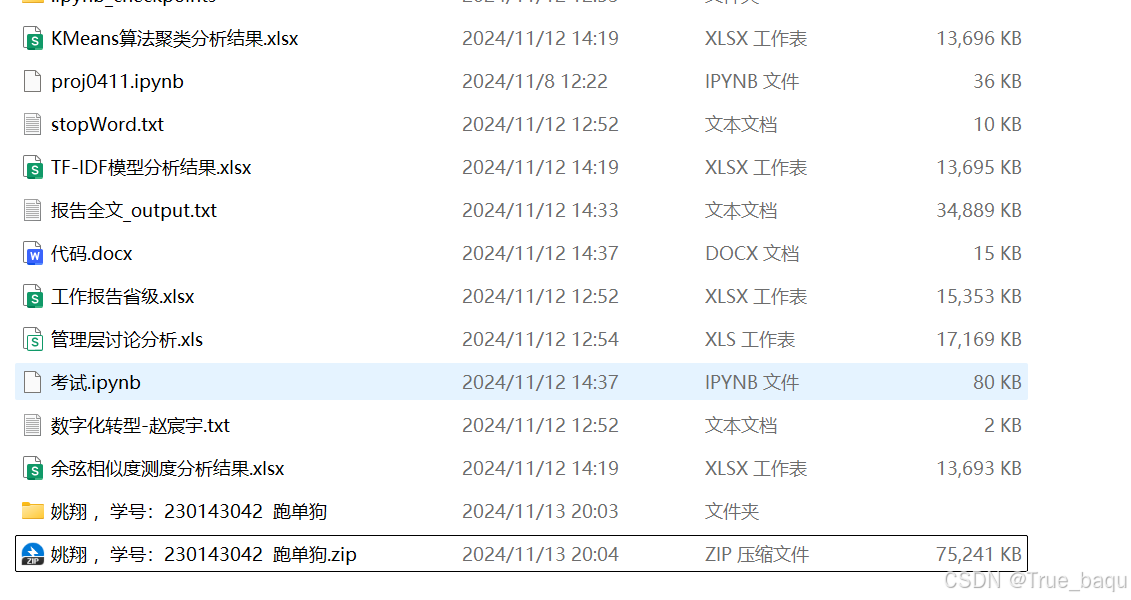
二、现有一份上市企业年度财务报告文本中管理层讨论与分析文本大数据,请测度以下相关的数据(60分):
(1)请从EXCEL表格中读取上市企业营理层讨论分析文本大数据,使用python程序代码将半年度和年度的管理层讨论与分析文本分别筛选出两个表格,并且将半年度和年度管理层讨论与分析文本再合并为一个表格,保留股票代码、公司简称、会计年度、经营时间、半年度和年度管理层讨论分析等基本信息(10分)。
(2)将(1)中合并后管理层讨论与分析文本,使用eba分词技术将半年度和年度管理层讨论分析文本进行分词处理,并且将分词后文本合并为一个表格,保留股票代码、公司简称、会计年度、半年报分词文本、年报分词文本(10分)。
(3)将(2)中合并后管理层讨论分词文本,使用词袋法,创建一个测度单个半年报分词文本和年报分词文本的余相似度的函数,包括文本向量化处理和余张相似变测度,再创律一个主程序测度所有企业半年报和年报管理层讨论分析文本的相似度,最后以表格形式显示股票代码、公司简称、会计年度、文本相似度,并保持到特定路径下文件来。(10分)。
(4)将(2)中合并后管理层讨论分词文本,使用TF-DF模型,创建一个测度单个的半年报分词文本和年报分词文本的余弦相似度的函数,包括文本向量化处理和余改相似度测度,再创律一个主程序测府所有企业半年报和年报管理层讨论分析文本的相似度,最后以表格形式显示股黑代吗、公司简称、会计年度、文本相似度,并保持到特定路径下文件夹。(15分)。
(5)使用TF-DF将年度管理层过论分析文本进行文本向量化处理,将其转换为表格后,使用KMeans算法对上市企业管理层讨论分析文木进行聚类分析,将上市企业管理层讨论分析文本分为5个类别(15分)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









