







Tri-MipRF: Tri-Mip Representation for Efficient Anti-Aliasing Neural Radiance Fields
Tri-MipRF是ICCV2023年的Oral和Best Paper Finalist,研究单位是字节跳动、清华大学和中国科学院计算技术研究所,文章主要思想是,将Mip-NeRF和Tri-plane进行结合,能够实现神经辐射场的快速重建,以及抗锯齿、高保真的实时渲染。
文章目录
一、背景与论文思路
尽管神经辐射场已经取得巨大进展,现有方法仍然面临着精度和效率之间权衡的困境,例如Mip-NeRF虽然实现了精细的重建和抗锯齿的渲染,但它需要数天的训练;而Instant-NGP虽然能在几分钟内完成重建,但当在不同距离或分辨率下进行渲染时,会出现模糊或锯齿效应。因此,本文想提出一种既高效率又高精度的重建方法。
本文的第一个Motivation是(如何实现高精度):传统NeRF通过发射射线来进行渲染:r(t)=o+td,并沿着射线进行三维坐标点x的采样,然后通过位置编码(PE)对点x进一步特征化,以产生γ(x)的特征向量。这种采样方式将像素建模为单个点,忽略了像素的面积,这与真实世界的成像传感器截然不同。当捕获/渲染的视图大致处于恒定距离时,它可以近似于真实世界的情况;而当在不同的距离捕获/渲染视图时,会产生明显的伪影,例如,近处视图会出现模糊,远处视图会出现锯齿效应。抗锯齿是计算机图形学的一个基本问题,从数学上讲,锯齿是由于采样率不足而导致的频率分量重叠的影响,超采样和预滤波(区域采样)分别是离线和实时渲染算法中减少锯齿伪影的两种典型方法。受到Mip-NeRF相关工作启发,本文提出了一种基于圆锥内切球体的采样方法,将像素公式化为图像平面上的圆盘,而不是忽略像素面积的单个点。
本文的第二个Motivation是(如何实现高效率):传统NeRF通过8层MLP来进行隐式重建,场景信息都包含在MLP网络参数中,虽然大幅提高了重建精度,需要数天的训练时间。为了实现快速的重建,后续方法(TensorRF、Instant-NGP)提出了显示+隐式混合的表示方式,即先采用显式的矩阵、张量表示三维场景特征,然后再采用少量MLP层回归σ、c信息。受TensoRF、EG3D这些工作启发,本文采用三平面来显式表示三维场景特征,从而实现高效率重建。同时,这种三平面的表示方式也能很好和上述的圆锥采样方法相结合,即,将采样得到的内切球体分别沿三个平面投影得到圆盘,即可实现区域采样。
二、数据集
本文主要在单尺度Blender数据集、多尺度Blender数据集上进行了测评。
以Lego数据集为例,单尺度数据集,即训练集为200张(800, 800)分辨率的图像,测试集为200张(800, 800)分辨率的图像,所有图像都以大致恒定距离围绕物体拍摄。
以Lego数据集为例,多尺度数据集,即将每张(800, 800)分辨率的图像进行缩放,分别得到四种分辨率的图像:(800, 800)、(400, 400)、(200, 200)、(100, 100)。由于投影几何的性质,这几乎等同于重新渲染原始数据集,其中到相机的距离增加了2、4和8的比例因子。
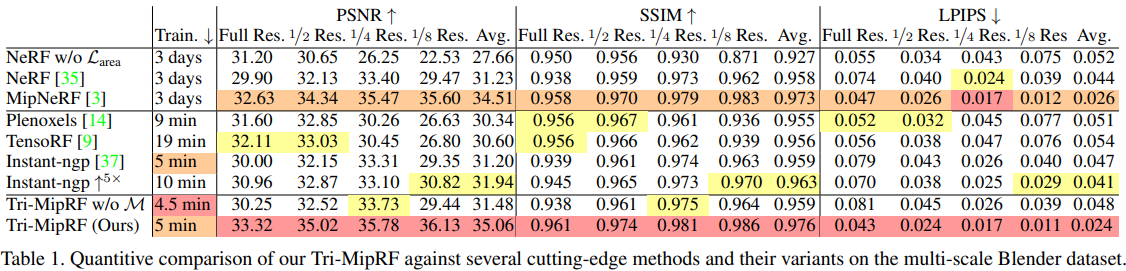
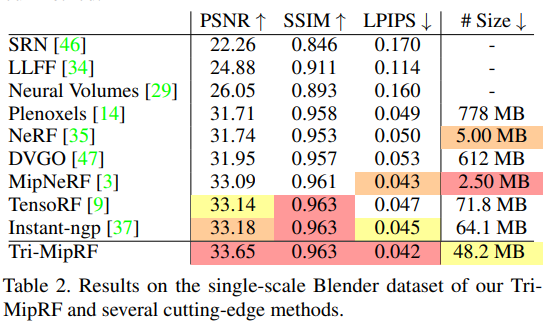
从测评结果看,Tri-MipRF在多尺度数据集中优势明显,而在单尺度数据集中性能提升一般。
三、Tri-MipRF原理与实现细节
Tri-MipRF整体架构主要由四部分构成,包括:圆锥投射、Tri-Mip编码、小型MLP回归、体素渲染及损失函数优化,非常简洁而优美。
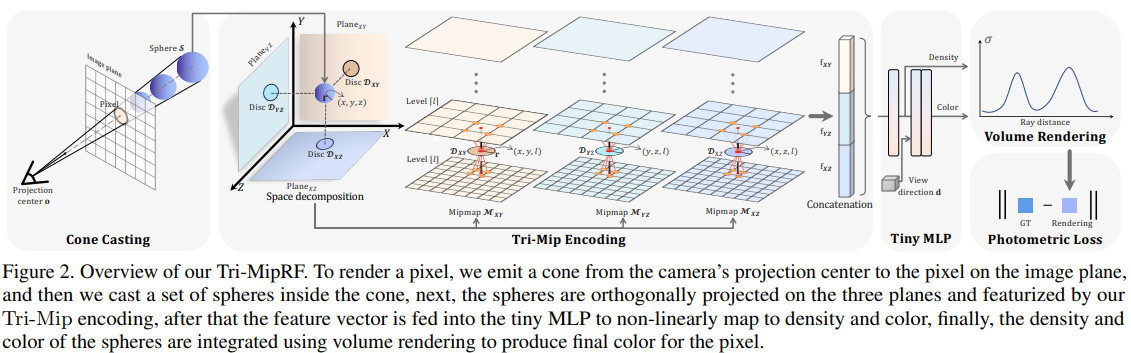
第1部分:圆锥投射。
与原始NeRF类似,Tri-MipRF从每个像素位置发射一个圆锥体,其中,圆锥体的顶点位于相机的光学中心,圆锥体与图像平面的交点是与像素相对应的圆盘,圆锥的中心轴为r(t)=o+td。
在圆锥的中心轴上,我们等间距采样一系列的球心点x,从而得到射线上的一组球体S(x, r)。通过立体几何,我们根据射线与图像平面的余弦值(cos)、球心采样点与光学中心的距离(d),就可以推导出不同球体的半径r,进而可以得到不同球体投影到三平面上的圆盘面积,以实现区域采样。球体半径r的计算公式如下:
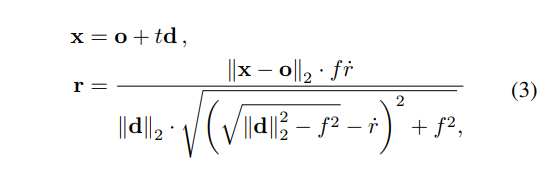
此时,对于每一条射线上的采样点,我们可以得到该射线的方向向量(nx, ny, nz)、采样点坐标(即,球心三维坐标x)、采样点对应的球体半径r。
第2部分:Tri-Mip编码。
Tri-Mip作为一种显式的场景表示方式,首先要定义一组可学习的参数矩阵,来表征整个三维场景的特征。以Lego数据集为例,Tri-MipRF将整个场景预定义在一个[-1.5, 1.5]×[-1.5, 1.5]×[-1.5, 1.5]的正方体中,三平面的分辨率定义为:(3, 512, 512, 16),即每个平面用(512, 512)的分辨率进行建模,特征维度为16,包含X-Y、Y-Z、X-Z三个平面。
在得到每个采样球体的球心三维坐标x、球体半径r后,即可将该球体分别投影到三个平面中,根据投影出的圆盘面积进行区域采样。这里采用了计算机图形学中经典Mip采样方式,论文里描述得非常复杂,实际代码中直接通过nvdiffrast.torch库函数来实现,非常简洁。

此时,我们得到了每个采样球体在三个平面上分别对应的16维特征,将这些特征全部拼接起来,每个采样球体即对应一个48维的特征。
第3部分:小型MLP编码。
在得到每个采样球体的48维特征后,论文中先定义了一个mlp_base全连接网络,将特征映射成16维,该mlp_base网络架构如下图,借助了 tinycudann库来实现。回归出的16维特征,第1维用作体密度特征,第2维-第16维用作颜色特征。
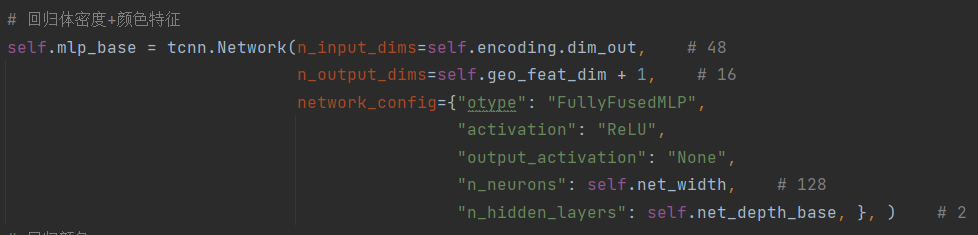
针对体密度特征(1维),采用TruncExp激活函数处理后,直接作为体密度σ输出。
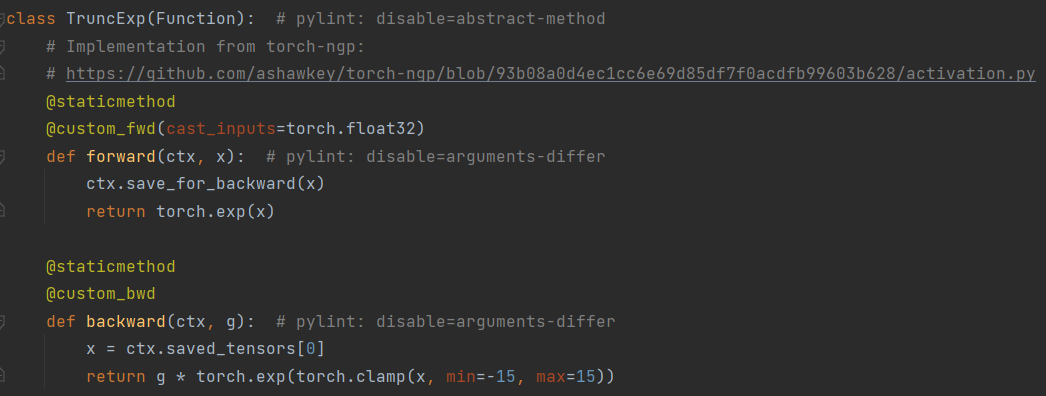
针对颜色特征(15维),首先定义了一个球弦编码函数,将归一化后的观测方向(nx, ny, nz)编码成16维,然后再与15维的颜色特征进行concatenate,得到31维的特征,最后输入定义好的mlp_head全连接网络,输出颜色c(3维)。

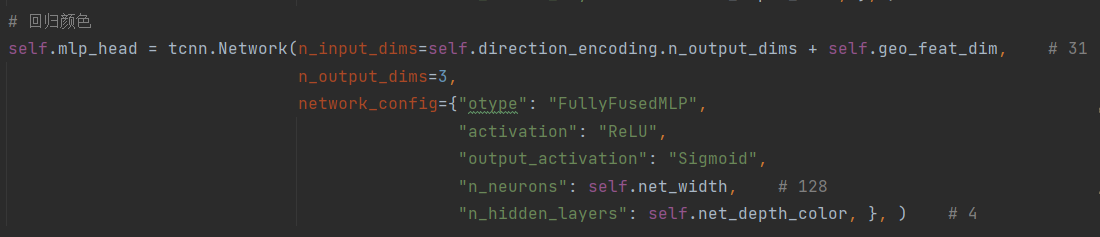
此时,对于一条射线上的每个采样球体,我们回归得到其对应的体密度σ、颜色c。
第4部分:体素渲染及损失函数优化。
与原始NeRF类似,回归得到射线上每个采样球体的体密度σ、颜色c后,对这条射线进行体素渲染,即可得到这条射线在图像上对应的颜色C( r)。
在损失函数优化部分,论文采用的是F.smooth_l1_loss损失,而不是原始MSE损失。此外,针对多尺度Blender数据集,论文中还依据不同的尺度还对损失进行了加权处理,而在单尺度Blender数据集中则是直接简单求和。
四、工程技巧
在工程技巧方面,论文中引入了nerfacc库来加速训练,这也是Tri-MipRF高效的一个关键。nerfacc主要对体素渲染过程进行了优化,它将体素渲染流程分为两个步骤:ray marching、differentiable rendering。
Ray marching是在场景中投射光线,并沿着光线生成离散样本的过程。这些样本后面会被送入辐射场中进行回归,而辐射场通常是整个流程的主要瓶颈,因此可以通过在射线行进过程中尽可能减少样本数量,来提高效率。由体素渲染方程可知,如果样本具有低不透明度alpha_i或低透射率T_i,则样本对最终图像颜色C(r )的贡献很小。换言之,在射线行进过程中,我们可以安全地跳过空白或遮挡区域中的样本,因为它们对最终图像没有贡献。
在nerfacc中,结合了使用Instant-NGP中的占用网络的想法,在训练期间存储和更新二进制网络,以存储场景中哪些区域是空的(例如,alpha_i<1e-2)。与Instant-NGP、PlenOctrees类似,nerfacc通过光线的透射率(例如,Ti<1e-4)来提前终止行进,从而跳过遮挡区域。注意,对于跳过的遮挡区域,我们需要知道样本沿光线的精确密度,以计算透射率。因此,对于用户定义的辐射场(例如MLP-NeRF、Instant-NGP-NeRF),在进行评估获得密度的时候,需要禁止梯度下降以最小化运算。
Differentiable rendering是将采样的颜色沿光线累积为像素颜色的过程。在这一步骤中,nerfacc以可微分的方式使用用户定义的辐射场,辐射场的所有输出都将接受来自像素监督的梯度。nerfacc支持任何采样属性,而不仅仅是颜色,并且可以通过nerfacc定义的函数接口进行渲染,例如深度和不透明度。
官网给出的测评结果,使用Nerfacc工具箱后:
(1)具有8层MLP的原始NeRF模型,可以在1小时内训练到更好的质量(+0.5 PSNR),而不是像论文中那样训练1-2天。
(2)与官方纯CUDA实现相比,Instant-NGP模型可以在Python中用4.5分钟训练到同等质量。
(3)动态场景的D-NeRF模型可以在1小时内训练,而不是像论文中那样在2天内训练,并且具有更好的质量(+2.0 PSNR)。
五、结论
TriMipRF算的上是ICCV2023一个比较有亮点的工作。从数学原理上,Tri-MipRF进行沿着Mip-NeRF路线进行优化,将射线投影建模为圆锥投影,并结合Tri-plane实现了区域采样,整体理论比较solid,流程上也非常简洁优美;从实验效果上,Tri-MipRF训练速度确实较快,而且在多尺度数据集上能有更好的渲染结果。
美中不足的是,Tri-MipRF在单尺度数据集上并未有太大的效果提升,和ECCV2022的TensoRF效果相差不大;此外,Tri-MipRF渲染出来的深度图感觉质量有问题,有较多噪声点。
源码:https://github.com/wbhu/Tri-MipRF
nerfacc文档:https://arxiv.org/pdf/2210.04847.pdf















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









