







舞蹈是一种重要的人类艺术形式,但创造新的舞蹈可能既困难又耗时。因此,Stanford 大学提出了EDGE(CVPR2023),这是首个基于Diffusion的音乐引导的舞蹈生成框架,能够通过AIGC的方式,生成动作丰富多样、物理意义合理、音乐节拍对齐的舞蹈。
一、背景
舞蹈是世界各地许多文化的重要组成部分,是一种表达、交流和社会互动的形式。然而,创造新的舞蹈动作是非常困难的,因为舞蹈动作富有表现力和自由形式,但又需要由音乐精确构建。
传统方法基于繁琐的手部人工设计或视频动作捕捉,这可能是昂贵且不切实际的。因此,使用AIGC方法自动生成舞蹈可以减轻创作过程的负担,从而产生许多应用。例如,可以帮助动画师创建新的舞蹈,或者根据用户提供的音乐为视频游戏或虚拟现实中的互动角色提供逼真多样的动作。此外,舞蹈生成可以深入了解音乐和运动之间的关系,这是神经科学的一个重要研究领域。

二、现有工作
音乐引导的舞蹈生成任务(Music to Dance)被广泛研究,它是人体动作生成任务的一个子方向。早期方法遵循运动检索范式,但往往会生成单调重复、不切实际的舞蹈动作。后来采用基于深度学习的舞蹈生成方法,包括对抗学习、递归神经网络、Transformer。尽管取得了令人印象深刻的性能,但这些系统非常复杂,涉及许多层的调节和子网络。
本文提出了Editable Dance GEneration(EDGE),这是一种最先进的舞蹈生成方法,可以基于输入音乐创建逼真、物理合理的舞蹈动作。EDGE使用了一个基于Transformer的扩散模型,并与Jukebox(一个强大的音乐特征提取器)配对。这种基于扩散的方法赋予了非常适合舞蹈的强大编辑功能。此外,本文发现之前的评估指标存在缺陷,提出了一种新的评估指标,用来度量生成舞蹈的物理合理性。
本文的贡献主要包括:
(a)提出了一种基于扩散模型的舞蹈生成方法,该方法将最先进的性能与强大的编辑功能相结合,能够生成任意长的序列;
(b)采用Jukebox来提取音乐特征表示,代替以前手动提取的音乐特征。Jukebox是一种预训练的音乐生成模型,在音乐特定预测任务上表现出强大的性能;
(c)在损失函数中,引入了接触一致性损失,来消除生成运动中的足部滑动物理不真实性;
(d)针对之前的评估指标存在缺陷,提出了一种新的评估指标,物理足部接触得分(Physical Foot Contact score,PFC)。这是一种简单的基于加速的定量指标,用于对生成的运动学运动的物理真实性进行评分,不需要明确的物理建模;
三、数据集介绍
官网:https://google.github.io/aistplusplus_dataset/factsfigures.html

AIST++舞蹈数据集是基于AIST Dance Video DB构建的,通过多视角视频,估计相机参数、3D人体关键点、3D人体舞蹈运动序列。
(1)提供了10.1M张图像的3D人体关键点标注和相机参数,涵盖9个视角的30个不同主体,是现有最大的3D人体关键点标注数据集。
(2)包含了1048个3D人体舞蹈运动序列,以joint rotations,root trajectories的形式表示。舞蹈动作包含10个舞蹈流派,动作持续时间从7.4秒到48秒不等,所有的舞蹈动作都有相应的音乐。
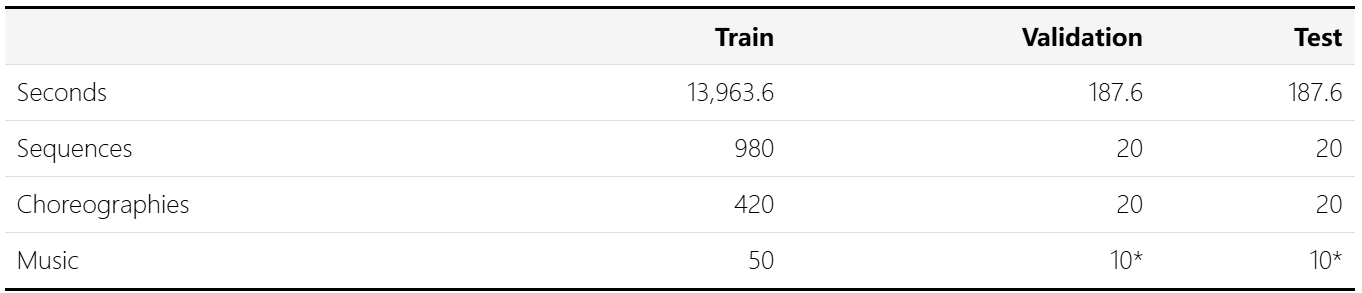
AIST++支持以下任务:(a)多视角人体关键点估计;(b)人体运动预测、生成;(c)运动和音乐之间的跨模态分析。数据集以不同的方式被分割成训练、验证、测试集,用于不同的目的。对于运动和音乐的任务,例如音乐条件动作生成,建议使用下表中描述的划分:
四、数据结构
音乐采用wav文件,舞蹈动作采用pkl文件,二者之间是对齐的,即:波形数据长度 / 音频采样率 = 视频帧数 / FPS。
给定一段长度任意(例如56s)的音频舞蹈序列,首先需要通过滑动窗口,重叠移动(步长0.5s)划分成一个个固定长度(5s)的序列。然后舞蹈动作序列会被下采样到30FPS,以与音频特征进行帧对齐(150帧)。最终,训练数据的维度为:
(batch,150,music_channel),(batch,150,motion_channel)。
4.1、音乐特征表征
给定一段固定长度(5s)的wav音频,可以通过Jukebox(预训练模型)或Librosa(手工传统方法)提取音频特征:
如果采用Jukebox进行特征提取,输出的特征维度:(batch,150,4800);
如果采用Librosa进行特征提取,输出的特征维度:(batch,150,35)。
4.2、舞蹈动作表征
原始pkl文件中,舞蹈动作采用:全局trans(3维)+ 24关节点旋转向量(24×3=72维)表征。

第一步:对于全局trans(3维),需要通过motion[“scale”]进行尺度缩放,避免坐标数值过大导致训练不稳定。
第二步:要将24关节点旋转向量(24×3=72维)表征,转化为24关节点6DoF(24×6=144维)表征。
第三步:将全局trans,24关节点6DoF旋转90度(以对齐AIST++数据集的x,y,z轴坐标系)。经过上述变换后,第1维度表示人体从左手往右手的方向,第2维度表示人体正前方正后方的方向,第3维度表示人体从脚到头的高度方向。

第四步:为引入接触一致性损失,通过FK前向过程计算24关节点的坐标,然后通过差分计算得到24关节点的帧移动速度。取出左脚趾、右脚趾,左脚踝,右脚踝这4个关节点,对移动速度小于0.01的帧进行标记,赋值为1,其余位置赋值为0,得到contacts标签(4维)。
第五步:将全局trans(3维),24关节点6DoF表示(144维),contacts标签(4维)全部concatenate,并进行normalize标准化处理,得到(batch,150,151)维度的舞蹈动作表征。
五、方法论
5.1、模型架构
输入:音乐特征,维度(batch,150,4800);舞蹈Ground Truth,维度(batch,150,151)。采用DDPM + Classifier Free架构进行音乐引导的舞蹈生成。

第一步:对舞蹈动作Ground Truth进行加噪,得到带噪声的舞蹈动作,维度(batch,150,151);
第二步:将音乐特征输入Transformer Encoder架构,通过自注意力机制进行特征融合,维度(batch,150,512);
第三步:对时间步数进行傅里叶编码,然后输入MLP网络,得到时间特征,维度(batch,512);
第四步:将音乐特征在序列维度上进行平均,然后与时间特征相加求和,得到指导信息,维度(batch,512);
第五步:将带噪声的舞蹈动作输入MLP网络,然后在Transformer Decoder架构中做特征融合,在交叉注意力中,以音频时间信息作为K和V,以舞蹈特征作为Q,输出去噪后的舞蹈动作,维度(batch,150,151);
第六步:采用Classifier Free思路,同时进行有条件的舞蹈动作生成,以及无条件的舞蹈动作生成;
值得注意的是,和原始DDPM不同,EDGE采用Transformer架构直接预测去噪后的x0,并不是预测噪声,因此在计算损失函数的时候,并不是预测噪声和真实噪声直接计算MSE,而是预测舞蹈动作和真实舞蹈动作之间计算MSE。
5.2、损失函数
损失函数包含四部分:
第一部分:去噪后的舞蹈动作,和舞蹈动作Ground Truth的MSE损失,权重取0.636;
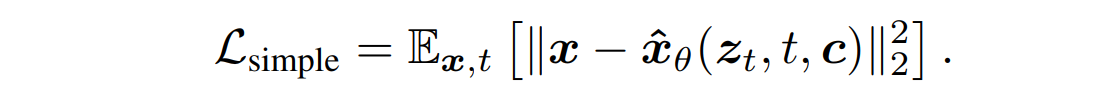
第二部分:通过FK过程,计算去噪后的舞蹈动作,以及舞蹈动作Ground Truth的24关节点坐标,计算MSE,权重取0.646;
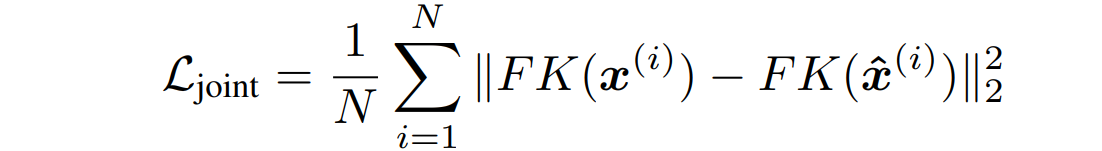
第三部分:通过FK过程,计算去噪后的舞蹈动作,以及舞蹈动作Ground Truth的移动速度,计算MSE,权重取2.964;
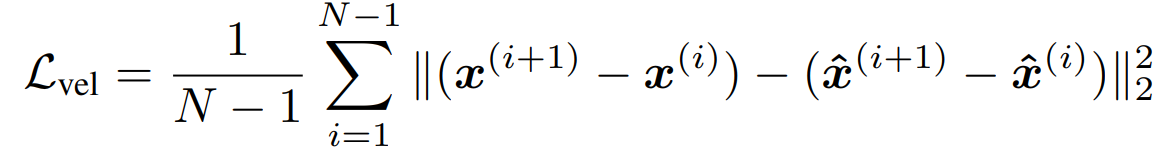
第四部分:计算足部约束损失。通过FK过程,计算去噪后的舞蹈动作,以及舞蹈动作Ground Truth的24关节点坐标的移动速度,取出左脚踝、左脚趾、右脚踝、右脚趾位置,对于预测出contact>0.95的部分,将其速度约束为0,计算MSE,权重取10.942;
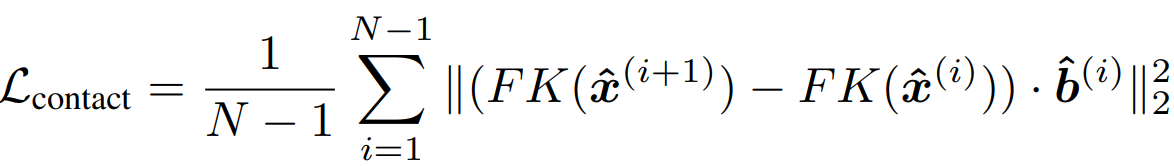
5.3、模型推理
训练阶段,输入和输出都是固定长度(5s)的音乐舞蹈片段;测试阶段,借助Mask Inpainting技巧可实现任意长度的舞蹈生成。
Mask Inpainting基本框架如下图所示:
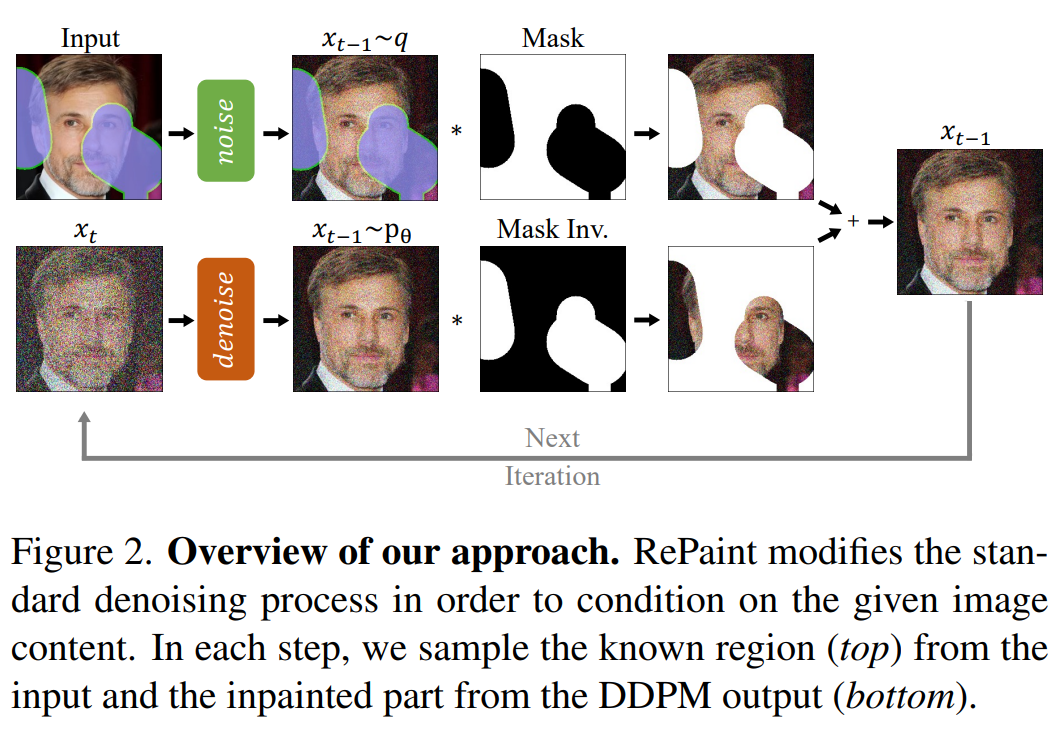
值得注意的是,Mask Inpainting并不能保证最终生成结果和掩码Ground Truth完全一致,为了保持衔接部分的平滑自然,最终生成的掩码位置的结果往往会有些许调整。
在推理阶段,采用standard masked de-noising technique,以及linear interp technique,生成长度任意的舞蹈:
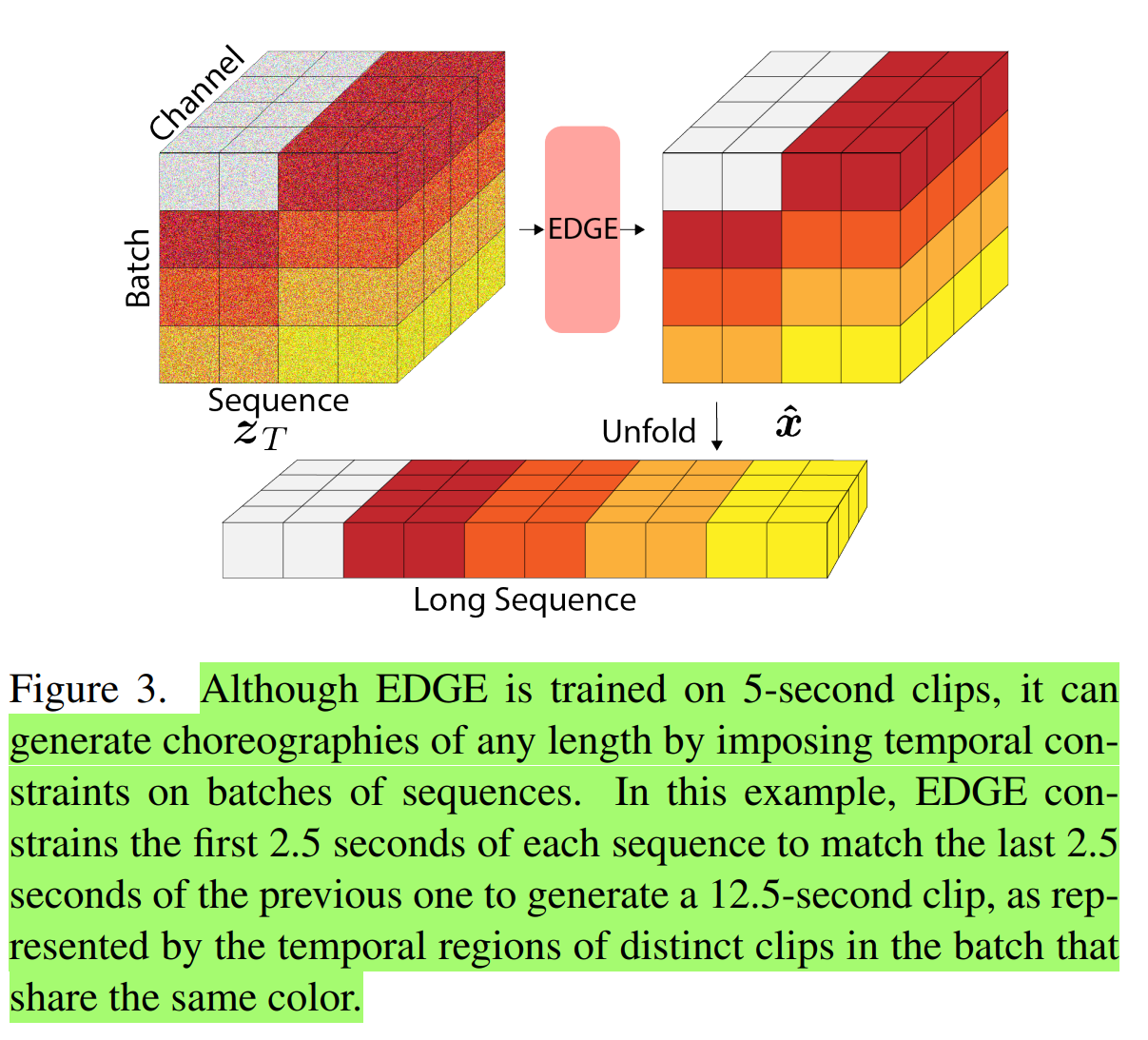
第一步:对于一段长度任意(56s)的音频序列,首先需要通过滑动窗口,重叠移动(步长2.5s)划分成一个个固定长度(5s)的序列;
第二步:对于每段固定长度的序列,提取音频特征,维度(batch,150,4800),其中不同片段被当成独立的样本进行预测,模型输出舞蹈序列(batch,150,151);
第三步:在扩散过程中,强制每个片段的前一半和上一个片段的后一半数值相同,从而实现不同片段之间的衔接;
第四步:合并成一段序列时,采用linear interp技巧,利用当前序列的后一半舞蹈和下一个序列的前一半舞蹈,插值生成最终结果;
总结
EDGE确实是个很优秀的开山之作,不愧是斯坦福大学提出的。借助Diffusion框架,EDGE能够生成的舞蹈动作的种类非常丰富,而且自然流畅,物理意义上合理,能够很好的与节拍对齐,有些可视化结果甚至已经逼近真实舞蹈动作。而且基于扩散框架,EDGE天然具有可编辑性,这为艺术创作留下了巨大的可操作空间,整体框架非常灵活。
不足之处在于,舞蹈生成领域的经典难题:动作滑步、漂移、抖动问题仍然存在,没有得到很好的解决。
源码:https://github.com/Stanford-TML/EDGE
官网可视化:https://edge-dance.github.io/
参考文献
[1] DDPM原理:https://zhuanlan.zhihu.com/p/693535104
[2] DDPM原理:https://blog.csdn.net/weixin_37817275/article/details/129817654
[3] DDIM原理:https://blog.csdn.net/qq_41915623/article/details/135468502
[4] DDIM原理:https://zhuanlan.zhihu.com/p/666552214


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









