







0. 前言
知识点:结构体、sort函数排序、vector迭代器
1. 题目:
【问题描述】
一共6个手机基站,具有记录手机连接基站的能力,6个手机基站分别记为ABCDEF,他们具有自己的覆盖范围且任何两个基站的覆盖范围不相交,基站保存的手机登陆日志包括手机号((11位,用字符串保存)、基站编号、登陆时间(6位数字,用字符串保存)、登出时间(6位,用字符串保存)。
读入某一天多个基站的手机登陆日志信息和一个要查找的人员的手机号,查找与该人员同时空的手机号
输入: 一个N和N条登陆日志信息,最后还有一个要查找人员的手机号输出: 输出与要查找人员时间和地点有重叠的人员信息(即日志信息),依次输出手机号、基站编号、登陆时间和登出时间; 按照登陆时间进行排序,如果登陆时间相同按照手机号进行排序(如果一个人员的登出时间和另一个人员的登陆时间相同也算时间重叠)
2. 测试样例:
输入:
7
11111 A 080000 225959
22222 B 080000 225959
33333 A 100000 110000
44444 B 101000 110000
55555 A 120000 131000
66666 A 225959 235959
77777 A 100000 120000
11111输出:
33333 A 100000 110000
77777 A 100000 120000
55555 A 120000 131000
66666 A 225959 235959
3. 分析:
题目理解起来也费劲,这时候即使要注意时间限制,但也不能着急开始写代码。首先手机基站是ABCDEF,那么数据类型就是char或者string,不要想当然地以为是int。接着,就能确定日志信息都使用字符串即可。考虑到题目中有要求字符串的位数,一开始打算使用char数组来做字符串,但无疑这会大大增加编程难度,一是输入很不好处理,而是排序实现困难。于是先不考虑这个位数限制……直接考虑使用c++的string类。
“查找与该人员同时空的手机号”,这个理解起来真的不容易。直接看输入输出的描述。根据输出描述,需要查找到与查找人员的时间和地点有重合的信息,也就是说判断条件是时间有重合、地点相同。此外,很容易忽略的一点是,查找的目标人员信息未必只有一条!可能多条,也就意味着要做多次判断。并且手机号相同的属于同一个人,就不要输出了!
然后是排序的考虑,如果要自己实现排序的话,非常麻烦,写出来考试都结束一万年了。而且未必写得出来。这里学习使用algorithm库里面的sort函数,sort函数支持vector、string、queue三种迭代器的排序。于是,存储日志信息,可以考虑使用vector,放弃采用结构体数组了。
4. 代码:
#include <iostream>
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
//#define maxsize 1000;
typedef struct log {
//char phone[11];
string phone,
base,
log_time,
exit_time;
}Log;
bool compare(const Log& a, const Log& b);
int main() {
int N;
cin >> N;
vector<Log> logs(N);
for (int i = 0; i < N; i++) {
//Log log = 上面定义的是logs(N),这里就没有必要再新创建Log对象,再加入vector,而是直接访问
cin >> logs[i].phone >> logs[i].base >> logs[i].log_time >> logs[i].exit_time;
}
string find_phone;
cin >> find_phone;
// 查找与目标号码相同的所有日志
vector<Log> target_logs;
for (auto& log : logs) {
if (log.phone == find_phone) {
target_logs.push_back(log);
}
}
// 查找与目标日志的时间地点重合的记录信息
vector<Log> overlap_logs;
for (auto& tar_log : target_logs) {
for(auto & log : logs) {
if ((log.phone != tar_log.phone) && (log.base == tar_log.base) && !(log.log_time > tar_log.exit_time || log.exit_time < log.log_time))
//(log.log_time > tar_log.log_time)&& (log.log_time <tar_log.exit_time)
overlap_logs.push_back(log);
}
}
sort(overlap_logs.begin(), overlap_logs.end(), compare); // 疑问1 sort 与compare函数的逻辑是什么???
// print the outcome
for (auto& log : overlap_logs) {
cout << log.phone << " " << log.base << " " << log.log_time << " " << log.exit_time << endl;
}
return 0;
}
bool compare(const Log& a, const Log& b) {
if (a.log_time == b.log_time) {
return a.phone < b.phone;
}
// 疑问2 字符串可以直接比较吗???逻辑是什么?
return a.log_time < b.log_time;
}5. 总结
(1)vector的不同定义
定义vector容器对象,一般使用` vector<Log> target_logs; ` 语句,这样创建的对象,在后续就要利用push_back函数将数据插入myvec中。
在已知vector容量大小的情况下,可以类似本题中使用`vector<Log> logs(N);`来定义,这样定义出的logs可以理解为大小为N的一个vector数组。这种方法定义的对象,已经用默认的构造函数初始化了,在接下来只需要利用下标访问输入数据即可,比如logs[i].phone,访问第i个的phone数据。若采用上一种方法,则需要先创建一个结构体对象log,输入数据,再push_back入容器。这就是区别。
(2)迭代语法auto& log : logs
auto自动类型转换,会将log自动转换为结构体类型Log。&引用对象,log对象迭代的是logs中元素的引用,在循环中可以访问和修改该对象;如果省略&,则为元素的副本,修改不会同步到原logs中对象。冒号:为迭代关键字,会使log自动迭代logs中的所有元素。
(3)sort函数
参考:https://blog.csdn.net/qq_42410605/article/details/100559877
sort(首元素地址,尾元素地址,比较函数逻辑)
对于vector对象,begin()获取指向首元素的迭代器(类似指针),end()获取尾元素。
对于比较函数,传入两个结构体Log对象,并实现按照登陆时间进行排序,如果登陆时间相同按照手机号进行排序。return a.log_time < b.log_time; 如果小于,返回true,则a排在前面,顺序为按照登录时间从小到大。反之如果为>,则按照从大到小排序,左边的排前面。
如果登录时间相等,则比较手机号码,按号码从小到大排。
bool compare(const Log& a, const Log& b) {
if (a.log_time == b.log_time) {
return a.phone < b.phone;
}
return a.log_time < b.log_time;
}于是,sort函数调用为:sort(overlap_logs.begin(), overlap_logs.end(), compare);
(4)string字符串的比较逻辑
比较的逻辑是看成字符数组,依次按ascii码比较(字典序),看下面测试用例有助于理解。对于本题的登录时间比较,我认为是存在bug的。这是由于比较时间需要两位两位地比较。但勉强能用。
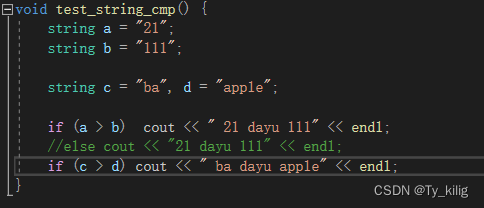
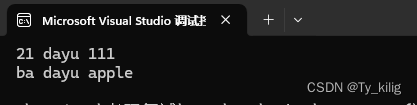















 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









