






NLP基础任务模型-NER
注: 基本全是转载,也都附加了转载链接,侵删。 多谢各位大佬的总结。
- 目录:
- 任务定义
- 简单综述
- 数据集细节总结
- 模型细节总结
- 损失函数计算
总结
NLP实战-中文命名实体识别
超详综述 | 基于深度学习的命名实体识别
目录
1. 全文简介
- NER 任务的常用标注语料
- 现成的 NER 工具
- 三个角度介绍现有研究工作:分布式嵌入表示,文本编码,标签解码;
- 其他研究方向的深度学习方法做 NER
- NER 面临的挑战与机遇
2. NER任务简介
命名实体识别(Named Entity Recognition, NER)是指从自由文本中识别出属于预定义类别的文本片段。 实体归为两类:generic(通用类)和 domain-specific(特定领域类)。
3.NER标注语料库(公开评测集)

重点关注数据集:
4. NER工具
论文对学术界和工业界一些 NER 工具进行汇总,工具中通常都包含预训练模型,可以直接在自己的语料上做实体识别。不过一般研究使用的话(所定义实体类别与工具预定的不符),还需要依据待抽取领域语料再训练模型,或重新训练模型。

5.评价指标 (Evaluation Metric)
论文将 NER 评测指标 P R F1 分为了两类介绍,这也是比赛和论文中通用评测方式:
- Exact-match:严格匹配,范围与类别都正确。其中 F1 值又可以分为 macro-averaged 和 micro-averaged,前者是按照不同实体类别计算 F1,然后取平均;后者是把所有识别结果合在一起,再计算 F1。这两者的区别在于实体类别数目不均衡,因为通常语料集中类别数量分布不均衡,模型往往对于大类别的实体学习较好。
- relaxed match :宽松匹配,简言之,可视为实体位置区间部分重叠,或位置正确类别错误的,都记为正确或按照匹配的位置区间大小评测。
6. 序列标注标签方案
- BIO
- BIOES
基本都逃不脱这两种,B 开始位置、I 中间位置、O 其他类别、S 单字表示一个实体。
句子:西南交通大学位于成都。
预定义实体类别:学校、地点。
上述句子按照BIOES方案标签:
西 南 交 通 大 学 位于 成 都
B-学校 I-学校 I-学校 I-学校 I-学校 E-学校 O O B-地点 E-地点
7.四类常用NER方法
- 规则模板,不需要标注数据,依赖于人工规则;
- 无监督学习方法,不需要标注数据,依赖于无监督学习算法;
- 基于特征的有监督学习算法,依赖于特征工程; CRF++
- 深度学习方法。
8.基于规则方法
- 特定领域词典,其中还包括同义林词典;
- 句法词汇模板;
- 正则表达式;
论文列出了一些基于规则的 NER 系统:LaSIE-II, NetOwl, Facile, SAR, FASTUS, and LTG。总的来说,当词汇表足够大时,基于规则的方法能够取得不错效果。但总结规则模板花费大量时间,且词汇表规模小,且实体识别结果普遍高精度、低召回。
9.无监督学习方法
主要是基于聚类的方法,根据文本相似度得到不同的簇,表示不同的实体类别组。常用到的特征或者辅助信息有词汇资源、语料统计信息(TF-IDF)、浅层语义信息(分块NP-chunking)等。
10. 基于特征的有监督学习(传统机器学习)
NER 任务可以是看作是 token 级别的多分类任务或序列标注任务,深度学习方法也是依据这两个任务建模。 (这整个任务做法有什么区别吗? )
特征工程:word 级别特征(词法特征、词性标注等),词汇特征(维基百科、DBpdia 知识),文档及语料级别特征。 (分别怎么建模和使用呢? )
机器学习算法:隐马尔可夫模型 HMM、决策树 DT、最大熵模型 MEM、最大熵马尔科夫模型 HEMM、支持向量机 SVM、条件随机场 CRF。(除了CRF和HMM其他方法具体都是怎样做的呢? )
11.深度学习方法
终于进入正题,下文将按照以下四点,详细介绍基于深度学习的 NER 方法。
- 深度学习优势
- 分布式表示
- 上下文编码结构
- 标签解码结构
11.1 深度学习优势
不能算深度学习做 NER 的优势,深度学习解决其他问题也是这些亮点。
- 强大的向量表示能力;
- 神经网络的强大计算能力;
- DL 从输入到输出的非线性映射能力;
- DL 无需复杂的特征工程,能够学习高维潜在语义信息;
- 端到端的训练方式。
11.2 分布式表示
-
词级别表示word-level representation
首先 Mikolov 提出的 word2vec(两种框架 CBOW 和 skip-gram),斯坦福的 Glove,Facebook 的 fasttext 和 SENNA。使用这几种词嵌入方式,一些研究工作使用不同语料进行训练,如生物医学领域PubMed、NYT 之类。 -
字符级别表示 character-level representation
字符级别通常是指英文或者是其他具备自然分隔符语种的拆开嵌入,在中文中指字级别嵌入,字符嵌入主要可以降低 OOV 率。文中给出了两种常用的字符级别嵌入方式,分别为 CNN、RNN。
着重提一下 18 年 COLING 的一项工作《Contextual String Embeddings for Sequence Labeling》,使用字符级别的神经语言模型产生上下文相关的文本嵌入。大致思路为使用双向RNN编码字符级别嵌入,将一个词的前向和后向隐层状态与词嵌入拼接作为最终词嵌入向量,如下图所示。

3. 混合信息表示 hybrid representation
除了词级别表示、字符级别表示外,一些研究工作还嵌入了其他一些语义信息,如词汇相似 度、词性标注、分块、语义依赖、汉字偏旁、汉字拼音等。此外,还有一些研究从多模态学习出发,通过模态注意力机制嵌入视觉特征。论文也将 BERT 归为这一类,将位置嵌入、token 嵌入和段嵌入看作是混合信息表示。
11.3 上下文编码
包括了卷积网络 CNN、循环网络 RNN、递归网络、Transformer。
11.3.1 CNN
基本框架如下图所示,句子经过 embedding 层,一个 word 被表示为 N 维度的向量,随后整个句子表示使用卷积(通常为一维卷积)编码,进而得到每个 word 的局部特征,再使用最大池化操作得到整个句子的全局特征,可以直接将其送入解码层输出标签,也可以将其和局部特征向量一起送入解码层。
11.3.2 循环神经网络 RNN
常用的循环神经网络包括 LSTM 和 GRU,在 NLP 中常使用双向网络 BiRNN,从左到右和从右到左两个方向提取问题特征。

11.3.4 Transformer
Google 的一篇《Attention is all you need》将注意力机制推上新的浪潮之巅,于此同时 transformer 这一不依赖于 CNN、RNN 结构,纯堆叠自注意力、点积与前馈神经网络的网络结构也被大家所熟知。此后的研究证明,transformer 在长距离文本依赖上相较 RNN 有更好的效果。
11.3.5 神经语言模型
- ELMO
- BERT
- GPT
- GPT2
- XLNET
- ALBERT
- RoBERTa
11.4 解码层
- MLP+softmax
- CRF
- RNN
- Pointer Network
对于 1、2 应该没什么要说的常规操作,着重看一下 3 和 4。使用 RNN 解码,框架图如下所示。文中所述当前输出(并非隐藏层输出)经过 softmax 损失函数后输入至下一时刻 LSTM 单元,所以这是一个局部归一化模型。
使用指针网络解码,是将 NER 任务当作先识别“块”即实体范围,然后再对其进行分类。指针网络通常是在 Seq2seq 框架中,如下图所示。

12.其他研究方向的NER方法
下面列出各类研究方向的 NER 方法,若想细致了解每个方向的文献,请移步原文。
- 多任务学习 Multi-task Learning
- 深度迁移学习 Deep Transfer Learning
- 深度主动学习 Deep Active Learning
- 深度强化学习 Deep Reinforcement Learning
- 深度对抗学习 Deep Adversarial Learning
- 注意力机制 Neural Attention
13.NER任务的挑战与机遇
13.1 挑战
- 数据标注
- 非正式文本(评论、论坛发言、tweets 或朋友圈状态等),未出现过的实体。
13.2 机遇与未来可研究方向
- 多类别实体
- 嵌套实体
- 实体识别与实体链接联合任务
- 利用辅助资源进行基于深度学习的非正式文本 NER(补充一点,知识图谱方向)
- NER模型压缩
- 深度迁移学习 for NER
损失函数部分
- 类似对话生成等、序列标注是不是计算loss时候也是将整句话的每个单词的loss进行求和。
也就是: 针对每个单词进行交叉熵计算完了再求和。
浅谈嵌套命名实体识别(Nested NER)

2.2 Nested NER
2.2.1 将分类任务的目标从单标签变成多标签
一个容易想到的解决方式是:Schema 不变,模型也不变,将输出从单分类转变为多分类:即在最后分类的时候,从输出一个类到输出所有满足一个指定阈值 的所有类。更为具体地,存在以下两种方案:
- [1] 完全不改变 Schema,只是在输入训练集的时候,训练集中的 label 从原来的 one-hot 编码形式变成一个指定类别的均匀分布;在训练时将损失函数改为 BCE 或 KL-divergence;在进行推理时,给定一个 hard threshold,所有概率超过这个阈值的类别都会被预测出来,当做这个 token 的类。
- [2] 修改 Schema,将可能共同出现的所有类别两两组合,产生新的标签(如:将 B-Location与 B-Organization 组合起来,构造一个新的标签 B-Loc|Org);这样做的好处是最后的分类任务仍然是一个单分类,因为所有可能的分类目标我们都在 Schema 中覆盖了。
我相信在这些年探索中,这个方案是有学者研究过的,因为它简单易行,改动也小;不过除了 NAACL18 与 ACL19 中的两篇文章仔细探讨了这些方案以外,我很少有见到有使用这种思路解决问题的 paper。因为它存在一些比较明显的问题:
- 仅针对第一种实现方式)模型学习的目标设置过难,阈值定义比较主观,很难泛化;
- 仅针对第二种实现方式)指数级增加了标签,导致分布过于稀疏,很难学习;对于多层嵌套,需要定义非常多的复合标签;
- 以及最初的问题:修改后的 Schema 预测的结果,复原回实体的时候又不再具有唯一性了。
当然,我们仍然能够给模型添加规则与约束,来一一解决这些问题,具体内容在论文中有相应的阐述。
2.2.2 修改模型的Decode过程
在这里,Decode 过程指的是基于模型输出的 token 表示来给 token 分类的过程,在 Sequence Labeling 中指的是 FFN + Softmax/CRF + Argmax 这一套操作。
严格来说,解决方案 1 的第一个实现方式也算是非常 naive 的修改了 Decode 过程,不过在这里我们讨论一些更加有效的方案。
值得注意的是,修改 Decoder 的目的是为了保证能够给一个 token 同时赋予多个类别,所以我们仍然将下面的方案视作 Sequence Labeling 任务(尽管最后输出的 label list 长度可能与 token 的数量不同,但这是因为由原来的单分类变成了多分类所必然导致的)。
-
既然直接使用 FFN 映射做单分类没法解决嵌套问题,做多分类又不容易做work,那是否可以考虑使用生成式的方法,如 seq2seq 中的 Decoder 来逐个生成每个 token 的标签?使用 Decoder 能够将输入的 token 数量与输出的类别数量解绑,允许给token打上超过一个的标签——但是与原来的生成方法不同,除了使用特殊字符[EOS](end of sentence)来标识整个生成过程结束以外,我们需要引入一个特殊字符[EOW](end of word)来标识接下来生成的是属于下一个 token 的标签。
-
使用分层的方式对token的表示进行预测也是一个非常有意思的方案:如果一次分类无法解决实体嵌套的问题,那就对第一次的分类结果继续做分类,如是迭代,直到达到最大迭代次数或是不再有新的实体产生为止。这种解决方案存在的问题是对 Decoder 的学习要求较高,如果前面的迭代过程中出现了错判,这个问题可能会传递到后续迭代过程中。
这一类方法相较于普通的多标签分类,从任务本身的角度来进行设计,通过横向(序列生成)与纵向(分层标注)两个层面修改了原始的 Sequence Labeling 模型将输入 token 与输出 label 强制绑定的形式。
2.2.3 抛弃Sequence Labeling
最后一种解决嵌套 NER 问题的方式可以叫做"丢掉序列标注,全面拥抱 Multi-Stage" 。
我们已经在上文中多次提到,序列标注任务是天然不支持给一个 token 赋予多个标签的,尽管我们已经进行了多个层面的修饰,使它能够应用到多标签分类上。
但是既然它应用到 Nested 任务上时效果并不突出,也没有其不可替代性,为什么不直接舍弃掉这个任务形式,尝试其它的解决方案呢?
撇开原来的 NER 解决方案,从头考虑一个实体识别的方案,我们仍然从一个非常 naive 的 proposal 出发:


3.相关Paper选读
3.1 逐个token的解析:基于状态转换(Transition)的方法
3.2 基于超图(Hypergraph)的方法
3.3 基于阅读理解的方法
NER难点整理及解决
难点一:命名『命名实体』
- 数量无穷。
- 构词灵活
- 类别模糊
难点二:实体的无穷
- 结构性较强的命名实体: 正则表达式
- 较短的命名实体,如人名: 分词+词性标注
难点三:歧义的消解
上下文语义信息
难点四:边界的界定
-
三种把词表信息融入模型的方法
-
Chinese NER Using Lattice LSTM
-
CNN-Based Chinese NER with Lexicon Rethinking
-
Simplify the Usage of Lexicon in Chinese NER
难点五:标注数据缺失
- 找相似领域的有标记数据做领域迁移。
- 用远程监督的思路,用领域词典生成标记数据
⭐⭐如何有效提升中文NER性能?词汇增强方法总结
众所周知,与英文NER相比,中文NER通常采取基于字符的方式。究其缘由,由于中文分词存在误差,基于字符的NER系统通常好于基于词汇(经过分词)的方法。而引入词汇信息(词汇增强)的方法,通常能够有效提升中文NER性能。本文对「词汇增强」的系列方法进行介绍。
一、为什么要进行词汇增强?
虽然基于字符的NER系统通常好于基于词汇(经过分词)的方法,但基于字符的NER没有利用词汇信息,而词汇边界对于实体边界通常起着至关重要的作用。
如何在基于字符的NER系统中引入词汇信息,是近年来NER的一个研究重点。本文将这种引入词汇的方法称之为「词汇增强」,以表达引入词汇信息可以增强NER性能。
从另一个角度看,由于NER标注数据资源的稀缺,BERT等预训练语言模型在一些NER任务上表现不佳。特别是在一些中文NER任务上,词汇增强的方法会好于或逼近BERT的性能。因此,关注「词汇增强」方法在中文NER任务很有必要。
二、词汇增强方法有哪些?
近年来,基于词汇增强的中文NER主要分为2条主线[9]:
- Dynamic Architecture:设计一个动态框架,能够兼容词汇输入;
- Adaptive Embedding :基于词汇信息,构建自适应Embedding;
本文按照上述2条主线,将近年来各大顶会的相关论文归纳如下:

Dynamic Architecture范式
Dynamic Architecture范式通常需要设计相应结构以融入词汇信息。
1. Lattice LSTM:Chinese NER Using Lattice LSTM(ACL2018)
本文是基于词汇增强方法的中文NER的开篇之作,提出了一种Lattice LSTM以融合词汇信息。具体地,当我们通过词汇信息(词典)匹配一个句子时,可以获得一个类似Lattice的结构。
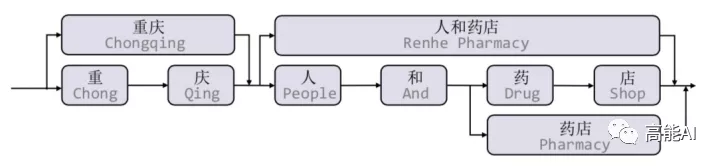
Lattice是一个有向无环图,词汇的开始和结束字符决定了其位置。Lattice LSTM结构则融合了词汇信息到原生的LSTM中:

如上图所示,Lattice LSTM引入了一个word cell结构,对于当前的字符,融合以该字符结束的所有word信息,如对于「店」融合了「人和药店」和「药店」的信息。对于每一个字符,Lattice LSTM采取注意力机制去融合个数可变的word cell单元,其主要的数学形式化表达为:
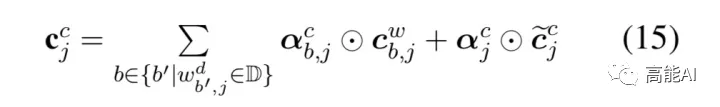
本文不再堆砌繁杂的数学公式,具体看参考原论文。需要指出的是,当前字符有词汇融入时,则采取上述公式进行计算;如当前字符没有词汇时,则采取原生的LSTM进行计算。当有词汇信息时,Lattice LSTM并没有利用前一时刻的记忆向量
c
j
−
1
c
c^c_{j-1}
cj−1c,即不保留对词汇信息的持续记忆。
Lattice LSTM 的提出,将词汇信息引入,有效提升了NER性能;但其也存在一些缺点:
- 计算性能低下,不能batch并行化。究其原因主要是每个字符之间的增加word cell(看作节点)数目不一致;
- 信息损失:1)每个字符只能获取以它为结尾的词汇信息,对于其之前的词汇信息也没有持续记忆。如对于「药」,并无法获得‘inside’的「人和药店」信息。2)由于RNN特性,采取BiLSTM时其前向和后向的词汇信息不能共享。
- 可迁移性差:只适配于LSTM,不具备向其他网络迁移的特性。
2.LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking(IJCAI2019)

Lattice LSTM采取RNN结构,导致其不能充分利用GPU进行并行化。此外,Lattice LSTM无法有效处理词汇信息冲突问题,如上图所示:字符 [长] 可以匹配到词汇 [市长] 和 [长隆],不同的匹配会导致[长] 得到不同的标签,而对于RNN结构:仅仅依靠前一步的信息输入、而不是利用全局信息,无法有效处理这一冲突问题。显而易见,对于中文NER,这种冲突问题很常见,在不参考整个句子上下文和高层信息的前提下很难有效解决。

本篇论文LR-CNN为解决这一问题,提出了Lexicon-Based CNNs和Refining Networks with Lexicon Rethinking:
- Lexicon-Based CNNs:采取CNN对字符特征进行编码,感受野大小为2提取bi-gram特征,堆叠多层获得multi-gram信息;同时采取注意力机制融入词汇信息;
- Refining Networks with Lexicon Rethinking:由于上述提到的词汇信息冲突问题,LR-CNN采取rethinking机制增加feedback layer来调整词汇信息的权值:具体地,将高层特征最为输入通过注意力模块调节每一层词汇特征分布。
如上图,高层特征得到的 [广州市] 和 [长隆]会降低 [市长] 在输出特征中的权重分布。最终对每一个字符位置提取调整词汇信息分布后的multi-gram特征,喂入CRF中解码。
LR-CNN最终相比于Lattice LSTM加速3.21倍,但LR-CNN仍然计算复杂,并且不具备可迁移性。
3. CGN: Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network( EMNLP2019)

由于Lattice LSTM存在信息损失,特别是无法获得‘inside’的词汇信息。针对这一问题,本篇论文构建了基于协作的图网络,由编码层、图网络层、融合层、解码层组成。在图网络层,构建了三种不同的建图方式:
- Word-Character Containing graph (C-graph):字与字之间无连接,词与其inside的字之间有连接。
- Word-Character Transition graph(T-graph):相邻字符相连接,词与其前后字符连接。
- Word-Character Lattice graph(L-graph):相邻字符相连接,词与其开始结束字符相连。
图网络层通过Graph Attention Network(GAN)进行特征提取,提取3种图网络中的前n个字符节点的特征:
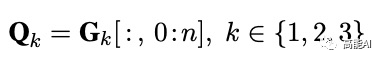
特征融合则将基于字符的上下文表征H与图网络表征加权融合:
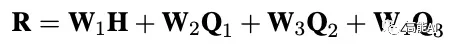
4.LGN:A Lexicon-Based Graph Neural Network for Chinese NER(EMNLP2019)

本篇论文与LR-CNN出发点类似,Lattice LSTM这种RNN结构仅仅依靠前一步的信息输入,而不是利用全局信息,如上图所示:字符 [流]可以匹配到词汇 [河流] 和 [流经]两个词汇信息,但Lattice LSTM却只能利用 [河流] ;字符 [度]只能看到前序信息,不能充分利用 [印度河] 信息,从而造成标注冲突问题。

本篇论文通过采取 lexicon-based graph neural network (LGN)来解决上述问题。如上图所示,将每一个字符作为节点,匹配到的词汇信息构成边。通过图结构实现局部信息的聚合,并增加全局节点进行全局信息融入。聚合方式采取Multi-Head Attention,具体计算公式可参考原论文。
5. FLAT: Chinese NER Using Flat-Lattice Transformer(ACL2020)
本篇论文来自 @邱锡鹏 老师团队。通过对上述4篇论文的介绍,我们可以发现:
- Lattice-LSTM和LR-CNN采取的RNN和CNN结构无法捕捉长距离依赖,而动态的Lattice结构也不能充分进行GPU并行。
- 而CGN和LGN采取的图网络虽然可以捕捉对于NER任务至关重要的顺序结构,但这两者之间的gap是不可忽略的。其次,这类图网络通常需要RNN作为底层编码器来捕捉顺序性,通常需要复杂的模型结构

众所周知,Transformer采取全连接的自注意力机制可以很好捕捉长距离依赖,由于自注意力机制对位置是无偏的,因此Transformer引入位置向量来保持位置信息。受到位置向量表征的启发,这篇论文提出的FLAT设计了一种巧妙position encoding来融合Lattice 结构,具体地,如上图所示,对于每一个字符和词汇都构建两个head position encoding 和 tail position encoding,可以证明,这种方式可以重构原有的Lattice结构。也正是由于此,FLAT可以直接建模字符与所有匹配的词汇信息间的交互,例如,字符[药]可以匹配词汇[人和药店]和[药店]。
因此,我们可以将Lattice结构展平,将其从一个有向无环图展平为一个平面的Flat-Lattice Transformer结构,由多个span构成:每个字符的head和tail是相同的,每个词汇的head和tail是skipped的。

在知乎专栏文章《如何解决Transformer在NER任务中效果不佳的问题?》,我们介绍了对于Tranformer结构,绝对位置编码并不适用于NER任务。因此,FLAT这篇论文采取XLNet论文中提出相对位置编码计算attention score:
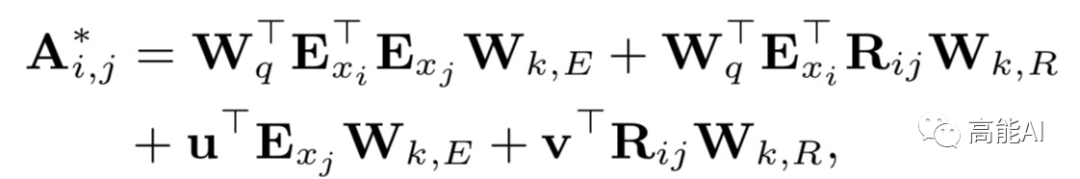
论文提出四种相对距离表示token之间的关系,同时也考虑字符和词汇之间的关系:

综上,FLAT采取这种全连接自注意力结构,可以直接字符与其所匹配词汇间的交互,同时捕捉长距离依赖。如果将字符与词汇间的attention进行masked,性能下降明显,可见引入词汇信息对于中文NER 的重要性。
此外,相关实验表明,FLAT有效的原因是:新的相对位置encoding有利于定位实体span,而引入词汇的word embedding有利于实体type的分类。
Adaptive Embedding范式
Adaptive Embedding范式仅在embedding层对于词汇信息进行自适应,后面通常接入LSTM+CRF和其他通用网络,这种范式与模型无关,具备可迁移性。
1. WC-LSTM: An Encoding Strategy Based Word-Character LSTM for Chinese NER Lattice LSTM(NAACL2019)

Lattice LSTM中每个字符只能获取以它为结尾的词汇数量是动态的、不固定的,这也是导致Lattice LSTM不能batch并行化的原因。WC-LSTM为改进这一问题,采取Words Encoding Strategy,将每个字符为结尾的词汇信息进行固定编码表示,即每一个字符引入的词汇表征是静态的、固定的,如果没有对应的词汇则用代替,从而可以进行batch并行化。(如果有多个词汇呢? )
这四种encoding策略分别为:最短词汇信息、最长词汇信息、average、self-attenion。以「average」为例:即将当前字符引入所有相关的词汇信息对应的词向量进行平均。
WC-LSTM仍然存在信息损失问题,无法获得‘inside’的词汇信息,不能充分利用词汇信息。虽然是Adaptive Embedding范式,但WC-LSTM仍然采取LSTM进行编码,建模能力有限、存在效率问题。
2.Multi-digraph: A Neural Multi-digraph Model for Chinese NER with Gazetteers(ACL2019)
不同于其他论文引入词汇信息的方式是基于一个词表(由论文Lattice LSTM 提供,没有实体标签,通常需要提取对应的word embedding),本篇论文引入词汇信息的方式是利用实体词典(Gazetteers,含实体类型标签)。

虽然引入实体词典等有关知识信息对NER性能可能会有所帮助,但实体词典可能会包含不相关甚至错误的信息,这会损害系统的性能。如上图所示,利用4个实体词典:「PER1」、「PER2」、「LOC1」、「LOC2」进行匹配,错误实体就有2个。

为了更好的利用词典信息,本文提出了一种多图结构更好地显示建模字符和词典的交互。如上图所示,结合自适应的Gated Graph Sequence Neural Networks (GGNN)和LSTM+CRF,基于上下文信息对来自不同词典的信息进行加权融合,解决词典匹配冲突的问题。()
具体地,本文通过图结构建模Gazetteers信息,关键在于怎么融入不同词典的信息。上述图结构中「边」的label信息即包含字符间的连接信息,也包含来自不同m个Gazetteers的实体匹配信息,共有L个label:
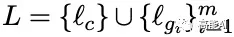
而传统的GGNN不能处理带有不同label信息的「边」,为了能够处理上述的多图结构,本文将邻接矩阵A扩展为包括不同标签的边,对边的每一个label分配相应的可训练参数:
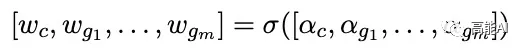
上述图结构的隐状态采用GRU更新,具体更新方式可参考原论文。最后,将基于GGNN提取字符所对应的特征表示喂入LSTM+CRF中。
3. Simple-Lexicon:Simplify the Usage of Lexicon in Chinese NER(ACL2020) [不太懂]
由上述分析可以发现Lattice LSTM只适配于LSTM,不具备向其他网络迁移的特性,同样Lattice LSTM存在的信息损失也不容小觑。本篇论文为避免设计复杂的模型结构、同时为便于迁移到其他序列标注框架,提出了一种在embedding层简单利用词汇的方法。本文先后对比了三种不同的融合词汇的方式:
第一种:Softword

如上图所示,Softword通过中文分词模型后,对每一个字符进行BMESO的embedding嵌入。显而易见,这种Softword方式存在由分词造成的误差传播问题,同时也无法引入词汇对应word embedding。
第二种:ExtendSoftword

ExtendSoftword则将所有可能匹配到的词汇结果对字符进行编码表示。如上图中,对于字符「山」来说,其可匹配到的词汇有中山、中山西、山西路,「山」隶属 {B,M,E}。论文对于字符对应的词汇信息按照BMESO编码构建5维二元向量,如「山」表示为[1,1,1,0,0].
ExtendSoftword也会存在一些问题:
1. 仍然无法引入词汇对应的word embedding;
2. 也会造成信息损失,无法恢复词汇匹配结果,例如,假设有两个词汇列表[中山,山西,中山西路]和[中山,中山西,山西路],按照ExtendSoftword方式,两个词汇列表对应字符匹配结果是一致的;换句话说,当前ExtendSoftword匹配结果无法复原原始的词汇信息是怎样的,从而导致信息损失。
第三种:Soft-lexicon

为了解决Softword和ExtendSoftword存在的问题,Soft-lexicon对当前字符,依次获取BMES对应所有词汇集合,然后再进行编码表示。

由上图可以看出,对于字符[语],其标签B对应的词汇集合涵盖[语言,语言学];标签M对应[中国语言];标签E对应[国语、中国语];标签S对应[语]。当前字符引入词汇信息后的特征表示为:
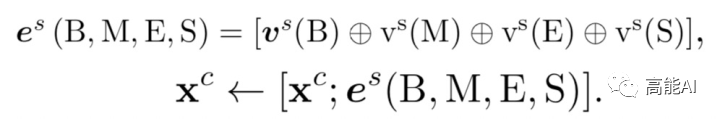
很容易理解,上述公式则将BMES对应的词汇编码与字符编码进行拼接,其计算方式为:
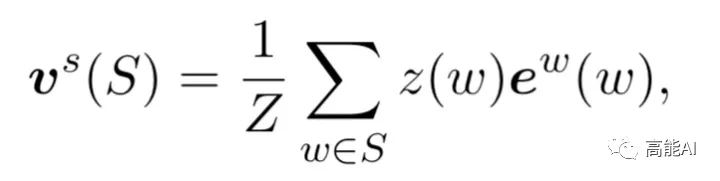
S为词汇集合, z(w)代表词频。考虑计算复杂度,本文没有采取动态加权方法,而采取如同上式的静态加权方法,即:对词汇集合中的词汇对应的word embedding通过其词频大小进行加权。词频根据训练集和测试集可离线统计。
综上可见,Soft-lexicon这种方法没有造成信息损失,同时又可以引入word embedding,此外,本方法的一个特点就是模型无关,可以适配于其他序列标注框架。
三、总结对比:结果分析
通过第二部分对于「词汇增强」方法主要论文的介绍,我们可以发现无论是Dynamic Architecture还是Adaptive Embedding,都是想如何更好的融入词汇信息。这些方法的出发点无外于两点:
1)如何更充分的利用词汇信息、最大程度避免词汇信息损失;
2)如何设计更为兼容词汇的Architecture,加快推断速度。
下面对于上述「词汇增强」方法进行汇总:

ACL2020中的两篇论文FLAT和Simple-Lexicon分别对应于Dynamic Architecture和Adaptive Embedding,这两种方法相比于其他方法:
1)能够充分利用词汇信息,避免信息损失;
2)FLAT不去设计或改变原生编码结构,设计巧妙的位置向量就融合了词汇信息;
Simple-Lexicon对于词汇信息的引入更加简单有效,采取静态加权的方法可以提前离线计算。
最后,我们来看一下,上述各种「词汇增强」方法在中文NER任务上的性能:

上图可以发现:总的来看,ACL2020中的FLAT和Simple-Lexicon效果最佳。具体地说:
- 引入词汇信息的方法,都相较于baseline模型biLSTM+CRF有较大提升,可见引入词汇信息可以有效提升中文NER性能。
- 采用相同词表对比时,FLAT和Simple-Lexicon好于其他方法。
- 结合BERT效果会更佳
除了上述中文NER任务,笔者还在医疗NER任务(CCKS2019)上进行了简单实验:

同样也可以发现,词汇增强可有效提升中文NER性能。而在推断速度方面,FLAT论文也与其他方法进行了对比,在指标领先的同时推断速度明显优于其他方法。

工业界求解NER问题的12条黄金法则
众所周知,命名实体识别(Named Entity Recognition,NER)是一项基础而又重要的NLP词法分析任务,也往往作为信息抽取、问答系统、机器翻译等方向的或显式或隐式的基础任务。在很多人眼里,NER似乎只是一个书本概念,跟句法分析一样存在感不强。一方面是因为深度学习在NLP领域遍地开花,使得智能问答等曾经复杂的NLP任务,变得可以端到端学习,于是分词、词性分析、NER、句法分析等曾经的显式任务都隐式地编码到了大型神经网络的参数中;另一方面,深度学习流行之后,NER问题相比之前有了比较长足的进步,LSTM+CRF的模式基本成为业内标配,很多人认为“这个事情应该差不多了”。
但!是!
真正在工业界解决NLP业务问题的NLPer,往往发现事情远没法这样轻描淡写。在真实的工业界场景中,通常面临标注成本昂贵、泛化迁移能力不足、可解释性不强、计算资源受限等问题,想要将NER完美落(bian)地(xian)可不简单,那些在经典benchmark上自称做到SOTA的方法放在现实场景中往往“也就那样”。以医疗领域为例:(越来越感觉是 AIG-知识图谱部-医疗组的同学写的了)
-
不同医院、不同疾病、不同科室的文本描述形式不一致,而标注成本又很昂贵,一个通用的NER系统往往不具备“想象中”的泛化迁移能力。当前的NER技术在医疗领域并不适合做成泛化的工具。
-
由于医疗领域的严肃性,我们既要知其然、更要知其所以然:NER系统往往不能采用“一竿子插到底”的黑箱算法,处理过程应该随着处理对象的层次和深度而逐步叠加模块,下级模块使用上级结果,方便进行迭代优化、并具备可解释性,这样做可解耦医学事件、便于进行医学实体消歧。
-
仅仅使用统计模型的NER系统往往不是万能的,医疗领域相关的实体词典和特征挖掘对NER性能也起着关键作用。此外,NER结果往往不能直接使用,还需进行医学术语标准化。
-
由于医院数据不可出院,需要在院内部署NER系统。而通常医院内部的GPU计算资源又不是很充足(成本问题),我们需要让机器学习模型又轻又快(BERT上不动哇),同时要更充分的利用显存。
以上种种困难,导致了工业界场景求解NER问题时都难以做到BERT finetune一把就能把问题解决,总之
那些口口声声遇事不决上BERT的人们,应该像我一样,看着你们在NER问题上翻车
几天前,卖萌屋的自然语言处理讨论群内就命名实体识别问题进行了一番激烈的讨论,由于讨论持续了接近2小时,这里就不贴详细过程了(省略8k字)。
经过一番激烈的辩论,最后卖萌屋的作者杰神(JayLou娄杰)就讨论中出现的若干问题给出了工业界视角下的实战建议(每一条都是实打实的实战经验哇)。
杰神首先分享了他在医疗业务上做NER的七条经验教训:
-
提升NER性能(performance)的⽅式往往不是直接堆砌⼀个BERT+CRF,这样做不仅性能不一定会好,推断速度也非常堪忧;就算直接使用BERT+CRF进行finetune,BERT和CRF层的学习率也不要设成一样,让CRF层学习率要更大一些(一般是BERT的5~10倍),要让CRF层快速学习。
-
在NER任务上,也不要试图对BERT进⾏蒸馏压缩,很可能吃⼒不讨好。
-
NER任务是⼀个重底层的任务,上层模型再深、性能提升往往也是有限的(甚至是下降的);因此,不要盲目搭建很深的网络,也不要痴迷于各种attention了。
-
NER任务不同的解码方式(CRF/指针网络/Biaffine[1])之间的差异其实也是有限的,不要过分拘泥于解码⽅式。
-
通过QA阅读理解的方式进行NER任务,效果也许会提升,但计算复杂度上来了,你需要对同⼀⽂本进行多次编码(对同⼀文本会构造多个question)。
-
设计NER任务时,尽量不要引入嵌套实体,不好做,这往往是一个长尾问题。
-
不要直接拿Transformer做NER,这是不合适的,详细可参考TENER[2]。
之后,杰神在群里分享了工业界中NER问题的正确打开⽅式:
非常直接的1层lstm+crf!
-
如何快速有效地提升NER性能? 如果这么直接的打开方式导致NER性能达不到业务目标,这一点也不意外,这时候除了badcase分析,不要忘记一个快速提升的重要手段:规则+领域词典。在垂直领域,一个不断积累、不断完善的实体词典对NER性能的提升是稳健的,基于规则+词典也可以快速应急处理一些badcase;对于通⽤领域,可以多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER。此外,怎么更好地将实体词典融入到NER模型中,也是一个值得探索的问题(如嵌入到图神经网络中提取特征[3])。
-
如何在模型层面提升NER性能? 如果想在模型层面(仍然是1层lstm+crf)搞点事情,上文讲过NER是一个重底层的任务,我们应该集中精力在embedding层下功夫,引入丰富的特征:比如char、bigram、词典特征、词性特征、elmo等等,还有更多业务相关的特征;在垂直领域,如果可以预训练一个领域相关的字向量&语言模型,那是最好不过的了~总之,底层的特征越丰富、差异化越大越好(构造不同视角下的特征)。
-
如何构建引入词汇信息(词向量)的NER? 我们知道中文NER通常是基于字符进行标注的,这是由于基于词汇标注存在分词误差问题。但词汇边界对于实体边界是很有用的,我们该怎么把蕴藏词汇信息的词向量“恰当”地引入到模型中呢?一种行之有效的方法就是信息无损的、引入词汇信息的NER方法,我称之为词汇增强,可参考《中文NER的正确打开方式:词汇增强方法总结》[4]。ACL2020的Simple-Lexicon[5]和FLAT[6]两篇论文,不仅词汇增强模型十分轻量、而且可以比肩BERT的效果。
将词向量引入到模型中,一种简单粗暴的做法就是将词向量对齐到相应的字符,
然后将字词向量进行混合,但这需要对原始文本进行分词(存在误差),性能提升通常是有限的。
-
如何解决NER实体span过长的问题? 如果NER任务中某一类实体span比较长(⽐如医疗NER中的⼿术名称是很长的),直接采取CRF解码可能会导致很多连续的实体span断裂。除了加入规则进行修正外,这时候也可尝试引入指针网络+CRF构建多任务学习(指针网络会更容易捕捉较长的span,不过指针网络的收敛是较慢的,可以试着调节学习率)。
-
如何客观看待BERT在NER中的作用? 对于工业场景中的绝大部分NLP问题(特别是垂直领域),都没有必要堆资源。但这绝不代表BERT是“一无是处”的,在不受计算资源限制、通用领域、小样本的场景下,BERT表现会更好。我们要更好地去利用BERT的优势:
a. 在低耗时场景中,BERT可以作为一个“对标竞品”,我们可以采取轻量化的多种策略组合去逼近甚至超越BERT的性能;
b. 在垂直领域应用BERT时,我们首先确认领域内的语料与BERT原始的预训练语料之间是否存在gap,如果这个gap越大,那么我们就不要停止预训练:继续进行领域预训练、任务预训练。
c.在小样本条件下,利用BERT可以更好帮助我们解决低资源问题:比如基于BERT等预训练模型的文本增强技术[7],又比如与主动学习、半监督学习、领域自适应结合(后续详细介绍)。
d. 在竞赛任务中,可以选取不同的预训练语⾔模型在底层进行特征拼接。具体地,我们可以将char、bigram和BERT、XLNet等一起拼接喂入1层lstm+crf中。语⾔模型的差异越⼤,效果越好。如果需要对语言模型finetune,需要设置不同的学习率。
-
如何冷启动NER任务? 如果⾯临的是⼀个冷启动的NER任务,业务问题定义好后,首先要做的就是维护好一个领域词典,而不是急忙去标数据、跑模型;当基于规则+词典的NER系统不能够满足业务需求时,才需要启动人工标注数据、构造机器学习模型。当然,我们可以采取一些省成本的标注方式,如结合领域化的预训练语言模型+主动学习,挖掘那些“不确定性高”、并且“具备代表性”的高价值样本(需要注意的是,由于NER通常转化为一个序列标注任务,不同于传统的分类任务,我们需要设计一个专门针对序列标注的主动学习框架)。
-
如何有效解决低资源NER问题? 如果拿到的NER标注数据还是不够,又不想标注人员介入,这确实是一个比较困难的问题。低资源NLP问题的解决方法通常都针对分类任务,这相对容易一些,如可以采取文本增强、半监督学习等方式,详情可参考 《如何解决NLP中的少样本困境》 。而这些解决低资源NLP问题的方法,往往在NER中提升并不明显。NER本质是基于token的分类任务,其对噪声极其敏感的。如果盲目应用弱监督方法去解决低资源NER问题,可能会导致全局性的性能下降,甚至还不如直接基于词典的NER。这里给出一些可以尝试的解决思路(也许还会翻车):
a. 上文已介绍BERT在低资源条件下能更好地发挥作用:我们可以使用BERT进行数据蒸馏(半监督学习+置信度选择),同时利用实体词典辅助标注。
b. 还可以利用实体词典+BERT相结合,进行半监督自训练,具体可参考文献[8]
c. 工业界毕竟不是搞学术,要想更好地解决低资源NER问题,RD在必要时还是要介入核查的。
-
如何缓解NER标注数据的噪声问题? 实际工作中,我们常常会遇到NER数据可能存在标注质量问题,也许是标注规范就不合理(一定要提前评估风险,不然就白干了),正常的情况下只是存在一些小规模的噪声。一种简单地有效的方式就是对训练集进行交叉验证,然后人工去清洗这些“脏数据”。当然也可以将noisy label learning应用于NER任务,惩罚那些噪音大的样本loss权重,具体可参考文献[9]。
-
如何克服NER中的类别不平衡问题? NER任务中,常常会出现某个类别下的实体个数稀少的问题,而常规的解决方法无外乎是重采样、loss惩罚、Dice loss[10]等等。而在医疗NER中,我们常常会发现这类实体本身就是一个长尾实体(填充率低),如果能挖掘相关规则模板、构建词典库也许会比模型更加鲁棒。
-
如何对NER任务进行领域迁移? 在医疗领域,我们希望NER模型能够在不同医院、不同疾病间进行更好地泛化迁移(领域自适应:源域标注数据多,目标域标注数据较少),如可以尝试将特征对抗迁移[11]。 在具体实践中,对抗&特征迁移通常还不如直接采取finetune方式(对源域进行预训练,在目标域finetune),特别是在后BERT时代。在医疗领域,泛化迁移问题并不是一个容易解决的问题,试图去将NER做成一个泛化工具往往是困难的。或许我们更应该从业务角度出发去将NER定制化,而不是拘泥于技术导致无法落地。
-
如何让NER系统变得“透明”且健壮? 一个好的NER系统并不是“一竿子插到底”的黑箱算法。在医疗领域,实体类型众多,我们往往需要构建一套多层级、多粒度、多策略的NER系统。
a. 多层级的NER系统更加“透明”,可以回溯实体的来源(利于医学实体消歧),方便“可插拔”地迭代优化;同时也不需要构建数目众多的实体类型,让模型“吃不消”。
b. 多粒度的NER系统可以提高准召。第⼀步抽取⽐较粗粒度的实体,通过模型+规则+词典等多策略保证⾼召回;第⼆步进⾏细粒度的实体分类,通过模型+规则保证⾼准确。
-
如何解决低耗时场景下的NER任务? 从模型层面来看,1层lstm+CRF已经够快了。从系统层面来看,重点应放在如何在多层级的NER系统中进行显存调度、或者使当前层级的显存占用最大化等。
综上,如果能在1层lstm+CRF的基础上引入更丰富的embedding特征、并进行多策略组合,足以解决垂直领域的NER问题;此外,我们要更好地利用BERT、使其价值最大化;要更加稳妥地解决复杂NER问题(词汇增强、冷启动、低资源、噪声、不平衡、领域迁移、可解释、低耗时)。
lstm+crf做实体提取时,保证精度的情况下,在提升模型速度上有没有什么好的办法或者建议?
杰神同样给予了一个饱含实战经验的回答:
个⼈经验来说,1层lstm+CRF够快了。
-
如果觉得lstm会慢,换成cnn或transformer也许更快一些,不过效果好不好要具体分析; 通常来说,lstm对于NER任务的⽅向性和局部特征捕捉会好于别的编码器。
-
果觉得crf的解码速度慢,引入label attention机制把crf拿掉,比如LAN这篇论文[12];当然可以⽤指针网络替换crf,不过指针网络收敛慢⼀些。
-
如果想进行模型压缩,比如对lstm+crf做量化剪枝也是⼀个需要权衡的⼯作,有可能费力不讨好~
可以看出,哪怕是命名实体识别,中文分词甚至文本分类这些看似已经在公开数据集上被求解的任务,放在实际的工业界场景下都可能存在大量的挑战。这也是提醒还未踏入工业界的小伙伴们,不仅要刷paper追前沿,更要记得积极实践,在实际问题中积累NLP炼丹技巧哦。
图文并茂生动详解命名实体识别NER理论与代码实战
nlp中的实体关系抽取方法总结
补充
生物医学命名实体识别(BioNER)最全论文清单
序列标注BIO、BIOSE、IOB、BILOU、BMEWO的异同
结论:
结论写在前面:大多数情况下,直接用BIO就可以了; 大多数情况下BIO和BIOES的结果差不太多,
文末展示了各个数据集上的结果。
CRF和LSTM 模型在序列标注上的优劣?
LSTM和crf是两个层面的东西。
crf的核心概念,是计算序列全局的似然概率,其更像一个loss的选择方式。
与其相对应的应该是cross entropy。crf把一个序列当作一个整体来计算似然概率,
而不是计算单点的似然概率。这样使得其在序列标注问题中效果比较好。
即使现在主流使用LSTM模型的,也会在loss层使用crf,基本验证是更好的。
而与LSTM相对应的应该是原来crf模型中特征层面的东东。比如在传统的crf模型中,
需要人工选择各种特征,但是目前主流的解决方案中倾向于,embedding层+bilstm层,
直接机器学习到特征。也就是end-to-end的思路。
三个角度对比
一、
做为一种概率图模型,CRF在理论上更完美一些,一步一步都有比较坚实的理论基础。
不过CRF的假设也比较明确,然而问题不总是能match其假设的。
LSTM理论上是能拟合任意函数的,对问题的假设明显放宽了很多。不过深度学习类模型的理论原理和可解释性一般。
二、
CRF比较难扩展,想在图模型上加边加圈,得重新推导公式和写代码。
LSTM想stack起来、改双向、换激活函数等,只不过左手右手一个慢动作的事儿。
三、
CRF针对大数据不好做。
LSTM有各种GPU加速,多机异步SGD等标准大数据训练套路。但同样的问题,
训练数据不够的话过拟合会很严重,效果堪忧。















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









